5.1. Классификация архитектур вычислительных систем с параллельной обработкой данных
5.2. Симметричная многопроцессорная архитектура SMP
5.3. Массивно-параллельная архитектура MPP
5.4. Гибридная архитектура NUMA
5.5. Параллельная архитектура PVP с векторными процессорами
5.7. Основные тенденции развития вычислительной техники
5.7.1. Повышение тактовой частоты
5.7.2. Увеличение объема и пропускной способности подсистемы памяти
5.7.3. Увеличение количества параллельно работающих вычислительных устройств
5.1. Классификация архитектур вычислительных систем с параллельной обработкой данных
Чтобы дать более полное представление о многопроцессорных вычислительных системах, помимо высокой производительности необходимо назвать и другие отличительные особенности. Прежде всего, это необычные архитектурные решения, направленные на повышение производительности (работа с векторными операциями, организация быстрого обмена сообщениями между процессорами или организация глобальной памяти в многопроцессорных системах и др.).
Понятие архитектуры высокопроизводительной системы является достаточно широким, поскольку под архитектурой можно понимать и способ параллельной обработки данных, используемый в системе, и организацию памяти, и топологию связи между процессорами, и способ исполнения системой арифметических операций. Попытки систематизировать все множество архитектур впервые были предприняты в конце 60-х годов и продолжаются по сей день.
В 1966 г. М. Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В его основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором.
Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса:
- SISD (Single Instruction Single Data) – 1 поток команд и 1 поток данных.
- MISD (Multiple Instruction Single Data) – несколько потоков команд и 1 поток данных.
- SIMD (Single Instruction Multiple Data) – 1 поток команд и несколько потоков данных.
- MIMD (Multiple Instruction Multiple Data) – несколько потоков команд и несколько потоков данных.
|
|
|
|
Рисунок 5.1 – Архитектура SISD, 1 поток команд и 1 поток данных |
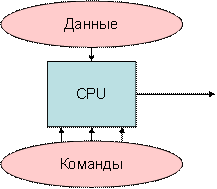
Рисунок 5.2 – Архитектура MISD, несколько потоков команд и 1 поток данных |
|
|
|
|
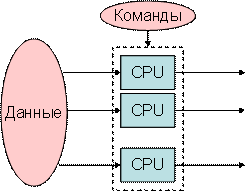
Рисунок 5.3 – Архитектура SIMD, 1 поток команд и несколько потоков данных |
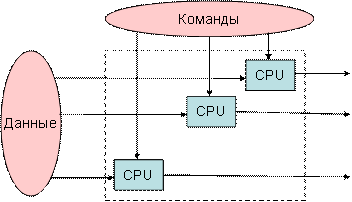
Рисунок 5.4 – MIMD, несколько потоков команд и несколько потоков данных |
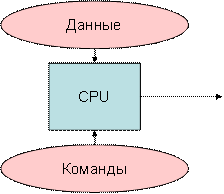
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций.
В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако каждый из них выполняет несвязанные потоки инструкций, что делает такие системы комплексами SISD-систем, действующих на разных пространствах данных.
Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка. В случае векторных систем векторный поток данных следует рассматривать как поток из одиночных неделимых векторов.
Примерами компьютеров с архитектурой SISD могут служить большинство рабочих станций Compaq, Hewlett-Packard и Sun Microsystems.
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должно выполняться над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, создано не было. В качестве аналога работы такой системы, по-видимому, можно рассматривать работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Поскольку база данных одна, а команд много, мы имеем дело с множественным потоком команд и одиночным потоком данных.
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров (от 1024 до 16384), которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных.
Примерами SIMD-машин являются системы CPP DAP, Gamma II и Quadrics Apemille.
Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. Когда данные обрабатываются посредством векторных модулей, результаты могут быть выданы на один, два или три такта частотогенератора (такт частотогенератора является основным временным параметром системы). При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа являются, например, компьютеры Hitachi S3600.
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от упомянутых выше многопроцессорных SISD-машин, команды и данные связаны, потому что они представляют различные части одной и той же задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач с целью сокращения времени выполнения основной задачи.
