7.2. Представление сверточного кодера
7.3. Формулировка задачи сверточного кодирования
7.3.1. Декодирование по методу максимального правдоподобия
7.3.2. Модели каналов: мягкое или жесткое принятие решений
7.3.3. Алгоритм сверточного декодирования Витерби
7.3.4. Пример сверточного декодирования Витерби
7.3.5.1. Процедура сложения, сравнения и выбора
7.3.5.2. Вид процедуры сложения, сравнения и выбора на решетке
7.4. Свойства сверточных кодов
7.4.1. Пространственные характеристики сверточных кодов
7.4.2. Систематические и несистематические сверточные коды
7.4.3. Накопление катастрофических ошибок в сверточных кодах
7.4.4. Границы рабочих характеристик сверточных кодов
7.4.5. Эффективность кодирования
7.4.6. Наиболее известные сверточные коды
7.4.7. Компромиссы сверточного кодирования
7.4.7.1. Производительность при когерентнойпередаче сигналов с модуляцией PSK
7.4.7.2.Производительность при некогерентной ортогональной передаче сигналов
7.5. Другие алгоритмы сверточного декодирования
7.1. Сверточное кодирование
На рис. 1.2 представлена типичная блочная диаграмма системы цифровой связи. Разновидность такой функциональной диаграммы, относящаяся, в первую очередь, к сверточному кодированию/декодированию и модуляции/демодуляции, показана на рис. 7.1. Исходное сообщение на входе обозначается последовательностью ![]() ., где
., где ![]() , — двоичный знак (бит), a i — индекс времени. Если быть точным, то элементы m следовало бы дополнять индексом члена класса (например, для бинарного кода, 1 или 0) и индексом времени. Однако в этой главе для простоты будет использоваться только индекс, обозначающий время (или расположение элемента внутри последовательности). Мы будем предполагать, что все
, — двоичный знак (бит), a i — индекс времени. Если быть точным, то элементы m следовало бы дополнять индексом члена класса (например, для бинарного кода, 1 или 0) и индексом времени. Однако в этой главе для простоты будет использоваться только индекс, обозначающий время (или расположение элемента внутри последовательности). Мы будем предполагать, что все ![]() , равновероятно равны единице или нулю и независимы между собой. Будучи независимой, последовательность битов нуждается в некоторой избыточности, т.е. знание о бите
, равновероятно равны единице или нулю и независимы между собой. Будучи независимой, последовательность битов нуждается в некоторой избыточности, т.е. знание о бите ![]() , не дает никакой информации о бите
, не дает никакой информации о бите ![]() , (при
, (при ![]() ): Кодер преобразует каждую последовательность m в уникальную последовательность кодовых слов
): Кодер преобразует каждую последовательность m в уникальную последовательность кодовых слов ![]() . Даже несмотря на то что последовательность m однозначно определяет последовательность U, ключевой особенностью сверточных кодов является то, что данный k-кортеж внутри m не однозначно определяет связанные с ним k-кортежи внутри U, поскольку кодирование каждого из k-кортежей является функцией не только k-кортежей, но и предыдущих К-1 k- кортежей Последовательность U можно разделить вд последовательность ответвленных слов:
. Даже несмотря на то что последовательность m однозначно определяет последовательность U, ключевой особенностью сверточных кодов является то, что данный k-кортеж внутри m не однозначно определяет связанные с ним k-кортежи внутри U, поскольку кодирование каждого из k-кортежей является функцией не только k-кортежей, но и предыдущих К-1 k- кортежей Последовательность U можно разделить вд последовательность ответвленных слов: ![]() . Каждое ответвленное слою
. Каждое ответвленное слою ![]() , состоит из двоичных кодовых символов, часто называемых канальными символами, канальными битами, или битами кода, в отличие от битов входного сообщения, кодовые символы не являются независимыми.
, состоит из двоичных кодовых символов, часто называемых канальными символами, канальными битами, или битами кода, в отличие от битов входного сообщения, кодовые символы не являются независимыми.
В типичных системах связи последовательность кодовых слов U модулируется сигналом s(t). В ходе передачи сигнал искажается шумом, в результате чего, как показан на рис. 7.1, получается сигнал ![]() и демодулированная последовательность
и демодулированная последовательность ![]() .Задача декодера состоит в получении оценки
.Задача декодера состоит в получении оценки ![]() исходной последовательности сообщения с помощью полученной последовательности Z и априорных знаний о процедуре кодирования.
исходной последовательности сообщения с помощью полученной последовательности Z и априорных знаний о процедуре кодирования.
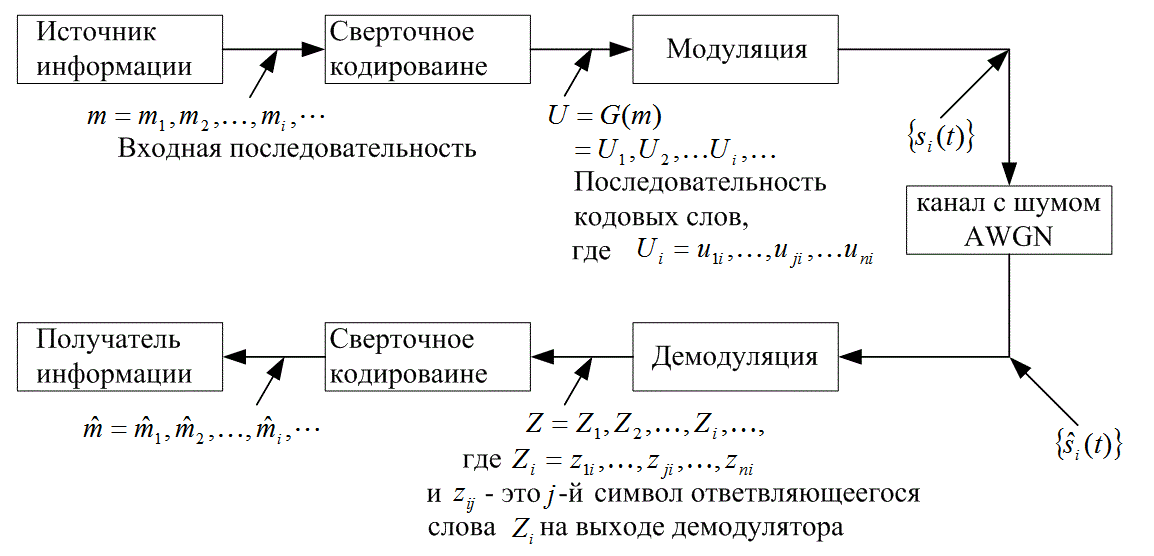
Рис. 7.1. Кодирование/декодирование и модуляция/демодуляция в канале связи
Обычный сверточный кодер, показанный на рис. 7.2, реализуется с kK-разрядным регистром сдвига и и сумматорами по модулю 2, где K — длина кодового ограничения. Длина кодового ограничения — это количество k-разрядных сдвигов, после которых один информационный бит может повлиять на выходной сигнал кодера. В каждый момент времени на место первых k разрядов регистра перемещаются k новых бит; все биты в регистре смещаются на k разрядов вправо, и выходные данные п сумматоров последовательно дискретизируются, давая, в результате, биты кода. Затем эти символы кода используются модулятором для формирования сигналов, которые будут переданы по каналу. Поскольку для каждой входящей группы из k бит сообщения имеется п бит кода, степень кодирования равна k/n бит сообщения на бит кода, где k < п.
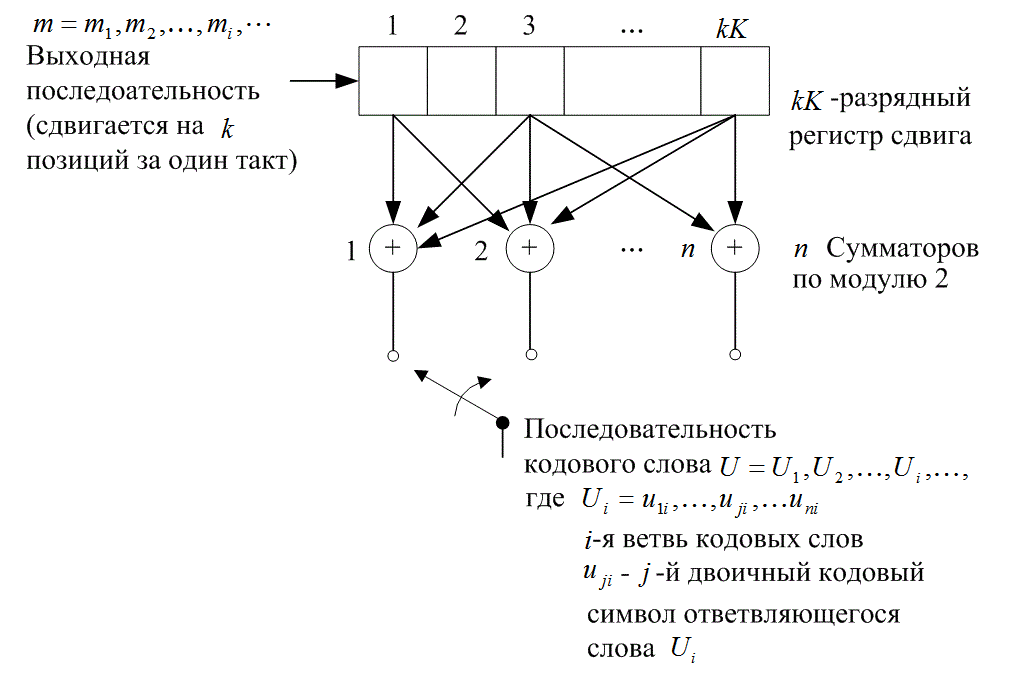
Рис. 7.2. Сверточный кодер с длинной кодового ограничения K и степенью кодирования k/n
Мы будем рассматривать только наиболее часто используемые двоичные сверточные кодеры, для которых ![]() , т.е. те кодирующие устройства, в которых биты сообщения сдвигаются по одному биту за раз, хотя обобщение на алфавиты более высоких порядков не вызывает никаких затруднений [1, 2]. Для кодера с
, т.е. те кодирующие устройства, в которых биты сообщения сдвигаются по одному биту за раз, хотя обобщение на алфавиты более высоких порядков не вызывает никаких затруднений [1, 2]. Для кодера с ![]() , за
, за ![]() -й момент времени бит сообщения
-й момент времени бит сообщения ![]() , будет перемещен на место первого разряда регистра сдвига; все предыдущие биты в регистре будут смещены на один разряд вправо, а выходной сигнал п сумматоров будет последовательно оцифрован и передан. Поскольку для каждого бита сообщения имеется п бит кода, степень кодирования равна 1/n. Имеющиеся в момент времени
, будет перемещен на место первого разряда регистра сдвига; все предыдущие биты в регистре будут смещены на один разряд вправо, а выходной сигнал п сумматоров будет последовательно оцифрован и передан. Поскольку для каждого бита сообщения имеется п бит кода, степень кодирования равна 1/n. Имеющиеся в момент времени ![]() п кодовых символов составляют i-e ответвленное слово,
п кодовых символов составляют i-e ответвленное слово, ![]() , где
, где ![]()
![]() — это j-й кодовый символ, принадлежащий i-му ответвленному слову. Отметим, что для кодера со степенью кодирования 1/n, kK-разрядный регистр сдвига для простоты можно называть K-разрядным регистром, а длину кодового ограничения K, которая выражается в единицах разрядов k-кортежей, можно именовать длиной кодового ограничения в битах.
— это j-й кодовый символ, принадлежащий i-му ответвленному слову. Отметим, что для кодера со степенью кодирования 1/n, kK-разрядный регистр сдвига для простоты можно называть K-разрядным регистром, а длину кодового ограничения K, которая выражается в единицах разрядов k-кортежей, можно именовать длиной кодового ограничения в битах.
7.2. Представление сверточного кодера
Чтобы иметь возможность описывать сверточный код, необходимо определить кодирующую функцию G(m) так, чтобы по данной входящей последовательности m можно было быстро вычислить выходную последовательность U. Для реализации сверточного кодирования используется несколько методов; наиболее распространенными из них являются графическая связь, векторы, полиномы связи, диаграмма состояния, древовидная и решетчатая диаграммы. Все они рассматриваются ниже.
7.2.1. Представление связи
При обсуждении сверточных кодеров в качестве модели будем использовать сверточный кодер, показанный на рис. 7.3. На этом рисунке изображен сверточный кодер (2,1) с длиной кодового ограничения K = 3. В нем имеется n =2 сумматора по модулю 2; следовательно, степень кодирования кода k/n равна 1/2. При каждом поступлении бит помещается в крайний левый разряд, а биты регистра смещаются на одну позицию вправо. Затем коммутатор на выходе дискретизирует выходы всех сумматоров по модулю 2 (т.е. сначала верхний сумматор, затем нижний), в результате чего формируются пары кодовых символов, образующих ответвленное слово, связанное с только что поступившим битом. Эта выполняется для каждого входного бита. Выбор связи между сумматорами и разрядами регистра влияет на характеристики кода. Всякое изменение в выборе связей приводит в результате к различным кодам. Связь, конечно же, выбирается и изменяется не произвольным образом. Задача выбора связей, дающая оптимальные дистанционные свойства, сложна и в общем случае не решается; однако для всех значений длины кодового ограничения, меньших 20, с помощью компьютеров были найдены хорошие коды [3-5].
В отличие от блочных кодов, имеющих фиксированную длину слова n, в сверточных кодах нет определенного размера блока. Однако с помощью периодического отбрасывания сверточным кодам часто принудительно придают блочную структуру. Это требует некоторого количества нулевых разрядов, присоединенных к концу входной последовательности данных, которые служат для очистки (или промывки) регистра сдвига от бит данных. Поскольку добавленные нули не несут дополнительной информации, эффективная степень кодирования будет ниже k/n. Чтобы степень кодирования оставалась близкой к k/n, период отбрасывания чаще всего делают настолько большим, на сколько это возможно.
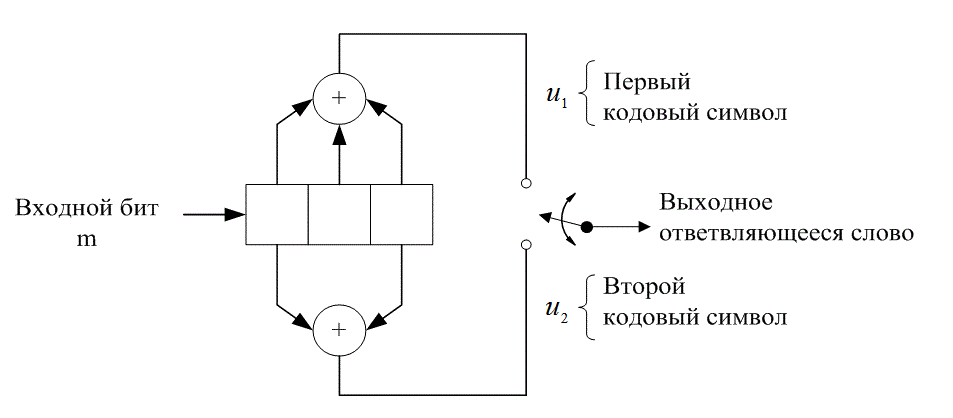
Рис. 7.3. Сверточный кодер (степень кодирования 1/2, К= 3)
Один из способов реализации кодера заключается в определении п векторов связи, по одному на каждый из п сумматоров по модулю 2. Каждый вектор имеет размерность K и описывает связь регистра сдвига кодера с соответствующим сумматором по модулю 2. Единица на i-й позиции вектора указывает на то, что соответствующий разряд в регистре сдвига связан с сумматором по модулю 2, а нуль в данной позиции указывает, что связи между разрядом и сумматором по модулю 2 не существует. Для кодера на рис. 7.2 можно записать вектор связи ![]()
![]() для верхних связей, а
для верхних связей, а ![]() — для нижних.
— для нижних.
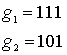
Предположим теперь, что вектор сообщения m = 1 0 1 закодирован с использованием сверточного кода и кодера, показанного на рис. 7.3. Введены три бита сообщения, по одному в момент времени ![]()
![]() , как показано на рис. 7.4. Затем для очистки регистра в моменты времени
, как показано на рис. 7.4. Затем для очистки регистра в моменты времени ![]() и
и ![]() введены
введены ![]() нуля, что в результате приводит к смещению конечного участка на всю длину регистра. Последовательность на выходе выглядит следующим образом: 1110001011, где крайний левый символ представляет первую передачу. Для декодирования сообщения нужна полная последовательность на выходе (включающая кодовые символы). Для удаления сообщения из кодера требуется на единицу меньше нулей, чем имеется разрядов в регистре, или
нуля, что в результате приводит к смещению конечного участка на всю длину регистра. Последовательность на выходе выглядит следующим образом: 1110001011, где крайний левый символ представляет первую передачу. Для декодирования сообщения нужна полная последовательность на выходе (включающая кодовые символы). Для удаления сообщения из кодера требуется на единицу меньше нулей, чем имеется разрядов в регистре, или ![]() очищенных бит. В момент времени
очищенных бит. В момент времени ![]() показан нулевой выход, это должно дать читателю возможность убедиться в том, что в момент времени
показан нулевой выход, это должно дать читателю возможность убедиться в том, что в момент времени ![]() регистр устанавливается в исходное состояние. Таким образом, в момент времени
регистр устанавливается в исходное состояние. Таким образом, в момент времени ![]() уже можно передавать новое сообщение.
уже можно передавать новое сообщение.
7.2.1.1. Реакция кодера на импульсное возмущение
Мы можем описать кодер через его импульсную характеристику, т.е. в виде отклика кодера на единичный проходящий бит. Рассмотрим содержимое регистра (рис. 7.3) при прохождении через него двоичной единицы.
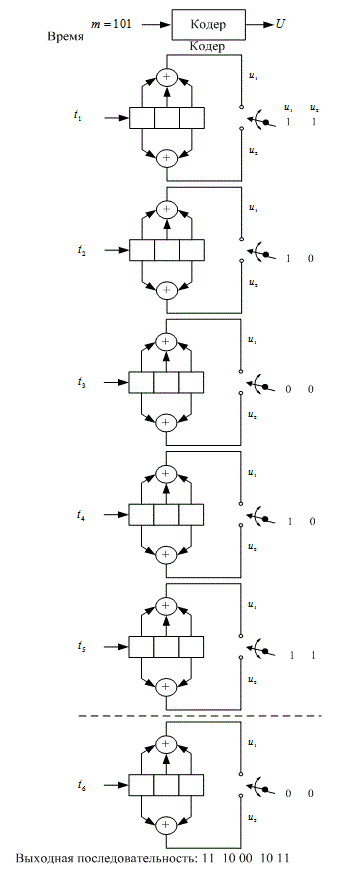
Рис. 7.4. Сверточное кодирование последовательности сообщения со степенью кодирования 1/2 кодером с К=3.
Ответвляющееся слово
|
Содержимое регистра |
|
|
|
|
100 |
1 |
1 |
|
|
010 |
1 |
0 |
|
|
001 |
1 |
1 |
|
|
Входная последовательность |
1 0 0 |
||
|
Выходная последовательность |
11 10 11 |
Последовательность на выходе при единице на входе называется откликом кодера на импульсное возмущение, или его импульсной характеристикой. Для входной последовательности m = 1 0 1 данные на выходе могут быть найдены путем суперпозиции или линейного сложения смещенных во времени входных "импульсов".
Вход, m Выход
|
1 |
11 |
10 |
11 |
||
|
0 |
00 |
00 |
00 |
||
|
1 |
11 |
11 |
10 |
11 |
|
|
Сумма по модулю 2 |
11 |
00 |
00 |
10 |
11 |
Обратите внимание на то, что эти данные на выходе такие же, как и на рис. 7.4, что указывает на линейность сверточных кодов — точно так же как и в блочных кодах в главе 6. Название сверточный кодер (convolutional encoder) возникло именно вследствие этого свойства генерации данных на выходе с помощью линейного сложения (или свертки) смещенных во времени импульсов последовательности на входе с импульсной характеристикой кодера. Такие устройства часто описываются с помощью матричного генератора бесконечного порядка [6].
Отметим, что в рассмотренном выше примере входящей последовательности из 3 бит и последовательности на выходе из 10 бит эффективная степень кодирования составляет k/n = 3/10, что значительно меньше величины 1/2, которую можно было бы ожидать, зная, что каждый бит данных на входе порождает пару канальных битов на выходе. Причина этого заключается в том, что окончательные биты данных нужно проводить через кодер. Все канальные биты на выходе нуждаются в процессе декодирования. Если бы сообщение было длиннее, скажем 300 бит, последовательность кодовых слов на выходе содержала бы 640 бит и значение для степени кодирования кода 300/640 было бы значительно ближе к 1/2.
7.2.1.2. Полиномиальное представление
Иногда связи кодера описываются с помощью полиномиального генератора, аналогичного используемому в главе 6 для описания реализации обратной связи регистра сдвига циклических кодов. Сверточный кодер можно представить в виде набора из п полиномиальных генераторов, по одному для каждого из п сумматоров по модулю 2. Каждый полином имеет порядок или меньше и описывает связь кодирующего регистра сдвига с соответствующим сумматором по модулю 2, почти так же как и вектор связи. Коэффициенты возле каждого слагаемого полинома порядка (K - 1) равны либо 1, либо 0, в зависимости от того, имеется ли связь между регистром сдвига и сумматором по модулю 2. Для кодера на рис. 7.3 можно записать полиномиальный генератор ![]() для верхних связей и
для верхних связей и![]() — для нижних.
— для нижних.
![]()
![]()
Здесь слагаемое самого нижнего порядка в полиноме соответствует входному разряду регистра. Выходная последовательность находится следующим образом.
![]() чередуется с
чередуется с ![]()
Прежде всего, выразим вектор сообщения m = 1 0 1 в виде полинома, т.е. ![]() . Для очистки регистра мы снова будем предполагать использование нулей, следующих за битами сообщения. Тогда выходящий полином U(X), или выходящая последовательность U кодера (рис. 7.3) для входящего сообщения m может быть найдена следующим образом.
. Для очистки регистра мы снова будем предполагать использование нулей, следующих за битами сообщения. Тогда выходящий полином U(X), или выходящая последовательность U кодера (рис. 7.3) для входящего сообщения m может быть найдена следующим образом.
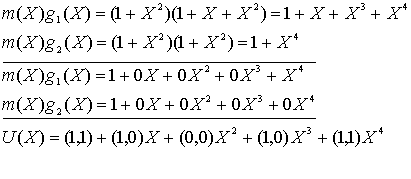
В этом примере мы начали обсуждение с того, что сверточный кодер можно трактовать как набор регистров сдвига циклического кода. Мы представили кодер в виде полиномиальных генераторов, с помощью которых описываются циклические коды. Однако мы пришли к той же последовательности на выходе, что и на рис. 7.4, и к той же, что и в предыдущем разделе, полученной при описании реакции на импульсное возмущение. (Чтобы иметь лучшее представление о структуре сверточного кода в контексте линейной последовательной схемы, обратитесь к работе [7].)
