8.1.1. Вероятность появления ошибок для кодов Рида-Соломона
8.1.2. Почему коды Рида-Соломона эффективны при борьбе c импульсными помехами
8.1.4.1.Операция сложения в поле расширения GF(2m)
8.1.4.2. Описание конечного поля с помощью примитивного полинома
8.1.4.3. Поле расширения GF(23)
8.1.4.4. Простой тест для проверки полинома на примитивность
8.1.5. Кодирование Рида-Соломона
8.1.5.1. Кодирование в систематической форме
8.1.5.2. Систематическое кодирование с помощью (n-k)-разрядного регистра сдвига
8.1.6. Декодирование Рида-Соломона
8.1.6.4. Исправление принятого полинома с помощью найденного полинома ошибок
Коды Рида-Соломона (Reed-Solomon code, R-S code) — это недвоичные циклические коды, символы которых представляют собой m-битовые последовательности, где т—положительное целое число, большее 2. Код (n, K) определен на m-битовых символах при всех п и k, для которых
![]() (8.1)
(8.1)
где k — число информационных битов, подлежащих кодированию, а n — число кодовых символов в кодируемом блоке. Для большинства сверточных кодов Рида-Соломона (n,k)
![]() (8.2)
(8.2)
где t — количество ошибочных битов в символе, которые может исправить код, а и ![]() — число контрольных символов. Расширенный код Рида-Соломона можно получить при
— число контрольных символов. Расширенный код Рида-Соломона можно получить при ![]() , но не более того.
, но не более того.
Код Рида-Соломона обладает наибольшим минимальным расстоянием, возможным для линейного кода с одинаковой длиной входных и выходных блоков кодера. Для недвоичных кодов расстояние между двумя кодовыми словами определяется (по аналогии с расстоянием Хэмминга) как число символов, которыми отличаются последовательности. Для кодов Рида-Соломона минимальное расстояние определяется следующим образом [1].
![]() (8.3)
(8.3)
Код, который исправляет все искаженные символы, содержащие ошибку в t или меньшем числе бит, где t приведено в уравнении (6.44), можно выразить следующим образом.
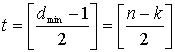 (8.4)
(8.4)
Здесь [x] означает наибольшее целое, не превышающее х. Из уравнения (8.4) видно, что коды Рида-Соломона, исправляющие t символьных ошибок, требуют не более 2t контрольных символов. Из уравнения (8.4) следует, что декодер имеет п-k "используемых" избыточных символов, количество которых вдвое превышает количество исправляемых ошибок. Для каждой ошибки один избыточный символ используется для обнаружения ошибки и один — для определения правильного значения. Способность кода к коррекции стираний выражается следующим образом.
![]() (8.5)
(8.5)
Возможность одновременной коррекции ошибок и стираний можно выразить как требование.
![]() (8.6)
(8.6)
Здесь ![]() — число символьных ошибочных комбинаций, которые можно исправить, а
— число символьных ошибочных комбинаций, которые можно исправить, а ![]() — количество комбинаций символьных стираний, которые могут быть исправлены. Преимущества недвоичных кодов, подобных кодам Рида-Соломона, можно увидеть в следующем сравнении. Рассмотрим двоичный код (п, k) = (7, 3). Полное пространство n-кортежей содержит
— количество комбинаций символьных стираний, которые могут быть исправлены. Преимущества недвоичных кодов, подобных кодам Рида-Соломона, можно увидеть в следующем сравнении. Рассмотрим двоичный код (п, k) = (7, 3). Полное пространство n-кортежей содержит ![]() n-кортежей, из которых
n-кортежей, из которых ![]() (или 1/16 часть всех n-кортежей) являются кодовыми словами. Затем рассмотрим недвоичный код (n, k)=(7, 3), где каждый символ состоит из т = 3 бит. Пространство n-кортежей содержит
(или 1/16 часть всех n-кортежей) являются кодовыми словами. Затем рассмотрим недвоичный код (n, k)=(7, 3), где каждый символ состоит из т = 3 бит. Пространство n-кортежей содержит ![]() 2 097 152 n-кортежа, из которых
2 097 152 n-кортежа, из которых ![]() (или 1/4096 часть всех n-кортежей) являются кодовыми словами. Если операции производятся над недвоичными символами, каждый из которых образован т битами, то только незначительная часть (т.е.
(или 1/4096 часть всех n-кортежей) являются кодовыми словами. Если операции производятся над недвоичными символами, каждый из которых образован т битами, то только незначительная часть (т.е. ![]() из большого числа
из большого числа ![]() ) возможных n-кортежей является кодовыми словами. Эта часть уменьшается с ростом т. Здесь важным является то, что если в качестве кодовых слов используется незначительная часть пространства n-кортежей, то можно достичь большего
) возможных n-кортежей является кодовыми словами. Эта часть уменьшается с ростом т. Здесь важным является то, что если в качестве кодовых слов используется незначительная часть пространства n-кортежей, то можно достичь большего ![]() .
.
Любой линейный код дает возможность исправить n-k комбинаций символьных стираний, если все n-k стертых символов приходятся на контрольные символы. Однако коды Рида-Соломона имеют замечательное свойство, выражающееся в том, что они могут исправить любой набор п-k символов стираний в блоке. Можно сконструировать коды с любой избыточностью. Впрочем, с увеличением избыточности растет сложность ее высокоскоростной реализации. Поэтому наиболее привлекательные коды Рида-Соломона обладают высокой степенью кодирования (низкой избыточностью).
8.1.1. Вероятность появления ошибок для кодов Рида-Соломона
Коды Рида-Соломона чрезвычайно эффективны для исправления пакетов ошибок, т.е. они оказываются эффективными в каналах с памятью. Также они хорошо зарекомендовали себя в каналах с большим набором входных символов. Особенностью кода Рида-Соломона является, то, что к коду длины n можно добавить два информационных символа, не уменьшая при этом минимального расстояния. Такой расширенный код имеет длину п + 2 и то же количество символов контроля четности, что и исходный код. Из уравнения (6.46) вероятность появления ошибки в декодированном символе, РЕ, можно записать через вероятность появления ошибки в канальном символе, ![]() .
.
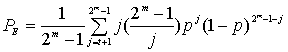 (8.7)
(8.7)
Здесь t — количество ошибочных битов в символе, которые может исправить код, а символы содержат т битов каждый.
Для некоторых типов модуляции вероятность битовой ошибки можно ограничить сверху вероятностью символьной ошибки. Для модуляции MFSK с М=![]() связь РВи РЕвыражается формулой (4.112).
связь РВи РЕвыражается формулой (4.112).
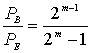 (8.8)
(8.8)
На рис. 8.1 показана зависимость ![]() от вероятности появления ошибки в канальном символе p, полученная из уравнений (8,7) и (8.8) для различных ортогональных 32-ричных кодов Рида-Соломона с возможностью коррекции t ошибочных бит в символе и n = 31 (тридцать один 5-битовый символ в кодовом блоке). На рис.8.2 показана зависимость
от вероятности появления ошибки в канальном символе p, полученная из уравнений (8,7) и (8.8) для различных ортогональных 32-ричных кодов Рида-Соломона с возможностью коррекции t ошибочных бит в символе и n = 31 (тридцать один 5-битовый символ в кодовом блоке). На рис.8.2 показана зависимость ![]() от
от ![]() /N0 для таких систем кодирования при использовании модуляции MFSK и некогерентной демодуляции в канале AWGN [2]. Для кодов Рида-Соломона вероятность появления ошибок является убывающей степенной функцией длины блока, n, а сложность декодирования пропорциональна небольшой степени длины блока [1]. Иногда коды Рида-Соломона применяются в каскадных схемах. В таких системах внутренний сверточный декодер сначала осуществляет некоторую защиту от ошибок за счет мягкой схемы решений на выходе демодулятора; затем сверточный декодер передает данные, оформленные согласно жесткой схеме, на внешний декодер Рида-Соломона, что снижает вероятность появления ошибок. В разделах 8.2.3 и 8.3 мы рассмотрим каскадное декодирование и декодирование Рида-Соломона на примере системы цифровой записи данных на аудиокомпакт-дисках (compact disc — CD).