Большое разнообразие попадающих в MIMD класс вычислительных систем делает классификацию Флинна не полностью адекватной. Действительно, и четырехпроцессорный SX-5 компании NEC, и тысячепроцессорный Cray T3E попадают в этот класс. Это заставляет использовать другой подход к классификации, иначе описывающий классы компьютерных систем.
Другой подход к классификации состоит в разделении вычислительных систем по способам обработки множественного потока команд.
Одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков. Такая возможность используется в MIMD-компьютерах, которые обычно называют конвейерными или векторными. В основе векторных компьютеров лежит концепция конвейеризации, т.е. явного сегментирования арифметического устройства на отдельные части, каждая из которых выполняет свою подзадачу для пары операндов.
Каждый поток обрабатывается своим собственным устройством. Такая возможность используется в параллельных компьютерах. В основе параллельного компьютера лежит идея использования для решения одной задачи нескольких процессоров, работающих сообща, причем процессоры могут быть как скалярными, так и векторными.
Классификация архитектур вычислительных систем нужна для того, чтобы понять особенности работы той или иной архитектуры, но она не является достаточно детальной, чтобы на нее можно было опираться при создании МВС, поэтому следует вводить более детальную классификацию, которая связана с различными архитектурами ЭВМ и с используемым оборудованием.
5.2. Симметричная многопроцессорная архитектура SMP
SMP (symmetric multiprocessing) – симметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP (рис.5.5) является наличие общей физической памяти, разделяемой всеми процессорами.
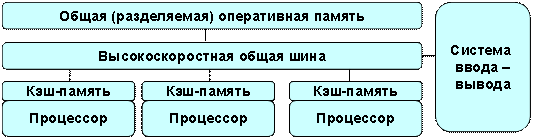 Рисунок 5.5 – Схематический вид SMP-архитектуры
Рисунок 5.5 – Схематический вид SMP-архитектуры
Память служит, в частности, для передачи сообщений между процессорами, при этом все вычислительные устройства при обращении к ней имеют равные права и одну и ту же адресацию для всех ячеек памяти. Поэтому SMP-архитектура называется симметричной. Последнее обстоятельство позволяет очень эффективно обмениваться данными с другими вычислительными устройствами.
SMP-система строится на основе высокоскоростной системной шины (SGI PowerPath, Sun Gigaplane, DEC TurboLaser), к слотам которой подключаются функциональные блоки типов: процессоры (ЦП), подсистема ввода/вывода (I/O) и т. п. Для подсоединения к модулям I/O используются уже более медленные шины (PCI, VME64).
Наиболее известными SMP-системами являются SMP-cерверы и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.) Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы по процессорам, но иногда возможна и явная привязка.
Основные преимущества SMP-систем:
- простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель программирования, используемую при создании приложения: обычно используется модель параллельных ветвей, когда все процессоры работают независимо друг от друга. Однако можно реализовать и модели, использующие межпроцессорный обмен. Использование общей памяти увеличивает скорость такого обмена, пользователь также имеет доступ сразу ко всему объему памяти. Для SMP-систем существуют довольно эффективные средства автоматического распараллеливания;
- простота эксплуатации. Как правило, SMP-системы используют систему кондиционирования, основанную на воздушном охлаждении, что облегчает их техническое обслуживание;
- относительно невысокая цена.
Недостатки:
- системы с общей памятью плохо масштабируются.
Этот существенный недостаток SMP-систем не позволяет считать их по-настоящему перспективными. Причиной плохой масштабируемости является то, что в данный момент шина способна обрабатывать только одну транзакцию, вследствие чего возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти.
В настоящее время конфликты могут происходить при наличии 8-24 процессоров. Все это очевидно препятствует увеличению производительности при увеличении числа процессоров и числа подключаемых пользователей. В реальных системах можно задействовать не более 32 процессоров. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры. При работе с SMP-системами используют так называемую парадигму программирования с разделяемой памятью (shared memory paradigm).