7.2.2. Представление состояния и диаграмма состояний
Сверточный кодер принадлежит классу устройств, известных как конечный автомат (finite-state machine). Это общее название дано системам, обладающим памятью о прошедших сигналах. Прилагательное конечный показывает, что существует ограниченное число состояний, которое может возникнуть в системе. Что имеется в виду под состоянием (state) в системах с конечным его числом? В более общем смысле состояние включает наименьшее количество информации, на основе которой вместе с текущими входными данными можно определить данные на выходе системы. Состояние дает некоторое представление о прошлых событиях (сигналах) и об ограниченном наборе возможных выходных данных в будущем. Будущие состояния ограничиваются прошлыми состояниями. Для сверточного кода со степенью кодирования 1/n состояние представлено содержимым K - 1 крайних правых разрядов (рис. 7.4). Знание состояния плюс знание следующих данных на входе является необходимым и достаточным условием для определения данных на выходе. Итак, пусть состояние кодера в момент времени ![]() определяется как
определяется как ![]() , i-я ветвь кодовых слов
, i-я ветвь кодовых слов ![]() полностью определяется состоянием
полностью определяется состоянием ![]() и введенными в настоящее время битами
и введенными в настоящее время битами ![]() ; таким образом, состояние
; таким образом, состояние ![]() описывает предысторию кодера для определения данных на его выходе. Состояния кодера считаются Марковскими в том смысле, что вероятность
описывает предысторию кодера для определения данных на его выходе. Состояния кодера считаются Марковскими в том смысле, что вероятность ![]() нахождения в состоянии
нахождения в состоянии ![]() , определяемая всеми предыдущими состояниями, зависит только от самого последнего состояния
, определяемая всеми предыдущими состояниями, зависит только от самого последнего состояния ![]() , т.е. она равна
, т.е. она равна ![]() .
.
Одним из способов представления простых кодирующих устройств является диаграмма состояния (state diagram); такое представление кодера, изображенного на рис. 7.3, показано на рис. 7.5. Состояния, показанные в рамках диаграммы, представляют собой возможное содержимое K - 1 крайних правых разрядов регистра, а пути между состояниями — ответвляющиеся слова на выходе, являющиеся результатом переходов между такими состояниями. Состояния регистра выбраны следующими: а = 00, b = 10, c = 01 и d = 11 диаграмма, показанная на рис. 7.5, иллюстрирует все возможные смены состояний для кодера, показанного нарис. 7.3. Существует всего два исходящих из каждого состояния перехода, соответствующие двум возможным входным битам. Далее для каждого пути между состояниями записано ответвляющееся слово на выходе, связанное с переходами между состояниями. При изображении путей, сплошной линией принято обозначать путь, связанный с нулевым входным битом, а пунктирной линией — путь, связанный с единичным входным битом. Отметим, что за один переход невозможно перейти из данного состояния в любое произвольное. Так как за единицу времени перемещается только один бит, существует только два возможных перехода между состояниями, в которые регистр может переходить за время прохождения каждого бита. Например, если состояние кодера — 00, при следующем смещении возможно возникновение только состояний 00 или 10.
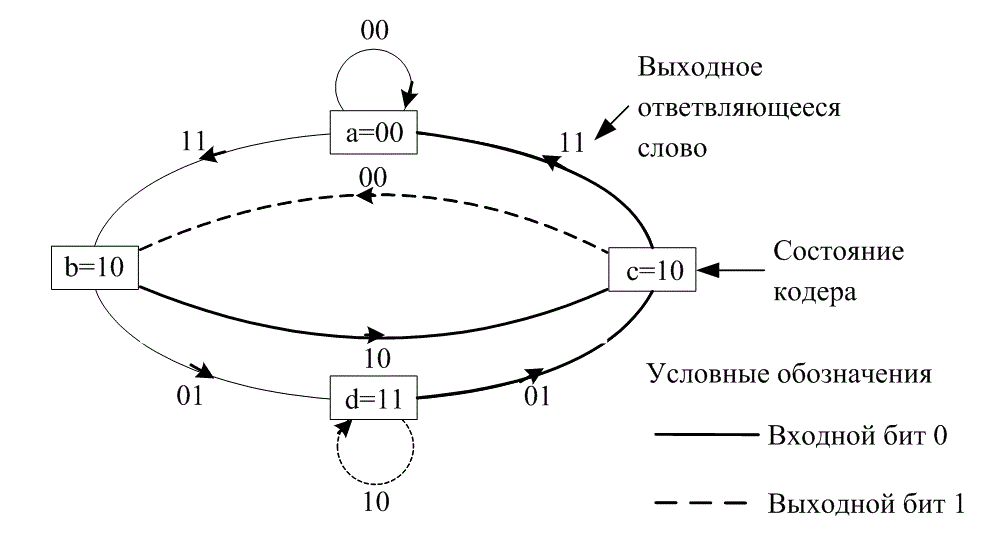
Рис. 7.5. Диаграмма состояний кодера (степень кодирования 1/2, К= 3)
Пример 7.1. Сверточное кодирование
Для кодера, показанного на рис. 7.3, найдите изменение состояний и результирующую последовательность кодовых слов U для последовательности сообщений m = 1 1 0 1 1, за которой следует ![]() нуля для очистки регистра. Предполагается, что в исходном состоянии регистр содержит одни нули.
нуля для очистки регистра. Предполагается, что в исходном состоянии регистр содержит одни нули.
Решение
Ответвляющееся слово в момент времени (![]() )
)
|
Ответвляющееся слово в момент времени |
|||||
| Входные Биты, |
Содержимое регистра | Состояние в момент времени |
Состояние в момент времени |
||
| - | 000 | 00 | 00 | - | |
| 1 | 100 | 00 | 10 | 1 | 1 |
| 1 | 110 | 10 | 11 | 0 | 1 |
| 0 | 011 | 11 | 01 | 0 | 1 |
| 1 | 101 | 01 | 10 | 0 | 1 |
| 1 | 110 | 10 | 11 | 0 | 1 |
| 0 | 011 | 11 | 01 | 0 | 1 |
| 0 | 0 |
01 | 00 | 1 | 1 |
![]() Последовательность на выходе U= 11 01 01 00 01 01 11
Последовательность на выходе U= 11 01 01 00 01 01 11
Пример 7.2. Сверточное кодирование
В примере 7.1 исходное содержимое регистра — все нули. Это эквивалентно тому, что данной последовательности на входе предшествовали два нулевых бита (кодирование является функцией настоящих информационных бит и K - 1 предыдущих бит). Повторите задание примера 7.1, предполагая, что данной последовательности предшествовали два единичных бита, и убедитесь, что теперь последовательность кодовых слов U для входящей последовательности т = 1 1 0 1 1 отличается от последовательности, найденной в примере 7.1.
Решение Запись "х" обозначает "неизвестно".
Ответвляющееся слово в момент времени (![]() )
)
|
Ответвляющееся слово в момент времени |
|||||
| Входные Биты, |
Содержимое регистра | Состояние в момент времени |
Состояние в момент времени |
||
| - | 11 |
1 |
11 | - | |
| 1 | 111 | 11 | 11 | 1 | 0 |
| 1 | 111 | 11 | 11 | 1 | 0 |
| 0 | 011 | 11 | 01 | 0 | 1 |
| 1 | 101 | 01 | 10 | 0 | 0 |
| 1 | 110 | 10 | 11 | 0 | 1 |
| 0 | 011 | 11 | 01 | 0 | 1 |
| 0 | 0 |
01 | 00 | 1 | 1 |
![]()
Последовательность на выходе U= 10 10 01 00 01 01 11
Сравнивая эти результаты с результатами из примера 7.1, можно видеть, что каждое ответвленное слово выходной последовательности U является функцией не только входного бита, но и предыдущих ![]() бит.
бит.
7.2.3. Древовидные диаграммы
Несмотря на то что диаграммы состояний полностью описывают кодер, по сути, их нельзя использовать для легкого отслеживания переходов кодера в зависимости от времени, поскольку диаграмма не представляет динамики изменений. Древовидная диаграмма (tree diagram) прибавляет к диаграмме состояния временное измерение. Древовидная диаграмма сверточного кодера, показанного на рис. 7.3, изображена на рис. 7.6. В каждый последующий момент прохождения входящего бита процедура кодирования может быть описана с помощью перемещения по диаграмме слева направо, причем каждая ветвь дерева описывает ответвленное слово на выходе. Правило ветвления для нахождения последовательности кодовых слов следующее: если входящим битом является нуль, то он связывается со словом, которое находится путем перемещения в следующую (по направлению вверх) крайнюю правую ветвь; если входящий бит — это единица, то ответвленное слово находится путем перемещения в следующую (по направлению вниз) крайнюю правую ветвь. Предполагается, что первоначально кодер содержал одни нули. Диаграмма показывает, что если первым входным битом был нуль, то ответвляющимся словом на выходе будет 00, а если первым входным битом была единица, то ответвляющимся словом на выходе будет 11. Аналогично, если первым входным битом была единица, а вторым — нуль, на выходе вторым ответвляющимся словом будет 10. Если первым входным видом была единица и вторым входным битом была единица, вторым ответвляющимся словом на выходе будет 01. Следуя этой процедуре, видим, что входящая последовательность 11011 представляется жирной линией, нарисованной на древовидной диаграмме (рис. 7.6). Этот путь соответствует выходной последовательности кодовых слов 1101010001. Дополнительное временное измерение в древовидной диаграмме (по сравнению с диаграммой состояния) допускает динамическое описание кодера как функции конкретной входной последовательности. Однако заметили ли вы, что при попытке описания с помощью древовидной диаграммы последовательности произвольной длины возникает проблема? Число ответвлений растет как ![]() , где L — это количество ответвляющихся слов в последовательности. При большом L вы бы очень быстро исписали бумагу и исчерпали терпение.
, где L — это количество ответвляющихся слов в последовательности. При большом L вы бы очень быстро исписали бумагу и исчерпали терпение.
7.2.4. Решетчатая диаграмма
Исследование древовидной диаграммы на рис. 7.6 показывает, что в этом примере после третьего ветвления в момент времени г4 структура повторяется (древовидная структура повторяется после К ответвлений, где К — длина кодового ограничения). Пометим каждый узел в дереве (рис. 7.6), ставя в соответствие четыре возможных состояния в регистре сдвига: а =00, b = 10, с = 01 и d = 11. Первое ветвление древовидной структуры в момент времени ![]() дает пару узлов, помеченных как а и b. При каждом последующем ветвлении количество узлов удваивается. Второе ветвление в момент времени
дает пару узлов, помеченных как а и b. При каждом последующем ветвлении количество узлов удваивается. Второе ветвление в момент времени ![]() дает в результате четыре узла, помеченных как а, b, c и d. После третьего ветвления всего имеется восемь узлов: два — а, два — b, два — с и два — d.
дает в результате четыре узла, помеченных как а, b, c и d. После третьего ветвления всего имеется восемь узлов: два — а, два — b, два — с и два — d.
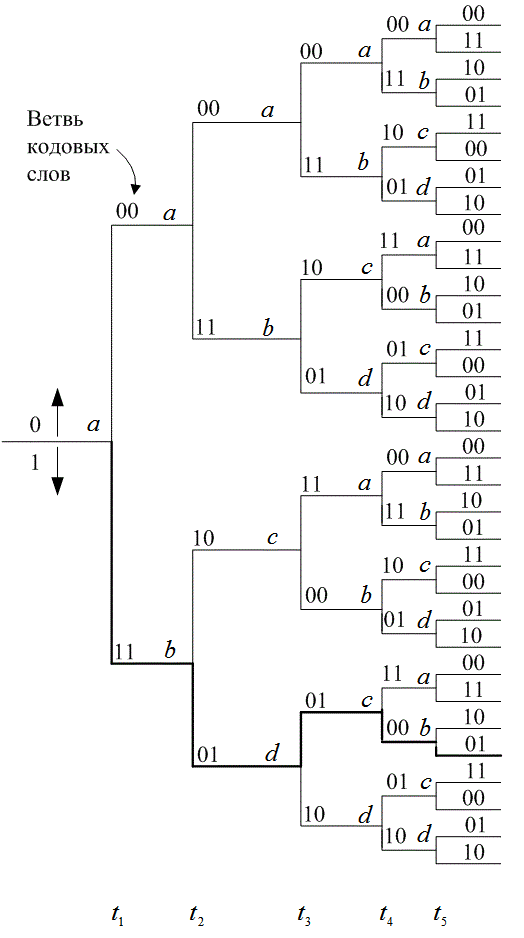
Рис. 7.6. Древовидное представление кодера (степень кодирования 1/2, К = 3)
Можно видеть, что все ветви выходят из двух узлов одного и того же состояния, образуя идентичные ветви последовательностей кодовых слов. В этот момент дерево делится на идентичные верхнюю и нижнюю части. Смысл этого становится яснее после рассмотрения кодера, изображенного на рис. 7.3. Когда четвертый входной бит входит в кодер слева, первый входной бит справа выбрасывается и больше не влияет на ответвленные слова на выходе. Следовательно, входящие последовательности 1 0 0 х у... и 0 0 0х у..., где крайний левый бит является самым ранним, после (К = 3)-го ветвления генерируют одинаковые ответвляющиеся слова. Это означает, что любые состояния, имеющие одинаковую метку в один и тот же момент ![]() , можно соединить, поскольку все последующие пути будут неразличимы. Если мы проделаем это для древовидной структуры, показанной на рис. 7.6, получим иную диаграмму, называемую решетчатой. Решетчатая диаграмма, которая использует повторяющуюся структуру, дает более удобное описание кодера, по сравнению с древовидной диаграммой. Решетчатая диаграмма для сверточного кодера, изображенного на рис. 7.3, показана на рис. 7.7
, можно соединить, поскольку все последующие пути будут неразличимы. Если мы проделаем это для древовидной структуры, показанной на рис. 7.6, получим иную диаграмму, называемую решетчатой. Решетчатая диаграмма, которая использует повторяющуюся структуру, дает более удобное описание кодера, по сравнению с древовидной диаграммой. Решетчатая диаграмма для сверточного кодера, изображенного на рис. 7.3, показана на рис. 7.7
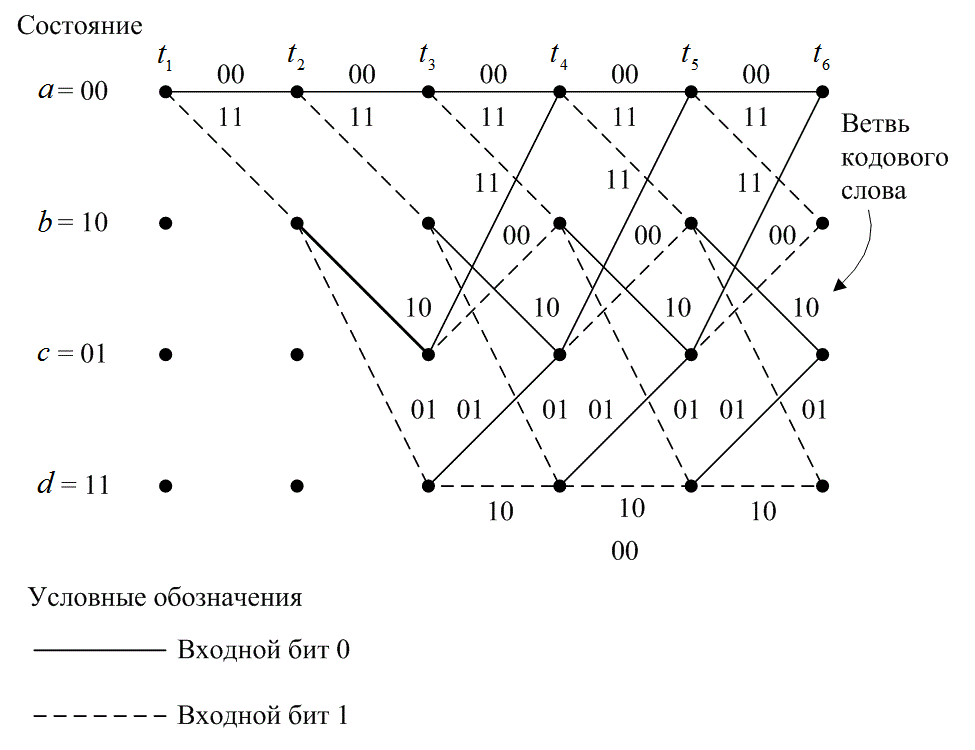
Рис. 7.7. Решетчатая диаграмма кодера (степень кодирования 1/2, К = 3)
При изображении решетчатой диаграммы мы воспользовались теми же условными обозначениями, что и для диаграммы состояния: сплошная линия обозначает выходные данные, генерируемые входным нулевым битом, а пунктирная — выходные данные, генерируемые входным единичным битом. Узлы решетки представляют состояния кодера; первый ряд узлов соответствует состоянию а = 00, второй и последующие — состояниям a = 00, b = 10, с = 01 и d = 11. В каждый момент времени для представления ![]() возможных состояний кодера решетка требует
возможных состояний кодера решетка требует ![]() узлов. В нашем примере после достижения глубины решетки, равной трем (в момент времени
узлов. В нашем примере после достижения глубины решетки, равной трем (в момент времени ![]() ), замечаем, что решетка имеет фиксированную периодическую структуру. В общем случае фиксированная структура реализуется после достижения глубины K. Следовательно, с этого момента в каждое состояние можно войти из любого из двух предыдущих состояний. Также из каждого состояния можно перейти в одно из двух состояний. Из двух исходящих ветвей одна соответствует нулевому входному биту, а другая — единичному входному биту. На рис. 7.7 ответвляющиеся слова на выходе соответствуют переходам, между состояниями, показанными как метки на ветвях решетки.
), замечаем, что решетка имеет фиксированную периодическую структуру. В общем случае фиксированная структура реализуется после достижения глубины K. Следовательно, с этого момента в каждое состояние можно войти из любого из двух предыдущих состояний. Также из каждого состояния можно перейти в одно из двух состояний. Из двух исходящих ветвей одна соответствует нулевому входному биту, а другая — единичному входному биту. На рис. 7.7 ответвляющиеся слова на выходе соответствуют переходам, между состояниями, показанными как метки на ветвях решетки.
Один столбец временного интервала сформировавшейся решетчатой структуры кодирования полностью определяет код. Несколько столбцов показаны исключительно для визуализации последовательности кодовых символов как функции времени. Состояние сверточного кодера представлено содержанием крайних правых ![]() разрядов в регистре кодера. Некоторые авторы описывают состояние с помощью крайних левых
разрядов в регистре кодера. Некоторые авторы описывают состояние с помощью крайних левых ![]() разрядов. Какое описание правильно? Они оба верны. Каждый переход имеет начальное и конечное состояние. Крайние правые
разрядов. Какое описание правильно? Они оба верны. Каждый переход имеет начальное и конечное состояние. Крайние правые ![]() разрядов описывают начальное состояние для текущих входных данных, которые находятся в крайнем левом разряде (степень кодирования предполагается равной 1/n). Крайние левые
разрядов описывают начальное состояние для текущих входных данных, которые находятся в крайнем левом разряде (степень кодирования предполагается равной 1/n). Крайние левые ![]() разрядов являются конечным состоянием для такого перехода. Последовательность кодовых символов характеризуется N ветвями (что представляет N бит данных), занимающими N интервалов времени. Она связана с конкретным состоянием в каждый из N + 1 интервалов времени (от начала до конца). Таким образом, мы запускаем биты в моменты времени
разрядов являются конечным состоянием для такого перехода. Последовательность кодовых символов характеризуется N ветвями (что представляет N бит данных), занимающими N интервалов времени. Она связана с конкретным состоянием в каждый из N + 1 интервалов времени (от начала до конца). Таким образом, мы запускаем биты в моменты времени ![]() и интересуемся метрикой состояния в моменты времени
и интересуемся метрикой состояния в моменты времени ![]()
![]() . Здесь использовано следующее условие: текущий бит располагается в крайнем левом разряде, а крайние правые
. Здесь использовано следующее условие: текущий бит располагается в крайнем левом разряде, а крайние правые ![]() разрядов стартуют из состояния со всеми нулями. Этот момент времени обозначим как начальное время,
разрядов стартуют из состояния со всеми нулями. Этот момент времени обозначим как начальное время, ![]() . Время завершения последнего перехода обозначим как время прекращения работы,
. Время завершения последнего перехода обозначим как время прекращения работы, ![]() .
.
7.3. Формулировка задачи сверточного кодирования
7.3.1. Декодирование по методу максимального правдоподобия
Если все входные последовательности сообщений равновероятны, минимальная вероятность ошибки получается при использовании декодера, который сравнивает условные вероятности и выбирает максимальную. Условные вероятности также называют функциями правдоподобия![]() , где Z — это принятая последовательность, а
, где Z — это принятая последовательность, а ![]() — одна из возможных переданных последовательностей. Декодер выбирает
— одна из возможных переданных последовательностей. Декодер выбирает ![]() , если
, если
![]()
![]()
по всем ![]() .
.
Принцип максимального правдоподобия, определяемый уравнением (7.1), является фундаментальным достижением теории принятия решений (см. приложение Б); это формализация способа принятия решений, основанного на "здравом смысле", когда имеются статистические данные о вероятностях. При рассмотрении двоичной демодуляции в главах 3 и 4, предполагалась передача только двух равновероятных сигналов ![]() и
и ![]() . Следовательно, принятие двоичного решения на основе принципа максимального правдоподобия, касающееся данного полученного сигнала, означает, что в качестве переданного сигнала выбирается
. Следовательно, принятие двоичного решения на основе принципа максимального правдоподобия, касающееся данного полученного сигнала, означает, что в качестве переданного сигнала выбирается ![]() , если
, если
![]() .
.
В противном случае считается, что передан был сигнал ![]() . Параметр z представляет собой величину
. Параметр z представляет собой величину ![]() , значение принятого сигнала до детектирования в конце каждого периода передачи символа t = Т. Однако при использовании принципа максимального правдоподобия в задаче сверточного декодирования, в сверточном коде обнаруживается наличие памяти (полученная последовательность является суперпозицией текущих и предыдущих двоичных разрядов). Таким образом, применение принципа максимального правдоподобия при декодировании бит данных, закодированных сверточным кодом, осуществляется в контексте выбора наиболее вероятной последовательности, как показано в уравнении (7.1). Обычно имеется множество возможных переданных последовательностей кодовых слов. Что касается двоичного кода, то последовательность из L ответвленных слов является членом набора из
, значение принятого сигнала до детектирования в конце каждого периода передачи символа t = Т. Однако при использовании принципа максимального правдоподобия в задаче сверточного декодирования, в сверточном коде обнаруживается наличие памяти (полученная последовательность является суперпозицией текущих и предыдущих двоичных разрядов). Таким образом, применение принципа максимального правдоподобия при декодировании бит данных, закодированных сверточным кодом, осуществляется в контексте выбора наиболее вероятной последовательности, как показано в уравнении (7.1). Обычно имеется множество возможных переданных последовательностей кодовых слов. Что касается двоичного кода, то последовательность из L ответвленных слов является членом набора из ![]() возможных последовательностей. Следовательно, в контексте максимального правдоподобия можно сказать, что в качестве переданной последовательности декодер выбирает
возможных последовательностей. Следовательно, в контексте максимального правдоподобия можно сказать, что в качестве переданной последовательности декодер выбирает ![]() , если вероятность
, если вероятность ![]() больше вероятности всех остальных возможно переданных последовательностей. Такой оптимальный декодер, минимизирующий вероятность ошибки (когда все переданные последовательности равновероятны), известен как декодер, работающий по принципу максимального правдоподобия (maximum likelihood detector). Функция правдоподобия задается или вычисляется, исходя из спецификации канала.
больше вероятности всех остальных возможно переданных последовательностей. Такой оптимальный декодер, минимизирующий вероятность ошибки (когда все переданные последовательности равновероятны), известен как декодер, работающий по принципу максимального правдоподобия (maximum likelihood detector). Функция правдоподобия задается или вычисляется, исходя из спецификации канала.
