4.1. Режимы работы процессоров IA-32
4.2. Структура микропроцессоров IA-32 (i386/486)
4.3. Регистры процессора IA-32
4.4. Формат команды микропроцессора IA-32 (i386/486)
4.5. Адресация операндов при обработке инструкций
4.6. Особенности архитектуры современных x86 процессоров
4.6.1. Архитектура процессоров Intel Pentium (P5/P6)
4.1. Режимы работы процессоров IA-32
4.1.1. Реальный режим
После инициализации (системного сброса) МП находится в реальном режиме (Real Mode). В реальном режиме МП работает в режиме эмуляции 8086 с возможностью использования 32-битных расширений. Механизм адресации, размеры памяти и обработка прерываний (с их последовательными ограничениями) МП 8086 полностью совпадают с аналогичными функциями других МП IA-32 в реальном режиме.
Имеется две фиксированные области в памяти, которые резервируются в режиме реальной адресации:
- область инициализации системы,
- область таблицы прерываний.
Ячейки от 00000h до 003FFH резервируются для векторов прерываний. Каждое из 256 возможных прерываний имеет зарезервированный 4-байтовый адрес перехода. Ячейки от FFFFFFF0H до FFFFFFFFH резервируются для инициализации системы.
4.1.2. Режим системного управления
В новых поколениях МП Intel появился еще один режим работы – режим системного управления. Впервые он был реализован в МП 80386SL и i486SL. Начиная с расширенных моделей Intel-486, этот режим стал обязательным элементом архитектуры IA-32. С его помощью прозрачно даже для операционной системы на уровне BIOS реализуются функции энергосбережения.
Режим системного управления (SMM – System Management Mode) предназначен для выполнения некоторых действий с возможностью их полной изоляции от прикладного программного обеспечения и даже от операционной системы.
Микропроцессор переходит в этот режим только аппаратно. Никакой программный способ не предусмотрен для перехода в этот режим. МП возвращается из режима системного управления в тот режим, при работе в котором был получен сигнал о переходе.
Следует отметить, что в режиме SMM не предусмотрена работа с прерываниями и особыми случаями: прерывания по IRQ и SMI# замаскированы, пошаговые ловушки и точки останова отключены, обработка прерывания по НМI откладывается до выхода из режима SMM.
Эти особенности режима системного управления позволяют использовать его для реализации системы управления энергосбережением компьютера или функций безопасности и контроля доступа.
4.1.3. Защищенный режим
Основным режимом работы МП является защищенный режим.
Ключевые особенности защищенного режима:
- виртуальное адресное пространство,
- защита,
- многозадачность.
Микропроцессор может быть переведен в защищенный режим установкой бита 0 (Protect Enable) в регистре CR0. Вернуться в режим реального адреса МП может по сигналу RESET или сбросом бита PE (в Intel-286 недоступно).
В защищенном режиме программа оперирует с адресами, которые могут относиться к физически отсутствующим ячейкам памяти, поэтому такое адресное пространство называется виртуальным. Размер виртуального адресного пространства программы может превышать емкость физической памяти и достигать 64 Тбайт.
Преобразование логического адреса в физический происходит в два этапа:
- сначала блок управления сегментами выполняет трансляцию адреса в соответствии с сегментированной моделью памяти, получая 32-битный линейный адрес,
- затем блок страничного преобразования выполняет разбиение на страницы, преобразуя 32-битный линейный адрес в 32-битный или 36-битный (P6) физический.
В рамках сегментированной модели адресации для программы память представляется группой независимых адресных блоков, называемых сегментами. Для адресации байта памяти программа должна использовать логический адрес, состоящий из селектора сегмента и смещения.
Селектор сегмента выбирает определенный сегмент, а смещение указывает на конкретный байт в адресном пространстве выбранного сегмента.
С каждым сегментом связана особая структура, хранящая информацию о нем – дескриптор. Дескриптор сегмента содержит базовый адрес описываемого сегмента, предел сегмента и права доступа к сегменту.
Дескрипторные таблицы – это массивы памяти переменной длины, содержащие 8-байтные элементы – дескрипторы.
Существуют две обязательных дескрипторных таблицы:
- глобальная дескрипторная таблица (Global Descriptor Table – GDT);
- дескрипторная таблица прерывания (Interrupt Descriptor Table – IDT).
А также множество (вплоть до 8191) необязательных локальных дескрипторных таблиц (Local Descriptor Table – LDT), из которых в каждый момент времени процессору доступна только одна. Расположение дескрипторных таблиц определяется регистрами процессора GDTR, IDTR, LDTR.
Таблица GDT содержит дескрипторы, доступные всем задачам в системе. GDT может содержать дескрипторы любых типов: и дескрипторы сегментов, и системные дескрипторы (кроме шлюзов прерываний и ловушек). Первый элемент GDT (с нулевым индексом) не используется. Ему соответствует нуль-селектор, обозначающий "пустой" указатель.
Таблица LDT обеспечивают способ изоляции сегментов программы и данных исполняемой задачи от других задач. LDT связана с конкретной задачей и может содержать только дескрипторы сегментов, шлюзы вызовов и шлюзы задач.
Использование двух дескрипторных таблиц позволяет, с одной стороны, изолировать и защищать сегменты исполняемой задачи, а с другой – позволяет разделять глобальные данные и код между различными задачами.
Для вычисления линейного адреса МП выполняет следующие действия (рис. 4.1):
1. Микропроцессор использует селектор сегмента для нахождения дескриптора сегмента. Селектор содержит индекс дескриптора в дескрипторной таблице (Index), бит TI, определяющий, к какой дескрипторной таблице производится обращение (LDT или GDT), а также запрашиваемые права доступа к сегменту (RPL). Если селектор хранится в сегментном регистре, то обращение к дескрипторным таблицам происходит только при загрузке селектора в сегментный регистр, т. к. каждый сегментный регистр хранит соответствующий дескриптор в программно-недоступном ("теневом") регистре-кэше.