5.3. Массивно-параллельная архитектура MPP
MPP (massive parallel processing) – массивно-параллельная архитектура. Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП), коммуникационные процессоры(роутеры) или сетевые адаптеры, иногда – жесткие диски и/или другие устройства ввода/вывода. По сути, такие модули представляют собой полнофункциональные компьютеры (см. рис. 5.6).
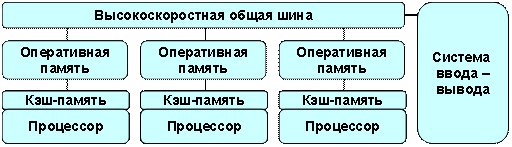 Рисунок 5.6 – Схематический вид архитектуры с раздельной памятью
Рисунок 5.6 – Схематический вид архитектуры с раздельной памятью
Доступ к банку ОП из данного модуля имеют только процессоры (ЦП) из этого же модуля. Модули соединяются специальными коммуникационными каналами. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами.
Используются два варианта работы операционной системы на машинах MPP-архитектуры:
- полноценная операционная система (ОС) работает только на управляющей машине (front-end), на каждом отдельном модуле функционирует сильно урезанный вариант ОС, обеспечивающий работу только расположенной в нем ветви параллельного приложения.
- на каждом модуле работает полноценная UNIX-подобная ОС, устанавливаемая отдельно.
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость: в отличие от SMP-систем, в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодня устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (ASCI Red, ASCI Blue Pacific).
Недостатки:
- отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами. Требуется специальная техника программирования для реализации обмена сообщениями между процессорами;
- каждый процессор может использовать только ограниченный объем локального банка памяти;
- вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально использовать системные ресурсы. Именно этим определяется высокая цена программного обеспечения для массивно-параллельных систем с раздельной памятью.
Системами с раздельной памятью являются суперкомпьютеры МВС-1000, IBM RS/6000 SP, SGI/CRAY T3E, системы ASCI, Hitachi SR8000, системы Parsytec. Машины последней серии CRAY T3E от SGI, основанные на базе процессоров Dec Alpha 21164 с пиковой производительностью 1200 Мфлопс/с (CRAY T3E-1200), способны масштабироваться до 2048 процессоров.
При работе с MPP-системами используют так называемую Massive Passing Programming Paradigm – парадигму программирования с передачей данных (MPI, PVM, BSPlib).
5.4. Гибридная архитектура NUMA
Главная особенность гибридной архитектуры NUMA (nonuniform memory access) – неоднородный доступ к памяти.
Суть этой архитектуры – в особой организации памяти, а именно: память физически распределена по различным частям системы, но логически она является общей, так что пользователь видит единое адресное пространство. Система построена из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной. По существу, архитектура NUMA является MPP (массивно-параллельной) архитектурой, где в качестве отдельных вычислительных элементов берутся SMP (симметричная многопроцессорная архитектура) узлы. Доступ к памяти и обмен данными внутри одного SMP-узла осуществляется через локальную память узла и происходит очень быстро, а к процессорам другого SMP-узла тоже есть доступ, но более медленный и через более сложную систему адресации.
Гибридная архитектура совмещает достоинства систем с общей памятью и относительную дешевизну систем с раздельной памятью.
В структурной схеме компьютера с гибридной сетью (рис. 5.7) три процессора связываются между собой при помощи общей оперативной памяти в рамках одного SMP-узла. Узлы связаны сетью типа "бабочка" (Butterfly).
Впервые идею гибридной архитектуры предложил Стив Воллох, он воплотил ее в системах серии Exemplar. Вариант Воллоха – система, состоящая из восьми SMP-узлов. Фирма HP купила идею и реализовала на суперкомпьютерах серии SPP. Идею подхватил Сеймур Крей (Seymour R. Cray) и добавил новый элемент – когерентный кэш, создав так называемую архитектуру cc-NUMA (Cache Coherent Non-Uniform Memory Access), которая расшифровывается как "неоднородный доступ к памяти с обеспечением когерентности кэшей". Он ее реализовал на системах типа Origin.
