1. Основные методы организации и обработки данных
2. Многоуровневое представление данных
3. Концептуальное моделирование данных
4. Логическое моделирование данных
4.1. Реляционная модель данных
4.2. Основные операции реляционной алгебры
4.3. Переход от ER-диаграмм к системе отношений (таблиц)
4.4. Понятие первичного и внешнего ключа
4.5. Ограничительные условия, поддерживающие целостность
5. Элементы пользовательского интерфейса в системе Microsoft Windows
8. Управление параллельным доступом
12. Администрирование базы данных
14. Перспективные направления развития информационных систем
1. Основные методы организации и обработки данных
1.1. Основные определения
Информация – это сведения интересующие пользователя.
Данные – описание какого-либо процесса, объекта или явления которое необходимо зафиксировать.
Модель данных (МД) – это средство обработки данных, позволяющее увидеть не только конкретные значения данных, но и их смысл.
Предметная область – это часть реального мира, которая подлежит изучению с целью организации управления и описания.
База данных (БД) – это совокупность данных о конкретной предметной области.
Объект БД – это элемент предметной области, о котором мы хотим хранить информацию.
Характеристики объекта: Имя, свойства, значение этого свойства.
Схема БД – это совокупность объектов БД и связей между ними.
Модель данных включает в себя 3 основных компонента:
- Структура данных.
- Множество операций над данными.
- Ограничения накладываемые на данные.
Система управления базами данных (СУБД) – это совокупность программных средств, реализующее все 3 компонента модели данных в готовом виде.
1.2. Этапы развития средств организации и обработки данных
Этап 1. Создание индивидуальных подпрограмм доступа и обработки данных каждым разработчиком для своих приложений
программы доступа и обработки данных создавались индивидуально каждым разработчиком для своих приложений.
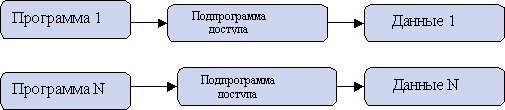
Этап 2. Появление стандартных библиотек для работы с данными

Этап 3. Появление баз данных, объединяющих данные всей организации, используемые разными приложениями
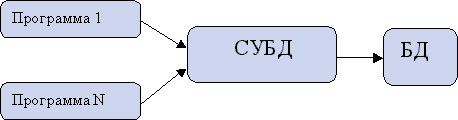
Развитие СУБД продвигалось в двух направлениях:
- Внедрение в имеющиеся языки программирования функций работы с БД.
- Автономные системы работы с БД.
Преимущества СУБД:
- Сокращение избыточности данных.
- Устранение противоречий данных.
- Возможность параллельной работы с данными нескольких пользователей.
- Возможность соблюдения стандартов предметной области.
- Возможность защиты данных.
- Независимость данных от программ их обработки.
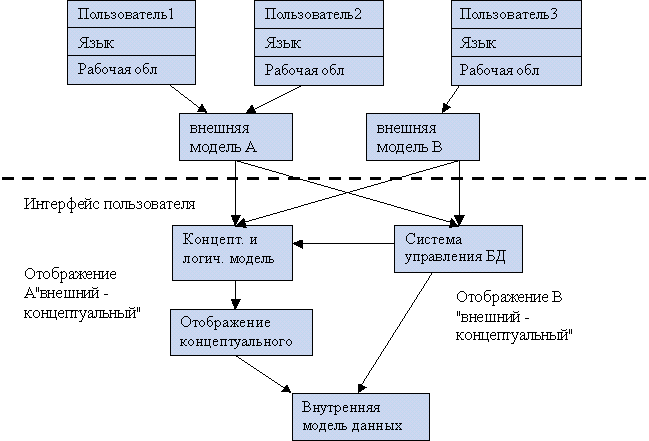
2. Многоуровневое представление данных
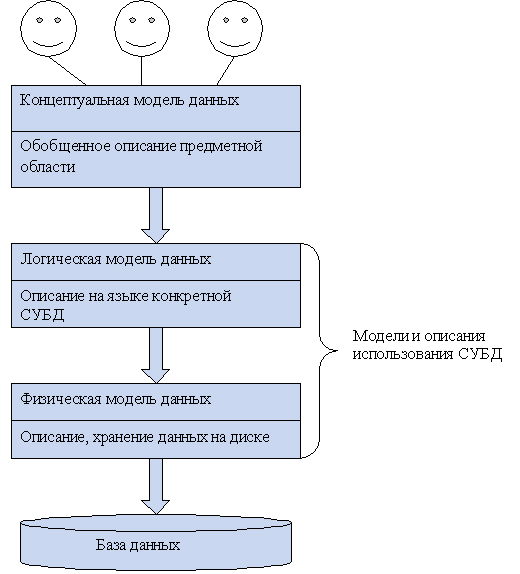
Администратор БД, пользователи различных категорий
Существует 4 модели данных:
- Иерархическая.
- Сетевая.
- Реляционная (данные представлены в виде таблиц).
- Внешняя (интерфейс пользователя).
3. Концептуальное моделирование данных
Диаграммы “сущность-связь” (ER-диаграммы).
Основные определения:
Основными компонентами этой модели являются сущности, атрибуты сущности и связи между сущностями.
Сущность – это объект предметной области, о котором необходимо хранить информацию (Например, сущностью является студент).
Атрибут сущности – это параметр, характеризующий сущность (Если студент- это сущность, то атрибутами сущности будут являться Ф.И.О. студента, год его поступления в ВУЗ, возраст, номер зачётной книжки и т.п.).
Связь между сущностями – это ассоциирование между двумя или несколькими сущностями.
Экземпляр сущности – это пример сущности.
Классификация связей между сущностями.
-
- По арности
Арность – это количество сущностей, участвующих в связи.
По арности связи могут быть:
-
- Бинарные (2сущности).
- Тернарные (3 сущности).
- Унарные (связь сущности с собой).
- По значности
- Один к одному. Это такой вид связи , в котором одному экземпляру первой сущности соответствует один экземпляр второй сущности.
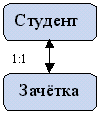
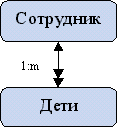
- Один ко многим (1:m). Это такой вид связи, при котором одному экземпляру первой сущности соответствует несколько экземпляров второй сущности, но не наоборот.
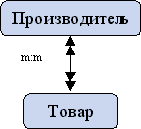
- Многие ко многим (m:m). Это такой вид связи, при котором одному экземпляру первой сущности соответствует несколько экземпляров второй сущности и наоборот.
-
- По членству
- Обязательные
- Возможные
- Необязательные
- По членству
Обязательная связь – это такой вид связи, при котором обе связываемые сущности зависят от наличия связи.
Возможная связь – это такой вид связи, при котором одна из связываемых сущностей зависит от наличия связей.
Необязательная связь – это такой вид связи, при котором обе сущности не зависят от наличия связей.
Сущность может быть подмножеством другой сущности.
4. Логическое моделирование данных
4.1. Реляционная модель данных
Реляционная модель данных – это такая модель данных, в которой данные представлены в виде таблиц.

Основные понятия реляционной МД.
Атомарное значение – неделимое значение.
Домен – множество атомарных значений одного и того же типа. Если значения принадлежат одному и тому же домену, то имеет смысл их сравнение. А1, А5, А7, Аi – атрибуты отношения, т.е. набор значений принадлежащих к одному и тому же домену.
Заголовок (схема отношений) – это набор его атрибутов.
Математическое определение отношений. Если V1, V2…, Vi – это набор множеств именуемых доменами, тогда отношение R (V1, V2, .., Vi) представляет собой подмножество декартовых произведений доменов (V1*V2*…*Vi). Каждому домену приписывается имя, в качестве отношения рассматривается отношение этих имён. Элементом отношения является кортеж.
Кортеж – это множество пар имён атрибутов, значений атрибутов (это строка таблицы).
Мощность отношения – это число его кортежей.
Степень отношения – это число его атрибутов (число столбцов в таблице).
Возможный ключ отношения – это минимальный набор атрибутов, который однозначно определяет кортеж. У ключа есть 2 свойства: уникальность и минимальность.
Уникальность – значения ключевых атрибутов не могут повторяться.
Минимальность – ни один из атрибутов не может быть исключён из набора без нарушения уникальности.
Свойства отношений:
- Отношение имеет своё уникальное имя.
- Уникальность имён атрибутов.
- Отсутствие кортежей-дубликатов.
- Атомарность значений атрибутов.
