Кодер речи является первым элементом собственно цифрового участка передающего тракта, следующим после АЦП (рис.2.1). Основная задача кодера - предельно возможное сжатие сигнала речи, представленного в цифровой форме, - при сохранении приемлемого качества передачи речи. Компромисс между степенью сжатия и сохранением качества отыскивается экспериментально, а проблема получения высокой степени сжатия без чрезмерного снижения качества составляет основную трудность при разработке кодера. В приемном тракте перед ЦАП размещен декодер речи, задача которого - восстановление обычного цифрового сигнала речи, с присущей ему естественной избыточностью, по принятому кодированному сигналу.
В предыдущих лекциях было показано, что кодирование речи на самом деле представляет собой процесс сжатия данных, при котором вместо преобразованных отсчетов входного сигнала для передачи подбираются кодированные параметры модели источника речи, позволяющие приемнику генерировать речевой сигнал (РС), чрезвычайно похожий на исходный. В системе GSM определены три стандарта кодирования речи:
- кодирование речи с полной скоростью (GSM FR);
- кодирование речи с половинной скоростью(GSM HR);
- улучшенноекодирование речи с полной скоростью (GSM EFR).
Современные мобильные телефоны имеют речевые кодеры и декодеры, позволяющие применять любой из перечисленных стандартов.
Кодирование речи с полной скоростью. Этот тип кодирования речи использует модифицированный метод RPE-LTP - линейное предсказание с возбуждением регулярной последовательностью импульсов и долговременным предсказателем (см. раздел 12). Упрощенная блок-схема кодера представлена на рис.13.1.
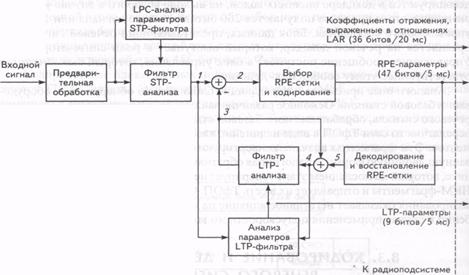
Рис. 13.1. Блок-схема полноскоростного кодера речи в системе GSM(FR)
Основные требования к кодеру состоят в сокращении избыточности речевого сигнала и обеспечении в перерывах во время пауз передачи речи. Поэтому при передаче речи в системе GSM используется техника прерывистой передачи DTX, означающая, что каждый речевой канал активен не непрерывно.
Блок предварительной обработки кодера осуществляет предыскажение входного сигнала при помощи цифрового фильтра восприятия, подчеркивающего верхние частоты, нарезание сигнала на сегменты по 160 выборок (20 миллисекунд) и взвешивание каждого из сегментов окном Хэмминга. Сигнал с выхода фильтра предыскажений подвергается анализу в соответствии с методом линейного предсказания, в результате чего определяются коэффициенты кратковременного линейного предсказания (STP). Полученные параметры, представляющие собой восемь коэффициентов отражения STP-фильтра, преобразуются в логарифмические отношения площадей (LAR), которые могут быть представлены более компактно, нежели сами коэффициенты отражения. Значения LAR в цифровой форме представляются 36 битами.
Затем найденные коэффициенты кратковременного линейного предсказания используются в фильтре-анализаторе STP для обработки того же самого сегмента входных отсчетов. В результате получаются 160 отсчетов остатка кратковременного предсказания сигнала.
Для дальнейшей обработки 20-мс сегмент остатка кратковременного предсказания z(n) делится на четыре подсегмента длительностью 5 мс, по 40 выборок в каждом. Каждый подсегмент последовательно обрабатывается в блоках кодера по отдельности.