Предположим, что мы имеем дело с аддитивным белым гауссовым шумом с нулевым средним в канале без памяти, т.е. шум влияет на каждый символ кода независимо от остальных символов. При степени кодирования сверточного кода, равной 1/n, правдоподобие можно выразить следующим образом.
![]() (7.2)
(7.2)
Здесь ![]() — это
— это ![]() -я ветвь полученной последовательности
-я ветвь полученной последовательности ![]() ,
,![]() — это ветвь отдельной последовательности кодовых слов
— это ветвь отдельной последовательности кодовых слов![]() — это
— это ![]() й кодовый символ
й кодовый символ ![]() , а каждая ветвь состоит из n кодовых символов. Задача декодирования заключается в выборе пути сквозь решетку, показанную на рис. 7.7 (каждый возможный путь определяет последовательность кодовых слов), аким образом, чтобы произведение
, а каждая ветвь состоит из n кодовых символов. Задача декодирования заключается в выборе пути сквозь решетку, показанную на рис. 7.7 (каждый возможный путь определяет последовательность кодовых слов), аким образом, чтобы произведение
![]() (7.3)
(7.3)
Как правило, при вычислениях удобнее пользоваться логарифмом функции правдоподобия, поскольку это позволяет произведение заменить суммированием. Мы можем воспользоваться таким преобразованием, поскольку логарифм является монотонно возрастающей функцией и, следовательно, не внесет изменений в выбор окончательного кодового слова. Логарифмическую функцию правдоподобия можно определить следующим образом.
![]() (7.4)
(7.4)
Теперь задача декодирования заключается в выборе пути вдоль дерева на рис. 7.6 или решетки на рис. 7.7 таким образом, чтобы ![]() было максимальным. При декодировании сверточных кодов можно использовать как древовидную, так и решетчатую структуру. При древовидном представлении кода игнорируется то, что пути снова объединяются. Для двоичного кода количество возможных последовательностей, состоящих из L ответвленных слов, равно
было максимальным. При декодировании сверточных кодов можно использовать как древовидную, так и решетчатую структуру. При древовидном представлении кода игнорируется то, что пути снова объединяются. Для двоичного кода количество возможных последовательностей, состоящих из L ответвленных слов, равно ![]() . Поэтому декодирование полученных последовательностей, основанное на принципе максимального правдоподобия с использованием древовидной диаграммы, требует метода "грубой силы" или исчерпывающего сопоставления
. Поэтому декодирование полученных последовательностей, основанное на принципе максимального правдоподобия с использованием древовидной диаграммы, требует метода "грубой силы" или исчерпывающего сопоставления ![]() накопленных логарифмических метрик правдоподобия, описывающих все варианты возможных последовательностей кодовых слов. Поэтому рассматривать декодирование на основе принципа максимального правдоподобия с помощью древовидной структуры практически невозможно. В предыдущем разделе было показано, что при решетчатом представлении кода декодер можно построить так, чтобы можно было отказываться от путей, которые не могут быть кандидатами на роль максимально правдоподобной последовательности. Путь декодирования выбирается из некоего сокращенного набора выживших путей. Такой декодер тем не менее является оптимальным; в том смысле, что путь декодирования такой же, как и путь, полученный с помощью декодера критерия максимального правдоподобия, действующего "грубой силой", однако предварительный отказ от неудачных путей снижает сложность декодирования.
накопленных логарифмических метрик правдоподобия, описывающих все варианты возможных последовательностей кодовых слов. Поэтому рассматривать декодирование на основе принципа максимального правдоподобия с помощью древовидной структуры практически невозможно. В предыдущем разделе было показано, что при решетчатом представлении кода декодер можно построить так, чтобы можно было отказываться от путей, которые не могут быть кандидатами на роль максимально правдоподобной последовательности. Путь декодирования выбирается из некоего сокращенного набора выживших путей. Такой декодер тем не менее является оптимальным; в том смысле, что путь декодирования такой же, как и путь, полученный с помощью декодера критерия максимального правдоподобия, действующего "грубой силой", однако предварительный отказ от неудачных путей снижает сложность декодирования.
В качестве великолепного пособия для изучения структуры сверточных кодов, декодирования на основе критерия максимального правдоподобия и реализации кода можно порекомендовать работу [8]. Существует несколько алгоритмов, которые дают приблизительные решения задачи декодирования на основе критерия максимального правдоподобия, включая последовательный [9, 10] и пороговый [11]. Каждый из этих алгоритмов является подходящим для узкоспециальных задач; однако все они близки к оптимальному. Алгоритм декодирования Витерби, напротив, осуществляет декодирование на основе критерия максимального правдоподобия и, следовательно, является оптимальным. Это не означает, что алгоритм Витерби в любой реализации является наилучшим; при его использовании существуют жесткие условия, налагаемые на аппаратное обеспечение.
7.3.2. Модели каналов: мягкое или жесткое принятие решений
Перед тем как начать разговор об алгоритме, который задает схему принятия максимально правдоподобного решения, давайте сначала опишем канал. Последовательность кодовых слов ![]() , определяемую ответвленными словами, каждое из которых состоит из n кодовых символов, можно рассматривать как бесконечный поток, в отличие от блочного кода, где исходные данные и их кодовые слова делятся на блоки строго определенного размера. Последовательность кодовых слов, показанная на рис. 7.1, выдается сверточным кодером и подается на модулятор, где кодовые символы преобразуются в сигналы. Модуляция может быть узкополосной (например, модуляция импульсными сигналами) или полосовой (например, модуляция PSK или FSK). Вообще, за такт в сигнал
, определяемую ответвленными словами, каждое из которых состоит из n кодовых символов, можно рассматривать как бесконечный поток, в отличие от блочного кода, где исходные данные и их кодовые слова делятся на блоки строго определенного размера. Последовательность кодовых слов, показанная на рис. 7.1, выдается сверточным кодером и подается на модулятор, где кодовые символы преобразуются в сигналы. Модуляция может быть узкополосной (например, модуляция импульсными сигналами) или полосовой (например, модуляция PSK или FSK). Вообще, за такт в сигнал ![]() преобразуется l символов, где l — целое, причем i = 1, 2,…, a
преобразуется l символов, где l — целое, причем i = 1, 2,…, a ![]() . Если l = 1, модулятор преобразует каждый кодовый символ в двоичный сигнал. Предполагается, что канал, по которому передается сигнал, искажает сигнал гауссовым шумом. После того как искаженный сигнал принят, он сначала обрабатывается демодулятором, а затем подается на декодер.
. Если l = 1, модулятор преобразует каждый кодовый символ в двоичный сигнал. Предполагается, что канал, по которому передается сигнал, искажает сигнал гауссовым шумом. После того как искаженный сигнал принят, он сначала обрабатывается демодулятором, а затем подается на декодер.
Рассмотрим ситуацию, когда двоичный сигнал передается за отрезок времени (0, Т), причем двоичная единица представляется сигналом ![]() , а двоичный нуль — сигналом
, а двоичный нуль — сигналом ![]() . Принятый сигнал имеет вид
. Принятый сигнал имеет вид ![]() , где n(t) представляет собой вклад гауссового шума с нулевым средним. В главе 3 мы описывали обнаружение
, где n(t) представляет собой вклад гауссового шума с нулевым средним. В главе 3 мы описывали обнаружение ![]() в два основных этапа. На первом этапе принятый сигнал переводится в число
в два основных этапа. На первом этапе принятый сигнал переводится в число ![]() , где
, где ![]() — это компонент сигнала z(T), a
— это компонент сигнала z(T), a ![]() — компонент шума. Компонент шума п0 — это случайная переменная, значения которой имеют гауссово распределение с нулевым средним. Следовательно,
— компонент шума. Компонент шума п0 — это случайная переменная, значения которой имеют гауссово распределение с нулевым средним. Следовательно, ![]() также будет случайной гауссовой величиной со средним
также будет случайной гауссовой величиной со средним ![]() или
или ![]() , в зависимости от того, какая величина была отправлена — двоичная единица или двоичный нуль. На втором этапе процесса обнаружения принимается решение о том, какой сигнал был передан. Это решение принимается на основе сравнения z(T) с порогом. Условные вероятности
, в зависимости от того, какая величина была отправлена — двоичная единица или двоичный нуль. На втором этапе процесса обнаружения принимается решение о том, какой сигнал был передан. Это решение принимается на основе сравнения z(T) с порогом. Условные вероятности ![]() , показанные на рис. 7.8, обозначены как правдоподобие
, показанные на рис. 7.8, обозначены как правдоподобие ![]() и
и ![]() . Демодулятор, представленный на рис. 7.1, преобразует упорядоченный по времени набор случайных переменных
. Демодулятор, представленный на рис. 7.1, преобразует упорядоченный по времени набор случайных переменных ![]() в кодовую последовательность Z и подает ее на декодер. Выход демодулятора можно настроить по-разному. Можно реализовать его в виде жесткой схемы принятия решений относительно того, представляет ли z(T) единицу или нуль. В этом случае выход демодулятора квантуется на два уровня, нулевой и единичный, и соединяется с декодером (это абсолютно та же схема пороговых решений, о которой шла речь в главах 3 и 4). Поскольку декодер работает в режиме жесткой схемы принятия решений, принятых демодулятором, такое декодирование называется жестким.
в кодовую последовательность Z и подает ее на декодер. Выход демодулятора можно настроить по-разному. Можно реализовать его в виде жесткой схемы принятия решений относительно того, представляет ли z(T) единицу или нуль. В этом случае выход демодулятора квантуется на два уровня, нулевой и единичный, и соединяется с декодером (это абсолютно та же схема пороговых решений, о которой шла речь в главах 3 и 4). Поскольку декодер работает в режиме жесткой схемы принятия решений, принятых демодулятором, такое декодирование называется жестким.
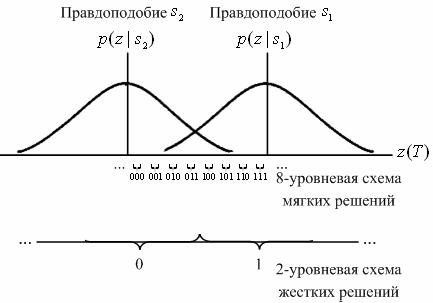
Рис. 7.8. Жесткая и мягкая схемы декодирования
Аналогично демодулятор можно настроить так, чтобы он подавал на декодер значение z(T), квантованное более чем на два уровня. Такая схема обеспечивает декодер большим количеством информации, чем жесткая схема решений. Если выход демодулятора имеет более двух уровней квантования, то декодирование называется мягким. На рис. 7.8 на оси абсцисс изображено восемь (3-битовых) уровней квантования. Если в демодуляторе реализована жесткая схема принятия двоичных решений, он отправляет на декодер только один двоичный символ. Если в демодуляторе реализована мягкая двоичная схема принятия решений, квантованная на восемь уровней, он отправляет на декодер 3-битовое слово, описывающее интервал, соответствующий ![]() . По сути, поступление такого 3-битового слова, вместо одного двоичного символа эквивалентно передаче декодеру меры достоверности вместе с решением относительно кодового символа. Согласно рис. 7.8, если с демодулятора поступила на декодер последовательность 111, это равносильно утверждению, что с очень высокой степенью достоверности кодовым символом была 1, в то время как переданная последовательность 100 равносильна утверждению, что с очень низкой степенью достоверности кодовым символом была 1. Совершенно ясно, что в конечном счете каждое решение, принятое декодером и касающееся сообщения, должно быть жестким; в противном случае на распечатках компьютера можно было бы увидеть нечто, подобное следующему: "думаю, это 1", "думаю, это 0" и т.д. То, что после демодулятора не принимается жесткое решение и на декодер поступает больше данных (мягкое принятие решений), можно понимать как промежуточный этап, необходимый для того, чтобы на декодер поступило больше информации, с помощью которой он затем сможет восстановить последовательность сообщения (с более высокой достоверностью передачи сообщения по сравнению с декодированием в рамках жесткой схемы принятия решений). Показанная на рис. 7.8, 8-уровневая метрика мягкой схемы принятия решений часто обозначается как -7, -5, -3, -1, 1, 3, 5, 7. Такие обозначения вводятся для простоты интерпретации мягкой схемы принятия решения. Знак метрики характеризует решение (например, выбирается
. По сути, поступление такого 3-битового слова, вместо одного двоичного символа эквивалентно передаче декодеру меры достоверности вместе с решением относительно кодового символа. Согласно рис. 7.8, если с демодулятора поступила на декодер последовательность 111, это равносильно утверждению, что с очень высокой степенью достоверности кодовым символом была 1, в то время как переданная последовательность 100 равносильна утверждению, что с очень низкой степенью достоверности кодовым символом была 1. Совершенно ясно, что в конечном счете каждое решение, принятое декодером и касающееся сообщения, должно быть жестким; в противном случае на распечатках компьютера можно было бы увидеть нечто, подобное следующему: "думаю, это 1", "думаю, это 0" и т.д. То, что после демодулятора не принимается жесткое решение и на декодер поступает больше данных (мягкое принятие решений), можно понимать как промежуточный этап, необходимый для того, чтобы на декодер поступило больше информации, с помощью которой он затем сможет восстановить последовательность сообщения (с более высокой достоверностью передачи сообщения по сравнению с декодированием в рамках жесткой схемы принятия решений). Показанная на рис. 7.8, 8-уровневая метрика мягкой схемы принятия решений часто обозначается как -7, -5, -3, -1, 1, 3, 5, 7. Такие обозначения вводятся для простоты интерпретации мягкой схемы принятия решения. Знак метрики характеризует решение (например, выбирается ![]() , если величина положительна, и
, если величина положительна, и ![]() , если отрицательна), а величина метрики описывает степень достоверности этого решения. Преимуществом метрики, показанной на рис. 7.8, является только то, что в ней не используются отрицательные числа.
, если отрицательна), а величина метрики описывает степень достоверности этого решения. Преимуществом метрики, показанной на рис. 7.8, является только то, что в ней не используются отрицательные числа.
Для гауссова канала восьмиуровневое квантование, по сравнению с двухуровневым, приводит в результате к улучшению на 2 дБ требуемого отношения сигнал/шум. Это означает, что восьмиуровневое квантование с мягкой схемой принятия решений может дать ту же вероятность появления ошибочного бита, что и декодирование с жесткой схемой принятия решений, однако требует на 2 дБ меньшего значения ![]() при прочих равных характеристиках. Аналоговое квантование (или квантование с бесконечным числом уровней) дает в результате улучшение на 2,2 дБ, по сравнению с двухуровневым; следовательно, при восьмиуровневом квантовании, по сравнению с квантованием с бесконечным числом уровней, теряется приблизительно 0,2 дБ. По этой причине квантование более чем на восемь уровней может дать только небольшое улучшение производительности [12]. Какова цена, которую следует заплатить за такое улучшение параметров декодирования с мягкой схемой принятия решений? В случае декодирования с жесткой схемой принятия решений, для описания каждого кодового символа используется один бит, в то время как при восьмиуровневой мягкой схеме принятия решения для описания каждого символа применяется 3 бит; следовательно, в течение процесса декодирования нужно успеть обработать в три раза больше данных. Поэтому за мягкое декодирование приходится платить увеличением требуемых объемов памяти (и, возможно, возникнут проблемы со скоростью обработки).
при прочих равных характеристиках. Аналоговое квантование (или квантование с бесконечным числом уровней) дает в результате улучшение на 2,2 дБ, по сравнению с двухуровневым; следовательно, при восьмиуровневом квантовании, по сравнению с квантованием с бесконечным числом уровней, теряется приблизительно 0,2 дБ. По этой причине квантование более чем на восемь уровней может дать только небольшое улучшение производительности [12]. Какова цена, которую следует заплатить за такое улучшение параметров декодирования с мягкой схемой принятия решений? В случае декодирования с жесткой схемой принятия решений, для описания каждого кодового символа используется один бит, в то время как при восьмиуровневой мягкой схеме принятия решения для описания каждого символа применяется 3 бит; следовательно, в течение процесса декодирования нужно успеть обработать в три раза больше данных. Поэтому за мягкое декодирование приходится платить увеличением требуемых объемов памяти (и, возможно, возникнут проблемы со скоростью обработки).
В настоящее время существуют блочные и сверточные алгоритмы декодирования, функционирующие на основе жесткой или мягкой схемы принятия решений. Однако при блочном декодировании мягкая схема принятия решений, как правило, не используется, поскольку ее значительно сложнее реализовать, чем схему жесткого принятия решений. Чаще всего мягкая схема принятия решений применяется в алгоритме сверточного декодирования Витерби, поскольку при декодировании Витерби мягкое принятие решений лишь незначительно усложняет вычисления.
7.3.2.1. Двоичный симметричный канал
Двоичный симметричный канал (binary symmetric channel - BSC) — это дискретный канал без памяти (см. раздел 6.3.1), имеющий на входе и выходе двоичный алфавит и симметричные вероятности перехода. Как показано на рис. 7.9, его можно описать с помощью условных вероятностей.
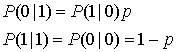 (7.5)
(7.5)
Вероятность того, что выходной символ будет отличаться от входного, равна р, а вероятность того, что выходной символ будет идентичен входному, равна (1 -р). Канал BSC является примером канала с жесткой схемой принятия решений; это, в свою очередь, означает, что даже если демодулятор получил сигнал с непрерывным значением, BSC позволяет принять только какое-то одно определенное решение, так что каждый символ ![]() на выходе демодулятора, как показано на рис. 7.1, содержит одно из двух двоичных значений. Индексы величины
на выходе демодулятора, как показано на рис. 7.1, содержит одно из двух двоичных значений. Индексы величины ![]() указывают на j-й кодовый символ i-го ответвленного слова
указывают на j-й кодовый символ i-го ответвленного слова ![]() . Далее демодулятор передает последовательность
. Далее демодулятор передает последовательность ![]() Z={Z,} на декодер.
Z={Z,} на декодер.
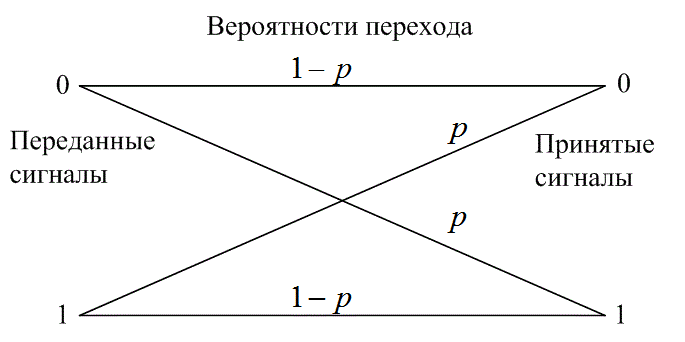
Рис. 7.9. Двоичный симметричный канал (канал с жесткой схемой принятия решений)
Пусть ![]() — это переданное по каналу BSC кодовое слово с вероятностью появления ошибочного символа р, Z - соответствующая последовательность, полученная декодером. Как отмечалось ранее, декодер, работающий по принципу максимального правдоподобия, выбирает кодовое слово
— это переданное по каналу BSC кодовое слово с вероятностью появления ошибочного символа р, Z - соответствующая последовательность, полученная декодером. Как отмечалось ранее, декодер, работающий по принципу максимального правдоподобия, выбирает кодовое слово ![]() , имеющее максимальное правдоподобие
, имеющее максимальное правдоподобие ![]() или его логарифм. Для BSC это эквивалентно выбору кодового слова
или его логарифм. Для BSC это эквивалентно выбору кодового слова ![]() находящегося на наименьшем расстоянии Хэмминга от Z [8]. Расстояние Хэмминга — это удобная метрика для описания расстояния или степени сходства между
находящегося на наименьшем расстоянии Хэмминга от Z [8]. Расстояние Хэмминга — это удобная метрика для описания расстояния или степени сходства между ![]() и Z. Из всех возможных переданных последовательностей
и Z. Из всех возможных переданных последовательностей ![]() декодер выбирает такую последовательность
декодер выбирает такую последовательность ![]() , для которой расстояние до Z минимально. Предположим, что каждая из последовательностей
, для которой расстояние до Z минимально. Предположим, что каждая из последовательностей ![]() и Z имеет длину L бит и отличается на dm позиций (т.е. расстояние Хэмминга между
и Z имеет длину L бит и отличается на dm позиций (т.е. расстояние Хэмминга между ![]() и Z равно dm). Тогда, поскольку предполагалось, что канал не имеет памяти, вероятность того, что
и Z равно dm). Тогда, поскольку предполагалось, что канал не имеет памяти, вероятность того, что ![]() преобразовалось в Z, находящееся на расстоянии dm от
преобразовалось в Z, находящееся на расстоянии dm от ![]() может быть записана в следующем виде.
может быть записана в следующем виде.
![]() (7.6)
(7.6)
Логарифмическая функция правдоподобия будет иметь следующий вид.
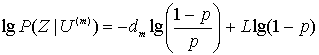 (7.7)
(7.7)
Если вычислить эту величину для каждой возможно переданной последовательности, последнее слагаемое в уравнении будет постоянным для всех случаев. Если предположить, что ![]() , уравнение (7.7) можно записать в следующей форме.
, уравнение (7.7) можно записать в следующей форме.
![]() (7.8)
(7.8)
Здесь А и В — положительные константы. Следовательно, такой выбор кодового слова ![]() , чтобы расстояние Хэмминга до полученной последовательности Z было минимальным, соответствует максимизации метрики правдоподобия или логарифма правдоподобия. Следовательно, в канале BSC метрика логарифма правдоподобия легко заменяется расстоянием Хэмминга, а декодер, работающий по принципу максимального правдоподобия, будет выбирать на древовидной или решетчатой диаграмме путь, соответствующий минимальному расстоянию Хэмминга между последовательностью
, чтобы расстояние Хэмминга до полученной последовательности Z было минимальным, соответствует максимизации метрики правдоподобия или логарифма правдоподобия. Следовательно, в канале BSC метрика логарифма правдоподобия легко заменяется расстоянием Хэмминга, а декодер, работающий по принципу максимального правдоподобия, будет выбирать на древовидной или решетчатой диаграмме путь, соответствующий минимальному расстоянию Хэмминга между последовательностью ![]() и полученной последовательностью Z.
и полученной последовательностью Z.