/N0 для таких систем кодирования при использовании модуляции MFSK и некогерентной демодуляции в канале AWGN [2]. Для кодов Рида-Соломона вероятность появления ошибок является убывающей степенной функцией длины блока, n, а сложность декодирования пропорциональна небольшой степени длины блока [1]. Иногда коды Рида-Соломона применяются в каскадных схемах. В таких системах внутренний сверточный декодер сначала осуществляет некоторую защиту от ошибок за счет мягкой схемы решений на выходе демодулятора; затем сверточный декодер передает данные, оформленные согласно жесткой схеме, на внешний декодер Рида-Соломона, что снижает вероятность появления ошибок. В разделах 8.2.3 и 8.3 мы рассмотрим каскадное декодирование и декодирование Рида-Соломона на примере системы цифровой записи данных на аудиокомпакт-дисках (compact disc — CD).
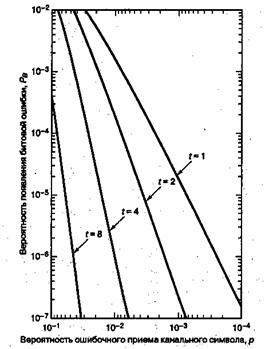
Рис. 8.1. Зависимость Рв от р для различных ортогональных 32-ринных кодов Рида-Соломона с возможностью коррекции t бит в символе и п = 31.(Перепечатано с разрешения автора из Data Communications, Network, and Systems, ed. Thomas C, Bartee, Howard W. Sams Company,Indianapolis,Ind., 1985, p. 311. Ранее публиковалось в J. P. Odenwalder, Error Control Coding Handbook, M/A-COM LINKABIT, Inc., San Diego, Calif., . ./ - . July,15, 1976,p.
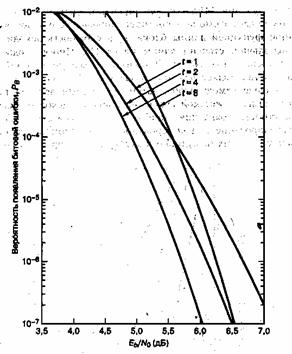
Рис. 8.2. Зависимость рв от Et/NQ для различных ортогональных кодов Рида-Соломона с возможностью коррекции t бит в символе и п = 31, при 32-ринной модуляции MFSK в канале AWGN. (Перепечатано с разрешения автора из Data Communications, Network, and Systems, ed. Thomas C. Bartee, Howard W. Sams Company, Indianapolis, Ind.f 1985, p. 312. Ранее публиковалось в J. P. Odenwalder, Error Control Coding Handbook, M/A-COM LINKABIT, Inc., San Diego, Calif., July, 15, 1976, p. 92.)
8.1.2. Почему коды Рида-Соломона эффективны при борьбе с импульсными помехами
Давайте рассмотрим код (n, k) = (255, 247), в котором каждый символ состоит из т = 8 бит (такие символы принято называть байтами). Поскольку п-k=8, из уравнения (8.4) можно видеть, что этот код может исправлять любые 4-символьные ошибки в блоке длиной до 255. Пусть блок длительностью 25 бит в ходе передачи поражается помехами, как показано на рис. 8.3. В этом примере пакет шума, который попадает на 25 последовательных битов, исказит точно 4 символа. Декодер для кода (255, 247) исправит любые 4-символьные ошибки без учета характера повреждений, причиненных символу. Другими словами, если декодер исправляет байт (заменяет неправильный правильным), то ошибка может быть вызвана искажением одного или всех восьми битов. Поэтому, если символ неправильный, он может быть искажен на всех двоичных позициях. Это дает коду Рида-Соломона огромное преимущество при наличии импульсных помех по сравнению с двоичными кодами (даже при использовании в двоичном коде чередования). В этом примере, если наблюдается 25-битовая случайная помеха, ясно, что искаженными могут оказаться более чем 4 символа (искаженными могут оказаться до 25 символов). Конечно, исправление такого числа ошибок окажется вне возможностей кода (255, 247).
8.1.3. Рабочие характеристики кода Рида-Соломона как функция размера, избыточности и степени кодирования
Для того чтобы код успешно противостоял шумовым эффектам, длительность помех должна составлять относительно небольшой процент от количества кодовых слов. Чтобы быть уверенным, что так будет большую часть времени, принятый шум необходимо усреднить за большой промежуток времени, что снизит эффект от неожиданной или необычной полосы плохого приема. Следовательно, можно предвидеть, что код с коррекцией ошибок будет более эффективен (повысится надежность передачи) при увеличении размера передаваемого блока, что делает код Рида-Соломона более привлекательным, если желательна большая длина блока [3]. Это можно оценить по семейству кривых, показанному на рис. 8.4, где степей кодирования взята равной 7/8, при этом длина блока возрастает с n = 32 символов (при w = 5 бит на символ) до n=256 символов (при n=8 бит на символ). Таким образом, размер блока возрастает с 160 бит до 2048 бит.
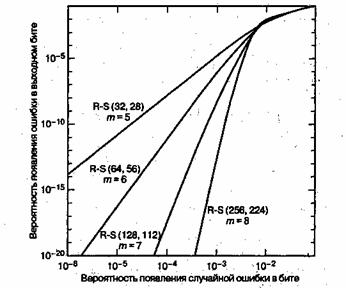
Рис. 8.4. Характеристики декодера Рида-Соломона как функция размера символов (степень кодирования = 7/8)
По мере увеличения избыточности кода (и снижения его степени кодирования), сложность реализации этого кода повышается (особенно для высокоскоростных устройств). При этом для систем связи реального времени должна увеличиться ширина полосы пропускания. Увеличение избыточности, например увеличение размера символа, приводит к уменьшению вероятности появления битовых ошибок, как можно видеть на рис. 8.5, еще кодовая длина п равна постоянному значению 64 при снижении числа символов данных с k = 60 до k = 4 (избыточность возрастает с 4 до 60символов).
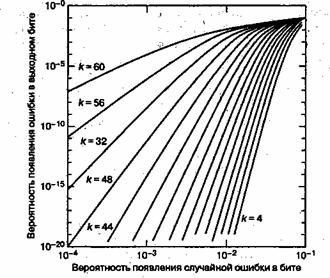
Рис. 8.5. Характеристики декодера Рида-Соломона (64, k) как функция избыточности
На рис. 8.5 показана передаточная функция (выходная вероятность появлений битовой ошибки, зависящая от входной вероятности появления символьной ошибки) гипотетических декодеров. Поскольку здесь не имеется в виду определенная система или канал (лишь вход-выход декодера), можно заключить, что надежность передачи является монотонной функцией избыточности и будет неуклонно возрастать с приближением степени кодирования к нулю. Однако это не так для кодов, используемых в системах связи реального времени. По мере изменения степени кодирования кода от максимального значения до минимального (от 0 до 1), интересно было бы понаблюдать за эффектами, показанными на рис. 8.6. Здесь кривые рабочих характеристик показаны при модуляции BPSK и кодах (31, к) для разных типов каналов. На рис. 8.6 показаны системы связи реального времени, в которых за кодирование с коррекцией ошибок приходится платить расширением полосы пропускания, пропорциональным величине, равной обратной степени кодирования. Приведенные кривые показывают четкий оптимум степени кодирования, минимизирующий требуемое значение ![]() [4]. Для гауссова канала оптимальное значение степени кодирования находится где-то между 0,6 и 0,7, для канала с райсовским замиранием - около 0,5 (с отношением мощности прямого сигнала к мощности отраженного К = 7 дБ) и 0,3 — для канала с релеевским замиранием. (Каналы с замиранием будут рассматриваться в главе 15.) Почему здесь как при очень высоких степенях кодирования (малой избыточности), так и при очень низких (значительной избыточности) наблюдается ухудшение
[4]. Для гауссова канала оптимальное значение степени кодирования находится где-то между 0,6 и 0,7, для канала с райсовским замиранием - около 0,5 (с отношением мощности прямого сигнала к мощности отраженного К = 7 дБ) и 0,3 — для канала с релеевским замиранием. (Каналы с замиранием будут рассматриваться в главе 15.) Почему здесь как при очень высоких степенях кодирования (малой избыточности), так и при очень низких (значительной избыточности) наблюдается ухудшение ![]() ? Для высоких степеней кодирования это легко объяснить, сравнивая высокие степени кодирования с оптимальной степенью кодирования. Любой код в целом обеспечивает все преимущества кодирования; следовательно, как только степень кодирования приближается к единице (нет кодирования), система проигрывает в надежности передачи. Ухудшение характеристик при низких степенях кодирования является более тонким вопросом, поскольку в системах связи реального времени используется и модуляция, и кодирование, т.е. работает два механизма. Один механизм направлен на снижение вероятности появления ошибок, другой повышает ее. Механизм, снижающий вероятность появления ошибки, — это кодирование; чем больше избыточность, тем больше возможности кода в коррекции ошибок. Механизм, повышающий эту вероятность, — это снижение энергии, приходящейся на канальный символ (по сравнению с информационным символом), что следует из увеличения избыточности (и более быстрой передачи сигналов в системах связи реального времени). Уменьшенная энергия символа вынуждает демодулятор совершать больше ошибок. В конечном счете второй механизм подавляет первый, поэтому очень низкие степени кодирования вызывают ухудшение характеристик кода.