Перед обработкой каждого подсегмента речевой кодер определяет параметры фильтра долгосрочного предсказания (LTP) – (весовой) коэффициент предсказания g и задержку d. Операция выполняется на основе текущего подсегмента остатка STP-предсказания (см. сигнал 1 на рис.13.1) и сохраненной последовательности из трех восстановленных предшествующих подсегментов остатка кратковременного предсказания (см. сигнал 4 на рис.13.1). Подсегмент остатка сигнала (2), прошедшего LTP-фильтр, представляет собой разность между подсегментом приближенных значений прошедшего STP-фильтр остатка сигнала (3) и подсегментом точных STP-фильтрованных значений остатка этого сигнала (1). В результате получается субсегмент остатка долговременного предсказания. После отбрасывания последнего отсчета этот подсегмент направляется в блок-анализатор с возбуждением последовательностью регулярных импульсов (RPE). RPE-анализатор разделяет обрабатываемый подсегмент на три последовательности возбуждения, каждая из которых состоит из 13 импульсов. Для этого производится децимация отсчетов и выбор сигнальной сетки (интервал следования импульсов возбуждения обычно втрое превышает период дискретизации исходного сигнала). Затем вычисляется энергия трех прореженных последовательностей. Последовательность с самой большой энергией выбирается как представляющая весь блок прошедших LTP-фильтр остатков. Выбранные импульсы возбуждения нормируются по отношению к наибольшей амплитуде и кодируется. Сдвиг сетки также кодируется и вместе со значениями импульсов возбуждения передается на приемник. В результате представление каждого 5-мс подсегмента производится 47-битовым блоком.
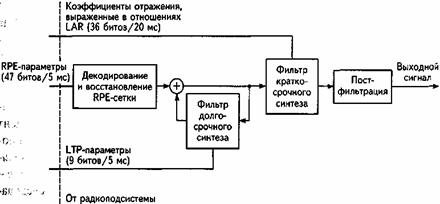
Рис. 13.2. Блок-схема RPE-LTP-декодера речи
Эти же RPE параметры подаются на блок декодирования и восстановления сетки RPE, который выдает подсегмент LTP-остатка (5). После прибавления отсчетов этого сегмента к приближенным значениям STP-остатка получаются реконструированные отсчеты STP-остатка, которые и направляются на вход фильтра долговременного анализа. В результате фильтрации получается новый подсегмент приближенных значений отсчетов остатка кратковременного предсказания, которые используются при обработке следующего подсегмента. В результате применения алгоритма кодирования 20-мс сегмент речи передается 260 битами информации, т.е. кодер речи осуществляет сжатие информации почти в 5 раз (1280 : 260 = 4,92), что обеспечивает цифровую скорость передачиRц = 64/5 @ 13 кбит/с. На рис.13.2 изображена упрощенная схема RPE-LTP-декодера. Он содержит такой же контур обратной связи, как и кодер.
В случае отсутствия ошибок передачи, выходной сигнал этой части декодера восстанавливает последовательность отсчетов остатка кратковременного предсказания. Затем эти отсчеты направляются на вход STP фильтра-синтезатора, после чего обрабатываются блоком постфильтрации для компенсации предыскажений, внесенных фильтром на входе кодера. Сигнал на выходе блока постфильтрации представляет собой восстановленные фрагменты речевого сигнала.
Кодирование речи с половинной скоростью. В GSM-кодере речи с половинной скоростью используется подход «анализ через синтез», рассмотренный в разделе 12, в версии VSELP. На рис. 13.3 изображена упрощенная блок-схема кодера с половинной скоростью.
Процедура «анализ через синтез» используется для поиска наилучшего кодового слова (вектора), характеризующего сигнал возбуждения для каждого 20-мс сегмента. Такое кодовое слово находится путем применения каждого кодового слова из словаря для возбуждения CELP-синтезатора. Затем синтезированный РС сравнивается с входным сигналом и вычисляется их разность. Разностный сигнал взвешивается спектральным взвешивающим фильтром с характеристикой W(z) и вторичным взвешивающим фильтром C(z). В результате получается сигнал ошибки е(п). Кодовое слово, обеспечивающее наименьшую среднюю мощность сигнала ошибки е(п), выбирается как наиболее точно соответствующее данному сегменту. Характеристики взвешивающего фильтра выбираются таким образом, чтобы обеспечить наилучшее субъективное восприятие синтезируемого РС человеческим ухом. Второй взвешивающий фильтр C(z) контролирует количество ошибок в гармониках речевого сигнала.
