1.1. Периоды создания и развития вычислительной техники
3. Данные, типы элементарных данных
4. Структуры данных и структурированная память
5. Виды памяти и ее характеристики
6.1. Типы процессоров. Арифметические процессоры
8.1. Назначение операционной системы
8.2. Эволюция операционных систем
8.3. Классификация операционных систем
8.4. Основные понятия операционных систем
8.5. Основные подсистемы операционных систем
1. Историческая справка
1.1. Периоды создания и развития вычислительной техники
В истории развития вычислительных машин различают домеханический, механический, электрический и электронный периоды. Рассмотрим каждый из них подробнее.
1.1.1. Домеханический период
Простым и эффективным приспособлением для счета, известным уже в V−IV вв. до н.э. в Греции и Западной Европе, был так называемый абак, представляющий собой пластину, выполненную из различных материалов, покрытую слоем пыли. На ней острой палочкой проводили линии и в получившихся колонках по позиционному принципу размещали какие–нибудь предметы, например, камешки или палочки. В Древнем Риме абак представлял собой пластину, имеющую полосковые углубления, в которых располагались счетные кости или шарики. Вычисления производились путем перекладывания в определенном порядке камешков, костей и т.п. Китайцы на аналогичном приспособлении (суан–пан) в XII−XIII вв. научились выполнять такие сложные математические операции, как извлечение корня квадратного и корня кубического. С его помощью они решали линейные уравнения и считали, что таким образом можно выполнить любую математическую операцию. Они же пришли к выводу, что для выполнения операций необходимы определенные правила — алгоритмы. От абака на рубеже XVI−XVII вв. произошли и русские счеты, которыми пользовались чуть не до конца XX века.
Великим творцом эпохи Возрождения Леонардо да Винчи (1452−1519 гг.) был разработан эскиз тринадцатиразрядного суммирующего устройства с десятизубыми колесами. Позднее по этому эскизу фирма IBM в целях рекламы построила работоспособную машину.
Знаменательным событием в области усовершенствования инструментального счета было изобретение логарифмов. В 1614 г. шотландский математик Джон Непер (1550−1617 гг.) опубликовал трактат «Описание удивительных таблиц логарифмов» — первое руководство по вычислениям с помощью логарифмов. Изобретение логарифмов позволило существенно упростить выполнение операций умножения и деления, которые были сведены к более простым арифметическим операциям сложения и вычитания. Непер изобрел также палочки для счета, которые впоследствии получили название палочек Непера. Палочки Непера, как и сам метод, быстро получили распространение в Европе и были одно время даже более популярны, чем логарифмы.
Открытие логарифмов послужило основой для создания логарифмической линейки, появление прототипа которой относят к началу XVII века. Первые логарифмические линейки были изобретены в Англии. Почти 3,5 столетия логарифмическая линейка господствовала среди всех счетных средств.
1.1.2. Механический период
Биографии механических вычислительных машин ведутся от машины восемнадцатилетнего французского математика и физика Блеза Паскаля (1623–1662 гг.). Первую модель вычислительной машины, которая получила распространение и могла выполнять арифметические операции сложения и вычитания, он создал в 1642 г. В 1645 г. арифметическая машина «Паскалина», или «Паскалево колесо», получает законченный вид. До настоящего времени сохранилось восемь его машин. Одна из них находится в Музее искусств и ремесел в Париже, где собрана полная коллекция математических инструментов (в том числе и модель арифмометра русского ученого П.Л. Чебышева).
Первая счетная машина, которая механически производила сложение, вычитание, умножение и деление была изобретена в 1670 г. немецким математиком, физиком, философом и изобретателем Готфридом Вильгельмом Лейбницем (1646–1716 гг.). Машина получила название арифмометр, ее окончательный вариант был завершен в 1710 г. Но машина была еще несовершенна, а потому не получила широкого распространения. Однако арифмометр Лейбница содержал уже почти все принципы работы позднейших механических арифмометров.
В XIX веке были сделаны открытия в области физики, станкостроения и автоматизации производства, которые положили начало интенсивному развитию вычислительной техники. В 1801–1804 гг. французский изобретатель Ж.М. Жаккар впервые использовал перфокарты для управления автоматическим ткацким станком.
Самым значительным событием XIX века в области создания вычислительной техники стал проект разностной машины английского математика Чарльза Бэббиджа (1791–1871 гг.), впервые в истории высказавшего идею создания вычислительных машин с программным управлением. Работать над машиной Ч. Бэббидж начал в 1812 г., к 1822 г. он построил действующую разностную машину и рассчитал на ней таблицу квадратов. Но более совершенную машину изготовить не удалось, поскольку в то время развитие техники и производство точных механизмов находились на недостаточно высоком уровне.
Совершенствуя разностную машину, ученый увидел возможность создания нового устройства, способного выполнять сложные вычислительные алгоритмы. В 1833 г. он приступил к работе над машиной, которую назвал аналитической. Она должна была отличаться большей скоростью и иметь более простую конструкцию, чем разностная машина.
Аналитическая машина состояла из трех основных блоков: устройства для хранения чисел и системы, которая передает эти числа от одного узла машины к другому (склад); устройства, позволяющего выполнять арифметические операции (фабрика); устройства для управления последовательностью действий машины. В конструкцию аналитической машины входило также устройство для ввода исходных данных и печати полученных результатов, т. е. ввод–вывод. Предполагалось, что машина будет действовать по программе, которая задавала бы последовательность операций и последовательность передач чисел со склада на фабрику и обратно.
С 1841 г. занялась изучением аналитической машины Ч. Бэббиджа Ада Августа Байрон (1815–1852 гг.), по мужу Лавлейс. О машине Ч. Бэббиджа Ада Лавлейс писала, что «аналитическая машина вышивает алгебраические узоры так же, как станок Жаккара вышивает цветочки и листочки». А. Лавлейс разработала первые программы для аналитической машины, заложив тем самым теоретические основы программирования. Она впервые ввела понятие цикла операции. Ей принадлежат некоторые термины, употребляемые программистами и сейчас, например, рабочие ячейки. В единственном своем труде — в «Комментариях» она высказала очень важную мысль о том, что аналитическая машина может решать такие задачи, которые из–за трудности вычислений практически невозможно решить вручную. Так впервые машина была рассмотрена не только как механизм, заменяющий человека, но и как устройство, способное выполнить работу, превышающую возможности человека. В наши дни А. А. Лавлейс по праву называют самым первым программистом в мире.
Ч. Бэббиджу так и не удалось реализовать свой проект по созданию универсальной вычислительной машины: cлишком сложной оказалась задача ее построения на основе средств той эпохи — штифтов, рычагов, зубчатых колес, объединенных сложнейшими кинематическими связями. Задолго до появления электронных вычислительных машин он заложил их теоретические основы, разработал принципы их построения, их главные узлы, предсказал пути развития вычислительной техники.
В XIX веке создаются счетные устройства и машины в России. В 1828 г. генерал–майор русской армии Ф.М. Слободской создает счетные приборы, которые вместе со специальными таблицами позволяли сводить арифметические действия к сложению и вычитанию. В 1845 г. З.Я. Слонимский получает патент на счетный прибор — суммирующую машину «Снаряд для сложения и вычитания». В 1867 г. российский ученый В.Я. Буняковский создает счетный механизм, основанный на принципе действий русских счетов. Русские ученые и инженеры внесли значительную лепту и в разработку конструкции арифмометров. Крупнейший русский математик и механик П.Л. Чебышев создает в 1878 г. оригинальный арифмометр с непрерывной передачей десятков. Этот аппарат выполнял суммирование и вычитание. В 1881 г. он изобрел приставку к своему прибору для умножения и деления. В 1880 г. петербургский инженер В.Т. Однер создает в России арифмометр с зубчаткой с переменным числом зубцов, а в 1890 г. налаживает массовый выпуск усовершенствованных арифмометров, нашедших применение во всем мире. Данные в арифмометр вводились вручную, а привод осуществлялся вращением рукоятки. Простота работы с арифмометрами и достаточная надежность сделали их популярными. Их модификация «Феликс» выпускалась в СССР до 50–х годов XX века. До 70–х гг. XX века выпускались электромеханические арифмометры (так называемые клавишные машины), отличавшиеся от своих предков тем, что их не требовалось вращать вручную. Все они были снабжены электроприводами и работали автоматически, делая нужное число оборотов и передвигая каретку без участия оператора.
В XIX столетии рост промышленности и транспорта и расширение коммерческой деятельности банков сделали построение быстродействующих счетных машин актуальной задачей. Но по–настоящему удачная конструкция многоразрядной клавишной суммирующей машины была предложена лишь в 1885 г. в США. Это сделал механик Дорр Э. Фелт (Фельт), назвавший свою машину комптометром. Практически одновременно с ним начинает работу над бухгалтерской машинойУильям С. Бэрроуз. В конце 1885 г. ему удалось создать машину, которая печатала вводимые числа, суммировала их и затем печатала результат. В 1886 г. У.С. Бэрроуз создает первую в мире фирму по производству счетных машин.
Важный шаг на пути автоматизации вычислений был сделан американцем Г. Холлеритом (1860–1929 гг.), который изобрел электромеханические машины для вычислений с помощью перфокарт, получившие название счетно–аналитических машин. Работая с 1882 г. в Массачусетском технологическом институте и затем в Бюро патентов США, он начал разрабатывать машины для механизации обработки данных переписи. В 1888 г. он создает особое устройство — табулятор, в котором обрабатывается информация, нанесенная на перфокарты. Перфокарты на специальной машине могли сортироваться по выбранному признаку, числа, пробитые в перфокартах, могли суммироваться, а сумма — пробиваться в перфокарте или печататься. В 1884–1889 гг. он оформил ряд патентов на устройства для статистической обработки информации. Система Г. Холлерита включала перфокарту, перфоратор, сортировальную машину и табулятор. В 1896 г. Г. Холлерит основал фирму по выпуску перфокарт и счетно–перфорационных машин (СПМ). В дальнейшем она была преобразована в известную фирму–производитель вычислительной техники — IBM. Развитие СПМ шло до 50–х годов. С появлением электронной техники возникли комбинированные системы, в которых вычислительные функции были расширены за счет введения в комплект машин электронных вычислителей, а носителем информации по–прежнему оставалась перфокарта. Такие гибридные машины выпускались как за рубежом, так и в нашей стране: IBM–604 (США), ЭВ–80, «Рута», М–5000 (СССР). В 1892 г. У. Барроуз выпускает первый коммерческий сумматор.
В 1904 г. известный русский математик, академик А.Н. Крылов предложил конструкцию машины для решения обыкновенных дифференциальных уравнений, которая была построена в 1912 г. В своих «Лекциях о приближенных вычислениях» он углубил теорию и привел описание различных механических систем для вычисления интегралов, гармонического анализа. Академик А.Н. Крылов изобрел также механический интегратор, развивающий принцип планиметра — прибора для вычисления площадей.
В 1919 г. академик Н.Н. Павловский создал метод исследования при помощи аналого–математического моделирования и дал ему полное теоретическое обоснование. Он же успешно применил новое средство вычислительной техники — аналоговую вычислительную машину (АВМ), которая была создана для реализации разработанного метода. Этот метод успешно развивался и действовал до 60–х гг., когда он был заменен цифровым моделированием на ЭВМ. Таким образом, развитие аналоговых вычислительных машин в 20–30–х гг. XX века обогнало развитие цифровой техники, так как в этот период еще не было технологической базы, необходимой для создания универсальных ЭВМ. В области цифровой техники продолжала развиваться линия арифмометров и СПМ для выполнения учетных и статистических расчетных работ.
Одной из технических предпосылок создания вычислительных машин было изобретение лампового диода и триода. В 1904 г. Дж. Флеминг (Великобритания) изобрел первый ламповый диод, а в 1906 г. Ли де Форест и Р. Либен (США) — первый триод. Но эра ЭВМ начинается с изобретения лампового триггера. В 1918 г. русский ученый М.А. Бонч–Бруевич изобрел триггер, имевший только два устойчивых положения равновесия: «открыто», «закрыто». Это изобретение имело большое значение для создания в дальнейшем современных вычислительных машин. В 1919 г. независимо от М.А. Бонч–Бруевича такой же прибор изобрели американцы У. Икклз (Экклз) и Ф. Джордан. Триггерные схемы постепенно стали широко применяться в электронике для переключения и релейной коммутации.
В 1931 г. французский инженер Р.–Л.В. Валтат выдвинул идею использования двоичной системы счисления при создании механических счетных устройств.
В начале XX века были проведены исследования в области полупроводников и сконструирована первая электронно–лучевая трубка.
В 1907 г. русский ученый Б.Л. Розинг заявил патент на использование в телевидении электроннолучевой трубки. К середине 30–х гг. XX столетия в результате разработок В.К. Зворыкина и Ф. Франсуорта в США, К. Свинтона в Великобритании, В.П. Грабовского, С.И. Катаева, А.П. Константинова, Б.Л. Розинга, П.В. Тимофеева и П.В. Шмакова в СССР появляются первые системы электронного телевидения.
В 1936 г. английский математик Алан Тьюринг (1912–1954 гг.) и независимо от него американский математик и логик Э.Л. Пост (1879–1954 гг.) выдвинули и разработали концепцию абстрактной вычислительной машины.
А. Тьюринг опубликовал в 1936 г. статью с доказательством того, что любой алгоритм может быть реализован с помощью дискретного автомата. Он предложил абстрактную схему такого автомата, получившего название машины Тьюринга и положившего начало целому направлению в теории автоматов. Машина Тьюринга — гипотетический универсальный преобразователь дискретной информации, теоретическая вычислительная система. Тьюринг и Пост показали принципиальную возможность решения автоматами любой проблемы при условии возможности ее алгоритмизации с учетом выполняемых им операций. Этими работами теоретически была доказана возможность создания универсальной цифровой вычислительной машины (ЦВМ).
Перед второй мировой войной А. Тьюринг начал разрабатывать вычислительную машину с широкими логическими возможностями.
За три года он разработал первый проект электронного мозга — автоматической вычислительной машины АСЕ — и первым подготовил ряд программ. В 1947 г. он занимается изучением проблемы обучения вычислительной машины.
В 1936 г. немецкий инженер–кибернетик К. Зюс начал работы по созданию универсальных автоматических цифровых машин с программным управлением на механических элементах. Это была последняя разработка, относящаяся к механическому периоду в истории развития вычислительных машин.
1.1.3. Электрический период
К 30–м годам XX века стала очевидной связь между релейными схемами и алгеброй логики (булевой алгеброй), основы которой заложил английский математик и логик Джордж Буль (1815–1864 гг.) в работе 1847 г. «Математический анализ логики». Идеи своей алгебры он развил в вышедшей в свет в 1854 г. работе «Исследование законов мышления». Когда появилась принципиальная возможность создания средств вычислительной техники на электрической базе, логические операции, введенные Дж. Булем, оказались весьма полезны. Они изначально ориентированы на работу только с двумя сущностями: истина и ложь. Нетрудно понять, как они пригодились для работы с двоичным кодом, который в вычислительных машинах представляется всего двумя сигналами: выключено и включено (ноль и единица). Начиная с 30–х гг. XX века появляются вычислительные машины, использующие логические схемы для электромагнитных реле и оперирующие перфокартами. Эти машины могли выполнять довольно сложные арифметические вычисления.
Первая удачная попытка построить универсальную цифровую машину была предпринята в 1937 г. в США математиком Говардом Айткеном. Эта машина получила название вычислительной машины с автоматическим управлением последовательностью операций и известна под именем «Марк–1». Над первым вариантом машины Г. Айткен работал до 1944 г., машина создавалась на базе фирмы IBM и имела программное управление, программа набиралась на коммутационных досках и переключателях. Машина была выполнена на релейных и механических элементах. Это еще не была машина с хранимой и гибко изменяющейся программой, однако она уже показала возможность построения автоматических вычислительных машин, состоящих из большого числа логических элементов. Арифметическое и запоминающее устройства были выполнены на электромеханических устройствах. Основным логическим элементом в схемах, как и в СПМ, были реле. Посравнению с СПМ машина «Марк–1» имела достаточно длинную последовательность программных кодов и хорошее для своего времени быстродействие. Но, как и всякое механическое устройство, машина не обладала тем быстродействием, которое позволило бы осуществить качественный скачок в технологии вычислений. Улучшенная конструкция на реле повышенной надежности легла в основу ЦВМ «Марк–2».
Наряду с работами Г. Айткена приблизительно в то же время велась работа других групп, в результате которой было создано еще несколько электромеханических релейных машин. Так, в 1939 г. была закончена и в 1940 г. демонстрировалась релейная машина американского математика Дж. Штибитца «Модель–Г», которая выполняла 4 арифметических действия над комплексными числами. Дальнейшая успешная разработка малых специализированных машин на тех же принципах привела к созданию в 1944–1946 гг. универсальной релейной вычислительной машины «Модель–V».
В 1937 г. американский физик Джон В. Атанасов формулирует принципы автоматической вычислительной машины на ламповых схемах для решения систем линейных уравнений. В 1939 г. он создал вместе со своим аспирантом Кл. Берри работающую настольную модель ЭВМ. Две малые ЭВМ, созданные ими в период 1937–1942 гг., были прототипами большой ЭВМ для решения систем линейных уравнений, которая была готова в декабре 1941 г. В машине Д. Атанасова были разделены блоки арифметического и оперативно–запоминающего устройств. Первое было выполнено на радиолампах, а второе — на вращающемся барабане с конденсаторами. Внешняя память была выполнена на типовом перфокарточном оборудовании. Работала машина в двоичной системе счисления. Переводы из десятичной системы в двоичную и обратно были решены схемно.
В конце 30–х гг. С.А. Лебедев (1902–1974 гг.) в Институте электротехники АН УССР приступил к конструированию ЭВМ, работающей в двоичной системе счисления. В 1941 г. работа была прервана.
В 1939 г. в США Дж. Стибниц закончил работу над релейной машиной фирмы «Белл», начатую в 1937 г. Машина выполняла арифметические операции над комплексными числами в двоично–пятеричной системе их представления. Это был релейный интерпретатор, управляемый программной перфолентой. В 1940 г. был проведен эксперимент по управлению на расстоянии вычислительной машиной «Белл–1». А в 1942 г. Дж. Стибниц сконструировал вычислительное устройство с программным управлением «Белл–2».
В 1940 г. в США под руководством Джона (Яноша) фон Неймана (1903–1957 гг.) разработан компьютер MANIAC (Mathematical Analyzer Numerical and Computer).
К первым универсальным ЦВМ с программным управлениям на электромеханических элементах относят также машины, разработанные в Германии К. Зюсом к 1941 г. — «Зюс–2» и «Зюс–3». Машина «Зюс–3» была релейной, для нее был разработан язык программирования, она использовалась при расчетах ракет.
Одной из наиболее совершенных релейных вычислительных машин была советская машина РВМ–1, сконструированная в начале 50–х гг. выдающимся инженером Н.И. Бессоновым (1906–1963 гг.) и построенная в 1956 г. Эта машина успешно работала до 1966 г.
Главными недостатками релейных машин являлось отсутствие хранимой программы, что обусловливалось небольшим объемом оперативной памяти, и невысокая скорость работы, вызванная низким быстродействием электромеханических релейных переключателей.
1.1.4. Электронный период
В начале 40–х годов XX века потребность в автоматизации вычислений стала настолько велика, что над созданием машин типа построенных К. Зюсом и Г. Айткеном одновременно работало несколько групп исследователей. В США исследования с ЭВМ продолжил Джон Моучли, который в 1941 г. детально ознакомился с проектом Дж. В. Атанасова, а в 1942 г. предложил собственный проект вычислительной машины, предназначенной для военных целей. В 1943 г. начались работы над реализацией проекта Дж. Моучли по заданию Баллистической исследовательской лаборатории Армии США. Работы велись в Пенсильванском университете под руководством Дж. Моучли и инженера–электронщика Д.П. Эккерта. Ученые начали конструировать вычислительную машину на основе электронных ламп, а не электрических реле. Их машина, названная ENIAC (ЭНИАК) — Electronic Numerical Integrator and Computer (электронный цифровой компьютер), в основном была закончена в 1944 г., её окончательный вариант был введен в строй 15 февраля 1946 г.
ЭНИАК предназначался для использования при расчетах баллистических таблиц для орудий береговой обороны США. Первым практическим применением ЭНИАК было решение задач для проекта атомной бомбы в Лос–Аламосской лаборатории в штате Нью–Мексико. В последующее время ЭНИАК использовался в Америке в основном в военных целях: для составления артиллерийских таблиц и таблиц прицельного сбрасывания бомб с самолетов.
Приблизительно одновременно с постройкой ЭНИАК создавалась ЭВМ и в Великобритании с целью дешифровки кодов, которыми пользовались вооруженные сила Германии в период второй мировой войны. Математический метод дешифровки был разработан группой математиков, в число которых входил А. Тьюринг. В начале 40–х годов А. Тьюринг совместно с Х.А. Ньюменом в Блетчи сконструировали машину «Colossus–1», которая в 1943 г. начала работать и которую можно считать первым электронным компьютером. Хотя и ЭНИАК и «Colossus–1» работали на электронных лампах, они по существу копировали электромеханические машины: новое содержание (электроника) было втиснуто в старую форму (структуру доэлектронных машин).
В 1945 г. Дж. фон Нейман разработал концепцию электронно–вычислительной машины EDVAC (Electronic Discrete Variable Computer) с вводимыми в память программами и числами. Сама машина была завершена в 1950 г. Главными элементами концепции были: принцип хранимой программы и принцип параллельной организации вычислений, согласно которому операции над числом проводятся по всем его разрядам одновременно.
В 1946 г. вместе с Г. Гольдстейном и А. Берксом он написал и выпустил отчет «Предварительное обсуждение логической конструкции электронной вычислительной машины», в котором и были изложены основные принципы логической структуры ЭВМ нового типа.
Авторы всесторонне обосновывали предлагаемые принципы и давали технические проработки их реализации в новой машине. Они утверждали, что ЭВМ должна создаваться на электронной основе и работать в двоичной системе счисления. В ее состав должны входить: арифметическое устройство с представлением чисел в форме с плавающей точкой, центральное устройство управления, запоминающие устройства (в том числе оперативное запоминающее устройство для чисел и команд и связанное с ним внешнее запоминающее устройство большой емкости), устройства ввода данных и вывода результатов на печать. В системе команд должны быть команды условной и безусловной передачи управления.
Принципы Дж. фон Неймана определили на многие годы бурное развитие цифровой вычислительной техники. Более того, архитектура большинства ЭВМ с последовательным выполнением команд в программе получила название фон Неймановской архитектуры ЭВМ.
Но работа по созданию EDVAC шла медленно, и запущена машина в эксплуатацию была лишь в 1952 г. По окончании работ над EDVAC фон Нейман не оставлял идеи об использовании ЭВМ как универсального инструмента для решения сложных математических и логических задач. Уже после смерти ученого, по оставшимся после него рукописям, А. Беркс выпустил книгу «Теория самовоспроизводящих автоматов», содержание которой послужило основой для возникновения нового научного направления — теории клеточных автоматов, переросшей позже в теорию однородных структур. Эта теория лежит в основе создания ЭВМ с новой архитектурой (нейрокомпьютеров), интенсивно разрабатывающихся в настоящее время.
Первый компьютер, в котором были воплощены принципы фон Неймана, был построен в 1949 г. английским профессором Морисом В. Уилксом. Машина называлась EDSAC (Electronic Data Storage Automatic Computer) и имела оперативную память на ртутных линиях задержки.
Машина «Джониак», построенная в 1946–1952 годах и названная так в честь фон Неймана, имела память на электроннолучевой трубке специальной конструкции.Позднее здесь был применен для запоминающего устройства магнитный барабан, впервые использованный в 1947 г. в английской вычислительной машине, созданной под руководством Э. и К. Бут. Магнитная лента была впервые использована в 1951 г. на машине UNIVAC–1, построенной Дж. Моучли и Д.П. Эккертом. Это была первая большая вычислительная машина, созданная не по специальному заказу, а для продажи.