? Для высоких степеней кодирования это легко объяснить, сравнивая высокие степени кодирования с оптимальной степенью кодирования. Любой код в целом обеспечивает все преимущества кодирования; следовательно, как только степень кодирования приближается к единице (нет кодирования), система проигрывает в надежности передачи. Ухудшение характеристик при низких степенях кодирования является более тонким вопросом, поскольку в системах связи реального времени используется и модуляция, и кодирование, т.е. работает два механизма. Один механизм направлен на снижение вероятности появления ошибок, другой повышает ее. Механизм, снижающий вероятность появления ошибки, — это кодирование; чем больше избыточность, тем больше возможности кода в коррекции ошибок. Механизм, повышающий эту вероятность, — это снижение энергии, приходящейся на канальный символ (по сравнению с информационным символом), что следует из увеличения избыточности (и более быстрой передачи сигналов в системах связи реального времени). Уменьшенная энергия символа вынуждает демодулятор совершать больше ошибок. В конечном счете второй механизм подавляет первый, поэтому очень низкие степени кодирования вызывают ухудшение характеристик кода.
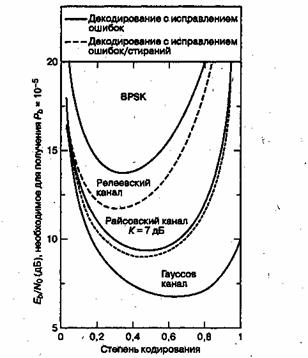
Рис. 8.6. Характеристики декодера Рида-Соломона (31, k) как функция степени кодирования (модуляция BPSK)
Давайте попробуем подтвердить зависимость вероятности появления ошибок от степени кодирования, показанную на рис. 8.6, с помощью кривых, изображенных на рис. 8.2. Непосредственно сравнить рисунки не удастся, поскольку на рис. 8.6 применяется модуляция BPSK, а на рис. 8.2 — 32-ричная модуляция MFSK. Однако, пожалуй, нам удастся показать, что зависимость характеристик кода Рида-Соломона от его степени кодирования выглядит одинаково как при BPSK, так и при MFSK. На рис. 8.2 вероятность появления ошибки в канале AWGN снижается при увеличении способности кода t к коррекции символьных ошибок с t = 1 до t = 4; случаи t = 1 и t = 4 относятся к кодам (31, 29) и (31,23) со степенями кодирования 0,94 и 0,74. Хотя при t = 8, что отвечает коду (31,15) со степенью кодирования 0,48, достоверность передачи ![]() достигается при примерно на 0,5 дБ большем отношении
достигается при примерно на 0,5 дБ большем отношении ![]() , по сравнению со случаем t = 4. Из рис. 8.2 можно сделать вывод, что если нарисовать график зависимости достоверности передачи от степени кодирования кода, то кривая будет иметь вид, подобный приведенному на рис. 8.6. Заметим, что это утверждение нельзя получить из рис. 8.1, поскольку там представлена передаточная функция декодера, которая несет в себе сведения о канале и демодуляции. Поэтому из двух механизмов, работающих в канале, передаточная функция (рис. 8.1) представляет только выгоды, которые проявляются на входе/выходе декодера, и ничего не говорит о потерях энергии как функции низкой степени кодирования.
, по сравнению со случаем t = 4. Из рис. 8.2 можно сделать вывод, что если нарисовать график зависимости достоверности передачи от степени кодирования кода, то кривая будет иметь вид, подобный приведенному на рис. 8.6. Заметим, что это утверждение нельзя получить из рис. 8.1, поскольку там представлена передаточная функция декодера, которая несет в себе сведения о канале и демодуляции. Поэтому из двух механизмов, работающих в канале, передаточная функция (рис. 8.1) представляет только выгоды, которые проявляются на входе/выходе декодера, и ничего не говорит о потерях энергии как функции низкой степени кодирования.
8.1.4. Конечные поля
Для понимания принципов кодирования и декодирования недвоичных кодов, таких как коды Рида-Соломона, нужно сделать экскурс в понятие конечных полей, известных как поля Галуа (Galois fields — GF). Для любого простого числа p существует конечное поле, которое обозначается GF(p) и содержит p элементов. Понятие GF(p) можно обобщить на поле из ![]() элементов, именуемое полем расширения GF(p); это поле обозначается GF(
элементов, именуемое полем расширения GF(p); это поле обозначается GF(![]() ), где т — положительное целое число. Заметим, что GF(
), где т — положительное целое число. Заметим, что GF(![]() ) содержит в качестве подмножества все элементы GF(p). Символы из поля расширения GF(
) содержит в качестве подмножества все элементы GF(p). Символы из поля расширения GF(
) используются при построении кодов Рида-Соломона.
Двоичное поле GF(2) является подполем поля расширения GF(![]() ), точно так же как поле вещественных чисел является подполем поля комплексных чисел. Кроме чисел 0 и 1, в поле расширения существуют дополнительные однозначные элементы, которые будут представлены новым символом а. Каждый ненулевой элемент в GF(
), точно так же как поле вещественных чисел является подполем поля комплексных чисел. Кроме чисел 0 и 1, в поле расширения существуют дополнительные однозначные элементы, которые будут представлены новым символом а. Каждый ненулевой элемент в GF(![]() ) можно представить как степень
) можно представить как степень ![]() . Бесконечное множество элементов, F, образуется из стартового множества
. Бесконечное множество элементов, F, образуется из стартового множества ![]() и генерируется дополнительными элементами путем последовательного умножения последней записи на
и генерируется дополнительными элементами путем последовательного умножения последней записи на ![]() .
.
![]() (8.9)
(8.9)
Для вычисления из F конечного множества элементов GF(![]() ) на F нужно наложить условия: оно может содержать только
) на F нужно наложить условия: оно может содержать только ![]() элемента и быть замкнутым относительно операции умножения. Условие замыкания множества элементов поля по отношению к операции умножения имеет вид неприводимого полинома.
элемента и быть замкнутым относительно операции умножения. Условие замыкания множества элементов поля по отношению к операции умножения имеет вид неприводимого полинома.
![]() (8.9)
(8.9)
или, что тоже самое,
![]() (8.10)
(8.10)
С помощью полиномиального ограничения любой элемент со степенью, большей или равной ![]() , можно следующим образом понизить до элемента со степенью, меньшей
, можно следующим образом понизить до элемента со степенью, меньшей ![]() .
.
![]() (8.11)
(8.11)
Таким образом, как показано ниже, уравнение (8.10) можно использовать для формирования конечной последовательности F* из бесконечной последовательности F.
![]() (8.12)
(8.12)
Следовательно, из уравнения (8.12) можно видеть, что элементы конечного поля GF(![]() ) даются следующим выражением.
) даются следующим выражением.