- Отсутствие упорядоченности атрибутов и кортежей.
4.2. Основные операции реляционной алгебры
В реляционной алгебре в качестве операндов используются отношения. В результате этих операций возникают новые отношения.
Условные обозначения:
X, Y – отношения-операнды.
R – отношение-результат.
Mx, My, Mr – мощности отношений X,Y,R.
А, B – подмножества схем отношений.
Все операции можно разбить на 2 группы:
- Теоретико-множественные.
- Операции, учитывающие структуру решений как модель данных.
-
- Объединение.
R=X+Y
Max(Mx,My) ≤ Mr ≤ Mx+My
Схемы кортежей и операндов должны быть одинаковы. - Разность.
R=X-Y
0 ≤Mr ≤ Mx - Пересечение
R=X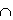 Y=X-(X-Y)
Y=X-(X-Y)
0 ≤ Mr ≤min(Mx,My) - Декартово произведение.
R=X*Y
Mr=Mx*My
- Объединение.
X:
|
A |
B |
|
15 |
7 |
|
8 |
11 |
Y:
|
W |
Z |
|
6 |
4 |
|
2 |
3 |
R=X*Y:
|
A |
B |
W |
Z |
|
15 |
7 |
6 |
4 |
|
8 |
11 |
6 |
4 |
|
15 |
7 |
2 |
3 |
|
8 |
11 |
2 |
3 |
-
- Проекция (ограничение).
R=X(A), где A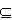 схема X.
схема X.
Результатом проекции является отношение со схемой А, где каждый кортеж составлен из значений соответствующего кортежа Х.
Пример:
- Проекция (ограничение).
Х:
|
Ф.И.О. |
Отдел |
должность |
Оклад |
|
Иванов |
ОГЭ |
Слесарь |
1000 |
|
Петров |
ОГМ |
Электрик |
2000 |
|
Сидоров |
ОГЭ |
Мастер |
3000 |
R=X(Ф.И.О.)
R:
|
Ф.И.О. |
|
Иванов |
|
Петров |
|
Сидоров |
Операция проекции обладает свойством собственности. Это значит, что 2 последовательных проекции могут быть заменены одной проекцией при соблюдении следующих условий:
![]()
- Селекция (выбор).
R=X(A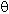 B), где А
B), где А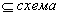 Х, В- множество констант,
Х, В- множество констант, 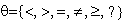
Нужно, чтобы А и В были сравнимы по смыслу с.
Для всякого Ai,j Bi,j должно иметь смысл.
Результатом операции селекции является отношение, состоящее из тех кортежей Х, которые удовлетворяют заданным условиям. Селекция часто используется в комбинации с проекцией. - Деление.
R=X(B)Y; B![]() схема Y
схема Y
Результатом операции деления является минимальное множество кортежей таких, что декартово произведение этого множества с Y присутствует в X.
Y(B)![]() X
X
- R1=X(A-B)*Y(B)-X(A)
- R=X(A-B)-R1(A-B)
Пример: Найти преподавателя, который проводит занятия по каждой дисциплине.
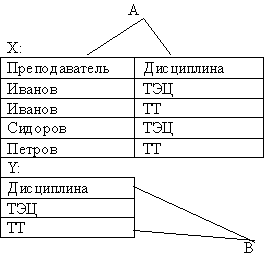
8. Соединение.
R=X(A![]() B)Y A
B)Y A![]() схема Х
схема Х
В![]() схема Y, или множество констант.
схема Y, или множество констант.
Результатом операции соединения является селекция по заданному условию декартова произведения операндов.
R1=X*Y R=R1(A![]() B)
B)
Пример: соединить отношения Х и У по условию W>5:
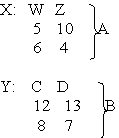
X(W>5)Y
R1: W Z C D W Z C D
5 10 12 13 6 4 8 7
6 4 8 7 6 4 12 13
5 10 8 7
6 4 12 13
9. Переименование.
Результатом переименования является тождественно равное отношение операндов, но с другим именем
Операции реляционной алгебры используются в запросах для поиска нужных данных в таблице.
4.3. Переход от ER-диаграмм к системе отношений (таблиц)
При создании системы отношений необходимо выполнить следующие условия:
- Информация в таблицах не должна повторяться.
- Поля таблиц не должны принимать неопределённых (пустых) значений.
ШАГ 1
- Преобразование сущностей. Каждая простая сущность становится таблицей.
- Каждый атрибут сущности становится столбцом в таблице.
- Уникальный идентификатор сущности становится первичным ключом таблицы.
- Если в ER-диаграмме присутствовали подтипы сущностей, они выносятся в отдельные столбцы.
ШАГ 2
Переход от ER-диаграмм к системе отношений.
|
Значность связи |
Членство |
Число таблиц |
|
1:1 |
Обязательная |
1 |
|
Возможная |
2 |
|
|
Необязательная |
3 |
|
|
1:m |
Обязательная |
2 |
|
Возможная |
2 |
|
|
Необязательная |
3 |
|
|
m:m |
Обязательная |
3 |
|
Возможная |
3 |
|
|
Необязательная |
3 |
4.4. Понятие первичного и внешнего ключа
Ключ – это минимальный набор атрибутов, который однозначно определяет кортеж.
Минимальность означает, что никакое подмножество атрибутов входящих в ключ не будет являться ключом.
Суперключ – это любой набор атрибутов, который однозначно определяет кортеж.
Составной ключ – это ключ, содержащий 2 или более атрибутов. Возможных ключей может быть много, но только один из них выбирается в качестве первичного.
Первичный ключ – это ключ наиболее удобный для поиска строк таблицы.
Внешний ключ – это набор атрибутов одного отношения, который является ключом другого отношения или того же самого отношения.
Рекурсивный внешний ключ – это внешний ключ, который ссылается на своё собственное отношение.
Набор схем отношений с определёнными первичными и внешними ключами называется схемой данных.
4.5. Ограничительные условия, поддерживающие целостность
Целостность – это согласованность данных в базе данных.
Ограничительные условия – это правила, которые определяют набор возможных значений в БД.
- Существует 2 вида целостности:
- Категорная целостность
- Целостность на уровне ссылок
Категория – это конкретный объект, информация о котором хранится в БД.
Правила категорной целостности заключаются в том, что никакой ключевой атрибут строки не может оставаться пустым.
При целостности на уровне ссылок каждое непустое значение внешнего ключа должно быть равно одному из текущих значений первичного ключа связанного с ним отношения.
Каскадное обновление – это автоматическое обновление данных в таблице при изменении данных связанных с ней.
4.6. Аномалии хранения данных
Аномалия обновления – это противоречивость данных, связанная с избыточностью и частичным обновлением.
Аномальное удаление – непреднамеренная потеря данных в связи с удалением других данных.
Аномалии ввода – это невозможность ввести данные в таблицу ввиду отсутствия других данных.
Декомпозиция – это разделение таблиц на 2 или несколько таблиц с целью устранения аномалий.
Подход создания БД с помощью декомпозиции называется аналитическим.
Синтетический способ – это способ, когда создаются таблицы сразу без аномалий.
4.7. Функциональная зависимость
R(X,Y) ; X,Y ![]() схема R.
схема R.
Если не может существовать более одного кортежа R, совпадающего по всем значениям из Х и отличающегося хотя бы по одному значению по Y, то зависимость называют функциональной зависимостью по Х.
Классификация функциональных зависимостей.
- Полная функциональная зависимость(ФЗ).
Y зависит от Х, но не зависит от любого подмножества Х. - Неполная ФЗ.
Y зависит от Х и от какого-нибудь подмножества Х. - Тривиальная ФЗ.
Y является подмножеством Х. - Транзитивная ФЗ.
R(X,Y,Z); X,Y,Z R
X Z, Z Y, X Y.
Z, Z Y, X Y.
В этом случае Х функционально определяет Z, Z определяет Y, когда Х не определяет функцию Y. - Многозначная ФЗ.
Говорят, что в отношении R с наборами атрибутов X,Y,Z имеется многозначная ФЗ, если существует множество значений Z, соответствующее паре значений X и Y, которое зависит функционально от Y, но не зависит функционально от Z.
Правила вывода или аксиомы Армстронга.
Сформулируем правила вывода:
- Рефлексивность.
X,Y схема R
Если XY, то Y X. - Присоединение.
X,Y,Z
W Z
XZ=X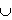 Z
Z
Если X Y, то XZ YW. - Транзитивность.
X,Y,Z
Если X Y и Y Z, то X Z - Псевдотранзитивность.
