Гибридные кодеры речевой информации основаны на комбинации линейного предсказания с элементами кодирования формы сигнала, т.е. звуковой волны. Так, в алгоритме линейного предсказания с возбуждением от остатка предсказания (RELP) (см. табл. 6.1) наряду с передачей вокодерных параметров (коэффициентов линейного предсказания и усиления) осуществляется передача сигнала остатка (ошибки) предсказания в полосе частот 0...800 Гц. Сигнал остатка предсказания приблизительно равен сигналу возбуждения голосового тракта модели речеобразования (см. рис. 10.1), поэтому в алгоритме RELP он используется в синтезаторе декодера для возбуждения синтезирующего фильтра. Формируемый в результате речевой сигнал звучит более естественно.
Большинство гибридных кодеров используют замкнутое кодирование на основе линейного предсказания, называемое также методом «анализ через синтез» (AbS). Этот метод характеризуется исчерпывающей самооптимизирующейся процедурой поиска. Ее выполняет аппаратура передачи, которая находит наилучшую аппроксимацию каждого речевого сегмента исходного речевого сигнала (РС). Как только такая аппроксимация определена, представляющий ее код передается на приемную сторону, где используется для синтеза РС.
Одной из первых реализаций метода анализа через синтез ( 1982 г.) является алгоритм линейного предсказания с многоимпульсным возбуждением (MPE), используемый в системах спутниковой связи. В многоимпульсном возбуждении сигнал остатка линейного предсказания представляется в виде последовательности импульсов с неравномерно распределенными интервалами и с разными амплитудами. Число импульсов в каждом кадре речевого сигнала зависит от требуемого качества речи, чем больше импульсов, тем выше качество речи. На каждом кадре в 10 мс речевого сигнала считается достаточным 6...8 импульсов (или 8 импульсов на период основного тона) для получения высокого качества синтезированной речи.
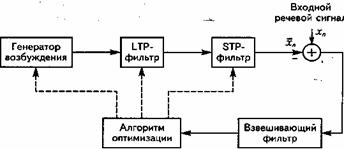
Рис. 12.1. Схема речевого кодера, использующего метод «анализ через синтез»
Согласно этому алгоритму (рис. 12.1), амплитуды и положения импульсов сигнала многоимпульсного возбуждения определяются на покадровой основе (кадр за кадром): на передающей стороне генератор возбуждения создает неравномерно распределенную последовательность импульсов и(п), которая в качестве сигнала возбуждения поступает на вход синтезирующего фильтра, на выходе которого возникают выборки речи Ŝ(n). Эти выборки сравниваются с соответствующими выборками S(n) исходного РС и находится ошибка предсказания z(n).
Кодер, реализованный на основе метода «анализ через синтез», - это речевой синтезатор, который генерирует сигнал, подобный объекту кодирования - речевому сигналу. Синтезатор состоит из генератора возбуждения и фильтров долговременного (LTP) и кратковременного (STP) предсказания. STP-фильтр моделирует краткосрочную корреляцию РС (восстанавливает огибающую спектра), порядок адаптации при этом составляет 20…30 мс, а порядок предсказания P обычно выбирается равным 8-12. LTP-фильтр формирует долгосрочную корреляцию РС (точную структуру спектра); период его адаптации – каждые 5…10 мс. Из-за рекурсивной природы обоих фильтров они содержат память-буфер, содержимое которого переносится из предыдущего анализируемого кадра.
В процессе кодирования каждого речевого сегмента (кадра) для него находятся такие “наилучшие” положения импульсов в последовательности и(п) и их амплитуды, которые обеспечивают минимальную ошибку. Алгоритм оптимизации, используя уравнение (10.2), минимизирует разность z(n) между исходным и синтезированным сигналами путем изменения возбуждающего сигнала и коэффициентов линейного предсказания api фильтров STP и LTP. Это достигается выполнением последовательных процедур – сначала определяются параметры нестационарного (т.е. синтезирующего) фильтра, затем по ним оптимизируется возбуждение.