2. Микропроцессор анализирует дескриптор сегмента, контролируя права доступа (сегмент доступен с текущего уровня привилегий) и предел сегмента (смещение не превышает предел);
3. Микропроцессор добавляет смещение к базовому адресу сегмента и получает линейный адрес.
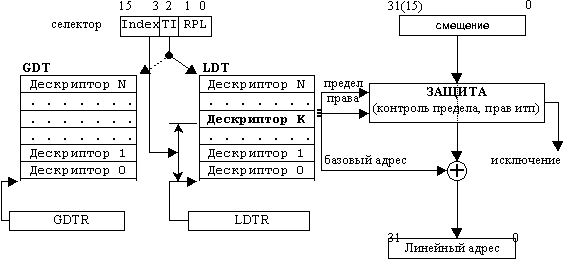 Рисунок 4.1 – Схема преобразования логического адреса в линейный
Рисунок 4.1 – Схема преобразования логического адреса в линейный
Если страничная трансляция отключена, то сформированный линейный адрес считается физическим и выставляется на шину процессора для выполнения цикла чтения или записи памяти.
Механизм сегментации обеспечивает превосходную защиту, но он не очень удобен для реализации виртуальной памяти (подкачки). В дескрипторе сегмента есть бит присутствия, по нему процессор определяет, находится ли данный сегмент в физической памяти или на внешнем запоминающем устройстве (на винчестере). Неудобство заключается в том, что различные сегменты могут иметь различную длину. Этого можно избежать, если механизм подкачки реализовывать на основе страничного преобразования.
Особенностью страничного преобразования является то, что процессор в этом случае оперирует с блоками физической памяти равной длины (4 Кбайта) – страницами. Страницы не имеют непосредственного отношения к логической структуре программы.
В страничном преобразовании участвуют два типа структур:
- каталоги таблиц (Page Directory) – элементы каталога таблиц (Page Directory Entry – PDE) адресуют таблицы страниц.
- таблицы страниц (Page Table). Элементы таблицы страниц (Page Table Entry – PTE) адресуют страницы.
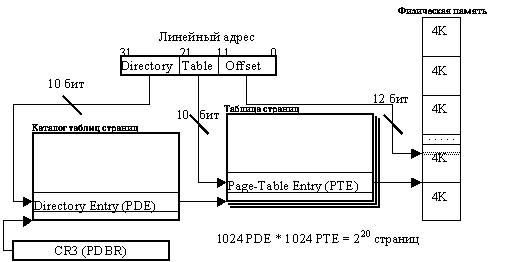 Рисунок 4.2 – Стандартная 2-уровневая схема страничной трансляции
Рисунок 4.2 – Стандартная 2-уровневая схема страничной трансляции
В процессе страничной трансляции адресов полученный линейный адрес разбивается на три части. Старшие десять бит (Directory) линейного адреса являются индексом элемента из каталога таблиц. По этому элементу определяется физический адрес таблицы страниц. Биты 21-12 (Table) линейного адреса выбирают элемент из этой таблицы страниц. Выбранный элемент определяет физический адрес страницы. Младшие 12 бит (Offset) линейного адреса определяют смещение от начала страницы.
В МП Pentium фирма Intel реализовала новую возможность – расширение размера страниц (Page Size Extension – PSE). PSE позволяет использовать страницы размером 4 Мбайт и одноуровневый механизм страничной трансляции.
В подсемействе P6 шина адреса была расширена до 36 бит. Соответственно, процессоры Pentium Pro, Pentium II, Pentium III и более поздние способны адресовать до 64 Гбайт физической памяти. Эта возможность называется расширением физического адреса (Physical Address Extension – PAE) и доступна только при использовании страничной трансляции.
Встроенные средства переключения задач обеспечивают многозадачность в защищенном режиме.
Задача – это "единица измерения" заданий для процессора, которую процессор может выполнять, приостанавливать и осуществлять над ней диспетчеризацию.
В защищенном режиме архитектура IA-32 предоставляет механизм для сохранения состояния задачи и переключения с одной задачи на другую. Все команды процессора выполняются в контексте той или иной задачи.
В качестве задачи может исполняться прикладная программа, сервис операционной системы, ядро операционной системы, обработчик прерывания или исключения и т.п. В защищенном режиме архитектура IA-32 предоставляет механизм для сохранения состояния задачи и переключения с одной задачи на другую. Все команды процессора выполняются в контексте той или иной задачи. Даже самые простые системы должны определить как минимум одну задачу. Более сложные системы могут использовать средства управления задачами для поддержки многозадачных приложений.
Среда задачи состоит из содержимого регистров МП и всего кода с данными в пространстве памяти. МП способен быстро переключаться из одной среды выполнения в другую, имитируя параллельную работу нескольких задач. Для некоторых задач может эмулироваться управление памятью, как у МП 8086. Такое состояние задачи называется режимом виртуального 8086 (Virtual 8086 Mode). О пребывании задачи в данном состоянии сигнализирует бит VM в регистре флагов. При этом задачи виртуального МП 8086 изолированы и защищены, как от друг друга, так и от обычных задач защищенного режима.
Задачу составляют два компонента:
- адресное пространство задачи
- сегмент состояния задачи (Task State Segment – TSS).
В адресное пространство задачи входят доступные ей сегменты кода, данных и стека. Если используется механизм привилегий, то каждой задаче должны быть предоставлены сегменты стека для всех используемых уровней привилегий.
Каждая задача идентифицируется селектором соответствующего ей TSS. В защищенном режиме процессор обеспечивает определенные механизмы защиты на основе сегментации и на основе страничного преобразования. Механизмы защиты позволяют ограничивать доступ к определенным сегментам или страницам при помощи уровней привилегий (4 для сегментов и 2 для страниц).
Например, критические код и данные операционной системы могут быть расположены на более привилегированном уровне, чем прикладные программы. Это позволит ограничить и контролировать доступ прикладных программ к функциям и данным операционной системы.