7.3.2.2. Гауссов канал
Для гауссова канала каждый выходной символ демодулятора ![]() , как показано на рис. 7.1, принимает значения из непрерывного алфавита. Символ
, как показано на рис. 7.1, принимает значения из непрерывного алфавита. Символ ![]() нельзя пометить для обнаружения как правильное или неправильное решение. Передачу на декодер таких мягких решений можно рассматривать как поступление семейства условных вероятностей различных символов (см. раздел 6.3.1). Можно показать [8], что максимизация
нельзя пометить для обнаружения как правильное или неправильное решение. Передачу на декодер таких мягких решений можно рассматривать как поступление семейства условных вероятностей различных символов (см. раздел 6.3.1). Можно показать [8], что максимизация ![]() эквивалентна максимизации скалярного произведения последовательности кодовых слов
эквивалентна максимизации скалярного произведения последовательности кодовых слов ![]() (состоящей из двоичных символов, представленных как биполярные значения) и аналогового значения полученной последовательности Z. Таким образом, декодер выбирает кодовое слово
(состоящей из двоичных символов, представленных как биполярные значения) и аналогового значения полученной последовательности Z. Таким образом, декодер выбирает кодовое слово ![]() , если выражение
, если выражение
![]() (7-9)
(7-9)
имеет максимальное значение. Это эквивалентно выбору кодового слова ![]() , находящегося на ближайшем евклидовом кодовом расстоянии от Z. Даже несмотря на то что каналы с жестким и мягким принятием решений требуют различных метрик, концепция выбора кодового слова
, находящегося на ближайшем евклидовом кодовом расстоянии от Z. Даже несмотря на то что каналы с жестким и мягким принятием решений требуют различных метрик, концепция выбора кодового слова ![]() , ближайшего к полученной последовательности Z, одинакова для обоих случаев. Чтобы в уравнении (7.9) точно выполнить максимизацию, декодер должен осуществлять арифметические операции с аналоговыми величинами. Это непрактично, поскольку обычно декодеры являются цифровыми. Таким образом, необходимо дискретизировать полученные символы
, ближайшего к полученной последовательности Z, одинакова для обоих случаев. Чтобы в уравнении (7.9) точно выполнить максимизацию, декодер должен осуществлять арифметические операции с аналоговыми величинами. Это непрактично, поскольку обычно декодеры являются цифровыми. Таким образом, необходимо дискретизировать полученные символы ![]() .He напоминает ли вам уравнение (7.9) демодуляционную обработку, рассмотренную в главах 3 и 4? Уравнение (7.9) является дискретным вариантом корреляции входного полученного сигнала
.He напоминает ли вам уравнение (7.9) демодуляционную обработку, рассмотренную в главах 3 и 4? Уравнение (7.9) является дискретным вариантом корреляции входного полученного сигнала ![]() с опорным сигналом
с опорным сигналом ![]() , которая выражается уравнением (4.15). Квантованный гауссов канал, обычно называемый каналом с мягкой схемой решений, — это модель канала, в которой предполагается, что декодирование осуществляется на основе описанной ранее мягкой схемы принятия решения.
, которая выражается уравнением (4.15). Квантованный гауссов канал, обычно называемый каналом с мягкой схемой решений, — это модель канала, в которой предполагается, что декодирование осуществляется на основе описанной ранее мягкой схемы принятия решения.
7.3.3. Алгоритм сверточного декодирования Витерби
Алгоритм декодирования Витерби был открыт и проанализирован Витерби (Viterbi) . [13] в 1967 году. В алгоритме Витерби, по сути, реализуется декодирование, основанное на принципе максимального правдоподобия; однако в нем уменьшается вычислительная нагрузка за счет использования особенностей структуры конкретной решетки кода. Преимущество декодирования Витерби, по сравнению с декодированием по методу "грубой силы", заключается в том, что сложность декодера Витерби не является функцией количества символов в последовательности кодовых слов. Алгоритм включает в себя вычисление меры подобия (или расстояния), между сигналом, полученным в момент времени ![]() , и всеми путями решетки, входящими в каждое состояние в момент времени
, и всеми путями решетки, входящими в каждое состояние в момент времени ![]() . В алгоритме Витерби не рассматриваются те пути решетки, которые, согласно принципу максимального правдоподобия, заведомо не могут быть оптимальными. Если в одно и то же состояние входят два пути, выбирается тот, который имеет лучшую метрику; такой путь называется выживающим. Отбор выживающих путей выполняется для каждого состояния. Таким образом, декодер углубляется в решетку, принимая решения путем исключения менее вероятных путей. Предварительный отказ от маловероятных путей упрощает процесс декодирования. В 1969 году Омура (Omura) [14] показал, что алгоритм Витерби — это, фактически, максимальное правдоподобие. Отметим, что задачу отбора оптимальных путей можно выразить как выбор кодового слова с максимальной метрикой правдоподобия или минимальной метрикой расстояния.
. В алгоритме Витерби не рассматриваются те пути решетки, которые, согласно принципу максимального правдоподобия, заведомо не могут быть оптимальными. Если в одно и то же состояние входят два пути, выбирается тот, который имеет лучшую метрику; такой путь называется выживающим. Отбор выживающих путей выполняется для каждого состояния. Таким образом, декодер углубляется в решетку, принимая решения путем исключения менее вероятных путей. Предварительный отказ от маловероятных путей упрощает процесс декодирования. В 1969 году Омура (Omura) [14] показал, что алгоритм Витерби — это, фактически, максимальное правдоподобие. Отметим, что задачу отбора оптимальных путей можно выразить как выбор кодового слова с максимальной метрикой правдоподобия или минимальной метрикой расстояния.
7.3.4. Пример сверточного декодирования Витерби
Для простоты предположим, что мы имеем дело с каналом BSC; в таком случае приемлемой мерой расстояния будет расстояние Хэмминга. Кодер для этого примера показан на рис. 7.3, а решетчатая диаграмма — на рис. 7.7. Для представления декодера, как показано на рис. 7.10, можно воспользоваться подобной решеткой. Мы начинаем в момент времени ![]() в состоянии 00 (вследствие очистки кодера между сообщениями декодер находится в начальном состоянии). Поскольку в этом примере возможны только два перехода, начинающиеся в некотором состоянии, для начала не нужно показывать все ветви. Полная решетчатая структура образуется после момента времени
в состоянии 00 (вследствие очистки кодера между сообщениями декодер находится в начальном состоянии). Поскольку в этом примере возможны только два перехода, начинающиеся в некотором состоянии, для начала не нужно показывать все ветви. Полная решетчатая структура образуется после момента времени ![]() . Принцип работы происходящего после процедуры декодирования можно понять, изучив решетку кодера на рис. 7.7 и решетку декодера, показанную на рис. 7.10. Для решетки декодера каждую ветвь за каждый временной интервал удобно пометить расстоянием Хэмминга между полученным кодовым символом и ответвляющимся словом, соответствующим той же ветви из решетки кодера. На рис. 7.10 показана последовательность сообщений m, соответствующая последовательности кодовых слов U, и исаженная шумом последовательность Z= 11 01 01 1001 — Как показано на рис. 7.3, кодер характеризуется кодовыми словами, находящимися на ветвях решетки кодера и заведомо известными как кодеру, так и декодеру. Эти ответвляющиеся слова являются кодовыми символами, которые можно было бы ожидать на выходе кодера в результате каждого перехода между состояниями. Пометки на ветвях решетки декодера накапливаются декодером в процессе. Другими словами, когда получен кодовый символ, каждая ветвь решетки декодера помечена метрикой подобия (расстоянием Хэмминга) между полученным кодовым символом и каждым ответвляющимся словом за этот временной интервал. Из полученной последовательности Z, показанной на рис. 7.10, можно видеть, что кодовые символы, полученные в (следующий) момент времени
. Принцип работы происходящего после процедуры декодирования можно понять, изучив решетку кодера на рис. 7.7 и решетку декодера, показанную на рис. 7.10. Для решетки декодера каждую ветвь за каждый временной интервал удобно пометить расстоянием Хэмминга между полученным кодовым символом и ответвляющимся словом, соответствующим той же ветви из решетки кодера. На рис. 7.10 показана последовательность сообщений m, соответствующая последовательности кодовых слов U, и исаженная шумом последовательность Z= 11 01 01 1001 — Как показано на рис. 7.3, кодер характеризуется кодовыми словами, находящимися на ветвях решетки кодера и заведомо известными как кодеру, так и декодеру. Эти ответвляющиеся слова являются кодовыми символами, которые можно было бы ожидать на выходе кодера в результате каждого перехода между состояниями. Пометки на ветвях решетки декодера накапливаются декодером в процессе. Другими словами, когда получен кодовый символ, каждая ветвь решетки декодера помечена метрикой подобия (расстоянием Хэмминга) между полученным кодовым символом и каждым ответвляющимся словом за этот временной интервал. Из полученной последовательности Z, показанной на рис. 7.10, можно видеть, что кодовые символы, полученные в (следующий) момент времени ![]() , — это 11. Чтобы пометить ветви декодера подходящей метрикой расстояния Хэмминга в (прошедший) момент времени
, — это 11. Чтобы пометить ветви декодера подходящей метрикой расстояния Хэмминга в (прошедший) момент времени ![]() , рассмотрим решетку кодера на рис. 7.7. Видим, что переход между состояниями 00
, рассмотрим решетку кодера на рис. 7.7. Видим, что переход между состояниями 00 ![]() 00 порождает на выходе ответвляющееся слово 00. Однако получено 11. Следовательно, на решетке декодера помечаем переход между состояниями 00
00 порождает на выходе ответвляющееся слово 00. Однако получено 11. Следовательно, на решетке декодера помечаем переход между состояниями 00 ![]() 00 расстоянием Хэмминга между ними, а именно 2. Глядя вновь на решетку кодера, видим, что переход между состояниями 00
00 расстоянием Хэмминга между ними, а именно 2. Глядя вновь на решетку кодера, видим, что переход между состояниями 00 ![]() 10 порождает на выходе ответвляющееся слово 11, точно соответствующее полученному в момент
10 порождает на выходе ответвляющееся слово 11, точно соответствующее полученному в момент ![]() кодовому символу. Следовательно, переход на решетке декодера между состояниями 00
кодовому символу. Следовательно, переход на решетке декодера между состояниями 00 ![]() 10 помечаем расстоянием Хэмминга 0. В итоге, метрика входящих в решетку декодера ветвей описывает разницу (расстояние) между тем, что было получено, и тем, что "могло бы быть" получено, имея ответвленные слова, связанные с теми ветвями, с которых они были переданы. По сути, эти метрики описывают величину, подобную корреляциям между полученным ответвляющимся словом и каждым из кандидатов на роль ответвляющегося слова. Таким же образом продолжаем помечать ветви решетки декодера по мере получения символов в каждый момент времени
10 помечаем расстоянием Хэмминга 0. В итоге, метрика входящих в решетку декодера ветвей описывает разницу (расстояние) между тем, что было получено, и тем, что "могло бы быть" получено, имея ответвленные слова, связанные с теми ветвями, с которых они были переданы. По сути, эти метрики описывают величину, подобную корреляциям между полученным ответвляющимся словом и каждым из кандидатов на роль ответвляющегося слова. Таким же образом продолжаем помечать ветви решетки декодера по мере получения символов в каждый момент времени ![]() . В алгоритме декодирования эти метрики расстояния Хэмминга используются для нахождения наиболее вероятного (с минимальным расстоянием) пути через решетку.
. В алгоритме декодирования эти метрики расстояния Хэмминга используются для нахождения наиболее вероятного (с минимальным расстоянием) пути через решетку.
Смысл декодирования Витерби заключается в следующем. Если любые два пути сливаются в одном состоянии, то при поиске оптимального пути один из них всегда можно исключить. Например, на рис. 7.11 показано два пути, сливающихся в момент времени ![]() в состоянии 00.
в состоянии 00.
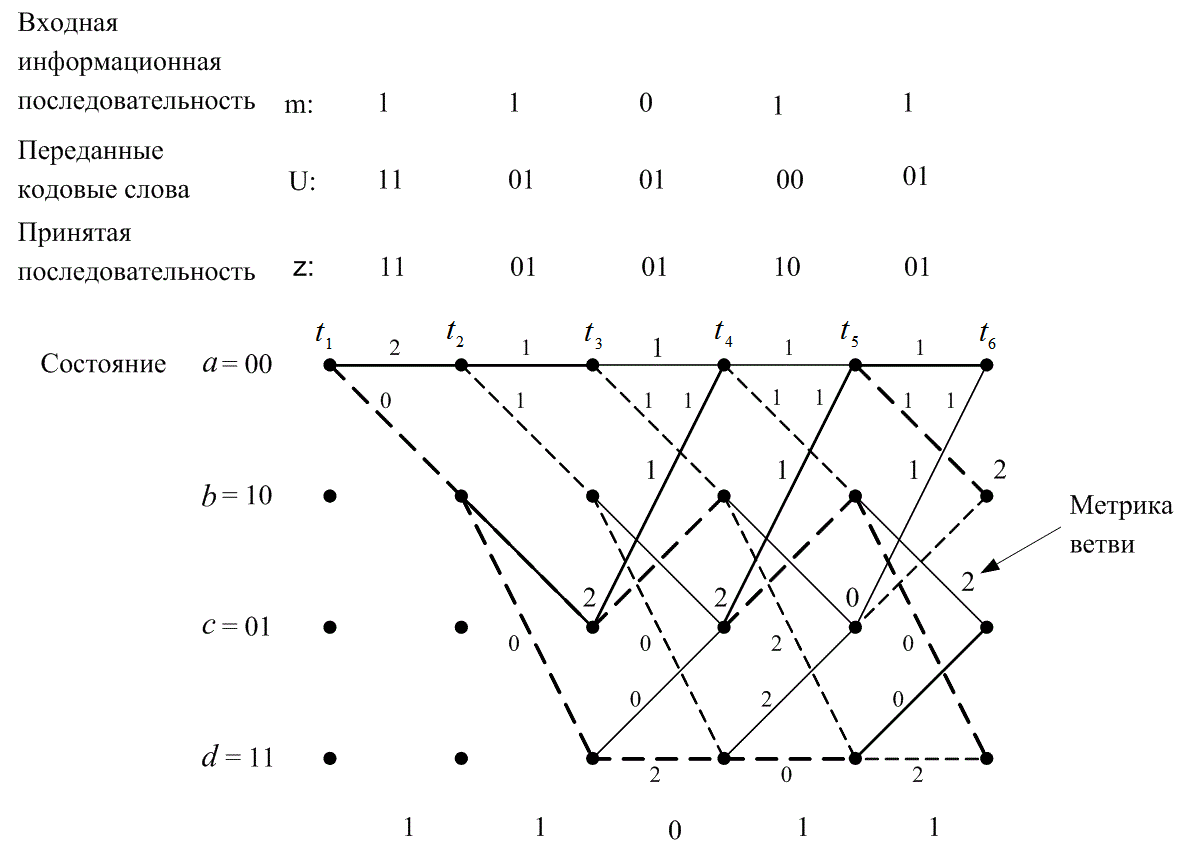
Рис. 7.10. Решетчатая диаграмма декодера (степень кодирования 1/2, K= 3)
Давайте определим суммарную метрику пути по Хэммингу для данного пути в момент времени ![]() , как сумму метрик расстояний Хэмминга ветвей, по которым проходит путь до момента
, как сумму метрик расстояний Хэмминга ветвей, по которым проходит путь до момента ![]() ,. На рис. 7.11 верхний путь имеет метрику 4, нижний — метрику 1. Верхний путь нельзя выделить как оптимальный, поскольку нижний путь, входящий в то же состояние, имеет меньшую метрику. Это наблюдение поддерживается Марковской природой состояний кодера. Настоящее состояние завершает историю кодера в том смысле, что предыдущие состояния не могут повлиять на будущие состояния или будущие ветви на выходе.
,. На рис. 7.11 верхний путь имеет метрику 4, нижний — метрику 1. Верхний путь нельзя выделить как оптимальный, поскольку нижний путь, входящий в то же состояние, имеет меньшую метрику. Это наблюдение поддерживается Марковской природой состояний кодера. Настоящее состояние завершает историю кодера в том смысле, что предыдущие состояния не могут повлиять на будущие состояния или будущие ветви на выходе.
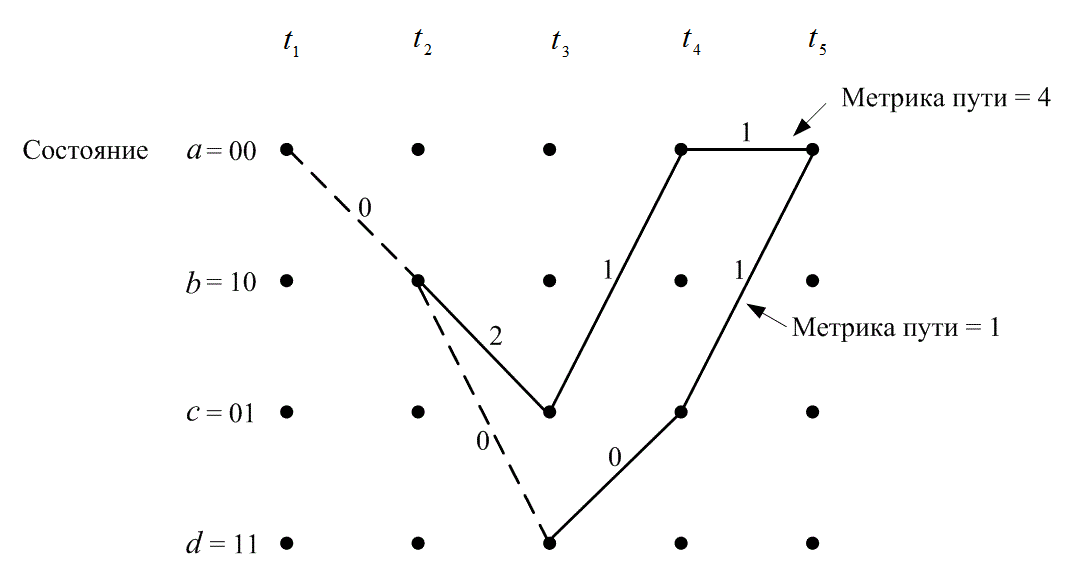
Рис. 7.11. Метрики пути для двух сливающихся путей
В каждый момент времени ![]() в решетке существует
в решетке существует ![]() состояний, где K — это длина кодового ограничения, и в каждое состояние может войти два пути. Декодирование Витерби состоит в вычислении метрики двух путей, входящих в каждое состояние, и исключении одного из них. Такие вычисления проводятся для каждого из
состояний, где K — это длина кодового ограничения, и в каждое состояние может войти два пути. Декодирование Витерби состоит в вычислении метрики двух путей, входящих в каждое состояние, и исключении одного из них. Такие вычисления проводятся для каждого из ![]() состояний или узлов в момент времени
состояний или узлов в момент времени ![]() ; затем декодер переходит к моменту времени
; затем декодер переходит к моменту времени ![]() , и процесс повторяется. В данный момент времени метрика выжившего пути для каждого состояния обозначается как метрика для этого состояния в этот момент времени. Первые несколько шагов в нашем примере декодирования будут следующими (рис. 7.12). Предположим, что последовательность входящих данных т, кодовое слово U и Полученная последовательность Z аналогичны показанным на рис. 7.10. Допустим, что декодер знает верное исходное состояние решетки. (Это предположение не является необходимым, однако упрощает объяснения.) В момент времени
, и процесс повторяется. В данный момент времени метрика выжившего пути для каждого состояния обозначается как метрика для этого состояния в этот момент времени. Первые несколько шагов в нашем примере декодирования будут следующими (рис. 7.12). Предположим, что последовательность входящих данных т, кодовое слово U и Полученная последовательность Z аналогичны показанным на рис. 7.10. Допустим, что декодер знает верное исходное состояние решетки. (Это предположение не является необходимым, однако упрощает объяснения.) В момент времени ![]() получены кодовые символы 11. Из состояния 00 можно перейти только в состояние 00 или 10, как показано на рис. 7.12, а. Переход между состояниями 00
получены кодовые символы 11. Из состояния 00 можно перейти только в состояние 00 или 10, как показано на рис. 7.12, а. Переход между состояниями 00 ![]() 10 имеет метрику ветви 0; переход между состояниями 00
10 имеет метрику ветви 0; переход между состояниями 00 ![]() 00 — метрику ветви 2. В момент времени
00 — метрику ветви 2. В момент времени ![]() из каждого состояния также может выходить только две ветви, как показано на рис. 7.12, б. Суммарная метрика этих ветвей обозначена как метрика состояний
из каждого состояния также может выходить только две ветви, как показано на рис. 7.12, б. Суммарная метрика этих ветвей обозначена как метрика состояний ![]() ,
, ![]() ,
, ![]() и
и ![]() , соответствующих конечным состояниям. В момент времени
, соответствующих конечным состояниям. В момент времени ![]() на рис. 7.12, на опять есть две ветви, выходящие из каждого состояния. В результате имеется два пути, входящих в каждое состояние, в момент времени
на рис. 7.12, на опять есть две ветви, выходящие из каждого состояния. В результате имеется два пути, входящих в каждое состояние, в момент времени ![]() . Один из путей, входящих в каждое состояние, может быть исключен, а точнее — это путь, имеющий большую суммарную метрику пути. Если бы метрики двух входящих путей имели одинаковое значение, то путь, который будет исключаться, выбирался бы произвольно. Выживший путь в каждом состоянии показан на рис. 7.12, г. В этой точке процесса декодирования имеется только один выживший путь, который называется полной ветвью, между моментами времени
. Один из путей, входящих в каждое состояние, может быть исключен, а точнее — это путь, имеющий большую суммарную метрику пути. Если бы метрики двух входящих путей имели одинаковое значение, то путь, который будет исключаться, выбирался бы произвольно. Выживший путь в каждом состоянии показан на рис. 7.12, г. В этой точке процесса декодирования имеется только один выживший путь, который называется полной ветвью, между моментами времени ![]() и
и ![]() . Следовательно, декодер теперь может решить, что между моментами
. Следовательно, декодер теперь может решить, что между моментами ![]() и
и ![]() произошел переход 00
произошел переход 00 ![]() 10. Поскольку переход вызывается единичным входным битом, на выходе декодера первым битом будет единица. Здесь легко можно проследить процесс декодирования выживших ветвей, поскольку ветви решетки показаны пунктирными линиями для входных нулей и сплошной линией для входных единиц. Заметим, что первый бит не декодируется, пока вычисление метрики пути не пройдет далее вглубь решетки. Для обычного декодера такая задержка декодирования может оказаться раз в пять больше длины кодового ограничения в битах.
10. Поскольку переход вызывается единичным входным битом, на выходе декодера первым битом будет единица. Здесь легко можно проследить процесс декодирования выживших ветвей, поскольку ветви решетки показаны пунктирными линиями для входных нулей и сплошной линией для входных единиц. Заметим, что первый бит не декодируется, пока вычисление метрики пути не пройдет далее вглубь решетки. Для обычного декодера такая задержка декодирования может оказаться раз в пять больше длины кодового ограничения в битах.
На каждом следующем шаге процесса декодирования всегда будет два пути для каждого состояния; после сравнения метрик путей один из них будет исключен. Этот шаг в процессе декодирования показан на рис. 7.12, д. В момент ![]() снова имеется по два входных пути для каждого состояния, и один путь из каждой пары подлежит исключению. Выжившие пути на момент
снова имеется по два входных пути для каждого состояния, и один путь из каждой пары подлежит исключению. Выжившие пути на момент ![]() показаны на рис. 7.12, е. Заметим, что в нашем примере мы еще не можем принять решения относительно второго входного информационного бита, поскольку еще остается два пути, исходящих в момент
показаны на рис. 7.12, е. Заметим, что в нашем примере мы еще не можем принять решения относительно второго входного информационного бита, поскольку еще остается два пути, исходящих в момент ![]() из состояния в узле 10. В момент времени
из состояния в узле 10. В момент времени ![]() на рис. 7.12, ж снова можем видеть структуру сливающихся путей, а на рис. 7.12, з — выжившие пути на момент
на рис. 7.12, ж снова можем видеть структуру сливающихся путей, а на рис. 7.12, з — выжившие пути на момент ![]() . Здесь же, на рис. 7.12, з, на выходе декодера в качестве второго декодированного бита показана единица как итог единственного оставшегося пути между точками
. Здесь же, на рис. 7.12, з, на выходе декодера в качестве второго декодированного бита показана единица как итог единственного оставшегося пути между точками ![]() и
и ![]() . Аналогичным образом декодер продолжает углубляться в решетку и принимать решения, касающиеся информационных битов, устраняя все пути, кроме одного.
. Аналогичным образом декодер продолжает углубляться в решетку и принимать решения, касающиеся информационных битов, устраняя все пути, кроме одного.