X,Y,Z,W
X W=XW
Y W=YW
Если X Y, XW YW, YW Z, то YW Z - Объединение.
X,Y,Z
Если X Y, X Z, то X YZ - Декомпозиция.
X,Y,Z
Если X YZ, то X Y и X Z
4.8. Нормальные формы отношений
Нормализация – это разбиение таблицы на 2 или несколько таблиц с целью улучшения её свойств при включении, добавлении или удалении данных.
Каждая таблица делится до тех пор, пока она не станет обладать некоторыми определёнными свойствами.
Свойства нормальных форм:
- Каждая нормальная форма должна обладать лучшими свойствами при включении, добавлении и удалении данных, чем предыдущая.
- Каждая следующая нормальная форма должна сохранять форму предыдущей.
Первая нормальная форма (1НФ).
При первой нормальной форме значения всех её атрибутов атомарные.
Сотрудники – отделы – проекты.
|
№сотрудника |
Зарплата |
№отдела |
№проекта |
Задание |
Ключом являются №сотрудника и №проекта
Функциональная зависимость (ФЗ):
№сотрудника ![]() зарплата (*)
зарплата (*)
№сотрудника, №проекта ![]() задание (**)
задание (**)
№сотрудника ![]() №отдела (***)
№отдела (***)
(*) и (***) – это неполные ФЗ.
Чтобы избежать аномалий, нужно данную таблицу разделить на 2 таблицы: удаляются все неполные ФЗ.
Вторая нормальная форма (2НФ).
Сотрудники – отделы
|
№сотрудника |
Зарплата |
№отдела |
Сотрудники – проекты
|
№сотрудника |
№проекта |
Задание |
ФЗ:
зарплата ![]() отдел
отдел
отдел ![]() зарплата
зарплата
сотрудник ![]() зарплата
зарплата
Третья нормальная форма (3НФ).
Сотрудники – отделы
|
№сотрудника |
№отдела |
Отдел – зарплата
|
№отдела |
Зарплата |
Отношение находится в 3НФ, когда удалены транзитивные ФЗ.
Нормальная форма Бойса-Кодда (НФБК).
|
№сотрудника |
Имя сотрудника |
№проекта |
Задание |
ФЗ:
№сотрудника ![]() имя сотрудника
имя сотрудника
№сотрудника, №проекта ![]() задание
задание
№сотрудника ![]() №проекта
№проекта
Имя сотрудника ![]() №проекта
№проекта
Исходная таблица разделяется на 2 таблицы:
|
№сотрудника |
Имя сотрудника |
|
№сотрудника |
№проекта |
Задание |
Отношение находится в НФБК, если любая нетривиальная зависимость в нём есть зависимость от ключа
№сотрудника, №проекта ![]() задание
задание
Четвёртая нормальная форма (4НФ).
Отношение находится в 4НФ, если любая многозначная зависимость в ней есть зависимость от ключа.
Достаточным условием для 4НФ является наличие в отношении не более 2 атрибутов.
|
№сотрудника |
№проекта |
Задание |
Исходная таблица разделяется на 2 таблицы:
|
№сотрудника |
№проекта |
|
№проекта |
Задание |
Пятая нормальная форма (5НФ).
Отношение находится в 5НФ тогда, когда в любой её полной декомпозиции все проекции содержат возможный ключ.
|
№сотрудника |
№отдела |
№проекта |
Ключ: №сотрудника, №отдела, №проекта
|
№сотрудника |
№отдела |
|
№сотрудника |
№проекта |
|
№отдела |
№проекта |
Общие правила нормализации:
1.T(k1,k2,F), k2 ![]() F , где Т, Т1,Т2 – это таблицы, k1, k2 – ключи.
F , где Т, Т1,Т2 – это таблицы, k1, k2 – ключи.![]()
T1(k1, k2), T2(k2, F).
3.T(k,F1,F2), F1 ![]() F2
F2![]()
T1(k, F1), T2(k, F2).
5. Элементы пользовательского интерфейса в системе Microsoft Windows
Интерфейс БД – это граница в системе, за которой пользователь ничего не видит.
Виды интерфейсов:
- Консольный интерфейс.
- Пассивный диалог.
- Оконный интерфейс.
Элементы интерфейса:
- Меню – это набор команд, из которых мы можем сделать выбор.
Различают горизонтальное, вертикальное, комплексное и контекстное меню.
Контекстное меню – это меню, которое может появиться в любом месте экрана.
Свойства команд меню:
- Доступность.
- Видимость. - Кнопка – это элемент управления прямоугольной формы, при нажатии на которую выполняется некоторая команда.
Кнопки бывают: с фиксацией, без фиксации, со значением по умолчанию, невидимая, флажок, радиокнопка. - Список – это набор значений, из которого выбирается необходимое.
Список ускоряет работу пользователя.
Различают обычный список и разворачивающийся список. - Поле – служит для отображения: изменений, просмотра, добавления данных в поля таблиц и т.п.
- Надпись – это объект, который появляется на экране, но не реагирует на действия пользователя.
Объектно-ориентированный подход к разработке интерфейса.
Программа оперирует не с базовыми типами переменных, а с объектами.
Различают 3 основных подхода к написанию программ:
- Алгоритмический (Например в языке Фортран).
- Модульный (Например языки Паскаль, Си).
Программа разбивается на набор модулей и с каждым модулем можно работать отдельно. - Объектно-ориентированный (Например в языке Си++).
Решаются задачи разработки и хранения данных, используется в инженерном проектировании.
Большинство программ являются событийно-управляемыми.
Событийная управляемость – это характеристика приложения. Она означает, что на происходящее событие откликается написанный для них сценарий.
Пример события: нажатие на кнопку, перемещение и т.п.
Сценарий – набор команд, выполняющихся в ответ на событие.
Приложение имеет иерархическую структуру.
Каждый объект управления обладает следующими свойствами:
- Шаблон – эта группа описывает внешний вид объекта.
- Данные – определяют поля таблиц БД, являющихся источником и приёмником для данного объекта управления.
- События. На них реагирует объект и связанный с этими объектами сценарий.
Разработка проекта интерфейса БД.
- Форма – это окно для ввода, изменения, удаления, просмотра и поиска данных в БД.
- Отчёт – способ представления данных на печать.
- Страница доступа к данным – это страница в Интернете, через которую мы осуществляем доступ к БД.
Этапы разработки интерфейса:
Определение количества и назначения окон входящих в интерфейс.
- В каждую из форм размещаются объекты (элементы) управления для выполнения различных действий.
- Определение свойств каждого элемента управления.
- Написание процедуры обработки событий, связанных с каждым объектом.
Для того чтобы создать качественный интерфейс нужно:
- Учитывать потребности пользователя.
- Учитывать дизайн.
- Учитывать время, затрачиваемое пользователем.
- Соблюдать санитарные требования (надписи должны быть хорошо читаемы, размеры элементов управления – крупными, количество элементов управления на экране должно быть не очень большим).
6. Защита данных
Защита данных есть комплекс мероприятий, предназначенных для обеспечения целостности, непротиворечивости, безопасности и секретности данных.
Непротиворечивость - свойство данных, заключающееся в отсутствии копий данных, находящихся на разных стадиях обновления.
Целостность - свойство данных, заключающееся в нахождении значений данных в определенных диапазонах. Например, первичный ключ должен быть уникальным и не пустым.
Секретность - свойство данных, заключающееся в отсутствии возможности несанкционированного доступа к ним.
Безопасность - свойство данных, заключающееся в отсутствии возможности их физического уничтожения.
Мероприятия по защите данных.
Все мероприятия разделяются на 3 группы:
- Организационные мероприятия
- Технические мероприятия
- Программные мероприятия
Организационные мероприятия, например, это ограничение доступа к помещению с данными.
Технические мероприятия - охранные комплексы, комплекты сигнализаций, видеокамеры и т.д.
Программные мероприятия - системы паролей и идентификации пользователей.
К мероприятиям относится следующее:
- Ограничение доступа к данным.
- Ограничение обработки данных.
- Ведение системного журнала.
- Управление транзакциями.
- Использование контрольных точек.
- Управление параллельным доступом.
- Страховое копирование.
Ограничение доступа к данным.
Доступ к данным можно ограничить на уровне пользователя и на уровне данных.
Существует 4 категории пользователей:
- Владелец данных - пользователь, который создал данные.
- Группа пользователей - определенный владельцем круг лиц, имеющих те или иные права на данные.