![]() (8.13)
(8.13)
8.1.4.1. Операция сложения в поле расширения GF(2m)
Каждый из ![]() элементов конечного поля GF(
элементов конечного поля GF(![]() ) можно представить как отдельный полином степени от m-1 или меньше. Степенью полинома называется степень члена максимального порядка. Обозначим каждый ненулевой элемент GF(
) можно представить как отдельный полином степени от m-1 или меньше. Степенью полинома называется степень члена максимального порядка. Обозначим каждый ненулевой элемент GF(![]() ) полиномом
) полиномом ![]() , в котором последние т коэффициентов
, в котором последние т коэффициентов ![]() нулевые. Для
нулевые. Для ![]() ,
,
![]() (8.14)
(8.14)
Рассмотрим случай m = 3, в котором конечное поле обозначается GF(23). На рис. 8.7 показано отображение семи элементов {![]() } и нулевого элемента в слагаемые базисных элементов
} и нулевого элемента в слагаемые базисных элементов ![]() , описываемых уравнением (8.14). Поскольку из уравнения (8.10)
, описываемых уравнением (8.14). Поскольку из уравнения (8.10) ![]() , в этом поле имеется семь ненулевых элементов или всего восемь элементов. Каждая строка на рис. 8.7 содержит последовательность двоичных величин, представляющих коэффициенты
, в этом поле имеется семь ненулевых элементов или всего восемь элементов. Каждая строка на рис. 8.7 содержит последовательность двоичных величин, представляющих коэффициенты ![]() ,
, ![]() и
и ![]() из уравнения (8.14). Одним из преимуществ использования элементов
из уравнения (8.14). Одним из преимуществ использования элементов ![]() поля расширения, вместо двоичных элементов, является компактность записи, что оказывается удобным при математическом описании процессов недвоичного кодирования и декодирования. Сложение двух элементов конечного поля, следовательно, определяется как суммирование по модулю 2 всех коэффициентов при элементах одинаковых степеней.
поля расширения, вместо двоичных элементов, является компактность записи, что оказывается удобным при математическом описании процессов недвоичного кодирования и декодирования. Сложение двух элементов конечного поля, следовательно, определяется как суммирование по модулю 2 всех коэффициентов при элементах одинаковых степеней.
![]() (8.15)
(8.15)
8.1.4.2. Описание конечного поля с помощью примитивного полинома
Класс полиномов, называемых примитивными полиномами, интересует нас, поскольку такие объекты определяют конечные поля GF(![]() ), которые, в свою очередь, нужны для описания кодов Рида-Соломона. Следующее утверждение является необходимым и достаточным условием примитивности полинома. Неприводимый полином f(X) порядка т будет примитивным, если наименьшим положительным целым числом п, для которого
), которые, в свою очередь, нужны для описания кодов Рида-Соломона. Следующее утверждение является необходимым и достаточным условием примитивности полинома. Неприводимый полином f(X) порядка т будет примитивным, если наименьшим положительным целым числом п, для которого ![]() делится на f(X), будет
делится на f(X), будет ![]() . Заметим, что неприводимый полином — это такой полином, который нельзя представить в виде произведения полиномов меньшего порядка; делимость А на В означает, что А делится на В с нулевым остатком и ненулевым частным. Обычно полином записывают в порядке возрастания степеней. Иногда более удобным является обратный формат записи (например, при выполнении полиномиального деления).
. Заметим, что неприводимый полином — это такой полином, который нельзя представить в виде произведения полиномов меньшего порядка; делимость А на В означает, что А делится на В с нулевым остатком и ненулевым частным. Обычно полином записывают в порядке возрастания степеней. Иногда более удобным является обратный формат записи (например, при выполнении полиномиального деления).
|
Образующие элементы |
||||
|
Элементы поля |
|
|
|
|
|
0 |
0 |
0 |
0 |
|
|
|
1 |
0 |
0 |
|
|
|
0 |
1 |
0 |
|
|
|
0 |
0 |
1 |
|
|
|
1 |
1 |
0 |
|
|
|
0 |
1 |
1 |
|
|
|
1 |
1 |
1 |
|
|
|
1 |
0 |
1 |
|
|
|
1 |
0 |
0 |
|
Рис. 8.7. Отображение элементов поля в базисные элементы GF(8) с помощью ![]()
Пример 8.1. Проверка полинома на примитивность
Основываясь на предыдущем определении примитивного полинома, укажите, какие из следующих неприводимых полиномов будут примитивными.
а) ![]()
б) ![]()
Решение
а) Мы можем проверить этот полином порядка т = 4, определив, будет ли он делителем ![]() для значений п из диапазона 1 < n < 15. Нетрудно убедиться, что
для значений п из диапазона 1 < n < 15. Нетрудно убедиться, что ![]() + 1 делится на
+ 1 делится на ![]() (см. раздел 6.8.1), и после повторения вычислений можно проверить, что при любых значениях п из диапазона 1<n<15 полином
(см. раздел 6.8.1), и после повторения вычислений можно проверить, что при любых значениях п из диапазона 1<n<15 полином ![]() +1 не делится на
+1 не делится на ![]() . Следовательно,
. Следовательно, ![]() является примитивным полиномом.
является примитивным полиномом.
б) Легко проверить, что полином является делителем ![]() . Проверив, делится ли
. Проверив, делится ли ![]() на
на ![]() , для значений n, меньших 15, можно также видеть, что указанный полином является делителем Xs+1. Следовательно, несмотря на то что полином
, для значений n, меньших 15, можно также видеть, что указанный полином является делителем Xs+1. Следовательно, несмотря на то что полином ![]() является неприводимым, он не будет примитивным.
является неприводимым, он не будет примитивным.
8.1.4.3. Поле расширения GF(23)
Рассмотрим пример, в котором будут задействованы примитивный полином и конечное поле, которое он определяет. В табл. 8.1 содержатся примеры некоторых примитивных полиномов. Мы выберем первый из указанных там полиномов, ![]() , который определяет конечное поле GF(
, который определяет конечное поле GF(![]() ), где степень полинома т=3. Таким образом, в поле, определяемом полиномом f(Х), имеется 2m = 23 = 8 элементов. Поиск корней полинома f(Х) — это поиск таких значений X, при которых
), где степень полинома т=3. Таким образом, в поле, определяемом полиномом f(Х), имеется 2m = 23 = 8 элементов. Поиск корней полинома f(Х) — это поиск таких значений X, при которых ![]() . Привычные нам двоичные элементы 0 и 1 не подходят полиному
. Привычные нам двоичные элементы 0 и 1 не подходят полиному ![]() (они не являются корнями), поскольку
(они не являются корнями), поскольку ![]() (в рамках операции по модулю 2). Кроме того, основная теорема алгебры утверждает, что полином порядка m должен иметь в точности m корней. Следовательно, в этом примере выражение
(в рамках операции по модулю 2). Кроме того, основная теорема алгебры утверждает, что полином порядка m должен иметь в точности m корней. Следовательно, в этом примере выражение ![]() должно иметь 3 корня. Возникает определенная проблема, поскольку 3 корня не лежат в одном конечном поле, что и коэффициенты f(X). А если они находятся где-то еще, то, наверняка, в поле расширения
должно иметь 3 корня. Возникает определенная проблема, поскольку 3 корня не лежат в одном конечном поле, что и коэффициенты f(X). А если они находятся где-то еще, то, наверняка, в поле расширения ![]() . Пусть,
. Пусть, ![]() , элемент поля расширения, определяется как корень полинома f(X). Следовательно, можно записать следующее.
, элемент поля расширения, определяется как корень полинома f(X). Следовательно, можно записать следующее.
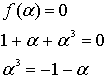 (8.16)
(8.16)
Поскольку при операциях над двоичным полем +1=-1, то ![]() можно представить следующим образом.
можно представить следующим образом.
![]() (8.17)
(8.17)
Таблица 8.1. Некоторые примитивные полиномы
|
m |
m |
||
|
3 |
|
14 |
|
|
4 |
|
15 |
|
|
5 |
|
16 |
|
|
6 |
|
17 |
|
|
7 |
|
18 |
|
|
8 |
|
19 |
|
|
9 |
|
20 |
|
|
10 |
|
21 |
|
|
11 |
|
22 |
|
|
12 |
|
23 |
|
|
13 |
|
24 |
|
Таким образом, ![]() представляется в виде взвешенной суммы всех
представляется в виде взвешенной суммы всех ![]() - членов более низкого порядка. Фактически так можно представить все степени
- членов более низкого порядка. Фактически так можно представить все степени ![]() . Например, рассмотрим следующее.
. Например, рассмотрим следующее.