Контроль пределов и типов сегментов обеспечивает целостность сегментов кода и данных. Программа не имеет права обратиться к виртуальной памяти, выходящей за предел того или иного сегмента. Программа не имеет права обратиться к сегменту данных как к коду, и наоборот.
Архитектура защиты МП обеспечивает 4 иерархических уровня привилегий, что позволяет ограничить задаче доступ к отдельным сегментам в зависимости от ее текущих привилегий.
Четыре уровня привилегий можно интерпретировать в виде колец защиты (рис. 4.3):
- центр (уровень 0) предназначен для сегментов, содержащих наиболее критичные программы (обычно ядро операционной системы).
- внешние кольца предназначены для сегментов с менее критичными программами или данными.
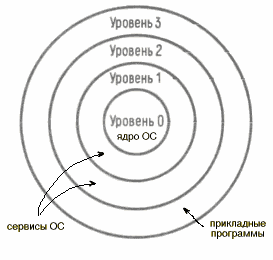 Рисунок 4.3 – Интерпретация уровней привилегий в виде колец защиты
Рисунок 4.3 – Интерпретация уровней привилегий в виде колец защиты
4.2. Структура микропроцессоров IA-32 (i386/486)
Базовую структуру микропроцессоров IA-32 можно рассмотреть на примере Intel-386 (рис. 4.4).
В структуре Intel-386 можно выделить шесть основных блоков, работающих параллельно:
- блок интерфейса с магистралью;
- блок предварительной выборки команд;
- блок декодирования команд;
- исполнительный блок;
- блок управления сегментами;
- блок страничной трансляции.
Блок интерфейса с магистралью содержит
- драйвер адреса;
- схемы управления размером адреса и конвейером;
- мультиплексор, приемопередатчики
- и др.
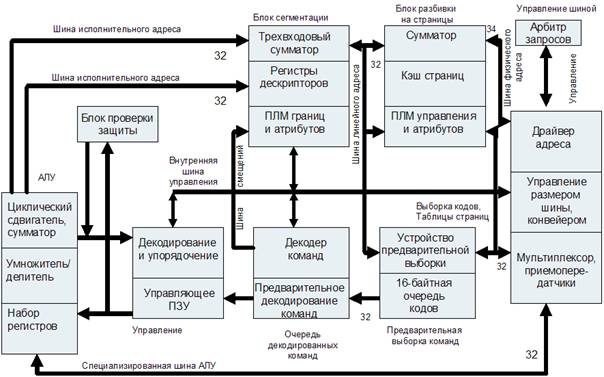 Рисунок 4.4 – Структура микропроцессора Intel-386
Рисунок 4.4 – Структура микропроцессора Intel-386
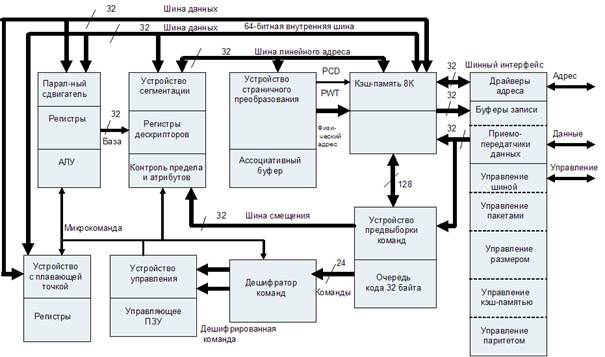 Рисунок 4.5 – Структура микропроцессора Intel-486
Рисунок 4.5 – Структура микропроцессора Intel-486
Блок интерфейса с магистралью обеспечивает интерфейс между МП и его окружением. Он принимает внутренние запросы для выборки команд от блока предварительной выборки команд и для обмена данными с исполнительным блоком и устанавливает приоритет этих запросов. Одновременно он генерирует или обрабатывает сигналы для исполнения текущего цикла магистрали. К ним относятся: сигналы адреса, данных и управления для обращения к внешней памяти и устройствам ввода-вывода.
При помощи схемы арбитра запросов блок управляет интерфейсом с внешними указателями используемой в текущий момент магистрали и сопроцессорами. В МП Intel-486 (рис. 4.5) этот блок был дополнен схемой управления паритетом (выравниванием) и схемой управления пакетами. На основе последней был реализован специальный режим работы магистрали – режим пакетирования. В этом режиме при передаче 4 слов на магистрали выставляется только адрес первого, что позволяет существенно сократить время обмена данными с оперативной памятью или внешним кэшем.
Для того чтобы заранее получать команды или данные перед их фактическим использованием, существует функция опережающего просмотра программы, которую в Intel-386 выполняет блок предвыборки команд. Когда блок интерфейса с магистралью не занимает цикла магистрали для исполнения команды, блок предвыборки команд использует его для последовательной выборки из памяти байтов команд. Эти команды хранятся в 16-байтовой очереди команд в ожидании обработки блоком декодирования команд.
Блок декодирования команд преобразует байты команды из этой очереди в микрокод. Декодированные команды в ожидании обработки исполнительным блоком хранятся в очереди команд, работающей по принципу FIFO (First In First Out).
В Intel-386 эта очередь имеет размер 3 команды, а в Intel-486 – уже 5 команд, что позволяет этому МП при некоторых условиях выполнять по одной команде за цикл.
Исполнительный блок выполняет команды из очереди команд и взаимодействует со всеми другими блоками, нужными для завершения выполнения команды. Для ускорения выполнения команд с обращением к памяти исполнительный блок приступает к их исполнению до завершения выполнения предыдущей команды. Так как команды с обращением к памяти встречаются очень часто, то благодаря такому перекрытию по времени производительность повышается.
В МП Pentium исполнительный блок реализован в виде двух параллельных конвейеров (u и v), что позволяет ему выполнять до двух команд за такт. Это архитектурное решение названо суперскалярностью. Особенностью конвейеров P6 является динамическое выполнение (предсказание ветвлений, спекулятивное выполнение, изменение последовательности команд).