Отсекание (сходящихся путей) в решетке гарантирует, что у нас никогда не будет путей больше, чем состояний. В этом примере можно проверить, что после каждого отсекания (рис. 7.12, б—д) остается только 4 пути. Сравните это с попыткой применить "грубую силу" (без привлечения алгоритма Витерби) при использовании для получения последовательности принципа максимального правдоподобия. В этом случае число возможных путей (соответствующее возможным вариантам последовательности) является степенной функцией длины последовательности. Для двоичной последовательности кодовых слов с длиной ответвленных слов L имеется ![]() возможные последовательности.
возможные последовательности.
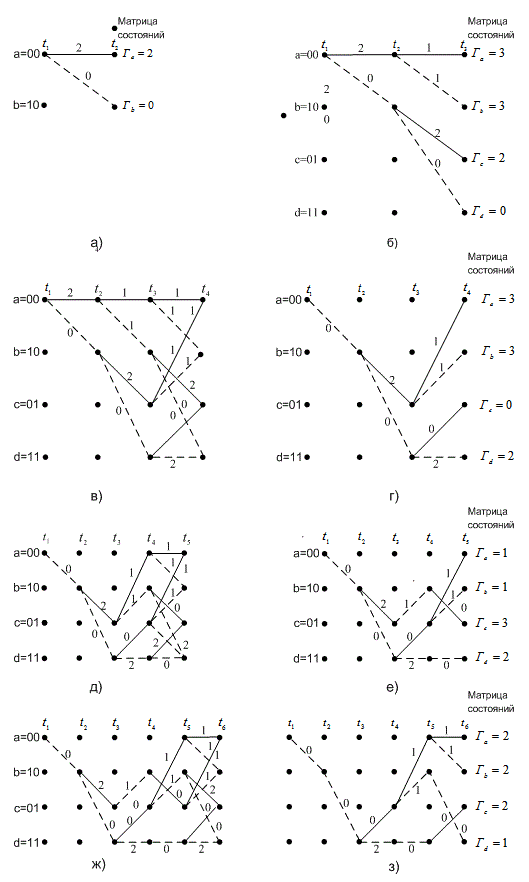
Рис. 7.12. Выбор выживших путей: а) выжившие на момент ![]() ; б) выжившие на момент
; б) выжившие на момент ![]() ; в) сравнение метрик в момент
; в) сравнение метрик в момент ![]() ; г) выжившие на момент
; г) выжившие на момент ![]() ; д) сравнение метрик в момент
; д) сравнение метрик в момент ![]() ; e) выжившие на момент
; e) выжившие на момент ![]() ; ж) сравнение метрик в момент
; ж) сравнение метрик в момент ![]() ; з) выжившие на момент
; з) выжившие на момент ![]()
7.3.5. Реализация декодера
В контексте решетчатой диаграммы, показанной на рис. 7.10, переходы за один промежуток времени можно сгруппировать в ![]() непересекающиеся ячейки; каждая ячейка будет изображать четыре возможных перехода, причем
непересекающиеся ячейки; каждая ячейка будет изображать четыре возможных перехода, причем ![]() называется памятью кодера (encoder memory). Если К = 3, то v = 2, и, следовательно, мы имеем
называется памятью кодера (encoder memory). Если К = 3, то v = 2, и, следовательно, мы имеем ![]() ячейки. Эти ячейки показаны на рис. 7.13, где буквы a, b, c и d обозначают состояния в момент
ячейки. Эти ячейки показаны на рис. 7.13, где буквы a, b, c и d обозначают состояния в момент ![]() , а
, а ![]() ,
, ![]() ,
, ![]() и
и ![]() —состояния в момент времени
—состояния в момент времени ![]() . Для каждого перехода изображена метрика ветви
. Для каждого перехода изображена метрика ветви![]() , индексы которой означают переход из состояния х в состояние у. Эти ячейки и соответствующие логические элементы, которые корректируют метрики состояний {
, индексы которой означают переход из состояния х в состояние у. Эти ячейки и соответствующие логические элементы, которые корректируют метрики состояний {![]() }, где х означает конкретное состояние, представляют основные составляющие элементы декодера.
}, где х означает конкретное состояние, представляют основные составляющие элементы декодера.
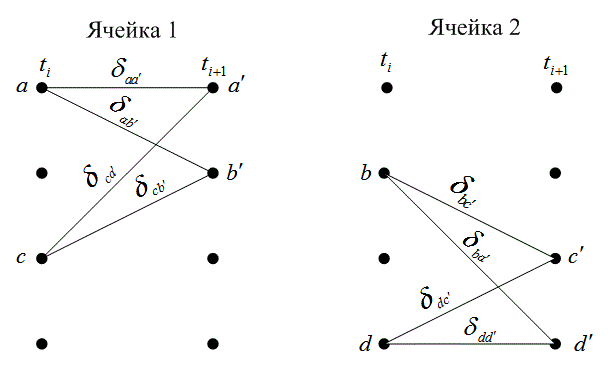
Рис. 7.13. Примеры ячеек декодера
7.3.5.1. Процедура сложения, сравнения и выбора
Вернемся к примеру двух ячеек с К = 3. На рис. 7.14 показан логический блок, соответствующий ячейке 1. Логическая схема осуществляет специальную операцию, которая называется сложение, сравнение и выбор (add-compare-select —ACS). Метрика состояния ![]() вычисляется путем прибавления метрики предыдущего состояния а,
вычисляется путем прибавления метрики предыдущего состояния а, ![]() , к метрике ветви
, к метрике ветви ![]() и метрики предыдущего состояния с,
и метрики предыдущего состояния с, ![]() , к метрике ветви
, к метрике ветви ![]() . Это даст в результате две метрики путей в качестве кандидатов для новой метрики состояния
. Это даст в результате две метрики путей в качестве кандидатов для новой метрики состояния ![]() . Оба кандидата сравниваются в логическом блоке, показанном на рис. 7.14. Наиболее правдоподобная из двух метрик путей (с наименьшим расстоянием) запоминается как новая метрика состояния
. Оба кандидата сравниваются в логическом блоке, показанном на рис. 7.14. Наиболее правдоподобная из двух метрик путей (с наименьшим расстоянием) запоминается как новая метрика состояния ![]() для состояния
для состояния ![]() . Также сохраняется новая история путей
. Также сохраняется новая история путей ![]() . для состояния а, где
. для состояния а, где ![]() — история пути информации для данного состояния, дополненная сведениями о выжившем пути.
— история пути информации для данного состояния, дополненная сведениями о выжившем пути.
На рис. 7.14 также показана логическая схема ACS для ячейки 1, которая дает новую метрику состояния ![]() и новую историю состояния
и новую историю состояния ![]() . Операция ACS аналогичным образом осуществляется и для путей в других ячейках. Выход декодера составляют последние биты на путях с наименьшими метриками состояний.
. Операция ACS аналогичным образом осуществляется и для путей в других ячейках. Выход декодера составляют последние биты на путях с наименьшими метриками состояний.
7.3.5.2. Вид процедуры сложения, сравнения и выбора на решетке
Рассмотрим тот же пример, которым мы воспользовались в разделе 7.3.4 для описания декодирования на основе алгоритма Витерби. Последовательность сообщений имела вид m = 11011, последовательность кодовых слов — U=11 01 01 00 01, а принятая последовательность — Z=11 01 01 10 01.
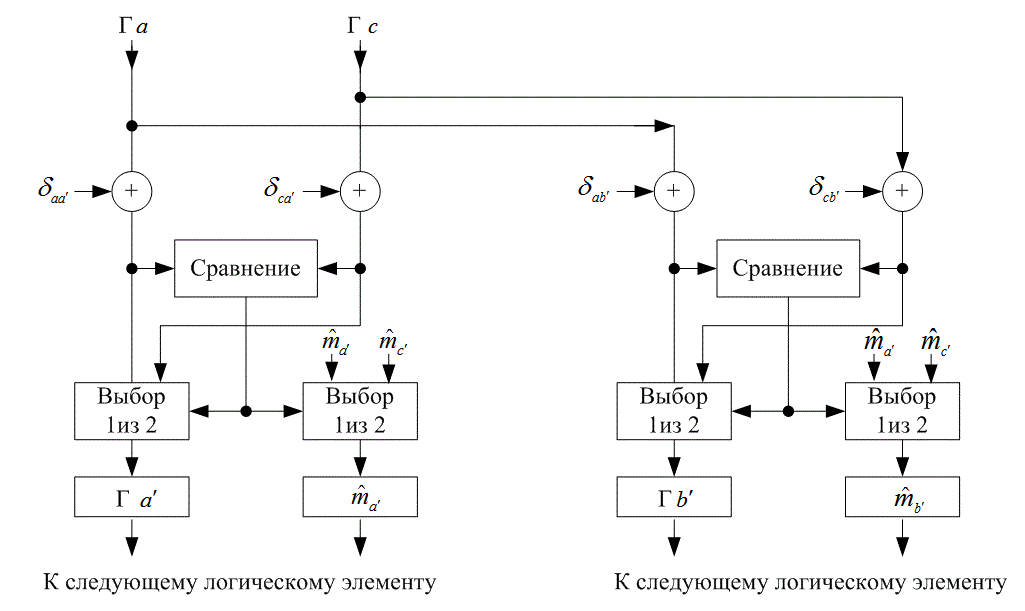
Рис. 7.14. Логический блок, предназначенный для осуществления операции сложения, сравнения и выбора
Решетчатая диаграмма декодирования, аналогичная показанной на рис. 7.10, изображена на рис. 7.15. Метрика ветви, которая описывает каждую ветвь, — это расстояние Хэмминга между принятым кодовым символом и соответствующим ответвленным словом из решетки кодера. Еще на решетке (рис. 7.15) показаны значения каждого состояния х в каждый момент ![]() , метрика состояния которых обозначена
, метрика состояния которых обозначена ![]() . Операция ACS выполняется после появления двух переходов, входящих в состояние, т.е. для момента
. Операция ACS выполняется после появления двух переходов, входящих в состояние, т.е. для момента ![]() и более поздних. Например, в момент времени
и более поздних. Например, в момент времени ![]() значение метрики состояния для состояния а вычисляется суммированием метрики состояния
значение метрики состояния для состояния а вычисляется суммированием метрики состояния ![]() = 3 в момент
= 3 в момент ![]() и метрики ветви
и метрики ветви ![]() , что в итоге дает значение 4. В то же время к метрике состояния
, что в итоге дает значение 4. В то же время к метрике состояния ![]() в момент времени
в момент времени ![]() прибавляется метрика ветви
прибавляется метрика ветви ![]() , что дает значение 3. В ходе процедуры ACS происходит отбор наиболее правдоподобной метрики (с минимальным расстоянием), т.е. новой метрики состояния; поэтому для состояния а в момент
, что дает значение 3. В ходе процедуры ACS происходит отбор наиболее правдоподобной метрики (с минимальным расстоянием), т.е. новой метрики состояния; поэтому для состояния а в момент ![]() новой метрикой состояния будет
новой метрикой состояния будет ![]() =3. Отобранный путь изображен жирной линией, а путь, который был отброшен, показан светлой линией. На рис. 7.15 на решетке слева направо показаны все метрики состояний. Убедимся, что в любой момент времени значение каждой метрики состояния получается суммированием метрики состояния, соединенного с предыдущим состоянием вдоль отобранного пути (жирная линия), и метрики ветви, соединяющей эти состояния. В определенной точке решетки (после временного интервала, равного 4 или 5 длинам кодового ограничения) будут декодированы самые ранние биты. Чтобы показать это, посмотрим на рис. 7.15 в момент
=3. Отобранный путь изображен жирной линией, а путь, который был отброшен, показан светлой линией. На рис. 7.15 на решетке слева направо показаны все метрики состояний. Убедимся, что в любой момент времени значение каждой метрики состояния получается суммированием метрики состояния, соединенного с предыдущим состоянием вдоль отобранного пути (жирная линия), и метрики ветви, соединяющей эти состояния. В определенной точке решетки (после временного интервала, равного 4 или 5 длинам кодового ограничения) будут декодированы самые ранние биты. Чтобы показать это, посмотрим на рис. 7.15 в момент ![]() . Видим, что значение метрики состояния, соответствующей минимальному расстоянию, равно 1. Отобранный путь можно проследить из состояния d обратно, к моменту
. Видим, что значение метрики состояния, соответствующей минимальному расстоянию, равно 1. Отобранный путь можно проследить из состояния d обратно, к моменту ![]() , и убедиться, что декодированное сообщение совпадает с исходным. Напомним, что пунктирные и сплошные линии соответствуют двоичным единице и нулю.
, и убедиться, что декодированное сообщение совпадает с исходным. Напомним, что пунктирные и сплошные линии соответствуют двоичным единице и нулю.
7.3.6. Память путей и синхронизация
Требования к памяти декодера, работающего согласно алгоритму Витерби, растут с увеличением длины кодового ограничения как степенная функция. Для кода со степенью кодирования 1/n после каждого шага декодирования декодер держит в памяти набор из ![]() путей.
путей.
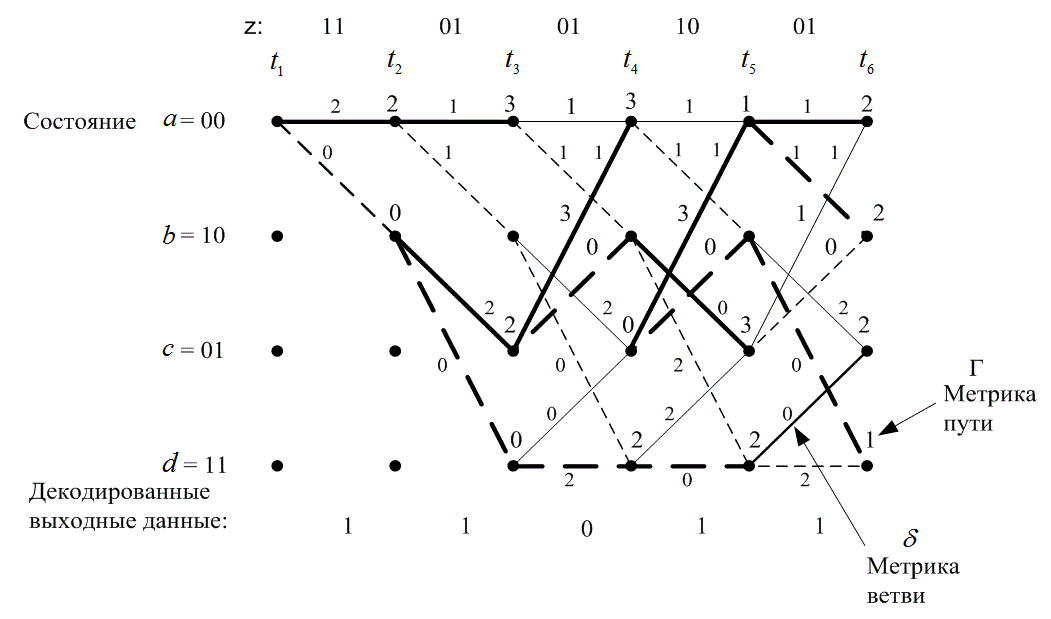
Рис. 7.15. Операция сложения, сравнения и выбора при декодировании по алгоритму Витерби
С высокой степенью вероятности при превышении существующей глубины декодирования эти пути не будут взаимно непересекающимися [12]. Все ![]() пути ведут к полной ветви, которая в конце концов разветвляется на разные состояния. Поэтому, если декодер сохраняет историю
пути ведут к полной ветви, которая в конце концов разветвляется на разные состояния. Поэтому, если декодер сохраняет историю ![]() путей, самые первые биты на всех путях будут одинаковы. Следовательно, простой декодер имеет фиксированный объем истории путей и выдает самые ранние биты произвольного пути каждый раз, когда продвигается на один уровень вглубь решетки. Требуемый объем сохраняемых путей будет равен следующему [12].
путей, самые первые биты на всех путях будут одинаковы. Следовательно, простой декодер имеет фиксированный объем истории путей и выдает самые ранние биты произвольного пути каждый раз, когда продвигается на один уровень вглубь решетки. Требуемый объем сохраняемых путей будет равен следующему [12].
![]() (7.10)
(7.10)
Здесь h - длина истории пути информационного бита на состояние. При уточнении, которое проводится для минимизации h, вместо самых ранних битов произвольных путей на выходе декодера используются самые ранние биты наиболее вероятных путей. Было показано [12], что значения h, равного 4 или 5 длинам кодового ограничения, достаточно, чтобы характеристики декодера были близки к оптимальным. Необходимый объем памяти и является основным ограничением при разработке декодеров, работающих согласно алгоритму Витерби. В серийно выпускаемых декодерах длина кодового ограничения равна величине порядка К = 10. Попытка повысить эффективность кодирования за счет увеличения длины кодового ограничения вызывает степенной рост требований к памяти (и сложности), как это следует из уравнения (7.10).
Синхронизация ответвляющихся слов — это процесс определения начала ответвляющегося слова в принятой последовательности. Такую синхронизацию можно осуществить, не прибавляя новую информацию к потоку передаваемых символов, поскольку можно видеть, что, пока принятые данные не синхронизированы, у них непомерно высокая частота появления ошибок. Следовательно, синхронизацию можно осуществить просто: нужно проводить сопутствующее наблюдение за уровнем частоты появления ошибок, т.е. нас должна интересовать частота, при которой увеличиваются метрики состояний, или частота, при которой сливаются выжившие пути на решетке. Параметр, за которым следят, сравнивается с пороговым значением, после чего соответствующим образом осуществляется синхронизация.
7.4 Свойства сверточных кодов
7.4.1. Пространственные характеристики сверточных кодов
Рассмотрим пространственные характеристики сверточных кодов в контексте простого кодера и его решетчатой диаграммы (рис 7.7.). Мы хотим узнать расстояние между всеми возможными парами последовательности кодовых слов. Как и в случае блочных кодов (см. раздел 6.5.2), нас интересует, минимальное расстояние между всеми такими парами последовательности таких кодовых слов в коде, поскольку минимальное расстояние связано с возможностями кода в коррекции ошибок. Поскольку сверточный код является групповым или линейным [6], можно без потери общности просто найти минимальное расстояние между последовательностью кодовых слов и нулевой последовательностью. Другими словами, для линейного кода данное контрольное сообщение окажется точно таким же «хорошим», как и любое другое. Так почему бы не взять то сообщение, которое легко проследить, а именно нулевую последовательность? Допустим, что на вход передана нулевая последовательность; следовательно, нас интересует такой путь, который начинается и заканчивается в состоянии 00 и не возвращается к состоянию 00 нигде внутри пути. Всякий раз, когда расстояние любых других путей, которые сливаются с состоянием а = 00 в момент ![]() окажется меньше расстояния нулевого пути. Иными словами, при нулевой передаче ошибка возникает всегда, когда не выживает нулевой путь. Следовательно, ошибка, о которой идет речь, связана с выживающим путем, который расходиться, а затем снова сливается с нулевым путем. Может возникнуть вопрос, зачем нужно чтобы пути сливались? Не будет ли для обнаружения ошибки достаточно лишь того, что бы пути расходились? В принципе, достаточно, но если ошибка характеризуется только расхождением, то декодер, начиная с этой точки, будет выдавать вместо оставшегося сообщения сплошной «мусор». Мы хотим выразить возможности декодера через число обычно появляющихся ошибок, то есть хотим узнать «самый легкий» для декодера способ сделать ошибку. Минимально расстояние для такой ошибки можно найти, полностью изучив все пути из состояния 00 в состояние 00. Итак, давайте заново начертим решетчатую диаграмму, как показано на рисунке 7.16, и обозначим каждую ветвь не символом ответвляющегося слова, а её расстояние Хемминга от нулевого кодового слова. Расстояние Хемминга между двумя последовательностями разной длины можно получить путем их сравнивания, т.е. прибавив к началу более короткой последовательности нужное количество нулей. Рассмотрим все пути, которые расходятся из нулевого пути и затем в какой то момент снова сливаются в произвольном узле. ИЗ диаграммы на рисунке 7.16 можно получить расстояние этих путей до нулевого пути. И так, на расстоянии 5 от нулевого пути имеется один путь; этот путь отходит от нулевого в момент в
окажется меньше расстояния нулевого пути. Иными словами, при нулевой передаче ошибка возникает всегда, когда не выживает нулевой путь. Следовательно, ошибка, о которой идет речь, связана с выживающим путем, который расходиться, а затем снова сливается с нулевым путем. Может возникнуть вопрос, зачем нужно чтобы пути сливались? Не будет ли для обнаружения ошибки достаточно лишь того, что бы пути расходились? В принципе, достаточно, но если ошибка характеризуется только расхождением, то декодер, начиная с этой точки, будет выдавать вместо оставшегося сообщения сплошной «мусор». Мы хотим выразить возможности декодера через число обычно появляющихся ошибок, то есть хотим узнать «самый легкий» для декодера способ сделать ошибку. Минимально расстояние для такой ошибки можно найти, полностью изучив все пути из состояния 00 в состояние 00. Итак, давайте заново начертим решетчатую диаграмму, как показано на рисунке 7.16, и обозначим каждую ветвь не символом ответвляющегося слова, а её расстояние Хемминга от нулевого кодового слова. Расстояние Хемминга между двумя последовательностями разной длины можно получить путем их сравнивания, т.е. прибавив к началу более короткой последовательности нужное количество нулей. Рассмотрим все пути, которые расходятся из нулевого пути и затем в какой то момент снова сливаются в произвольном узле. ИЗ диаграммы на рисунке 7.16 можно получить расстояние этих путей до нулевого пути. И так, на расстоянии 5 от нулевого пути имеется один путь; этот путь отходит от нулевого в момент в ![]()
![]() . Точно так же имеется два пути с расстоянием 6, один отходит в момент
. Точно так же имеется два пути с расстоянием 6, один отходит в момент ![]() и сливается с ним в момент
и сливается с ним в момент ![]() , а другой отходит в момент
, а другой отходит в момент ![]() и сливается с ним в момент
и сливается с ним в момент ![]() и т.д. Также можно видеть (по пунктирным и сплошным линиям на диаграмме), что входными битами для расстояния 5 будет 100; от нулевой последовательности эта последовательность отличается только одним битом. Точно так же входные биты для путей с расстоянием 6 будут 1100 и 10100; каждая из этих последовательностей отличается от нулевого пути в двух местах. Минимальная длина пути из числа расходящихся, а затем сливающихся путей называетсяминимальным просветом (minimum free distance), или просто просветом (free distance). Его можно видеть на рис. 7.16, где он показан жирной линией. Для оценки возможностей кода коррекции ошибок, мы повторно приведем уравнение (6.44) с заменой минимального расстояния
и т.д. Также можно видеть (по пунктирным и сплошным линиям на диаграмме), что входными битами для расстояния 5 будет 100; от нулевой последовательности эта последовательность отличается только одним битом. Точно так же входные биты для путей с расстоянием 6 будут 1100 и 10100; каждая из этих последовательностей отличается от нулевого пути в двух местах. Минимальная длина пути из числа расходящихся, а затем сливающихся путей называетсяминимальным просветом (minimum free distance), или просто просветом (free distance). Его можно видеть на рис. 7.16, где он показан жирной линией. Для оценки возможностей кода коррекции ошибок, мы повторно приведем уравнение (6.44) с заменой минимального расстояния ![]() на просвет
на просвет ![]() .
.
![]() (7.11)
(7.11)
Здесь [x] означает наибольшее целое, не большее х. Положив ![]() =5, можно видеть, что код, описываемый кодером на рис. 7.3, может исправить две любые ошибки канала.