- Общие права - предоставляются все.
- Администратор - в рамках данной системы он может все.
Способы контроля доступа:
- Идентификация
- Верификация
Идентификация - процедура, определяющая права доступа. Для любого пользователя существует уникальное имя (login), определяющее его категорию и права.
Верификация - процедура, подтверждающая права пользователя с помощью паролей, электронных подписей, отпечатков пальцев и т.п.
Ограничение доступа на уровне данных достигается путем разделения данных на:
- Пользовательские
- Групповые
- Общие
- Системные.
Ограничение обработки данных.
Может быть на уровне пользователя и на уровне данных.
Ограничение на уровне пользователя предполагает наделение пользователя совокупностью прав на обработку данных:
- Чтение
- Запись/модификация
- Удаление
- Передача прав другим пользователям (только администратор)
Ограничение прав на уровне данных предполагает определение для каждых данных множества операций, которые допустимо выполнять над данными:
- Данные только для чтения
- Те данные, которые можно изменять
- Те данные, которые можно удалять
Ведение системного журнала.
Системный журнал - набор данных, в которых автоматически вводятся записи обо всех изменениях в базе данных.
Системный журнал необходим для того, чтобы в случае сбоя можно было восстановить согласованное состояние базы данных.
Управление транзакциями.
Транзакция - набор операций над данными, воспринимаемый, как единое целое. Примером транзакции может быть перевод денег с одного электронного счёта на другой. На внешний носитель записываются только результаты завершенных транзакций.
BEGIN TRANSACTION начать транзакцию
READ A прочитать какие-то данные
A=A+1 совершить над данными определённые операции
…
…
COMMIT зафиксировать результат транзакции
(ROLLBACK) (откат) необходимо отменить результат транзакции.
Каждая операции транзакции заносится в буфер системного журнала. При получении ROLLBACK начинается выполнение операций обратных тем, что были в транзакции. При получении COMMIT на внешнем носителе сохраняются результаты транзакции, а в системном журнале отмечается факт выполнения транзакции.
Недостаток журнала - большие затраты памяти.
Для сокращения затрат на буфер внутри транзакции организуются контрольные точки.

В случае выполнения отката он происходит от ближайшей контрольной точки.
Управление параллельным доступом
Параллельный доступ - ситуация, когда к одним и тем же данным обращается одновременно несколько пользователей. При этом возможны следующие конфликты:
- R-W (read-write, чтение-запись): когда один пользователь читает данные, модифицируемые другим пользователем.
- W-R (write-read, запись-чтение): когда один пользователь модифицирует данные, читаемые другим пользователем.
- W-W (write-write, запись-запись): когда 2 транзакции модифицируют одновременно одни и те же данные.
Избежать этих конфликтов можно введя блокировки по чтению и по записи.
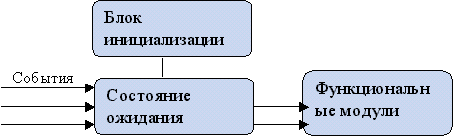
Потенциальные пути утечки и повреждения информации.
|
ЭВМ |
Компьютер, на котором находится БД |
|
УК |
Узел коммутации |
|
Т |
Терминал |
|
1 |
Электромагнитное излучение |
|
2 |
Подключение к каналам связи |
|
3 |
Перекрестные помехи |
|
4 |
Ошибки коммутации |
|
5 |
Ошибки ввода |
|
6 |
Ошибки программного обеспечения |
|
7 |
Аппаратные сбои |
|
8 |
Подглядывание, подслушивание |
|
9 |
“Сбор мусора” |
Атаки на БД можно ждать:
- со стороны пользователей
- со стороны персонала (администраторов подсистем)
- программистов
- электронщиков
- вспомогательный персонал
Классификация угроз системе защиты.
-
- Случайные
- стихийные бедствия
- ошибки ввода
- сбои в аппаратном обеспечении
- ошибки в программном обеспечении
- Неслучайные
- Подключение к каналам связи
- сбор ЭМИ, “мусора”
- Косвенные(нет явного нарушения защиты, но действия могут способствовать)
- Непосредственные
- Случайные
(действия, ведущие к потерям информации)
Мероприятия, по защите секретности.
- Ограничения доступа
- Контроль за путями утечки
- Шифрование
- Контроль надежности всех элементов информационной системы (аппаратура, программное обеспечение, данные, персонал)
7. Языковые средства СУБД
Языковые средства СУБД представляют собой:
- Язык описания данных (Data Definition Language, DDL)
- Язык манипулирования данными (Data Manipulation Language, DML)
DDL позволяет:
- Определить структуру данных
- Определить связи между данными
- Определить ограничения на данные.
DME позволяет описать алгоритмы доступа и обработки данных.
Реализации языковых средств СУБД делятся на:
- Закрытые системы: со свои собственным языком и не работающих со стандартными языками (dBase, FoxPro)
- Открытые системы: нет своего языка, а пользующие универсальные языки программирования.
- Комбинированные системы: симбиоз открытых систем и закрытых.
Базовый язык описывает структуры и алгоритмы обработки данных
Расширение языка работает с данными.
Способы реализации базового языка:
- Новый транслятор (Pascal -> Delphi)
- Препроцессор (программа, реализующая команды работы с данными в последовательности команд базового языка)
- Call-интерфейс (библиотека, нужная для работы с данными)
Реализация call-интерфейса через много подпрограмм (dBase: dbopen(), dbclose()…)
Реализация call-интерфейса через одну процедуру, где команда передается через параметры
SQL (Structured Query Language).
Реляционно-ориентированный язык, позволяющий минимумом команд реализовать около 30 операций по работе с данными, позволяющий как формулировать запросы, так и писать прикладные программы.
Команды делятся на группы:
- Команды определения данных
- создание БД
- создание таблиц
- задание полей таблиц
- создание индексов
- удаление таблиц, индексов, БД.
- Запросы на выборку данных
- Команды модификации данных
- добавление данных
- удаление данных
- изменение данных
- Команды управления данными
- привелегии
- паралельный доступ
- транзакции
Кроме команд, существует множество операторов:
- Арифметические вычисления
- сравнения
- создание виртуальных таблиц
- запоминание результатов запросов/вычислений в таблицах БД
- группировка данных по группам
Типы данных в SQL:
| integer | целые числа |
| decimal(p,q) | с фиксированной точкой, p- всего знаков, q – после запятой |
| float | с плавающей точкой |
| char(n) | строка длиной n |
| archer | строка переменной длины |
| date | дата |
| time | время |
| datetime | дата/время |
| money | денежный тип |
| logical | логический |
| doubleprecesion | двойная точность |
Cуществует 3 уровня языка SQL
- Минимальный SQL
- INSERT
- SELECT
- UPDATE
- Базовый SQL
- ALTER TABLE
- CREATE TABLE
- CREATE VIEW
- Более рсширеный синтаксис SELECT
- Расширеный SQL (используется в “навороченных” СУБД Oracle, DB2…)
Запросы в SQL.
Запросы бывают:
- Простые (данные берутся только из одной таблицы)
- Многотабличные (данные из нескольких таблиц)
- Вложенные (запрос внутри запроса)
SELECT [[ALL]/DISTINCT] {*/поле1, поле2…}
FROM {базовая таблица1/представление 1}, {базовая таблица2/представление 2}
[WHERE условие]
Результатом команды SELECT есть таблица (представление).
ALL все значения в столбцах
DISTINCT только уникальные значения
FROM задает таблицы, откуда запрашивается
WHERE условия на выборку
Пример 1:
Список штукатуров
SELECT Фамилия
FROM Сотрудник
WHERE Должность=’штукатур’
Пример 2:
Данные о всех студентах АД-76
SELECT *
FROM Студенты
WHERE Группа=’АД-76
Составное условие
WHERE [NOT] условие1 [AND/OR] [NOT] условие2…
условия:
значение {=/<>/<=/</>=/>} {константа/выражение}
значение1 [NOT] BEETWEEN значение2 AND значение3
значение [NOT] IN {список констант/значений}
значение IS [NOT] NULL
Пример 3:
Сотрудники с окладом 800..1000 р.