Суперскалярность получило дальнейшее развитие в МП подсемейства P6 (Pentium Pro, Pentium II, Pentium III), где исполнительный блок представлен уже тремя конвейерами.
В исполнительный блок встроены регистры общего назначения (РОН), которые используются для таких операций, как двоичное сложение или вычисление и модификация адресов. Исполнительный блок содержит восемь 32-разрядных РОНов, применяемых как для вычисления адресов, так и для операций с данными. Этот блок содержит также 64-разрядный регистр, необходимый для ускорения операций сдвига, циклического сдвига, умножения и деления.
Интеграция в МП i486DX блока вычислений с плавающей точкой (FPU - Floating Point Unit) резко повысила производительность вещественной арифметики.
В МП Pentium MMX был добавлен набор команд, позволяющий использовать регистры блока FPU для параллельной обработки пакета целочисленных данных: SIMD – "одна инструкция – несколько операндов". В МП Pentium III эта технология была расширена, за счет добавлением блока XMM, позволяющего параллельно обрабатывать пакет вещественных данных: SSE – потоковое расширение SIMD.
Блоки сегментации и страничной трансляции образуют устройство управления памятью.
Блок сегментации преобразует логические адреса в линейные по запросу исполнительного блока. Для ускорения этого преобразования текущие дескрипторы сегментов помещаются во встроенную кэш-память.
Во время трансляции адресов блок управления сегментами проверяет, нет ли нарушения сегментации. Эти проверки выполняются отдельно от проверок нарушений статической сегментации, осуществляемых механизмом проверки защиты. Блок сегментации обеспечивает четыре уровня защиты (от 0 до 3) с целью изоляции и защиты друг от друга прикладных программ и операционной системы. Этот компонент также позволяет легко создавать перемещаемые программы и данные и обеспечивает их совместное использование. Полученный линейный адрес направляется в блок страничной трансляции.
Если механизм страничного преобразования включен, то для получения физических адресов по линейным используется блок страничной трансляции. Если же этот механизм выключен, то это означает, что, физический адрес совпадает с линейным, и трансляция не нужна.
Для ускорения трансляции адресов в кэш-память дескрипторов страниц помещаются каталог недавно использованных страниц, а также информация о входах в таблицу страниц в буфере трансляции адресов. Затем блок страничной трансляции пересылает физические адреса в блок интерфейса с магистралью для выполнения цикла обращения к памяти или устройствам ввода-вывода. МП Intel-386 использует 32-разрядные регистры и шины данных для поддержки адресов и типов данных такой же разрядности.
Блок страничной трансляции позволяет прозрачно управлять пространством физических адресов независимо от управления сегментами. Каждый сегмент отображается в пространство линейных адресов, которое, в свою очередь, отображается в одну или несколько страниц объемом 4 Кб.
Для реализации эффективной системы виртуальной памяти Intel-386 полностью поддерживает способность рестарта (повторного запуска) в случае отказа во всех страницах и сегментах.
В МП 80486 был интегрирован кэш первого уровня размером 8 Кб. В МП Pentium размер кэша первого уровня удвоен: 8 Кб – кэш команд и 8 Кб – кэш данных. В МП Pentium Pro, кроме того, на кристалле интегрирован кэш второго уровня.
4.3. Регистры процессора IA-32
Процессоры IA -32 включают в себя следующие регистры:
- восемь регистров общего назначения;
- шесть регистров сегментов;
- указатель команд;
- регистр системных флагов;
- регистры системных адресов;
- четыре регистра управления;
- шесть регистров отладки.
Восемь регистров общего назначения имеют длину в 32 бит и содержат адреса или данные. Они поддерживают операнды-данные длиной 1, 8, 16, 32 и (при использовании двух регистров) 64 бит; битовые поля от 1 до 32 бит; операнды-адреса длиной 16 и 32 бит.
Эти регистры называются:
|
‑ EAX; |
‑ ECX; | ‑ ESI; | ‑ EBP; |
| ‑ EBX; | ‑ EDX; | ‑ EDI; | ‑ ESP. |
Доступ к младшим 16 бит этих регистров выполняется независимо при использовании соответствующих имен 16-битных регистров:
|
‑ AX; |
‑ CX; | ‑ SI; | ‑ BP; |
| ‑ BX; | ‑ DX; | ‑ DI; | ‑ SP. |
Также могут использоваться индивидуально младший (биты 0-7) и старший (биты 8-15) байты регистров AX, BX, CX, DX. Им соответствуют обозначения AH, DH, CH, BH и AL, DL, CL, BL.
Хотя регистр ESP тоже относится к регистрам общего назначения, он содержит указатель на вершину стека и не используется для других целей.
Следует отметить, что регистры могут быть неравнозначны и при использовании определенных инструкций могут иметь специальное значение:
- EAX – аккумулятор, операнд-источник или приемник результата (некоторые инструкции могут быть короче на один байт при использовании EAX);
- EBX – указатель на данные в сегменте DS;
- ECX – счетчик для цепочечных (например, MOVS) и циклических (с префиксом REP) инструкций;
- EDX – адрес порта ввода-вывода для инструкций IN/INS, OUT/OUTS;
- ESI – указатель на операнд-источник в сегменте DS для цепочечных инструкций;
- EDI – указатель на операнд-приемник в сегменте ES для цепочечных инструкций;
- EBP – указатель на данные в сегменте SS.
МП включает шесть непосредственно доступных 16-битных регистров сегментов. С каждым сегментным регистром ассоциирован программно-недоступный кэш дескриптора соответствующего сегмента, содержащий базовый адрес сегмента в линейном адресном пространстве, предел сегмента и атрибуты сегмента. Этот кэш заполняется при загрузке значения в сегментный регистр. В реальном режиме предел сегмента всегда 0FFFFh, атрибуты игнорируются, а базовый адрес вычисляется сдвигом значения селектора на 4 бита влево. В защищенном режиме кэш заполняется соответствующими значениями из дескрипторной таблицы.