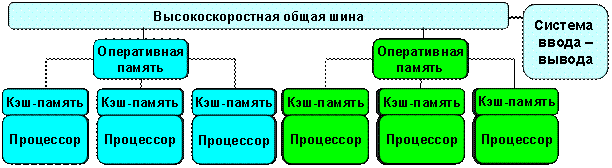 Рисунок 5.7 – Структурная схема компьютера с гибридной сетью
Рисунок 5.7 – Структурная схема компьютера с гибридной сетью
Организация когерентности многоуровневой иерархической памяти
Понятие когерентности кэшей описывает тот факт, что все центральные процессоры получают одинаковые значения одних и тех же переменных в любой момент времени. Действительно, поскольку кэш-память принадлежит отдельному компьютеру, а не всей многопроцессорной системе в целом, данные, попадающие в кэш одного компьютера, могут быть недоступны другому. Чтобы этого избежать, следует провести синхронизацию информации, хранящейся в кэш-памяти процессоров.
Для обеспечения когерентности кэшей существует несколько возможностей:
- использовать механизм отслеживания шинных запросов (snoopy bus protocol), в котором кэши отслеживают переменные, передаваемые к любому из центральных процессоров и при необходимости модифицируют собственные копии таких переменных;
- выделять специальную часть памяти, отвечающую за отслеживание достоверности всех используемых копий переменных.
Наиболее известными системами архитектуры cc-NUMA являются: HP 9000 V-class в SCA-конфигурациях, SGI Origin3000, Sun HPC 15000, IBM/Sequent NUMA-Q 2000. На сегодня максимальное число процессоров в cc-NUMA-системах может превышать 1000 (серия Origin3000). Обычно вся система работает под управлением единой ОС, как в SMP. Возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС. При работе с NUMA-системами, так же, как с SMP, используют так называемую парадигму программирования с общей памятью (shared memory paradigm).
5.5. Параллельная архитектура PVP с векторными процессорами
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах.
Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько узлов могут быть объединены с помощью коммутатора (аналогично MPP). Поскольку передача данных в векторном формате осуществляется намного быстрее, чем в скалярном (максимальная скорость может составлять 64 Гбайт/с, что на 2 порядка быстрее, чем в скалярных машинах), то проблема взаимодействия между потоками данных при распараллеливании становится несущественной. И то, что плохо распараллеливается на скалярных машинах, хорошо распараллеливается на векторных. Таким образом, системы PVP-архитектуры могут являться машинами общего назначения (general purpose systems). Однако, поскольку векторные процессоры весьма дорого стоят, эти машины не могут быть общедоступными.
Наиболее популярны три машины PVP-архитектуры:
1. CRAY X1, SMP-архитектура (рис. 5.8). Пиковая производительность системы в стандартной конфигурации может составлять десятки терафлопс.
2. NEC SX-6, NUMA-архитектура. Пиковая производительность системы может достигать 8 Тфлопс, производительность одного процессора составляет 9,6 Гфлопс. Система масштабируется с единым образом операционной системы до 512 процессоров.
3. Fujitsu-VPP5000 (vector parallel processing), MPP-архитектура (рис. 5.9). Производительность одного процессора составляет 9.6 Гфлопс, пиковая производительность системы может достигать 1249 Гфлопс, максимальная емкость памяти – 8 Тбайт. Система масштабируется до 512 процессоров.
Парадигма программирования на PVP-системах предусматривает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
За счет большой физической памяти (доли терабайта) даже плохо векторизуемые задачи на PVP-системах решаются быстрее на машинах со скалярными процессорами.
|
|
|
|
Рисунок 5.8 – CRAY SV-2 |
Рисунок 5.9 – Fujitsu-VPP5000 |


5.6. Кластерная архитектура
Кластер представляет собой два или более компьютеров (часто называемых узлами), объединяемые при помощи сетевых технологий на базе шинной архитектуры или коммутатора и предстающие перед пользователями в качестве единого информационно-вычислительного ресурса.
Кластерная архитектура представлена на рис. 5.10.