SELECT Фамилия
FROM Сотрудники
WHERE Оклад BEETWEEN 800 AND 1000
Пример 4:
Сотрудники 2, 5 и 6 отделов
SELECT Фамилия
FROM Сотрудники
WHERE Отдел IN 2,5,6
Пример 5:
Студенты АД-76, не сдававшие экзамен
SELECT Фамилия
FROM Студент
WHERE Группа=’АД-76’ AND Оценка IS NULL
ORDER BY Упорядочить выводимые поля
ASC по возрастанию
DESC по убыванию
Пример 6:
Студенты АД-76, упорядоченные по алфавиту
SELECT Фамилия
FROM Студент
WHERE Группа=’АД-76’
ORDER BY Фамилия ASC
Многотабличный запрос
Сотрудники:
|
Код сотрудника |
Фамилия |
Код отдела |
|
1 |
Иванов |
1 |
|
2 |
Петров |
3 |
Отделы
|
Код отдела |
Название |
|
1 |
Снабжение |
Пример 7:
Список сотрудников из отдела “Снабжения”
SELECT Фамилия
FROM Сотрудники, Отдел
WHERE Название=’Снабжение’
AND Сотрудники.КодОтдела=Отдел.КодОтдела
Алгоритм выполнения запроса:
- Строится декартово произведение таблиц
- Из результата произведения выбираются нужные строки
- Из строк выбираются нужные столбцы
Пример 8:
|
КодСотрудника |
ФИО |
КодОтдела |
КодНачальника |
Необходимо выбрать ФИО и Фамилию начальника
SELECT А.Фамилия, В.Фамилия
FROM Сотрудник.А, Сотрудник.В
WHERE В.КодСотрудник=А.КодНачальника
Вложеные запросы.
Подзапрос помещается в WHERE главного запроса
Пример 9:
Расписание
|
КодСотрудника |
День |
Время |
Должности работающих в понедельник
SELECT Должность
FROM Сотрудник
WHERE КодСотрудника IN (
SELECT КодСотрудника
FROM Расписание
WHERE День=’Понедельник’
)
Подзапросы бывают двух видов:
- Некорелированные (результат подзапроса не зависит от главного запроса)
- Корелированные (связи нет)
Пример 10:
Списки людей, работающих в тех отделах, которые работают по понедельникам
Расписание
|
КодОтдела |
День |
Время |
SELECT Должность
FROM Сотрудники
WHERE КодОтдела IN (
SELECT КодОтдела
FROM Расписание
WHERE День=’Понедельник’ AND
Сотрудник.КодОтдела=
Расписание. КодОтдела=
)
Операции группировки
Встроенные в SQL функции
|
SUM |
Суммирование |
|
COUNT |
Количество элементов в группе |
|
AVG |
Среднее значение в группе |
|
MAX |
Максимальной значение в группе |
|
MIN |
Минимальной значение в группе |
Пример 11.
Максимальный и минимальный оклад
SELECT MAX(Оклад), MIN(Оклад)
FROM Сотрудники
Группировка:
SELECT . . .
. . .
. . .
GROUP BY {поле1, поле2} [HAVING условие]
HAVING- условие, накладываемое на группу
Пример 12.
Максимальный и минимальный оклад в отделе
SELECT MAX(Оклад), MIN(Оклад)
FROM Сотрудники
GROUP BY КодОтдела
Пример 13.
Максимальный и минимальный оклад в отделах, в которых более 1 сотрудника
SELECT MAX(Оклад), MIN(Оклад)
FROM Сотрудники
GROUP BY КодОтдела
HAVING COUNT(*)>1
Пример 14.
Сотрудники с окладом выше среднего по предприятию
SELECT Фамилия
FROM Сотрудники
WHERE Оклад> (
SELECT AVG(Оклад)
FROM Cотрудники
)
Команды модификации данных
Модификация - ввод новых данных в таблицы, изменение данных, удаление данных из таблицы.
Удаление данных
DELETE
FROM {таблица/представление}
[WHERE условие]
Удаляется из указанной таблицы все записи, удовлетворяющие условию.
DELETE
FROM Сотрудники
WHERE Фамилия=’Иванов’
Добавление данных
INSERT
INTO {таблица/представление} (столбец [, столбец..])
VALUES ({константа/переменная}[,{константа/переменная}…])
Добавляет строку с указанными значениями.
INSERT
INTO Сотрудники (Фамилия, Имя, Отчество)
VALUES ('Иванов', 'Иван', 'Иванович')
второй вариант
INSERT
INTO {таблица/представление} (столбец [, столбец..])
подзапрос
Пример:
INSERT
INTO Начальник (фамилия, имя, отчество)
(
SELECT фамилия, имя, отчество
FROM Сотрудники
WHERE Должность= 'Инженер'
)
Изменение данных
UPDATE {таблица/представление}
SET столбец=значение [,столбец=значение]…
WHERE условие
устанавливает значение столбцов в тех кортежах, которые удовлетворяют условию.
UPDATE {таблица/представление}
SET столбец=значение [,столбец=значение]…
FROM {базовая таблица/представление} [псевдоним]
[,{базовая таблица/представление} [псевдоним]…]
Пример:
UPDATE Поставка
SET Цена=0
WHERE КодПоставщика IN (
SELECT КодПоставщика
FROM Поставщики
WHERE Город=’Москва’
)
Использование операций реляционой алгебры в SQL
- UNION- объединение.
SELECT *
FROM Сотрудники UNION Начальники
- INTERSECT – Пересечение
SELECT *
FROM Сотрудники INTERSECT Начальники - EXCEPT – разность
SELECT *
FROM Сотрудники EXCEPT Начальники - JOIN- Соединение
- Естественное соединение
От результата остаются только строки с совпадающими общими строками.
“Сотрудники JOIN должность” равносильно
SELECT *
FROM Сотрудники, Должность
WHERE Сотрудники.КодДолжности=Должность.КодДолжности. - Тета-соединение
- Соединение с тета-операцией
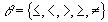
Команды определения данных
Это команды, позволяющие создавать/удалять таблицы, индексы, представления.
Таблицы.
CREATE TABLE базовая_таблица (столбец тип_данных [NOT NULL] ….)
Создать таблицу с указанным набором столбцов. NOT NULL показывает, что столбец не может быть пустым.
CREATE TABLE Сотрудник (Фамилия CHAR(50) NOT NULL)
DROP TABLE базовая_таблица
Удалить таблицу
Индексы
Индексы позволяют выполнять более быстрый поиск по таблице.
Индекс представляет собой один или несколько столбцов таблицы, по которым наиболее часто ведётся поиск, упорядоченные по значению первичного ключа.
CREATE [UNIQUE] INDEX имя_индекса
ON Базовая_Таблица (столбец [[ASC]/DESC]…)
- Создать индекс на основе таблицы и указанных столбцов таблицы.
DROP INDEX имя_индекса
Удалить индекс
CREATE INDEX Тема
ON КнижныйФонд (Тема ASC)
Представления
Представление- это временная таблица в БД, отажающая необходимые в данный момент пользователю данные. Необходимы представления для того, чтобы:
- пользователь мог видеть только те данные, что необходимы (на какие есть права)
- обеспечетить независимость работы различных приложений с доними и теми же таблицами.
CREATE VIEW ИмяПредставления (столбец…)
AS подзапрос [WITH CHECK OPTIONS]
- Создать представление на основе указанных таблиц.
DROP VIEW ИмяПредставления
Удалить представление.
Пример:
CREATE VIEW Назначение (ФИО, Должность)
AS SELECT ФИО, Должность, КодДолжности
FROM Сотрудник UNION Должность.
Привилегии пользователей при работе с данными
GRANT привелегии ON объект TO пользователь
REVOKE привелегии ON объект TO пользователь
Установить/снять привелегии.
8. Управление параллельным доступом
Параллельный доступ - это ситуация, возникающая когда несколько транзакций обращаются к одним данным одновременно.
Проблема доступа в том, что необходима полная изолированность пользователей.
Изолированность - это создание иллюзии, что каждый пользователь работает с БД самостоятельно.
3 уровня изолированности пользователей:
-
- Отсутствие потерянных изменений
|
Транзакция1 |
Транзакция2 |
|
READ A A=A+1 WRITE A COMMIT |
READ A A=A+1 ROLLBACK |
ROLLBACK из второй транзакции откатит и изменения, сделанный первой транзакцией.
До завершения транзакции1 нельзя менять объект, с которым работает транзакция
-
- Отсутствие чтения “грязных” данных
|
Транзакция1 |
Транзакция2 |
|
READ A A=A+1 WRITE A ROLLBACK |
. . . . . . . . . READ A A=A-1 |
Никакая транзакция не должна читать объект до завершения изменений.
