13.1.2. Источники волновых сигналов
13.2.2. Равномерное квантование
13.2.4. Добавление псевдослучайного шума
13.2.5. Неравномерное квантование
13.3. Дифференциальная импульсно-кодовая модуляция
13.3.1. Одноотводное предсказание
13.3.2. N-отводное предсказание
13.3.4. Сигма-дельта-модуляция
13.4.2. Синтетическое/аналитическое кодирование
13.6. Преобразующее кодирование
13.7. Кодирование источника для цифровых данных
13.8. Примеры кодирования источника
13.1. Источники
Кодирование источника связано с задачей создания эффективного описания исходной информации. Эффективное описание допускает снижение требований к памяти или полосе частот, связанных с хранением или передачей дискретных реализаций исходных данных. Для дискретных источников способность к созданию описаний данных со сниженной скоростью передачи зависит от информационного содержимого и статистической корреляции исходных символов. Для аналоговых источников способность к созданию описаний данных со сниженной скоростью передачи (согласно принятому критерию точности) зависит от распределения амплитуд и временной корреляции волнового сигнала источника. Целью кодирования источника является получение описания исходной информации с хорошей точностью при данной номинальной скорости передачи битов или допуск низкой скорости передачи битов, чтобы получить описание источника с заданной точностью. Чтобы понять, где эффективны методы и средства кодирования источника, важно иметь общие меры исходных параметров. По этой причине в данном разделе изучаются простые модели дискретных и аналоговых источников, а затем дается описание того, как кодирование источника может быть применено к этим моделям.
13.1.1. Дискретные источники
Дискретные источники генерируют (или выдают) последовательность символов Х(k), выбранную из исходного алфавита в дискретные промежутки времени kT, где k=1, 2, ... — счетные индексы. Если алфавит содержит конечное число символов, скажем N, говорят, что источник является конечным дискретным (finite discrete source). Примером такого источника является выход 12-битового цифро-аналогового преобразователя (один из 4096 дискретных уровней) или выход 10-битового аналого-цифрового преобразователя (один из 1024 двоичных 10-кортежей). Еще одним примером дискретного источника может послужить последовательность 8-битовых ASCII-символов, введенных с клавиатуры компьютера.
Конечный дискретный источник определяется последовательностью символов (иногда называемых алфавитом) и вероятностью, присвоенной этим символам (или буквам). Будем предполагать, что источник кратковременно стационарный, т.е. присвоенные вероятности являются фиксированными в течение периода наблюдения. Пример, в котором алфавит фиксирован, а присвоенные вероятности изменяются, — это последовательность символов, генерируемая клавиатурой, когда кто-то печатает английский текст, за которым следует печать испанского и наконец французского текстов.
Если известно, что вероятность каждого символа Xj есть Р(Хj), можно определить самоинформацию (self-information) I(Xj) для каждого символа алфавита.
![]() (13.1)
(13.1)
Средней самоинформацией для символов алфавита, называемой также энтропией источника (source entropy), является следующее.
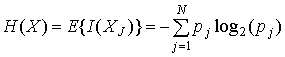 (13.2)
(13.2)
где Е{Х} — математическое ожидание X. Энтропия источника определяется как среднее количество информации на выход источника. Энтропия источника — это средний объем неопределенности, которая может быть разрешена с использованием алфавита. Таким образом, это среднее количество информации, которое должно быть отправлено через канал связи для разрешения этой неопределенности. Можно показать, что это количество информации в битах на символ ограничено снизу нулем, если не существует неопределенности, и сверху log2(N), если неопределенность максимальна.
![]() (13.3)
(13.3)
Пример 13.1. Энтропия двоичного источника
Рассмотрим двоичный источник, который генерирует независимые символы 0 и 1 с вероятностями р и (1 —р). Этот источник описан в разделе 7.4.2, а его функция энтропии представлена на рис. 7.5. Если р = 0,1 и (1 — р) = 0,9, энтропия источника равна следующему.
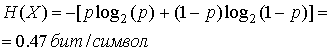 (13.4)
(13.4)
Таким образом, этот источник может быть описан (при использовании соответствующего кодирования) с помощью менее половины бита на символ, а не одного бита на символ, как в текущей форме.
Отметим, что первая причина, по которой кодирование источника работает, — это то, что информационное содержание N-символьного алфавита, используемое в действительных системах связи, обычно меньше верхнего предела соотношения (13.3). Известно, что, как отмечено в примере 7.1, символы английского текста не являются равновероятными. Например, высокая вероятность конкретных букв в тексте используется как часть стратегии игры Хенгмана (Hangman). (В этой игре игрок должен угадывать буквы, но не их позиции в скрытом слове известной длины. За неверные предположения назначаются штрафы, а буквы всего слова должны быть определены до того, как произойдет шесть неверных предположений.)
Дискретный источник называется источником без памяти (memoryless), если символы, генерируемые источником, являются статистически независимыми. В частности, это означает, что их совместная вероятность двух символов является просто произведением вероятностей соответствующих символов.
![]() (13.5)
(13.5)
Следствием статистической независимости есть то, что информация, требуемая для передачи последовательности М символов (называемой M-кортежем) данного алфавита, точно в М раз превышает среднюю информацию, необходимую для передачи отдельного символа. Это объясняется тем, что вероятность статистически независимого М-кортежа задается следующим образом.
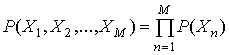 (13.6)
(13.6)
Поэтому средняя на символ энтропия статистически независимого М-кортежа равна следующему.
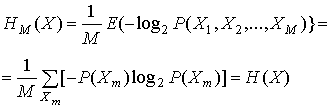 (13.7)
(13.7)
Говорят, что дискретный источник имеет память, если элементы источника, образующие последовательность, не являются независимыми. Зависимость символов означает, что для последовательности M символов неопределенность относительно M-го символа уменьшается, если известны предыдущие (М-1) символов. Например, большая ли неопределенность существует для следующего символа последовательности CALIFORNI_? M-кортеж с зависимыми символами содержит меньше информации или разрешает меньше неопределенности, чем кортеж с независимыми символами. Энтропией источника с памятью является следующий предел.
![]() (13-8)
(13-8)
Видим, что энтропия М-кортежа из источника с памятью всегда меньше, чем энтропия источника с тем же алфавитом и вероятностью символов, но без памяти.
![]() (13.9)
(13.9)
Например, известно, что при данном символе (или букве) "q" в английском тексте следующим символом, вероятно, будет "u". Следовательно, в контексте системы связи, если сказать, что буква "u" следует за буквой "q", то это дает незначительную дополнительную информацию о значении слова, которое было передано. Можно привести и другой пример. Наиболее вероятным символом, следующим за буквами "th", может быть один из таких символов: а, е, i, о, u, r и пробел. Таким образом, дополнение следующим символом данного множества разрешает некоторую неопределенность, но не очень сильно. Формальная формулировка сказанного выше: средняя энтропия на символ М-кортежа из источника с памятью убывает при увеличении длины М. Следствие: более эффективным является групповое кодирование символов из источника с памятью, а не кодирование их по одному. При кодировании источника размер последовательности символов, рассматриваемой как группа, ограничивается сложностью кодера, ограничениями памяти и допустимой задержкой времени.
Чтобы помочь понять цели, преследуемые при кодировании источников с памятью, построим простые модели этих источников. Одна из таких моделей называется Марковским источником первого порядка (first-order Markov source) [1]. Эта модель устанавливает соответствие между множеством состояний (или символов в контексте теории информации) и условными вероятностями перехода к каждому последующему состоянию. В модели первого порядка переходные вероятности зависят только от настоящего состояния. Иными словами, P(Xi+1|Xi, Xi-1, ...) = P(Xi+1|Xi). Память модели не распространяется дальше настоящего состояния. В контексте двоичной последовательности это выражение описывает вероятность следующего бита при данном значении текущего бита.
Пример 13.2. Энтропия двоичного источника с памятью
Рассмотрим двоичный (т.е. двухсимвольный) Марковский источник второго порядка, описанный диаграммой состояний, изображенной на рис. 13.1. Источник определен вероятностями переходов состояний Р(0|1) и P(l|0), равными 0,45 и 0,05. Энтропия источника X — это взвешенная сумма условных энтропии, соответствующих вероятностям переходов модели.
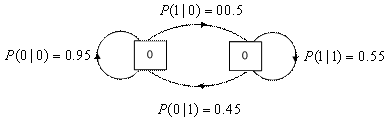
Рис. 13.1. Диаграмма переходов от состояния к состоянию для Марковской модели первого порядка
![]() (13.10)
(13.10)
где
![]()
и
![]()
Априорная вероятность каждого состояния находится с помощью формулы полной вероятности.
![]()
![]()
![]()
Вычисляя априорные вероятности с использованием переходных вероятностей, получим следующее.
![]()
При вычислении энтропии источника с использованием равенства (13.10) получим следующее.
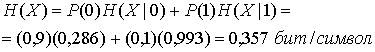
Сравнивая этот результат с результатом примера 13.1, видим, что источник с памятью имеет энтропию ниже, чем источник без памяти, даже несмотря на то что априорные вероятности символов те же.
Пример 13.3. Коды расширения
Алфавит двоичного Марковского источника (пример 13.2) состоит из 0 и 1, появляющихся с вероятностями 0,9 и 0,1, соответственно. Последовательные символы не являются независимыми, и для использования преимуществ этой зависимости можно определить новое множество кодовых символов — двоичные 2-кортежи (коды расширения).
Двоичные 2-кортежи Символ расширения Вероятность символа расширения
|
Двоичные 2-кортежи |
Символ расширения |
Вероятность символа расширения |
|
00 |
a |
Р(а) = Р(0|0)Р(0) = (0,95)(0,9) = 0,855 11 |
|
11 |
b |
Р(b) = Р(1| 1 )Р( 1) = (0,55)(0,1 ) = 0,055 |
|
01 |
c |
Р(с) = Р(0| 1 )Р( 1) = (0,45)(0,1 ) = 0,045 |
|
11 |
d |
Р(с) = Р(1| 0 )Р( 0) = (0,05)(0,9 ) = 0,045 |
Здесь крайняя правая цифра 2-кортежа является самой ранней. Энтропия для этого алфавита кодов расширения находится посредством обобщения равенства (13.10).
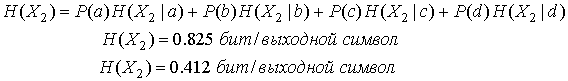
где Xk — расширение k-гo порядка источника X. Более длинный код расширения, использующий преимущества зависимости соседствующих символов, имеет следующий вид.