Несмотря на то, что исследования в области электроники в нашей стране были начаты на несколько лет позже, чем в США и Великобритании, в сжатые сроки был выполнен ряд проектов цифровых ЭВМ. Первые ЭВМ в нашей стране создавались для решения сложных и трудоемких математических задач. Работы над первой ЭВМ начались в 1946 г. группой ученых под руководством академика Сергея Алексеевича Лебедева в Институте электротехники АН УССР. В 1947 г. был закончен проект малой электронной счетной машины — МЭСМ. Основные опытно–конструкторские работы, монтаж и испытания прошли в 1949–1950 гг. В октябре 1951 г. машина была введена в эксплуатацию. Это была самая быстродействующая тогда машина в Европе. С ее помощью был решен ряд важных задач, в том числе расчет устойчивости магистральной линии электропередачи Куйбышев–Москва (1951 г.). Функциональная схема машины удовлетворяла всем принципам Дж. фон Неймана.
Осенью 1952 г. вступил в строй опытный образец машины БЭСМ (большая электронно–счетная машина), созданный в Институте точной механики и вычислительной техники под руководством С.А. Лебедева. По многим параметрам БЭСМ превосходила EDVAC, в ней были осуществлены решения, вошедшие в практику вычислительной техники только через несколько лет. БЭСМ–2 имела оперативную память на электронно–акустических линиях задержки, затем — на электронно–лучевых трубках и позже — на ферритовых сердечниках. Внешнее запоминающее устройство состояло из магнитных барабанов и магнитной ленты.
В Энергетическом институте АН СССР под руководством И.С. Брука и М.А. Карцева в 1952 г. была введена в действие машина М–2 средней мощности и малая машина М–3.
Серийное производство ЭВМ в нашей стране началось в 1953 г. Под руководством Ю.Я. Базилевского и Б.И. Рамеева была разработана машина «Стрела», выпускавшаяся малой серией. В 1955 г. в Пензе начался выпуск малой ЭВМ «Урал–1», созданной также под руководством Б.И. Рамеева. В 50–е годы разработаны серийные ЭВМ: в Ереване под руководством Ф.Т. Саркисяна — «Раздан», в Минске (В.В. Пржиялковскй и др.) — ЭВМ «Минск», а в Киеве — «Киев».
В 1958 г. самой мощной в Европе была советская ЭВМ М–20, созданная усилиями коллективов С.А. Лебедева и Ю.Я. Базилевского.
С переходом к серийному производству ламповых ЭВМ с хранимой программой начинается период машин первого поколения. Здесь история развития вычислительной техники переходит в историю поколений ЭВМ.
1.2. Поколения ЭВМ
1.2.1. Первое поколение
Первое поколение ЭВМ представляло собой машины дорогие, громоздкие, использовавшиеся только в крупных научных центрах для решения задач, связанных с исследованиями в области ядерной физики, ракетной техники, космоса и метеорологии. Машины этого поколения отличались большим потреблением энергии, низкой надежностью, сравнительно малым быстродействием. Программирование на них велось в машинных кодах. Эти машины создавались и производились с начала и до конца 50–х гг. XX века.
В эти годы появился ряд технологических, структурных и программных нововведений. В технологии наблюдались миниатюризация электронных ламп, улучшение их характеристик и постепенный переход к твердотельным элементам. Этот процесс начался заменой ламповых диодов полупроводниковыми и завершился заменой ламповых триодов транзисторами. Первые серийные универсальные ЭВМ, выполненные на транзисторах, выпущены в 1958 г. в США, Японии и ФРГ, в 1959 г. — в Великобритании, в 1960 г. — во Франции и в 1961 г. — в СССР («Раздан–2», главный конструктор Е.Я. Брусиловский). В системе запоминающих устройств важнейшим изобретением стало создание оперативной памяти на ферритовых сердечниках и долговременной памяти на магнитных дисках. В 1951 г. Дж. Рабинов (США) построил прототип дискового запоминающего устройства. В 1957 г. начался серийный выпуск машин с памятью на дисках.
В организации вычислительного процесса крупнейшим нововведением было совмещение во времени вычислений и ввода–вывода информации. Впервые это новшество применили в серийных моделях высокого класса, разработанных в США (IBM–704 (1956 г.) и IBM–709 (1958 г.)) и в СССР (М–20 (1958 г.)). В программировании к числу важнейших относятся разработки методов программирования в символических обозначениях и появление алгоритмических языков. В СССР в 1952–1953 гг. А.А. Ляпунов разработал операторный метод программирования, а в 1953–54 гг. Л.В. Канторович — концепцию крупноблочного программирования.
Таким образом, с первым поколением ЭВМ связаны разработки основ программирования, достижение сравнительно емкой и быстрой памяти, переход к ЭВМ на стандартных и специализированных блоках, разработка устройств ввода–вывода (УВВ) информации на перфокартах и перфолентах. Применение машин первого поколения дало возможность накопить опыт конструирования и использования программирования.
Характерные черты ЭВМ первого поколения:
- элементная база: электронно–вакуумные лампы, резисторы, конденсаторы. Соединение элементов — навесной монтаж проводами;
- габариты: ЭВМ выполнена в виде громоздких шкафов и занимает специальный машинный зал;
- быстродействие: 10–20 тыс. операций в секунду;
- эксплуатация: слишком сложна из–за частого выхода из строя;
- программирование: трудоемкий процесс в машинных кодах. Общение с ЭВМ требовало от специалистов высокого профессионализма.
1.2.2. Второе поколение
Второе поколение компьютеров обязано своим рождением транзистору — миниатюрному полупроводниковому прибору, заменившему электронные лампы. Транзистор сконструировали американские физики Уолтер Браттейн, Джон Бардин и Уильям Шокли в 1948 г. Первый промышленный биполярный транзистор был создан также в 1948 г.
В 1954 г. в мире выпускалось около 5 млн транзисторов, в 1958 г. — 200 млн, в 1963 г. — около 1.5 млрд. Использование транзисторов в радио– и вычислительной технике позволило уменьшить размеры и потребляемую мощность устройств.
Период машин второго поколения — наиболее короткий в истории вычислительной техники. Эти машины выпускались с конца 50–х и в начале 60–х годов XX века. Первый компьютер на транзисторах был создан фирмой NCR в США в 1954–1957 гг. Он назывался NCR–304. Всего в мире было изготовлено около 30 тыс. транзисторных ЭВМ, причем произошел крупный сдвиг в области их применения. Если в начале 50–х гг. ЭВМ использовались преимущественно для научно–технических расчетов, то в 60–е гг. первое место стала занимать обработка символьной информации, в основном экономической.
Единственная часть компьютера, где транзисторы не смогли заменить электронные лампы — это блоки памяти, но там стали использовать изобретенные к тому времени схемы на магнитных сердечниках. К середине 60–х годов появились и значительно более компактные внешние устройства для компьютеров, что позволило фирме Digital Equipment Corporation выпустить в 1965 г. первый мини–компьютер PDP–8.
Более дешевое производство новой элементной базы и использование печатных схем позволили удешевить и сами машины, уменьшить их габариты, повысить быстродействие и емкость памяти при достаточной надежности. В ЦВМ этого поколения получает развитие мультипрограммирование, т.е. совмещение во времени выполнения различных программ, а также переход от машинных к проблемно–ориентированным и универсальным алгоритмическим языкам. К 1967 г. насчитывалось уже около 1000 таких языков. В 1953–57 гг. в США под руководством Дж. Бейкуса разработан алгоритмический язык Fortran (Фортран) — «переводчик формул». В 1957 г. разработан первый вариант процедурно–ориентированного алгоритмического языка Algol (Алгол). В конце 50–х годов Дж. Маккарти в Массачусетском технологическом институте (МТИ, США) разрабатывает язык LISP (ЛИСП) для работ по проблеме искусственного интеллекта. В 1960 г. в США создается COBOL (Кобол) — язык, ориентированный на обработку коммерческой информации. В этом же 1960 г. С. Пейперт с коллегами из МТИ предлагают язык программирования LOGO (Лого), с помощью которого можно управлять «черепахой» — программной моделью малого робота.
В 1965 г. Дж. Кемени и Т. Курц в США разрабатывают язык программирования BASIC (Бейсик), который первоначально предназначался для вводного курса по информатике. BASIC — Beginner's All–purpose Symbolic Instruction Code, что может быть переведено как «многоцелевой символический код–инструкция для начинающих». Математическое и программное обеспечение становится фактором, определяющим стоимость и конструктивные решения машины.
Первые ЦВМ на полупроводниках в нашей стране начали создаваться с 1961 г. Для научных расчетов создаются ЭВМ средней мощности: в Москве — М–220 (разработчик В.С. Антонов), БЭСМ–3, БЭСМ–4; в Пензе — «Урал–11», «Урал–14», «Урал–16»; в Минске — «Минск–22», «Минск–23», «Минск–32»; в Ереване — «Раздан–2», «Раздан–3». В 1961 г. была создана первая в стране серийная универсальная полупроводниковая ЭВМ Днепр–1. Машина М–220 была совместима с БЭСМ–4 и продолжала линию М–20. Принципы совместимости машин внутри семейства и агрегатный принцип комплектации были осуществлены на серии «Урал–11» — «Урал–16» раньше, чем он был провозглашен и реализован на всемирно известной серии IBM–360, однако ограниченность производственной базы и малая численность системных программистов не позволяли разработчикам «Урала» распространить эти принципы в глобальном масштабе.
В машинах «Минск–22», «Минск–23», «Минск–32» появилось алфавитно–цифровое печатающее устройство (АЦПУ). Это был громоздкий, но надежный агрегат, который позволял печатать на перфорированной бумаге форматированный текст. В первой половине 70–х гг. самой распространенной машиной в СССР стала «Минск–32», имевшая неплохую операционную систему, мощные системы программирования, пишущую машинку в качестве терминала оператора.
В 1967–1969 гг. в Институте точной механики и вычислительной техники АН СССР под руководством С.А. Лебедева и В.А. Мельникова создаются первые полупроводниковые мини–ЭВМ для научных расчетов, под руководством Г.Е. Овсепяна в Ереване — «Наири–2», под руководством В.М. Глушкова в Киеве (институт кибернетики АН УССР) — «Мир–2». Для машин «Мир» создаются специальные входные языки Мир, Аналитик. В «Мир–2» впервые диалог с пользователем осуществляется с помощью дисплея со световым пером. В это же время в СССР развивается применение ЭВМ для управления технологическими процессами сбора и обработки экспериментальных данных в реальном масштабе времени, для планово–экономических расчетов. Сдана в эксплуатацию и рекомендована к массовому внедрению первая в стране автоматизированная система управления (АСУ) предприятия с массовым производством — «Львов». В институте кибернетики АН УССР создается управляющая ЭВМ «Днепр–2» с развитой системой прерывания, обеспечивающей одновременную работу с более 1600 входных и более 100 выходных аналоговых устройств.
Лучшей в мире ЭВМ второго поколения стала БЭСМ–6, созданная в Институте точной механики и вычислительной техники АН СССР под руководством С.А. Лебедева и В.А. Мельникова. БЭСМ–6 работала в мультипрограммном режиме, обладала высоким быстродействием (около 1 млн операций в сек.), по своей архитектуре была близка к ЭВМ третьего поколения. До 1973 г. она была одной из наиболее производительных однопроцессорных машин в мире. Машина имела систему автоматизированного программирования с входными языками: Фортран, Алгол–60, ЛИСП и др. Программное обеспечение разрабатывалось Л.Н. Королевым, М.Р. Шура–Бурой, Н.Н. Говоруном, Э.З. Любимским и др. В дальнейшем на БЭСМ–6 используется разработанная в Новосибирске под руководством А.П. Ершова α–система программирования с расширением языка Алгол–60. Эта машина широко использовалась при разработке и реализации отечественных космических программ. БЭСМ–6 выпускалась серийно до 1981 г. и использовалась на вычислительных центрах до конца 90–х гг.
Период машин второго поколения характеризуется крупнейшими сдвигами в архитектуре ЭВМ, их программном обеспечении, организации взаимодействия человека с машиной. Эти достижения в дальнейшем применяются в машинах третьего и четвертого поколений. Это в первую очередь относится к многопроцессорным системам, организации мультипрограммной работы, разделению времени. Формируются основы организации взаимодействия человека с машиной. Но с ростом требований к вычислительной технике, расширением сфер ее использования машины второго поколения перестают удовлетворять потребителей вследствие большой трудоемкости их производства и невысокой надежности из–за множества дискретных элементов и связей.
Характерные черты ЭВМ второго поколения:
- элементная база: полупроводниковые элементы; cоединение элементов – печатные платы и навесной монтаж;
- габариты: ЭВМ выполнены в виде однотипных стоек, для их размещения требуется специально оборудованный машинный зал,
в котором под полом прокладываются кабели, соединяющие между собой многочисленные автономные устройства;
- производительность: до 1 млн операций/с;
- эксплуатация: появились вычислительные центры (ВЦ) с большим штатом обслуживающего персонала, где устанавливались обычно несколько ЭВМ. При выходе из строя нескольких элементов производилась замена целиком всей платы, а не каждого элемента в отдельности, как в ЭВМ предыдущего поколения;
- программирование велось преимущественно на алгоритмических языках. Программисты передавали свои программы на перфокартах или магнитных лентах операторам ЭВМ на ВЦ для организации дальнейших расчетов на ЭВМ. Решение задач производилось в пакетном режиме, т. е. все программы вводились в ЭВМ подряд друг за другом, а их обработка велась по мере освобождения соответствующих ресурсов. Результаты решения распечатывались на специальной перфорированной бумаге.
1.2.3. Третье поколение
К 1964 г. появились ЭВМ третьего поколения на интегральных схемах (ИС), постепенно заменявших транзисторы. Период создания и внедрения ЭВМ третьего поколения занял по времени отрезок от начала 60–х до середины 70–х гг. Элементной базой этих компьютеров стали ИС, идея создания которых была предложена в 1952 г. инженером из Великобритании Дж. Даммером. В 1958 г. Джек Килби (США) решил задачу, как на одной пластине полупроводника получить несколько транзисторов. В 1959 г. Роберт Нойс (будущий основатель фирмы Intel, США) изобрел метод, позволивший создавать на одной пластине и транзисторы, и все необходимые соединения между ними. Полученные электронные схемы и стали называться интегральными схемами, или чипами.
В 1961 г. в продажу поступила первая, выполненная на пластине кремния интегральная схема, содержащая триггер на 6 элементах, в 1963 г. ИС имела 10–20 элементов, в 1967 г. — примерно 100, к 1970 г. — 1000, к 1975 г. — 30000, к 1982 г. — 300000 элементов на кристалле в несколько квадратных миллиметров.
В 1968 г. фирма Burroughs выпустила первый компьютер на интегральных схемах, а в 1970 г. фирма Intel начала продавать ИС памяти.
Использование ИС привело к резкому снижению габаритов ЭВМ, повышению их надежности, увеличению производительности. К тому же времени относится появление внешних запоминающих устройств на магнитных дисках, обладающих емкостью в сотни миллионов бит и высоким быстродействием. Основным режимом эксплуатации машин этого поколения является режим мультипрограммирования.
Начало периода машин третьего поколения связано с разработкой ЭВМ серии IBM–360, позднее — IBM–370 (IBM — International Business Machines Corporation), оказавшей огромное влияние на развитие вычислительной техники во всем мире. Выпуск машин IBM–360 был начат в США в 1965 г. Сущность идей, заложенных в проект IBM–360, заключалась в создании семейства машин на ИС, имеющих широкий диапазон производительности и совместимых на уровне машинных языков, периферийных устройств, модулей конструкции и системы элементов, а также операционных систем (ОС).
Наиболее значительным явлением в этот период было создание мини–ЭВМ. Сущность идеи состояла в такой минимизации аппаратуры, которая позволяла на уровне технологии середины 60–х гг. создать универсальные ЭВМ, способные осуществлять управление в реальном масштабе времени.
В этот период развитие ЭВМ в СССР проходило в направлении создания ЭВМ единой системы (ЕС ЭВМ), в основных чертах копирующих IBM–360 и IBM–370, программно–совместимых между собой, а также с ЭВМ типа IBM–360. При создании всех моделей ЕС ЭВМ ставились следующие задачи: улучшить соотношение между стоимостью и производительностью машин; увеличить объем оперативной памяти; повысить точность вычислений; разработать комплекс внешних устройств; обеспечить возможность создания многопроцессорных и многомашинных вычислительных систем.
К третьему поколению ЭВМ принадлежат и малые вычислительные машины СМ — семейство малых ЭВМ. Это были СМ–1, СМ–2, СМ–3 и СМ–4. Наличие запоминающих устройств различной емкости и быстродействия, стандартизация подключения к процессору устройств ввода–вывода символьной и графической информации открыли возможности использования СМ ЭВМ в различных измерительных, управляющих, информационных комплексах. Они сопрягались с ЕС ЭВМ как периферийные процессоры, удаленные терминалы, процессоры ввода–вывода.
В это же время в СССР выпускаются мини–ЭВМ «Мир–31», «Мир–32», «Наири–34», ЭВМ серии АСВТ М–6000 и М–7000 для управления технологическими процессами; на интегральных микросхемах — настольные мини–ЭВМ М–180 «Электроника–100, –200», «Электроника ДЗ–28», «Электроника НЦ–60» и другие.
Вклад отечественной науки в мировое развитие электронной вычислительной техники в этот период связан с идеями и разработками машины М–10 (1975 г., главный конструктор М. А. Карцев). М–10 была первой в мире промышленно освоенной многопроцессорной ЭВМ.
В структуру машин третьего поколения вводятся ОС, облегчающие программирование, связь пользователя с машиной, ее обслуживание. Также в состав этих машин включали системы, работающие в режиме реального масштаба времени — встроенные микропроцессоры, позволявшие практически немедленно обрабатывать всю поступающую от других систем, периферийных устройств и датчиков информацию и тут же посылать обратно управляющие сигналы. Мини–ЭВМ стали использоваться в станках с числовым программным управлением, для управления роботами–манипуляторами и т.п.
Однако компьютеры третьего поколения по–прежнему оставались сложными в обслуживании. Большим ЭВМ требовались специальные помещения, а малые плохо подходили для установки на сравнительно небольших движущихся объектах: самолетах, космических кораблях, где ЭВМ нужны для управления оборудованием, для вычисления курса. А высокая стоимость не позволяла использовать подобные компьютеры в недорогих технических устройствах.
Характерные черты ЭВМ третьего поколения:
- элементная база — интегральные схемы;
- габариты: малые ЭВМ — это в основном две стойки, дисплей. Они не нуждались, как ЕС ЭВМ, в специально оборудованном помещении;
- производительность: сотни тысяч — миллионы операций в секунду;
- эксплуатация: более оперативно производится ремонт стандартных неисправностей, но из–за большой сложности системной организации требуется штат высококвалифицированных специалистов. Незаменимую роль играет системный программист;
- технология программирования и решения задач: во многих вычислительных центрах появились дисплейные залы, где каждый программист мог подсоединиться к ЭВМ в режиме разделения времени. Как и прежде, основным оставался режим пакетной обработки задач;
- произошли изменения в структуре ЭВМ. Наряду с микропрограммным способом управления используются принципы модульности и магистральности. Модульность проявляется в построении компьютера на основе набора модулей — конструктивно и функционально законченных электронных блоков в стандартном исполнении. Под магистральностью понимается способ связи между модулями компьютера, когда все входные и выходные устройства подсоединены одними и теми же проводами (шинами). Это — прообраз современной системной шины;
- увеличились объемы памяти. Магнитный барабан вытесняется магнитными дисками. Появились дисплеи, графопостроители.
1.2.4. Четвертое поколение. Персональные компьютеры
Переход к машинам четвертого поколения — ЭВМ на больших интегральных схемах (БИС) происходил в середине и второй половине 70–х годов и завершился приблизительно к 1980 г. Машины этого поколения развивались, во–первых, в направлении создания мощных многопроцессорных систем, имеющих производительность до сотен миллионов операций в секунду, и, во–вторых, в направлении создания дешевых компактных мини– и микро–ЭВМ.
Большие ЭВМ четвертого поколения представляют собой многопользовательские машины с развитыми возможностями для работы с базами данных, с различными формами удаленного доступа. Они имеют несколько процессоров и ориентированы на выполнение определенных операций, процедур или на решение некоторых классов задач. Выпуск их стал увеличиваться, хотя их доля в общем парке постоянно снижается. Серия машин IBM S/390 продолжила линию машин IВМ–360 и IВМ–370. Они позволяют задавать переменную конфигурацию (число процессоров 1–10, емкость оперативной памяти 512– 81292 Мбайт, число каналов 3–256).
К числу машин четвертого поколения относятся и машины RS/6000, предназначенные для создания графических рабочих станций, Unix–серверов, кластерных комплексов. Первоначально эти машины предполагалось применять для обеспечения научных исследований.
К числу средних ЭВМ четвертого поколения относят ЭВМ типа AS/400 (Advanced Portable Model 3) — 64–разрядные «бизнескомпьютеры». Они предназначены в первую очередь для работы в финансовых структурах. В этих машинах особое внимание уделяется сохранению и безопасности данных, программной совместимости и т.д. Они могут использоваться в качестве основы серверов в локальных сетях, для управления сложными технологическими производственными процессами.
В период машин четвертого поколения стали серийно производиться супер–ЭВМ. Первым суперкомпьютером считается «Сгау–1» («КРЭЙ–1», проект С. Крея), установленный в Лос–Аламосе (США). Этот компьютер выполнял до 100 млн арифметических операций в секунду. В нашей стране похожие характеристики имела супер–ЭВМ «Эльбрус–2». Многопроцессорные комплексы «Эльбрус–2» и «Эльбрус–3» имели суммарное быстродействие соответственно 100 млн и порядка 1 млрд операций в секунду. Нашими учеными также была создана многопроцессорная вычислительная система ПС–2000, содержащая до 64 процессоров, которые управлялись общим потоком команд. В этой системе при распараллеливании процесса выполнения программ могло достигаться быстродействие до 200 млн операций в секунду.
Рост степени интеграции БИС стал технологической основой повышения производительности ЭВМ. В нескольких серийных моделях был преодолен рубеж 1 млрд операций в секунду. В 1985 г. начался серийный выпуск четырехпроцессорной «КРЭЙ–2» производительностью 200 млн скалярных и 1,2 млрд векторных операций в секунду, в 1990 г. — выпуск японской четырехпроцессорной SX–344.
К числу наиболее значительных разработок конца 80–х—начала 90–х гг. относится ЭВМ «КРЭЙ–3». Проект предусматривал 16–процессорную организацию машины и выполнение 8 млрд скалярных и 16 млрд векторных операций в секунду.
С развитием науки и техники выдвигаются новые задачи, требующие больших объемов вычислений. Особенно эффективно применение супер–ЭВМ при решении задач проектирования, в которых натурные эксперименты оказываются дорогостоящими, недоступными или практически неосуществимыми. В этом случае ЭВМ позволяет методами численного моделирования получить результаты вычислительных экспериментов, обеспечивая приемлемое время и точность решения, т.е. решающим условием необходимости разработки и применения подобных ЭВМ является экономический показатель «производительность/стоимость». Например, при создании супер–ЭВМ GF–11 (Gigaflop–11) с быстродействием 11 млрд оп/сек предварительные расчеты показали, что применение этой системы позволит решить целый комплекс новых задач. Одной из таких задач было уточнение массы протона на основе квантовой хромодинамики — доминирующей теории, пытающейся описать первичную структуру материи. При использовании новой ЭВМ эта работа должна была быть выполнена за 1,5–4 месяца. Решение же этой задачи на существующей вычислительной технике требовало около 15 лет. Еще одним примером крупномасштабных задач считается задача разработки новых схем СБИС (сверхбольших ИС) для следующих поколений ЭВМ. Супер–ЭВМ позволяют по сравнению с другими типами машин точнее, быстрее и качественнее решать подобные задачи, обеспечивая необходимый приоритет в разработках перспективной вычислительной техники. Дальнейшее развитие супер–ЭВМ связывается с использованием направления массового параллелизма, при котором одновременно могут работать сотни и даже тысячи процессоров. В настоящее время супер–ЭВМ используются для решения крупномасштабных вычислительных задач, для обслуживания крупнейших информационных банков данных.
Требуемое количество супер–ЭВМ для отдельной страны, такой как Россия, должно составлять 100–200 штук, больших ЭВМ — тысячи, средних — десятки и сотни тысяч, ПЭВМ — миллионы, встраиваемых микро–ЭВМ — миллиарды.