![]() (8.18,а)
(8.18,а)
А теперь взглянем на следующий случай.
![]() (8.18,б)
(8.18,б)
Из уравнений (8.17) и (8.18), получаем следующее.
Из уравнений (8.17) и (8.18), получаем следующее.
![]() (8.18,в)
(8.18,в)
Из уравнений (8.17) и (8.18), получаем следующее.
![]() (8.18,г)
(8.18,г)
А теперь из уравнения (8.18,г) вычисляем
![]() (8.18,д)
(8.18,д)
Заметим, что ![]() и, следовательно, восьмью элементами конечного поля GF(
и, следовательно, восьмью элементами конечного поля GF(![]() ) ,будут
) ,будут
![]() (8.19)
(8.19)
Отображение элементов поля в базисные элементы, короче описывается уравнением (8.14), можно проиллюстрировать с помощью схемы линейного регистра сдвига с обратной связью (linear feedback shift register – LFSR) (рис 8.8). Схема генерирует (при m = 3) ![]() ненулевых элементов поля и, таким образом, обобщает процедуры, описанные в уравнениях (8.17) – (8.19). Следует отметить, что показанная на рис. 8.8. обратная связь соответствует коэффициентам полинома
ненулевых элементов поля и, таким образом, обобщает процедуры, описанные в уравнениях (8.17) – (8.19). Следует отметить, что показанная на рис. 8.8. обратная связь соответствует коэффициентам полинома ![]() , как и в случае двоичных циклических кодов (см. раздел 6.7.5.). Пусть вначале схема находится в некотором состоянии, например 1 0 0; при выполнении правого сдвига на один такт можно убедиться, что каждый из элементов поля (за исключением нулевого), показанных на рис.8.7, циклически будет появляться в разрядах регистра сдвига. На данном конечном поле GF(
, как и в случае двоичных циклических кодов (см. раздел 6.7.5.). Пусть вначале схема находится в некотором состоянии, например 1 0 0; при выполнении правого сдвига на один такт можно убедиться, что каждый из элементов поля (за исключением нулевого), показанных на рис.8.7, циклически будет появляться в разрядах регистра сдвига. На данном конечном поле GF(![]() ) можно определить две арифметические операции – сложение и умножение. В таб. 8.2. показана операция сложения, а в таб. 8.3. – операция умножения, но только для ненулевых элементов. Правила суммирования следуют из уравнений (8.17) и (8.18,д); и их можно рассчитать путем сложения (по модулю 2) соответствующих коэффициентов из базисных элементов. Правила умножения, указанные в табл. 8.3, следуют из обычной процедуры, в которой произведение элементов поля вычисляются путем сложения по модулю
) можно определить две арифметические операции – сложение и умножение. В таб. 8.2. показана операция сложения, а в таб. 8.3. – операция умножения, но только для ненулевых элементов. Правила суммирования следуют из уравнений (8.17) и (8.18,д); и их можно рассчитать путем сложения (по модулю 2) соответствующих коэффициентов из базисных элементов. Правила умножения, указанные в табл. 8.3, следуют из обычной процедуры, в которой произведение элементов поля вычисляются путем сложения по модулю ![]() их показателей степеней или, для данного случая, по модулю 7.
их показателей степеней или, для данного случая, по модулю 7.
Таблица 8.2. Таблица сложения для GF(8) при ![]()
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
Таблица 8.3. Таблица умножения для GF(8) при ![]()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8.1.4.4. Простой тест для проверки полинома на примитивность
Существует еще один, чрезвычайно простой способ проверки, является ли полином примитивным. У неприводимого полинома, который является примитивным, по крайней мере, хотя бы один из корней должен быть примитивным элементом. Примитивным элементом называется такой элемент поля, который, будучи возведенным в более высокие степени, даст ненулевые элементы поля. Поскольку данное поле является конечным, количество таких элементов также конечно.
Пример 8.2. Примитивный полином должен иметь, по крайней мере, хотя бы один примитивный элемент.
Найдите m = 3 корня полинома ![]() и определите, примитивен ли полином. Для этого проверьте, имеется ли среди корней полинома хотя бы один примитивный элемент. Каковы корни полинома? Какие из них примитивны?
и определите, примитивен ли полином. Для этого проверьте, имеется ли среди корней полинома хотя бы один примитивный элемент. Каковы корни полинома? Какие из них примитивны?
Решение
Корни будут найдены прямым перебором. Итак, ![]() не будет корнем, поскольку
не будет корнем, поскольку ![]() .Теперь, чтобы проверить, является ли корнем
.Теперь, чтобы проверить, является ли корнем ![]() , воспользуемся табл. 8.2. Поскольку
, воспользуемся табл. 8.2. Поскольку ![]() , значит,
, значит, ![]() будет корнем полинома. Далее проверим, будет ли корнем
будет корнем полинома. Далее проверим, будет ли корнем ![]() .
.![]() Значит, и
Значит, и ![]() также будет корнем полинома. Теперь проверим
также будет корнем полинома. Теперь проверим ![]() .
. ![]() Следовательно,
Следовательно, ![]() корнем полинома не является. Будет ли корнем
корнем полинома не является. Будет ли корнем ![]() ?
? ![]() Да,
Да, ![]() будет корнем полинома. Значит, корнями полинома
будет корнем полинома. Значит, корнями полинома ![]() будут
будут ![]() . Нетрудно убедиться, что, последовательно возводя в степень любой из этих корней, можно получить все 7 ненулевых элементов поля. Таким образом, все корни будут примитивными элементами. Поскольку в определении требуется, чтобы по крайней мере один из корней был примитивным, полином является примитивным.
. Нетрудно убедиться, что, последовательно возводя в степень любой из этих корней, можно получить все 7 ненулевых элементов поля. Таким образом, все корни будут примитивными элементами. Поскольку в определении требуется, чтобы по крайней мере один из корней был примитивным, полином является примитивным.
В этом примере описан относительно простой метод проверки полинома на примитивность. Для проверяемого полинома нужно составить регистр LFSR с контуром обратной связи, соответствующий коэффициентам полинома, как показана на рис. 8.8. Затем в схему регистра следует загрузить любое ненулевое состояние и выполнить за каждый такт правый сдвиг. Если за один период схема сгенерирует все ненулевые элементы поля, то данный полином с полем GF(![]() ) будет примитивным.
) будет примитивным.
8.1.5. Кодирование Рида-Соломона
В уравнении (8.2) представлена наиболее распространенная форма кодов Рида-Соломона через параметры n, k, t и некоторое положительное число m > 2. Приведем это уравнение повторно.
![]() (8.20)
(8.20)
Здесь ![]() - число контрольных символов, а t – количество ошибочных битов в символе, которые может исправить код. Генерирующий полином для кода Рида-Соломона имеет следующий вид.
- число контрольных символов, а t – количество ошибочных битов в символе, которые может исправить код. Генерирующий полином для кода Рида-Соломона имеет следующий вид.
![]() (8.21)
(8.21)
Степень полиномиального генератора равна числу контролируемых символов. Коды Рида-Соломона являются подмножеством кодов БЧХ, которые обсуждались в разделе 6.8.3. и показаны в табл. 6.4. Поэтому связь между степенью полиномиального генератора и числом контрольных символов, как и в кодах БЧХ, не должна оказаться неожиданностью. В этом можно убедиться, подвергнув проверке любой генератор из табл. 6.4. Поскольку полиномиальный генератор имеет порядок 2t, мы должны иметь в точности 2t последовательные степени ![]() , которые являются корнями полинома. Обозначим корни
, которые являются корнями полинома. Обозначим корни ![]() как:
как: ![]() . Нет необходимости начинать именно с корня
. Нет необходимости начинать именно с корня ![]() , это можно сделать с помощью любой степени
, это можно сделать с помощью любой степени ![]() . Возьмем, к примеру, код (7,3) с возможностью коррекции двухсимвольных ошибок. Мы выразим полиномиальный генератор через
. Возьмем, к примеру, код (7,3) с возможностью коррекции двухсимвольных ошибок. Мы выразим полиномиальный генератор через ![]() корня следующим образом.
корня следующим образом.
