4.6.1. Архитектура процессоров Intel Pentium (P5/P6)
4.6.1. Архитектура процессоров Intel Pentium (P5/P6)
Процессоры семейства Pentium имеют ряд архитектурных и структурных особенностей по сравнению с предыдущими моделями микропроцессоров фирмы Intel. Наиболее характерными из них являются:
- гарвардская архитектура с разделением потоков команд и данных при помощи введения отдельных внутренних блоков кэш-памяти для хранения команд и данных, а также шин для их передачи;
- суперскалярная архитектура, обеспечивающая одновременное выполнение нескольких команд в параллельно работающих исполнительных устройствах;
- динамическое исполнение команд, реализующее изменение последовательности команд, использование расширенного регистрового файла (переименование регистров) и эффективное предсказание ветвлений;
- двойная независимая шина, содержащая отдельную шину для обращения к кэш-памяти 2-го уровня (выполняется с тактовой частотой процессора) и системную шину для обращения к памяти и внешним устройствам (выполняется с тактовой частотой системной платы).
Основные характеристики процессоров семейства Pentium следующие:
- 32-разрядная внутренняя структура;
- использование системной шины с 36 разрядами адреса и 64 разрядами данных;
- раздельная внутренняя кэш-память первого уровня для команд и данных емкостью по 16 Кбайт;
- поддержка общей кэш-памяти команд и данных второго уровня емкостью до 2 Мбайт;
- конвейерное исполнение команд;
- предсказание направления программного ветвления с высокой точностью;
- ускоренное выполнение операций с плавающей точкой;
- приоритетный контроль при обращении к памяти;
- поддержка реализации мультипроцессорных систем;
- наличие внутренних средств, обеспечивающих самотестирование, отладку и мониторинг производительности.
Новая микроархитектура процессоров Pentium (рис. 4.6) и более поздних базируется на методе суперскалярной обработки.
Под суперскалярностью подразумевается наличие более одного конвейера для обработки команд (в отличие от скалярной – одноконвейерной архитектуры).
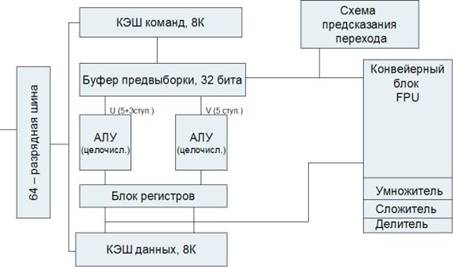 Рисунок 4.6 – Блок-схема архитектуры МП Pentium
Рисунок 4.6 – Блок-схема архитектуры МП Pentium
В МП Pentium команды распределяются по двум независимым исполнительным конвейерам (U и V). Конвейер U может выполнять любые команды семейства IA-32, включая целочисленные команды и команды с плавающей точкой. Конвейер V предназначен для выполнения простых целочисленных команд и некоторых команд с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, причем при выдаче устройством управления в одном такте пары команд более сложная команда поступает в конвейер U, а менее сложная – в конвейер V.
Однако, такая попарная обработка команд (спаривание) возможна только для ограниченного подмножества целочисленных команд. Команды вещественной арифметики не могут запускаться в паре с целочисленными командами. Одновременная выдача двух команд возможна только при отсутствии зависимостей по регистрам.
Одной из главных особенностей шестого поколения микропроцессоров архитектуры IA-32 является динамическое (спекулятивное) исполнение. Под этим термином подразумевается следующая совокупность возможностей:
- глубокое предсказание ветвлений (с вероятностью > 90% можно предсказать 10-15 ближайших переходов);
- анализ потока данных (на 20-30 шагов вперед просмотреть программу и определить зависимость команд по данным или ресурсам);
- опережающее исполнение команд (МП P6 может выполнять команды в порядке, отличном от их следования в программе).
Внутренняя организация МП P6 соответствует архитектуре RISC, поэтому блок выборки команд, считав поток инструкций IA-32 из L1 кэша инструкций, декодирует их в серию микроопераций. Поток микроопераций попадает в буфер переупорядочивания (пул инструкций). В нем содержатся как не выполненные пока микрооперации, так и уже выполненные, но еще не повлиявшие на состояние процессора.
Для декодирования инструкций предназначены три параллельных дешифратора: два для простых и один для сложных инструкций.
Каждая инструкция IA-32 декодируется в 1-4 микрооперации. Микрооперации выполняются пятью параллельными исполнительными устройствами: два для целочисленной арифметики, два для вещественной арифметики и блок интерфейса с памятью. Таким образом, возможно выполнение до пяти микроопераций за такт.