=5, можно видеть, что код, описываемый кодером на рис. 7.3, может исправить две любые ошибки канала.
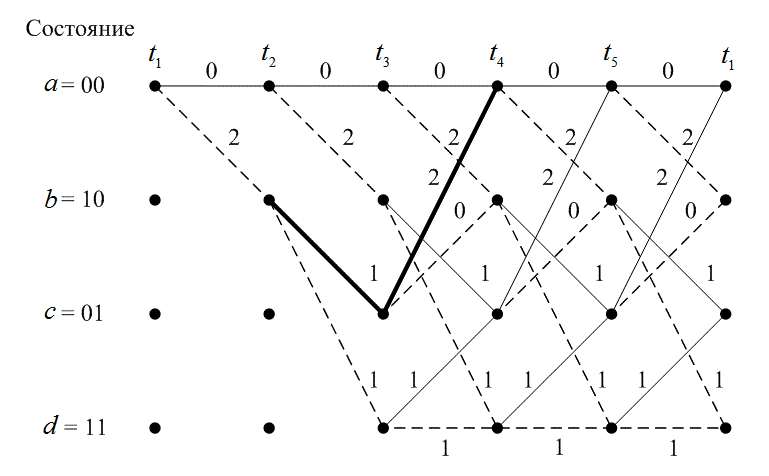
Рис. 7.16. Решетчатая диаграмма с обозначенными расстояниями от нулевого пути
Решетчатая диаграмма представляет собой "правила игры". Она является как бы символическим описанием всех возможных переходов и соответствующих начальных и конечных состояний, ассоциируемых с конкретным конечным автоматом. Эта диаграмма позволяет взглянуть глубже на выгоды (эффективность кодирования), которые дает применение кодирования с коррекцией ошибок. Взглянем на рис. 7.16 и на возможные ошибочные расхождения и слияния путей. Из рисунка видно, что декодер не может сделать ошибку произвольным образом. Ошибочный путь должен следовать одному из возможных переходов. Решетка позволяет нам определить все такие доступные пути. Получив по этому пути кодированные данные, мы можем наложить ограничения на переданный сигнал. Если декодер знает об этих ограничениях, то это позволяет ему более просто (используя меньшее ![]() ) удовлетворять требованиям надежной безошибочной работы.
) удовлетворять требованиям надежной безошибочной работы.
Хотя на рис. 7.16 представлен способ прямого вычисления просвета, для него можно получить более строгое аналитическое выражение, воспользовавшись для этого диаграммой состояний, изображенной на рис. 7.5. Для начала обозначим ветви диаграммы состояний как ![]() , как это показано на рис. 7.17, где показатель D означает расстояние Хэмминга между ответвленным словом этой ветви и нулевой ветвью. Петлю в узле а можно убрать, поскольку она не дает никакого вклада в пространственные характеристики последовательности кодовых слов относительно нулевой последовательности. Более того, узел а можно разбить на два узла (обозначим их а и е), один из них представляет вход, а другой — выход диаграммы состояний. Все пути, начинающиеся из состояния а=00 и заканчивающиеся в е=00, можно проследить на модифицированной диаграмме состояний, показанной на рис. 7.17. Передаточную функцию пути a b c e (который начинается и заканчивается в состоянии 00) можно рассчитать через неопределенный “заполнитель” D как
, как это показано на рис. 7.17, где показатель D означает расстояние Хэмминга между ответвленным словом этой ветви и нулевой ветвью. Петлю в узле а можно убрать, поскольку она не дает никакого вклада в пространственные характеристики последовательности кодовых слов относительно нулевой последовательности. Более того, узел а можно разбить на два узла (обозначим их а и е), один из них представляет вход, а другой — выход диаграммы состояний. Все пути, начинающиеся из состояния а=00 и заканчивающиеся в е=00, можно проследить на модифицированной диаграмме состояний, показанной на рис. 7.17. Передаточную функцию пути a b c e (который начинается и заканчивается в состоянии 00) можно рассчитать через неопределенный “заполнитель” D как ![]() . Степень D — общее число единиц на пути, а значит, расстояние Хэмминга до нулевого пути. Точно так же пути a b d c e и а b c b с е имеют передаточную функцию D6 и, соответственно, расстояние Хэмминга, равное 6, до нулевого пути. Теперь уравнения состояния можем записать следующим образом
. Степень D — общее число единиц на пути, а значит, расстояние Хэмминга до нулевого пути. Точно так же пути a b d c e и а b c b с е имеют передаточную функцию D6 и, соответственно, расстояние Хэмминга, равное 6, до нулевого пути. Теперь уравнения состояния можем записать следующим образом
![]()
![]() (7.12)
(7.12)
![]()
![]()
Здесь ![]() являются фиктивными переменными неполных путей между промежуточными узлами. Передаточную функцию,T(D), которую иногда называют производящей функцией кода, можно записать как
являются фиктивными переменными неполных путей между промежуточными узлами. Передаточную функцию,T(D), которую иногда называют производящей функцией кода, можно записать как ![]() . Решение уравнений состояния (7.12) имеет следующий вид [15, 16].
. Решение уравнений состояния (7.12) имеет следующий вид [15, 16].
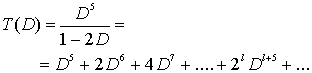 (7.13)
(7.13)
Передаточная функция этого кода показывает, что имеется один путь с расстоянием 5 до нулевого вектора, два пути — с расстоянием 6, четыре — с расстоянием 7. Вообще, существуют ![]() пути с расстоянием l+5 до нулевого вектора, причем l = 0,1,2,... . Просвет df кода является весовым коэффициентом Хэмминга члена наименьшего порядка разложения T(D). В данном случае df=5. Для оценки пространственных характеристик при большой длине кодового ограничения передаточную функцию T(D) использовать нельзя, поскольку сложность T(D) растет с увеличением длины кодового ограничения как степенная функция.
пути с расстоянием l+5 до нулевого вектора, причем l = 0,1,2,... . Просвет df кода является весовым коэффициентом Хэмминга члена наименьшего порядка разложения T(D). В данном случае df=5. Для оценки пространственных характеристик при большой длине кодового ограничения передаточную функцию T(D) использовать нельзя, поскольку сложность T(D) растет с увеличением длины кодового ограничения как степенная функция.
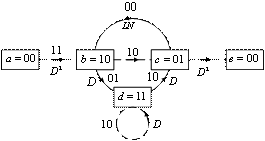
Рис. 7.17. Диаграмма состояний с обозначенными расстояниями до нулевого пути
С помощью передаточной функции можно получить более подробную информацию, чем при использовании лишь расстояния между различными путями. В каждую ветвь диаграммы состояний введем множитель L так, чтобы показатель L мог служить счетчиком ветвей в любом пути из состояния а = 00 в состояние е = 00. Более того, мы можем ввести множитель N во все ветви переходов, порожденных входной двоичной единицей. Таким образом, после прохождения ветви суммарный множитель N возрастает на единицу, только если этот переход ветви вызван входной битовой единицей. Для сверточного кода, описанного на рис. 7.3, на перестроенной диаграмме состояний (рис. 7.18) показаны дополнительные множители L и N. Уравнения (7.12) теперь можно переписать следующим образом.
![]()
![]() (7.14)
(7.14)
![]()
![]()
Передаточная функция такой доработанной диаграммы состояний будет следующей.
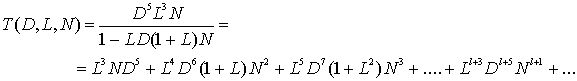 (7.15)
(7.15)
Таким образом, мы можем проверить некоторые свойства путей, показанные на рис. 7.16. Существует один путь с расстоянием 5 и длиной 3, который отличается от нулевого пути одним входным битом. Имеется два пути с расстоянием 6, один из них имеет длину 4, другой — длину 5, и оба отличаются от нулевого пути двумя входными битами. Также есть пути с расстоянием 7, из которых один имеет длину 5, два — длину 6 и один — длину 7; все четыре пути соответствуют входной последовательности, которая отличается от нулевого пути тремя входными битами. Следовательно, если нулевой путь является правильным и шум приводит к тому, что мы выбираем один из неправильных путей, то в итоге получится три битовые ошибки.
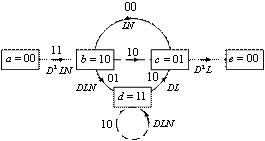
Рис. 7.18. Диаграмма состояний с обозначением расстояния, длины и числа входных единиц
7.4.1.1. Возможности сверточного кода в коррекции ошибок
В главе 6 при изучении блочных кодов говорилось, что способность кода к коррекции ошибок, t, представляет собой количество ошибочных кодовых символов, которые можно исправить в каждом блоке кода путем декодирования по методу максимального правдоподобия. В то же время при декодировании сверточных кодов способность кода к коррекции ошибок нельзя сформулировать так лаконично. Из уравнения (7.11) можно сказать, что при декодировании по принципу максимального правдоподобия код способен исправить t ошибок в пределах нескольких длин кодового ограничения, причем "несколько" — это где-то от 3 до 5. Точное значение длины зависит от распределения ошибок. Для конкретного кода и ошибочной комбинации длину можно ограничить с использованием методов передаточной функции. Такое ограничение будет описано позднее.
7.4.2. Систематические и несистематические сверточные коды
Систематический сверточный код — это код, в котором входной k-кортеж фигурирует как часть выходного n-кортежа ответвляющегося слова, соответствующего этому k-кортежу. На рис. 7.19 показан двоичный систематический кодер со степенью кодирования 1/2 и К=3. Для линейных блочных кодов любой несистематический код можно преобразовать в систематический с такими же пространственными характеристиками блоков. При использовании сверточных кодов это не так. Это означает, что сверточные коды сильно зависят от просвета; при построении сверточного кода в систематической форме при данной длине кодового ограничения и степени кодирования максимально возможное значение просвета снижается.

Рис. 7.19. Систематический сверточный кодер (степень кодирования 1/2, К=3)
В табл. 7.1 показан максимальный просвет при степени кодирования 1/2 для систематического и несистематического кодов с К от 2 до 8. При большой длине кодового ограничения результаты отличаются еще сильнее [17].
Таблица 7.1. Сравнение систематического и несистематического просветов, степень кодирования 1/2
|
Длина кодового ограничения |
Просвет систематического кода |
Просвет несистематического кода |
|
2 3 4 5 6 7 8 |
3 4 4 5 6 6 7 |
3 5 6 7 8 10 10 |
Источник:. A. J. Viteibi and J. К. Omura. Principles of Digital Communication and Coding, McGraw-Hill Book Company, New-York, 1979, p. 251.
7.4.3. Накопление катастрофических ошибок в сверточных кодах
Катастрофическая ошибка возникает, когда конечное число ошибок в кодовых символах вызывает бесконечное число битовых ошибок в декодированных данных. Мэсси (Massey) и Сейн (Sain) указали необходимые и достаточные условия для сверточного кода, при которых возможно накопление катастрофических ошибок. Условием накопления катастрофических ошибок для кода со степенью кодирования 1/2, реализованного на полиномиальных генераторах, описанных в разделе 7.2.1, будет наличие у генераторов общего полиномиального делителя (степени не менее единицы). Например, на рис. 7.20, а показан кодер с К = 3, степенью кодирования 1/2, со старшим полиномом ![]() и младшим
и младшим ![]() .
.
![]()
![]() (7.16)
(7.16)
Генераторы ![]() и
и ![]() имеют общий полиномиальный делитель 1+X, поскольку
имеют общий полиномиальный делитель 1+X, поскольку
![]() .
.
Следовательно, в кодере, показанном на рис. 7.20, а, может происходить накопление катастрофической ошибки.
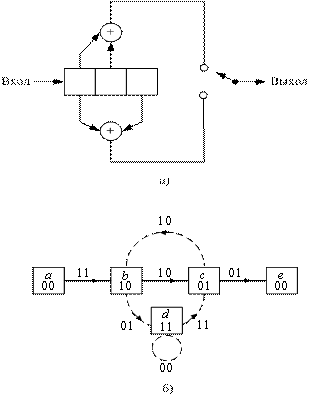
Рис. 7.20. Кодер, в котором возможно накопление катастрофической ошибки: а) кодер; б) диаграмма состояний
Если говорить о диаграмме состояний кода произвольной степени кодирования, то катастрофическая ошибка может появиться тогда и только тогда, когда любая петля пути на диаграмме имеет нулевой весовой коэффициент (нулевое расстояние до нулевого пути). Чтобы проиллюстрировать это, рассмотрим пример, приведенный на рис. 7.20. На диаграмме (рис. 7.20, б) узел состояния а = 00 разбит на два узла, а и е, как и ранее. Допустим, что нулевой путь является правильным, тогда неправильный путь a b d d... d c e имеет точно 6 единиц, независимо от того, сколько раз мы обойдем вокруг петли в узле d. Поэтому, например, для канала BSC к выбору этого неправильного пути могут привести три канальные ошибки. На таком пути может появиться сколь угодно большое число ошибок (две, плюс количество раз обхода петли). Для кодов со степенью кодирования 1/n можно видеть, что если каждый сумматор в кодере имеет четное количество соединений, петли, которые соответствуют информационным состояниям со всеми единицами, будут иметь нулевой вес, и, следовательно, код будет катастрофическим.
Единственное преимущество описанного ранее систематического кода заключается в том, что он никогда не будет катастрофическим, поскольку каждая петля должна содержать по крайней мере одну ветвь, порождаемую ненулевым входным битом; следовательно, каждая петля должна содержать ненулевой кодовый символ. Впрочем, можно показать [19], что только небольшая часть несистематических кодов (исключая тот, в котором все сумматоры имеют четное количество соединений) является катастрофической.
7.4.4. Границы рабочих характеристик сверточных кодов
Можно показать [8], что вероятность битовой ошибки ![]() в бинарном сверточном коде, использующем при декодировании жесткую схему принятия решений, может быть ограничена сверху следующим образом.
в бинарном сверточном коде, использующем при декодировании жесткую схему принятия решений, может быть ограничена сверху следующим образом.
![]() (7.17)
(7.17)
где p — вероятность ошибки в канальном символе. Для примера, приведенного на рис. 7.3, T(D,N) получено из T(D, L, N) путем задания L=1 в уравнении (7.15).
![]() (7.18)
(7.18)
и
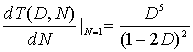 (7.19)
(7.19)
Объединяя уравнения (7.17) и (7.19), можем записать следующее.
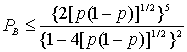 (7.20)
(7.20)
Можно показать, что при когерентной модуляции BPSK в канале с аддитивным белым гауссовым шумом (additive white Gaussian noise — AWGN) вероятность битовой ошибки ограничивается следующей величиной.
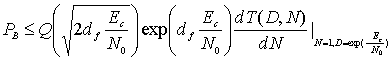 (7.21)
(7.21)
где
![]()
![]() — отношение энергии информационного бита к спектральной плотности мощности шума,
— отношение энергии информационного бита к спектральной плотности мощности шума,
![]() — отношение энергии канального символа к спектральной плотности мощности шума,
— отношение энергии канального символа к спектральной плотности мощности шума,
![]() —степень кодирования,
—степень кодирования,
а Q(x) определяется уравнениями (3.43) и (3.44) и приведено в табл. Б.1. Следовательно, для кода со степенью кодирования 1/2 и просветом df=5, при использовании когерентной схемы BPSK и жесткой схемы принятия решений при декодировании, можем записать следующее.
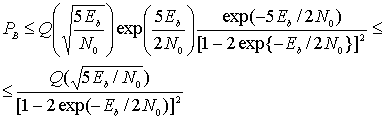 (7.22)
(7.22)
7.4.5. Эффективность кодирования
Эффективность кодирования, представленная уравнением (6.19), определяется как уменьшение (обычно выраженное в децибелах) отношения ![]() , требуемого для достижения определенной вероятности появления ошибок в кодированной системе, по сравнению с не кодированной системой с той же модуляцией и характеристиками канала. В табл. 7.2 перечислены верхние границы эффективности кодирования. Они сравниваются с не кодированным сигналом с когерентной модуляцией BPSK для нескольких значений минимальных просветов сверточного кода. Длина кодового ограничения в гауссовом канале с жесткой схемой принятия решений при декодировании изменяется от 3 до 9. В таблице отражен тот факт, что даже при использовании простого сверточного кода можно достичь значительной эффективности кодирования. Реальная эффективность кодирования будет изменяться в зависимости от требуемой вероятности появления битовых ошибок [20].
, требуемого для достижения определенной вероятности появления ошибок в кодированной системе, по сравнению с не кодированной системой с той же модуляцией и характеристиками канала. В табл. 7.2 перечислены верхние границы эффективности кодирования. Они сравниваются с не кодированным сигналом с когерентной модуляцией BPSK для нескольких значений минимальных просветов сверточного кода. Длина кодового ограничения в гауссовом канале с жесткой схемой принятия решений при декодировании изменяется от 3 до 9. В таблице отражен тот факт, что даже при использовании простого сверточного кода можно достичь значительной эффективности кодирования. Реальная эффективность кодирования будет изменяться в зависимости от требуемой вероятности появления битовых ошибок [20].
Таблица 7.2. Верхние границы эффективности кодирования для некоторых сверточных кодов
|
Коды со степенью кодирования 1/2 |
Коды со степенью кодирования 1/2 |
||||
|
K |
|
Верхняя граница (дБ) |
К |
|
Верхняя граница (дБ) |
|
3 4 5 6 7 8 9 |
5 6 7 8 10 10 12 |
3,97 4,76 5,43 6,00 6,99 6,99 7,78 |
3 4 5 6 7 8 9 |
8 10 12 13 15 16 18 |
4,26 5,23 6,02 6,37 6,99 7,27 7,78 |
Источник: V. К. Bhargava, D. Haccoun, R. Matyas and P. Nuspl. Digital Communications by Satellite. John Wiley & Sons, Inc., New York, 1981.
В табл. 7.3 приводятся оценки эффективности кодов, сравниваемые с не кодированным сигналом с когерентной модуляцией BPSK, реализованной аппаратным путем или путем моделирования на компьютере, в гауссовом канале с мягкой схемой принятия решений при декодировании [21]. Не кодированное значение ![]() дано в крайнем левом столбце. Из табл. 7.3 можно видеть, что эффективность кодирования возрастает при уменьшении вероятности появления битовой ошибки. Однако эффективность кодирования не может возрастать бесконечно. Как показано в таблице, она имеет верхнюю границу. Эту границу (в децибелах) можно выразить следующим образом.
дано в крайнем левом столбце. Из табл. 7.3 можно видеть, что эффективность кодирования возрастает при уменьшении вероятности появления битовой ошибки. Однако эффективность кодирования не может возрастать бесконечно. Как показано в таблице, она имеет верхнюю границу. Эту границу (в децибелах) можно выразить следующим образом.
эффективность кодирования ![]() (7.23)
(7.23)
Здесь r— степень кодирования, a df— просвет. При изучении табл. 7.3 обнаруживается также, что (при ![]() ) для кодов со степенью кодирования 1/2 и 2/3 более слабые коды имеют тенденцию находиться ближе к верхней границе, чем более мощные коды.
) для кодов со степенью кодирования 1/2 и 2/3 более слабые коды имеют тенденцию находиться ближе к верхней границе, чем более мощные коды.
Таблица 7.3. Основные значения эффективности кодирования (в дБ) при использовании мягкой схемы принятия решений в ходе декодирования по алгоритму Витерби
|
Не кодированное |
Степень кодирования |
1/3 |
½ |
2/3 |
3/4 |
||||||
|
(дБ) |
|
К |
7 |
8 |
5 |
6 |
7 |
6 |
8 |
6 |
9 |
|
6,8 9,6 11,3 Верхняя граница |
|
4,2 5,7 6,2 7,0 |
4,4 5,9 6,5 7,3 |
3,3 4,3 4,9 5,4 |
3,5 4,6 5,3 6,0 |
3,8 5,1 5,8 7,0 |
2,9 4,2 4,7 5,2 |
3,1 4,6 5,2 6,7 |
2,6 3,6 3,9 4,8 |
2,6 4,2 4,8 5,7 |
|
Источник: I. M. Jacobs. Practical Applications of Coding. IEEE Trans. Inf. Theory, vol. IT20, May 1974, pp. 305-310. .
Как правило, декодирование по алгоритму Витерби используется в двоичном входном канале с жестким или мягким 3-битовым квантованным выходом. Длина кодового ограничения варьируется от 3 до 9, причем степень кодирования кода редко оказывается меньше 1/3, и память путей составляет несколько длин кодового ограничения [12]. Памятью путей называется глубина входных битов, которая сохраняется в декодере. После рассмотрения в разделе 7.3.4 декодирования по алгоритму Витерби может возникнуть вопрос об ограничении объема памяти путей. Из этого примера может показаться, что декодирование ответвленного слова в любом узле может происходить сразу, как только останется один выживший путь в этом узле. Это действительно так; хотя для создания реального декодера таким способом потребуется большое количество постоянных проверок после декодирования ответвленного слова. На практике вместо всего этого обеспечивается фиксированная задержка, после которой ответвляющееся слово декодируется. Было показано [12, 22], что информации о происхождении состояния с наименьшей метрикой состояния (с использованием фиксированного объема путей, порядка 4 или 5 длин кодового ограничения) достаточно для получения характеристик декодера, которые для гауссова канала и канала BSC на величину порядка 0,1 дБ меньше характеристик оптимального канала. На рис. 7.21 показаны характерные результаты моделирования достоверности передачи при декодировании по алгоритму Витерби с жесткой схемой квантования [12]. Заметьте, что каждое увеличение длины кодового ограничения приводит к улучшению требуемого значения ![]() на величину, равную приблизительно 0,5 дБ, при
на величину, равную приблизительно 0,5 дБ, при ![]() .
.
7.4.6. Наиболее известные сверточные коды
Векторы связи или полиномиальные генераторы сверточного кода обычно выбираются исходя из свойств просветов кода. Главным критерием при выборе кода является требование, чтоб код не допускал катастрофического накопления ошибок и имел максимальный просвет при данной степени кодирования и длине кодового ограничения.
![]() (дБ)
(дБ)
Рис. 7.21. Зависимость вероятности появления битовой ошибки от ![]() при степени кодирования кодов 1/2; используется когерентная модуляция BPSK в канале ВSС, декодирование согласно алгоритму Витерби и 32-битовая (Перепечатано с разрешения авторов из J. A. Heller and I. M. Jacobs. "Viterbi Decoding for Satellite and Space Communication". IEEE Trans. Commun. Technol., vol. COM19, n. 5, October, 1971, Fig. 7, p. 84 © 1971, IEEE.)
при степени кодирования кодов 1/2; используется когерентная модуляция BPSK в канале ВSС, декодирование согласно алгоритму Витерби и 32-битовая (Перепечатано с разрешения авторов из J. A. Heller and I. M. Jacobs. "Viterbi Decoding for Satellite and Space Communication". IEEE Trans. Commun. Technol., vol. COM19, n. 5, October, 1971, Fig. 7, p. 84 © 1971, IEEE.)