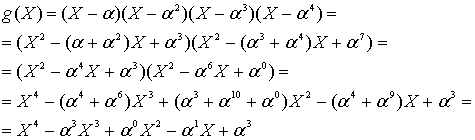
8.1.5.1. Кодирование в систематической форме
Так как код Рида-Соломона является циклическим, кодирование в систематической форме аналогично процедуре двоичного кодирования, разработанной в разделе 6.7.3. Мы можем осуществить сдвиг полинома сообщения m(X) в крайние правые k разряды регистра кодового слова и провести последующее прибавление полинома четности p(X) в крайние левые n – k разряды. Поэтому мы умножаем m(X) на ![]() , проделав алгебраическую операцию таким образом, что m(X) оказывается сдвинутым вправо на n – k позиций. В главе 6 это показано в уравнении (6.61) на примере двоичного кодирования. Далее мы делим
, проделав алгебраическую операцию таким образом, что m(X) оказывается сдвинутым вправо на n – k позиций. В главе 6 это показано в уравнении (6.61) на примере двоичного кодирования. Далее мы делим ![]() на полиномиальный генератор g(X), что можно записать следующим образом.
на полиномиальный генератор g(X), что можно записать следующим образом.
![]()
![]()
Здесь q(X) и p(X) – это частное и остаток от полиномиального деления. Как и в случае двоичного кодирования, остаток будет четным. Уравнение (8.23) можно представить следующим образом.
![]() (8.24)
(8.24)
Результирующий полином кодового слова U(X), показанный в уравнении (6.64), можно переписать следующим образом.
![]() (8.25)
(8.25)
Продемонстрируем шаги, подразумеваемые уравнениями (8.24) и (8.25), закодировав сообщение из трех символов
![]()
с помощью кода (7,3), генератор которого определяется уравнением (8.22). Сначала мы умножаем (сдвиг вверх) полином сообщения ![]() , что дает
, что дает ![]() Далее мы делим такой сдвинутый вверх полином сообщения на полиномиальный генератор из уравнения (8.22),
Далее мы делим такой сдвинутый вверх полином сообщения на полиномиальный генератор из уравнения (8.22), ![]() Полиномиальное деление недвоичных коэффициентов – это еще более утомительная процедура, чем ее двоичный аналог (см. пример 6.9), поскольку операции сложения (вычитания) и умножения (деления) выполняются согласно табл. 8.2 и 8.3. Мы оставим числителю в качестве вспомогательного упражнения проверку того, что полиномиальное деление даст в результате следующей полиномиальный остаток (полином четности).
Полиномиальное деление недвоичных коэффициентов – это еще более утомительная процедура, чем ее двоичный аналог (см. пример 6.9), поскольку операции сложения (вычитания) и умножения (деления) выполняются согласно табл. 8.2 и 8.3. Мы оставим числителю в качестве вспомогательного упражнения проверку того, что полиномиальное деление даст в результате следующей полиномиальный остаток (полином четности).
![]()
Заметим, из уравнения (8.25), полином кодового слова можно записать следующим образом.
![]()
8.1.5.2. Систематическое кодирование с помощью (n-k)-разрядного регистра сдвига
Как показано на рис. 8.9, кодирование последовательности из 3 символов в систематической форме на основе кода (7,3), определяемого генератором g(X) из уравнения (8.22), требует реализации регистра LFSR. Нетрудно убедиться, что элементы умножителя на рис. 8.9, взятые справа налево, соответствуют коэффициентам полинома в уравнении (8.22). Этот процесс кодирования является недвоичным аналогом циклического кодирования, которое описывалась в разделе 6.7.5. Здесь, в соответствии с уравнением (8.20), ненулевые кодовые слова образованы ![]() символами, и каждый символ состоит из m = 3 бит.
символами, и каждый символ состоит из m = 3 бит.
Следует отметить сходство между рис. 8.9, 6.18 и 6.19. Во всех трех случаях количество разрядов в регистре равно n – k. Рисунки в главе 6 отображают пример двоичного кодирования, где каждый разряд содержит 1 бит. В данной главе приведен пример двоичного кодирования, так что каждый разряд регистра сдвига, изображенного на рис. 8.9, содержит 3-битовый символ. На рис. 6.18 коэффициенты, обозначенные ![]() являются двоичными. Поэтому они принимают одно из значений 0 или 1, просто указывая на наличие или отсутствие связи в LFSR. На рис. 8.9 каждый коэффициент является 3-битовым, так что они могут принимать одно из 8 значений.
являются двоичными. Поэтому они принимают одно из значений 0 или 1, просто указывая на наличие или отсутствие связи в LFSR. На рис. 8.9 каждый коэффициент является 3-битовым, так что они могут принимать одно из 8 значений.
Недвоичные операции, осуществляемые кодером, показанным на рис. 8.9, создают кодовые слова в систематической форме, так же как и в двоичном случае. Эти операции определяются следующими шагами.
1. Переключатель 1 в течение первых k тактовых импульсов закрыт, для того чтобы подавать символы сообщения в (n - k)-разрядный регистр сдвига.
2. В течение первых k тактовых импульсов переключатель 2 находится в нижнем положении, что обеспечивает одновременную процедуру всех символов сообщения непосредственно на регистр выхода (на рис. 8.9 не показан).
3. После передачи k-го символа на регистр выхода, переключатель 1 открывается, а переключатель 2 переходит в верхнее положение.
4. Остальные (n-k) тактовых импульсов очищают контрольные символы, содержащиеся в регистре, подавая из на регистр выхода.
5. Общее число тактовых импульсов равно n, и содержимое регистра выхода является полиномом кодового слова ![]() , где p(X) представляет собой кодовые символы, а m(X) – символы сообщения в полиномиальной форме.
, где p(X) представляет собой кодовые символы, а m(X) – символы сообщения в полиномиальной форме.
Для проверки возьмем те же последовательность символов, что и в разделе 8.1.5.1.
![]()
Здесь крайний правый символ является самым первым и крайний правый бит также является самым первым. Последовательность действий в течение первых k = 3 сдвигов в цепи кодирования на рис. 8.9 будет иметь следующий вид.
Очередь ввода Такт Содержимое регистра обратная связь
|
|
|
|
0 |
0 |
0 |
0 |
0 |
|
|
|
|
1 |
|
|
|
|
|
|
|
|
2 |
|
0 |
|
|
|
||
|
- |
3 |
|
|
|
|
- |
Как можно видеть, после третьего такта регистр содержит 4 контрольных символа, ![]() . Затем переключатель 1 переходит в верхнее положение, и контрольные символы, содержащиеся в регистре, подаются на выход. Поэтому выходное слово, записанное в полиномиальной форме, можно представить в следующим виде.
. Затем переключатель 1 переходит в верхнее положение, и контрольные символы, содержащиеся в регистре, подаются на выход. Поэтому выходное слово, записанное в полиномиальной форме, можно представить в следующим виде.
![]()
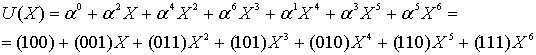 (8.26)
(8.26)
Процесс проверки содержимого регистра во время разных тактов несколько сложнее, чем в случае бинарного кодирования. Здесь сложение и умножение элементов поля должны выполняться согласно табл. 8.2 и 8.3.
Корни полиномиального генератора g(X) должны быть и корнями кодового слова, генерируемого g(X), поскольку правильное кодовое слово имеет следующий вид.
![]() (8.27)
(8.27)
Следовательно, произвольное кодовое слово, выражаемое через корень генератора g(X), должно давать нуль. Представляется интересным, действительно ли полином кодового слова в уравнении (8.26) дает нуль, когда он выражается через какой-либо из четырех корней g(X). Иными словами, это означает проверку следующего.
![]()
Независимо выполнив вычисления для разных корней, получим следующее.
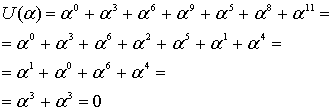
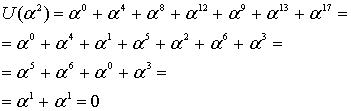
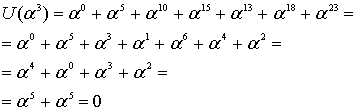
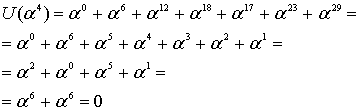
Эти вычисления показывают, что, как и ожидалось, кодовое слово, выражаемое через любой корень генератора g(X), должно давать нуль.