История создания персональных компьютеров берет свое начало с момента создания микропроцессора (МП). Микропроцессор — это программируемое логическое устройство, выполненное на основе одной или нескольких БИС. Его задача — декодировать команды вложенной в него программы и реализовать их. Микропроцессоры обладают высокой надежностью и производительностью, малыми размерами и низкой стоимостью. Это позволяет встраивать микропроцессоры в контрольно–измерительные приборы, промышленно–технологи-ческое оборудование, бытовые приборы. Создание микропроцессора стало наиболее крупным сдвигом в электронной вычислительной технике, связанным с применением БИС, поскольку именно на его основе были созданы микро–ЭВМ. Микрокомпьютер (микро–ЭВМ) представляет собой вычислительную систему, включающую микропроцессор, память и устройства ввода–вывода. Микро–ЭВМ обладают достаточно высокими эксплуатационными параметрами, сравнимыми с аналогичными параметрами средних ЭВМ. Габариты микро–ЭВМ, требования к условиям эксплуатации и потребление электроэнергии находятся в границах обычных требований, предъявляемых к бытовым электроприборам. Область применения микро–ЭВМ весьма широка. Они входят составной частью в измерительные комплексы, системы числового программного управления, управляющие системы различного назначения.
В 1970 г. Маршиан Эдвард Хофф из фирмы Intel сконструировал интегральную схему, аналогичную по своим функциям центральному процессору (ЦП) большой ЭВМ. В конечном счете на одном кремниевом кристалле ему удалось сформировать минимальный по составу аппаратуры процессор, а на других БИС — оперативную и постоянную память. Так появился первый микропроцессор Intel–4004, который был выпущен в продажу в конце 1970 г. Конечно, возможности Intel–4004 были куда скромнее, чем у центрального процессора большой ЭВМ — он работал гораздо медленнее и мог обрабатывать одновременно только 4 бита информации (процессоры больших ЭВМ обрабатывали 16 или 32 бита одновременно). Но в 1973 г. фирма Intel выпустила 8–битовый микропроцессор Intel–8008, а в 1974 г. — его усовершенствованную версию Intel–8080, которая до конца 70–х годов стала стандартом для микрокомпьютерной индустрии.
Выпуск первого микропроцессора служит ориентировочной датой начала микропроцессорной революции. Она шла двумя путями: МП встраиваются непосредственно в аппаратуру (связи, производственную, медицинскую, бытовую и т. д.) и служат основой построения соответствующих управляющих устройств; на базе МП создаются как микро–ЭВМ, так и суперсистемы. В ходе микропроцессорной революции систематически совершенствовалась технология БИС, с чем связана стремительная смена поколений МП. В 80–е гг. создаются мощные 32–разрядные МП, содержащие схемы памяти, контроля и диагностики и служащие элементной базой для создания ЭВМ пятого поколения.
С микропроцессорной революцией непосредственно связано одно из важнейших событий в истории ЭВМ — создание и широкое применение персональных ЭВМ (ПЭВМ).
С их распространением начинается фаза всеобщей компьютеризации, которая продолжается и сегодня. С 1980 г. по 1990 г. выпуск ПЭВМ в США вырос с 0,37 млн до 25 млн шт. и в настоящее время этот класс машин абсолютно доминирует в мировом парке ЭВМ.
В начале 1975 г. появился первый коммерчески распространяемый компьютер «Альтаир–8800» (фирма MITS, США), построенный на основе микропроцессора Intel–8080. Хотя возможности его были весьма ограничены (оперативная память составляла 256 байт, клавиатура и экран отсутствовали), его появление было встречено с большим энтузиазмом. Покупатели этого компьютера снабжали его дополнительными устройствами: монитором, клавиатурой, блоками расширения памяти и т.д. В конце 1975 г. Пол Аллен и Билл Гейтс (будущие основатели фирмы Microsoft) создали для компьютера «Альтаир»интерпретатор языка Basic, что позволило пользователям достаточно просто общаться с компьютером и легко писать для него программы. Позднее потребности в ПЭВМ возрастали невиданными темпами. Так, в 1983 г. в мире было продано 10 млн персональных компьютеров — небывалое число для вычислительной техники.
В дальнейшем компьютеры стали продаваться в полной комплектации, с клавиатурой и монитором. Росту объема продаж ПК способствовали также многочисленные программы, разработанные для деловых применений (например, редактор текстов WordStar и табличный процессор VisiCalc соответственно 1978 и 1979 гг.). Эти программы сделали для делового мира покупку компьютеров выгодным вложением денег: с их помощью стало возможно эффективнее выполнять бухгалтерские расчеты, составлять документы и т.д. В результате оказалось, что для многих организаций необходимые им расчеты стало возможно выполнять не на больших или мини–ЭВМ, а на ПК, что значительно дешевле.
Революция в индустрии персональных компьютеров была совершена двумя фирмами — IBM и Apple Computer, соперничество которых способствовало бурному развитию высоких технологий, улучшению технических и пользовательских качеств персональных компьютеров. При этом первым всенародным персональным компьютером стал компьютер фирмы Apple Computer.
История этой фирмы началась в 1976 году, когда Стивен Джобс и Стивен Возник создали свою первую модель, назвав ее «Apple» (яблоко). Развитием работ в данном направлении стал компьютер Apple II, созданной на 8–разрядном микропроцессоре фирмы Motorola.
Компьютер Apple II обладал модульной конструкцией с возможностью расширения системы. Техническая информация о компьютере была опубликована, что дало возможность др. производителям выпускать аппаратуру, которой пользователи могли дополнять свои компьютеры. Другими словами, архитектура Apple II была открытой, что явилось новинкой для того времени.
В 1981 году на рынке персональных компьютеров появилась фирма IBM, которая во много раз превосходила по своим размерам и финансовым возможностям фирму Apple. Это связано с тем, что распространение ПЭВМ к концу 70–х годов привело к снижению спроса на большие и мини–ЭВМ. В качестве основного микропроцессора компьютера IBM был выбран микропроцессор Intel–8088. В данном компьютере были использованы и другие комплектующие различных фирм, а его программное обеспечение было поручено разработать небольшой фирме Microsoft.
В августе 1981 г. новый компьютер под названием IBM PC был представлен публике и вскоре после этого приобрел большую популярность у пользователей. Через один–два года IBM PC занял ведущее место на рынке, вытеснив модели 8–битовых компьютеров, став фактически стандартом персонального компьютера. Сейчас такие компьютеры (совместимые с IBM PC) составляют более 90% всех производимых в мире ПК. Основой популярности IBM PC является заложенная в нем возможность усовершенствования его отдельных частей и использования новых устройств. Фирма IBM сделала компьютер не единым неразъемным устройством, а обеспечила возможность его сборки из частей, изготовленных независимо различными фирмами.
В 1983 г. был выпущен компьютер IBM PC XT (Personal Computer Extended Technology), имеющий встроенный жесткий диск, в 1985 г. — компьютер IBM PC AT (Personal Computer Advanced Technology) на основе нового микропроцессора Intel–80286, работающий в 3–4 раза быстрее IBM PC XT.
Однако очень скоро другие фирмы начали собирать компьютеры, совместимые с IBM PC, и продавать их значительно дешевле аналогичных компьютеров фирмы IBM. Уже в 1982 г. на рынке появились точные копии компьютеров фирмы IBM, так называемые клоны, выпускаемые другими фирмами, поэтому сегодня мы говорим об IBM–совместимых компьютерах, сохраняющих архитектуру и технологические особенности первоначального IBM PC. Принцип открытой архитектуры лишил фирму IBM монополии на выпуск ПК класса IBM PC. К 1984 г. IBM PC–совместимые компьютеры производили уже около 50 компаний, а к концу 1986 г. ежегодная продажа IBM PC–совместимых компьютеров сторонними фирмами превзошла по объему продажу оригинальных компьютеров IBM. При этом первые компьютеры на основе 32–разрядного микропроцессора Intel–80386 были выпущены уже не IBM, a фирмой Compaq Computer. В конце 80–х гг. фирма IBM опять сделала попытку вернуть себе монополию на производство персональных компьютеров, выпустив новую оригинальную модель PS/2, отличную от IBM PC и имеющую закрытую архитектуру. Однако модель не имела успеха и в настоящее время большинство компьютеров типа IBM PC изготавливается в Юго–Восточной Азии (Тайвань, Сингапур, Южная Корея и т.д.). Наибольшее влияние на развитие компьютеров типа IBM PC теперь оказывает не IBM, a фирма Intel — производитель микропроцессоров и фирма Microsoft — разработчик ОС Windows и многих других используемых на IBM PC программ.
Что же касается Apple Computer, то она сохранила особенности своей модели, отличной от IBM PC. Компьютер, выполненный фирмой на самом новом в то время микропроцессоре Motorola 68000, получил имя Macintosh (название одного из популярных сортов американских яблок «макинтош»). Компьютер имел высококачественный графический дисплей, «мышь» и был прост в освоении даже для неподготовленного пользователя, который мог практически ничего не вводить с клавиатуры, а лишь использовать маленькие картинки–пиктограммы, обозначающие разнообразные действия. Кроме этого, впервые компьютер дополнили генератором звука и микрофоном. В начале 1984 года Macintosh поступил в продажу. В комплекте с новейшим лазерным печатающим устройством (принтером) Macintosh с его графическими возможностями стал идеальной машиной для развивающихся в то время настольных издательств. Полюбился компьютер и преподавателям школ, колледжей, университетов. А вот в деловом мире по–прежнему популярностью пользовались IBM–совместимые компьютеры.
В СССР в 1988 г. был начат массовый выпуск школьных персональных компьютеров и классов учебной вычислительной техники «Корвет», «Электроника УКНЦ» и др., профессиональных компьютеров ДВК–ЗМ, ДВК–4, «Искра–1030», «Нейрон», ЕС–1841 и др.
Выпуск микропроцессоров серии Power PC, разработанных совместно фирмами Apple, IBM и Motorola, начался в 1993 г., а в 1994 г. стали появляться в продаже компьютеры фирм Apple и IBM на базе этого микропроцессора. Большой интерес для пользователей представляет персональный компьютер Power Macintosh, который появился в 1994 г. Этот компьютер использует микропроцессор Power PC. Особенностью Power Macintosh является возможность работать с программами, написанными для IBM–совместимых персональных компьютеров.
В настоящее время на компьютерном рынке рядом с фирмами IBM и Apple Computer трудятся такие крупные фирмы, как Compaq, Packard Bell, Dell, Hewlett–Packard и др.
Причины успеха персональных компьютеров. В настоящее время индустрия производства компьютеров и ПО для них является одной из наиболее важных сфер экономики развитых стран. Ежегодно в мире продаются десятки миллионов компьютеров. Только в США объем продаж компьютеров, услуг и программного обеспечения составляет десятки миллиардов долларов и постоянно продолжает расти. Основная причина этого – невысокая стоимость компьютеров и их сравнительная выгодность для многих деловых применений по сравнению с большими и мини–ЭВМ. Но имеются и другие причины:
- простота использования, обеспеченная с помощью диалогового способа взаимодействия с компьютером, удобных и понятных пользовательских интерфейсов;
- возможность индивидуального взаимодействия с компьютером без каких–либо посредников и ограничений;
- относительно высокие возможности по переработке информации (типичная скорость — несколько миллионов операций в секунду, емкость оперативной памяти — до сотен Мбайт, емкость жестких дисков — десятки Гбайт);
- высокая надежность и простота ремонта, основанные на интеграции компонентов компьютера;
- возможность расширения и адаптации к особенностям применения — один и тот же компьютер может быть оснащен различными периферийными устройствами и программными средствами;
- наличие программного обеспечения, охватывающего практически все сферы человеческой деятельности, а также мощных систем для разработки нового ПО.
Но несмотря на то, что область применения персональных компьютеров очень широка, имеются задачи, которые лучше решать на более мощных ЭВМ.
Ограниченность области применения персональных компьютеров:
- при обработке больших объемов информации часто оказывается целесообразным совместное использование компьютеров разного уровня, где на каждом уровне решаются задачи, соответствующие его возможностям. Например, в крупном коммерческом банке обработка информации о клиентах и расчетах скорее всего потребует большую ЭВМ, а ввод данных и анализ результатов может осуществляться и на персональных компьютерах;
- во многих задачах оказывается недостаточной вычислительная мощность персональных компьютеров. Например, расчет механической прочности конструкции из нескольких сотен элементов можно сделать и на персональном компьютере, но если надо рассчитать прочность конструкции из сотен тысяч элементов, то потребуется уже большая или даже супер–ЭВМ;
- при компьютерном производстве видеофильмов персональный компьютер вполне можно использовать для создания простеньких движущихся картинок на экране. Но для создания реалистичных фильмов и специальных видеоэффектов используются специализированные компьютеры, предназначенные для эффективной обработки трехмерных изображений и анимации.
1.2.5. Пятое поколение
С конца 80–х годов XX века в истории развития ЭВМ наступила пора пятого поколения машин. Проект машин пятого поколения разработан ведущими японскими фирмами и научными организациями, согласно этому проекту ЭВМ и вычислительные системы коренным образом отличаются от машин предшествующих поколений. Прежде всего, их структура отличается от той, которую предложил Джон фон Нейман, и содержит:
- блок общения, обеспечивающий интерфейс между пользователем и ЭВМ на языке, близком к естественному;
- базу знаний, хранящую все необходимые для решения задач сведения о той предметной области, к которой эти задачи относятся;
- решатель, который организует подготовку программы решения задачи на основании знаний из базы знаний и исходных данных, полученных из блока общения.
ЭВМ пятого поколения должны самоорганизовываться в процессе решения задач, иметь собственную внутреннюю модель мира и активно взаимодействовать с внешней средой, распознавать образы, делать выводы из информации, уметь оперировать в нечетких ситуациях, пополнять имеющиеся знания (т.е. иметь способность обучаться), вести диалог с человеком на естественном речевом или графическом языках, иметь способность понимать содержимое базы знаний и использовать эти знания при решении задач. Таким образом, в этих машинах широко используются модели и средства, разработанные в искусственном интеллекте. В них, в частности, широко используются языки, характерные для представления знаний, модели знаний в виде семантических сетей, фреймов и продукций.
Разработка машин пятого поколения ведется на основе СБИС, а также на основе перехода к супермикроэлектронике, где расстояния между элементами схем будут меньше микрона, и на основе использования достижений интегральной микрооптоэлектроники, в которой каналами связи являются световые лучи, а для преобразования электрических сигналов в световые и наоборот используются лазеры, свето– и фотодиоды. Благодаря достижениям современной техники только в компьютерах пятого поколения стало возможным технически реализовать идеи, высказанные еще в 70–е годы.
Отличительные черты ЭВМ пятого поколения:
- новая технология производства на базе новых материалов;
- отказ от традиционных языков высокого уровня (Фортран, Паскаль и др.) в пользу языков с повышенными возможностями манипулирования символами и с элементами логического программирования (Пролог, ЛИСП);
- акцент на новые архитектуры (например, на архитектуру потока данных) и отход от структур фон Неймана;
- новые способы ввода–вывода, удобные для пользователя (например, распознавание речи и образов, синтез речи, обработка сообщений на естественном языке);
- искусственный интеллект, тесно связанный с исследованиями в области экспертных систем.
2. Компьютер фон Неймана
В отчете «Предварительное обсуждение логической конструкции электронной вычислительной машины», подготовленном в 1946 г. фон Нейманом совместно с Г. Гольдстейном и А. Берксом изложены основные принципы логической структуры ЭВМ (компьютера фон Неймана):
- принцип использования двоичной системы счисления для представления информации в ЭВМ. Машина должна работать не в десятичной системе счисления (как механические арифмометры), а в двоичной (бинарной). Это означает, что программа и данные должны быть записаны в коде двоичной системы, где каждое число или символ представляется определенной комбинацией нулей и единиц;
- программное управление работой ЭВМ. Программы состоят из отдельных шагов — команд; команда осуществляет единичный акт преобразования информации; последовательность команд, необходимая для реализации алгоритма, является программой; все разновидности команд, использующиеся в конкретной ЭВМ, в совокупности являются языком машины или системой команд машины;
- принцип условного перехода. Возможность перехода в процессе вычислений на тот или иной участок программы в зависимости от промежуточных, получаемых в ходе вычислений результатов; реализация принципа условного перехода позволяет осуществлять в программе циклы с автоматическим выходом из них, итерационные процессы и т.п. Благодаря принципу условного перехода число команд в программе получается во много раз меньше, чем число выполненных машиной команд при исполнении данной программы за счет многократного вхождения в работу участков программы;
- принцип хранимой программы. Программа, которая управляет последовательностью выполнения операций, должна храниться в памяти машины. Там же должны храниться исходные данные и промежуточные результаты;
- принцип иерархичности запоминающих устройств. Память компьютера следует организовать по иерархическому принципу, т. е. она должна состоять, по крайней мере, из двух частей: быстрой, но небольшой по емкости (оперативной) и большой (медленной) внешней.
Классическая структурная схема ЭВМ, построенной в соответствии с принципами фон Неймана, приведена на рисунке 2.1. На схеме представлены: память (оперативная и внешняя), состоящая из перенумерованных ячеек (номер ячейки называют адресом); процессор, включающий в себя устройство управления (УУ) и арифметико–логическое устройство (АЛУ); устройство ввода; устройство вывода. Эти устройства соединены каналами связи, по которым передается информация (управляющая – прерывистые стрелки, данные – непрерывные стрелки).
Рисунок 2.1 — Классическая структурная схема ЭВМ
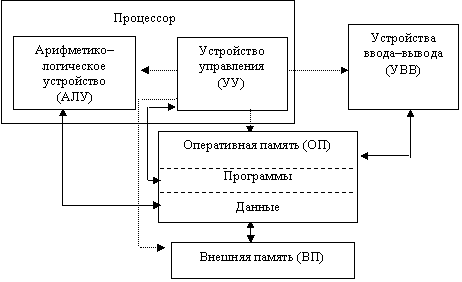
Функции памяти:
- приём информации из других устройств;
- запоминание информации;
- выдача информации по запросу в другие устройства машины.
Функции процессора:
- обработка данных по заданной программе путем выполнения арифметических и логических операций;
- программное управление работой устройств компьютера.
Та часть процессора, которая выполняет команды, называется арифметико–логическим устройством, а другая его часть, выполняющая функции управления устройствами, называется устройством управления. Обычно эти два устройства выделяются чисто условно, конструктивно они не разделены. АЛУ реализует важную часть процесса обработки данных, заключающуюся в выполнении набора про- стых операций. Операции АЛУ подразделяются на три основные категории: арифметические, логические и операции над битами. Арифметической операцией называют процедуру обработки данных, аргументы и результат которой являются числами (сложение, вычитание, умножение, деление). Логической операцией именуют процедуру, осуществляющую построение сложного высказывания (операции И, ИЛИ, НЕ). Операции над битами обычно подразумевают сдвиги.
Алгоритмом решения задачи численным методом называют последовательность арифметических и логических операций, которые надо произвести над исходными данными и промежуточными результатами для получения решения задачи. Алгоритм можно задать указанием, какие следует произвести операции, в каком порядке и над какими словами. Описание алгоритма в форме, воспринимаемой ЭВМ, называется программой.
Программа состоит из отдельных команд. Каждая команда предписывает определенное действие и указывает, над какими словами (операндами) это действие производится. Программа представляет собой совокупность команд, записанных в определенной последовательности, обеспечивающей решение задачи на ЭВМ.
Для того чтобы устройство управления могло воспринимать команды, они должны быть закодированы в цифровой форме. Автоматическое управление процессом решения задачи достигается на основе принципа программного управления, который составляет главную особенность ЭВМ.
Другим важнейшим принципом является принцип хранимой в памяти программы, согласно которому программа, закодированная в цифровом виде, хранится в памяти наравне с числами. В команде указываются не сами участвующие в операциях числа, а адреса ячеек ОП, в которых они находятся, и адрес ячейки, куда помещается результат операции.
Использование двоичных схем, принципов программного управления и хранимой в памяти программы позволило достигнуть высокого быстродействия и сократить во много раз число команд в программах решения задач, содержащих вычисляемые циклы, по сравнению с числом операций, которые производит машина при выполнении этих программ.
Команды выполняются в порядке, соответствующем их расположению в последовательных ячейках памяти, кроме команд безусловного и условного перехода, изменяющих этот порядок соответственно безусловно или только при выполнении некоторого условия, обычно задаваемого в виде равенства нулю, положительного или отрицательного результата предыдущей команды или отношения типа <, =, > для указываемых командой чисел. Благодаря наличию команд условного перехода ЭВМ может автоматически изменять ход выполняемого процесса, решать сложные логические задачи.
При помощи устройства ввода программа и исходные данные считываются и переносятся в ОП.
Как правило, процесс выполнения команды разбивается на следующие этапы:
- из ячейки памяти, адрес которой хранится в счетчике команд УУ, выбирается очередная команда, содержимое счетчика команд при этом увеличивается на длину команды;
- выбранная команда передается в УУ на регистр команд;
- УУ расшифровывает адресное поле команды;
- по сигналам УУ операнды считываются из памяти и записываются в АЛУ на специальные регистры операндов;
- УУ расшифровывает код операции и выдает в АЛУ сигнал выполнения соответствующей операции над данными;
- результат операции либо остается в процессоре, либо отправляется в память, если в команде был указан адрес результата;
- все предыдущие этапы повторяются до достижения команды «стоп».
3. Данные, типы элементарных данных
Непрерывная и дискретная информация. Информация о различных природных явлениях и технологических процессах воспринимается человеком в виде тех или иных полей. Математически такие поля представляются с помощью функций ![]() , где t — время, х — точка, в которой измеряется поле, у — величина поля в этой точке. При измерениях поля в фиксированной точке
, где t — время, х — точка, в которой измеряется поле, у — величина поля в этой точке. При измерениях поля в фиксированной точке ![]() функция
функция ![]() вырождается в функцию времени
вырождается в функцию времени ![]() , которую можно изобразить в виде графика.
, которую можно изобразить в виде графика.
В большинстве случаев скалярные величины, входящие в соотношение![]() , могут принимать непрерывный ряд значений, измеряемых вещественными числами. Под непрерывностью здесь понимается то, что рассматриваемые величины могут изменяться сколь угодно мелкими шагами. Ввиду этого представляемую таким способом информацию называют непрерывной (аналоговой) информацией.
, могут принимать непрерывный ряд значений, измеряемых вещественными числами. Под непрерывностью здесь понимается то, что рассматриваемые величины могут изменяться сколь угодно мелкими шагами. Ввиду этого представляемую таким способом информацию называют непрерывной (аналоговой) информацией.
Если применительно к той же самой информации о поле ![]() установить минимальные шаги изменения всех характеризующих ее скалярных величин, то получим дискретное представление информации (дискретная информация). Поскольку точность измерений всегда ограничена, то, даже имея дело с непрерывной информацией, человек воспринимает ее в дискретном виде. Но любая непрерывная информация может быть аппроксимирована дискретной информацией с любой степенью точности, поэтому говорят об универсальности дискретной формы представления информации.
установить минимальные шаги изменения всех характеризующих ее скалярных величин, то получим дискретное представление информации (дискретная информация). Поскольку точность измерений всегда ограничена, то, даже имея дело с непрерывной информацией, человек воспринимает ее в дискретном виде. Но любая непрерывная информация может быть аппроксимирована дискретной информацией с любой степенью точности, поэтому говорят об универсальности дискретной формы представления информации.
Результаты измерения скалярных величин представляются в итоге в числовом виде, а поскольку при заданной точности измерений эти числа представимы в виде конечных наборов цифр (с запятой или без нее), то дискретную форму представления информации отождествляют с цифровой информацией.
Абстрактные алфавиты. Цифровая информация представляет собой частный случай так называемого алфавитного способа представления дискретной информации. Его основой является произвольный фиксированный конечный набор символов любой природы, называемый абстрактным алфавитом или просто алфавитом.
Совокупность десятичных цифр вместе с запятой для отделения дробной части числа можно рассматривать как частный случай абстрактного алфавита с 11 символами — буквами этого алфавита. Другой пример — алфавит естественного человеческого языка, языка математических и других научных текстов и др.