Двоичный 3-кортеж Символ расширения Вероятность символа расширения
|
Двоичные 2-кортежи |
Символ расширения |
Вероятность символа расширения |
|
000 |
a |
Р(а) = Р(0|00)P(00) = (0,95)(0,855) = 0,8123 |
|
100 |
b |
P(b) = P(1|00)P(00) = (0,05)(0,855) =0,0428 |
|
001 |
c |
P(с) = P(0|01)P(01) = (0,95)(0,045) = 0,0428 |
|
111 |
d |
P(d) = P(1|11)P(11) = (0,55)(0,055) =0,0303 |
|
110 |
e |
P(e) = P(1|10)P(10) = (0,55)(0,045) = 0,0248 |
|
011 |
f |
P(f) = P(0|11)P(1 1) = (0,45)(0,055) =0,0248 |
|
010 |
g |
P(g) = P(0|10)P(10) = (0,45)(0,045) = 0,0203 |
|
101 |
h |
P(h) = P(1|01)P(01) = (0,05)(0,045) = 0,0023 |
Используя снова обобщение уравнения (13.10), энтропию для этого кода расширения можно найти как
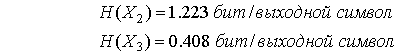
Отметим, что энтропия односимвольного, двухсимвольного и трехсимвольного описаний источника (0,470, 0,412 и 0,408 бит, соответственно) асимптотически убывает к энтропии источника, равной 0,357 бит/входной символ. Напомним, что энтропия источника — это нижний предел в битах на входной символ для этого алфавита (память бесконечна), и этот предел не может быть достигнут с помощью кодирования конечной длины.
13.1.2. Источники волновых сигналов
Источник волнового сигнала — это случайный процесс некоторой случайной переменной. Считается, что эта случайная переменная — время, так что рассматриваемый волновой сигнал — это изменяющийся во времени волновой сигнал. Важными примерами изменяющихся во времени волновых сигналов являются выходы датчиков, используемых для контроля процессов и описывающих такие физические величины, как температура, давление, скорость и сила ветра. Значительный интерес представляют такие примеры, как речь и музыка. Волновой сигнал может также быть функцией одной или более пространственных величин (т.е. расположение на плоскости с координатами х и у). Важными примерами пространственных волновых сигналов являются единичные зрительные образы, такие как фотография, или движущиеся зрительные образы, такие как последовательные кадры художественного фильма (24 кадра/с). Пространственные волновые сигналы часто преобразуются в изменяющиеся во времени волновые сигналы посредством сканирования. Например, это делается для систем факсимильной связи и передач в формате JPEG, а также для стандартных телевизионных передач.
13.1.2.1. Функции плотности амплитуд
Дискретные источники описываются путем перечисления их возможных элементов (называемых буквами алфавита) и с помощью их многомерных функций плотности вероятности (probability density function — pdf) всех порядков. По аналогии источники волновых сигналов подобным образом описываются в терминах их функций плотности вероятности, а также параметрами и функциями, определенными с помощью этих функций плотности вероятности. Многие волновые сигналы моделируются как случайные процессы с классическими функциями плотности вероятности и простыми корреляционными свойствами. В процессе моделирования различаются краткосрочные, или локальные (временные), характеристики и долгосрочные, или глобальные. Это деление необходимо, так как многие волновые сигналы являются нестационарными.
Функция плотности вероятности реального процесса может быть не известна разработчику системы. Конечно, в реальном времени для короткого предшествующего интервала можно быстро построить выборочные плотности и использовать их как разумные оценки в течение последующего интервала. Менее претенциозная задача — это создание краткосрочных средних параметров, связанных с волновыми сигналами. Эти параметры — выборочное среднее (или среднее по времени), выборочная дисперсия (или среднеквадратическое значение процесса с нулевым средним) и выборочные коэффициенты корреляции, построенные на предшествующем выборочном интервале. При анализе волновых сигналов входной волновой сигнал преобразуется в процесс с нулевым средним путем вычитания его среднего значения. Например, это происходит в устройствах сравнения сигналов, используемых в аналого-цифровых преобразователях, для которых вспомогательная схема измеряет внутренние смещения от уровня постоянного напряжения канала передачи данных и вычитает их в процессе, известном как автонуль (autozero). Далее оценка дисперсии часто используется для масштабирования входного волнового сигнала, чтобы сопоставить динамику размаха амплитуды последующего волнового сигнала, обусловленную схемой. Этот процесс, выполняемый при сборе данных, называется автоматической регулировкой усиления (automatic gain control — AGC, АРУ). Функцией этих операций, связанных с предварительным формированием сигналов, — вычитание среднего, контроль дисперсии или выравнивание усиления (показанных на рис. 13.2) — является нормирование функций плотности вероятности входного волнового сигнала. Это нормирование обеспечивает оптимальное использование ограниченного динамического диапазона последующих записывающих, передающих или обрабатывающих подсистем.
Многие источники волновых сигналов демонстрируют значительную корреляцию амплитуды на последовательных временных интервалах. Эта корреляция означает, что уровни сигнала на последовательных временных интервалах не являются независимыми. Если временные сигналы независимы на последовательных интервалах, автокорреляционная функция будет импульсной. Многие сигналы, представляющие инженерный интерес, имеют корреляционные функции конечной ширины. Эффективная ширина корреляционной функции (в секундах) называется временем корреляции процесса и подобна временной константе фильтра нижних частот. Этот временной интервал является показателем того, насколько большой сдвиг вдоль оси времени требуется для потери корреляции между данными. Если время корреляции большое, то это значит, что амплитуда волнового сигнала меняется медленно. Наоборот, если время корреляции мало, делаем вывод, что амплитуда волнового сигнала значительно меняется за очень малый промежуток времени.
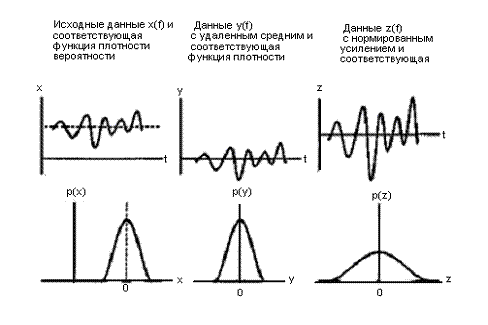

Рис. 13.2. Удаление среднего и нормирование дисперсии (регулировка усиления) для зависимых от данных систем предварительного формирования сигнала
13.2. Квантование амплитуды
Квантование амплитуды — это задача отображения выборок волновых сигналов непрерывной амплитуды в конечное множество амплитуд. Аппаратное обеспечение, которое выполняет отображение, — это аналогоцифровой преобразователь (analog-to-digital converter — ADC, АЦП). Квантование амплитуды происходит после операции выборки-запоминания. Простейшее устройство квантования, которое можно изобразить, выполняет мгновенное отображение с каждого непрерывного входного выборочного уровня в один из предопределенных, равномерно расположенных выходных уровней. Квантующие устройства, которые характеризуются равномерно расположенными приращениями между возможными выходными уровнями, называются равномерными устройствами квантования, или линейными квантующими устройствами. Возможные мгновенные характеристики входа/выхода легко изображаются с помощью простого ступенчатого графика, подобного изображенному на рис. 13.3. На рис. 13.3, а, б и г представлены устройства с равномерными шагами квантования, а на рис. 13.3, в — устройство с неравномерным шагом квантования. На рис. 13.3, а характеристика устройства имеет нуль в центре шага квантования, а на рис. 13.3, б и г — на границе шага квантования. Отличительная особенность устройств, имеющих характеристики с нулем в центре шага квантования и характеристики с нулем на границе шага квантования, связана, соответственно, с наличием или отсутствием выходных изменений уровня, если входом квантующего устройства является шум низкого уровня. На рис. 13.3, г представлено смещенное (т.е. усекающее) устройство квантования, а другие устройства, изображенные на рисунке, являются несмещенными и называются округляющими. Такие несмещенные устройства квантования представляют собой идеальные модели, но в аналого-цифровых преобразователях округление не реализуется никогда. Как правило, устройства квантования реализуются как усекающие преобразователи. Термины "характеристика с нулем в центре шага квантования" (midtread) или "характеристика с нулем на границе шага квантования" (midriser) относятся к ступенчатым функциям и используются для описания того, имеются ли в начале координат горизонтальная или вертикальная составляющая ступенчатой функции. Пунктирная линия единичного наклона, проходящая через начало координат, представляет собой неквантованную характеристику входа/выхода, которую пытаются аппроксимировать ступенчатой функцией. Разность между ступенчатой функцией и отрезком линии единичного наклона представляет собой ошибку аппроксимации, допускаемую устройством квантования на каждом входном уровне. На рис. 13.4 показана ошибка аппроксимации амплитуды в сравнении с входной амплитудой функции для каждой из характеристик квантующего устройства, изображенных на рис. 13.3. Рис. 13.4 соответствует рис. 13.3. Часто эта ошибка моделируется как шум квантования, поскольку последовательность ошибок, полученная при преобразовании широкополосного случайного процесса, напоминает аддитивную последовательность шума. Однако, в отличие от действительно аддитивных источников шума, ошибки преобразования являются сигнально зависимыми и высоко структурированными. Желательно было бы нарушить эту структуру, что можно сделать путем введения независимых шумовых преобразований, известных как псевдослучайный шум, предшествующих шагу преобразования. (Эта тема обсуждается в разделе 13.2.4.)
Линейное устройство квантования легко реализовать и очень легко понять. Оно представляет собой универсальную форму квантующего устройства, поскольку не предполагает никаких знаний о статистике амплитуд и корреляционных свойствах входного волнового сигнала, а также не использует преимуществ требований к точности, предоставляемых пользователями. Устройства квантования, которые используют указанные преимущества, являются более эффективными как кодеры источника и предназначены для более специфических задач, чем общие линейные устройства квантования. Эти квантующие устройства являются более сложными и более дорогими, но они оправдывают себя с точки зрения улучшения производительности системы. Существуют приложения, для которых равномерные устройства квантования являются наиболее желаемыми преобразователями амплитуды. Это — приложения обработки сигналов, графические приложения, приложения отображения изображений и контроля процессов. Для некоторых иных приложений более приемлемыми преобразователями амплитуды являются неравномерные адаптивные квантующие устройства. Эти устройства включают в себя кодеры волнового сигнала для эффективного запоминания и эффективной связи, контурные кодеры для изображений, векторные кодеры для речи и аналитические/синтетические кодеры (такие, как вокодер) для речи.