Блок исполнительных устройств способен выбирать инструкции из пула в любом порядке. При этом благодаря блоку предсказания ветвлений возможно выполнение инструкций, следующих за условными переходами. Блок резервирования постоянно отслеживает в пуле инструкций те микрооперации, которые готовы к исполнению (исходные данные не зависят от результата других невыполненных инструкций) и направляет их на свободное исполнительное устройство соответствующего типа. Одно из целочисленных исполнительных устройств дополнительно занимается проверкой правильности предсказания переходов. При обнаружении неправильно предсказанного перехода все микрооперации, следующие за переходом, удаляются из пула и производится заполнение конвейера команд инструкциями по новому адресу.
Взаимная зависимость команд от значения регистров архитектуры IA-32 может требовать ожидания освобождения регистров. Для решения этой проблемы предназначены 40 внутренних регистров общего назначения, используемых в реальных вычислениях.
Блок удаления отслеживает результат спекулятивно выполненных микроопераций. Если микрооперация более не зависит от других микроопераций, ее результат переносится на состояние процессора, и она удаляется из буфера переупорядочивания. Блок удаления подтверждает выполнение инструкций (до трех микроопераций за такт) в порядке их следования в программе, принимая во внимание прерывания, исключения, точки останова и промахи предсказания переходов.
Описанная схема отображена на рис. 4.7.
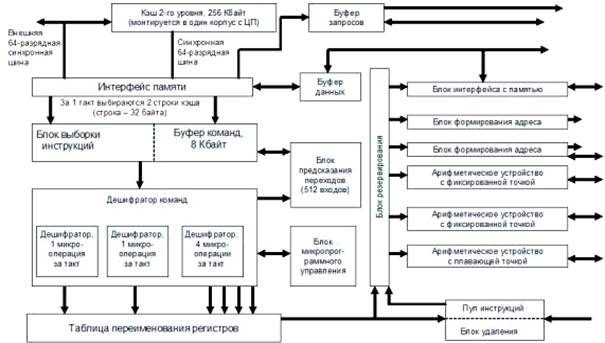
Рисунок 4.7 – Блок схема микропроцессора Pentium Pro
4.6.2. SIMD-расширения ММХ
Многие алгоритмы работы с мультимедийными данными допускают простейшие элементы распараллеливания, когда одна операция может выполняться параллельно над несколькими числами. Такой подход называется SIMD – single-instruction multiple-data (одна инструкция – множество данных). Впервые эта технология была реализована в поколении P55 (микропроцессор Pentium MMX).
MMX (Multi-Media eXtension) – это SIMD-расширение для потоковой обработки целочисленных данных, реализованное на основе блока FPU (с использованием регистров FPU).
Одна инструкция MMX может выполнить арифметическую или логическую операцию над "пакетами" целых чисел, упакованных в регистрах MMX. Например, инструкция PADDSB складывает 8 байт одного "пакета" с соответствующими восьмью байтами другого пакета, фактически выполняя сложение восьми пар чисел одной инструкцией.
4.6.3. Процессоры Pentium Pro, Pentium II, Pentium III
В процессоре Pentium II соединены лучшие свойства процессоров Intel: производительность процессора Pentium Pro и возможности технологии MMX. Это сочетание обеспечивает существенное увеличение производительности процессоров Pentium II по сравнению с предыдущими процессорами IA-32-архитектуры.
Процессор содержит раздельные внутренние блоки кэш-памяти команд и данных по 16 Кбайт и 512 Кбайт общей неблокирующей кэш-памяти второго уровня.
Повышение производительности IA-32 достигалось не только путем оптимизации конвейера команд и добавления исполнительных блоков, но и, например, внедрением кэш-памяти в ядро процессора. В семействе IA-32 встроенный кэш L1 размером 8 Кбайт впервые был реализован в процессорах Intel-486. В процессорах Pentium размер кэша был удвоен. Первые представители P6 (Pentium Pro) содержали также кэш L2 размером 256 или 512 Кбайт. Однако такое решение в то время оказалось слишком дорогим и невыгодным, поэтому в Pentium II была представлена технология Dual Independent Bus (DIB) – двойная независимая шина. Для доступа к кэшу и для доступа к внешней памяти использовались раздельные шины. Такое же архитектурное решение использовалось в первых моделях Pentium III. Начиная с 1999 года (Pentium III Coppermine), кэш L2 вновь был возвращен внутрь кристаллов процессоров.
Развитием идеи SIMD для вещественных чисел стала технология SSE (Streamed SIMD Extensions), впервые представленная в процессорах Pentium III. Блок SSE дополняет технологию MMX восемью 128-битными регистрами XMM0-XMM7 и 32-битным регистром управления и состояния MXCSR.