Кодирование. При обработке информации часто необходимо представлять средствами одного алфавита буквы других алфавитов. Такое представление носит в информатике наименование кодирования. Проблема решается просто, если требуется закодировать буквы алфавита X с меньшим числом букв, чем у кодирующего алфавита Y. Если, например, X — алфавит десятичных цифр, a Y — обычный русский алфавит, то для кодирования X в Y достаточно положить 0 = а, 1 = б, 2 = в, 3 = г, ..., 9 = к. Конечно, возможны и другие способы кодирования, одним из наиболее естественных из которых является просто замена десятичных цифр их русскими названиями: нуль, один, два и т. д.
При кодировании алфавитов с большим числом букв в алфавитах с меньшим числом букв использование для кодирования последовательностей букв является обязательным условием для возможности различения кодов разных букв, что является условием правильного кодирования. Так, буквы русского алфавита можно закодировать парами десятичных цифр, например, а = 01, б = 02, ..., к = 10, л = 11, ...
Двоичный алфавит. Простейшим абстрактным алфавитом, достаточным для кодирования любого другого алфавита, является алфавит, состоящий из двух букв. Такой алфавит носит наименование двоичного, а две его буквы чаще всего принято обозначать цифрами 0 и 1. Величина, способная принимать лишь два различных значения, представляет собой информационный атом, получивший наименование бит.
Байтовый алфавит. Ввиду своей простоты двоичный алфавит наиболее широко распространен в технических устройствах, в первую очередь в ЭВМ. Для кодирования же алфавитов, которыми привык пользоваться человек, употребляются последовательности двоичных цифр. Легко видеть, что последовательностями из п двоичных цифр можно закодировать 2n различных символов. При п = 8 их число равно 256, что оказывается достаточным для кодирования большинства встречающихся на практике алфавитов.
Последовательность из 8 двоичных цифр получила в связи с этим наименование байта. Составляемый же подобными последовательностями алфавит из 256 букв называют байтовым алфавитом. В практике использования ЭВМ в международном масштабе укоренился единый стандарт байтового кодирования строчных и прописных букв латинского алфавита, знаков препинания, десятичных цифр с десятичной запятой (точкой), а также ряда математических символов (знаки арифметических и логических операций, знаки равенства и неравенства и др.). Специальный код закрепляется за знаком пробела.
Мощность (число букв) байтового алфавита достаточна для представления, кроме этих символов, строчных и прописных букв русского алфавита, отличных по написанию от латинских букв. Остается резерв и для кодирования других символов, например греческих букв.
Слова и абстрактные языки. Любая конечная последовательность букв в алфавите X называется словом. Для того чтобы из всего получаемого таким образом множества слов выделить правильные в каком–то смысле слова, над исходным алфавитом X строится так называемый формальный язык. Кроме алфавита X формальный язык задается своей формальной грамматикой. Она представляет собой не что иное, как конечную совокупность формальных правил, с помощью которых порождаются все слова данного языка и только такие слова.
Данные, элементарные данные. Информация, с которой имеют дело ЭВМ, называется данными, которые разбиваются на отдельные составляющие, называемые элементарными данными или элементами данных. Употребляются элементы данных различных типов. Тип данных (элементарных) зависит от значений, которые эти данные могут принимать. В современной информатике среди различных типов элементарных данных наиболее употребительными являются целые и вещественные числа, слова и булевы величины.
Прежде всего различают двоичное и двоично–десятичное представления чисел. В двоичном представлении используется двоичная система счисления с фиксированным числом двоичных разрядов (чаще всего 32 разряда, включая разряд для представления знака числа). Если нулем обозначать плюс, а единицей — минус, то 00001010 означает целое число ![]() , а 10001100 — число
, а 10001100 — число ![]() (для простоты взято 8–разрядное представление). В случае вещественных чисел (а фактически, с учетом ограниченной разрядности, дробных двоичных чисел) употребляются две формы представления: с фиксированной и с плавающей запятой. В первом случае просто заранее условливаются о месте нахождения запятой, не указывая ее в коде числа. Например, если условиться, что запятая стоит между 3–м и 4–м разрядами справа, то код 00001010 будет означать число
(для простоты взято 8–разрядное представление). В случае вещественных чисел (а фактически, с учетом ограниченной разрядности, дробных двоичных чисел) употребляются две формы представления: с фиксированной и с плавающей запятой. В первом случае просто заранее условливаются о месте нахождения запятой, не указывая ее в коде числа. Например, если условиться, что запятая стоит между 3–м и 4–м разрядами справа, то код 00001010 будет означать число ![]() .
.
Во втором случае код числа разбивается на два кода в соответствии с представлением числа в виде ![]() . При этом число а (со знаком) называется мантиссой, а число b (со знаком) — характеристикой числа х. О положении кода характеристики и мантиссы (вместе с их знаками) в общем коде числа также условливаются заранее. Для экономии числа разрядов в характеристике b ее часто представляют в виде
. При этом число а (со знаком) называется мантиссой, а число b (со знаком) — характеристикой числа х. О положении кода характеристики и мантиссы (вместе с их знаками) в общем коде числа также условливаются заранее. Для экономии числа разрядов в характеристике b ее часто представляют в виде ![]() , где k — фиксированная константа (обычно k = 2). Вводя еще одну константу т и полагая
, где k — фиксированная константа (обычно k = 2). Вводя еще одну константу т и полагая ![]() , можно избежать также использования в коде характеристики знака (при малых
, можно избежать также использования в коде характеристики знака (при малых ![]() число b отрицательно, а при больших — положительно).
число b отрицательно, а при больших — положительно).
В двоично–десятичном представлении обычные десятичные цифры (а также запятая и знак) кодируются двоичными цифрами. При этом часто используется так называемый упакованный код, когда с помощью одного байта кодируется не одна, а две десятичные цифры. Подобное представление позволяет кодировать числа любой значности.
Тип данных «произвольное слово во входном алфавите» не нуждается в специальных пояснениях. Единственное условие — необходимость различать границы отдельных слов. Это достигается использованием специальных ограничителей и указателей длины слов.
Тип булев присваивается элементарным данным, способным принимать лишь два значения: «истина» и «ложь». Для представления булевых величин обычно используется двоичный алфавит.
Переменные и постоянные величины (данные). Для идентификации данных употребляются специальные наименования, называемые идентификаторами. Они являются аналогами переменных величин, фигурирующих в математике. Область значений, которые может принимать эта переменная, определяется типом элемента данных, именем которого она является. В качестве идентификаторов элементарных данных принято использовать любые конечные последовательности латинских букв и десятичных цифр, начинающиеся буквой.
В отличие от переменных величин, для которых требуется различать их имя и значение, для постоянных величин ее значение может служить и ее именем. Однако часто полезно именовать постоянные величины идентификаторами (например, число е ≈ 2,718 и др.), имея в виду, что такого рода идентификатор представляет собой константу и может принимать лишь единственное значение.
4. Структуры данных и структурированная память
На практике в большинстве случаев данные образуют ту или иную структуру. Структурирование данных задается, прежде всего, с помощью различного рода отношений порядка (упорядоченности). Простейший вид упорядоченности — нумерация данных с помощью последовательных целых чисел. Идентификаторы упорядоченных таким образом данных образуются обычно путем приписывания какому–либо фиксированному идентификатору специального идентификатора индекса, значения которого пробегают заданный набор целых чисел.
Возникающий идентификатор вида ![]() или
или ![]() , где i пробегает целые числа от т до п, идентифицирует упорядоченный набор данных, называемый обычно одномерным массивом. Двухиндексный идентификатор вида
, где i пробегает целые числа от т до п, идентифицирует упорядоченный набор данных, называемый обычно одномерным массивом. Двухиндексный идентификатор вида ![]() или
или ![]() идентифицирует двумерный массив, трехиндексный — трехмерный массив и т. д. В упорядоченных таким образом массивах возникает естественное отношение следования: так, следующим по индексу j для элемента
идентифицирует двумерный массив, трехиндексный — трехмерный массив и т. д. В упорядоченных таким образом массивах возникает естественное отношение следования: так, следующим по индексу j для элемента ![]() будет элемент
будет элемент ![]() , а предыдущим — элемент
, а предыдущим — элемент ![]() . Если индекс j пробегает значения от р до q, то для р не существует предыдущего, а для q – следующего значения индекса.
. Если индекс j пробегает значения от р до q, то для р не существует предыдущего, а для q – следующего значения индекса.
Если границы изменений индексов задаются константами, то говорят, что соответствующий массив — прямоугольный, поскольку в двумерной целочисленной решетке область возможных значений индексов в этом случае представляет собой прямоугольник (термин прямоугольный применяется также для массивов любой размерности). Области значений индексов могут задаваться и более сложными способами. Например, соотношения ![]() задают треугольный массив. Массивы обычно предполагаются однородными, состоящими из элементов одного типа. Одномерные однородные массивы
задают треугольный массив. Массивы обычно предполагаются однородными, состоящими из элементов одного типа. Одномерные однородные массивы ![]() называют векторами, двумерные
называют векторами, двумерные ![]() — матрицами, а составляющие их элементарные данные — их компонентами (элементами). В общем случае индексы могут пробегать не обязательно последовательно все целые числа с шагом, равным единице, а любые их конечные подмножества, в том числе с переменной величиной шага.
— матрицами, а составляющие их элементарные данные — их компонентами (элементами). В общем случае индексы могут пробегать не обязательно последовательно все целые числа с шагом, равным единице, а любые их конечные подмножества, в том числе с переменной величиной шага.
Помимо однородных массивов на практике часто приходится иметь дело с данными различных типов. Рассмотрим, например, содержание обычной анкеты, применяемой при учете кадров. Одни графы этой анкеты заполняются словами, другие — числами, третьи — булевыми величинами (да, нет). В информатике каждая совокупность данных, характеризующая тот или иной объект или явление, называется записью. Кадровая анкета представляет собой один из возможных видов подобной записи. Совокупность записей (обычно одного и того же типа) носит наименование файла.
Если запись характеризует тот или иной объект, то отдельные ее позиции представляют собой различные свойства этого объекта, или его атрибуты. Если запись состоит из п атрибутов, то каждый файл записей такого типа задает п–местный предикат (п–местное отношение) ![]() на множестве всевозможных значений этих атрибутов. Этот предикат считается истинным для значений атрибутов
на множестве всевозможных значений этих атрибутов. Этот предикат считается истинным для значений атрибутов ![]() , если в заданном файле существует запись
, если в заданном файле существует запись ![]() , и ложным в противном случае. Таким образом, всякий набор файлов задает некоторую модель данных.
, и ложным в противном случае. Таким образом, всякий набор файлов задает некоторую модель данных.
Записи — это подмножества множества данных длины n, имеющие специальный вид. В общем случае структура данных может быть задана в виде произвольной системы N подмножеств множества М (упорядоченных или нет). Подмножества системы N получают при этом некоторые имена и включаются в рассмотрение в качестве составных данных наряду с исходными (элементарными) данными множества М. Например, любая книга без рисунков может рассматриваться как упорядоченная последовательность букв (в число которых включаются знаки препинания и другие специальные символы, включая символ пробела). Эти буквы объединяются в слова, которые можно рассматривать как составные объекты первого уровня, слова — в предложения, предложения — в параграфы, а параграфы — в главы.
В структурированной таким образом книге объект (данное) каждого уровня (за исключением самого верхнего) входит в один и только один объект следующего (более высокого) уровня. Данные с такой структуризацией принято называть деревьями, или иерархическими структурами. Составной объект самого верхнего уровня называется корнем, а объекты самого нижнего уровня — листьями этого дерева.
5. Виды памяти и ее характеристики
Запоминающие устройства (ЗУ), или память, хранят команды и данные. Память делится на ячейки, или слова, состоящие обычно из фиксированного числа двоичных разрядов — битов (последовательность из 8 двоичных цифр — байт). Ячейки нумеруются последовательными целыми числами n=0,1,2,… Номера ячеек принято называть адресами. Объем ЗУ обычно выражается в килобайтах (Кбайт или сокращенно К) или мегабайтах (Мбайт). Поскольку адресация большинства ЗУ осуществляется в двоичной системе счисления, в качестве килобайта удобно брать 1024 = 210 байт. Соответственно, под мегабайтом обычно понимается величина 220 байт.
Запоминающие устройства с произвольным доступом характеризуются одним и тем же временем доступа в произвольную ячейку независимо как от ее адреса, так и от предыдущих обращений в память. Под временем доступа здесь понимается время, необходимое для установления соединения данной ячейки запоминающего устройства с некоторым буферным регистром. Добавляя к этому времени время, необходимое для фактического перемещения информации из ЗУ в регистр или обратно, получают соответственно времена цикла чтения и цикла записи. Возможность в любой момент времени считать или записать информацию в любую ячейку памяти делает ЗУ с произвольным доступом естественным партнером центрального процессора в качестве оперативного хранилища информации. Это привело к закреплению за ними наименования оперативного запоминающего устройства (ОЗУ).
При высоком быстродействии процессора время цикла для ОЗУ может явиться ограничивающим фактором для скорости работы системы ОЗУ — процессор. В качестве выхода из этого положения строятся двухуровневые памяти, когда относительно медленное ОЗУ большого объема взаимодействует непосредственно не с процессором, а со специальной сверхоперативной памятью (СОЗУ), представляющей собой память с произвольным доступом относительно небольшого объема, но существенно более быструю, чем ОЗУ.
В ЗУ последовательного доступа доступ осуществляется последовательно в порядке роста или убывания адресов ячеек. Поэтому после обращения в ячейку с адресом п следующее соединение будет установлено либо с (п+1)–й, либо с (n–1)–й ячейкой. Последовательные ЗУ характеризуются помимо объема также скоростью передачи информации, которая в этом случае существенным образом зависит как от ееместорасположения в памяти,так и от адреса предыдущего соединения с ЗУ. Примером ЗУ последовательного доступа является магнитная лента.
ЗУ с прямым доступом комбинируют черты устройств с произвольным и последовательным доступом. Обладая возможностью перехода от одного адреса к любому другому, они вместе с тем гораздо быстрее открывают ячейки с последовательными адресами. Поэтому в их характеристику, помимо максимального времени произвольного доступа, входит, как и в последовательных ЗУ, независимая от этого времени скорость передачи информации.
При построении ЭВМ часто оказывается удобным использовать ЗУ магазинного типа, называемые также стеками: при вводе (записи) нового слова уже заполненные слова сдвигаются на один шаг в глубь магазина; при выводе (чтении) процесс протекает в обратном направлении. Таким образом, реализуется принцип: последнее слово из записанных читается первым.
Для ряда приложений очень удобна так называемая ассоциативная память. Запись в нее осуществляется в произвольную ячейку, выбираемую самим ЗУ. Доступ к нужному элементу данных осуществляется не по адресу, а по запоминаемому вместе с этим элементом признаку. Конструктивно такая память выполняется в виде матрицы ![]() с булевыми первичными ячейками. Вторичные (составные) ячейки (адресуемые индексом i) образуют строки этой матрицы, тогда как столбцы (адресуемые индексом j) несут в себе соответствующие разряды признаков всех строк, запомненных в ЗУ. Для реализации, помимо обычного (адресного) доступа по строкам матрицы, ассоциативного доступа достаточно реализовать доступ по второму индексу — адресу столбца матрицы (с соответствующей схемой анализа выбранного столбца).
с булевыми первичными ячейками. Вторичные (составные) ячейки (адресуемые индексом i) образуют строки этой матрицы, тогда как столбцы (адресуемые индексом j) несут в себе соответствующие разряды признаков всех строк, запомненных в ЗУ. Для реализации, помимо обычного (адресного) доступа по строкам матрицы, ассоциативного доступа достаточно реализовать доступ по второму индексу — адресу столбца матрицы (с соответствующей схемой анализа выбранного столбца).
Иерархия запоминающих устройств. Принцип кэширования данных. Память ЭВМ представляет собой иерархию запоминающих устройств (внутренние регистры процессора, различные типы сверхоперативной и оперативной памяти, диски, ленты), отличающихся средним временем доступа и стоимостью хранения данных в расчете на один бит (рисунок 5.1).
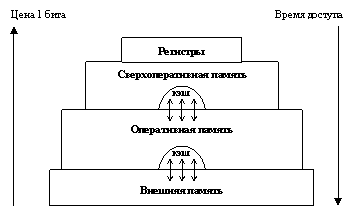
Рисунок 5.1 — Иерархия ЗУ
Пользователю хотелось бы иметь и недорогую и быструю память. Кэш–память представляет некоторое компромиссное решение этой проблемы. Кэш–память — это способ организации совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который позволяет уменьшить среднее время доступа к данным за счет динамического копирования в «быстрое» ЗУ наиболее часто используемой информации из «медленного» ЗУ. Кэш–памятью часто называют не только способ организации работы двух типов запоминающих устройств, но и одно из устройств — «быстрое» ЗУ. Оно стоит дороже и, как правило, имеет сравнительно небольшой объем. Важно, что механизм кэш–памяти является прозрачным для пользователя, который не должен сообщать никакой информации об интенсивности использования данных и не должен никак участвовать в перемещении данных из ЗУ одного типа в ЗУ другого типа, все это делается автоматически системными средствами.
6. Процессоры
Процессором называется устройство, способное выполнять некоторый заданный набор операций над данными в структурированной памяти и вырабатывать значение заданного набора логических условий над этими данными.
Стандартная схема процессора состоит из двух устройств, называемых арифметико–логическим устройством и устройством управления (рисунок 6.1).

Рисунок 6.1 — Схема процессора
В схему АЛУ включается структурированная память, состоящая, как правило, из регистров, к которым может добавляться один или несколько стеков. С помощью специальных комбинационных схем в структурированной памяти может осуществляться тот или иной набор преобразований.
Операции, выполняемые АЛУ за один такт синхронизирующего генератора, называются микрооперациями, а соответствующий их выполнению такт — микротактом. Выбор той или иной микрооперации осуществляется путем подачи кода этой микрооперации на специальный управляющий вход АЛУ. Как правило, в состав микроопераций АЛУ включаются очистка регистров и стеков (обращение их содержимого в нуль), пересылки данных между регистрами и стеками, сдвиги (вправо или влево) двоичного кода на регистрах, а также накапливающее суммирование. Для этой операции выделяются специальные регистры, называемые накапливающими сумматорами (аккумуляторами). При передаче кода некоторого числа х в аккумулятор, содержавший число у, происходит суммирование (с учетом знаков) этих чисел, а сумма х + у замещает в аккумуляторе его первоначальное содержимое у.
Помимо описанных внутренних микроопераций, в АЛУ реализуются также внешние микрооперации, осуществляющие прием и выдачу данных, т. е. обмен данными между АЛУ и внешним миром.
Кроме того, АЛУ может формировать дополнительно выходные сигналы в виде набора логических условий, выражающих те или иные свойства содержимого памяти АЛУ. Примеры таких свойств: «коды в регистрах А и В одинаковы», «число в регистре А отрицательно» и т. д.
Устройство управления процессора на основе входных сигналов, в качестве которых служат формируемые АЛУ наборы логических условий, формирует выходные сигналы — коды микроопераций АЛУ. Кроме того, УУ может иметь также каналы обмена с внешним миром. Каналы выдачи и приема УУ и АЛУ обычно объединяются в каналы обмена процессора с внешним миром.
Через канал приема в УУ поступают коды команд (инструкций) на выполнение тех или иных операций процессора, а через канал выдачи — запросы на очередные команды, либо сигнал останова, который прекращает работу процессора. Операция процессора обычно не сводится к одной микрооперации, а индуцируется некоторой их последовательностью. Такие последовательности определяются микропрограммами, встраиваемыми или запоминаемыми в УУ. В случае запоминаемых микропрограмм их можно оперативно менять, настраивая процессор на различные наборы операций (команд). В этом случае говорят, что процессор имеет мягкую (перестраиваемую) архитектуру.
Работа процессора может осуществляться двумя различными способами. В первом из них процессор сам извлекает последовательно команды из программы, запомненной в быстродействующей памяти – внешней по отношению к процессору. Все необходимые данные (исходные, промежуточные и выходные) также хранятся в этой памяти. Команды, помимо кода операции, содержат адреса данных, необходимых для их исполнения. Извлекая из памяти очередную команду и анализируя ее, процессор тут же извлекает необходимые для ее выполнения данные. В этом случае принято говорить, что процессор управляется потоком команд. Другой способ состоит в том, что данные, поступающие в АЛУ процессора из внешнего источника, запоминаются в нем, анализируются и вызывают (с помощью УУ) выборку из быстродействующей памяти последовательности команд для их обработки. В этом режиме процессор управляется потоком данных. Быстродействие процессора должно быть достаточно велико, чтобы обработать поступившие данные и выдать результат обработки до поступления очередной порции данных.
6.1. Типы процессоров. Арифметические процессоры
Арифметическими называются процессоры, предназначенные в первую очередь для автоматизации вычислительных операций той или иной степени сложности. Для сложных научных, проектно–конструкторских и планово–экономических расчетов наиболее употребительны процессоры, выполняющие полный набор арифметических операций над многозначными числами в двоичной системе счисления параллельным способом. Выбор двоичной системы и параллельного способа выполнения операций (над всеми разрядами одновременно) обусловлен тем, что при этом достигаются наибольшая скорость вычислений и наилучшее использование оборудования (прежде всего — памяти).
Магистральные процессоры. При выполнении последовательности поступающих команд процессор реализует ряд повторяющихся операций: он должен воспринять код очередной операции, адреса, по которым хранятся операнды, и адрес, по которому должен быть размещен результат операции, принять и разместить на регистрах операнды, выполнить операцию, разместить ее результат и подготовиться к восприятию следующей команды (выработать адрес, по которому за ней надо обратиться).
Поскольку все эти составные части процесса выполнения любой команды выстроены в цепочку, закономерна мысль об их выполнении на конвейере, представляющем собой ряд соединенных друг с другом специализированных процессоров, каждый из которых выполняет лишь свою часть работы, после чего передает обрабатываемую команду следующему процессору по цепочке. Сам же он получает от предыдущего процессора следующую команду для исполнения соответствующей ее части. Темп выполнения команд при этом существенно ускоряется. Рассмотренный конвейерный метод выполнения команд представляет собой частный случай магистрального метода. В отличие от рассмотренного простого конвейера, в магистрали на отдельные составные части раскладывается также выполнение основной операции. Поскольку такие разложения для разных операций, вообще говоря, различны, в магистральном методе используется обычно несколько конвейерных линий с гибко перестраиваемыми связями между ними.
Особенно большой эффект подобное распараллеливание основной операции дает в случае сложных операций, характерных для интеллектуальных процессоров, при этом, чем сложнее операции, тем больший эффект может быть получен.
В идеале на магистральном процессоре последовательность команд может обрабатываться в темпе следования отдельных микроопераций или в темпе — один рабочий такт процессора (микротакт) на одну команду (при достаточной скорости внешних обменов).
Специализированные процессоры. Если ЭВМ предназначается для работы, в которой часто приходится использовать определенные виды сложных операций, в ее состав включают специализированные процессоры, предназначенные для быстрого выполнения этих операций. Наибольшее распространение получили векторные и матричные процессоры, в состав которых включается обычно несколько десятков элементарных процессоров для одновременного выполнения тех или иных операций над отдельными компонентами вектора или матрицы.
Наряду с векторно–матричными процессорами достаточно широкое распространение получили процессоры, ориентированные на задачи спектрального анализа сигналов (быстрое преобразование Фурье), задачи интерполяции и на ряд других применений.
Микропроцессоры. Успехи микроэлектроники позволили создать процессоры, полностью размещаемые на одном кристалле. Вначале разрядность таких процессоров была очень низкой (4 двоичных разряда), что фактически не позволяло использовать их как отдельные устройства. По мере увеличения уровня интеграции оказалось возможным повысить разрядность однокристальных микропроцессоров до 8, а потом и до 32 двоичных разрядов.
Важнейшим качеством микропроцессоров, помимо миниатюрных размеров и малого энергопотребления, является их относительно низкая стоимость. Благодаря этому качеству микропроцессоры и строящиеся на их основе микро–ЭВМ и ПЭВМ находят широкий класс применений, для которых применение ЭВМ прежних поколений было экономически невыгодно.