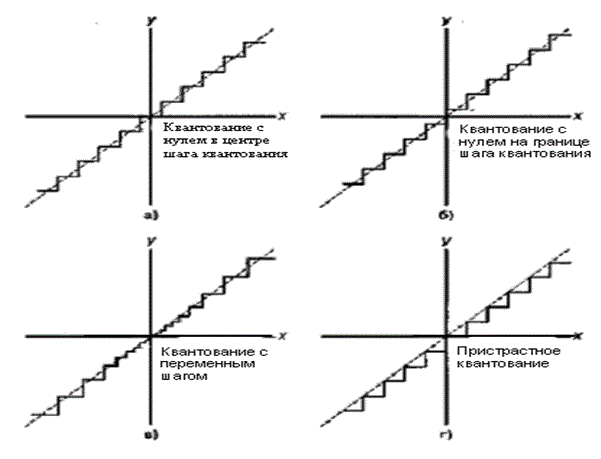 Рис. 13.3. Различные передаточные функции устройства квантования
Рис. 13.3. Различные передаточные функции устройства квантования
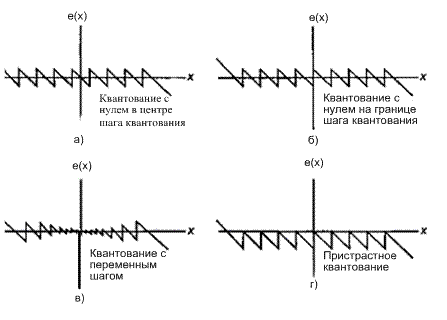
Рис. 13.4. Мгновенная ошибка для различных передаточных функций устройства квантования
13.2.1. Шум квантования
Разность между входом и выходом преобразователя называется ошибкой квантования (quantizing error). На рис. 13.5 изображен процесс отображения входной последовательности x(t) в квантованную выходную последовательность x(t). Получение x(t) можно представить как сложение каждого x(t) с ошибочной последовательностью e(i).
![]()
Ошибочная последовательность e(t) детерминированно определяется входной амплитудой через зависимость мгновенной ошибки от амплитудной характеристики, изображенной на рис. 13.4. Отметим, что ошибочная последовательность демонстрирует две различные характеристики в различных входных рабочих областях.
Первым рабочим интервалом является гранулированная область ошибок, соответствующая подаче на вход пилообразной характеристики ошибки. Внутри этого интервала квантующие устройства ограничены размерами соседних ступенчатых подъемов. Ошибки, которые случаются в этой области, называются гранулированными (granular errors), или иногда ошибками квантования (quantizing error). Входной интервал, для которого ошибки преобразования являются гранулированными, определяет динамическую область преобразователя. Этот интервал иногда называется областью линейного режима (region of linear operation). Соответствующее использование квантующего устройства требует, чтобы условия, порожденные входным сигналом, приводили динамическую область входного сигнала в соответствие с динамической областью устройства квантования. Этот процесс является функцией сигнально зависимой системы регулировки усиления, называемой автоматической регулировкой усиления (automatic gain control — AGC, АРУ), которая показана на пути прохождения сигнала на рис. 13.5.
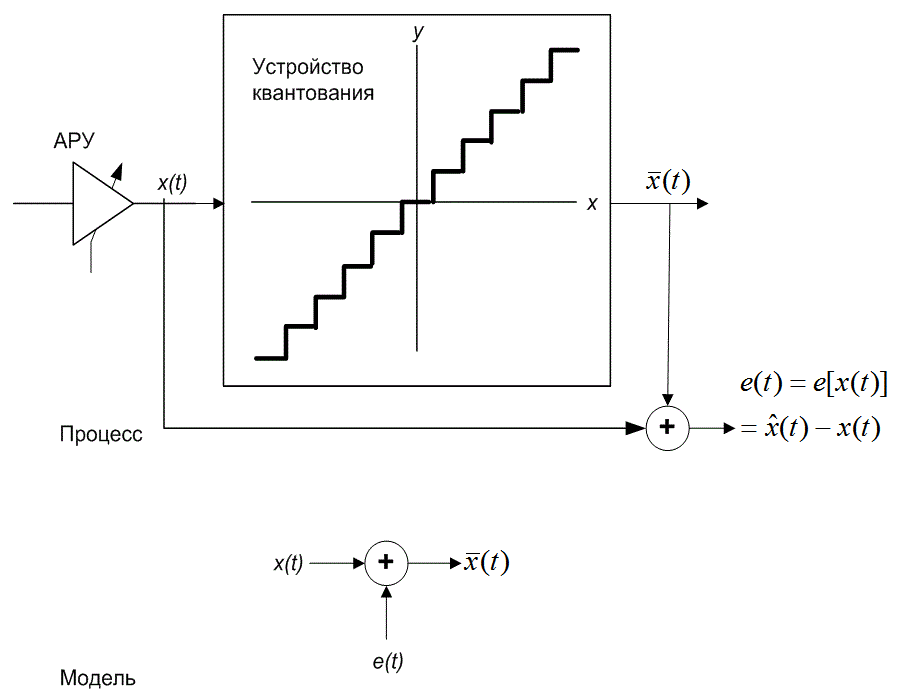
Рис. 13.5. Процесс и модель повреждения входного сигнала шумом квантования
Вторым рабочим интервалом является негранулированная область ошибок, соответствующая линейно возрастающей (или убывающей) характеристике ошибки. Ошибки, которые происходят в этом интервале, называются ошибками насыщения (saturation error) или перегрузки (overload error). Когда квантующее устройство работает в этой области, говорят, что преобразователь насыщен. Ошибки насыщения больше, чем гранулированные ошибки, и могут оказывать большее нежелательное влияние на точность воспроизведения информации.
Ошибка квантования, соответствующая каждому значению входной амплитуды, представляет слагаемое ошибки или шума, связанное с данной входной амплитудой. Если интервал квантования мал в сравнении с динамической областью входного сигнала и входной сигнал имеет гладкую функцию плотности вероятности в интервале квантования, можно предположить, что ошибки квантования равномерно распределены в этом интервале, как изображено на рис. 13.6. Функция плотности вероятности с нулевым средним соответствует округляющему квантующему устройству, в то время как функция плотности вероятности со средним -q/2 соответствует усекающему квантующему устройству.
Квантующее устройство, или аналого-цифровой преобразователь (analog-to-digital converter — ADC, АЦП), определяется числом, размером и расположением своих уровней квантования (или границами шагов и соответствующими размерами шагов). В равномерном квантующем устройстве размеры шагов равны и расположены на одинаковом расстоянии. Число уровней N обычно является степенью 2 вида N = 2b, где b — число бит, используемых в процессе преобразования.
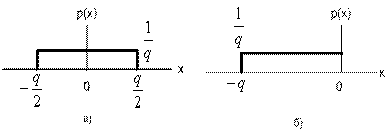
Рис. 13.6. Функции плотности вероятности для ошибки квантования, равномерно распределенной в интервале квантили, q: а) функция плотности вероятности для округляющего преобразователя; б) функция плотности вероятности для усекающего преобразователя
Это число уровней равномерно распределено в динамической области возможных входных уровней. Обычно этот интервал определяется как +Emax, подобно ±1,0 В или ±5,0 В. Таким образом, для полного интервала 2Emax величину шага преобразования получим в следующем виде.
![]() (13.11)
(13.11)
В качестве примера использования равенства (13.11) шаг квантования (в дальнейшем называемый квантилъю) для 10-битового преобразователя, работающего в области ±1,0V, равен 1,953 мВ. Иногда рабочая область преобразователя изменяется так, что квантиль является "целым" числом. Например, изменение рабочей области преобразователя до ±1,024 В приводит к шагу квантования, равному 2,0 мВ. Полезным параметром равномерного квантующего устройства является его выходная дисперсия. Если предположить, что ошибка квантования равномерно распределена в отдельном интервале ширины q, дисперсия квантующего устройства (которая представляет собой шум квантующего устройства или мощность ошибки) для ошибки с нулевым средним находится следующим образом.
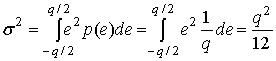 (13.12)
(13.12)
где р(е) = l/q в интервале q — это функция плотности вероятности (probability density function — pdf) ошибки квантования е. Таким образом, среднеквадратическое значение шума квантования в интервале квантили ширины q равно ![]() или 0,29q. Уравнение (13.12) определяет мощность шума квантования в интервале размером в одну квантиль в предположении, что ошибки равновероятны в пределах интервала квантования. Если включить в рассмотрение работу в интервале насыщения квантующего устройства или рассмотреть неравномерные устройства квантования, то получим, что интервалы квантования не имеют равной ширины внутри области изменения входной переменной и плотность амплитуды не является равномерной внутри интервала квантования. Можно вычислить эту зависящую от амплитуды энергию ошибки
или 0,29q. Уравнение (13.12) определяет мощность шума квантования в интервале размером в одну квантиль в предположении, что ошибки равновероятны в пределах интервала квантования. Если включить в рассмотрение работу в интервале насыщения квантующего устройства или рассмотреть неравномерные устройства квантования, то получим, что интервалы квантования не имеют равной ширины внутри области изменения входной переменной и плотность амплитуды не является равномерной внутри интервала квантования. Можно вычислить эту зависящую от амплитуды энергию ошибки ![]() усредняя квадраты ошибок по амплитуде переменной, взвешенной вероятностью этой амплитуды. Это можно выразить следующим образом.
усредняя квадраты ошибок по амплитуде переменной, взвешенной вероятностью этой амплитуды. Это можно выразить следующим образом.
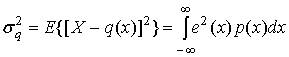 (13.13)
(13.13)
где х — входная переменная, q(x) — ее квантованная версия, е(х) = х - q(x) — ошибка, а р(х) — функция плотности вероятности амплитуды х. Интервал интегрирования в формуле (13.13) можно разделить на два основных интервала: один отвечает за ошибки в ступенчатой или линейной области квантующего устройства, а второй — за ошибки в области насыщения. Определим амплитуду насыщения квантующего устройства как Emaх. Предположим также, что передаточная функция квантующего устройства есть четно-симметричной и такой же является функция плотности вероятности для входного сигнала. Мощность ошибки ![]() , определенная равенством (13.13), является полной мощностью ошибки, которая может быть разделена следующим образом.