Не все сегментные регистры равнозначны. Регистр CS хранит селектор сегмента кода. МП извлекает очередную инструкцию для исполнения, формируя логический адрес из селектора в CS и смещения в регистре EIP. Значение этого регистра нельзя изменить непосредственно, оно меняется в командах межсегментного перехода (FAR JMP), межсегментного вызова (FAR CALL), при вызове обработчика прерывания (INT) и при возврате из далекой процедуры (RETF) или обработчика прерывания (IRET).
Регистр SS хранит селектор сегмента стека. Стек используется для передачи параметров подпрограммам и для сохранения адреса возврата при вызове подпрограммы или обработчика прерывания. Вершиной стека считается байт, логический адрес которого образуется из селектора в регистре SS и смещения в регистре ESP. Программа может непосредственно изменить значение SS, что дает ей возможность переключаться между несколькими стеками. Причем на время выполнения команды MOV SS,xxxx и одной команды, следующей за ней (обычно это MOV ESP,xxxx), запрещаются маскируемые и блокируются немаскируемые прерывания.
Регистры DS, ES, FS и GS хранят селекторы сегментов данных. Если инструкция обращается к памяти, но содержит только смещение, то считается, что она обращается к данным в сегменте DS. Сегмент ES может использоваться без явного указания в цепочечных командах. Сегменты FS и GS используются при обращении к памяти только при явном использовании в инструкции префиксов этих сегментов.
Указатель команд (EIP) является 32-разрядным регистром. Он содержит смещение следующей команды, подлежащей выполнению. Относительный адрес отсчитывается от базового адреса сегмента исполняемой задачи. Указатель команд непосредственно недоступен программисту, но он изменяется явно командами управления потоком, прерываниями и исключениями (JMP, CALL, RET, IRET, команды условного перехода). Получить текущее значение EIP можно, если выполнить команду CALL, а затем прочитать слово на вершине стека.
Регистр системных флагов EFLAGS содержит группу флагов состояния, управления и системных флагов. Младшие 16 бит регистра представляют собой 16-разрядный регистр флагов и состояния МП 8086, называемый FLAGS, который наиболее полезен при исполнении программ для МП 8086 и Intel-286. Некоторые из флагов могут быть изменены специально предназначенными для этой цели инструкциями. Для изменения или проверки группы флагов можно воспользоваться следующими командами:
- LAHF/SAHF – загрузка/сохранение младших 8 битов регистра флагов в регистре AH;
- PUSHF/POPF – помещение/извлечение из стека младших 16 битов регистра флагов;
- PUSHFD/POPFD – помещение/извлечение из стека 32-битного регистра EFLAGS.
Регистры управления сегментированной памятью, известные также как регистры системных адресов, указывают на структуры данных, которые управляют механизмом сегментированной памяти. Они определены для ссылок на таблицы или сегменты, поддерживаемые моделью защиты МП.
Регистр глобальной дескрипторной таблицы (GDTR). Содержит 32-битный линейный адрес и 16-битную границу глобальной дескрипторной таблицы. Значение этого регистра можно загрузить/сохранить при помощи привилегированных инструкций LGDT/SGDT. В реальном режиме этот регистр не используется. Перед переходом в защищенный режим в этот регистр следует загрузить корректные значения.
Регистр локальной дескрипторной таблицы (LDTR). Содержит 16-битный селектор локальной дескрипторной таблицы. С регистром связан программно-недоступный кэш дескриптора для хранения базового адреса, предела и атрибутов соответствующей дескрипторной таблицы. С каждой задачей в защищенном режиме может быть связана своя локальная дескрипторная таблица, поэтому селектор LDT хранится в TSS и автоматически загружается при переключении задач.
Регистр таблицы дескрипторов прерываний (IDTR). Указывает на таблицу точек входа в программы обработки прерываний. Регистр содержит 32-битный линейный базовый адрес и 16-битный предел таблицы.
Регистр задачи (TR). Указывает на информацию, необходимую МП для определения текущей задачи. Регистр содержит 16-битный селектор дескриптора сегмента состояния задачи. С регистром связан программно-недоступный кэш дескриптора TSS для хранения базового адреса, предела и атрибутов соответствующего сегмента состояния задачи.
МП имеет четыре 32-разрядных регистра управления CR0-CR4, в которых хранятся флаги состояния МП или глобальные флаги. Вместе с регистрами системных адресов эти регистры хранят информацию о состоянии МП, которая влияет на все задачи в системе. Системным программистам регистры управления доступны только через варианты команды MOV, которые позволяют их загружать или сохранять в регистрах общего назначения.
Шесть доступных регистров отладки DR0-DR3, DR6, DR7, (регистры DR4 и DR5 зарезервированы) расширяют возможности отладки. Они устанавливают точки останова по данным и позволяют устанавливать задавать точки останова по командам без модификации сегментов программ. Регистры DR0-DR3 предназначены для хранения четырех линейных адресов точек останова. Регистр DR6 отражает текущее состояние точек останова. Регистр DR7 задает условие для точек останова.
В МП Intel-386 и Intel-486 использовались также 2 регистра страничных проверок (TR6 и TR7), которые позднее были исключены из архитектуры IA‑32.
4.4. Формат команды микропроцессора IA-32 (i386/486)
Инструкция микропроцессора может содержать следующие поля:
|
Префикс |
КОП |
Mod R/M |
SIB |
Смещение |
Непосредственный операнд |
|
0/1 байт |
1/2 байта |
0/1 байт |
0/1 байт |
0/1/2/4 байта |
0/1/2/4 байта |
Префикс – необязательная часть инструкции, которая позволяет изменить некоторые особенности ее выполнения. В команде может быть использовано сразу несколько префиксов разного типа. Типы префиксов: командные префиксы (префиксы повторения) REP, REPE/REPZ, REPNE/REPNZ; префикс блокировки шины LOCK; префиксы размера; префиксы замены сегмента.