Затем при данном просвете df минимизируется число путей или число ошибочных битов данных, которые представляют путь. Процедуру выбора можно усовершенствовать, рассматривая количество путей или ошибочных битов при df+1, df +2и т.д., пока не останется только один код или класс кодов. Список наиболее известных кодов со степенью кодирования 1/2 при K , равном от 3 до 9, и со степенью кодирования 1/3 при K, равном от 3 до 8, соответствующих этому критерию, был составлен Оденуальдером (Odenwalder) [3, 23] и приводится в табл. 7.4. Векторы связи в этой таблице представляют наличие или отсутствие (1 или 0) соединения между соответствующими регистрами сверточного кодера, причем крайний левый элемент соответствует крайнему левому разряду регистра кодера. Интересно, что эти соединения можно обратить (заменить в указанной выше схеме крайний; левые на крайние правые). При декодировании по алгоритму Витерби обратные соединения приведут к кодам с точно такими же пространственными характеристиками, а значит, и с такими же рабочими характеристиками, как показаны в табл. 7.4.
Таблица 7.4. Оптимальные коды с малой длиной кодового ограничения (степень кодирования 1/2 и 1/3)
|
Степень кодирования |
Длина кодового ограничения | Просвет | Вектор кода |
| 1/2 | 3 | 5 | 111 101 |
| 1/2 | 4 | 6 | 1111 1011 |
| 1/2 | 5 | 7 | 10111 11001 |
| 1/2 | 6 | 8 | 101111 110101 |
| 1/2 | 7 | 10 | 10011111 11100101 |
| 1/2 | 8 | 10 | 110101111 11100101 |
| 1/2 | 9 | 12 | 110101111 100011101 111 |
| 1/3 | 3 | 8 | 111 101 1111 |
| 1/3 | 4 | 10 | 1011 1101 11111 |
| 1/3 | 5 | 12 | 11011 10101 10111 |
| 1/3 | 6 | 13 | 110101 111001 1001111 |
| 1/3 | 7 | 15 | 1010111 1101101 11101111 |
| 1/3 | 8 | 16 | 10011011 10101001 |
Источник: J. P. Odenwalder. Error Control Coding Handbook. Linkabit Corp., San Diego, Calif., July, 15, 1976.
7.4.7. Компромиссы сверточного кодирования
7.4.7.1. Производительность при когерентной передаче сигналов с модуляцией PSK
Возможности схемы кодирования в коррекции ошибок возрастают при увеличении числа канальных символов n, приходящихся на число информационных бит k, или при снижении степени кодирования k/n. В то же время при этом увеличивается ширина полосы пропускания канала и сложность декодера: Выгода низких степеней кодирования при использовании сверточного кода совместно с когерентной модуляцией PSK проявляется в снижении требуемого значения ![]() (для широкого диапазона степеней кодирования), что позволяет при заданном значении мощности осуществить передачу на более высоких скоростях или снизить мощность при заданной скорости передачи информации. Компьютерное моделирование показало [16, 22], что при фиксированной длине кодового ограничения снижение степени кодирования с 1/2 до 1/3 в итоге приводит к уменьшению требуемого значения
(для широкого диапазона степеней кодирования), что позволяет при заданном значении мощности осуществить передачу на более высоких скоростях или снизить мощность при заданной скорости передачи информации. Компьютерное моделирование показало [16, 22], что при фиксированной длине кодового ограничения снижение степени кодирования с 1/2 до 1/3 в итоге приводит к уменьшению требуемого значения ![]() примерно на 0,4 дБ (сложность декодера при этом возрастает примерно на 17%). Для меньших значений степени кодирования улучшение рабочих характеристик по отношению к росту сложности декодирования быстро убывает [22]. В конечном счете, существует точка, по достижении которой дальнейшее снижение степени кодирования приводит к падению эффективности кодирования (см. раздел 9.7.7.2).
примерно на 0,4 дБ (сложность декодера при этом возрастает примерно на 17%). Для меньших значений степени кодирования улучшение рабочих характеристик по отношению к росту сложности декодирования быстро убывает [22]. В конечном счете, существует точка, по достижении которой дальнейшее снижение степени кодирования приводит к падению эффективности кодирования (см. раздел 9.7.7.2).
7.4.7.2. Производительность при некогерентной ортогональной передаче сигналов
В отличие от модуляции PSK, при некогерентной ортогональной передаче сигналов существует оптимальное значение степени кодирования, приблизительно равное 1/2. Надежность передачи при степени кодирования 1/3, 2/3 и 3/4 хуже, чем при степени кодирования 1/2. При фиксированной длине кодового ограничения и степени кодирования 1/3, 2/3 или 3/4 качество кодирования, как правило, падает на 0,25, 0,5 и 0,3 дБ, соответственно, по сравнению с достоверностью передачи при Степени кодирования 1/2 [16].
7.4.8. Мягкое декодирование по алгоритму Витерби
Для двоичной кодовой системы со степенью кодирования 1/2, демодулятор подает на декодер два кодовых символа за раз. Для жесткого (двухуровневого) декодирования каждую пару принятых кодовых символов можно изобразить на плоскости в виде одного из углов квадрата, как показано на рис. 7.22, а. Углы помечены двоичными числами (0, 0), (0, 1), (1, 0) и (1, 1), представляющими четыре возможных значения, которые могут принимать два кодовых символа в жесткой схеме принятия решений. Аналогично для 8-уровневого мягкого декодирования каждую пару кодовых символов можно отобразить на плоскости в виде равностороннего прямоугольника размером 8x8, состоящего из 64 точек, как показано на рис. 7.22, б. В этом случае демодулятор больше не выдает жестких решений; он выдает квантованные сигналы с шумом (мягкая схема принятия решений).
Основное различие между мягким и жестким декодированием по алгоритму Витерби состоит в том, что в мягкой схеме не используется метрика расстояния Хэмминга, поскольку она имеет ограниченное разрешение. Метрика расстояний, которая имеет нужное разрешение, называется евклидовым кодовым расстоянием, поэтому далее, чтобы облегчить ее применение, соответствующим образом преобразуем двоичные числа из единиц и нулей в восьмеричные числа от 0 до 7. Это можно увидеть на рис. 7.22, в, где соответствующим образом обозначены углы квадрата; теперь для описания любой из 64 точек мы будем пользоваться парами целых чисел от 0 до 7. На рис. 7.22, в также изображена точка 5,4, представляющая пример пары значений кодовых символов с шумом. Представим себе, что квадрат на рис. 7.22, в изображен в координатах (x, y). Каким будет евклидово кодовое расстояние между точкой с шумом 5,4 и точкой без шума 0,0? Оно равно ![]() . А если мы захотим узнать евклидово кодовое расстояние между точкой с шумом 5,4 и точкой без шума 7,7? Аналогично
. А если мы захотим узнать евклидово кодовое расстояние между точкой с шумом 5,4 и точкой без шума 7,7? Аналогично ![]() .
.
Рис. 7.22. Декодирование Витерби: а) плоскость жесткой схемы принятия решений; б) 8-уровневая плоскость мягкой схемы принятия решений; в) пример мягких кодовых символов; г) секция решетки кодирования; д) секция решетки декодирования
Мягкое декодирование по алгоритму Витерби, по большей части, осуществляется так же, как и жесткое декодирование (как описывалось в разделах 7.3.4 и 7.3.5). Единственное отличие состоит в том, что здесь не используется расстояние Хэмминга. Поэтому рассмотрим мягкое декодирование, осуществляемое с евклидовым кодовым расстоянием. На рис. 7.22, г показана первая секция решетки кодирования, которая вначале имела вид, приведенный на рис. 7.7. При этом кодовые слова преобразованы из двоичных в восьмеричные. Допустим, что пара кодовых символов, поступившая на декодер во время первого перехода, согласно мягкой схеме декодирования имеет значения 5,4. На рис. 7.22, д показана первая секция решетки декодирования. Метрика (![]() ), представляющая евклидово кодовое расстояние между прибывшим ответвленным словом 5,4 и ответвленным словом 0,0, обозначена сплошной линией. Аналогично метрика (
), представляющая евклидово кодовое расстояние между прибывшим ответвленным словом 5,4 и ответвленным словом 0,0, обозначена сплошной линией. Аналогично метрика (![]() ) представляет собой евклидово кодовое расстояние между поступившим кодовым символом 5,4 и кодовым символом 7,7; это расстояние показано пунктирной линией. Оставшаяся часть задачи декодирования, которая сводится к отсечению решетки и поиску полной ветви, осуществляется аналогично схеме жесткого декодирования. Заметим, что в реальных микросхемах, предназначенных для сверточного декодирования, евклидово кодовое расстояние в действительности не применяется, вместо него используется монотонная метрика, которая обладает сходными свойствами, но значительно проще в реализации. Примером такой метрики является' квадрат евклидова кодового расстояния, в котором исключается рассмотренная выше операция взятия квадратного корня. Более того, если двоичные кодовые символы представлены биполярными величинами, тогда можно использовать метрику скалярного произведения, определяемую уравнением (7.9). При такой метрике вместо минимального расстояния мы должны будем рассматривать максимальные корреляции.
) представляет собой евклидово кодовое расстояние между поступившим кодовым символом 5,4 и кодовым символом 7,7; это расстояние показано пунктирной линией. Оставшаяся часть задачи декодирования, которая сводится к отсечению решетки и поиску полной ветви, осуществляется аналогично схеме жесткого декодирования. Заметим, что в реальных микросхемах, предназначенных для сверточного декодирования, евклидово кодовое расстояние в действительности не применяется, вместо него используется монотонная метрика, которая обладает сходными свойствами, но значительно проще в реализации. Примером такой метрики является' квадрат евклидова кодового расстояния, в котором исключается рассмотренная выше операция взятия квадратного корня. Более того, если двоичные кодовые символы представлены биполярными величинами, тогда можно использовать метрику скалярного произведения, определяемую уравнением (7.9). При такой метрике вместо минимального расстояния мы должны будем рассматривать максимальные корреляции.
7.5. Другие алгоритмы сверточного декодирования
7.5.1. Последовательное декодирование
Ранее, до того как Витерби открыл оптимальный алгоритм декодирования сверточных кодов, существовали и другие алгоритмы. Самым первым был алгоритм последовательного декодирования, предложенный Уозенкрафтом (Wozencraft) [24, 25] и модифицированный Фано (Fano) [2]. В ходе работы последовательного декодера генерируется гипотеза о переданной последовательности кодовых слов и рассчитывается метрика между этой гипотезой и принятым сигналом. Эта процедура продолжается до тех пор, пока метрика показывает, что выбор гипотезы правдоподобен, в противном случае гипотеза последовательно заменяется, пока не будет найдена наиболее правдоподобная. Поиск при этом происходит методом проб и ошибок. Для мягкого или жесткого декодирования можно разработать последовательный декодер, но обычно мягкого декодирования стараются избегать из-за сложных расчетов и большой требовательности к памяти.
Рассмотрим ситуацию, когда используется кодер, изображенный на рис. 7.3, и последовательность m=11011 кодирована в последовательность кодовых слов U=1101010001, как было в примере 7.1. Допустим, что принятая последовательность Z является, фактически, правильной передачей U. У декодера имеется копия кодового дерева, показанная на рис. 7.6, и он может воспользоваться принятой последовательностью Z для прохождения дерева. Декодер начинает с узла дерева в момент t и генерирует оба пути, исходящие из этого узла. Декодер следует пути, который согласуется с полученными n кодовыми символами. На следующем уровне дерева декодер снова генерирует два пути, выходящие из узла, и следует пути, согласующемуся со второй группой и символов. Продолжая аналогичным образом, декодер быстро перебирает все дерево.
Допустим теперь, что принятая последовательность Z является искаженным кодовым словом U. Декодер начинает с узла дерева в момент ![]() и генерирует оба пути, выходящие из этого узла. Если принятые п кодовых символов совпадают с одним из сгенерированных путей, декодер следует этому пути. Если согласования нет, то декодер следует наиболее вероятному пути, но при этом ведет общий подсчет несовпадений между принятыми символами и ответвляющимися словами на пути следования. Если две ветви оказываются равновероятными, то приемник делает произвольный выбор, как и в случае с нулевым входным путем. На каждом уровне дерева декодер генерирует новые ветви и сравнивает их со следующим набором п принятых кодовых символов. Поиск продолжается до тех пор, пока все дерево не будет пройдено по наиболее вероятному пути, и при этом составляется счет несовпадений.
и генерирует оба пути, выходящие из этого узла. Если принятые п кодовых символов совпадают с одним из сгенерированных путей, декодер следует этому пути. Если согласования нет, то декодер следует наиболее вероятному пути, но при этом ведет общий подсчет несовпадений между принятыми символами и ответвляющимися словами на пути следования. Если две ветви оказываются равновероятными, то приемник делает произвольный выбор, как и в случае с нулевым входным путем. На каждом уровне дерева декодер генерирует новые ветви и сравнивает их со следующим набором п принятых кодовых символов. Поиск продолжается до тех пор, пока все дерево не будет пройдено по наиболее вероятному пути, и при этом составляется счет несовпадений.
Если счет несовпадений превышает некоторое число (оно может увеличиваться после прохождения дерева), декодер решает, что он находится на неправильном пути, отбрасывая этот путь и повторяет все снова. Декодер помнит список отброшенных путей, чтобы иметь возможность избежать их при следующем прохождении дерева. Допустим, кодер, представленный на рис. 7.3, кодирует информационную последовательность m=11011 в последовательность кодовых слов U, как показано на рис. 7.1. Предположим, что четвертый и седьмой биты переданной последовательности U приняты с ошибкой.
|
Время |
|
|
|
|
|
|
|
Информационная последовательность |
m= |
1 |
1 |
0 |
1 |
1 |
|
Переданная последовательность |
U= |
11 |
01 |
01 |
00 |
01 |
|
Принятая последовательность |
Z= |
11 |
00 |
01 |
10 |
01 |
Давайте проследим за траекторией пути декодирования на рис. 7.23. Допустим; что критерием возврата и повторного прохождения путей будет общий счет не согласующихся путей, равный 3. На рис. 7.23 числа у путей прохождения представляют собой текущее значение счетчика несовпадений. Итак, прохождение дерева будет иметь следующий вид.
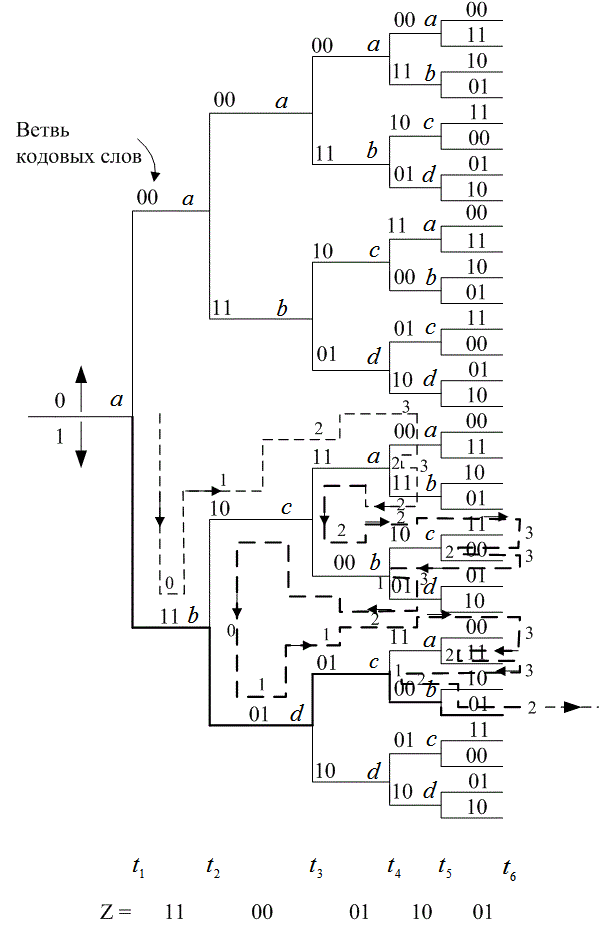
Рис. 7.23. Схема последовательного декодирования
1. В момент времени ![]() мы принимаем символы 11 и сравниваем их с ответвляющимся словами, исходящими из первого узла.
мы принимаем символы 11 и сравниваем их с ответвляющимся словами, исходящими из первого узла.
2. Наиболее вероятна та ветвь, у которой ответвляющееся слово 11 (соответствующее входной битовой единице или ответвлению вниз), поэтому декодер решает, что входная битовая единица правильно декодирована, и переходит на следующий уровень.
3. В момент ![]() на этом втором уровне декодер принимает символы 00 и сравнивает их с возможными ответвленными словами 10 и 01.
на этом втором уровне декодер принимает символы 00 и сравнивает их с возможными ответвленными словами 10 и 01.
4. Здесь нет "хорошего" пути; поэтому декодер произвольно выбирает путь, соответствующий входному битовому нулю (или ответвляющемуся слову 10), и счетчик несовпадений регистрирует 1.
5. В момент времени ![]() декодер принимает символы 01 и сравнивает их на третьем уровне с ответвляющимися словами 11 и 00.
декодер принимает символы 01 и сравнивает их на третьем уровне с ответвляющимися словами 11 и 00.
6. Здесь снова ни один из путей не имеет преимуществ. Декодер произвольно выбирает нулевой входной путь (или ответвленное слово 11), и счетчик несовпадений возрастает до 2.
7. В момент ![]() декодер принимает символы 10 и сравнивает их на четвертом уровне с ответвленными словами 00 и 11.
декодер принимает символы 10 и сравнивает их на четвертом уровне с ответвленными словами 00 и 11.
8. Здесь снова ни один из путей не имеет преимуществ, и декодер произвольно выбирает нулевой входной путь (или ответвленное слово 00); счетчик несовпадений возрастает до 3.
9. Поскольку счет несовпадений, равный 3, соответствует точке возврата, декодер "делает откат" и пробует альтернативный путь. Счетчик переустанавливается на 2 несовпадения.
10. Альтернативный путь на четвертом уровне соответствует пути входной битовой единицы (или ответвленному слову 11). Декодер принимает этот путь, но после сравнения его с принятыми символами 10 несовпадение остается равным 1, и счетчик устанавливается равным 3.
11. Счет 3 является критерием точки возврата, поэтому декодер делает откат назад с этого пути, и счетчик снова устанавливается на 2. На данном уровне ![]() все альтернативные пути использованы, поэтому декодер возвращается на узел в момент
все альтернативные пути использованы, поэтому декодер возвращается на узел в момент ![]() и переустанавливает счетчик на 1.
и переустанавливает счетчик на 1.
12. В узле ![]() декодер сравнивает символы, принятые в момент времени
декодер сравнивает символы, принятые в момент времени ![]() а именно 01, с неиспользованным путем 00. В данном случае несовпадение равно 1, и счетчик устанавливается на 2.
а именно 01, с неиспользованным путем 00. В данном случае несовпадение равно 1, и счетчик устанавливается на 2.
13. В узле ![]() декодер следует за ответвляющимся словом 10, которое совпадает с принятым в момент
декодер следует за ответвляющимся словом 10, которое совпадает с принятым в момент ![]() кодовым символом 10. Счетчик остается равным 2.
кодовым символом 10. Счетчик остается равным 2.
14. В узле ![]() ни один из путей не имеет преимуществ, и декодер, как и определяется правилами, следует верхней ветви. Счетчик устанавливается на 3 несовпадения.
ни один из путей не имеет преимуществ, и декодер, как и определяется правилами, следует верхней ветви. Счетчик устанавливается на 3 несовпадения.
15. При таком счете декодер делает откат, переустанавливает счетчик на 2 и пробует альтернативный путь в узле ![]() . Поскольку другим ответвляющимся словом является 00, снова получаем одно несовпадение с принятым в момент
. Поскольку другим ответвляющимся словом является 00, снова получаем одно несовпадение с принятым в момент ![]() кодовым символом 01, и счетчик устанавливается равным 3.
кодовым символом 01, и счетчик устанавливается равным 3.
16. Декодер уходит с этого пути, и счетчик переустанавливается на 2. На этом уровне ![]() все альтернативные пути исправлены, по этому декодер возвращается на узел в момент
все альтернативные пути исправлены, по этому декодер возвращается на узел в момент ![]() и переустанавливает счетчик на 1.
и переустанавливает счетчик на 1.
17. Декодер пробует альтернативные пути в узле ![]() , метрика которого возрастает до 3, поскольку в ответвляющемся слове имеется не совпадение в двух позициях. В этот момент декодер должен сделать откат всех путей до момента
, метрика которого возрастает до 3, поскольку в ответвляющемся слове имеется не совпадение в двух позициях. В этот момент декодер должен сделать откат всех путей до момента ![]() , поскольку все пути более высоких уровней уже использованы. Счетчик снова переустановлен на нуль.
, поскольку все пути более высоких уровней уже использованы. Счетчик снова переустановлен на нуль.
18. В узле ![]() декодер следует ответвляющемуся слову 01. Поскольку имеются не совпадения в одной позиции с принятыми в момент
декодер следует ответвляющемуся слову 01. Поскольку имеются не совпадения в одной позиции с принятыми в момент ![]() кодовыми символами 00, то счетчик устанавливается на 1.
кодовыми символами 00, то счетчик устанавливается на 1.
Далее декодер продолжает свои поиски таким же образом. Как видно из рис. 7.23, финальный путь, счетчик которого не нарушает критерия точки возврата, дает правильно декодированную информационную последовательность 11011. Последовательное декодирование можно понимать как тактику проб и ошибок для поиска правильного пути на кодовом дереве. Поиск осуществляется последовательно; всегда рассматривается только один путь за раз. Если принимается не правильное решение, последующие пути будут ошибочными. Декодер может со временем распознать ошибку, отслеживая метрики пути. Алгоритм напоминает путешественника, отыскивающего путь на карте дорог. До тех пор, пока путешественник видит, что дорожные ориентиры соответствуют таковым на карте, он продолжает путь. Когда он замечает странные ориентиры (увеличение его своеобразной метрики), в конце концов приходит к выводу, что он находиться на не правильном пути, и возвращается к точке, где он может узнать ориентиры (его метрика возвращается в приемлемые рамки). Тогда он пробует альтернативный путь.
7.5.2. Сравнение декодирования по алгоритму Витерби с последовательным декодированием и их ограничения
Главный недостаток декодирования по алгоритму Витерби заключается в том, что, когда вероятность появления ошибки экспоненциально убывает с ростом длины кодового ограничения, число кодовых состояний, а значит сложность декодера, экспоненциально растет с увеличением длины кодового ограничения. С другой стороны, вычислительная сложность алгоритма Витерби является независимой характеристикой канала (в отличие от жесткого и мягкого декодирования, которые требуют обычного увеличения объемов вычислений). Последовательное декодирование асимптотически достигает той же вероятности появления ошибки, что и декодирование по принципу максимального правдоподобия, но без поиска всех возможных состояний. Фактически при последовательном декодировании число перебираемых состояний существенно независимо от длины кодового ограничения, и это позволяет использовать очень большие (К = 41) длины кодового ограничения. Это является важным фактором при обеспечении таких низких вероятностей появления ошибок. Основным недостатком последовательного декодирования является то, что количество перебираемых метрик состояний является случайной величиной. Для последовательного декодирования ожидаемое число неудачных гипотез и повторных переборов является функцией канального отношения сигнал/шум (signal to noise ratio — SNR). При низком SNR приходится перебирать больше гипотез, чем при высоком SNR. Из-за такой изменчивости вычислительной нагрузки, поступившие последовательности необходимо сохранять в буфере памяти. При низком SNR последовательности поступают в буфер до тех пор, пока декодер не сможет найти вероятную гипотезу. Если средняя скорость передачи символов превышает среднюю скорость декодирования, буфер будет переполняться, вне зависимости от его емкости, и данные будут теряться. Обычно, пока идет переполнение, буфер убирает данные без ошибок, в то время как декодер пытается выполнить процедуру восстановления. Порог переполнения буфера существенно зависит от SNR. Поэтому важным техническим требованием к последовательному декодеру является вероятность переполнения буфера.