6.2. Оценка производительности процессоров
Производительность процессоров определяется обычно количеством операций (команд), которые они могут выполнить за одну секунду. Однако время выполнения различных операций может довольно сильно разниться. Поэтому при определении производительности указывают среднее быстродействие на смеси различных операций, взятых в определенных пропорциях друг к другу.
Если ![]() — относительные доли этих операций в смеси, a
— относительные доли этих операций в смеси, a ![]() — время выполнения каждой из этих операций (в секундах), то среднее быстродействие
— время выполнения каждой из этих операций (в секундах), то среднее быстродействие ![]() вычисляется по формуле
вычисляется по формуле
 .
.
Одна из наиболее употребительных смесей, основанная на статистике для многих научных задач и называемая смесью Гибсона I, принимает для операций сложения и вычитания с фиксированной запятой ![]() %, с плавающей запятой
%, с плавающей запятой ![]() %; для умножения с фиксированной запятой
%; для умножения с фиксированной запятой![]() %, с плавающей запятой
%, с плавающей запятой ![]() %; для деления с фиксированной запятой
%; для деления с фиксированной запятой ![]() %, с плавающей запятой
%, с плавающей запятой ![]() % (время выполнения операции сложения и вычитания у ЭВМ обычно одно и то же). Доля операций других типов составляет 53,3 %.
% (время выполнения операции сложения и вычитания у ЭВМ обычно одно и то же). Доля операций других типов составляет 53,3 %.
6.3. Мультипроцессирование
В многопроцессорных вычислительных системах центральные процессоры закрепляются и своевременно перераспределяются между различными программными модулями и различными потоками данных. Наиболее просто этот вопрос решается в том случае, когда каждый ЦП решает свою собственную независимую задачу. Если несколько ЦП используются для решения одной и той же задачи, то должно производиться распараллеливание вычислительного процесса.
Необходимо отметить, что распараллеливание допускают не все процессы. В тех случаях, когда оно возможно, различают два основных типа распараллеливания. Первый тип использует для всех процессоров один и тот же поток команд, но различные потоки данных. Например, при сложении двух матриц можно разделить между процессорами строки этих матриц и выполнить параллельно сложение различных пар строк с помощью одного и того же программного цикла. Второй тип распараллеливания использует для каждого процессора свой программный модуль, выполняемый над одними и теми же или различными данными. Поскольку разные модули исполняются, как правило, за разное время, возникает задача их синхронизации. Смысл ее состоит в том, что очередной программный модуль запускается в работу лишь после того, как для него подготовлены (в результате работы предшествующих модулей) все необходимые исходные данные. Подобная взаимозависимость модулей определяет одновременно и возможность их параллельного исполнения.
7. Режимы работы ЭВМ
Первые ЭВМ могли выполнять только одну программу, расположенную в их памяти. В последующим широкое распространение получил режим пакетной обработки данных, суть которого состоит в том, что в ЭВМ вводится одновременно не одна программа, а пакет программ. Используя то обстоятельство, что в современных ЭВМ обмены с внешними устройствами могут выполняться одновременно с работой центрального процессора, ЭВМ одновременно работает с несколькими программами. Подобный режим, называемый режимом мультипрограммирования, обеспечивает лучшую загрузку оборудования и увеличение пропускной способности ЭВМ в целом. В процессе такой работы переключение центрального процессора с одной программы на другую осуществляется не только по их окончании, но и в том случае, если данные для решаемой задачи еще не введены или промежуточные результаты ее решения необходимо вывести на устройство вывода или во внешнюю память. Одновременно с таким прерыванием решаемой задачи формируется соответствующее задание необходимому внешнему устройству, которое и выполняется параллельно с работой центрального процессора по выполнению одной из программ.
Второй режим работы компьютера – режим разделения времени обусловлен появлением пользовательских терминалов и позволяет одновременно обслуживать большое количество пользователей, взаимодействующих с ЭВМ в диалоговом (интерактивном) режиме. С этой целью каждому пользователю выделяются элементарные порции (кванты) времени, в течение которого ЭВМ его и обслуживает. Поскольку время реакции пользователя на ту или иную ситуацию намного превышает время реакции ЭВМ, у каждого из них создается впечатление, что он один обслуживается компьютером.
Третий режим работы компьютера — режим реального времени получил распространение в связи с широким использованием ЭВМ для управления внешними по отношению к компьютеру оборудованием и процессами: станками, технологическими процессами и т.п. В этом случае работа компьютера управляется внешним потоком данных, при этом производительность ЭВМ должна быть достаточной для того, чтобы обработать поступившие данные до поступления новой, очередной порции данных, а также на основе результатов обработки выдать при необходимости управляющее воздействие на внешнее оборудование за приемлемое, обусловленное особенностями работы этого оборудования время.
8. Операционные системы
8.1. Назначение операционной системы
На современном уровне при рассмотрении ЭВМ выделяют их техническую часть (HardWare) и программное обеспечение (SoftWare), центральная часть которого и представлена операционной системой. Все программное обеспечение принято делить на две части: прикладное и системное. К прикладному программному обеспечению, как правило, относят разнообразные бизнес–программы, игры, текстовые процессоры и т. п. Под системным программным обеспечением понимают программы, способствующие функционированию и разработке прикладных программ. На рисунке 8.1 структура программного обеспечения отображена в виде последовательности слоев, где выделена отдельно наиболее общая часть системного программного обеспечения — операционная система.
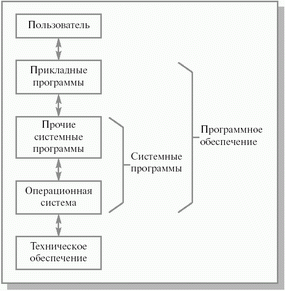
Рисунок 8.1 — Слои программного обеспечения компьютерной системы
Операционная система как виртуальная машина. Архитектура компьютеров очень неудобна для использования как прикладными программистами, так и конечными пользователями. Например, работа с магнитным диском предполагает знание внутреннего устройства его электронного компонента — контроллера для ввода команд вращения диска, поиска и форматирования дорожек, чтения и записи секторов и т. д. Ясно, что прикладной программист не в состоянии учитывать все особенности работы оборудования, а должен иметь в своем распоряжении простую высокоуровневую абстракцию, представляя информационное пространство диска как набор файлов. Файл можно открывать для чтения или записи, использовать для получения или сброса информации, а потом закрывать.Аналогичным образом скрываются от программиста все подробности работы таймера, управления памятью и т. д. Более того, на современных вычислительных комплексах можно создать иллюзию неограниченного размера оперативной памяти и числа процессоров. Кроме того, конечным пользователям должен быть предоставлен в распоряжение простой и удобный способ взаимодействия с компьютером через посредство терминала, что можно обеспечить только средствами программного обеспечения. Всем этим занимается операционная система. Таким образом, операционная система представляется пользователю виртуальной машиной, с которой проще иметь дело, чем непосредственно с оборудованием компьютера.
Операционная система как защитник пользователей и программ. Если вычислительная система допускает совместную работу нескольких пользователей, то возникает проблема организации их безопасной деятельности. Необходимо обеспечить сохранность информации на диске, чтобы никто не мог удалить или повредить чужие файлы. Нельзя разрешить программам одних пользователей произвольно вмешиваться в работу программ других пользователей. Нужно пресекать попытки несанкционированного использования вычислительной системы. Все это осуществляет операционная система как организатор безопасной работы пользователей и их программ.
8.2. Эволюция операционных систем
Оборудование и программное обеспечение ЭВМ эволюционировали параллельно, оказывая влияние друг на друга. Появление новых технических возможностей приводило к созданию более совершенных программ, а свежие идеи в программной области стимулировали поиски новых технических решений. Критерии удобства, эффективности и безопасности играли роль факторов естественного отбора при эволюции вычислительных систем.
Первый период (1945–1955 гг.). Об операционных системах не было и речи, все задачи организации вычислительного процесса решались вручную программистом с пульта управления. Программа загружалась в память машины в лучшем случае с перфокарт, а обычно с помощью панели переключателей.
Вычислительная система выполняла одновременно только одну операцию (ввод–вывод или собственно вычисления). Отладка программ велась с пульта управления с помощью изучения состояния памяти и регистров машины. Существенная часть времени уходила на подготовку запуска программы, а сами программы выполнялись строго последовательно. В целом первый период характеризуется крайне высокой стоимостью вычислительных систем, их малым количеством и низкой эффективностью использования.
Второй период (1955 г.–начало 60–х). С середины 50–х годов начался следующий период в эволюции вычислительной техники, связанный с появлением новой технической базы — полупроводниковых элементов. Размеры компьютеров уменьшились. Снизилась стоимость эксплуатации и обслуживания вычислительной техники. Началось использование ЭВМ коммерческими фирмами. Одновременно наблюдается бурное развитие алгоритмических языков (FORTRAN, LISP, COBOL, ALGOL–60, PL–1 и т.д.). Появляются первые компиляторы, редакторы связей, библиотеки математических и служебных подпрограмм. Упрощается процесс программирования. Именно в этот период происходит разделение персонала на программистов и операторов, специалистов по эксплуатации вычислительных машин.
Изменяется сам процесс выполнения расчетов по программам. Теперь пользователь приносит программу с входными данными в виде колоды перфокарт и указывает необходимые ресурсы. Такая колода получает название задания. Оператор загружает задание в память машины и запускает его на исполнение. Полученные выходные данные печатаются на принтере и пользователь получает их через некоторое (часто продолжительное) время.
Смена запрошенных ресурсов вызывает приостановку выполнения программ, в результате процессор часто простаивает. Для повышения эффективности использования компьютера задания с похожими ресурсами начинают собирать вместе, создавая пакет заданий. Появляются первые пакетные мониторы, которые просто автоматизируют запуск одной программы из пакета за другой и тем самым увеличивают коэффициент загрузки процессора. При реализации пакетных мониторов был разработан формализованный язык управления заданиями, с помощью которого программист сообщал системе и оператору, какую работу он хочет выполнить на вычислительной машине.
Третий период (начало 1960–х–1980 г.). Следующий важный период развития вычислительных машин относится к началу 1960–х–1980 г. В это время в технической базе произошел переход от отдельных полупроводниковых элементов типа транзисторов к интегральным микросхемам. Вычислительная техника становится более надежной и дешевой. Растет сложность и количество задач, решаемых компьютерами. Повышается производительность процессоров.
Повышению эффективности использования процессорного времени мешает низкая скорость работы механических устройств ввода–вывода (считыватель перфокарт мог обработать 1200 перфокарт в минуту, принтеры печатали до 600 строк в минуту). Вместо непосредственного чтения пакета заданий с перфокарт в память начинают использовать его предварительную запись, сначала на магнитную ленту, а затем и на диск. Когда в процессе выполнения задания требуется ввод данных, они читаются с диска. Точно так же выходная информация сначала копируется в системный буфер и записывается на ленту или диск, а печатается только после завершения задания. Такой прием получает название spooling (сокращение от Simultaneous Peripheral Operation On Line) или подкачки–откачки данных. Введение техники подкачки–откачки в пакетные системы позволило совместить реальные операции ввода–вывода одного задания с выполнением другого задания, но потребовало обеспечения параллельной работы внешних устройств как друг с другом, так и с ЦП на основе использования аппарата прерываний.
Магнитные ленты были устройствами последовательного доступа, то есть информация считывалась с них в том порядке, в каком была записана. Появление магнитного диска, для которого не важен порядок чтения информации, привело к дальнейшему развитию вычислительных систем. При обработке пакета заданий на магнитной ленте очередность запуска заданий определялась порядком их ввода. При обработке пакета заданий на магнитном диске появилась возможность выбора очередного выполняемого задания. Пакетные системы начинают заниматься планированием заданий: в зависимости от наличия запрошенных ресурсов, срочности вычислений и т.д. для обработки выбирается то или иное задание.
Дальнейшее повышение эффективности использования процессора было достигнуто с помощью мультипрограммирования. Идея мультипрограммирования заключается в следующем: пока одна программа выполняет операцию ввода–вывода, процессор не простаивает, как это происходило при однопрограммном режиме, а выполняет другую программу. Когда операция ввода–вывода заканчивается, процессор возвращается к выполнению первой программы. Естественно, что мультипрограммирование требует наличия в памяти нескольких программ одновременно. При этом каждая программа загружается в свой участок оперативной памяти, называемый разделом, и не должна влиять на выполнение другой программы.
Появление мультипрограммирования потребовало настоящей революции в строении вычислительной системы. Особую роль здесь играет аппаратная поддержка (многие аппаратные новшества появились еще на предыдущем этапе эволюции), наиболее существенные особенности которой перечислены ниже:
- реализация защитных механизмов. Программы не должны иметь самостоятельного доступа к распределению ресурсов, что приводит к появлению привилегированных и непривилегированных команд. Привилегированные команды, например, команды ввода–вывода, могут исполняться только операционной системой. Говорят, что она работает в привилегированном режиме. Переход управления от прикладной программы к ОС сопровождается контролируемой сменой режима. Кроме того, это защита памяти, позволяющая изолировать конкурирующие пользовательские программы друг от друга, а ОС – от программ пользователей;
- наличие прерываний. Внешние прерывания оповещают ОС о том, что произошло асинхронное событие, например, завершилась операция ввода–вывода. Внутренние прерывания возникают, когда выполнение программы привело к ситуации, требующей вмешательства ОС, например, деление на ноль или попытка нарушения защиты;
- развитие параллелизма в архитектуре. Прямой доступ к памяти и организация каналов ввода–вывода позволили освободить центральный процессор от рутинных операций.
Не менее важна в организации мультипрограммирования роль операционной системы. Она отвечает за следующие операции:
- организацию интерфейса между прикладной программой и ОС при помощи системных вызовов;
- планирование использования процессора заданиями из очереди заданий в памяти;
- сохранение при переключении с одного задания на другое необходимых для выполнения задания содержимого регистров и структур данных, иначе говоря, контекста для обеспечения правильного продолжения вычислений;
- управление памятью, то есть упорядочение процессов размещения, замещения и выборки информации из памяти;
- организацию хранения информации на внешних носителях в виде файлов и обеспечение доступа к конкретному файлу только определенным категориям пользователей;
- обеспечение программ средствами коммуникации для санкционированного обмена данными;
- разрешение конфликтных ситуаций, возникающих при работе с различными ресурсами, предоставление программам средств координации и синхронизации их действий.
Мультипрограммные системы обеспечили возможность более эффективного использования системных ресурсов (например, процессора, памяти, периферийных устройств), но они еще долго оставались пакетными. Пользователь не мог непосредственно взаимодействовать с заданием и должен был предусмотреть с помощью управляющих карт все возможные ситуации. Отладка программ по–прежнему занимала много времени и требовала изучения распечаток содержимого памяти и регистров или использования отладочной печати.
Появление терминалов на основе телетайпов, а позднее — на основе дисплеев поставили на очередь решение этой проблемы. Логическим расширением систем мультипрограммирования стали time–sharing системы, или системы разделения времени. В них процессор переключается между задачами не только на время операций ввода–вывода, но и просто по прошествии определенного времени. Эти переключения происходят так часто, что пользователи могут взаимодействовать со своими программами во время их выполнения, то есть интерактивно.
В результате появляется возможность одновременной работы нескольких пользователей на одной компьютерной системе. Чтобы уменьшить ограничения на количество работающих пользователей, была внедрена идея неполного нахождения исполняемой программы в оперативной памяти. Основная часть программы находится на диске, а фрагмент, который необходимо в данный момент выполнять, должен быть загружен в оперативную память, а ненужный - выгружен обратно на диск. Это реализуется с помощью механизма виртуальной памяти, объем которой складывается из объема реального ОЗУ и части объема ВЗУ. Основным достоинством такого механизма является создание иллюзии неограниченной оперативной памяти ЭВМ.
Каждая программа получает свою область подобного воображаемого ОЗУ, на которой полностью помещаются как сама программа, так и все данные, которыми она оперирует. Кроме того, каждая программа получает свою элементарную порцию времени, по истечении которой по сигналу от электронных часов производится прерывание данной программы и передача управления следующей по порядку программе.
В системах разделения времени пользователь получил возможность эффективно производить отладку программы в интерактивном режиме и записывать информацию на диск, не используя перфокарты, а непосредственно с клавиатуры.
Этот же период времени характеризуется использованием ЭВМ для целей управления станками, процессами и т.п. в реальном времени, что обусловило создание специальных ОС реального времени, ориентированных на решение задач такого рода. Четвертый период (с 1980 г. по настоящее время). Следующий период в эволюции вычислительных систем связан с появлением больших интегральных схем. В эти годы произошло резкое возрастание степени интеграции и снижение стоимости микросхем. Компьютер, не отличающийся по архитектуре от мини–ЭВМ PDP–11, по цене и простоте эксплуатации стал доступен отдельному человеку, а не отделу предприятия или университета. Наступила эра персональных компьютеров. Первоначально ПЭВМ предназначались для использования одним пользователем в однопрограммном режиме, что повлекло за собой деградацию архитектуры этих ЭВМ и их операционных систем (в частности, пропала необходимость защиты файлов и памяти, планирования заданий и т. п.).
Компьютеры стали использоваться не только специалистами, что потребовало разработки «дружественного» программного обеспечения.
Однако рост сложности и разнообразия задач, решаемых на персональных компьютерах, необходимость повышения надежности их работы привели к возрождению практически всех черт, характерных для архитектуры больших вычислительных систем.
В середине 80–х стали бурно развиваться сети компьютеров, в том числе персональных, работающих под управлением сетевых или распределенных операционных систем.
В сетевых операционных системах пользователи могут получить доступ к ресурсам другого сетевого компьютера, если они знают об их наличии и умеют это делать. Каждая машина в сети работает под управлением своей локальной ОС, отличающейся от операционной системы автономного компьютера наличием дополнительных средств программной поддержки для сетевых интерфейсных устройств и доступа к удаленным ресурсам.
Распределенная система, напротив, внешне выглядит как обычная автономная система. Пользователь не знает и не должен знать, где его файлы хранятся – на локальной или удаленной машине – и где его программы выполняются. Он может вообще не знать, подключен ли его компьютер к сети. Внутреннее строение распределенной ОС имеет существенные отличия от автономных систем.
В дальнейшем автономные операционные системы мы будем называть классическими операционными системами.
Просмотрев этапы развития вычислительных систем, мы можем выделить шесть основных функций, которые выполняли классические операционные системы в процессе эволюции:
- планирование заданий и использования процессора;
- обеспечение программ средствами коммуникации и синхронизации;
- управление памятью;
- управление файловой системой;
- управление вводом–выводом;
- обеспечение безопасности.
Каждая из приведенных функций обычно реализована в виде подсистемы, являющейся структурным компонентом ОС. Они не были изначально придуманы как составные части операционных систем, а появились в процессе развития, по мере того как вычислительные системы становились все более удобными, эффективными и безопасными.
8.3. Классификация операционных систем
Исходя из вышесказанного операционные системы можно разделить на три класса: системы пакетной обработки, системы разделения времени и системы реального времени. При этом можно видеть, что сетевые и распределенные ОС по существу не являются новым классом операционных систем, а отражают определенные свойства систем указанных классов.
Системы пакетной обработки предназначаются для решения задач в основном вычислительного характера, не требующих быстрого получения результатов. Главной целью и критерием эффективности систем пакетной обработки является максимальная пропускная способность ЭВМ, то есть решение максимального числа задач в единицу времени. Можно сказать, что они направлены на увеличение пропускной способности ЭВМ по потоку задач в целом, а не на ускорение решения отдельной наперед заданной задачи. Для достижения этой цели в системах пакетной обработки используется следующая схема функционирования: в начале работы формируется пакет заданий, каждое задание содержит требование к системным ресурсам; из этого пакета заданий формируется мультипрограммная смесь, то есть множество одновременно выполняемых задач. Для одновременного выполнения выбираются задачи, предъявляющие отличающиеся требования к ресурсам, так, чтобы обеспечивалась сбалансированная загрузка всех устройств вычислительной машины. Таким образом, выбор нового задания из пакета заданий зависит от внутренней ситуации, складывающейся в системе, то есть выбирается «выгодное» задание. Следовательно, в таких ОС невозможно гарантировать выполнение того или иного задания в течение определенного периода времени.
В системах пакетной обработки переключение процессора с выполнения одной задачи на выполнение другой происходит только в случае, если активная задача сама отказывается от процессора, например, из–за необходимости выполнить операцию ввода–вывода. Поэтому одна задача может надолго занять процессор, что делает невозможным выполнение интерактивных задач. Таким образом, взаимодействие пользователя с вычислительной машиной, на которой установлена система пакетной обработки, сводится к тому, что он приносит задание, отдает его диспетчеру–оператору, а в конце дня после выполнения всего пакета заданий получает результат. Очевидно, что такой порядок снижает эффективность работы пользователя.
Системы разделения времени призваны исправить основной недостаток систем пакетной обработки — изоляцию пользователя–программиста от процесса выполнения его задач. Каждому пользователю системы разделения времени предоставляется терминал, с которого он может вести диалог со своей программой. Так как в системах разделения времени каждой задаче выделяется только квант процессорного времени, ни одна задача не занимает процессор надолго, и время ответа оказывается приемлемым. Если квант выбран небольшим, то у всех пользователей, одновременно работающих на одной и той же машине, складывается впечатление, что каждый из них единолично использует машину. Ясно, что системы разделения времени обладают меньшей пропускной способностью, чем системы пакетной обработки, так как на выполнение принимается каждая запущенная пользователем задача, а не та, которая «выгодна» системе, и, кроме того, имеются накладные расходы вычислительной мощности на более частое переключение процессора с задачи на задачу. Критерием эффективности систем разделения времени является не максимальная пропускная способность, а удобство и эффективность работы пользователя.
Системы реального времени применяются для управления различными техническими объектами, такими, например, как станок, спутник, научная экспериментальная установка или технологическими процессами, такими как гальваническая линия, доменный процесс и т.п. Во всех этих случаях существует предельно допустимое время, в течение которого должна быть выполнена та или иная программа, управляющая объектом, в противном случае может произойти авария: спутник выйдет из зоны видимости, экспериментальные данные, поступающие с датчиков, будут потеряны, толщина гальванического покрытия не будет соответствовать норме. Таким образом, критерием эффективности для систем реального времени является их способность выдерживать заранее заданные интервалы времени между запуском программы и получением результата (управляющего воздействия). Это время называется временем реакции системы, а соответствующее свойство системы — реактивностью. Для этих систем мультипрограммная смесь представляет собой фиксированный набор заранее разработанных программ, а выбор программы на выполнение осуществляется исходя из текущего состояния объекта или в соответствии с расписанием плановых работ. Некоторые операционные системы могут совмещать в себе свойства систем разных типов, например, часть задач может выполняться в режиме пакетной обработки, а часть — в режиме реального времени или в режиме разделения времени. В таких случаях режим пакетной обработки часто называют фоновым режимом.
8.4. Основные понятия операционных систем
Системные вызовы. В любой операционной системе поддерживается механизм, который позволяет пользовательским программам обращаться к услугам ядра ОС. В операционных системах наиболее известной советской вычислительной машины БЭСМ–6 соответствующие средства назывались экстракодами, в операционных системах IBM — системными макрокомандами и т.д. В ОС Unix такие средства называют системными вызовами.
Системные вызовы (system calls) — это интерфейс между ОС и пользовательской программой. Они создают, удаляют и используют различные объекты, главные из которых — процессы и файлы. Пользовательская программа запрашивает сервис у операционной системы, осуществляя системный вызов. В результате осуществляется прерывание процессора, после чего управление передается обработчику данного вызова, входящему в ядро операционной системы. Поэтому системные вызовы иногда еще называют программными прерываниями, в отличие от аппаратных прерываний, которые чаще называют просто прерываниями. При этом ядро операционной системы имеет полный доступ к памяти пользовательской программы, и при системном вызове достаточно передать адреса одной или нескольких областей памяти с параметрами вызова и адреса одной или нескольких областей памяти для результатов вызова.
Прерывание (hardware interrupt) — это событие, генерируемое внешним (по отношению к процессору) устройством. Посредством аппаратных прерываний аппаратура либо информирует центральный процессор о том, что произошло какое–либо событие, требующее немедленной реакции (например, пользователь нажал клавишу), либо сообщает о завершении асинхронной операции ввода–вывода (например, закончено чтение данных с диска в основную память). Важный тип аппаратных прерываний — прерывания таймера, которые генерируются периодически через фиксированный промежуток времени. Прерывания таймера используются операционной системой при планировании процессов. Каждый тип аппаратных прерываний имеет собственный номер, однозначно определяющий источник прерывания. Аппаратное прерывание- это асинхронное событие, то есть оно возникает вне зависимости от того, какой код исполняется процессором в данный момент. Обработка аппаратного прерывания не должна учитывать, какой процесс является текущим.