Рисунок 5.10 – Кластерная архитектура
В качестве узлов кластера могут быть выбраны серверы, рабочие станции и даже обычные персональные компьютеры. Узел характеризуется тем, что на нем работает единственная копия операционной системы.
Элементами кластера являются – один управляющий узел и остальные вычислительные, связанные в локальную сеть.
Управляющий узел – подготовка параллельных программ и данных, взаимодействие с вычислительными узлами через управляющую сеть.
Вычислительные узлы – выполнение параллельной программы, обмен данными через коммуникационную сеть.
Возможности масштабируемости кластеров позволяют многократно увеличивать производительность приложений для большего числа пользователей технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора. Такие суперкомпьютерные системы являются самыми дешевыми, поскольку собираются на базе стандартных комплектующих элементов ("off the shelf"), процессоров, коммутаторов, дисков и внешних устройств.
Кластеры условно можно разделить на классы.
Класс I. Класс машин строится целиком из стандартных деталей, которые продают многие поставщики компьютерных компонентов (низкие цены, простое обслуживание, аппаратные компоненты доступны из различных источников).
Класс II. Система имеет эксклюзивные или не слишком широко распространенные детали. Таким образом, можно достичь очень хорошей производительности, но при более высокой стоимости.
Кластеры могут существовать в различных конфигурациях. Наиболее распространенными типами кластеров являются:
- системы высокой надежности – в случае сбоя какого-либо узла другой узел кластера может взять на себя нагрузку неисправного узла, и пользователи не заметят прерывания в доступе;
- системы для высокопроизводительных вычислений – предназначены для параллельных расчетов. Эти кластеры обычно собраны из большого числа компьютеров. Разработка таких кластеров является сложным процессом, требующим на каждом шаге согласования таких вопросов как инсталляция, эксплуатация и одновременное управление большим числом компьютеров, технические требования параллельного и высокопроизводительного доступа к одному и тому же системному файлу (или файлам) и межпроцессорная связь между узлами, и координация работы в параллельном режиме. Эти проблемы проще всего решаются при обеспечении единого образа операционной системы для всего кластера;
- многопоточные системы – используются для обеспечения единого интерфейса к ряду ресурсов, которые могут со временем произвольно наращиваться (или сокращаться). Типичным примером может служить группа web-серверов.
Отметим, что границы между этими типами кластеров до некоторой степени размыты, и кластер может иметь такие свойства или функции, которые выходят за рамки перечисленных типов. Более того, при конфигурировании большого кластера, используемого как система общего назначения, приходится выделять блоки, выполняющие все перечисленные функции.
В 1994 году Томас Стерлинг (Sterling) и Дон Беккер (Becker) создали 16-узловой кластер из процессоров Intel DX4, соединенных сетью 10 Мбит/с Ethernet с дублированием каналов. Они назвали его "Beowulf" (рис. 5.7 – 5.9) по названию старинной эпической поэмы. Кластер возник в центре NASA Goddard Space Flight Center для поддержки необходимыми вычислительными ресурсами проекта Earth and Space Sciences. Проектно-конструкторские работы быстро превратились в то, что известно сейчас как проект Beowulf.
|
|
|
|
Рисунок 5.11 – Лезвие (Blade) – вычислительный узел |
Рисунок 5.12 – Blade – модуль |
|
|
|
|
Рисунок 5.13 – Кластер Beowulf (на лезвиях) |
Рисунок 5.14 – Коммутационный узел |




Проект стал основой общего подхода к построению параллельных кластерных компьютеров, он описывает многопроцессорную архитектуру, которая может с успехом использоваться для параллельных вычислений. Beowulf-кластер, как правило, является системой, состоящей из одного серверного узла (который обычно называется головным), а также одного или нескольких подчиненных (вычислительных) узлов, соединенных посредством стандартной компьютерной сети. Система строится с использованием стандартных аппаратных компонентов, таких как ПК, запускаемые под Linux, стандартные сетевые адаптеры (например, Ethernet) и коммутаторы. Нет особого программного пакета, называемого "Beowulf". Вместо этого имеется несколько кусков программного обеспечения, которые многие пользователи нашли пригодными для построения кластеров Beowulf. Beowulf использует такие программные продукты как операционная система Linux, системы передачи сообщений PVM, MPI, системы управления очередями заданий и другие стандартные продукты. Серверный узел контролирует весь кластер и обслуживает файлы, направляемые к клиентским узлам.