, определенная равенством (13.13), является полной мощностью ошибки, которая может быть разделена следующим образом.
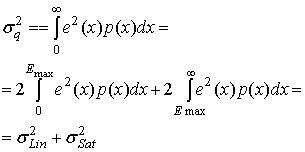
(13.14,а)
(13.14,6)
Здесь ![]() — мощность ошибки в линейной области, a
— мощность ошибки в линейной области, a ![]() — мощность ошибки в области насыщения. Мощность ошибки
— мощность ошибки в области насыщения. Мощность ошибки ![]() может быть далее разделена на подынтервалы, соответствующие последовательным дискретным входным уровням квантующего устройства (т.е. квантилям). Если предположить, что существует N таких уровней квантили, интеграл превращается в следующую сумму.
может быть далее разделена на подынтервалы, соответствующие последовательным дискретным входным уровням квантующего устройства (т.е. квантилям). Если предположить, что существует N таких уровней квантили, интеграл превращается в следующую сумму.
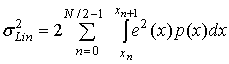 (13.15)
(13.15)
где хn — уровень квантующего устройства, а интервал или шаг между двумя такими уровнями называется интервалом квантили (quantile interval). Напомним, что N, как правило, является степенью 2. Таким образом, существует N/2 — 1 положительных уровней, N/2 - 1 отрицательных уровней и нулевой уровень — всего N - 1 уровень и N -2 интервала. Теперь, если аппроксимировать плотность на каждом интервале квантили константами qn= (xn+1 - хn), выражение (13.15) упростится до следующего вида.
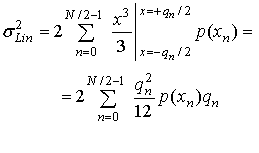 (13.16)
(13.16)
где е(х) в равенстве (13.15) было заменено х из (13.16), поскольку е(х) — линейная функция от х, имеющая единичный наклон и проходящая через нуль в центре каждого интервала. Кроме того, пределы интегрирования в равенстве (13.15) были заменены в соответствии с изменениями х внутри интервала квантили. Поскольку область изменения была обозначена через qn, нижний и верхний пределы могут быть обозначены как х= -qn/2 и х= +qn/2. Равенство (13.16) описывает мощность ошибки в линейной области в виде суммы мощности ошибки q![]() /12 в каждом интервале квантили, взвешенной вероятностью p(xn)qn этой энергии ошибки.
/12 в каждом интервале квантили, взвешенной вероятностью p(xn)qn этой энергии ошибки.
13.2.2. Равномерное квантование
Если устройство квантования имеет равномерно расположенные квантили, равные q, и все интервалы равновероятны, выражение (13.16) упрощается далее.
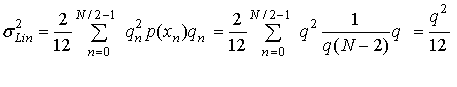 (13.17)
(13.17)
Если квантующее устройство работает не в области насыщения (мощности шума квантования), тогда ![]() и эти величины часто используются как взаимозаменяемые. Отметим, что мощность шума сама по себе не будет полно описывать поведение шума устройства квантования. Более полной мерой качества является отношение второго центрального момента (дисперсии) шума квантования к входному сигналу. Если предположить, что входной сигнал имеет нулевое среднее, дисперсия сигнала равна следующему.
и эти величины часто используются как взаимозаменяемые. Отметим, что мощность шума сама по себе не будет полно описывать поведение шума устройства квантования. Более полной мерой качества является отношение второго центрального момента (дисперсии) шума квантования к входному сигналу. Если предположить, что входной сигнал имеет нулевое среднее, дисперсия сигнала равна следующему.
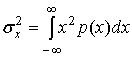 (13.18)
(13.18)
Дальнейшее изучение среднего шума квантующего устройства требует конкретизации функции плотности и устройства.
Пример 13.4. Равномерное квантующее устройство
Определим дисперсию устройства квантования и отношение мощности шума к мощности сигнала (noise-to-signal power ratio — NSR) для равномерно распределенного в полной динамической области сигнала, созданного устройством квантования с 2b расположенными на одинаковых расстояниях уровнями квантили. В этом случае шума насыщения не существует и должна быть вычислена только величина линейного шума. Каждый интервал квантили равен следующему.
![]()
Здесь 2Еmax — это входной интервал между положительной и отрицательной границами линейной области квантования.
Решение
Подставляя выражение (13.19) в формулу (13.12) или (13.17), получим следующую мощность шума квантования (в линейной области).
![]()
Мощность входного сигнала находится посредством интегрирования выражения (13.18) j равномерной плотности вероятности в интервале длины ![]() с центром в точке 0, так р(х) = l/(
с центром в точке 0, так р(х) = l/(![]() ), и дисперсия сигнала находится следующим образом.
), и дисперсия сигнала находится следующим образом.
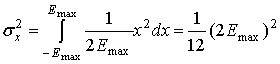
Рассматривая отношение мощности шума к мощности сигнала (NSR), получим следующё
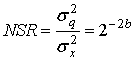
Теперь, превращая NSR в децибелы, получим следующее.
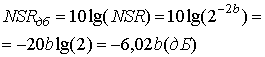
Выражение (13.23, б) свидетельствует о том, что за каждый бит, который используете процессе преобразования, мы платим -6,02 дБ отношения шума к сигналу. Действитель NSR для любого равномерного квантующего устройства, не работающего в области насьи ния, имеет следующий вид.
![]()
Здесь член С зависит от функции плотности вероятности сигнала (probability density fu tion — pdf); он положителен для функций плотности, являющихся узкими по отношени] уровню насыщения преобразователя.
13.2.2.1. Сигнал и шум квантования в частотной области
До настоящего момента шум квантования обсуждался с точки зрения его влиж на выборку временного ряда, представляющую дискретный сигнал. Шум квантования может быть также описан в частотной области; это позволяет взглянуть на влияние условий работы, что и будет сделано ниже. В процессе этого изучения предполагает также рассмотрение насыщения (раздел 13.2.3), возмущения (раздел 13.2.4) и квантующих устройств с обратной связью по шуму (раздел 13.2.6).
На рис. 13.7 представлено дискретное преобразование Фурье двух синусоид, которые были образованы линейным 10-битовым АЦП. Сравнительные амплитуды данных синусоид равны 1,0 и 0,01 (т.е. одна на 40 дБ ниже другой). На рис. 13.7, а сигнал низкой частоты (обозначенный 0 дБ) масштабируется на 1 дБ ниже полной динамической области 10-битового квантующего устройства, которую для удобства будем считать единичной. Отметим, что на рис. 13.7, а полномасштабный сигнал 0 дБ находится на 6 дБ ниже входного уровня поглощения 1 дБ. Это объясняется наличием множителя 1/2 в спектральном разложении действительного сигнала по всем ненулевым частотам. Среднее отношение сигнала к шуму квантования (SNR) для 10-битового квантующего устройства равно 60 + С дБ. Для полномасштабной синусоиды константа С равна 1,76 дБ, что делает суммарное отношение SNR примерно равным 62 дБ. При дискретном преобразовании Фурье (discrete Fourier transform — DFT, ДПФ), которое выполнялось для получения графика на рис. 13.7, длина равнялась 256. Поскольку отношение SNR преобразования увеличивается пропорционально длине преобразования (или времени интегрирования), то благодаря преобразованию SNR улучшается на 24 дБ [2] с потерей 3,0 дБ вследствие усечения. Таким образом, на выходе преобразования вершина SNR вследствие квантования равна 62 + 24 - 3 = 83 дБ. Шумовой сигнал на каждой частоте ДПФ может быть представлен как квадратный корень из суммы квадратов гауссовых случайных величин, которая описывается как случайная величина, имеющая распределение хи-квадрат с двумя степенями свободы. Дисперсия (мощность шума) равна квадрату среднего. Таким образом, имеем значительные колебания вокруг математического ожидания уровня мощности шума. Для получения устойчивой оценки нижнего уровня шума нам потребуется среднее по ансамблю. Видно, что нижний уровень шума (получен с помощью 400 средних) равен -83 дБ. К сигналу перед квантованием был добавлен псевдослучайный шум (описанный в разделе 13.2.4), чтобы рандомизировать ошибки квантования. На рис. 13.7, б и в входные сигналы ослабляются относительно полномасштабного входа на 20 и 40 дБ. Это ослабление увеличивает константу С в формуле (13.24) на 20 и 40 дБ, что проявляется как уменьшение спектральных уровней входных синусоид на эти же величины. Отметим, что входной сигнал наивысшей частоты (рис. 13.7, в), который теперь уменьшился на 80 дБ относительно полной шкалы, располагается на 3 дБ ниже среднего уровня шума преобразователя. Синусоида самой низкой частоты на рис. 13.7, в теперь ослаблена на 40 дБ относительно полной шкалы, поэтому характеризуется SNR на 40 дБ меньшим, чем для сигнала на рис. 13.7, а.
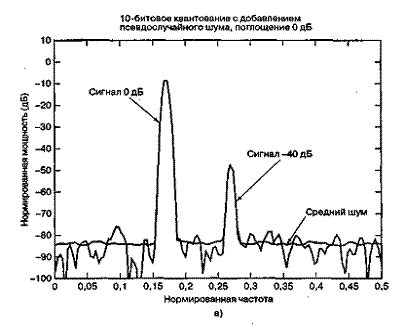
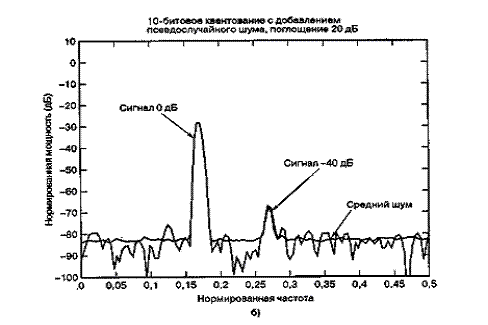
Рис. 13.7. Энергетический спектр сигналов, квантованных равномерным АЦП
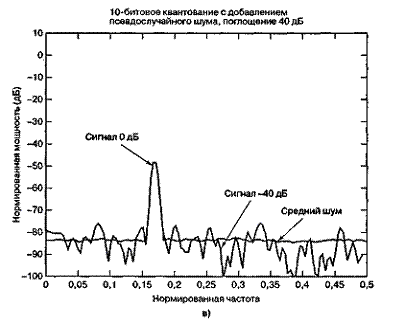
Рис. 13.7. Энергетический спектр сигналов, квантованных равномерным АЦП (прожолжение)
При минимизации среднего отношения шума к сигналу квантования мы сталкиваемся с противоречием в требованиях. С одной стороны, желательно удерживать сигналы большими по отношению к интервалу квантования q с целью получения большого SNR. С другой стороны, необходимо удерживать сигнал малым, чтобы избежать насыщения квантующего устройства. Противоречивые требования разрешаются путем масштабирования входного сигнала; в результате его среднеквадратическое значение представляет собой заданную долю полномасштабной области значений квантующего устройства. Указанная доля выбирается так, чтобы согласовать ошибки насыщения (взвешенные вероятностями их появления) с ошибками квантования (взвешиваются аналогично) и таким образом достигнуть минимального отношения шума к сигналу. Положение этой желательной рабочей точки преобразователя обсуждается в следующем разделе.