КОП – код операции.
Байт "Mod R/M" определяет режим адресации, а также иногда дополнительный код операции. Необходимость байта "Mod R/M" зависит от типа инструкции.
Байт SIB (Scale-Index-Base) определяет способ адресации при обращении к памяти в 32-битном режиме. Необходимость байта SIB зависит от режима адресации, задаваемого полем "Mod R/M".
Кроме того, инструкция может содержать непосредственный операнд и/или смещение операнда в сегменте данных.
На размер инструкции накладывается ограничение в 15 байт. Инструкция большего размера может получиться при некорректном использовании большого количества префиксов. В IA-32 в таком случае генерируют исключение #13.
4.5. Адресация операндов при обработке инструкций
Если инструкция микропроцессора требует операнды, то они могут задаваться следующими способами:
- непосредственно в коде инструкции (только операнд-источник);
- в одном из регистров;
- через порт ввода-вывода;
- в памяти.
Для совместимости с 16-битными процессорами архитектура IA-32 использует одинаковые коды для инструкций, оперирующих как с 16-битными, так и 32-битными операндами. Новая архитектура предусматривает также новые возможности при указании адреса для операнда в памяти. Как процессор будет считать операнд или его адрес, зависит от эффективного размера операнда и эффективного размера адреса для данной команды. Эти значения определяются на основе режима работы, бита D дескриптора используемого сегмента и наличия в инструкции определенных префиксов.
Непосредственный режим адресации подразумевает включение операнда-источника в код инструкции. Операнд может быть 8-битовым или 16-битовым, если значение эффективного размера операнда – 16. Операнд может быть 8-битовым или 32-битовым, если значение эффективного размера операнда – 32. Обычно непосредственные операнды используются в арифметических инструкциях.
Регистровый режим адресации определят операнд-источник или операнд-приемник в одном из регистров процессора или сопроцессора.
В некоторых случаях, (например, в инструкциях DIV и MUL) могут использоваться пары 32-битных регистров (например, EDX:EAX), образуя 64-битный операнд.
Адресация через порт ввода-вывода подразумевает получение операнда или сохранение операнда через пространство портов ввода-вывода. Адрес порта ввода-вывода либо непосредственно включается в код инструкции, либо берется из регистра DX.
Очень распространенный способ адресации операнда – адресация через память. Таким образом, может быть указан операнд-источник или операнд-приемник. Следует отметить, что процессор не позволяет одновременно задавать оба операнда через память (за исключением некоторых цепочечных команд).
Для получения операнда из памяти процессору необходимо знать селектор сегмента и смещение в сегменте. В некоторых командах селектор может быть указан непосредственно в коде инструкции. В других случаях процессор может явно или неявно использовать значение одного из сегментных регистров.
Под неявным использованием сегментных регистров подразумевается то, что в зависимости от предназначения операнда процессор использует определенный сегментный регистр для обращения к памяти:
- CS - для выборки инструкций;
- SS – для работы со стеком или обращения к памяти через регистры ESP или EBP;
- ES – для получения адреса операнда-приемника в цепочечных командах;
- DS – при всех остальных обращениях к памяти.
Явное использование сегментных регистров возможно, если в код инструкции включается префикс смены сегмента. Указание префикса смены сегмента допустимо не для всех команд: нельзя менять сегмент для команд работы со стеком (всегда используется SS); для цепочечных команд можно менять сегмент только операнда-источника (операнд-приемник всегда адресуется через ES).
Смещение в сегменте (эффективный или исполнительный адрес – EA) может быть вычислено на основе значений регистров общего назначения и/или указанного в коде инструкции относительного смещения, при этом любой или даже несколько из указанных компонентов могут отсутствовать:
EA = BASE + (INDEX*SCALE) + DISPLACEMENT
Такая схема позволяет в языках высокого уровня и на языке Ассемблера легко реализовать работу с массивами.
4.6. Особенности архитектуры современных x86 процессоров
4.6.1. Архитектура процессоров Intel Pentium (P5/P6)
Процессоры семейства Pentium имеют ряд архитектурных и структурных особенностей по сравнению с предыдущими моделями микропроцессоров фирмы Intel. Наиболее характерными из них являются:
- гарвардская архитектура с разделением потоков команд и данных при помощи введения отдельных внутренних блоков кэш-памяти для хранения команд и данных, а также шин для их передачи;
- суперскалярная архитектура, обеспечивающая одновременное выполнение нескольких команд в параллельно работающих исполнительных устройствах;
- динамическое исполнение команд, реализующее изменение последовательности команд, использование расширенного регистрового файла (переименование регистров) и эффективное предсказание ветвлений;
- двойная независимая шина, содержащая отдельную шину для обращения к кэш-памяти 2-го уровня (выполняется с тактовой частотой процессора) и системную шину для обращения к памяти и внешним устройствам (выполняется с тактовой частотой системной платы).
Основные характеристики процессоров семейства Pentium следующие:
- 32-разрядная внутренняя структура;
- использование системной шины с 36 разрядами адреса и 64 разрядами данных;
- раздельная внутренняя кэш-память первого уровня для команд и данных емкостью по 16 Кбайт;
- поддержка общей кэш-памяти команд и данных второго уровня емкостью до 2 Мбайт;
- конвейерное исполнение команд;
- предсказание направления программного ветвления с высокой точностью;
- ускоренное выполнение операций с плавающей точкой;
- приоритетный контроль при обращении к памяти;
- поддержка реализации мультипроцессорных систем;
- наличие внутренних средств, обеспечивающих самотестирование, отладку и мониторинг производительности.
Новая микроархитектура процессоров Pentium (рис. 4.6) и более поздних базируется на методе суперскалярной обработки.