Метод “анализа через синтез” дает весьма высокое качество синтезированной кодеком речи, поскольку учитывает процессы квантования коэффициентов вокодера, возникающие ошибки квантования, их влияние на синтезированную речь. К тому же, при вычислении величины ошибки между синтезированной и исходной речью используют не среднеквадратический критерий, а критерий, учитывающий особенности субъективного восприятия слушателем (в частности, эффект маскировки сигнала малого уровня сигналом большого уровня). Для этого перед вынесением решения о величине средней ошибки на речевом сегменте сигнал ошибки пропускают через взвешивающий фильтр, т.е. в алгоритме оптимизации используется не сама погрешность, а ее взвешенное значение zw(n). Этот фильтр перестраивается одновременно с синтезирующим фильтром и перераспределяет энергию ошибки по частотному диапазону (где-то усиливает, а где-то ослабляет). В результате большая часть шума квантования попадает в места расположения формантных областей (максимумов спектра) РС, а меньшая — между областями. В этом случае в формантных областях происходит маскировка шума речевым сигналом, в результате чего общая заметность шума в синтезированной речи уменьшится.
На сторону приема передаются параметры LTP- и STP-фильтров, а также параметры сигнала возбуждения. Представление сигнала возбуждения и(п) в виде последовательности импульсов с неравномерно распределенными интервалами и различными амплитудами позволяет более точно учесть особенности возбуждения голосового тракта человека.
Метод “анализа через синтез” применяется почти в каждом вокодере. Это обусловлено тем, что оптимальные значения для некоторых параметров, участвующих в синтезе речи, можно найти только методом перебора (внутри заданного заранее множества их значений).
Установлено, что для вокализованного РС многоимпульсное возбуждение можно упростить, представив его в виде последовательности равномерно расположенных импульсов (обычно 10 импульсов на интервале 5 мс). В методе возбуждения регулярной импульсной последовательностью (RPE) взаимное положение импульсов предопределено заранее - используют решетку равноотстоящих импульсов, а оптимизируют расположение решетки и амплитуды импульсов. В этом методе число импульсов определяется интервалом между ними. Экспериментально установлено, что интервал, равный четырем отсчетам (4*0,125 = 0,5 мс) РС, является оптимальным. Интервал больше, чем 5 отсчетов ухудшает звучание, особенно женских голосов. Местоположение первого импульса должно определяться каждые 5 мс минимизацией сигнала остатка.
Качество речи, синтезированной с использованием этого метода возбуждения, конечно, не имеет той полноты звучания, которое получается при многоимпульсном возбуждении. Однако алгоритм обработки при RPE значительно проще. Это и определяет широкое распространение данного метода аппроксимации второго остаточного сигнала.
В 1984 году, как естественное развитие многоимпульсного метода возбуждения, было предложено так называемое векторное кодирование (VQ), когда кодируется одновременно группа параметров, характеризующих позиции импульсов и их амплитуды. В этом случае в качестве сигнала возбуждения используется последовательность отсчетов (т.е. “вектор”), взятая из заданного набора этих последовательностей (т.е. из “кодовой книги векторов”). Входной вектор, представляющий собой образец входного РС, сравнивается с векторами, находящимися в кодовой книге, и находится вектор, наиболее близкий к входному. Критерием выбора вектора часто становится минимизация среднеквадратичной ошибки между образцом входного сигнала и вектором. Каждому “вектору” из этой “книги” соответствует свой адрес - индекс (номер), который и передается по каналу связи на приемную сторону. На рис. 12.2 изображен процесс кодирования. На приемной стороне в декодере используется точно такая же кодовая книга, из которой по индексу извлекается требуемый вектор. Таким образом, снижение скорости в результате использования VQ достигается путем передачи на прием только номера (индекса) вектора с масштабным коэффициентом.