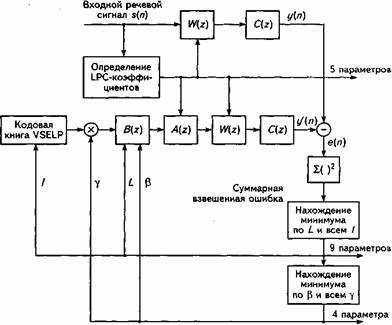
Рис. 13.3. Упрощенная блок-схема GSM-кодера речи с половинной скоростью
A(z) - кратковременный спектральный фильтр; B(z) - долговременный фильтр
с задержкой L
В процессе «анализа через синтез» кодер вычисляет 18 параметров, которые характеризуют каждый 20-мс сегмент. Параметры единичного сегмента представляются 112 битами, что эквивалентно скорости передачи данных 5,6 кбит/с на выходе полускоростного кодера.
Декодер с половинной скоростью представляет собой усечённый вариант кодера. На основе принятых параметров речь генерируется тем же синтезатором, что и в кодере.
При кодировании речи с половинной скоростью количество битов, представляющих 20-мс сегмент, значительно меньше, чем при кодировании с полной скоростью; следовательно, необходим более высокий уровень их защиты в канале передачи. Применение более эффективного канального кодирования приводит к увеличению числа битов в 20-мс сегменте до 228. Это равнозначно скорости потока данных 11,4 кбит/с на выходе канального кодера, что составляет ровно половину скорости на выходе канального кодера, работающего совместно с полноскоростным кодером речи.
Основное преимущество кодера речи с половинной скоростью заключается в удвоении емкости физического канала. Один и тот же временной слот может использоваться чередующимися полускоростными каналами трафика. Внедрение кодирования речи с половинной скоростью связано с попытками обойти проблемы с емкостью системы в густонаселенных районах. Это привело к необходимости внедрить в мобильные телефоны кодеры, которые могут работать с обоими стандартами. Основной недостаток кодирования речи с половинной скоростью - ухудшение качества передачи речи.
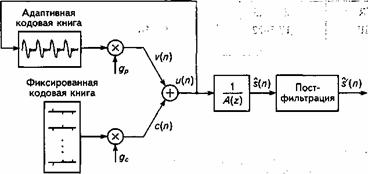
Рис. 13.4. Упрощенная блок-схема GSM-EFR - кодера
Улучшенное кодирование речи с полной скоростью. В основе такого кодера лежит модель линейного предсказания с кодовым возбуждением (CELP). В этой модели речевой сигнал синтезируется в линейном фильтре синтеза с кратковременным предсказанием (STP) 1/A(z) 10-го порядка (рис.13.4). Сигнал u(n) для его возбуждения формируется путем сложения двух векторов возбуждения из адаптивной и фиксированной кодовых книг. LTP-фильтр синтеза реализован с использованием адаптивной кодовой книги. Оптимальный вектор возбуждения ищется в кодовой книге с помощью процедуры «анализ через синтез» - аналогичной той, которая используется в кодировании речи с половинной скоростью.
Для каждого сегмента (20 мс, 160 отсчетов) определяются такие параметры модели CELP, как коэффициенты фильтра линейного предсказания, адреса в адаптивной и фиксированной кодовой книгах, а также весовые коэффициенты. Затем они кодируются и пересылаются на приемник. Декодер использует принятые параметры для восстановления речевого сигнала в CELP-синтезаторе, идентичном применяемому в передатчике при анализе речи.
EFR-кодер генерирует поток данных со скоростью 13 кбит/с. Тесты показали, что EFR-кодирование позволяет получить намного лучшее качество передачи речи, чем RPE-LTP-коди-рование. Такой тип кодеров в основном используется во вновь разворачиваемых сетях, в частности, в сетях PCS-1900 в Северной Америке.