В теории помехоустойчивого кодирования важным является вопрос об использовании избыточности для корректирования возникающих при передаче ошибок. Здесь удобно рассмотреть блочные моды, в которых всегда имеется возможность выделить отдельные кодовые комбинации. Напомним, что для равномерных кодов, которые в дальнейшем только и будут изучаться, число возможных комбинаций равно M=2n, где п — значность кода. В обычном некорректирующем коде без избыточности, например в коде Бодо, число комбинаций М выбирается равным числу сообщений алфавита источника М0и все комбинации используются для передачи информации. Корректирующие коды строятся так, чтобы число комбинаций М превышало число сообщений источника М0. Однако в.этом случае лишь М0комбинаций из общего числа используется для передачи информации. Эти комбинации называются разрешенными, а остальные М—М0комбинаций носят название запрещенных. На приемном конце в декодирующем устройстве известно, какие комбинации являются разрешенными и какие запрещенными. Поэтому если переданная разрешенная комбинация в результате ошибки преобразуется в некоторую запрещенную комбинацию, то такая ошибка будет обнаружена, а при определенных условиях исправлена. Естественно, что ошибки, приводящие к образованию другой разрешенной комбинации, не обнаруживаются.
Различие между комбинациями равномерного кода принято характеризовать расстоянием, равным числу символов, которыми отличаются комбинации одна от другой. Расстояние d![]() между двумя комбинациями
между двумя комбинациями ![]() и
и ![]() определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
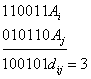
Для любого кода d![]()
![]() . Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
. Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
Расстояние между комбинациями ![]() и
и ![]() условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций
условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций ![]() и
и ![]() , разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация
, разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация ![]() преобразовалась в другую разрешенную комбинацию
преобразовалась в другую разрешенную комбинацию ![]() , должно исказиться d символов.
, должно исказиться d символов.
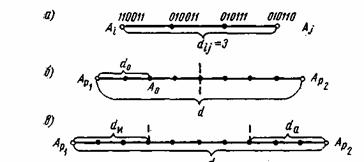
Рис. 7.2. Геометрическое представление разрешенных и запрещенных кодовых комбинаций
При искажении меньшего числа символов комбинация ![]() перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
![]() (7.1)
(7.1)
Если g>d, то некоторые ошибки также обнаруживаются. Однако полной гарантии обнаружения ошибок здесь нет, так как ошибочная комбинация ib этом случае может совпасть с какой-либо разрешенной комбинацией. Минимальное кодовое расстояние, при котором обнаруживаются любые одиночные ошибки, d=2.
Процедура исправления ошибок в процессе декодирования сводится к определению переданной комбинации по известной принятой. Расстояние между переданной разрешенной комбинацией и принятой запрещенной комбинацией d0 равно кратности ошибок g. Если ошибки в символах комбинации происходят независимо относительно друг друга, то вероятность искажения некоторых g символов в n-значной комбинации будет равна:
![]() (7.2)
(7.2)
где ![]() — вероятность искажения одного символа. Так как обычно
— вероятность искажения одного символа. Так как обычно ![]() <<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация
<<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация ![]() (см.рис.7.2б), тогда принимается решение, что была передана комбинация
(см.рис.7.2б), тогда принимается решение, что была передана комбинация ![]() . Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
. Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
![]() (7.3)
(7.3)
Минимальное значение d, при котором еще возможно исправление любых одиночных ошибок, равно 3.
Возможно также построение таких кодов, в которых часть ошибок исправляется, а часть только обнаруживается. Так, в соответствии с рис. 7.2в ошибки кратности ![]() исправляются, а ошибки, кратность которых лежит в пределах
исправляются, а ошибки, кратность которых лежит в пределах ![]() только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах
только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах ![]() , то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А
, то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А![]() вместо A
вместо A![]() или наоборот.
или наоборот.
Существуют двоичные системы связи, в которых решающее устройство выдает, кроме обычных символов 0 и 1, еще так называемый символ стирания ![]() . Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов
. Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов ![]() оказалось равным gc, причем
оказалось равным gc, причем
![]() (7.4)
(7.4)
а остальные символы приняты без ошибок, то такая комбинация полностью восстанавливается. Действительно, для восстановления всех символов ![]() необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок
необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок ![]() , то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
, то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
Если ![]() , то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
, то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
Таким образом, при фиксированном кодовом расстоянии максимально возможная кратность корректируемых ошибок достигается в кодах, которые обнаруживают ошибки или .восстанавливают стертые символы. Исправление ошибок представляет собой более трудную задачу, практическое решение которой сопряжено с усложнением кодирующих и декодирующих устройств. Поэтому исправляющие «оды обычно используются для корректирования ошибок малой кратности.
Корректирующая способность кода возрастает с увеличением d. При фиксированном числе разрешенных комбинаций М![]() увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
![]() (7.5)
(7.5)
что, в свою очередь, требует избыточного числа символов r=n—k, где k — количество символов в комбинации кода без избыточности. Можно ввести понятие избыточности кода и количественно определить ее по аналогии с (6.12) как
![]() (7.6)
(7.6)
При независимых ошибках вероятность определенного сочетания g ошибочных символов в n-значной кодовой комбинации выражается ф-лой ((7.2), а количество всевозможных сочетаний g ошибочных символов в комбинации зависит от ее длины и определяется известной формулой числа сочетаний
![]()
Отсюда полная вероятность ошибки кратности g, учитывающая все сочетания ошибочных символов, равняется:
![]() (7.7)
(7.7)
Используя (7.7), можно записать формулы, определяющие вероятность отсутствия ошибок в кодовой комбинации, т. е. вероятность правильного приема
![]()
и вероятность правильного корректирования ошибок
![]()
Здесь суммирование 'Производится по всем значениям кратности ошибок g, которые обнаруживаются и исправляются. Таким образом, вероятность некорректируемых ошибок равна:
![]() (7.8)
(7.8)
Анализ ф-лы (7.8) показывает, что при малой величине Р0и сравнительно небольших значениях п наиболее вероятны ошибки малой кратности, которые и необходимо корректировать в первую очередь.
Вероятность Р![]() , избыточность
, избыточность ![]() и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
Общая задача, которая ставится при создании кода, заключается, в достижении наименьших значений Р![]() и
и ![]() . Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
. Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
В соответствии с общим принципом корректирования ошибок, основанным на использовании разрешенных и запрещенных комбинаций, необходимо сравнивать принятую комбинацию со всеми комбинациями данного кода. В результате М сопоставлений и принимается решение о переданной комбинации. Этот способ декодирования логически является наиболее простым, однако он требует сложных устройств, так как в них должны запоминаться все М комбинаций кода. Поэтому на практике чаще всего используются коды, которые позволяют с помощью ограниченного числа преобразований принятых кодовых символов извлечь из них всю информацию о корректируемых ошибках. Изучению таких кодов и посвящены последующие разделы.