8.1.6. Декодирование Рида-Соломона
В разделе 8.1.5 тестовое сообщение кодируется в систематической форме с помощью кода (7,3), что дает в результате полином кодового слова, описываемый уравнением (8.26). Допустим, что в ходе передачи это кодовое слово подверглось искажению: 2 символа были приняты с ошибкой. (Такое количество ошибок соответствует максимальной способности кода к коррекции ошибок.) При использовании 7-символьного кодового слова ошибочную комбинацию можно представить в полиномиальной форме следующим образом.
![]() (8.28)
(8.28)
Пусть двухсимвольная ошибка будет такой, что
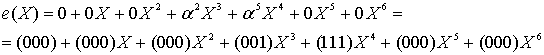 (8.29)
(8.29)
Другими словами, контрольный символ искажен 1-битовой ошибкой (представленной как ![]() ), а символ сообщения — 3-битовой ошибкой (представленной как
), а символ сообщения — 3-битовой ошибкой (представленной как ![]() ). В данном случае принятый полином поврежденного кодового слова r(Х) представляется в виде суммы полинома переданного кодового слова и полинома ошибочной комбинации, как показано ниже.
). В данном случае принятый полином поврежденного кодового слова r(Х) представляется в виде суммы полинома переданного кодового слова и полинома ошибочной комбинации, как показано ниже.
![]()
![]() (8.30)
(8.30)
Следуя уравнению (8.30), мы суммируем U(X) из уравнения (8.26) и e(Х) из уравнения (8.29) и имеем следующее.
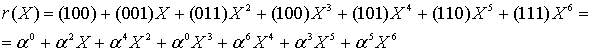 (8.31)
(8.31)
В данном примере исправления 2-символьной ошибки имеется четыре неизвестных — два относятся к расположению ошибки, а два касаются ошибочных значений. Отметим важное различие между недвоичным декодированием r(Х), которое мы показали в уравнении (8.31), и двоичным, которое описывалось в главе 6. При двоичном декодировании декодеру нужно знать лишь расположение ошибки. Если известно, где находится ошибка, бит нужно поменять с 1 на 0 или наоборот. Но здесь недвоичные символы требуют, чтобы мы не только узнали расположение ошибки, но и определили правильное значение символа, расположенного на этой позиции. Поскольку в данном примере у нас имеется четыре неизвестных, нам нужно четыре уравнения, чтобы найти их.
8.1.6.1. Вычисление синдрома
Вернемся к разделу 6.4.7 и напомним, что синдром — это результат проверки четности, выполняемой над r, чтобы определить, принадлежит ли r набору кодовых слов. Если r является членом набора, то синдром S имеет значение, равное 0. Любое ненулевое значение S означает наличие ошибок. Точно так же, как и в двоичном случае, синдром S состоит из n-k символов, ![]()
![]() . Таким образом, для нашего кода (7, 3) имеется по четыре символа в каждом векторе синдрома; их значения можно рассчитать из принятого полинома r(Х). Заметим, кдк облегчаются вычисления благодаря самой структуре кода, определяемой уравнением (8.27).
. Таким образом, для нашего кода (7, 3) имеется по четыре символа в каждом векторе синдрома; их значения можно рассчитать из принятого полинома r(Х). Заметим, кдк облегчаются вычисления благодаря самой структуре кода, определяемой уравнением (8.27).
![]()
Из этой структуры можно видеть, что каждый правильный полином кодового слова U(X) является кратным полиномиальному генератору g(X). Следовательно, корни g(X) также должны быть корнями U(X). Поскольку ![]() , то r(Х), вычисляемый с каждым корнем g(X), должен давать нуль, только если r(Х) будет правильным кодовым словом. Любые ошибки приведут в итоге к ненулевому результату в одном (или более) случае. Вычисления символов синдрома можно записать следующим образом.
, то r(Х), вычисляемый с каждым корнем g(X), должен давать нуль, только если r(Х) будет правильным кодовым словом. Любые ошибки приведут в итоге к ненулевому результату в одном (или более) случае. Вычисления символов синдрома можно записать следующим образом.
![]() (8.32)
(8.32)
Здесь, как было показано в уравнении (8.29), r(Х) содержит 2-символьные ошибки. Если r(Х) окажется правильным кодовым словом, то это приведет к тому, что все символы синдрома ![]() будут равны нулю. В данном примере четыре символа синдрома находятся следующим образом.
будут равны нулю. В данном примере четыре символа синдрома находятся следующим образом.
![]()
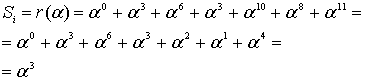 (8.33)
(8.33)
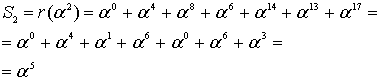 (8.34)
(8.34)
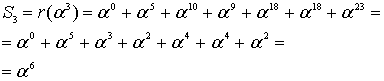 (8.35)
(8.35)
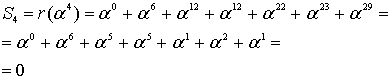 (8.36)
(8.36)
Результат подтверждает, что принятое кодовое слово содержит ошибку (введенную нами), поскольку ![]() .
.
Пример 8.3. Повторная проверка значений синдрома
Для рассматриваемого кода (7, 3) ошибочная комбинация известна, поскольку мы выбрали ее заранее. Вспомним свойство кодов, обсуждаемое в разделе 6.4.8.1, когда была введена нормальная матрица. Все элементы класса смежности (строка) нормальной матрицы имеют один и тот же синдром. Нужно показать, что это свойство справедливо и для кода Рида-Соломона, путем вычисления полинома ошибок e(Х) со значениями корней g(X). Это должно дать те же значения синдрома, что и вычисление r(Х) со значениями корней g(X). Другими словами, это должно дать те же значения, которые были получены в уравнениях (8.33)-(8.36).
Решение
![]()
![]()
![]()
Из уравнения (8.29) следует, что ![]() , поэтому
, поэтому
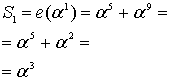
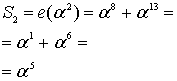
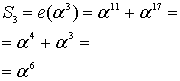
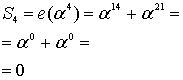
Из этих результатов можно заключить, что значения синдрома одинаковы — как полученные путем вычисления e(Х) со значениями корней g(X), так и полученные путем вычисления r(Х) с теми же значениями корней g(X).
8.1.6.2. Локализация ошибки
Допустим, в кодовом слове имеется ![]() ошибок, расположенных на позициях
ошибок, расположенных на позициях ![]() . Тогда полином ошибок, определяемый уравнениями (8.28) и (8.29), можно записать следующим образом.
. Тогда полином ошибок, определяемый уравнениями (8.28) и (8.29), можно записать следующим образом.
![]() (8.37)
(8.37)
Индексы 1, 2, ..., ![]() обозначают 1-ю, 2-ю, ...,
обозначают 1-ю, 2-ю, ..., ![]() -ю ошибки, а индекс
-ю ошибки, а индекс ![]() — расположение ошибки. Для коррекции искаженного кодового слова нужно определить каждое значение ошибки
— расположение ошибки. Для коррекции искаженного кодового слова нужно определить каждое значение ошибки ![]() и ее расположение
и ее расположение ![]() , где
, где ![]() . Обозначим номер локатора ошибки как
. Обозначим номер локатора ошибки как ![]() . Далее вычисляем
. Далее вычисляем ![]() символа синдрома, подставляя
символа синдрома, подставляя ![]() в принятый полином при
в принятый полином при ![]() .
.
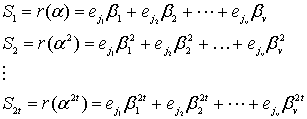 (8.38)
(8.38)
У нас имеется 2t неизвестных (t значений ошибок и t расположений) и система 2t уравнений. Впрочем, эту систему 2t уравнений нельзя решить обычным путем, поскольку уравнения в ней нелинейны (некоторые неизвестные входят в уравнение в степени). Методика, позволяющая решить эту систему уравнений, называется алгоритмом декодирования Рида-Соломона.