5.7. Основные тенденции развития вычислительной техники
Сердцем вычислительной системы является один или несколько процессоров. Поэтому именно с модернизаций процессоров, как основной вычислительной части, связывается прогресс вычислительной техники.
Рассмотрим основные направления развитие микропроцессоров.
5.7.1. Повышение тактовой частоты
Для повышения тактовой частоты при выбранных материалах используются:
- более совершенный технологический процесс с меньшими проектными нормами;
- увеличение числа слоев металлизации;
- более совершенная схемотехника меньшей каскадности и с более совершенными транзисторами,
- более плотная компоновка функциональных блоков кристалла.
Уменьшение размеров транзисторов, сопровождаемое снижением напряжения питания с 5 В до 2,5-3 В и ниже, увеличивает быстродействие и уменьшает выделяемую тепловую энергию. Все производители микропроцессоров перешли с проектных норм 0,35-0,25 мкм на 0,18 мкм и 0,12 мкм и стремятся использовать уникальную 0,07 мкм технологию.
Уменьшение длины межсоединений актуально для повышения тактовой частоты работы, так как существенную долю длительности такта занимает время прохождения сигналов по проводникам внутри кристалла. Например, в Alpha 21264 предприняты специальные меры по кластеризации обработки, призванные локализовать взаимодействующие элементы микропроцессора. Проблема уменьшения длины межсоединений на кристалле при использовании традиционных технологий решается путем увеличения числа слоев металлизации.
5.7.2. Увеличение объема и пропускной способности подсистемы памяти
Возможные решения по увеличению пропускной способности подсистемы памяти включают:
- создание кэш-памяти одного или нескольких уровней,
- увеличение пропускной способности интерфейсов между процессором и кэш-памятью и конфликтующей с этим увеличением пропускной способности между процессором и основной памятью.
Совершенствование интерфейсов реализуется как увеличением пропускной способности шин (путем увеличения частоты работы шины и/или ее ширины), так и введением дополнительных шин, расшивающих конфликты между процессором, кэш-памятью и основной памятью. В последнем случае одна шина работает на частоте процессора с кэш-памятью, а вторая – на частоте работы основной памяти.
Общая тенденция увеличения размеров кэш-памяти реализуется по-разному:
- внешние кэш-памяти данных и команд с двух тактовым временем доступа объемом от 256 Кбайт до 2 Мбайт со временем доступа 2 такта в HP PA-8000;
- отдельный кристалл кэш-памяти второго уровня, размещенный в одном корпусе в Pentium Pro;
- размещение отдельных кэш-памяти команд и кэш-памяти данных первого уровня объемом по 8 Кбайт и общей для команд и данных кэш-памяти второго уровня объемом 96 Кбайт в Alpha 21164.
Наиболее используемое решение состоит в размещении на кристалле отдельных кэш-памятей первого уровня для данных и команд с возможным созданием внекристальной кэш-памяти второго уровня.
5.7.3. Увеличение количества параллельно работающих вычислительных устройств
Каждое семейство микропроцессоров демонстрирует в следующем поколении увеличение числа функциональных исполнительных устройств и улучшение их характеристик, как временных (сокращение числа ступеней конвейера и уменьшение длительности каждой ступени), так и функциональных (введение ММХ-расширений системы команд и т.д.).
В настоящее время процессоры могут выполнять до 6 операций за такт. Однако число операций с плавающей точкой в такте ограничено двумя для R10000 и Alpha 21164, а 4 операции за такт делает HP PA-8500. Для того чтобы загрузить функциональные исполнительные устройства, используются переименование регистров и предсказание переходов, устраняющие зависимости между командами по данным и управлению, буферы динамической переадресации.