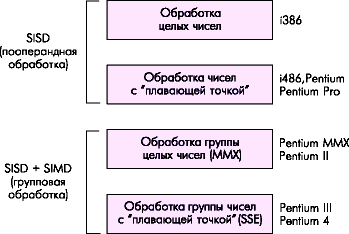
Рисунок 4.9 - Эволюция процесса обработки данных в процессорах Intel Pentium
4.6.4. Pentium 4 (P7) – микроархитектура Net Burst
Процессор Pentium 4 является 32-разрядным представителем семейства IA-32, по микроархитектуре принадлежащим к новому, седьмому (по классификации Intel) поколению. С программной точки зрения он представляет собой процессор IA-32 с очередным расширением системы команд – SSE2. По набору программно-доступных регистров Pentium 4 повторяет процессор Pentium III. С внешней, аппаратной точки зрения – это процессор с системной шиной нового типа, в которой кроме повышения тактовой частоты применены ставшие уже привычными принципы двойной (2х) и четырехкратной (4х) синхронизации, а также предпринят ряд мер по обеспечению работоспособности на ранее немыслимых частотах. Микроархитектура процессора, получившая название Net Burst, разработана с учетом высоких частот как ядра (более 1,4 ГГц), так и системной шины (400 МГц).
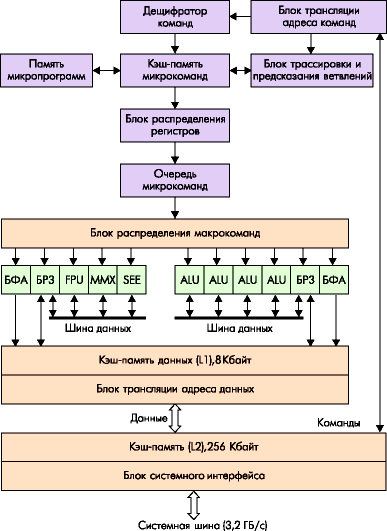
Рисунок 4.10 – Микроархитектура NetBurst
Процессор Pentium 4 является однокристальным. Кроме собственно вычислительного ядра, он содержит кэш-память двух уровней. Вторичный кэш, общий для инструкций и данных, имеет размер 256 Кбайт и разрядность шины 256 бита (32 байта), как и в последних процессорах Pentium III. Шина вторичного кэша работает на частоте ядра, что обеспечивает ее пропускную способность 32х1,4 = 44,8 Гбайт/с на частоте 1,4 ГГц. Вторичный кэш имеет ЕСС-контроль, позволяющий обнаруживать и исправлять ошибки. Первичный кэш данных имеет такую же высокую пропускную способность (44,8 Гбайт/с), но его объем сократился вдвое (8 Кбайт против 16 в Pentium III). Первичный кэш инструкций в привычном понимании отсутствует, его заменил кэш трассы (trace cache). В нем хранятся последовательности микроопераций, в которые декодированы инструкции. Здесь могут помещаться до 12К микроинструкций.
Интерфейс системной шины процессора рассчитан только на однопроцессорные конфигурации. Интерфейс во многом напоминает шину Р6, протокол также ориентирован на одновременное выполнение нескольких транзакций. Принят ряд мер по обеспечению высокой пропускной способности. В процессоре Pentium 4 частота шины 400 МГц с "четырехкратной накачкой" (quad pumped) – тактовая частота системной шины составляет 100 МГц, но частота передачи адресов и данных выше. Новая информация по линиям с общей синхронизацией может передаваться на каждом такте с частотой 100 МГц. Для 2 и 4-кратной передачи используется синхронизация от источника данных.
Исполнительные устройства МП (АЛУ) работают на удвоенной частоте, что дает возможность выполнять большинство целочисленных инструкций за половину такта. По сравнению с предыдущими поколениями IA-32, Pentium 4 содержит самый длинный конвейер команд, состоящий из 20 этапов и названный гиперконвейером. В связи с этой особенностью многие специалисты отмечают, что микроархитектура NetBurst будет иметь максимальную производительность исполнения предсказуемых (линейных и циклических) участков программы, характерных для приложений, на которые ориентирован Pentium 4. На непредсказуемо ветвящихся программах, к которым относятся, например, офисные приложения, длинный гиперконвейер оказывается менее эффективным, чем конвейер Р6, если бы тот удалось разогнать до частот 1,4 ГГц и выше. Чтобы частично компенсировать этот недостаток, были существенно оптимизированы механизмы спекулятивного исполнения и предсказания ветвлений.