Исключительная ситуация (exception) — событие, возникающее в результате попытки выполнения программой команды, которая по каким–то причинам не может быть выполнена. Примерами таких команд могут быть попытки доступа к ресурсу при отсутствии достаточных привилегий или обращения к отсутствующей странице памяти, выполнение операции деления на нуль и т.п. Исключительные ситуации, как и системные вызовы, являются синхронными событиями, возникающими в контексте выполняемой программы.
Файлы. Под файлом в самом общем случае понимают именованную часть пространства на внешнем носителе информации, предназначенную для хранения информации. Главная задача файловой системы (file system) - скрыть особенности ввода–вывода и дать программисту простую модель файлов, независимых от устройств. Для чтения, создания, удаления, записи, открытия и закрытия файлов имеется обширная категория системных вызовов (создание, удаление, открытие, закрытие, чтение и т.д.). Процессы. Понятие процесса в ОС тесно связано с понятием программа. По ходу выполнения программы компьютер обрабатывает различные команды и преобразует значения переменных. Для выполнения программы операционная система должна выделить определенное количество оперативной памяти, закрепить за ней устройства ввода–вывода или файлы, то есть зарезервировать ресурсы из общего числа ресурсов всей вычислительной системы. Для описания выполняющейся программы и используется термин процесс.
В простейшем случае процесс можно рассматривать как абстракцию, характеризующую программу во время выполнения. В действительности понятие процесса характеризует некоторую совокупность набора исполняющихся команд, ассоциированных с ним ресурсов (выделенная для исполнения память или адресное пространство, стеки, используемые файлы и устройства ввода–вывода и т. д.) и текущего момента его выполнения (значения регистров, программного счетчика, состояние стека и значения переменных), находящуюся под управлением ОС. Не существует взаимно–однозначного соответствия между процессами и программами, обрабатываемыми вычислительными системами. В некоторых операционных системах для работы определенных программ может организовываться более одного процесса или один и тот же процесс может исполнять последовательно несколько различных программ.
8.5. Основные подсистемы операционных систем
Обобщив вышесказанное, приходим к выводу, что в качестве основных в структуре ОС можно назвать следующие подсистемы: управление процессами, управление памятью, управление вводом–выводом, управление файлами, управление безопасностью.
8.5.1. Управление процессами
Все, что выполняется в вычислительных системах (не только программы пользователей, но и определенные части ОС), организовано как набор процессов. Понятно, что реально на однопроцессорной компьютерной системе в каждый момент времени может исполняться только один процесс. Для мультипрограммных вычислительных систем псевдопараллельная обработка нескольких процессов достигается с помощью переключения процессора с одного процесса на другой. Пока один процесс выполняется, остальные ждут своей очереди. В многозадачной (многопроцессной) системе процесс может находиться в одном из трех основных состояний:
- выполнение - активное состояние процесса, во время которого процесс обладает всеми необходимыми ресурсами и непосредственно выполняется процессором;
- ожидание - пассивное состояние процесса, процесс заблокирован, он не может выполняться по своим внутренним причинам, он ждет осуществления некоторого события, например, завершения операции ввода–вывода, получения сообщения от другого процесса, освобождения какого–либо необходимого ему ресурса;
- готовность - также пассивное состояние процесса, но в этом случае процесс заблокирован в связи с внешними по отношению к нему обстоятельствами: процесс имеет все требуемые для него ресурсы, он готов выполняться, однако процессор занят выполнением другого процесса.
В ходе жизненного цикла каждый процесс переходит из одного состояния в другое в соответствии с алгоритмом планирования процессов, реализуемым в данной операционной системе. Типичный граф состояний процесса показан на рисунке 8.1.
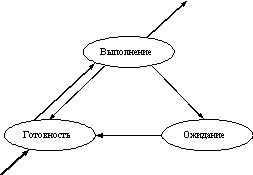
Рисунок 8.1 — Граф состояний процесса в многозадачной среде
В состоянии Выполнение в однопроцессорной системе может находиться только один процесс, а в каждом из состояний Ожидание и Готовность — несколько процессов, эти процессы образуют очереди соответственно ожидающих и готовых процессов. Жизненный цикл процесса начинается с состояния Готовность, когда процесс готов к выполнению и ждет своей очереди. При активизации процесс переходит в состояние Выполнение и находится в нем до тех пор, пока либо он сам освободит процессор, перейдя в состояние Ожидание какого–нибудь события, либо будет насильно «вытеснен» из процессора, например, вследствие исчерпания отведенного данному процессу кванта процессорного времени. В последнем случае процесс возвращается в состояние Готовность. В это же состояние процесс переходит из состояния Ожидание, после того как ожидаемое событие прои-зойдет.
На протяжении существования процесса его выполнение может быть многократно прервано и продолжено. Для того чтобы возобновить выполнение процесса, необходимо восстановить состояние его операционной среды. Состояние операционной среды отображается состоянием регистров и программного счетчика, режимом работы процессора, указателями на открытые файлы, информацией о незавершенных операциях ввода–вывода, кодами ошибок, выполняемых данным процессом системных вызовов и т.д. Эта информация называется контекстом процесса. Кроме этого, операционной системе для реализации планирования процессов требуется дополнительная информация: идентификатор процесса, состояние процесса, данные о степени привилегированности процесса, другая информация. В некоторых ОС информацию такого рода, используемую ОС для планирования процессов, называют дескриптором процесса. Дескриптор процесса по сравнению с контекстом содержит более оперативную информацию, которая должна быть легко доступна подсистеме планирования процессов. Контекст процесса содержит менее актуальную информацию и используется операционной системой только после того, как принято решение о возобновлении прерванного процесса.
Очереди процессов представляют собой дескрипторы отдельных процессов, объединенные в списки. Таким образом, каждый дескриптор, кроме всего прочего, содержит, по крайней мере, один указатель на другой дескриптор, соседствующий с ним в очереди. Такая организация очередей позволяет легко их переупорядочивать, включать и исключать процессы, переводить процессы из одного состояния в другое. Программный код только тогда начнет выполняться, когда для него операционной системой будет создан процесс. Создать процесс — это значит: создать информационные структуры, описывающие данный процесс, то есть его дескриптор и контекст; включить дескриптор нового процесса в очередь готовых процессов; загрузить кодовый сегмент процесса в оперативную память или в область свопинга.
8.5.2. Управление памятью
Программы вместе с данными, к которым они имеют доступ, в процессе выполнения должны находиться в оперативной памяти. Операционной системе приходится решать задачу распределения памяти между пользовательскими процессами и компонентами ОС. Эта деятельность называется управлением памятью.
Как мы уже знаем, запоминающие устройства компьютера разделяют, как минимум, на два уровня: основную (оперативную) и вторичную (внешнюю) память.
Основная память представляет собой упорядоченный массив однобайтовых ячеек, каждая из которых имеет свой уникальный адрес (номер). Обычно основная память изготавливается с применением полупроводниковых технологий и теряет свое содержимое при отключении питания.
Вторичную память (это главным образом диски) также можно рассматривать как одномерное линейное адресное пространство, состоящее из последовательности байтов. В отличие от оперативной памяти, она является энергонезависимой, имеет существенно большую емкость и используется в качестве расширения основной памяти.
Эту схему можно дополнить еще несколькими промежуточными уровнями, как показано на рисунке 5.1. Разновидности памяти могут быть объединены в иерархию по убыванию времени доступа, возрастанию цены и увеличению емкости.
Многоуровневую схему используют следующим образом. Информация, которая находится в памяти верхнего уровня, обычно хранится также на уровнях с большими номерами. Если процессор не обнаруживает нужную информацию на i–м уровне, он начинает искать ее на следующих уровнях. Когда нужная информация найдена, она переносится в память более высокого уровня.
Оказывается, при таком способе организации по мере снижения скорости доступа к уровню памяти снижается также и частота обращений к нему.
Память является важнейшим ресурсом, требующим тщательного управления со стороны мультипрограммной операционной системы. Распределению подлежит вся оперативная память, не занятая операционной системой. Обычно ОС располагается в самых младших адресах, однако может занимать и самые старшие адреса. Функциями ОС по управлению памятью являются: отслеживание свободной и занятой памяти; выделение памяти процессам и освобождение памяти при завершении процессов; вытеснение процессов из оперативной памяти на диск, когда размеры основной памяти не достаточны для размещения в ней всех процессов, и возвращение их в оперативную память, когда в ней освобождается место; настройка адресов программы на конкретную область физической памяти.
Типы адресов. Для идентификации переменных и команд используются символьные имена (метки), виртуальные и физические адреса (рисунок 8.2). Символьные имена присваивает пользователь при написании программы на алгоритмическом языке или языке ассемблера.
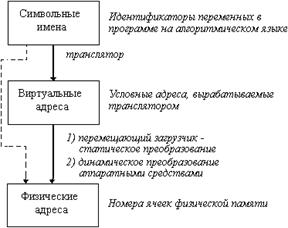
Рисунок 8.2 — Типы адресов
Виртуальные адреса вырабатывает транслятор, переводящий программу на машинный язык. Так как во время трансляции в общем случае не известно, в какое место оперативной памяти будет загружена программа, то транслятор присваивает переменным и командам виртуальные (условные) адреса, обычно считая по умолчанию, что программа будет размещена, начиная с нулевого адреса. Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. Каждый процесс имеет собственное виртуальное адресное пространство. Максимальный размер виртуального адресного пространства ограничивается разрядностью адреса, присущей данной архитектуре компьютера, и, как правило, не совпадает с объемом физической памяти, имеющимся в компьютере.
Физические адреса соответствуют номерам ячеек оперативной памяти, где в действительности расположены или будут расположены переменные и команды. Переход от виртуальных адресов к физическим может осуществляться двумя способами. В первом случае замену виртуальных адресов на физические делает специальная системная программа — перемещающий загрузчик. Перемещающий загрузчик на основании имеющихся у него исходных данных о начальном адресе физической памяти, в которую предстоит загружать программу, и информации, предоставленной транслятором об адресно–зависимых константах программы, выполняет загрузку программы, совмещая ее с заменой виртуальных адресов физическими.
Второй способ заключается в том, что программа загружается в память в неизмененном виде в виртуальных адресах, при этом операционная система фиксирует смещение действительного расположения программного кода относительно виртуального адресного пространства. Во время выполнения программы при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Второй способ является более гибким, он допускает перемещение программы во время ее выполнения, в то время как перемещающий загрузчик жестко привязывает программу к первоначально выделенному ей участку памяти. Вместе с тем использование перемещающего загрузчика уменьшает накладные расходы, так как преобразование каждого виртуального адреса происходит только один раз во время загрузки, а во втором случае — каждый раз при обращении по данному адресу.
В некоторых случаях, когда заранее точно известно, в какой области оперативной памяти будет выполняться программа, транслятор формирует исполняемый код сразу в физических адресах.
Адреса в основной памяти, характеризующие реальное расположение данных в ней, называются физическими адресами. Набор физических адресов, с которым работает программа, называют физическим адресным пространством.
Методы распределения памяти. Все методы управления памятью могут быть разделены на два класса: методы, не использующие перемещение процессов между оперативной памятью и диском, и методы, которые делают это (рисунок 8.3).
Методы распределения памяти без использования дискового пространства. Самым простым способом управления оперативной памятью является ее предварительное (обычно на этапе генерации или в момент загрузки системы) разбиение на несколько разделов фиксированной величины (схема с фиксированными разделами). Поступающие процессы помещаются в тот или иной раздел. При этом происходит условное разбиение физического адресного пространства. Связывание логических и физических адресов процесса происходит на этапе его загрузки в конкретный раздел, иногда — на этапе компиляции.
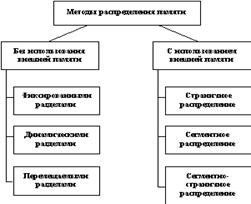
Рисунок 8.3 – Классификация методов распределения памяти
Каждый раздел может иметь свою очередь процессов, а может существовать и глобальная очередь для всех разделов (рисунок 8.4).
Эта схема была реализована в IBM OS/360 (MFT), DEC RSX–11 и ряде других систем.
Подсистема управления памятью оценивает размер поступившего процесса, выбирает подходящий для него раздел, осуществляет загрузку процесса в этот раздел и настройку адресов.
Очевидный недостаток этой схемы — число одновременно выполняемых процессов ограничено числом разделов.
Распределение памяти разделами переменной величины. В этом случае память машины не делится заранее на разделы, каждой вновь поступающей программе выделяется необходимая ей память. Если достаточный объем памяти отсутствует, то программа не принимается на выполнение и стоит в очереди. После завершения программы память освобождается и на это место может быть загружена другая программа. Таким образом, в произвольный момент времени оперативная память представляет собой случайную случайную последовательность занятых и свободных участков (разделов) произвольного размера (рисунок 8.5).
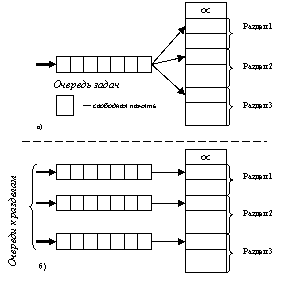
Рисунок 8.4 — Распределение памяти фиксированными разделами
а) — с общей очередью; б) — с отдельными очередями
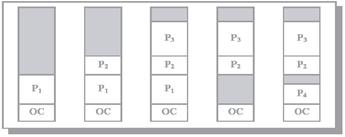
Рисунок 8.5 — Динамика распределения памяти между процессами
Задачами операционной системы при реализации данного метода управления памятью являются:
- ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти;
- при поступлении новой программы — анализ запроса, просмотр таблицы свободных областей и выбор раздела, размер которого достаточен для размещения поступившей программы;
- загрузка программы в выделенный ей раздел и корректировка таблиц свободных и занятых областей;
- после завершения программы корректировка таблиц свободных и занятых областей.
Программный код не перемещается во время выполнения, то есть может быть проведена единовременная настройка адресов посредством использования перемещающего загрузчика. По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток — фрагментация памяти. Фрагментация — это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Перемещаемые разделы. Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших либо в сторону младших адресов так, чтобы вся свободная память образовывала единую свободную область. В дополнение к функциям, которые выполняет ОС при распределении памяти переменными разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется сжатием. Сжатие может выполняться либо при каждом завершении программы, либо только тогда, когда для вновь поступившей программы нет свободного раздела достаточного размера. Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то преобразование адресов из виртуальной формы в физическую должно выполняться динамическим способом.
Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени, что часто перевешивает преимущества данного метода.
Методы распределения памяти с использованием дискового пространства. Описанные выше схемы недостаточно эффективно используют память, поэтому в современных схемах управления памятью не принято размещать процесс в оперативной памяти одним непрерывным блоком. Вообще, необходимо отметить, что проблема размещения в памяти программ, размер которых превышает имеющуюся в наличии свободную память, существовала всегда. С появлением внешней памяти на начальных этапах решением было разбиение программы на части, называемые оверлеями. Нулевой оверлей начинал выполняться первым. Когда он заканчивал свое выполнение, он вызывал другой оверлей. Все оверлеи хранились на диске и перемещались между памятью и диском средствами ОС. Однако разбиение программы на части и планирование их загрузки в оперативную память должен был осуществлять программист.
Развитие работ в этом направлении привело к появлению понятия виртуальной памяти, позволяющей пользователям писать программы, размер которых превосходит имеющуюся оперативную память. Осуществляется это, как и в случае с оверлеями, за счет использования дискового пространства, но уже в автоматическом режиме, без участия программиста. Можно сказать, что виртуальная память – это пространство, образованное множеством виртуальных адресов программы, размеры которого часто превосходят размеры реальной физической оперативной памяти.
При работе с виртуальной памятью ОС решает следующие задачи:
- размещает данные в запоминающих устройствах разного типа, например, часть программы в оперативной памяти, а часть — на диске;
- перемещает по мере необходимости данные между запоминающими устройствами разного типа, например, подгружает нужную часть программы с диска в оперативную память;
- преобразует виртуальные адреса в физические.
Наиболее распространенными реализациями виртуальной памяти является страничное, сегментное и странично–сегментное распределение памяти, а также свопинг.
Страничное распределение. На рисунке 8.6 показана схема страничного распределения памяти. Виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами.
В общем случае размер виртуального адресного пространства не является кратным размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью. Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами (или блоками).
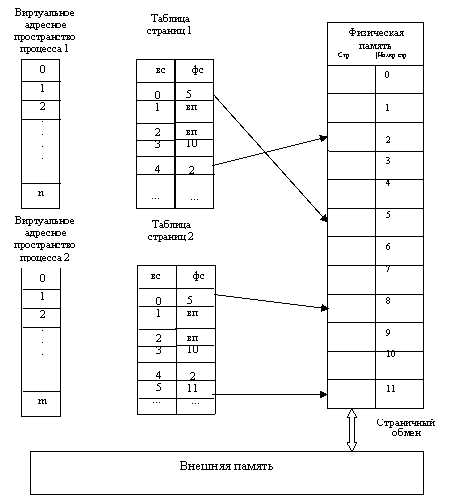
ВС — виртуальная страница; ФС — физическая страница;
ВП — внешняя память
Рисунок 8.6 — Страничное распределение памяти
Размер страницы обычно выбирается равным степени двойки (512, 1024 и т.д.), что позволяет упростить механизм преобразования виртуальных адресов в физические. При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные — на диск. Смежные виртуальные страницы не обязательно располагаются в смежных физических страницах. При этом ОС создает для каждого процесса таблицу страниц, в которой устанавливается соответствие между номерами виртуальных и физических страниц для страниц, загруженных в оперативную память, или делается отметка о том, что виртуальная страница выгружена на диск. Кроме того, в таблице страниц содержится управляющая информация, такая как признак невыгружаемости (выгрузка некоторых страниц может быть запрещена), признак обращения к странице (используется для подсчета числа обращений за определенный период времени) и другие данные, формируемые и используемые механизмом виртуальной памяти.
При активизации очередного процесса в специальный регистр процессора загружается адрес таблицы страниц данного процесса.
При каждом обращении к памяти происходит чтение из таблицы страниц информации о виртуальной странице, к которой произошло обращение. Если данная виртуальная страница находится в оперативной памяти, то выполняется преобразование виртуального адреса в физический. Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания, и активизируется другой процесс из очереди готовых. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то решается вопрос, какую страницу следует выгрузить из оперативной памяти. После того, как выбрана страница, которая должна покинуть оперативную память, анализируется ее признак модификации (из таблицы страниц). Если выталкиваемая страница с момента загрузки была модифицирована, то ее новая версия должна быть переписана на диск. Если нет, то она может быть просто уничтожена, то есть соответствующая физическая страница объявляется свободной.
Рассмотрим механизм преобразования виртуального адреса в физический при страничной организации памяти (рисунок 8.7).
Виртуальный адрес при страничном распределении может быть представлен в виде пары (p, s), где p — номер виртуальной страницы процесса (нумерация страниц начинается с 0), а s — смещение в пределах виртуальной страницы. Учитывая, что размер страницы равен 2 в степени к, смещение s может быть получено простым отделением k младших разрядов в двоичной записи виртуального адреса. Оставшиеся старшие разряды представляют собой двоичную запись номера страницы p. При каждом обращении к оперативной памяти аппаратными средствами выполняются следующие действия: на основании начального адреса таблицы страниц (содержимое регистра адреса таблицы страниц), номера виртуальной страницы (старшие разряды виртуального адреса) и длины записи в таблице страниц (системная константа) определяется адрес нужной записи в таблице; из этой записи извлекается номер физической страницы; к номеру физической страницы присоединяется смещение (младшие разряды виртуального адреса).
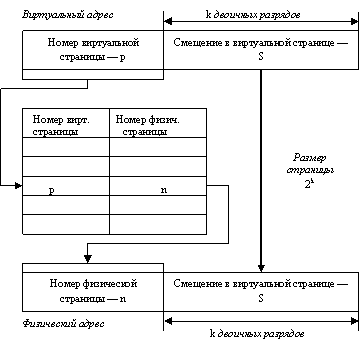
Рисунок 8.7 — Механизм преобразования виртуального адреса в физический при страничной организации памяти
Использование того факта, что размер страницы равен степени 2, позволяет применить операцию конкатенации (присоединения) вместо более длительной операции сложения, что уменьшает время получения физического адреса, а значит, повышает производительность компьютера.
На производительность системы со страничной организацией памяти влияют временные затраты, связанные с обработкой страничных прерываний и преобразованием виртуального адреса в физический. Время преобразования виртуального адреса в физический в значительной степени определяется временем доступа к таблице страниц. В связи с этим таблицу страниц стремятся размещать в «быстрых» запоминающих устройствах. Это может быть, например, набор специальных регистров или память, использующая для уменьшения времени доступа ассоциативный поиск и кэширование данных.
Сегментное распределение. При страничной организации виртуальное адресное пространство процесса делится механически на равные части, что не позволяет дифференцировать способы доступа к разным частям программы (сегментам), а также организовать разделение одного сегмента несколькими процессами. Например, если два процесса используют одну и ту же подпрограмму, то в оперативную память может быть загружена только одна копия этой подпрограммы.
Рассмотрим, каким образом сегментное распределение памяти реализует эти возможности (рисунок 8.8). Виртуальное адресное пространство процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т.п. Иногда сегментация программы выполняется по умолчанию компилятором.
При загрузке процесса часть сегментов помещается в оперативную память, а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Во время загрузки система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается начальный физический адрес сегмента в оперативной памяти, размер сегмента, правила доступа, признак модификации, признак обращения к данному сегменту за последний интервал времени и некоторая другая информация. Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.
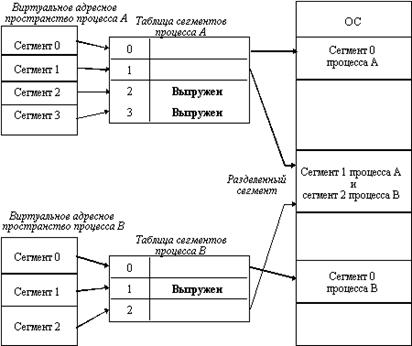
Рисунок 8.8 — Распределение памяти сегментами
Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту.
Виртуальный адрес при сегментной организации памяти может быть представлен парой (g, s), где g — номер сегмента, а s — смещение в сегменте. Физический адрес получается путем сложения начального физического адреса сегмента, найденного в таблице сегментов по номеру g, и смещения s.
Недостатком данного метода распределения памяти является фрагментация на уровне сегментов и более медленное по сравнению со страничной организацией преобразование адреса.
Странично–сегментное распределение. Хранить в памяти сегменты большого размера целиком так же неудобно, как и хранить процесс непрерывным блоком. Напрашивается идея разбиения сегментов на страницы. В этом случае виртуальное пространство процесса делится на сегменты, а каждый сегмент в свою очередь делится на виртуальные страницы, которые нумеруются в пределах сегмента (рисунок 8.9).

Рисунок 8.9 — Странично–сегментное распределение памяти
Оперативная память делится на физические страницы. Загрузка процесса выполняется ОС постранично, при этом часть страниц размещается в оперативной памяти, а часть — на диске. Для каждого сегмента создается своя таблица страниц, структура которой полностью совпадает со структурой таблицы страниц, используемой при страничном распределении. Для каждого процесса создается таблица сегментов, в которой указываются адреса таблиц страниц для всех сегментов данного процесса. Адрес таблицы сегментов загружается в специальный регистр процессора, когда активизируется соответствующий процесс. На рисунке 8.9 показана схема преобразования виртуального адреса в физический для данного метода.
Свопинг. Разновидностью виртуальной памяти является свопинг. В соответствии с этим методом некоторые процессы (обычно находящиеся в состоянии ожидания) временно выгружаются на диск. Планировщик операционной системы не исключает их из своего рассмотрения, и при наступлении условий активизации некоторого процесса, находящегося в области свопинга на диске, этот процесс перемещается в оперативную память. Если свободного места в оперативной памяти не хватает, то выгружается другой процесс.