Широко используются архитектуры с длинным командным словом – VLIW. Так, архитектура IA-64, развиваемая Intel и HP, использует объединение нескольких инструкций в одной команде (EPIC). Это позволяет упростить процессор и ускорить выполнение команд. Процессоры с архитектурой IA-64 могут адресоваться к 4 Гбайтам памяти и работать с 64-разрядными данными. Архитектура IA-64 используется в микропроцессоре Merced, обеспечивая производительность до 6 Гфлоп при операциях с одинарной точностью и до 3 Гфлоп – с повышенной точностью на частоте 1 ГГц.
5.7.4. Системы на одном кристалле и новые технологии
В настоящее время получили широкое развитие системы, выполненные на одном кристалле – SOC (System On Chip). Сфера применения SOC – от игровых приставок до телекоммуникаций.
Основной технологический прорыв в области SOC удалось сделать корпорации IBM, которая в 1999 году смогла реализовать процесс объединения на одном кристалле логической части микропроцессора и оперативной памяти. Использование новой технологии открывает перспективу для создания более мощных и миниатюрных микропроцессоров и помогает создавать компактные, быстродействующие и недорогие электронные устройства.
Для создания SOC IBM использует самые современные технологические решения, одним из которых являются медные межсоединения (copper interconnect). Первым микропроцессором IBM с медными межсоединениями в 1998 г. стал PowerPC 750. По сравнению с технологией, где межсоединения выполнены на основе алюминия, медь позволяет сделать кристалл меньшим по размеру и более быстродействующим. Медная металлизация уменьшает общее сопротивление, что позволяет увеличить скорость работы кристалла на 15-20 %. Обычно эта технология дополняется еще одной новинкой: технологией кремний на изоляторе – КНИ (SOI, Silicon On Insulator). Она уменьшает паразитные емкости, возникающие между элементами микросхемы и подложкой. Благодаря этому тактовую частоту работы транзисторов также можно увеличить. Возрастание скорости от использования КНИ приближается к 20-30%. Таким образом, общий рост производительности в идеальном случае может достигнуть 50%.
5.7.5. Нанотехнологии
Нанотехнологии – это технологии, оперирующие величинами порядка нанометра. Это технологии манипуляции отдельными атомами и молекулами, в результате которых создаются структуры сложных спецификаций. Слово "нано" (в древнегреческом языке "nano" – "карлик") означает миллиардную часть единицы измерения и является синонимом бесконечно малой величины, в сотни раз меньшей длины волны видимого света и сопоставимой с размерами атомов. Поэтому переход от "микро" к "нано" – это уже не количественный, а качественный переход: скачок от манипуляции веществом к манипуляции отдельными атомами. Мир таких бесконечно малых величин намного меньше, чем мир сегодняшних микрокристаллов и микротранзисторов.
По мнению аналитиков, предел миниатюризации для традиционной кремниевой электроники наступит через 10-15 лет, а число транзисторов в более сложных устройствах вроде электрических схем неуклонно растет.
Ученые из лаборатории Lucent Technologies Bell Labs сообщили о создании транзистора, который в миллион раз меньше крупицы песка. Это событие может стать ключевым моментом в создании миниатюрных компьютерных микросхем с малым потреблением энергии. Транзисторы являются "мозгом" компьютеров и любых других электронных устройств. Используя органическую молекулу и химические внутренние процессы, исследователи уменьшили размер транзистора до 1-2 нм (миллиардной части метра), чего еще никому не удавалось.
При создании транзисторов использовалась техника "самосборки", когда молекулы фактически сами присоединяются одна к другой с помощью электродов, сделанных из золота. Это позволило уменьшить размер канала до 1-2 нм, причем использованная методика относительно недорога и позволяет увеличить плотность транзисторов на единицу площади. Хотя пока получен только экспериментальный образец, исследователи настроены весьма оптимистично и считают, что вскоре станет возможным строить микропроцессоры и микросхемы памяти из транзисторов размером с молекулу.