-
- Отсутствие неповторяющихся чтений
|
Транзакция1 |
Транзакция2 |
|
READ A A=A+1 WRITE A |
READ A A=A-1 . . . WRITE A |
Средства управления транзакциями: блокировки и метод временных меток.
Блокировки.
Блокировка- запрет на доступ к ресурсу. Заблокировать можно поле, кортеж, отношение, группу отношений или всю базу данных.
LOCK A - заблокировать ресурс А
UNLOCK A - разблокировать ресурс А
Совместимость блокировок.
|
запись объекта |
Чтение объекта |
запись части объекта |
чтение части объекта |
чтение/запись части объекта |
|
|
запись объекта |
нет |
Нет |
нет |
нет |
Нет |
|
чтение объекта |
нет |
Да |
нет |
да |
Нет |
|
запись части объекта |
нет |
Нет |
да |
да |
Да |
|
чтение части объекта |
нет |
Да |
нет |
да |
Да |
|
чтение/запись части объекта |
нет |
Нет |
нет |
да |
Нет |
Проблемы, вызванные блокировками
1. “Бесконечное ожидание”
|
Транзакция1 |
Транзакция2 |
Транзакция3 |
|
LOCK A . . . . . . UNLOCK A . . . LOCK A |
. . . . . . . . . LOCK A |
. . . . . . . . . LOCK A . . . UNLOCK A |
Если приоритет второй транзакции мал, то она ждать будет долго.
Решения:
- Динамические приоритеты (чем дольше ждет, тем выше приоритет)
- Ранжирование очередей (несколько очередей, в каждой транзакции одного приоритета. очереди обходятся по-порядку, из них по очереди достаются транзакции.
2. Тупики (DeadLock)
|
Транзакция1 |
Транзакция2 |
|
LOCK A . . . LOCK B . . . . . . |
LOCK B . . . LOCK A . . . . . . |
Дойдя до этого места, транзакции войдут в тупик, ожидая друг друга.
Способы обнаружения тупиков:
- Контроль времени ожидания
- Построение графа ожиданий.
При обнаружении подобной структуры выбирается транзакция с наименьшим приоритетом и она снимается.
Способы предупреждения тупиков:
- упорядочить ресурсы БД и захватывать их в заданном порядке.
- захватывать в транзакции сразу все объекты.
Двухфазный протокол:
Все операции LOCK должны предшествовать операциям UNLOCK.
|
Транзакция1 |
Транзакция2 |
|
LOCK A LOCK B ….. LOCK C ….. UNLOCK A ….. |
LOCK C ….. UNLOCK C …… …… LOCK A UNLOCK A |
Метод временных меток.
Транзакция, обращаясь к объекту, ставит флаг, указывающий время обращения к объекту и операцию. Если флаг уже есть, а операции конфликтуют, то более старая транзакция снимается.
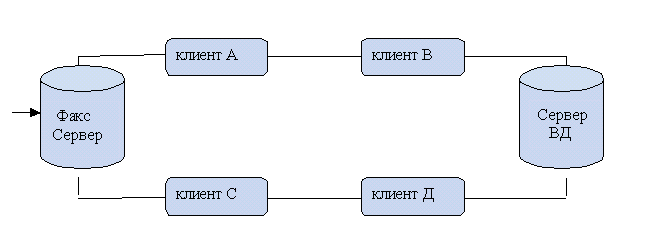
9. Системы “клиент – сервер”
![]()
Открытыми системами называются МСЭ.
Стандартизированные операционные системы:
- Windows NT
- UNJX (удобнее для работы в сети).
Свойства открытых систем:
- Мобильность. Понимают возможность переноса программных средств на другие платформы.
- Интеропертабельность (способность взаимодействовать) – это возможность создания новых систем на основе имеющихся компонентов со стандартным интерфейсом.
Преимущества открытых сетей.
- Пользователи могут изменять компаненты системы, изменятьее не теряя при этом работоспособность.
- Нет зависимости от конкретного производителя.
Все компьютеры делятся на:
- пользовательские – рабочие станции;
- те компьютеры, которые отдают свои ресурсы и обслуживают другие компьютеры в сети – Серверы.
Рабочая станция от Сервера отличается объемом оперативной памяти, объемом жесткого диска, характеристиками процессора, характеристиками монитора.
Рабочая станция
Виды сервера:
- Сервер может быть логическим – это совокупность программных средств расположенных физически на разных компьютерах и воспринимаемых пользователем как единое целое.
- Сервер может быть вычислительный – производящий сложные расчеты.
- Сервер может быть телекоммуникационный.
- Сервер может быть дисковый – коммутатор обладающий большим объемом дисковой памяти.
- Сервер может быть файловый.
- Сервер может быть сервером баз данных.
- Сервер может предоставлять свои услуги, как рабочим станциям, так и другим серверам.
Архитектура систем “клиент – сервер”.
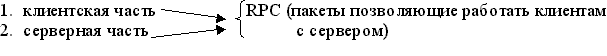
Любая программа, работающая в системе “клиент – сервер” разделяется на две части:
- клиентская часть RPC (пакеты позволяющие работать клиентам
- серверная часть с сервером)
В чем заключается особенность открытой системы “клиент – сервер” - программное обеспечение сервера должно быть универсальным. Поэтому были созданы специальные программные средства:
- RPC (Remote Procedure Call) – удаленный вызов процедур. Задача RPC – принять данные от клиентской части преобразовать их формат доступный серверу и обеспечить последовательность сетевых взаимодействий. Система использующая RPC может быть перенесена в любую открытую среду.
Серверы базы данных.
Предназначены для хранения и доступа баз данных. Обычно вся БД хранится на одном компьютере, а все другие обращаются к нему. Интерфейсы между клиентской частью и серверы сообщаются следующим образом:
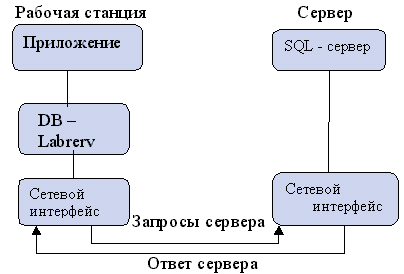
DB – Labrery – программный пакет, который обеспечивает взаимодействие с БД
Запрос посылается на SQL сервер.
DB – Labrery относится к клиентской части.
ODBS – пакет универсального доступа.
SQL сервер – это программный пакет.
RPC – это программные пакте, преобразующие формат данных клиента в формат данных сервера.
Преимущества:
- Клиенты не зависимы от сервера.
- При помощи RPC перераспределяется информация между клиентами сервера.
- Физически неоднородная среда. RPC распознает кодировки и физически неоднородная среда становится логической однородной средой.
Недостаток:
Вся обработка информации производится на сервере. Это приводит к тому, что при ограниченной пропускной способности возникают очереди.
Особенности SQL в системе “клиент – сервер”
- Возможность создания пользовательских типов данных.
Тип данных пользователя:
Name (№ дома)
Owner
Base Daeatyre - базовый тип данных. (Integer)
Length – длина (2 байта)
Null - ограничение на пустые значения (No)
Desalt – значение по умолчанию.
Rule – правило ограничено на переменные.
Создаются правила, которым будут соответствовать наши данные.
CREAT RULE
№ дома > 0 AND № дома < 1000. - Использование триггеров – это программа, которая выполняется при удалении, прибавлении или изменении данных в таблице.
Триггеры:
- обновления
- удаления
- добавления
Существуют специальные триггерные таблицы:
Inserted
Deleted
Пример:
| Код сотрудника |
Отдел |
Оклад |
Создадим триггер CREAT TRIGGER оклад.
ON сотрудник.
FOR INSERT, UPDATE, DELETE.
AS UPDATE, сотрудник SET средний оклад= SELECT AVG(оклад) FROM cотрудник GROUP BY отдел.
Если сотрудники добавляются с помощью триггера, то им автоматически начисляется оклад.
10. Распределение базы данных
Все таблицы данных распределяются по сети (узлом), где осуществляется их применение. Каналы между узлами – соединения. Все данные в сети делятся на 2 подвида:
- Локальные – используются только в своем узле.
- Глобальные данные – могут использоваться в любом узле.
Преимущество:
- уменьшенное время на доступ наиболее часто используемых программ.
- рассширяются объемы данных, в которых можно иметь доступ.
- надежность хранения увеличивается
Недостатки:
- производительность падает.
- запросы обрабатывать сложнее.
- управление транзакциями при параллельном доступе усложняется.
- возникает проблема обновления при терражировании данных.