При свопинге, в отличие от рассмотренных ранее методов реализации виртуальной памяти, процесс перемещается между памятью и диском целиком, то есть в течение некоторого времени процесс может полностью отсутствовать в оперативной памяти. Существуют различные алгоритмы выбора процессов на загрузку и выгрузку, а также различные способы выделения оперативной и дисковой памяти загружаемому процессу.
8.5.3. Управление вводом–выводом
Функционирование любой вычислительной системы обычно сводится к выполнению двух видов работ: обработке информации и операций по осуществлению ее ввода–вывода. Одной из главных функций ОС при этом является управление всеми устройствами ввода–вывода компьютера. ОС должна передавать устройствам команды, перехватывать прерывания и обрабатывать ошибки; она также должна обеспечивать интерфейс между устройствами и остальной частью системы.
В целях развития интерфейс должен быть одинаковым для всех типов устройств (независимость от устройств).
Физические принципы организации ввода–вывода. Устройства ввода–вывода делятся на два типа: блок–ориентированные и байт–ориентированные. Блок–ориентированные устройства хранят информацию в блоках фиксированного размера, каждый из которых имеет свой собственный адрес. Самое распространенное блок–ориентированное устройство — диск. Байт–ориентированные устройства не адресуемы и не позволяют производить операцию поиска, они генерируют или потребляют последовательность байтов. Примерами являются терминалы, строчные принтеры и др. Однако некоторые внешние устройства не относятся ни к одному классу, например, часы, которые, с одной стороны, не адресуемы, а с другой стороны, не порождают потока байтов. Это устройство только выдает сигнал прерывания в некоторые моменты времени. Внешнее устройство обычно состоит из механического и электронного компонента. Электронный компонент называется контроллером устройства, или адаптером. Механический компонент представляет собственно устройство. Некоторые контроллеры могут управлять несколькими устройствами. Операционная система обычно имеет дело не с устройством, а с контроллером. Контроллер, как правило, выполняет простые функции, например, преобразует поток бит в блоки, состоящие из байт, и осуществляет контроль и исправление ошибок. Каждый контроллер имеет несколько регистров, которые используются для взаимодействия с центральным процессором. В некоторых компьютерах эти регистры являются частью физического адресного пространства. В таких компьютерах нет специальных операций ввода–вывода. В других компьютерах адреса регистров ввода–вывода, называемых портами, образуют собственное адресное пространство за счет введения специальных операций ввода–вывода.
ОС выполняет ввод–вывод, записывая команды в регистры контроллера. При завершении команды контроллер организует прерывание для того, чтобы передать управление процессором операционной системе, которая должна проверить результаты операции. Процессор получает результаты и статус устройства, читая информацию из регистров контроллера.
Несмотря на все многообразие устройств, управление их работой и обмен информацией с ними строятся на относительно небольшом наборе принципов, которые мы и рассмотрим ниже.
Общие сведения об архитектуре современного компьютера. В простейшем случае процессор, память и внешние устройства связаны большим количеством электрических соединений — линий, которые в совокупности принято называть локальной магистралью компьютера. Внутри локальной магистрали линии, служащие для передачи сходных сигналов и предназначенные для выполнения сходных функций, принято группировать в шины. При этом понятие шины включает в себя не только набор проводников, но и набор жестко заданных протоколов, определяющий перечень сообщений, который может быть передан с помощью электрических сигналов по этим проводникам. В современных компьютерах выделяют, как минимум, три шины:
- шину данных, состоящую из линий данных и служащую для передачи информации между процессором и памятью, процессором
и устройствами ввода–вывода, памятью и внешними устройствами; - адресную шину, состоящую из линий адреса и служащую для задания адреса ячейки памяти или указания устройства ввода–вывода, участвующих в обмене информацией;
- шину управления, состоящую из линий управления локальной магистралью и линий ее состояния, определяющих поведение локальной магистрали.
Количество линий, входящих в состав шины, принято называть разрядностью (шириной) этой шины. Ширина адресной шины, например, определяет максимальный размер оперативной памяти, которая может быть установлена в вычислительной системе. Ширина шины данных определяет максимальный объем информации, которая за один раз может быть получена или передана по этой шине.
Внешние устройства разнесены пространственно и могут подключаться к локальной магистрали в одной или множестве точек, получивших название портов ввода–вывода. При этом каждый порт получает свой номер или адрес в адресном пространстве портов ввода–вывода.
В некоторых случаях, когда адресное пространство оперативной памяти задействовано не полностью (остались адреса, которым не соответствуют физические ячейки памяти) и протоколы работы с внешним устройством совместимы с протоколами работы с памятью, часть портов ввода–вывода может быть отображена непосредственно в адресное пространство памяти (так, например, поступают с видеопамятью дисплеев). В этом случае действия, необходимые для обмена данными с внешними устройствами, не отличаются от действий, производимых для передачи информации между оперативной памятью и процессором, и для их выполнения применяются те же самые команды.
Если же порт отображен в адресное пространство портов ввода–вывода, то процесс обмена информацией инициируется специальными командами ввода–вывода. Что именно должны делать устройства, приняв информацию через свой порт, и каким именно образом они должны поставлять информацию для чтения из порта, определяется электронными схемами устройств, получившими название контроллеров. Контроллер может непосредственно управлять отдельным устройством (например, контроллер диска), а может управлять несколькими устройствами, связываясь с их контроллерами посредством специальных шин ввода–вывода.
Выделим некоторые общие черты контроллеров, необходимые им для взаимодействия с вычислительной системой. Обычно каждый контроллер имеет, по крайней мере, четыре внутренних регистра, называемых регистрами состояния, управления, входных данных и выходных данных. Для доступа к содержимому этих регистров вычислительная система может использовать один или несколько портов. Для простоты изложения будем считать, что каждому регистру соответствует свой порт.
Регистр состояния содержит биты, значение которых определяется состоянием устройства ввода–вывода и которые доступны только для чтения вычислительной системой. Эти биты индицируют завершение выполнения текущей команды на устройстве (бит занятости), наличие очередного данного в регистре выходных данных (бит готовности данных), возникновение ошибки при выполнении команды (бит ошибки) и т. д.
Регистр управления получает данные, которые записываются вычислительной системой для инициализации устройства ввода–вывода или выполнения очередной команды, а также изменения режима работы устройства. Часть битов в этом регистре может быть отведена под код выполняемой команды, часть битов будет кодировать режим работы устройства, бит готовности команды свидетельствует о том, что можно приступить к ее выполнению.
Регистр выходных данных служит для помещения в него данных для чтения вычислительной системой, а регистр входных данных предназначен для помещения в него информации, которая должна быть выведена на устройство.
Рассмотрим, как выполняется команда вывода данных на внешнее устройство с использованием контроллера:
- процессор читает информацию из порта регистра состояний и проверяет значение бита занятости. Если бит занятости установлен, то это означает, что устройство еще не завершило предыдущую операцию, и процессор повторяет операцию чтения. Если бит занятости сброшен, то устройство готово к выполнению новой операции, и процессор переходит на следующий шаг;
- процессор записывает код команды вывода в порт регистра управления;
- процессор записывает данные в порт регистра входных данных;
- процессор устанавливает бит готовности команды. В следующих шагах процессор не задействован;
- когда контроллер определяет, что бит готовности команды установлен, он устанавливает бит занятости;
- контроллер анализирует код команды в регистре управления и обнаруживает, что это команда вывода. Он берет данные из регистра входных данных и инициирует выполнение команды;
- после завершения операции контроллер обнуляет бит готовности команды;
- при успешном завершении операции контроллер обнуляет бит ошибки в регистре состояния, при неудачном завершении команды – устанавливает его;
- контроллер сбрасывает бит занятости.
Как видим, процессор ожидает освобождения устройства, непрерывно опрашивая значение бита занятости. Такой способ взаимодействия процессора и контроллера получил название способа опроса устройств.
Для того чтобы процессор не дожидался состояния готовности устройства ввода–вывода, непрерывно опрашивая его, а мог выполнять в это время другую работу, необходимо, чтобы устройство само умело сигнализировать процессору о своей готовности. Механизм, который позволяет внешним устройствам оповещать процессор о завершении команды вывода или команды ввода, получил название механизма внешних прерываний.
В простейшем случае для реализации механизма прерываний необходимо к имеющимся шинам локальной магистрали добавить еще одну линию, соединяющую процессор и устройства ввода–вывода — линию прерываний. По завершении выполнения операции внешнее устройство выставляет на эту линию специальный сигнал, по которому процессор после выполнения очередной команды изменяет свое поведение. Вместо выполнения очередной команды из потока команд он частично сохраняет содержимое своих регистров и переходит на выполнение программы обработки прерывания, расположенной по заранее оговоренному адресу. При наличии только одной линии прерываний процессор при выполнении этой программы должен опросить состояние всех устройств ввода–вывода, чтобы определить, от какого именно устройства пришло прерывание, выполнить необходимые действия (например, вывести в это устройство очередную порцию информации или перевести соответствующий процесс из состояния ожидание в состояние готовность) и сообщить устройству, что прерывание обработано (снять прерывание).
В большинстве современных компьютеров устройства сообщают о своей готовности процессору не напрямую, а через специальный контроллер прерываний, при этом для общения с процессором он может использовать не одну линию, а целую шину прерываний. Каждому устройству присваивается свой номер прерывания, который при возникновении прерывания контроллер прерывания заносит в свой регистр состояния для дальнейшей передачи процессору по специальному запросу. Номер прерывания обычно служит индексом в специальной таблице прерываний, хранящейся по адресу, задаваемому при инициализации вычислительной системы, и содержащей адреса программ обработки прерываний — векторы прерываний. Обычно при установке в систему нового устройства ввода–вывода требуется аппаратно или программно определить, каким будет номер прерывания, вырабатываемый этим устройством.
Не все внешние устройства являются одинаково важными с точки зрения вычислительной системы. Соответственно, некоторые прерывания являются более существенными, чем другие. Контроллер прерываний обычно позволяет устанавливать приоритеты для прерываний от внешних устройств. При одновременном возникновении прерываний от нескольких устройств процессору сообщается номер наиболее приоритетного прерывания для его обслуживания в первую очередь. Менее приоритетное прерывание при этом не пропадает, о нем процессору будет доложено после обработки более приоритетного прерывания. Более того, при обработке возникшего прерывания процессор может получить сообщение о возникновении прерывания с более высоким приоритетом и переключиться на его обработку.
Похожим образом процессор обрабатывает исключительные ситуации и программные прерывания (внутренние прерывания). Исключительные ситуации возникают во время выполнения процессором команды. К их числу относятся ситуации переполнения, деления на ноль, обращения к отсутствующей странице памяти и т. д. Программные прерывания возникают после выполнения специальных команд, как правило, для выполнения привилегированных действий внутри системных вызовов.
Использование механизма прерываний позволяет разумно загружать процессор в то время, когда устройство ввода–вывода занимается своей работой. Однако запись или чтение большого количества информации, например, с диска, приводят к большому количеству операций ввода–вывода, которые должен выполнять процессор. Для освобождения процессора от операций последовательного вывода данных из оперативной памяти или последовательного ввода в нее был предложен механизм прямого доступа внешних устройств к памяти — ПДП или Direct Memory Access — DMA. Выполняется такой доступ через специальный контроллер прямого доступа к памяти, который и управляет такого рода обменом без участия центрального процессора (исключая этапы инициализации и окончания обмена).
Строение жесткого диска. Современный жесткий магнитный диск представляет собой набор круглых пластин, находящихся на одной оси и покрытых с одной или двух сторон специальным магнитным слоем (рисунок 8.10).
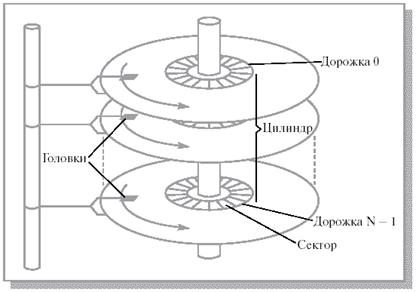
Рисунок 8.10 — Схема жесткого диска
Около каждой рабочей поверхности каждой пластины расположены магнитные головки для чтения и записи информации. Эти головки присоединены к специальному рычагу, который может перемещать весь блок головок над поверхностями пластин как единое целое. Поверхности пластин разделены на концентрические кольца, внутри которых, собственно, и может храниться информация. Набор концентрических колец на всех пластинах для одного положения головок (т. е. все кольца, равноудаленные от оси) образует цилиндр. Каждое кольцо внутри цилиндра получило название дорожки (по одной или две дорожки на каждую пластину). Все дорожки делятся на равное число секторов. Количество дорожек, цилиндров и секторов может варьироваться от одного жесткого диска к другому в достаточно широких пределах. Как правило, сектор является минимальным объемом информации, которая может быть прочитана с диска за один раз.
При работе диска набор пластин вращается вокруг своей оси с высокой скоростью, подставляя по очереди под головки соответствующих дорожек все их сектора. Номер сектора, номер дорожки и номер цилиндра однозначно определяют положение данных на жестком диске и, наряду с типом совершаемой операции — чтение или запись, полностью характеризуют часть запроса, связанную с устройством, при обмене информацией в объеме одного сектора.
Организация программного обеспечения ввода–вывода. Основная идея организации программного обеспечения ввода–вывода состоит в разбиении его на несколько уровней, причем нижние уровни обеспечивают экранирование особенностей аппаратуры от верхних, а те, в свою очередь, обеспечивают удобный интерфейс для пользователей.
Ключевым принципом является независимость от устройств. Вид программы не должен зависеть от того, читает ли она данные с гибкого или с жесткого диска. Очень близкой к идее независимости от устройств является идея единообразного именования, то есть для именования устройств должны быть приняты единые правила.
Другим важным вопросом для программного обеспечения ввода–вывода является обработка ошибок. Вообще говоря, ошибки следует обрабатывать как можно ближе к аппаратуре. Если контроллер обнаруживает ошибку чтения, то он должен попытаться ее скорректировать. Если же это ему не удается, то исправлением ошибок должен заняться драйвер устройства. Многие ошибки могут исчезать при повторных попытках выполнения операций ввода–вывода, например, ошибки, вызванные наличием пылинок на головках чтения или на диске. И только если нижний уровень не может справиться с ошибкой, он сообщает об ошибке верхнему уровню.
Еще один ключевой вопрос — это использование блокирующих (синхронных) и неблокирующих (асинхронных) передач. Большинство операций физического ввода–вывода выполняется асинхронно: процессор начинает передачу и переходит на другую работу, пока не наступает прерывание. Пользовательские программы намного легче писать, если операции ввода–вывода блокирующие: после команды READ программа автоматически приостанавливается до тех пор, пока данные не попадут в буфер программы. ОС выполняет операции ввода–вывода асинхронно, но представляет их для пользовательских программ в синхронной форме. Последняя проблема состоит в том, что одни устройства являются разделяемыми, а другие — выделенными. Диски — это разделяемые устройства, так как одновременный доступ нескольких пользователей к диску не представляет собой проблему. Принтеры — это выделенные устройства, потому что нельзя смешивать строчки, печатаемые различными пользователями. Наличие выделенных устройств создает для операционной системы некоторые проблемы. Для решения поставленных проблем целесообразно разделить программное обеспечение ввода–вывода на четыре слоя (рисунок 8.11):
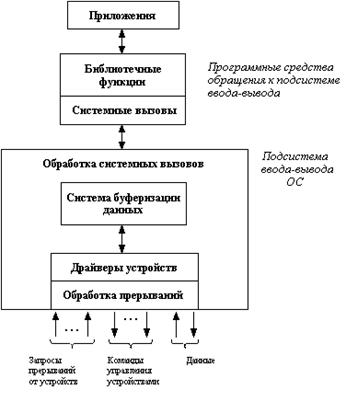
Рисунок 8.11 — Многоуровневая организация подсистемы ввода–вывода
- обработка прерываний;
- драйверы устройств;
- независимый от устройств слой операционной системы;
- пользовательский слой программного обеспечения.
Обработка прерываний. Прерывания должны быть скрыты как можно глубже в недрах операционной системы, чтобы как можно меньшая часть ОС имела с ними дело. Наилучший способ состоит в разрешении процессу, инициировавшему операцию ввода–вывода, блокировать себя до завершения операции и наступления прерывания. При наступлении прерывания процедура обработки прерывания выполняет разблокирование процесса, инициировавшего операцию ввода–вывода.
Драйверы устройств. Весь зависимый от устройства код помещается в драйвер устройства, являющийся частью операционной системы. Каждый драйвер управляет устройствами одного типа или, может быть, одного класса. В операционной системе только драйвер устройства знает о его конкретных особенностях. Например, только драйвер диска имеет дело с дорожками, секторами, цилиндрами, временем установления головки и другими факторами, обеспечивающими правильную работу диска. Драйвер устройства принимает запрос от устройств программного слоя и решает, как его выполнить. Типичным запросом является чтение n блоков данных. Если драйвер был свободен во время поступления запроса, то он начинает выполнять запрос немедленно. Если же он был занят обслуживанием другого запроса, то вновь поступивший запрос присоединяется к очереди уже имеющихся запросов, и он будет выполнен, когда наступит его очередь. Первый шаг в реализации запроса ввода–вывода, например, для диска, состоит в преобразовании его из абстрактной формы в конкретную. Для дискового драйвера это означает преобразование номеров блоков в номера цилиндров, головок, секторов, проверку, работает ли мотор, находится ли головка над нужным цилиндром. Короче говоря, он должен решить, какие операции контроллера нужно выполнить и в какой последовательности. После передачи команды контроллеру драйвер должен решить, блокировать ли себя до окончания заданной операции или нет. Если операция занимает значительное время, как при печати некоторого блока данных, то драйвер блокируется до тех пор, пока операция не завершится, и обработчик прерывания не разблокирует его. Если команда ввода–вывода выполняется быстро (например, прокрутка экрана), то драйвер ожидает ее завершения без блокирования.
Независимый от устройств слой операционной системы. Большая часть программного обеспечения ввода–вывода является независимой от устройств. Точная граница между драйверами и независимыми от устройств программами определяется системой, так как некоторые функции, которые могли бы быть реализованы независимым способом, в действительности выполнены в виде драйверов для повышения эффективности или по другим причинам. Типичными функциями для независимого от устройств слоя являются:
- обеспечение общего интерфейса к драйверам устройств;
- именование устройств;
- защита устройств;
- обеспечение независимого размера блока;
- буферизация;
- распределение памяти на блок–ориентированных устройствах;
- распределение и освобождение выделенных устройств;
- уведомление об ошибках.
Остановимся на некоторых функциях данного перечня.
Обеспечение независимого размера блока. Верхним слоям программного обеспечения неудобно работать с блоками разной величины, поэтому данный слой обеспечивает единый размер блока, например, за счет объединения нескольких различных блоков в единый логический блок. В связи с этим верхние уровни имеют дело с абстрактными устройствами, которые используют единый размер логического блока независимо от размера физического сектора.
Распределение памяти на блок–ориентированных устройствах. При создании файла или заполнении его новыми данными необходимо выделить ему новые блоки. Для этого ОС должна вести список или битовую карту свободных блоков диска. На основании информации о наличии свободного места на диске может быть разработан алгоритм поиска свободного блока, независимый от устройства и реализуемый программным слоем, находящимся выше слоя драйверов.
Буферизация. Под буфером обычно понимается некоторая область памяти для запоминания информации при обмене данными между двумя устройствами, двумя процессами или процессом и устройством. Здесь нас будет интересовать использование буферов в том случае, когда одним из участников обмена является внешнее устройство. Существует четыре причины, приводящие к использованию буферов в подсистеме ввода–вывода.
Разные скорости приема и передачи информации, которыми обладают участники обмена. Рассмотрим, например, случай передачи потока данных от клавиатуры к модему. Скорость, с которой поставляет информацию клавиатура, определяется скоростью набора текста человеком и обычно существенно меньше скорости передачи данных модемом. Для того чтобы не занимать модем на все время набора текста, делая его недоступным для других процессов и устройств, целесообразно накапливать введенную информацию в буфере или нескольких буферах достаточного размера и отсылать ее через модем после заполнения буферов.
Разные объемы данных, которые могут быть приняты или получены участниками обмена единовременно. Возьмем другой пример. Пусть информация поставляется модемом и записывается на жесткий диск. Помимо обладания разными скоростями совершения операций, модем и жесткий диск представляют собой устройства разного типа. Модем является символьным устройством и выдает данные байт за байтом, в то время как диск является блочным устройством и для проведения операции записи для него требуется накопить необходимый блок данных в буфере. Здесь также можно применять более одного буфера. После заполнения первого буфера модем начинает заполнять второй, одновременно с записью первого на жесткий диск. Поскольку скорость работы жесткого диска в тысячи раз больше, чем скорость работы модема, к моменту заполнения второго буфера операция записи первого будет завершена, и модем снова сможет заполнять первый буфер одновременно с записью второго на диск.
Необходимость копирования данных из приложений, осуществляющих ввод–вывод, в специальную область оперативной памяти, откуда они и будут выведены на внешнее устройство по мере освобождения последнего (в противном случае при использовании асинхронных обменов в пользовательской программе данные, подлежащие выводу на внешнее устройство, могут подвергнуться изменению еще до выполнения операции вывода).
Необходимость сокращения времени обмена между оперативной памятью и внешним устройством за счет использования механизма кэширования (с понятием кэш–памяти мы сталкивались при рассмотрении иерархии памяти).
Пользовательский слой программного обеспечения. Хотя большая часть программного обеспечения ввода–вывода находится внутри ОС, некоторая его часть содержится в библиотеках, связываемых с пользовательскими программами. Системные вызовы, включающие вызовы ввода–вывода, обычно делаются библиотечными процедурами. Набор подобных процедур является частью системы ввода–вывода.
В частности, форматирование ввода или вывода выполняется библиотечными процедурами. Стандартная библиотека ввода–вывода содержит большое число процедур, которые выполняют ввод–вывод и работают как часть пользовательской программы.
Другой категорией программного обеспечения ввода–вывода является подсистема спулинга (spooling). Спулинг — это способ работы с выделенными устройствами в мультипрограммной системе. Рассмотрим типичное устройство, требующее спулинга — строчный принтер. Хотя технически легко позволить каждому пользовательскому процессу открыть специальный файл, связанный с принтером, такой способ опасен из–за того, что пользовательский процесс может монополизировать принтер на произвольное время. Вместо этого создается специальный процесс — монитор, который получает исключительные права на использование этого устройства. Также создается специальный каталог, называемый каталогом спулинга. Для того чтобы напечатать файл, пользовательский процесс помещает выводимую информацию в этот файл и помещает его в каталог спулинга. Процесс–монитор по очереди распечатывает все файлы, содержащиеся в каталоге спулинга.
8.5.4. Управление файлами
Файловая система — это часть операционной системы, назначение которой состоит в том, чтобы организовать эффективную работу с данными, хранящимися во внешней памяти, и обеспечить пользователю удобный интерфейс при работе с такими данными.
В широком смысле понятие файловая система включает:
- совокупность всех файлов на диске;
- наборы структур данных, используемых для управления файлами, такие, например, как каталоги файлов, дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске;
- комплекс системных программных средств, реализующих управление файлами, в частности: создание, уничтожение, чтение, запись, именование, поиск и другие операции над файлами.
Перечислим основные функции файловой системы:
- идентификация файлов. Связывание имени файла с выделенным ему пространством внешней памяти;
- распределение внешней памяти между файлами. Для работы с конкретным файлом пользователю не требуется иметь информацию о местоположении этого файла на внешнем носителе информации. Например, для того чтобы загрузить документ в редактор с жесткого диска, нам не нужно знать, на какой стороне какого магнитного диска, на каком цилиндре и в каком секторе находится данный документ;
- обеспечение надежности и отказоустойчивости. Стоимость информации может во много раз превышать стоимость компьютера.
- обеспечение защиты от несанкционированного доступа;
- обеспечение совместного доступа к файлам так, чтобы пользователю не приходилось прилагать специальных усилий по обеспечению синхронизации доступа;
- обеспечение высокой производительности.
Иногда говорят, что файл — это поименованный набор связанной информации, записанной во вторичную память. Для большинства пользователей файловая система — наиболее видимая часть ОС, предоставляющая им механизм для хранения и доступа как к данным, так и к программам.