13.2.3. Насыщение
На рис. 13.8 представлено среднее NSR равномерного квантующего устройства как функция отношения уровня насыщения квантующего устройства к среднеквадратическому значению сигнала. На рисунке изображены отношения NSR сигналов с тремя различными функциями плотности вероятности: арксинус (синусообразная плотность сигнала), равномерная и гауссова.
По оси абсцисс (рис. 13.8) отложено отношение уровня насыщения квантующего устройства к среднеквадратическому уровню входного сигнала. При каждой из трех плотностей для фиксированного числа бит существует значение абсциссы, соответствующее минимуму NSR. Другими словами, для данной входной плотности можно определить уровень входного сигнала (связанный с насыщением), при котором достигается минимум NSR.
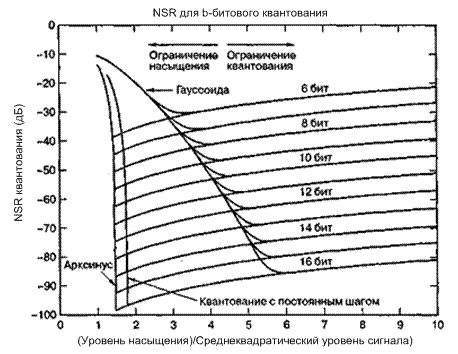
Рис. 13.8. Отношение NSR аналого-цифрового преобразователя в сравнении с отношением уровня насыщения АЦП к среднеквадратическому уровню сигнала
Уменьшенные уровни входных сигналов соответствуют большим значениям NSR на оси абсцисс и представляют собой движение вправо. Увеличенные уровни входных сигналов также соответствуют большим значениям NSR на оси абсцисс и представляют собой движение влево. Это увеличение происходит вследствие работы в области насыщения устройства квантования. Отметим, что скорость изменения отношения NSR при движении влево от оптимальной рабочей точки выше, чем при движении вправо. Например, это, в частности, верно для равномерной плотности и плотности типа арксинуса. Это свидетельствует о том, что шум насыщения более нежелателен, чем линейный шум квантования. Как следствие, если допустить ошибку в определении рабочей точки, называемой точкой атаки квантующего устройства, то будет лучше иметь ошибку на стороне превышения поглощения, чем на стороне недостаточного поглощения входного сигнала. Начало насыщения происходит в точках с различными значениями абсциссы. Для синусообразного сигнала (плотность типа
арксинуса) это происходит примерно в точке ![]() . Для треугольных сигналов (равномерная плотность) это случается примерно в точке
. Для треугольных сигналов (равномерная плотность) это случается примерно в точке ![]() . Для шумоподобных сигналов (гауссова плотность), когда уровень сигнала сокращается относительно насыщения, насыщение происходит непрерывно, с убывающей вероятностью. Рассмотрим в качестве примера 10-битовый АЦП, имеющий отношение NSR -60 дБ для равномерной плотности при работе на вершине насыщения и NSR -62 дБ для плотности типа арксинуса при работе на вершине насыщения. С другой стороны, тот же 10-битовый преобразователь имеет минимум NSR приблизительно в точке -52 дБ для всех плотностей, когда среднеквадратический уровень равен 1/4 уровня насыщения (точка 4 на оси абсцисс). Данный рисунок иллюстрирует, что шум насыщения более опасен, чем шум квантования. Этому можно дать достаточно простое объяснение, изучив мгновенную характеристику ошибки (как показано на рис. 13.4) и отметив, что ошибки насыщения очень велики в сравнении с ошибками квантования. Таким образом, малое насыщение, даже если оно случается нечасто, будет вносить большой вклад в средний уровень шума квантующего устройства.
. Для шумоподобных сигналов (гауссова плотность), когда уровень сигнала сокращается относительно насыщения, насыщение происходит непрерывно, с убывающей вероятностью. Рассмотрим в качестве примера 10-битовый АЦП, имеющий отношение NSR -60 дБ для равномерной плотности при работе на вершине насыщения и NSR -62 дБ для плотности типа арксинуса при работе на вершине насыщения. С другой стороны, тот же 10-битовый преобразователь имеет минимум NSR приблизительно в точке -52 дБ для всех плотностей, когда среднеквадратический уровень равен 1/4 уровня насыщения (точка 4 на оси абсцисс). Данный рисунок иллюстрирует, что шум насыщения более опасен, чем шум квантования. Этому можно дать достаточно простое объяснение, изучив мгновенную характеристику ошибки (как показано на рис. 13.4) и отметив, что ошибки насыщения очень велики в сравнении с ошибками квантования. Таким образом, малое насыщение, даже если оно случается нечасто, будет вносить большой вклад в средний уровень шума квантующего устройства.
Шум насыщения и шум квантования отличаются несколько по-иному. Шум квантования приближается к белому шуму. По этой причине к аналоговому сигналу до квантования могут намеренно добавляться сигналы псевдослучайного шума. Отметим, что шум насыщения подобен белому шуму только тогда, когда входной сигнал имеет широкую полосу частот и может быть гармонически связанным с входным сигналом, если тот имеет узкую полосу частот. Таким образом, влияние шума квантования может быть отфильтровано или усреднено, так как по характеристикам — это белый шум. С другой стороны, шум насыщения неотличим от содержимого полезного сигнала и в общем случае не может быть устранен с помощью последовательного усреднения или фильтрующих технологий.
На рис. 13.9 представлены дискретные преобразования Фурье того же сигнального множества, что и на рис. 13.8, квантованного 10-битовым АЦП. Кроме того, на рис. 13.9 пиковая амплитуда сигнала выбрана так, чтобы на 10% (0,83 дБ) превышать уровень насыщения АЦП. Отметим, что некоторые спектральные составляющие больше, чем сигнал в -40 дБ. Эти составляющие (шум насыщения) будут возрастать еще больше, когда отклонения сигнала будут идти глубже в режим насыщения. Чтобы увидеть существенную разницу во влиянии слишком слабого поглощения сигнала (следовательно, имеем насыщение) на выход шума АЦП, сравните этот рисунок с рис. 13.7.
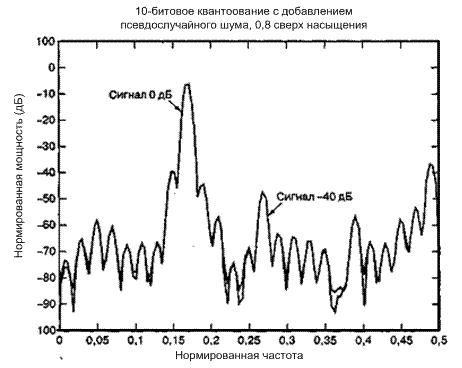
Рис. 13.9. Энергетический спектр равномерно квантованных сигналов с насыщением квантующего устройства на пиках сигнала в 0,8 дБ вне полномасштабного входного уровня
13.2.4. Добавление псевдослучайного шума
Добавление псевдослучайного шума представляет собой одно из самых разумных применений шума как полезного инженерного инструмента. Псевдослучайный шумовой сигнал — это небольшое возмущение или помеха, добавленные к измеряемому процессу, чтобы ограничить влияние малых локальных нелинейностей. Наиболее знакомой формой псевдослучайного шума является встряхивание компаса перед собственно его использованием. В данном случае имеем последовательность малых импульсов, применяемую для вывода движения стрелки из локальной области, которая имеет нелинейный коэффициент трения при малых скоростях. Более сложным примером того же эффекта является механическое псевдослучайное возмущение, применяемое к вращающимся лазерным лучам лазерного лучевого гироскопа с целью вывода гироскопа из ловушки низкоуровневой частоты, известной как мертвая полоса [3].
В случае аналого-цифрового преобразователя цель псевдослучайного шума — ограничить (или избежать) локальные разрывы (т.е. подъемы и ступени) мгновенной передаточной функции входа/выхода. Чтобы лучше представить себе влияние этих разрывов, можно перечислить ожидаемые свойства ошибочной последовательности, образованной процессом квантования, с последующим изучением действительных свойств той же последовательности. Ошибочная последовательность квантующего устройства моделируется как аддитивный шум. Давайте рассмотрим ожидаемые свойства такой последовательности шума.
1. Нулевое среднее Е{е(n)}=0
2. Белый шум Е{е(n) е(n+m)}=![]()
3. Отсутствие корреляции с данными х(n) Е{е(n) x(n+m)}= 0
В данном случае m и n— выборочные индексы, ![]() — дельта-функция Дирака. Изучение рис. 13.10, на котором представлена последовательность выборок, образованная усекающим АЦП, позволяет сделать следующие наблюдения.
— дельта-функция Дирака. Изучение рис. 13.10, на котором представлена последовательность выборок, образованная усекающим АЦП, позволяет сделать следующие наблюдения.
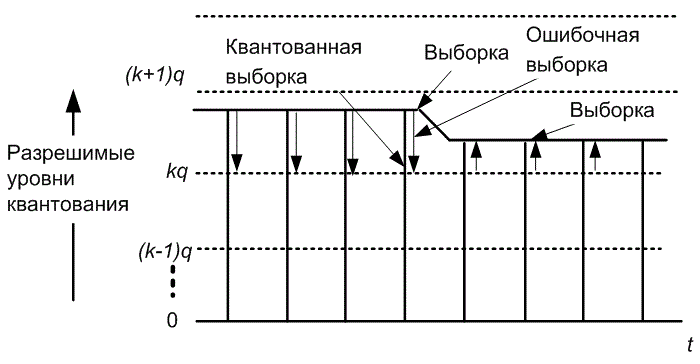
Рис. 13.10. Последовательность дискретных данных квантуется в ближайшие наименьшие уровни квантили посредством присвоенной ошибочной последовательности
1. Вся ошибочная последовательность имеет одну и ту же полярность; следовательно, ее среднее не равно нулю.