Все распределенные базы данных делятся на два типа:
- Однородные – те базы данных. У которых все локальные данные управляются СУБД одного типа.
- Неоднородные – это такие БД, у которых все локальные данные могут управляться СУБД разного типа и могут иметь разные модели данных.
Все узлы в распределенных БД являются автономными, т.е. полная независимость узла от других узлов.
Задачи РСУБД:
- Выполнение запросов.
- Обработка транзакций.
- Обнаружение распределенных тупиков.
- Восстановление РБД.
Каждая таблица имеет: имя, состоящее из:
- Полное имя: задается командой CREAT TABL
- Системное имя (создается при создании автоматически)
- имя таблицы
- № узла создания
- № узла в котором таблица была размещена после создания (родовой узел)
- имя создателя.
Существует оператор, который позволяет отправить таблицу на любой из узлов сети: MYGRATE TABLE эту таблицу можно найти по локальному каталогу в котором эта таблица была размещена после создания. Когда запрос обращается к таблице, считывается имя и затем считывается адрес, где находится.
Порядок выполнения запросов в БД
Узел, из которого исходит запрос, называется главным. Узлы, из которых исходит запрос, называется дополнительными.
- Происходит разбор команды SQL в главном узле. С заменой полных имен таблиц на системные имена
- В главном узле определяется порядок взаимодействия узлов.
- Запрос (весь) разбивается на составные части, в каждом из которых будет воспроизводиться в своем узле. Эти части (подзапросы) рассылаются по соответствующим узлам.
- На дополнительных узлах происходит проверка прав доступа пользователя, оптимизация запроса в соответствии с имеющимися индексами, происходит комплектация запросов, т.е. генерация машинных кодов.
Архитектура РСУБД
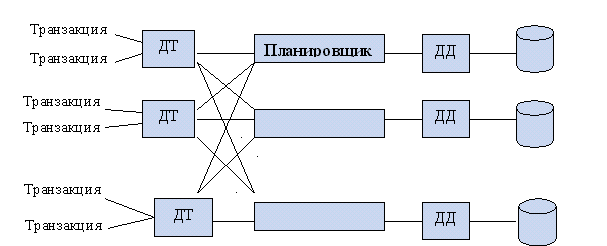
Транзакция в РБД может состоять из нескольких мастей – агентов.
Транзакции состоящая из нескольких агентов называются глобальными.
Транзакция, с которой начинается обработка, называется инициирующая.
ДТ – диспетчер транзакции. Фиксирует начало и конец транзакции, передает информацию о четности планировщику.
Планировщик – составляет расписание работы транзакции, устанавливает блокировку по чтению БД.
ДД – диспетчер данных. Выполняет команду чтения и записи над данными, результаты этих операций передаю планировщику. Планировщик передает ДТ, а ДТ передает обратно транзакции.
Протокол двухфазной фиксации
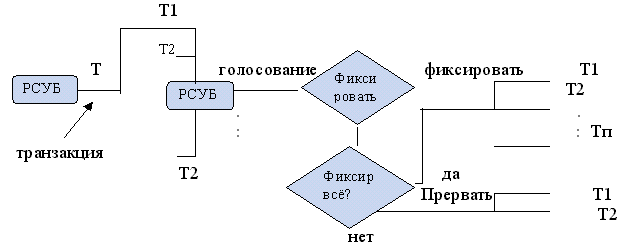
Главная транзакция посылает команду подтранзакции, фиксировать или прервать. Если голосование единогласно, то принимается решение фиксировать и эта команда отправляется подтранзакциям. Если же хотя бы одна подтранзакция обработала с ошибкой, то главная подтранзакция посылает подтранзакциям команду отказ и все данные уничтожаются.
Фрагментация – хранение фрагментов таблицы в разных узлах сети.
Пример:
| Категория билетов | Станция | цена | |
| Красноярск | |||
| Новосибирск | |||
| Москва | |||
| Владивосток |
Горизонтальная фрагментация таблицы
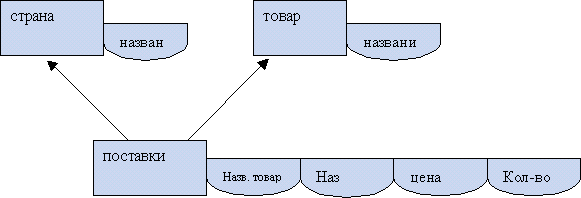
Разбиение таблицы на фрагменты по строкам выполняется с помощью команды R:=(R(SELECT * FROMR WHERE Город = “Новосибирск”))
Вертикальная фрагментация – разделение таблицы по вертикали (убираются те данные, которые не нужны).
Стратегия распределения нефрагментированных файлов.
Чтобы оптимально распределить файлы по сети, нужно. минимизировать количество удаленных обращений и максимизировать число локальных обращений.
Алгоритм размещения файла по сети
Cij – объем свободного дискового пространства узла j;
Fi – размер файла i;
Тк – транзакция
N - число узлов
-
- Определяется значение каждой транзакции к каждому файлу Fik.
|
Ф Т |
1 |
2 |
3 |
|
1 |
10 |
0 |
0 |
|
2 |
0 |
10 |
30 |
|
3 |
5 |
10 |
0 |
-
- Среднее число запусков транзакций на узлах сети. Nij
|
У Т |
1 |
2 |
|
1 |
2 |
1 |
|
2 |
0 |
2 |
|
3 |
2 |
0 |
-
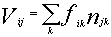 Вычисляется весовой коэффициент Vij, определяется на какое место нужно отправить файл.
Вычисляется весовой коэффициент Vij, определяется на какое место нужно отправить файл.
|
Ф У |
1 |
2 |
3 |
|
1 |
30 |
30 |
0 |
|
2 |
20 |
20 |
60 |
- максимум (Vij) для указанного узла j.
- Осуществляется проверка:
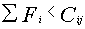
Как только файл нашел свой узел, все соответствующие столбцы удаляются из таблицы. Как только свободное дисковое пространство на узле заполнилось, то соответствующие ему строка и столбцы удаляются из таблицы. Таким образом распределяется от файла к узлу.
11. Физическая организация БД
Это структура хранения баз данных на физическом носителе.
Система физического доступа к базам данных.
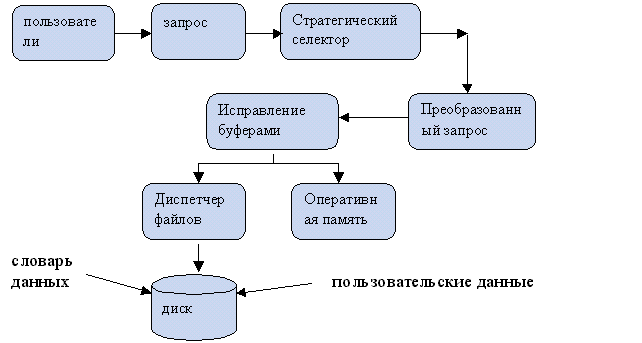
Стратегический сектор – это программа, которую преобразует запрос в эффективную для исполнения форму.
Программа управления буферами – контролирует обмен информации между оперативной памятью и диском.
Диспетчер файлов – программа, управляющая размещением файлов на диске.
Словарь данных – это часть СУБД, определяющая структуру пользовательских данных и возможность их использования.
Пользовательские данные – содержимое таблиц.
Устройство дисковода.
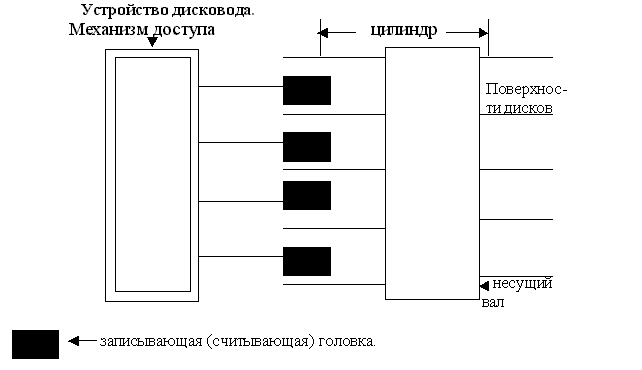
Цилиндр – совокупность дорожек с одинаковым порядковым номером на разных поверхностях дисков.
Дорожка разбита на блоки.
Блок – это физическая запись – это минимальная единица данных на диске.
Информация с диска считывается полностью блоками, каждый блок имеет свой Nnk.