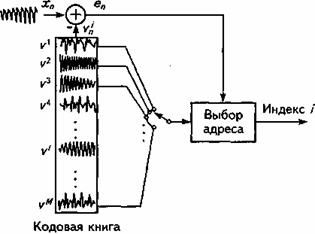
Рис. 12.2. Принцип векторного кодирования
Как правило, кодовая книга состоит из большого количества векторов, т.к. ее размер оказывает значительное влияние на качество речи. В виду очень больших вычислительных затрат прямой перебор векторов для отыскания среди них оптимального оказывается очень часто не возможен. Поэтому прибегают к различным ухищрениям в виде разбиения одной книги на несколько и последовательного поиска в каждой из них, а также структурирования содержания книги. Чтобы уменьшить время поиска подходящего вектора в кодовой книге, используют также так называемый древовидный поиск. В этом случае число вычислительных операций равно log2N, где N - число векторов. Однако при этом требуется большой объем памяти. Как правило, создаются две кодовые книги: одна для образцов сигнала возбуждения, другая - для образцов огибающей спектра.
Наиболее подходящий вектор возбуждения выбирается из заранее составленных кодовых книг, содержащих обычно 27 -210 квазислучайных векторов заданной длины с элементами, нормированными по амплитуде. Амплитуда вектора возбуждения кодируется отдельно в соответствии с громкостью передаваемого сегмента речи. Векторное кодирование лежит в основе метода стохастического кодирования, или метода линейного предсказания с кодовым возбуждением (CELP). Частными случаями CELP являются методы VSELP и ACELP.
Кодер CELP реализует процедуру анализа через синтез (рис.12.3). Сигнал возбуждения u(h) формируется путем сложения масштабированного сигнала из адаптивной кодовой книги (добавляются долговременные частотные составляющие речевого сигнала) и масштабированного сигнала из большой фиксированной кодовой книги. Полученный сигнал возбуждения управляет синтезирующим фильтром, который моделирует эффекты голосового тракта. В декодере сигнал возбуждения проходит через синтезирующий фильтр, формируя восстановленный речевой сигнал Ŝ(n).
Очевидно, что сначала определяются параметры фильтра, а затем уже находятся индексы кодовых книг а и k и соответствующие коэффициенты усиления G1 и G2. Параметры кодовых книг выбираются так, чтобы минимизировать взвешенную ошибку между исходным речевым сигналом S(n) и восстановленным Ŝ(n), что достигается подачей содержимого каждой «ячейки» кодовой книги на синтезирующий фильтр с целью выявления максимально похожего (по восприятию) образца.
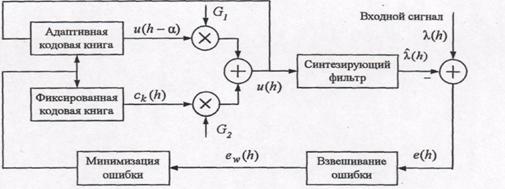
Рис. 12.3. Блок-схема кодера CELP
В алгоритме VSELP используется не одна большая стохастическая кодовая книга, а две, меньшего размера (128 векторов в каждой). Для эффективности кодирования эти две книги также образуются с помощью нескольких базовых векторов (базиса книги). Базовые вектора взаимно ортогональны друг другу, что обеспечивает и ортогональность самих книг кодовых книг между собой. Структура кодовой книги алгоритма ACELP (с речевой скоростью 7,4 кбит/c) следующая: существует 4 базовых вектора. Различной линейной комбинацией этих векторов и образуются все вектора кодовой книги. Такая жесткая структуризация книги позволяет резко снизить требуемые вычислительные затраты на поиск в ней оптимального вектора.
Кодовые книги бывают детерминированными и стохастическими. Детерминированные книги образуется посредством процесса “обучения”, т.е. заполнения книги векторами, полученными из реальных речевых сигналов. Обучение проводится на достаточно большой длительности (30..40 мин) для нескольких дикторов, на мужских и женских голосах. В отличие от детерминированных, стохастические книги не требуют обучения. Они заполняются случайными гауссовскими последовательностями (отрезками белого шума с нулевым средним и единичной дисперсией). Основанием для использования такой книги в качестве возбуждающей является то, что в системах с линейным предсказанием с двумя предсказателями (кратковременным и долговременным) в сигнале остатка на выходе этих предсказателей практически устранены все корреляционные связи, он имеет случайный характер.