2. Последовательность не является независимой при переходе от выборки к выборке; следовательно, она не является белым шумом.
3. Последовательность ошибки коррелирует с входом; следовательно, она не является независимой.
Повторяющиеся измерения того же сигнала будут давать в результате тот же шум, и, таким образом, усреднение ни по какому числу измерений не уменьшит отклонение от истинного входного сигнала. Парадоксально, но мы хотели бы видеть этот шум "более шумным". Если шум является независимым на последовательных измерениях, усреднение будет сокращать отклонение от истинных значений. Таким образом, столкнувшись с проблемой, что получаемый шум не является тем шумом, который нам необходим, выбираем возможность изменить этот шум, добавляя к нему наш собственный. Измерения дополняются возмущением, чтобы превзойти нежелательный низкоуровневый шум устройства квантования. Дополненное возмущение в известном смысле преобразует плохой шум в хороший [4].
Пример 13.5. Линеаризация с помощью псевдослучайного шума
Предположим, рассматриваются квантующие устройства, которые могут измерять только целые величины и превращать входные данные в наименьшие ближайшие целые — процесс, называемый усечением. Сделано 10 измерений сигнала, скажем, амплитуды 3,7. При отсутствии добавочного сигнала все замеры равны 3,0. Теперь перед измерениями добавим к входной последовательности равномерно распределенную (на интервале от 0 до 1) случайную числовую последовательность. Последовательность данных имеет следующий вид.
|
Измерение |
Необработанный сигнал |
Квантованный необработанный сигнал |
Псевдослучайный шум |
Суммарный сигнал |
Квантованный суммарный сигнал |
|
1 |
3,7 |
3,0 |
0,3485 |
4,0485 |
4,0 |
|
2 |
3,7 |
3,0 |
0,8685 |
4,5685 |
4,0 |
|
3 |
3,7 |
3,0 |
0,2789 |
3,9789 |
4,0 |
|
4 |
3,7 |
3,0 |
0,3615 |
4,0615 |
4,0 |
|
5 |
3,7 |
3,0 |
0,1074 |
3,8074 |
3,0 |
|
6 |
3,7 |
3,0 |
0,2629 |
3,9629 |
3,0 |
|
7 |
3,7 |
3,0 |
0,9252 |
4,6252 |
4,0 |
|
8 |
3,7 |
3,0 |
0,5599 |
4,2599 |
4,0 |
|
9 |
3,7 |
3,0 |
0,3408 |
4,0408 |
4,0 |
|
10 |
3,7 |
3,0 |
0,5228 |
4,2228 |
4,0 |
|
Средние = |
3,0 |
0,4576 |
4,1576 |
3,7 |
|
|
Среднее псевдослучайнго шума |
0,4576 |
||||
|
Среднее суммарного сигнала -среднее псевдослучайного шума |
3,7 |
В этом примере для удаления смещения квантующего устройства был использован смещенный псевдослучайный шум. Среднее суммированных и преобразованных измерений (при наличии корректного измерения) в общем случае будет ближе к истинному сигналу, чем несуммированные с псевдослучайным шумом и преобразованные измерения [5, 6].
Чтобы проиллюстрировать влияние процесса добавления псевдослучайного шума на процесс квантования изменяющегося во времени сигнала, рассмотрим следующий эксперимент. Пусть синусоидальный сигнал, имеющий амплитуду 1,0, подавляется на 60 дБ. Тогда ослабляемый сигнал имеет полную амплитуду 0,001, что составляет примерно половину интервала квантования, равного 0,001957, для десятибитового равномерного устройства квантования (получается делением удвоенной амплитуды сигнала 2 на 210 - 2). Когда на округляющее квантующее устройство подается ослабленная синусоида, на выходе будут получаться в основном все нули, за исключением отдельных единиц в ±1 квантиль, что происходит в том случае, когда вход пересекает уровень ±q/2, равный 0,000979 (соответствующий наименее значимому биту АЦП). Если входной сигнал ослаблен еще на 0,23 дБ, пороговые уровни самого младшего бита никогда не будут пересекаться и выходная последовательность будет представлять собой все нули. Теперь добавим псевдослучайный шум со среднеквадратической амплитудой, равной 0,001, к ослабленной синусоиде амплитуды 0,001 так, чтобы сумма сигнала с псевдослучайным шумом регулярно пересекала уровни ±q/2 АЦП. На рис. 13.11 изображен спектр мощности, полученный путем преобразования и усреднения 400 реализаций этого суммарного сигнала. В результате ослабленный на 60 дБ сигнал на пределе разрешающей способности АЦП все еще присутствовал и, будучи точно измеренным, составил -63 дБ (-3 дБ вследствие округления). Псевдослучайный шум давал эффект расширения динамической области АЦП (как правило, с 9 до 12 дБ или с 1,5 до 2,0 бит) и повысил эффективность ступенчатой аппроксимации АЦП.
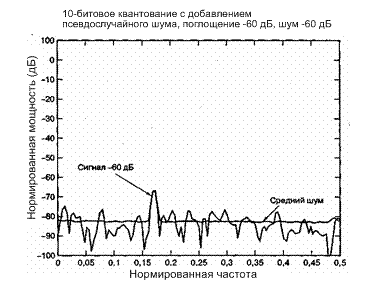
Рис. 13.11. Спектр мощности равномерного АЦП с добавлением псевдослучайного низкоуровневого сигнала
13.2.5. Неравномерное квантование
Равномерные квантующие устройства представляют собой наиболее распространенный тип аналого-цифровых преобразователей, так как они наиболее устойчивы. Под "устойчивостью" подразумевается, что они относительно нечувствительны к незначительным изменениям входных статистик. Эта устойчивость достигается в результате того, что преобразователи не настраиваются окончательно на одно конкретное множество входных параметров. Это позволяет им работать хорошо даже при наличии неопределенных входных параметров; даже незначительные изменения входных статистик приводят к несущественным изменениям выходных статистик.
Когда существует малая неопределенность в статистиках входного сигнала, можно создать неравномерное устройство квантования, которое дает меньшее отношение NSR, чем равномерное устройство квантования, использующее то же количество бит. Это реализует-
ся с помощью деления входной динамической области на неравномерные интервалы так, что мощность шума, взвешенная вероятностью появления на каждом интервале, является одинаковой. Для оптимального квантующего устройства могут быть найдены итерационные решения для границ принятия решения и размеров шагов для конкретных плотностей и малого количества бит. Эта задача упрощается путем моделирования неравномерного устройства квантования как последовательности операторов, как изображено на рис. 13.12. Сначала входной сигнал отображается с помощью нелинейной функции, называемой компрессором (compressor), в альтернативную область уровней. Эти уровни равномерно квантуются, и квантованные уровни сигнала затем отображаются с помощью дополняющей нелинейной функции, называемой экспандером (expander), в выходную область уровней. Объединяя части наименований каждой из операций COMpress и exPAND, получим название процесса: компандирование (companding).
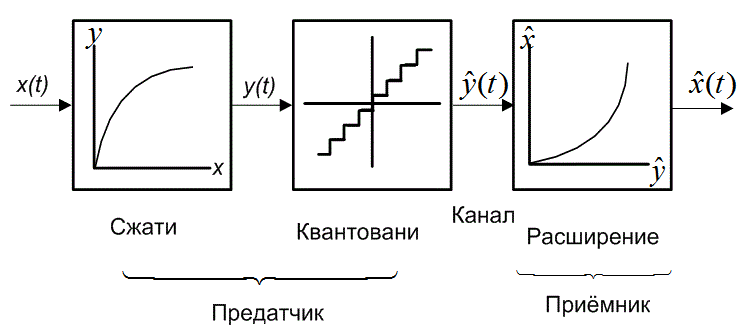
Рис. 13.12. Неравномерное устройство квантования как последовательность операторов: сжатие, равномерное квантование и расширение
13.2.5.1. Субоптимальное неравномерное квантование
Изучая характеристику компрессора у = С(х) на рис. 13.13, видим, что размеры шага квантования для выходной переменной у связаны с размерами шага квантования входной переменной х через наклон ![]() (х) (например,
(х) (например, ![]() . Для произвольной функции плотности вероятности и произвольной характеристики компрессора можно достичь выходной дисперсии шума квантования [7].
. Для произвольной функции плотности вероятности и произвольной характеристики компрессора можно достичь выходной дисперсии шума квантования [7].
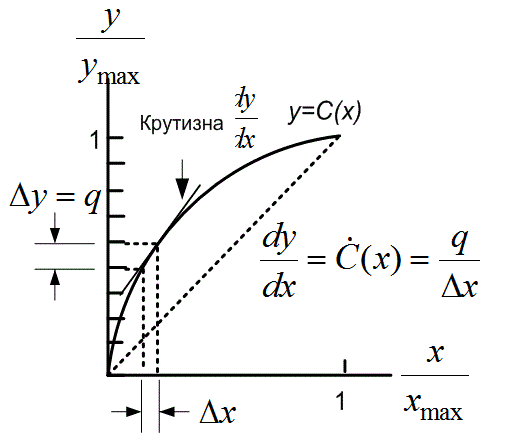
Рис. 13.13. Характеристика компрессора С(х) и оценка локального наклона ![]()
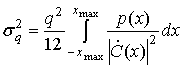 (13.25)
(13.25)
Для определенной функции плотности вероятности может быть найдена характеристика компрессора С(х), которая минимизирует ![]() . Оптимальный закон сжатия для данной функции плотности вероятности выражается следующим образом [8].
. Оптимальный закон сжатия для данной функции плотности вероятности выражается следующим образом [8].
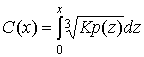 (13.26)
(13.26)
Находим, что оптимальная характеристика сжатия пропорциональна интегралу от кубического корня от входной функции плотности вероятности. Это называется точной настройкой (fine tuning). Если компрессор настроен на работу с одной функцией плотности, а используется с другой (например, отличающейся только масштабом), говорят, что устройство квантования рассогласовано, и вследствие этого может существенно снижаться эффективность функционирования [6].