Под суперскалярностью подразумевается наличие более одного конвейера для обработки команд (в отличие от скалярной – одноконвейерной архитектуры).
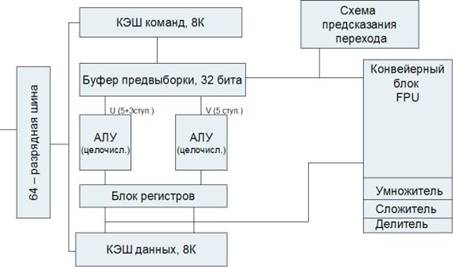 Рисунок 4.6 – Блок-схема архитектуры МП Pentium
Рисунок 4.6 – Блок-схема архитектуры МП Pentium
В МП Pentium команды распределяются по двум независимым исполнительным конвейерам (U и V). Конвейер U может выполнять любые команды семейства IA-32, включая целочисленные команды и команды с плавающей точкой. Конвейер V предназначен для выполнения простых целочисленных команд и некоторых команд с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, причем при выдаче устройством управления в одном такте пары команд более сложная команда поступает в конвейер U, а менее сложная – в конвейер V.
Однако, такая попарная обработка команд (спаривание) возможна только для ограниченного подмножества целочисленных команд. Команды вещественной арифметики не могут запускаться в паре с целочисленными командами. Одновременная выдача двух команд возможна только при отсутствии зависимостей по регистрам.
Одной из главных особенностей шестого поколения микропроцессоров архитектуры IA-32 является динамическое (спекулятивное) исполнение. Под этим термином подразумевается следующая совокупность возможностей:
- глубокое предсказание ветвлений (с вероятностью > 90% можно предсказать 10-15 ближайших переходов);
- анализ потока данных (на 20-30 шагов вперед просмотреть программу и определить зависимость команд по данным или ресурсам);
- опережающее исполнение команд (МП P6 может выполнять команды в порядке, отличном от их следования в программе).
Внутренняя организация МП P6 соответствует архитектуре RISC, поэтому блок выборки команд, считав поток инструкций IA-32 из L1 кэша инструкций, декодирует их в серию микроопераций. Поток микроопераций попадает в буфер переупорядочивания (пул инструкций). В нем содержатся как не выполненные пока микрооперации, так и уже выполненные, но еще не повлиявшие на состояние процессора.
Для декодирования инструкций предназначены три параллельных дешифратора: два для простых и один для сложных инструкций.
Каждая инструкция IA-32 декодируется в 1-4 микрооперации. Микрооперации выполняются пятью параллельными исполнительными устройствами: два для целочисленной арифметики, два для вещественной арифметики и блок интерфейса с памятью. Таким образом, возможно выполнение до пяти микроопераций за такт.
Блок исполнительных устройств способен выбирать инструкции из пула в любом порядке. При этом благодаря блоку предсказания ветвлений возможно выполнение инструкций, следующих за условными переходами. Блок резервирования постоянно отслеживает в пуле инструкций те микрооперации, которые готовы к исполнению (исходные данные не зависят от результата других невыполненных инструкций) и направляет их на свободное исполнительное устройство соответствующего типа. Одно из целочисленных исполнительных устройств дополнительно занимается проверкой правильности предсказания переходов. При обнаружении неправильно предсказанного перехода все микрооперации, следующие за переходом, удаляются из пула и производится заполнение конвейера команд инструкциями по новому адресу.
Взаимная зависимость команд от значения регистров архитектуры IA-32 может требовать ожидания освобождения регистров. Для решения этой проблемы предназначены 40 внутренних регистров общего назначения, используемых в реальных вычислениях.
Блок удаления отслеживает результат спекулятивно выполненных микроопераций. Если микрооперация более не зависит от других микроопераций, ее результат переносится на состояние процессора, и она удаляется из буфера переупорядочивания. Блок удаления подтверждает выполнение инструкций (до трех микроопераций за такт) в порядке их следования в программе, принимая во внимание прерывания, исключения, точки останова и промахи предсказания переходов.
Описанная схема отображена на рис. 4.7.
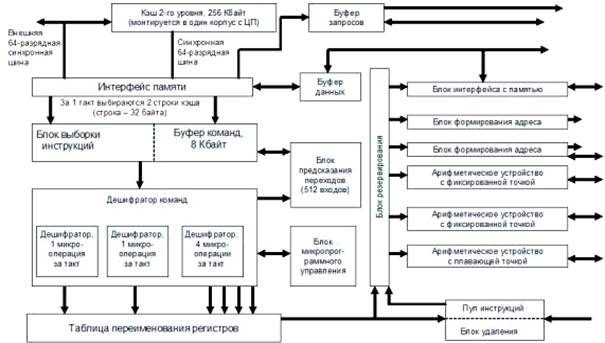
Рисунок 4.7 – Блок схема микропроцессора Pentium Pro
4.6.2. SIMD-расширения ММХ
Многие алгоритмы работы с мультимедийными данными допускают простейшие элементы распараллеливания, когда одна операция может выполняться параллельно над несколькими числами. Такой подход называется SIMD – single-instruction multiple-data (одна инструкция – множество данных). Впервые эта технология была реализована в поколении P55 (микропроцессор Pentium MMX).
MMX (Multi-Media eXtension) – это SIMD-расширение для потоковой обработки целочисленных данных, реализованное на основе блока FPU (с использованием регистров FPU).
Одна инструкция MMX может выполнить арифметическую или логическую операцию над "пакетами" целых чисел, упакованных в регистрах MMX. Например, инструкция PADDSB складывает 8 байт одного "пакета" с соответствующими восьмью байтами другого пакета, фактически выполняя сложение восьми пар чисел одной инструкцией.
4.6.3. Процессоры Pentium Pro, Pentium II, Pentium III
В процессоре Pentium II соединены лучшие свойства процессоров Intel: производительность процессора Pentium Pro и возможности технологии MMX. Это сочетание обеспечивает существенное увеличение производительности процессоров Pentium II по сравнению с предыдущими процессорами IA-32-архитектуры.