Если вычислен ненулевой вектор синдрома (один или более его символов не равны нулю), это означает, что была принята ошибка. Далее нужно узнать расположение ошибки (или ошибок). Полином локатора ошибок можно определить следующим образом.
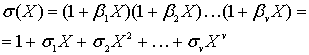 (8.39)
(8.39)
Корнями ![]() будут
будут ![]() . Величины, обратные корням
. Величины, обратные корням ![]() , будут представлять номера расположений ошибочной комбинации e(Х). Тогда, воспользовавшись авторегрессионной техникой моделирования [5], мы составим из синдромов матрицу, в которой первые t синдромов будут использоваться для предсказания следующего синдрома.
, будут представлять номера расположений ошибочной комбинации e(Х). Тогда, воспользовавшись авторегрессионной техникой моделирования [5], мы составим из синдромов матрицу, в которой первые t синдромов будут использоваться для предсказания следующего синдрома.
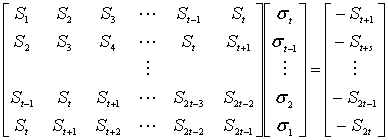 (8.40)
(8.40)
Мы воспользовались авторегрессионной моделью уравнения (8.40), взяв матрицу наибольшей размерности с ненулевым определителем. Для кода (7, 3) с коррекцией двухсимвольных ошибок матрица будет иметь размерность ![]() , и модель запишется следующим образом.
, и модель запишется следующим образом.
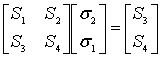 (8.41)
(8.41)
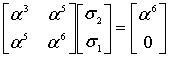 (8.42)
(8.42)
Чтобы найти коэффициенты ![]() и
и ![]() полинома локатора ошибок
полинома локатора ошибок ![]() ,. сначала необходимо вычислить обратную матрицу для уравнения (8.42). Обратная матрица для матрицы [А] определяется следующим образом.
,. сначала необходимо вычислить обратную матрицу для уравнения (8.42). Обратная матрица для матрицы [А] определяется следующим образом.
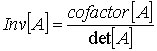
Следовательно,
det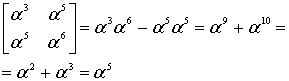 (8.43)
(8.43)
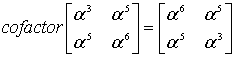 (8.44)
(8.44)
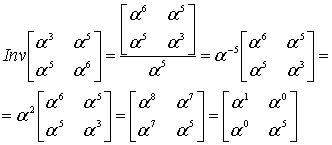 (8.45)
(8.45)
Проверка надежности
Если обратная матрица вычислена правильно, то произведение исходной и обратной матрицы должно дать единичную матрицу.
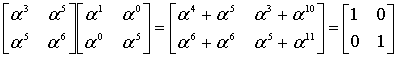 (8.46)
(8.46)
С помощью уравнения (8.42) начнем поиск положений ошибок с вычисления коэффициентов полинома локатора ошибок ![]() , как показано далее.
, как показано далее.
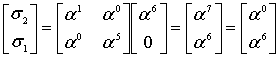 (8.47)
(8.47)
Из уравнений (8.39) и (8.47)
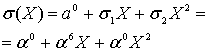 (8.48)
(8.48)
Корни ![]() являются обратными числами к положениям ошибок. После того как эти корни найдены, мы знаем расположение ошибок. Вообще, корни
являются обратными числами к положениям ошибок. После того как эти корни найдены, мы знаем расположение ошибок. Вообще, корни ![]() могут быть одним или несколькими элементами поля. Определим эти корни путем полной проверки полинома
могут быть одним или несколькими элементами поля. Определим эти корни путем полной проверки полинома ![]() со всеми элементами поля, как будет показано ниже. Любой элемент X, который дает
со всеми элементами поля, как будет показано ниже. Любой элемент X, который дает ![]() , является корнем, что позволяет нам определить расположение ошибки.
, является корнем, что позволяет нам определить расположение ошибки.
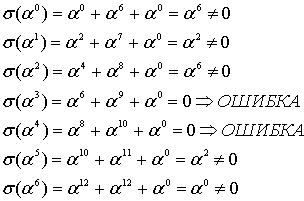
Как видно из уравнения (8.39), расположение ошибок является обратной величиной к корням полинома. А значит, ![]() означает, что один корень получается при
означает, что один корень получается при ![]() . Отсюда
. Отсюда ![]() . Аналогично
. Аналогично ![]() означает, что другой корень появляется при
означает, что другой корень появляется при ![]() , где (в данном примере)
, где (в данном примере) ![]() и
и ![]() обозначают 1-ю и 2-ю ошибки. Поскольку мы имеем дело с 2-символьными ошибками, полином ошибок можно записать следующим образом.
обозначают 1-ю и 2-ю ошибки. Поскольку мы имеем дело с 2-символьными ошибками, полином ошибок можно записать следующим образом.
![]() (8.49)
(8.49)
Здесь были найдены две ошибки на позициях ![]() и
и ![]() . Заметим, что индексация номеров расположения ошибок является сугубо произвольной. Итак, в этом примере мы обозначили величины
. Заметим, что индексация номеров расположения ошибок является сугубо произвольной. Итак, в этом примере мы обозначили величины ![]() как
как ![]()
![]() и
и ![]() .
.
8.1.6.3. Значения ошибок
Мы обозначили ошибки ![]() , где индекс j обозначает расположение ошибки, а индекс l — l-ю ошибку. Поскольку каждое значение ошибки связано с конкретным меcторасположением, систему обозначений можно упростить, обозначив
, где индекс j обозначает расположение ошибки, а индекс l — l-ю ошибку. Поскольку каждое значение ошибки связано с конкретным меcторасположением, систему обозначений можно упростить, обозначив ![]() просто как
просто как ![]() . Теперь, приготовившись к нахождению значений ошибок
. Теперь, приготовившись к нахождению значений ошибок ![]() и
и ![]() , связанных с позициями
, связанных с позициями ![]() и
и ![]() можно использовать любое из четырех синдромных уравнений. Выразим из уравнения (8.38)
можно использовать любое из четырех синдромных уравнений. Выразим из уравнения (8.38) ![]() , и
, и ![]() .
.
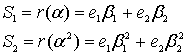 (8.50)
(8.50)
Эти уравнения можно переписать в матричной форме следующим образом.
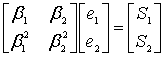 (8.51)
(8.51)
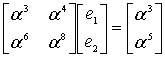 (8.52)
(8.52)
Чтобы найти значения ошибок ![]() и
и ![]() , нужно, как обычно, выполнить поиск обратной матрицы для уравнения (8.52).
, нужно, как обычно, выполнить поиск обратной матрицы для уравнения (8.52).
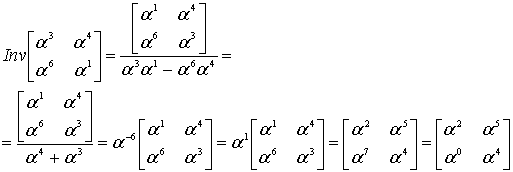 (853)
(853)
Теперь мы можем найти из уравнения (8.52) значения ошибок.
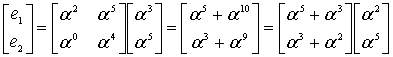 (8.54)
(8.54)
8.1.6.4. Исправление принятого полинома с помощью найденного полинома ошибок
Из уравнений (8.49) и (8.54) мы находим полином ошибок.
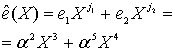 (8.55)
(8.55)
Показанный алгоритм восстанавливает принятый полином, выдавая в итоге предполагаемое переданное кодовое слово и, в конечном счете, декодированное сообщение.
![]() (8.56)
(8.56)
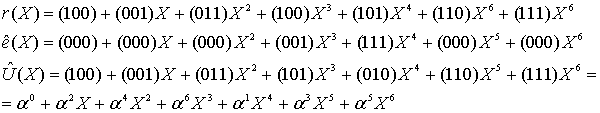 (8.57)
(8.57)
Поскольку символы сообщения содержатся в крайних правых k = 3 символах, декодированным будет следующее сообщение.
![]()
![]()
![]()
Это сообщение в точности соответствует тому, которое было выбрано для этого примера в разделе 8.1.5. (Для более детального знакомства с кодированием Рида-Соломона обратитесь к работе [6].)