13.2.5.2. Логарифмическое сжатие
В предыдущем разделе был представлен закон сжатия для случая, когда входная функция плотности вероятности сигнала хорошо определена. Сейчас обратимся к случаю, в котором об этой функции известно мало. Это, например, происходит, когда средняя энтропия входного сигнала является случайной величиной. Например, уровень голоса случайно выбранного телефонного пользователя может варьироваться от одного экстремального значения (доверительный шепот) до другого (крик).
При неизвестной функции плотности вероятности характеристика компрессора неравномерного устройства квантования должна быть выбрана так, чтобы результирующий шум не зависел от конкретной плотности. Хотя это и представляется идеальным, достижение такой независимости может оказаться невозможным. Однако мы хотим компромисса и будем пытаться установить возможную независимость среди большого числа входных дисперсий и плотностей. Пример квантующего устройства, которое показывает отношение SNR, независимое от функции плотности вероятности входного сигнала, можно представить с помощью рис. 2.18. На этом рисунке можно наблюдать значительное отличие в отношениях NSR для входных сигналов с различными амплитудами, квантованных с помощью равномерного квантующего устройства. Для сравнения можно видеть, что неравномерное устройство квантования допускает только большие ошибки для больших сигналов. Преимущество такого подхода понятно интуитивно. Если SNR должно быть независимо от распределения амплитуды, шум квантования должен быть пропорционален входному уровню. В формуле (13.25) представлена дисперсия шума квантующего устройства для произвольной функции плотности вероятности и произвольной характеристики компрессора. Дисперсия сигнала для любой функции плотности вероятности равна следующему.
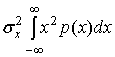 (13.27)
(13.27)
При отсутствии насыщения SNR квантующего устройства имеет следующий вид.
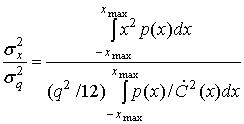 (13.28)
(13.28)
Чтобы SNR не зависело от конкретной плотности, необходимо, чтобы числитель был масштабированной версией знаменателя. Это требование равносильно следующему.
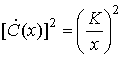 (13.29)
(13.29)
или
![]() (13.30)
(13.30)
Отсюда с помощью интегрирования находим следующее.
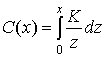 (13.31)
(13.31)
или
C(x)=ln x+const (13.32)
Этот результат является интуитивно привлекательным. Логарифмический компрессор допускает постоянное SNR на выходе, поскольку с использованием логарифмической шкалы одинаковые расстояния (или ошибки) являются в действительности одинаковыми отношениями, а это и требуется для того, чтобы SNR оставалось фиксированным в области входного сигнала. Константа в равенстве (13.32) нужна для согласования граничных условий по дг|тхи ;упих. Учитывая эти граничные условия, получим логарифмический преобразователь следующего вида.
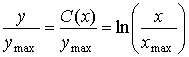 (13.33)
(13.33)
Вид сжатия, предложенный логарифмической функцией, изображен на рис. 13.14, а. Сложность, связанная с этой функцией, состоит в том, что она не отображает отрицательные входные сигналы. Отрицательные сигналы учитываются путем добавления отраженной версии логарифма на отрицательную полуось. Эта модификация изображается на рис. 13.14 и влечет за собой следующее.
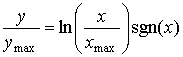 (13.34)
(13.34)
где
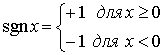
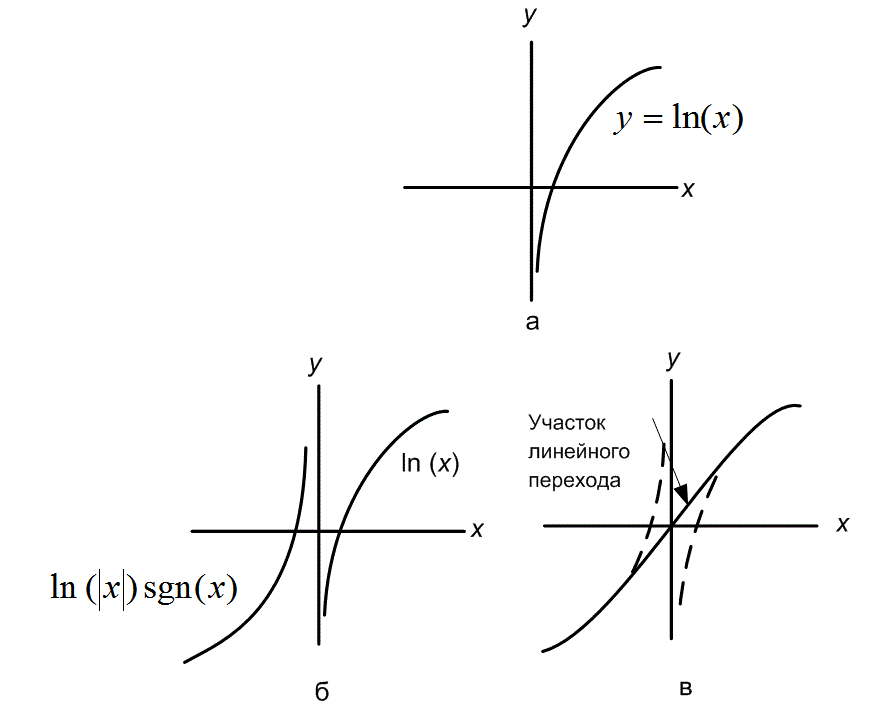
Рис. 13.14. Логарифмическое сжатие: а) прототип логарифмической функции для закона сжатия; 6) прототип функции ln|x| sgn x для закона сжатия; в) функция ln|x| sgn x с плавным соединением между сегментами.
Еще одна возникающая в этой ситуации сложность состоит в том, что сжатие, описанное равенством (13.34), не является непрерывным в начале координат; в действительности оно не имеет смысла в начале координат. Необходимо выполнить плавное соединение между логарифмической функцией и линейным отрезком, проходящим через начало координат. Существует две стандартные функции сжатия, выполняющие это соединение, —![]() -закон компандера и А-закон компандера.
-закон компандера и А-закон компандера.
Компандер, использующий ![]() -закон. Компандер, использующий
-закон. Компандер, использующий ![]() -закон, введенный компанией Bell System для использования в Северной Америке, имеет следующий вид.
-закон, введенный компанией Bell System для использования в Северной Америке, имеет следующий вид.
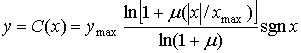 (13.35)
(13.35)
Приблизительное поведение этого компрессора в областях, соответствующих малым и большим значениям аргумента, является следующим.
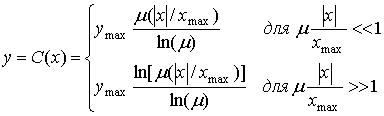 (13.36)
(13.36)
Параметр ![]() в компандере, использующем
в компандере, использующем ![]() -закон, обычно устанавливался равным 100 для 7-битового преобразователя. Позже он изменился до 255 для 8-битового преобразователя. В настоящее время стандартным североамериканским конвертером является 8-битовый АЦП с
-закон, обычно устанавливался равным 100 для 7-битового преобразователя. Позже он изменился до 255 для 8-битового преобразователя. В настоящее время стандартным североамериканским конвертером является 8-битовый АЦП с ![]() = 255.
= 255.
Пример 13.6. Среднее SNR для компрессора, использующего ц-закон
Среднее SNR для компрессора, использующего ц-закон, можно оценить, подставляя выражение для ц-закона в формулу (13.28). Для положительных значений входной переменной х закон сжатия имеет следующий вид.
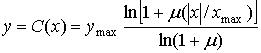 (13.37)
(13.37)
Затем производная равна следующему.
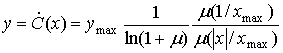 (13.38)
(13.38)
Для значений входной переменной, для которых ![]() является большим в сравнении с единицей, производная переходит в следующее выражение.
является большим в сравнении с единицей, производная переходит в следующее выражение.
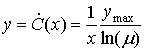 (13.39)
(13.39)
Подставляя 1/ С(х) в формулу (13.28), получаем следующее.
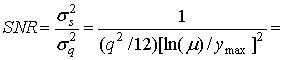 (13.40)
(13.40)
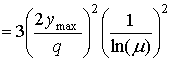 (13.41)
(13.41)
Отношение 2ymax/q приблизительно равно числу уровней квантования (2b) для b-битового сжимающего устройства квантования. Для 8-битового преобразователя с ![]() = 255 имеем следующее.
= 255 имеем следующее.
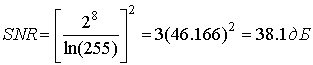 (13.42)
(13.42)
Для сравнения на рис. 13.15 представлено отношение SNR АЦП, использующего ![]() -закон. Здесь SNR изображено для входных синусоид различной амплитуды. Там же изображен уровень 38,1 дБ, вычисленный в формуле 13.42, и SNR для линейного квантующего устройства с той же областью входных амплитуд. Как и предсказывалось, квантующее устройство, использующее
-закон. Здесь SNR изображено для входных синусоид различной амплитуды. Там же изображен уровень 38,1 дБ, вычисленный в формуле 13.42, и SNR для линейного квантующего устройства с той же областью входных амплитуд. Как и предсказывалось, квантующее устройство, использующее ![]() -закон, поддерживает постоянное SNR для значительного диапазона входных уровней. Зубчатость кривой производительности (гранулярность квантующего устройства) вызвана логарифмической функцией сжатия. Реальные преобразователи, помимо этого, показывают дополнительную зубчатость вследствие кусочно-линейной аппроксимации непрерывной кривой
-закон, поддерживает постоянное SNR для значительного диапазона входных уровней. Зубчатость кривой производительности (гранулярность квантующего устройства) вызвана логарифмической функцией сжатия. Реальные преобразователи, помимо этого, показывают дополнительную зубчатость вследствие кусочно-линейной аппроксимации непрерывной кривой ![]() -закона. На рис. 13.16 представлено дискретное преобразование Фурье пары входных синусоид относительных амплитуд 1,0 (0 дБ) и 0,01 (-40 дБ). Входной сигнал квантуется с помощью 10-битового преобразователя, использующего
-закона. На рис. 13.16 представлено дискретное преобразование Фурье пары входных синусоид относительных амплитуд 1,0 (0 дБ) и 0,01 (-40 дБ). Входной сигнал квантуется с помощью 10-битового преобразователя, использующего ![]() -закон (
-закон (![]() = 500), и на рис. 13.16, а-в уровни сигнала ослабляются на 1,20 и 40 дБ относительно полномасштабного входа. Отметим, что уровни шума квантования для полномасштабного сигнала на рис. 13.16, а выше, чем у равномерного АЦП (-72 дБ против -83 дБ, как видно из рис. 13.7). Для ослабленных сигналов отмечаем улучшенное отношение SNR логарифмически сжимающего АЦП по сравнению с равномерным АЦП. Видно, что поскольку уровни входного сигнала уменьшились, шум квантования также снизился, и при ослаблении в 40 дБ уровень шума упал до -108 дБ. Таким образом, логарифмически сжимающие АЦП не имеют проблемы "видения" входного сигнала низкого уровня даже при ослаблении на 40 дБ, как на рис. 13.16, в, в то время как тот же сигнал теряется среди шума равномерного преобразователя, как показано на рис. 13.7, в.