Процессор содержит раздельные внутренние блоки кэш-памяти команд и данных по 16 Кбайт и 512 Кбайт общей неблокирующей кэш-памяти второго уровня.
Повышение производительности IA-32 достигалось не только путем оптимизации конвейера команд и добавления исполнительных блоков, но и, например, внедрением кэш-памяти в ядро процессора. В семействе IA-32 встроенный кэш L1 размером 8 Кбайт впервые был реализован в процессорах Intel-486. В процессорах Pentium размер кэша был удвоен. Первые представители P6 (Pentium Pro) содержали также кэш L2 размером 256 или 512 Кбайт. Однако такое решение в то время оказалось слишком дорогим и невыгодным, поэтому в Pentium II была представлена технология Dual Independent Bus (DIB) – двойная независимая шина. Для доступа к кэшу и для доступа к внешней памяти использовались раздельные шины. Такое же архитектурное решение использовалось в первых моделях Pentium III. Начиная с 1999 года (Pentium III Coppermine), кэш L2 вновь был возвращен внутрь кристаллов процессоров.
Развитием идеи SIMD для вещественных чисел стала технология SSE (Streamed SIMD Extensions), впервые представленная в процессорах Pentium III. Блок SSE дополняет технологию MMX восемью 128-битными регистрами XMM0-XMM7 и 32-битным регистром управления и состояния MXCSR.
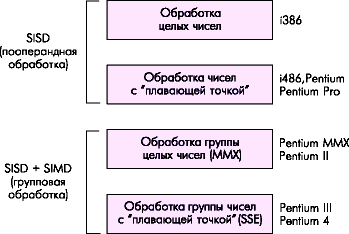
Рисунок 4.9 - Эволюция процесса обработки данных в процессорах Intel Pentium
4.6.4. Pentium 4 (P7) – микроархитектура Net Burst
Процессор Pentium 4 является 32-разрядным представителем семейства IA-32, по микроархитектуре принадлежащим к новому, седьмому (по классификации Intel) поколению. С программной точки зрения он представляет собой процессор IA-32 с очередным расширением системы команд – SSE2. По набору программно-доступных регистров Pentium 4 повторяет процессор Pentium III. С внешней, аппаратной точки зрения – это процессор с системной шиной нового типа, в которой кроме повышения тактовой частоты применены ставшие уже привычными принципы двойной (2х) и четырехкратной (4х) синхронизации, а также предпринят ряд мер по обеспечению работоспособности на ранее немыслимых частотах. Микроархитектура процессора, получившая название Net Burst, разработана с учетом высоких частот как ядра (более 1,4 ГГц), так и системной шины (400 МГц).
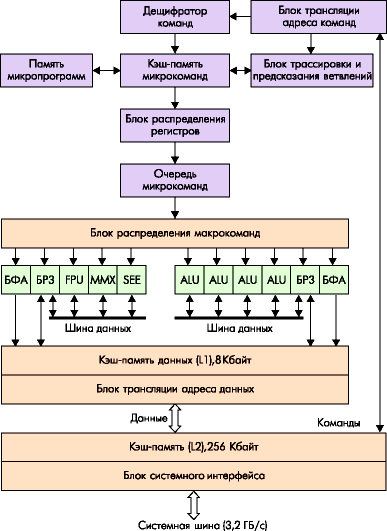
Рисунок 4.10 – Микроархитектура NetBurst
Процессор Pentium 4 является однокристальным. Кроме собственно вычислительного ядра, он содержит кэш-память двух уровней. Вторичный кэш, общий для инструкций и данных, имеет размер 256 Кбайт и разрядность шины 256 бита (32 байта), как и в последних процессорах Pentium III. Шина вторичного кэша работает на частоте ядра, что обеспечивает ее пропускную способность 32х1,4 = 44,8 Гбайт/с на частоте 1,4 ГГц. Вторичный кэш имеет ЕСС-контроль, позволяющий обнаруживать и исправлять ошибки. Первичный кэш данных имеет такую же высокую пропускную способность (44,8 Гбайт/с), но его объем сократился вдвое (8 Кбайт против 16 в Pentium III). Первичный кэш инструкций в привычном понимании отсутствует, его заменил кэш трассы (trace cache). В нем хранятся последовательности микроопераций, в которые декодированы инструкции. Здесь могут помещаться до 12К микроинструкций.
Интерфейс системной шины процессора рассчитан только на однопроцессорные конфигурации. Интерфейс во многом напоминает шину Р6, протокол также ориентирован на одновременное выполнение нескольких транзакций. Принят ряд мер по обеспечению высокой пропускной способности. В процессоре Pentium 4 частота шины 400 МГц с "четырехкратной накачкой" (quad pumped) – тактовая частота системной шины составляет 100 МГц, но частота передачи адресов и данных выше. Новая информация по линиям с общей синхронизацией может передаваться на каждом такте с частотой 100 МГц. Для 2 и 4-кратной передачи используется синхронизация от источника данных.
Исполнительные устройства МП (АЛУ) работают на удвоенной частоте, что дает возможность выполнять большинство целочисленных инструкций за половину такта. По сравнению с предыдущими поколениями IA-32, Pentium 4 содержит самый длинный конвейер команд, состоящий из 20 этапов и названный гиперконвейером. В связи с этой особенностью многие специалисты отмечают, что микроархитектура NetBurst будет иметь максимальную производительность исполнения предсказуемых (линейных и циклических) участков программы, характерных для приложений, на которые ориентирован Pentium 4. На непредсказуемо ветвящихся программах, к которым относятся, например, офисные приложения, длинный гиперконвейер оказывается менее эффективным, чем конвейер Р6, если бы тот удалось разогнать до частот 1,4 ГГц и выше. Чтобы частично компенсировать этот недостаток, были существенно оптимизированы механизмы спекулятивного исполнения и предсказания ветвлений.