На рис. 7.24 показаны типичные кривые, отображающие зависимость ![]() от
от ![]() для двух распространенных схем — декодирования по алгоритму Витерби и последовательного декодирования. Здесь сравниваются их характеристики при использовании когерентной модуляции BPSK в канале AWGN. Сравниваются кривые для декодирования по алгоритму Витерби (степень кодирования 1/2 и 1/3, К = 7, жесткое декодирование), декодирования по алгоритму Витерби (степень кодирования 1/2 и 1/3, К=7, мягкое декодирование) и последовательного декодирования (степень кодирования 1/2 и 1/3, К=41, жесткое декодирование), из рис- 7.24 можно видеть, что при последовательном декодировании можно достичь эффективности кодирования порядка 8 дБ при
для двух распространенных схем — декодирования по алгоритму Витерби и последовательного декодирования. Здесь сравниваются их характеристики при использовании когерентной модуляции BPSK в канале AWGN. Сравниваются кривые для декодирования по алгоритму Витерби (степень кодирования 1/2 и 1/3, К = 7, жесткое декодирование), декодирования по алгоритму Витерби (степень кодирования 1/2 и 1/3, К=7, мягкое декодирование) и последовательного декодирования (степень кодирования 1/2 и 1/3, К=41, жесткое декодирование), из рис- 7.24 можно видеть, что при последовательном декодировании можно достичь эффективности кодирования порядка 8 дБ при ![]() . Поскольку в работе Шеннона (Shannon) [26] предсказывается потенциальная эффективность кодирования около 11 дБ, по сравнению с не кодированной передачей с модуляцией BPSK, похоже, что, в основном, теоретически достижимые возможности уже получены.
. Поскольку в работе Шеннона (Shannon) [26] предсказывается потенциальная эффективность кодирования около 11 дБ, по сравнению с не кодированной передачей с модуляцией BPSK, похоже, что, в основном, теоретически достижимые возможности уже получены.
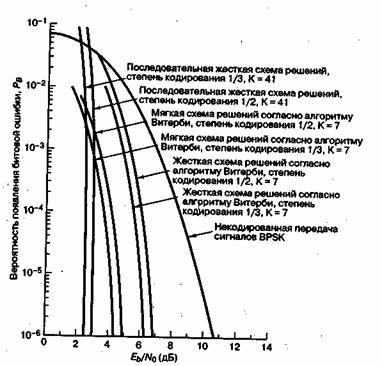
Рис. 7.24. Вероятности появления битовых ошибок для различных схем декодирования по алгоритму Витерби и последовательного декодирования, при когерентной модуляции BPSK в канале AWGN. (Перепечатано с разрешения авторов из J. К. Отит and В. К. Levitt, "Coded Error Probability Evaluation for Antijam Communication Systems". IEEE Trans. Commun., vol. COM30, n. 5, May, 1982, Fig. 4, p. 900. © 1982, IEEE.)
7.5.3. Декодирование с обратной связью
Декодер с обратной Связью реализует жесткую схему принятия решений относительно информационного бита в разряде j, исходя при этом из метрик, полученных из разрядов j, j+1…, j+т, где т—заранее установленное положительное целое число. Длина упреждения (look-ahead length) L определяется как L=m+1, количество принятых кодовых символов, выраженных через соответствующее число входных битов, задействованных для декодирования информационного бита. Решение о том, является ли информационный бит нулем или единицей, принимается в зависимости от того, на какой ветви путь минимального расстояния Хэмминга переходит в окне упреждения(look-ahead window) из разряда J в разряд j+т. Поясним это на конкретном примере. Рассмотрим декодер с обратной связью, предназначенный для сверточного кода со степенью кодирования 1/2, который показан на рис. 7.3. На рис. 7.25 приведена древовидная диаграмма и работа декодера с обратной связью при L=3. Иными словами, при декодировании бита из ветви j декодер содержит пути из ветвей j, j + 1 и j + 2.
Начиная из первой ветви, декодер вычисляет ![]() (восемь) совокупных метрик путей расстояния Хэмминга и решает, что бит для первой ветви является нулевым, если путь минимального расстояния содержится в верхней части дерева, и единичным, если путь минимального расстояния находится в нижней части дерева. Пусть принята последовательность Z=1100010001. Рассмотрим восемь путей от момента
(восемь) совокупных метрик путей расстояния Хэмминга и решает, что бит для первой ветви является нулевым, если путь минимального расстояния содержится в верхней части дерева, и единичным, если путь минимального расстояния находится в нижней части дерева. Пусть принята последовательность Z=1100010001. Рассмотрим восемь путей от момента ![]() до момента t3 в блоке, обозначенном на рис. 7.24 буквой А, и рассчитаем метрики, сравнивая эти восемь путей для первых шести принятых кодовых символов (три ветви вглубь умножить на два символа для ветви). Выписав метрики Хэмминга общих путей (начиная с верхнего пути), видим, что они имеют следующие значения.
до момента t3 в блоке, обозначенном на рис. 7.24 буквой А, и рассчитаем метрики, сравнивая эти восемь путей для первых шести принятых кодовых символов (три ветви вглубь умножить на два символа для ветви). Выписав метрики Хэмминга общих путей (начиная с верхнего пути), видим, что они имеют следующие значения.
Метрики верхней части 3, 3, 6, 4
Метрики нижней части 2,2,1,3
Видим, что наименьшая метрика содержится в нижней части дерева. Следовательно, первый декодированный бит является единицей (и определяется сдвигом вниз на дереве). Следующий шаг будет состоять в расширении нижней части дерева (выживающий путь) на один разряд глубже, и здесь снова вычисляется восемь метрик, теперь уже для моментов ![]() . Получив, таким образом, два декодированных символа, мы теперь можем сдвинуться на два символа вправо и снова начать расчет метрик путей, но уже для шести кодовых символов. Эта процедура видна в блоке, обозначенном на рис. 7.25 буквой В. И снова, проследив метрики верхних и нижних путей, находим следующее.
. Получив, таким образом, два декодированных символа, мы теперь можем сдвинуться на два символа вправо и снова начать расчет метрик путей, но уже для шести кодовых символов. Эта процедура видна в блоке, обозначенном на рис. 7.25 буквой В. И снова, проследив метрики верхних и нижних путей, находим следующее.
Метрики верхней части 2, 4, 3, 3
Метрики нижней части 3, 1, 4, 4
Минимальная метрика для ожидаемой принятой последовательности находится в нижней части блока В. Следовательно, второй декодируемый бит также является единицей.
Таким образом, процедура продолжается до тех пор, пока не будет декодировано все сообщение целиком. Декодер называется декодером с обратной связью, поскольку найденное решение подается обратно в декодер, чтобы потом использовать его в определении подмножества кодовых путей, которые будут рассматриваться следующими. В канале BSC декодер с обратной связью может оказаться, почти таким же эффективным, как и декодер, работающий по алгоритму Витерби (17). Кроме того, он может исправлять все наиболее вероятные ошибочные комбинации, а именно — те, которые имеют весовой коэффициент ![]() или менее, где df — просвет кода. Важным параметром разработки сверточного декодера с обратной связью является L, длина упреждения. Увеличение L приводит к повышению эффективности кодирования, но при этом растет сложность конструкции декодера.
или менее, где df — просвет кода. Важным параметром разработки сверточного декодера с обратной связью является L, длина упреждения. Увеличение L приводит к повышению эффективности кодирования, но при этом растет сложность конструкции декодера.
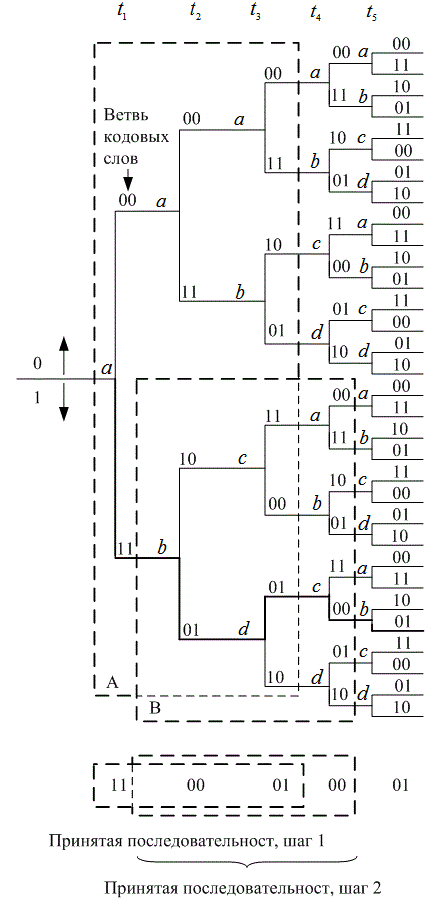
Рис. 7.25. Пример декодирования с обратной связью
Литература
1. Gallager R. G. Information Theory and Reliable Communication. John Wiley & Sons, Inc., New York, 1968.
2. Fano R. M. A Heuristic Discussion of Probabilistic Decoding. IRE Trans. Inf. Theory, vol. IT9. n. 2, 1963, pp. 64-74.
3. Odenwalder J. P. Optimal Decoding of Conventional Codes. Ph. D. dissertation, University of California, Los Angeles, 1970.
4. Curry S. J. Selection of Convolutional Codes Having Large Free Distance. Ph. D. dissertation, University of California, Los Angeles, 1971.
5. Larsen K. J. Short Conolutional Codes with Maximal Free Distance for Rates 1/2, 1/3, and 1/4. IEEE Trans. Inf. Theory, vol. IT19, n. 3, 1973, pp. 371-372.
6. Lin S. and Costello D. J. Jr. Error Control Coding: Fundamentals and Applications. Prentice-Hall, Inc., Englewood Clffls, N. J., 1983.
7. Forney G. D. Jr. Convolutional Codes: I. Algebraic Structure. IEEE Trans. Inf. Theory, vol. IT16,n. 6, November, 1970, pp. 720-738.
8. Viterbi A. Convolutional Codes and Their Performance in Communication Systems. IEEE Trans. Commun. Technol., vol. COM19, n. 5, October, 1971, pp. 751-772.
9. Forney G. D. Jr. and Bower E. K. A High Speed Sequential Decoder. Prototype Design and Test. IEEE Trans. Commun. Technol., vol. COM19, n. 5, October, 1971, pp. 821-835.
10. Jelinek F. Fast Sequential Decoding Algorithm Using a Stack. IBM J. Res. Dev., vol.13, November, 1969, pp. 675-685.
11. Massey J. L. Threshold Decoding. The MIT Press, Cambridge, Mass., 1963.
12. Heller J. A. and Jacobs I. W. Viterbi Decoding for Satellite and Space Communication. ШЕЕ Trans. Commun. Technol., vol. COM19, n. 5, October, 1971, pp. 835-848.
13. Viterbi A. J. Error Bounds Jor Convolutions! Codes and an Asymptotically Optimum Decoding Algorithm. IEEE Trans. Inf. Theory, vol. ' YT\$, April, 1967, pp. 260-269.
14. Omura J. K. On the Viterbi Decoding Algorithm (correspondence). IEEE Trans. Inf. Theory, vol. ГГ15, January, 1969, pp. 177-179.
15. Mason S. J. and Zimmerman H. J. Electronic Circuits, Signals, and Systems'. John Wiley & Sons, Inc. New York, 1960.
16. Clark G. C. and Cain J. B. Error-Correction Coding for Digital Communications. Plenum Press, New York, 1981.
17. Viterbi A. J. and Omura J. K. Principles of Digital Communication and Coding. McGraw-Hill Book Company, New York, 1979.
18. Massey J. L. and Sain M. K. Inverse of Linear Sequential Circuits. IEEE Trans. Comput., vol. C17, April, 1968, pp. 330-337.
19. Rosenberg W. J. Structural Properties of Convolutional Codes. Ph. D. dissertation, University of California, Los Angeles, 1971.
20. Bhargava V. K., Haccoun D., Matyas R. and Nuspl P. Digital Communications by Satellite. John Wiley & Sons, Inc., New York, 1981.
21. Jacobs I. M. Practical Applications of Coding. IEEE Trans. Inf. Theory, vol. J.T20, May, 1974, pp. 305-310.
22. Linkabit Corporation. Coding Systems Study for High Data Rate Telemetry Links. NASA Ames Res. Center, Final Rep. CR-114278, Contract NAS-2-6-24, Moffett Field, Calif., 1970.
23. Odenwalder J. P. Error Control Coding Handbook. Linkabit Corporation, San Diego, Calif., July, 15, 1976,
24. Wozencraft J. M. Sequential Decoding for Reliable Commumication. IRE Natl. Conv. Rec., vol. 5, pt. 3, 1957, pp. 11-25.
25. Wozencraft J. M. and Reiffen B. Sequential Decoding. The MIT Press, Cambridge, Mass., 1961.
26. Shannon C. E. A Mathematical Theory of Communication. Bell Syst. Tech. J., vol.27, 1948, pp. 379-423, 623-656.
Задачи
7.1. Нарисуйте диаграмму состояний, древовидную и решетчатую диаграммы для кода со степенью кодирования 1/3 при К = 3, который имеет следующие генераторы.
![]()
![]()
![]()
7.2. Дан двоичный сверточный код со степенью кодирования 1/2 и К = 3 с частично заполненной диаграммой состояний, изображенной на рис. 37.1. Найдите полную диаграмму состояний и опишите ее для кодера.
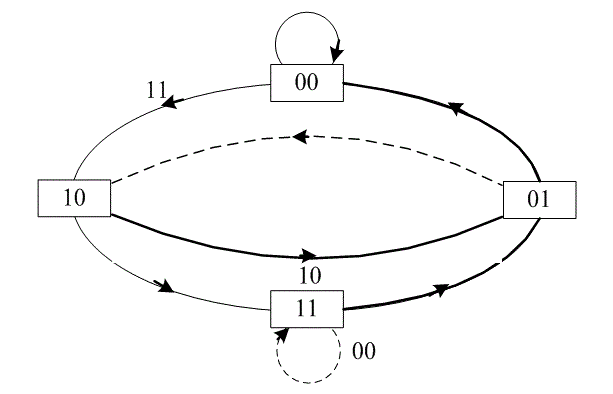
Рис. 37.1
7.3. Нарисуйте диаграмму состояний, древовидную и решетчатую диаграммы для сверточного кодера, который описывается блочной диаграммой, показанной на рис. 37.2.
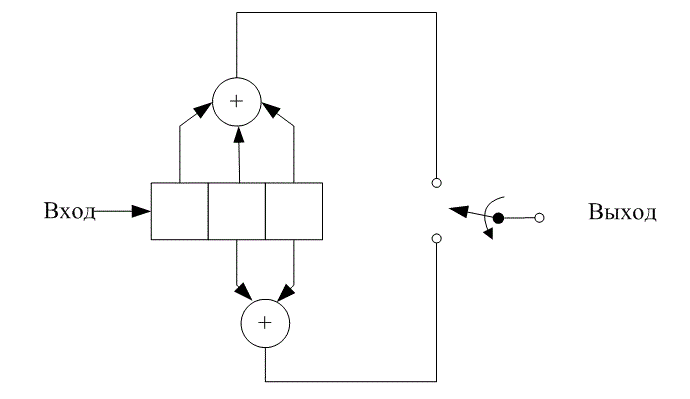
Рис. 37.2
7.4. Допустим, что вы пытаетесь найти самый быстрый путь из Лондона в Вену поездом или на судне. Диаграмма на рис. 37.3 построена с учетом различных расписаний. Обозначения возле каждого пути являются временем путешествия. Используя алгоритм Витерби, найдите наиболее быстрый маршрут из Лондона в Вену. Объясните, как работает этот алгоритм, какие вычисления необходимо проделать и какие данные нужно сохранить в памяти для включения их в алгоритм.
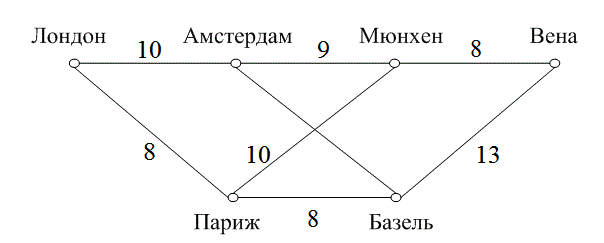
Рис. 37.3
7.5. Рассмотрим сверточный кодер, показанный на рис. 37.4.
а) Запишите векторы и полиномы связи для этого кодера.
б) Нарисуйте диаграмму состояний, древовидную и решетчатую диаграммы.
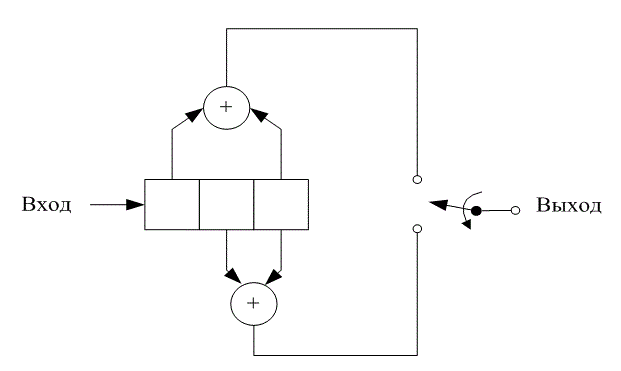
Рис.37.4
7.6. Какой будет импульсная характеристика в задаче 7.5? Используя эту характеристику, определите выходную последовательность, если на вход подается 101. Проверьте ответ с помощью полиномиальных генераторов.
7.7. Будет ли кодер, описанный в задаче 7.5, давать возможность для накопления катастрофической ошибки? Приведите пример в защиту своего ответа.
7.8. Найдите просвет для кодера из задачи 7.3, используя передаточную функцию.
7.9. Пусть кодовые слова в схеме кодирования имеют следующий вид.
a=000000
b=101010
c=010101
d=111111
Если по двоичному симметричному каналу принимается последовательность 111010 и при этом осуществляется декодирование по принципу максимального правдоподобия, то каким будет декодированный символ?
7.10. Пусть на двоичном симметричном канале (binary symmetric channel — BSC) используется кодер со степенью кодирования 1/2 и К=3, как показано на рис. 7.3. Допустим, что начальным состоянием кодера будет 00. На выходе канала BSC принимается последовательность Z=(110000101l остальное все ”0”).
а) Найдите на решетчатой диаграмме максимально правдоподобный путь и определите первые 5 декодированных информационных битов. При наличии двух сливающихся путей выбирайте верхнюю ветвь.
б) Определите канальные биты в Z, которые подверглись искажению в ходе передачи.
7.11. Выясните, какие из следующих ниже кодов со степенью кодирования 1/2 будут катастрофическими.
a)![]() ,
,![]()
б)![]() ,
,![]()
в)![]() ,
,![]()
г)![]() ,
,![]()
д)![]() ,
,![]()
е)![]() ,
,![]()
7.12. а) Рассмотрим сигнал BPSK с когерентным обнаружением, кодируемый с помощью кодера, показанного на рис. 7.3. Найдите верхнюю границу вероятности появления битовой ошибки, ![]() , если номинальное значение
, если номинальное значение ![]() равно 6 дБ. Предполагается жесткое декодирование.
равно 6 дБ. Предполагается жесткое декодирование.
б) Сравните значение ![]() с не кодированным случаем и определите выигрыш в отношении сигнал/шум.
с не кодированным случаем и определите выигрыш в отношении сигнал/шум.
7.13. С помощью последовательного декодирования изобразите путь вдоль древовидной диаграммы, показанной на рис. 7.22, если принята последовательность 0111000111. Критерием отката будет три несовпадения.
7.14. Повторите пример декодирования из задачи 7.13, воспользовавшись декодированием с обратной связью при длине упреждения 3. В случае появления связи выбирайте верхнюю часть дерева.
7.15. На рис. 37.5 показан сверточный кодер с длиной кодового ограничения, равной 2.
а) Нарисуйте диаграмму состояний, древовидную и решетчатую диаграммы.
б) Допустим, что от этого кодера поступило сообщение 1 10010. Декодируйте это сообщение, воспользовавшись алгоритмом декодирования с обратной связью и считая длину упреждения равной 2.
7.16. С помощью данных об ответвляющемся слове решетки кодера на рис. 7.7, декодируйте последовательность Z=(0111000111, остальные все "0"), считая, что используется жесткая схема принятия решений и алгоритм декодирования Витерби.
7.17. Рассмотрим сверточный кодер со степенью кодирования 2/3, показанный на рис. 37.6. За раз в кодер подается k = 2 бит; n = 3 бит подается на выход кодера. Имеется kK=4 разряда регистра, и длина кодового ограничения равна К = 2 в единицах 2-битовых байтов. Coстояние кодера определяется как содержимое К-1 крайних правых разрядов k-кортежа. Нарисуйте диаграмму состояния, древовидную и решетчатую диаграммы.
7.18.Найдите детекторное значение спектральной плотности отношения сигнал/шум ![]() , требуемое для получения скорости передачи декодированных данных в 1 Мбит/с, при вероятности появления ошибки
, требуемое для получения скорости передачи декодированных данных в 1 Мбит/с, при вероятности появления ошибки ![]() . Предположите, что применяется двоичная некогерентная модуляция FSK. Также считайте, что осуществляется сверточное кодирование и
. Предположите, что применяется двоичная некогерентная модуляция FSK. Также считайте, что осуществляется сверточное кодирование и
![]() ,
,
где ![]() и
и ![]() — это вероятности появления ошибок внутри и вне декодера.
— это вероятности появления ошибок внутри и вне декодера.
7.19. Исходя из табл. 7.4, разработайте двоичный сверточный кодер со степенью кодирования 1/2 и К = 4.
а) Нарисуйте его блок-схему.
б) Нарисуйте решетку кодирования и обозначьте на ней состояния и ответвляющиеся слова.
в) Подберите ячейки, которые должны быть реализованы в алгоритме ACS.
7.20. Для следующей демодулированной последовательности выполните мягкое декодирование, используя код со степенью кодирования 1/2 и К = 3, который описывается схемой кодера, изображенной на рис. 7.3. Сигналы — это квантованные на 8 уровней целые числа от 0 до 7. Уровень 0 представляет собой идеальный двоичный 0, а уровень 7 — идеальную двоичную 1. Вход декодера: 6, 7, 5, 3, 1, 0, 1, 1, 2, 0, где крайнее левое число является самым первым. Декодируйте первые два бита данных, используя решетчатую диаграмму декодирования. Предположите, что кодер начинает из состояния 00 и процесс декодирования полностью синхронизирован.
Вопросы для самопроверки
7.1.Зачем нужна периодическая очистка регистра при сверточном кодировании (См. разделы 7.2.1 и 7.3.4)?
7.2. Дайте определение состоянию системы (см. раздел 7.2.2).
7.3. Что такое конечный автомат (см. раздел 7.2.2)?
7.4. Что такое мягкая схема принятия решений и насколько более сложным является мягкое декодирование по алгоритму Витерби в сравнении с жестким декодированием (см. разделы 7.3.2 и 7.4.8)?
7.5. Каково иное (описательное) название двоичного симметричного канала (binary symmetric channel — BSC) (см. раздел 7.3.2.1)?
7.6. Опишите расчеты процедуры сложения, сравнения и выбора (add-compare-select ASQ), которые осуществляются в ходе декодирования по алгоритму Витерби (см. раздел 7.3.5).
7.8. На решетчатой диаграмме ошибка соответствует выжившему пути, который сначала расходится, а затем снова сливается с правильным путем. Почему пути должны повторно сливаться (см. раздел 7.4.1)?