Имена файлов. Файлы идентифицируются именами. Пользователи дают файлам символьные имена, при этом учитываются ограничения ОС как на используемые символы, так и на длину имени. Так, в популярной файловой системе MS DOS — FAT длина имен ограничивается схемой 8.3 (8 символов — собственно имя, 3 символа — расширение имени), в ОС UNIX System V имя не может содержать более 14 символов, ОС Windows NT в файловой системе NTFS устанавливает, что имя файла может содержать до 255 символов. В соответствии со стандартом POSIX популярные ОС в настоящее время оперируют также длинными именами (до 255 символов). Длинные имена поддерживаются не только новыми файловыми системами, но и новыми версиями хорошо известных файловых систем. Например, в ОС Windows 95 используется файловая система VFAT, представляющая собой измененный вариант FAT, обеспечивающая поддержку длинных имен.
Обычно разные файлы могут иметь одинаковые символьные имена. В этом случае файл однозначно идентифицируется так называемым составным именем, представляющим собой последовательность символьных имен каталогов. В некоторых системах одному и тому же файлу не может быть дано несколько разных имен, а в других такое ограничение отсутствует. В последнем случае операционная система присваивает файлу дополнительно уникальное имя, так, чтобы можно было установить взаимно–однозначное соответствие между файлом и его уникальным именем. Уникальное имя представляет собой числовой идентификатор и используется программами операционной системы.
Типы файлов. Основные типы файлов: регулярные (обычные) файлы, специальные файлы и директории (каталоги). Обычные файлы в свою очередь подразделяются на текстовые и двоичные (бинарные). Текстовые файлы содержат символьные строки, которые можно распечатать, увидеть на экране или редактировать обычным текстовым редактором. Это могут быть документы, исходные тексты программ и т.п. Другой тип обычных файлов нетекстовые, или двоичные файлы. Обычно они имеют некоторую внутреннюю структуру, например, объектный код программы или архивный файл. Обычно прикладные программы, работающие с файлами, распознают тип файла по его имени в соответствии с общепринятыми соглашениями. Например, файлы с расширениями .c, .pas, .txt — ASCII–файлы, файлы с расширениями .exe —исполняемые, файлы с расширениями .rar, .zip — архивные и т. д. Специальные файлы — это файлы, ассоциированные с устройствами ввода–вывода, которые позволяют выполнять операции ввода–вывода с использованием обычных команд записи в файл или чтения из файла. Эти команды обрабатываются вначале программами файловой системы, а затем преобразуются ОС в команды управления соответствующим устройством. Специальные файлы так же, как и устройства ввода–вывода, делятся на блок–ориентированные и байт–ориентированные. Директория (каталог) — это, с одной стороны, группа файлов, объединенных пользователем исходя из некоторых соображений (например, файлы, содержащие программы игр, или файлы, составляющие один программный пакет), а с другой стороны, — это файл, содержащий системную информацию о группе файлов, его составляющих. В каталоге содержится список файлов, входящих в него, и устанавливается соответствие между файлами и их характеристиками (атрибутами).
В разных файловых системах могут использоваться в качестве атрибутов разные характеристики, обычно набор атрибутов содержит следующие элементы: основную информацию (имя, тип файла), адресную информацию (устройство, начальный адрес, размер), информацию об управлении доступом (владелец, допустимые операции) и информацию об использовании (даты создания, последнего чтения, модификации и др.). Список атрибутов обычно хранится в структуре директорий или других структурах, обеспечивающих доступ к данным файла.
Каталоги могут образовывать иерархическую структуру за счет того, что каталог более низкого уровня может входить в каталог более высокого уровня (рисунок 8.12). Иерархия каталогов может быть деревом или сетью. Каталоги образуют дерево, если файлу разрешено входить только в один каталог, и сеть, если файл может входить сразу в несколько каталогов. В MS–DOS и Windows каталоги образуют древовидную структуру, а в UNIX — сетевую. Как и любой другой файл, каталог имеет символьное имя и однозначно идентифицируется составным именем, содержащим цепочку символьных имен всех каталогов, через которые проходит путь от корня до данного каталога.
Логическая организация файла. Программист имеет дело с логической организацией файла, представляя файл в виде определенным образом организованных логических записей. Логическая запись — это наименьший элемент данных, которым может оперировать программист при организации обмена с внешним устройством.
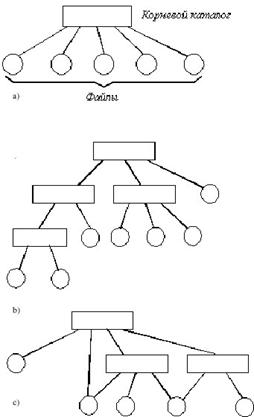
а) — одноуровневая; b) — иерархическая (дерево); c) — иерархическая (сеть)
Рисунок 8.12 — Организация файловой системы
Даже если физический обмен с устройством осуществляется большими единицами, операционная система обеспечивает программисту доступ к отдельной логической записи.
На рисунке 8.13 показаны несколько схем логической организации файла. Записи могут быть фиксированной или переменной длины, могут быть расположены в файле последовательно (последовательная организация) или в более сложном порядке, с использованием так называемых индексных таблиц, позволяющих обеспечить быстрый доступ к отдельной логической записи (индексно–последовательная организация). Для идентификации записи может быть использовано специальное поле записи, называемое ключом. В файловых системах ОС UNIX и MS–DOS файл имеет простейшую логическую структуру — последовательность однобайтовых записей.

Рисунок 8.13 — Способы логической организации файлов
Поясним подробнее наиболее сложную – с использованием индексных таблиц организацию файла. Индексная таблица обычно оформляется в виде отдельного — индексного файла (файла индексов), хранится на том же устройстве, что и основной файл, и состоит из списка элементов, каждый из которых содержит идентификатор (ключ) записи, за которым следует указание о местоположении данной записи. Для поиска записи вначале происходит обращение к файлу индексов, где находится указатель на нужную запись. В отличие от записей основного файла записи файла индексов имеют фиксированную длину, что позволяет упорядочивать их по значению ключа с целью ускорения поиска необходимой информации.
Физическая организация файла. Физическая организация файла описывает правила его расположения на устройстве внешней памяти, в частности, на диске, в виде набора блоков.
Блок — наименьшая единица данных, которой внешнее устройство обменивается с оперативной памятью.
Непрерывное размещение — простейший вариант физической организации, при котором файлу предоставляется последовательность блоков диска, образующих единый сплошной участок дисковой памяти. Для задания адреса файла в этом случае достаточно указать только номер начального блока. Но у этого способа имеются два существенных недостатка. Во–первых, во время создания файла заранее не известна его длина, а значит не известно, сколько памяти надо зарезервировать для его размещения, во–вторых, при таком порядке размещения неизбежно возникает эффект фрагментации, что приводит к неэффективному использованию внешней памяти. Следующий способ физической организации — размещение в виде связанного списка блоков дисковой памяти. При таком способе в начале каждого блока содержится указатель на следующий блок.
В этом случае адрес файла также может быть задан одним числом – номером первого блока. В отличие от предыдущего способа, каждый блок может быть встроен в цепочку какого–либо файла, следовательно, фрагментация отсутствует. Файл может изменяться во время своего существования, наращивая число блоков. Недостатком является сложность реализации доступа к произвольно заданному месту файла: для того чтобы прочитать пятый по порядку блок файла, необходимо последовательно прочитать четыре первых блока, прослеживая цепочку номеров блоков. Популярным способом является использование связанного списка индексов. В этом случае с каждым блоком связывается его идентификатор — индекс, совокупность которых размещается в отдельной области памяти. Если блок распределен некоторому файлу, то индекс этого блока содержит номер следующего блока данного файла. При такой физической организации сохраняются все достоинства предыдущего способа, но снимается отмеченный недостаток: для доступа к произвольному месту файла достаточно прочитать только блок индексов, отсчитать нужное количество блоков файла по цепочке и определить номер нужного блока.
Контроль доступа к файлам. Наличие в системе многих пользователей предполагает организацию контролируемого доступа к файлам.
Выполнение любой операции над файлом должно быть разрешено только в случае наличия у пользователя соответствующих прав доступа. Обычно контролируются следующие операции: чтение, запись и выполнение. Другие операции, например, копирование файлов или их переименование, также могут контролироваться. Однако они чаще реализуются через перечисленные. Так, операцию копирования файлов можно представить как операцию чтения и последующую операцию записи.
Различают два основных подхода к определению прав доступа:
- избирательный доступ, когда для каждого файла и каждого пользователя сам владелец может определить допустимые операции;
- мандатный подход, когда система наделяет пользователя определенными правами по отношению к каждому разделяемому ресурсу (в данном случае файлу) в зависимости от того, к какой группе пользователь отнесен.
Кэширование диска. В большинстве файловых систем запросы к внешним устройствам, в которых адресация осуществляется блоками (диски, ленты), перехватываются промежуточным программным слоем — подсистемой буферизации. Подсистема буферизации представляет собой буферный пул, располагающийся в оперативной памяти, и комплекс программ, управляющих этим пулом. Каждый буфер пула имеет размер, равный одному блоку. При поступлении запроса на чтение некоторого блока подсистема буферизации просматривает свой буферный пул и если находит требуемый блок, то копирует его в буфер запрашивающего процесса. Операция ввода–вывода считается выполненной, хотя физического обмена с устройством не происходило. Если же нужный блок в буферном пуле отсутствует, то он считывается с устройства и одновременно с передачей запрашивающему процессу копируется в один из буферов подсистемы буферизации. При отсутствии свободного буфера на диск вытесняется наименее используемая информация. Таким образом, подсистема буферизации работает по принципу кэш–памяти. Общая модель файловой системы. Функционирование любой файловой системы можно представить многоуровневой моделью (рисунок 8.14), в которой каждый уровень предоставляет некоторый интерфейс (набор функций) вышележащему уровню, а сам, в свою очередь, для выполнения своей работы использует интерфейс (обращается с набором запросов) нижележащего уровня.
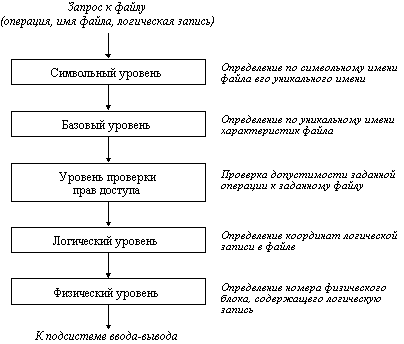
Рисунок 8.14 — Общая модель файловой системы
Задачей символьного уровня является определение по символьному имени файла его уникального имени. В файловых системах, в которых каждый файл может иметь только одно символьное имя, этот уровень отсутствует, так как символьное имя, присвоенное файлу пользователем, является одновременно уникальным и может быть использовано операционной системой. В других файловых системах, в которых один и тот же файл может иметь несколько символьных имен, на данном уровне просматривается цепочка каталогов для определения уникального имени файла.
На следующем, базовом уровне, по уникальному имени файла определяются его характеристики: права доступа, адрес, размер и другие.
Как уже было сказано, характеристики файла могут входить в состав каталога или храниться в отдельных таблицах. При открытии файла его характеристики перемещаются с диска в оперативную память, чтобы уменьшить среднее время доступа к файлу.
Следующим этапом реализации запроса к файлу является проверка прав доступа к нему. Для этого сравниваются полномочия пользователя или процесса, выдавших запрос, со списком разрешенных видов доступа к данному файлу. Если запрашиваемый вид доступа разрешен, то выполнение запроса продолжается, если нет, то выдается сообщение о нарушении прав доступа.
На логическом уровне определяются координаты запрашиваемой логической записи в файле, то есть требуется определить, на каком расстоянии (в байтах) от начала файла находится требуемая логическая запись. Алгоритм работы данного уровня зависит от логической организации файла. Например, если файл организован как последовательность логических записей фиксированной длины l, то n–я логическая запись имеет смещение l*(n–1) байт. Для определения координат логической записи в файле с индексно–последовательной организацией выполняется чтение таблицы индексов (ключей), в которой непосредственно указывается адрес логической записи.
На физическом уровне файловая система определяет номер физического блока, который содержит требуемую логическую запись, и смещение логической записи в физическом блоке. Для решения этой задачи используются результаты работы логического уровня: смещение логической записи в файле, адрес файла на внешнем устройстве, а также сведения о физической организации файла, включая размер блока. После определения номера физического блока, файловая система обращается к системе ввода–вывода для выполнения операции обмена с внешним устройством. В ответ на этот запрос в буфер файловой системы будет передан нужный блок, в котором на основании полученного при работе физического уровня смещения выбирается требуемая логическая запись.
Современные архитектуры файловых систем. Разработчики новых ОС стремятся обеспечить пользователя возможностью работать сразу с несколькими файловыми системами. Современная файловая система имеет многоуровневую структуру (рисунок 8.15), на верхнем уровне которой располагается переключатель, обеспечивающий интерфейс между запросами приложения и конкретной файловой системой, к которой обращается это приложение. Переключатель файловых систем преобразует запросы в формат, воспринимаемый следующим уровнем уровнем файловых систем.
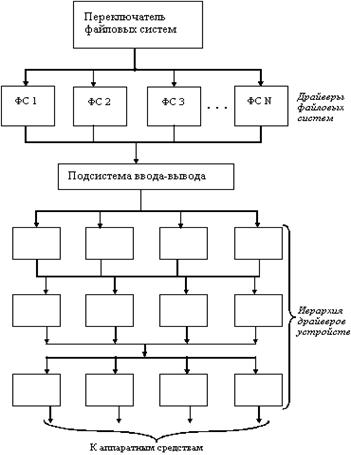
Рисунок 8.15 Архитектура современной файловой системы
Каждый компонент данного уровня выполнен в виде драйвера соответствующей файловой системы и поддерживает ее определенную организацию. Переключатель является единственным модулем, который может обращаться к драйверу файловой системы. Драйвер может быть написан в виде реентерабельного кода, что позволяет сразу нескольким приложениям выполнять операции с файлами. Каждый драйвер файловой системы в процессе собственной инициализации регистрируется у переключателя, передавая ему таблицу точек входа, которые будут использоваться при последующих обращениях к файловой системе.
Для выполнения своих функций драйверы файловых систем обращаются к подсистеме ввода–вывода, которая должна постоянно присутствовать в памяти и организовывать совместную работу иерархии драйверов устройств. В эту иерархию могут входить драйверы устройств определенного типа (драйверы жестких дисков или накопителей на лентах), драйверы, поддерживаемые поставщиками (такие драйверы перехватывают запросы к блочным устройствам и могут частично изменить поведение существующего драйвера этого устройства, например, зашифровать данные), драйверы портов, которые управляют конкретными адаптерами.
8.5.5. Защитные механизмы операционных систем
Перейдем к описанию системы защиты операционных систем. Ее основными задачами являются идентификация, аутентификация, авторизация — определение полномочий и уровня доступа пользователя к ресурсам, протоколирование и аудит.
Идентификация и аутентификация. Наиболее распространенным способом контроля доступа являются процедуры идентификации и последующей аутентификации пользователя. Идентификация основана на использовании регистрационного имени пользователя (идентификатора), позволяющего системе определить его атрибуты, заданные при первоначальной регистрации в ОС. Для того, чтобы установить, что пользователь именно тот, за кого себя выдает, используется процедура аутентификации, задача которой — предотвращение доступа к системе нежелательных лиц.
Обычно для аутентификации используются: ключ или магнитная карта; секретный пароль; отпечатки пальцев, подпись, голос и др.
Пароли. Наиболее простой подход к аутентификации — применение пароля. Когда пользователь идентифицирован системой, у него запрашивается пароль. Если пароль, сообщенный пользователем, совпадает с паролем, хранящимся в системе, система предполагает, что процедура аутентификации закончена.
Недостатки паролей связаны с тем, что они могут быть угаданы, случайно показаны или нелегально переданы одним пользователем другому.
Есть несколько основных способов выяснить чужой пароль. Один связан со сбором информации о пользователе (в качестве паролей часто используют имена, даты рождения, номерные знаки автомобилей и пр.), другой основан на переборе всех наиболее вероятных комбинаций букв, чисел и знаков пунктуации (атака по словарю). Кроме того, может быть просто похищена база данных о пользователях, в которой хранятся зашифрованные пароли, а затем применен специальный инструмент для их расшифровки. В некоторых случаях можно взломать пароль, получив информацию из пакетов запрос/ответ протокола аутентификации, перехваченных в сети. Чтобы заставить пользователя выбрать наиболее сложный пароль, во многих системах используется процедура, которая при помощи собственной программы–взломщика может оценить качество пароля, введенного пользователем.
Авторизация. После успешно выполненных процедур идентификации и аутентификации система должна предоставить пользователю права на доступ к ее ресурсам, определенные ранее администратором ОС. При этом система контроля доступа базируется на общей модели, называемой матрицей доступа. Рассмотрим ее более подробно.
Компьютерная система может быть представлена как набор субъектов (процессы, пользователи) и объектов. Под объектами мы понимаем как ресурсы оборудования (процессор, сегменты памяти, принтер, диски и ленты), так и программные ресурсы (файлы, программы), то есть все то, доступ к чему контролируется. Каждый объект имеет уникальное имя, отличающее его от других объектов в системе, и каждый из них может быть доступен через определенные операции.
Операции зависят от объектов. Hапример, процессор может только выполнять команды, сегменты памяти могут быть записаны и прочитаны, считыватель магнитных карт может только читать, а файлы данных могут быть записаны, прочитаны, переименованы и т. д.
Различают дискреционный (избирательный) способ управления доступом и полномочный (мандатный).
При дискреционном доступе определенные операции над конкретным ресурсом запрещаются или разрешаются субъектам. Текущее состояние прав доступа при дискреционном управлении описывается матрицей, в строках которой перечислены субъекты, в столбцах — объекты, а в ячейках — операции, которые субъект может выполнить над объектом.
Полномочный подход заключается в том, что все объекты могут иметь уровни секретности, а все субъекты делятся на группы, образующие иерархию в соответствии с уровнем допуска к информации. Иногда это называют моделью многоуровневой безопасности.
Большинство операционных систем реализуют дискреционное управление доступом. Главное его достоинство — гибкость, основные недостатки — рассредоточенность управления и сложность централизованного контроля.
Домены безопасности. Чтобы рассмотреть схему дискреционного доступа более детально, введем понятие домена безопасности. Каждый домен определяет набор объектов и типов операций, которые могут производиться над каждым объектом. Возможность выполнять операции над объектом есть права доступа, каждое из которых есть упорядоченная пара <имя объекта, вид доступа>. Домен, таким образом, есть набор прав доступа. Hапример, если домен D имеет права доступа <file F, {read, write}>, это означает, что процесс, выполняемый в домене D, может читать или писать в файл F, но не может выполнять других операций над этим объектом. Пример доменов можно увидеть на рисунке 8.16.
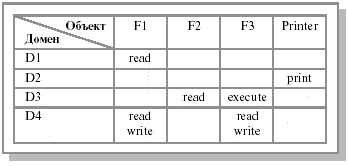
Рисунок 8.16 Специфицирование прав доступа к ресурсам
Связь конкретных субъектов, функционирующих в операционных системах, может быть организована следующим образом:
- каждому пользователю может соответствовать домен. В этом случае набор объектов, к которым может быть организован доступ, зависит от результатов идентификации пользователя;
- каждому процессу может соответствовать домен. В этом случае набор доступных объектов определяется идентификацией процесса;
- каждой процедуре может соответствовать домен. В этом случае набор доступных объектов соответствует локальным переменным, определенным внутри процедуры.
Матрица доступа. Список доменов безопасности может быть представлен в виде матрицы, называемой матрицей доступа. Эту матрицу можно разложить по столбцам, в результате чего получим списки
разрешенных прав доступа к каждому объекту для каждого домена. В результате разложения матрицы по строкам получаем списки разрешенных прав доступа ко всем объектам для каждого домена, т.е. характеристики соответствующего мандата.
Выявление вторжений. Аудит системы защиты. Обнаружение попыток вторжения является важнейшей задачей системы защиты, поскольку ее решение позволяет минимизировать ущерб от взлома и собирать информацию о методах вторжения. Как правило, поведение взломщика отличается от поведения легального пользователя. Иногда эти различия можно выразить количественно, например, подсчитывая число некорректных вводов пароля во время регистрации.
Основным инструментом выявления вторжений является сохранение данных аудита. Отдельные действия пользователей протоколируются, а полученный протокол используется для выявления вторжений.
Аудит, таким образом, заключается в регистрации специальных данных о различных типах событий, происходящих в системе и так или иначе влияющих на состояние безопасности компьютерной системы.
К числу таких событий обычно относят следующие: вход или выход из системы; выполнение операций над файлами (открытие, закрытие, переименование, удаление и пр.); обращение к удаленной системе; смена привилегий или иных атрибутов безопасности (режима доступа, уровня благонадежности пользователя и т. п.).
Если фиксировать все события в системе, объем регистрационной информации будет расти слишком быстро, а ее эффективный анализ станет невозможным. Обычно предусматривают наличие средств выборочного протоколирования как в отношении пользователей, так и в отношении событий.
Помимо протоколирования, можно периодически сканировать систему на наличие слабых мест в системе безопасности. Такого рода сканирование может проверить разнообразные аспекты системы (наличие легко раскрываемых паролей, изменения в системных программах, обнаруженные при помощи подсчета контрольных сумм и пр.).
Любая проблема, обнаруженная сканером безопасности, может быть как ликвидирована автоматически, так и передана для решения менеджеру системы.
Список литературы
1. Глушков, В.М. Основы безбумажной информатики [Текст] / В.М. Глушков. — М.: Наука, 1990. — 552 с.
2. Гуров, В.В. Основы теории и организации ЭВМ [Текст] / В.В. Гуров, В.О. Чуканов. — М.: Интернет–университет информационных технологий — ИНТУИТ.ру , 2006. — 280 с.
3. Baer, J. L. Computer Systems Architecture [Text] / J.L. Baer // Rockville, Md.: Computer Science Press. — 1980. — PP. 547—586.
4. Пятибратов, А.П. Вычислительные системы, сети и телекоммуникации [Текст]: учебник для ВУЗов / А.П. Пятибратов, А.А. Кириченко, Л.П. Гудыно. — М.: Финансы и статистика, 2002. — 400 с.
5. Карпов, В.Е. Основы операционных систем [Текст] / В.Е. Карпов, К.А. Коньков. — М.: Интернет–университет информационных технологий ИНТУИТ.ру , 2004. — 536 с.
6. Tanenbaum, Andrew S. Modern Operating Systems, 2/E [Text] / Andrew S. Tanenbaum. — Prentice Hall, 2001. — 976 pp.
7. Олифер, В.Г. Сетевые операционные системы [Текст] /
В.Г. Олифер, Н.А. Олифер. — СПб.: Питер, 2001. — 544 с.
8. Дейтел, Г. Введение в операционные системы [Текст]: [пер. с англ.]: В 2 т. / Г. Дейтел. — М.: Мир, 1987. — 2 т.
9. Кейслер, С. Проектирование операционных систем для малых ЭВМ [Текст]: [пер. с англ.] / С. Кейслер. — М.: Мир, 1986.
10. Краковяк, С. Основы организации и функционирования ОС ЭВМ [Текст]: [пер. с фр.] / С. Краковяк. — М.: Мир, 1988.
11. Мэдник, С. Операционные системы [Текст]: [пер. с англ.] /
С. Мэдник, Дж. Донован. — М.: Мир, 1978 .
12. Галатенко, В.А. Основы информационной безопасности [Текст] / В.А. Галатенко. — М.: Интернет–университет информационных технологий — ИНТУИТ.ру , 2005 — 208 с.
13. Уразалина, З.К. Я могу работать в Microsoft Windows [Текст] / З.К.Уразалина. — М.: Интернет–университет информационных технологий ИНТУИТ.ру , 2006. 232 с.
14. Курячий, Г.В. Операционная система Unix [Текст] / Г.В. Курячий. — М.: Интернет–университет информационных технологий — ИНТУИТ.ру, 2004. — 292 с.
15. Петерсен, Р. LINUX: руководство по операционной системе [Текст]: [пер. с англ.]: В 2 т. / Р. Петерсен. — Киев: Издательская группа BHV, 1999. — 2 т.