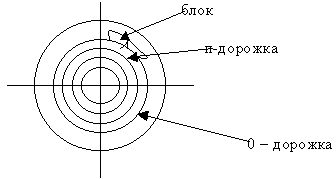
Адрес записи.
![]()
Время считывания
Факторы, влияющие на быстродействие дисковода.
- Время установки головки примерно 12 – 15 мс (А). Это время, которое требуется переместить головки.
- Время активизации головки (то есть по №головки нужная головка переводится в активное состояние).
- Время поворота диска зависит от скорости вращения диска. Средняя задержка вращения =R/2, где R – время полного поворота диска.
- Скорость обмена данными между ОЗУ и диском ( примерно несколько килобайт в секунду).
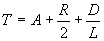 Время доступа к данным:
Время доступа к данным:
Где D – скорость обмена данными между ОЗУ;
L - длина блока данных, байт.
Форментация – уплотнение данных.
Форматы хранения данных на диске.
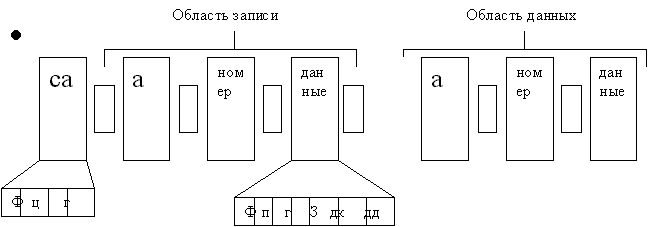
СА – собственный адрес![]() - индексная метка – обозначает начало и конец каждой дорожки
- индексная метка – обозначает начало и конец каждой дорожки
Ф – флаг
Ц – номер цилиндра
Г – номер головки
ЦП – проверочный элемент циклического кода ( чтобы избежать возникновение сбоев
А - адресный маркер
з – зазор (пустое место), чтобы процессор успевал обрабатывать данную информацию
З – номер записи
ДК – длина ключа
ДД – длина данных
Физические записи на диске фиксированной длины или переменной; блокированной и деблокированной.
- Блокированная запись – это записи, в которых один блок информации соответствует одной логической записи
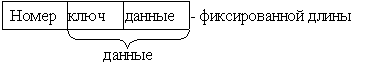
- Деблокированная запись – это запись, в которой один блок информационный соответствует двум логическим записям
Организация файлов и способы адресации.
Организация файлов:
- Последовательная. Все записи упорядочиваются по значению первичного ключа. Пользователь, обращается к записи, и система читает весь файл последовательно, чтобы добраться до записи.
- Индексно-последовательная. Позволяет обращаться как последовательно, так и напрямую. С помощью индексных таблиц.Индексная таблица:
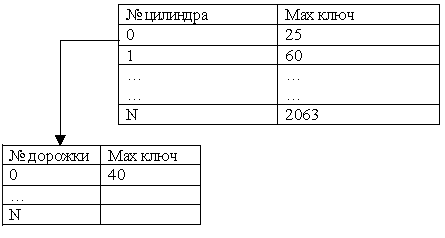
Система считывает первичный ключ и сравнивает с максимальным ключом, определяя сначала № цилиндра, затем № дорожки. Недостатком является то, что к каждой записи приходится обращаться дважды (обращение к диску)
- Прямая. Существует определённый алгоритм (это алгоритм хэмирования – вычисление физического адреса записи на использование значения ключа)
№стр = 2000 строк; число записей в блоке: №бл = 500 байт; Vстр = 100 байт; Vотв пам = 30 бл; система отводит на 20% больше.
Отношение реально отводимой памяти к отводимой получило название коэффициент нагрузки.
R – относительный адрес записи (относительно начала файла)
![]()
В итоге адрес = НА + R , где НА – начальный адрес.
В случае записи:
![]()
I ищем до тех пор, пока не найдем свое место. Этот метод называется методом квадратных частных.
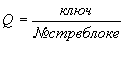
12. Администрирование базы данных
Задача администрирования:
- обеспечение выполнения требований конечных пользователей; отслеживает частоту обращений пользователей к базам данных; отслеживает время отклика на их приложения; и администратор обучает пользователей
- обеспечение защиты целостности базы данных: контроль доступа к БД и контроль обновления данных.
- Определение процедуры резервного копирования и восстановления; оповещает пользователей о сбое; для предупреждения сбойных систем разрабатывает тесты и анализирует их результаты.
Жизненный цикл программного обеспечения.
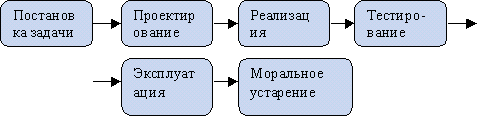
Проверка:
- БД выполнена без нарушения целостности. Внешние ключи не равны нулю, повтор первичных ключей не должен быть.
- Приложение правильно взаимодействует с БД.
- Рабочие характеристики системы удовлетворяют потребностям пользователя.
- Когда и в каких случаях БД функционируют не так как ожидается.
- Поддержка функционирования БД:
- управление ресурсами
- прогноз будущих потребностей в оборудовании
- поддержка изменения информационной системы
- резервное копирование
Существуют специальные средства мониторинга, отслеживающие следующие средства:
- число операций чтения записи, выполняемое за определенный промежуток времени
- число транзакций за определенный промежуток времени
- троссировка – это пошаговая проверка некоторых операций. Используется системный журнал.
13. Выбор СУБД
Функции СУБД:
- Словарь данных (системный каталог). Должен обеспечивать:
- изменение физической записи без влияния на работающие с ними приложения;
- хранение параметров;
- централизованное определение;
- удобные для пользователя язык описания данных и язык манипулирования
- способы проверки словаря
- средства создания отчётов
- Защита и целостность данных:
- средства ограничения доступа к программам данных
- контроль параллельной обработки данных
- управление доступом представления
- средства шифровки данных
- средства копирования и восстановления данных.
- Возможности создания запросов и отчетов: запросы должны быть с маленьким временем отклика и внутри запроса возможность выполнения операций.
- Поддержка создания специальных программ
Свойства СУБД:
- Обязательные
- Важные (не обязательные)
- Не обязательные, имеющие второстепенное значение
- Излишние
- Нежелательные, мешающие решению задач.
Способ сбора данных СУБД
- Опрос других пользователей
- Тестирование имеющихся БД на реальных приложениях
- Вопросы, задаваемые поставщикам БД
- Аттестация.
14. Перспективные направления развития информационных систем
- Линейное программирование (Фортран)
- Модульное (Паскаль)
- Объектно-ориентированное (СИ++)
Появились объектно-ориентированные БД (ООБД). Основной особенностью является то, что концептуальные модели реализуются напрямую. Любая сущность реализуется в виде объекта, информация о котором хранится в БД.
Поведение объекта – это набор значений его атрибутов.
Методы – это набор программных средств, оперирующих над состоянием объекта.
Класс объектов – это множество объектов с одним и тем же набором атрибутов и методов.
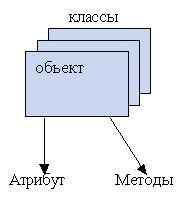
Объекты одного класса могут служить значениями для атрибутов другого класса. Классы объектов, которые служат значениями атрибутов другого класса называются доменами.
У классов есть способность наследования – это порождение нового класса на основе уже существующего класса, и новый класс наследует все методы и атрибуты существующего класса.
Тот класс, который наследует свойство другого класса называется подклассом, а родительский называется суперклассом.
Возникает множество наследований, в том случае когда имеется несколько подклассов.
Основные свойства ООБД
- Возможность обрабатывания сложных объектов
- Возможность фиксировать операции над данными объекта (методы)
- Возможность регулировать объекты как члены класса
- Возможность представлять иерархию класса и наследование.
Любой класс может иметь любое количество подклассов, следовательно любой подкласс может иметь любое количество суперклассов. Запросы в ООБД адресуются в классы.
Система управления БД кроме стандартных средств СУБД обладает средствами ввода и хранения логических правил для превращения данных в информацию.
знания = данные + правила
Составляющие базы знаний.
- База данных, содержащая факты
- БД, содержащая правила
- Программное обеспечение, управляющее БЗ (СУБЗ), позволяющие выводить правила, управляющие данными.
Классификация знаний.
- Структурные – знания о зависимости между данными и ограничения на них.
- Общие процедурные знания – знания которые можно описать только при помощи процедуры.
- Прикладные знания – знания, которые имеют значения в конкретной предметной области.
- Знания предприятий – это внутренняя информация на предприятии.