= 500), и на рис. 13.16, а-в уровни сигнала ослабляются на 1,20 и 40 дБ относительно полномасштабного входа. Отметим, что уровни шума квантования для полномасштабного сигнала на рис. 13.16, а выше, чем у равномерного АЦП (-72 дБ против -83 дБ, как видно из рис. 13.7). Для ослабленных сигналов отмечаем улучшенное отношение SNR логарифмически сжимающего АЦП по сравнению с равномерным АЦП. Видно, что поскольку уровни входного сигнала уменьшились, шум квантования также снизился, и при ослаблении в 40 дБ уровень шума упал до -108 дБ. Таким образом, логарифмически сжимающие АЦП не имеют проблемы "видения" входного сигнала низкого уровня даже при ослаблении на 40 дБ, как на рис. 13.16, в, в то время как тот же сигнал теряется среди шума равномерного преобразователя, как показано на рис. 13.7, в.
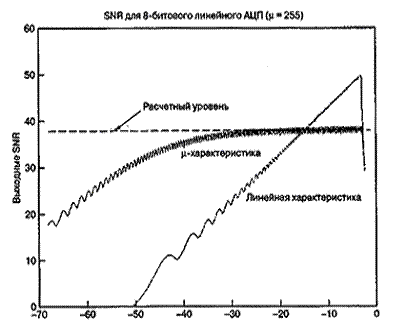
Рис. 13.15. Предсказанное и измеренное отношение SNR для АЦП, использующегоц ![]() -закон
-закон
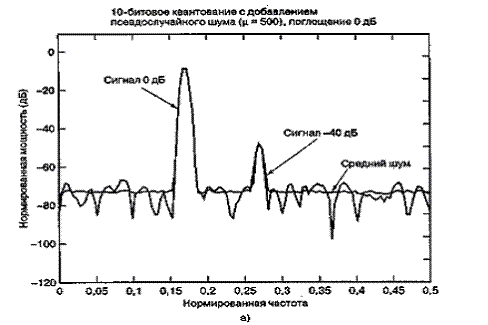
Рис. 13.16. Спектр мощности сигналов АЦП, использующего ![]() -закон
-закон
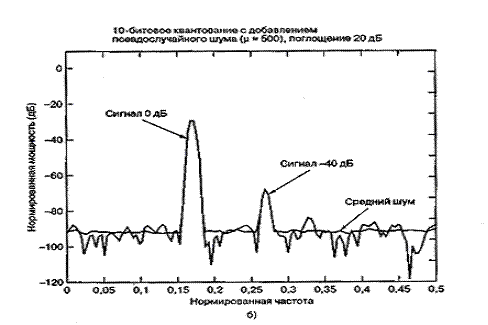
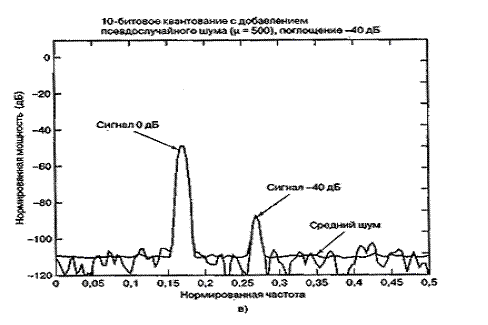
Рис. 13.16. Спектр мощности сигналов АЦП, использующего![]() -закон (окончание)
-закон (окончание)
Реальная характеристика компрессора, использующего ![]() -закон, описана формулой (13.35). Как показано на рис. 13.17, 16 сегментов линейных хорд аппроксимируют функциональное выражение на 256 возможных выходных уровнях. Восемь из этих сегментов расположены в первом квадранте, восемь — в третьем квадранте и сегмент "0" имеет один и тот же наклон в обоих квадрантах. Вдоль каждого сегмента хорды квантование является равномерным по четырем битам преобразования низшего порядка. Таким образом, 8-битовый сжимающий формат преобразования имеет следующий вид.
-закон, описана формулой (13.35). Как показано на рис. 13.17, 16 сегментов линейных хорд аппроксимируют функциональное выражение на 256 возможных выходных уровнях. Восемь из этих сегментов расположены в первом квадранте, восемь — в третьем квадранте и сегмент "0" имеет один и тот же наклон в обоих квадрантах. Вдоль каждого сегмента хорды квантование является равномерным по четырем битам преобразования низшего порядка. Таким образом, 8-битовый сжимающий формат преобразования имеет следующий вид.
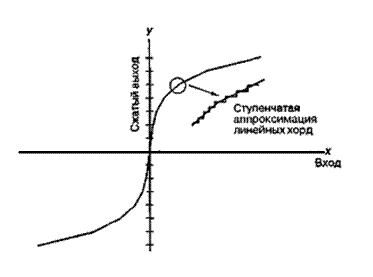
Рис. 13.17. Семибитовое сжатое квантование для 16-сегментной аппроксимации ![]() -закона
-закона
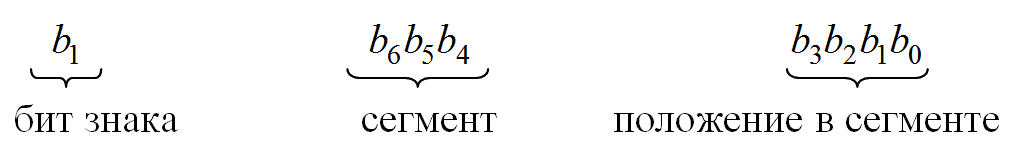
Он представляет собой кусочную аппроксимацию хордами до плавной функции и ступенчатую аппроксимацию каждой хорды, учитывающую дополнительную зубчатость в кривой SNR, которая представлена на рис. 13.15.
Компандер, использующий А-закон. Этот компандер является стандартом CCITT (Consultative Committee for International Telephone and Telegraphy — Международный консультативный комитет по телеграфии и телефонии, МККТТ), а следовательно европейским стандартом аппроксимации логарифмического сжатия. Характеристика компрессора имеет следующий вид.
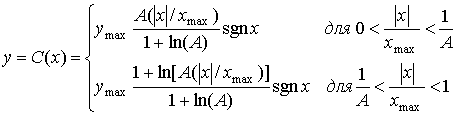 (13.43)
(13.43)
Стандартным значением параметра А является 87,56, и (при использовании 8-битового преобразователя) SNR для этого значения равно 38,0 дБ. Сжимающая характеристика А-закона аппроксимируется подобно тому, как это делалось для компрессора, использующего ![]() -закон, — с помощью последовательности 16 линейных хорд, охватывающих выходную область. Нижние две хорды в каждом квадранте являются в действительности хордами сигнала, соответствующими линейному сегменту компрессора, использующего А-закон. Одним важным отличием между характеристиками сжатия А- и
-закон, — с помощью последовательности 16 линейных хорд, охватывающих выходную область. Нижние две хорды в каждом квадранте являются в действительности хордами сигнала, соответствующими линейному сегменту компрессора, использующего А-закон. Одним важным отличием между характеристиками сжатия А- и ![]() -законов является то, что стандарт А-закона имеет характеристику с нулем на границе шага квантования, в то время как стандарт
-законов является то, что стандарт А-закона имеет характеристику с нулем на границе шага квантования, в то время как стандарт ![]() -закона — характеристику с нулем в центре шага квантования. Таким образом, компрессор с A-законом не имеет нулевого значения, и следовательно, для него не существует интервала, на котором бы при нулевом входе не передавались данные.
-закона — характеристику с нулем в центре шага квантования. Таким образом, компрессор с A-законом не имеет нулевого значения, и следовательно, для него не существует интервала, на котором бы при нулевом входе не передавались данные.
Существует прямое отображение из формата АЦП, использующего 8-битовое сжатие с А-законом, в 12-битовый линейный двоичный код и из формата 8-битового сжатия с ![]() -законом в 13-битовый линейный код [8]. Эта операция позволяет преобразование аналоговой информации в цифровую с помощью равномерного устройства квантования с последующим отображением в меньшее число бит в кодовом преобразователе. Кроме того, это позволяет обратное отображение в приемнике (т.е. расширение) производить на числовой выборке.
-законом в 13-битовый линейный код [8]. Эта операция позволяет преобразование аналоговой информации в цифровую с помощью равномерного устройства квантования с последующим отображением в меньшее число бит в кодовом преобразователе. Кроме того, это позволяет обратное отображение в приемнике (т.е. расширение) производить на числовой выборке.
Импульсно-кодовая модуляция. Одной из задач, выполняемых в ходе импульсно-кодовой модуляции (pulse-code modulation — PCM), является преобразование исходных волновых сигналов в дискретные двоичные последовательности. Эта задача производится с помощью трехэтапного процесса — дискретизации, квантования и кодирования. Процесс дискретизации изучался в главе 2, а процесс квантования — в данной главе и в главе 2. Отметим, что процесс кодирования, следующий за квантованием (см. рис. 2.2), часто воплощается на аппаратном уровне и выполняется тем же устройством, что и квантование. Вообще, процесс может быть описан следующим образом: последовательная аппроксимация аналого-цифровых преобразователей образует последовательные биты декодированных данных с помощью обратной связи, сравнения и процесса принятия решения. В процессе обратной связи постоянно задается вопрос, входной сигнал находится выше или ниже средней точки остаточного интервала неопределенности. С помощью этой технологии интервал неопределенности сокращается до половинного на каждом шаге сравнения и принятия решения до тех пор, пока интервал неопределенности не совпадет с допустимым интервалом квантования.
При последовательной аппроксимации результат каждого предыдущего решения снижает неопределенность, которая должна быть разрешена во время следующего преобразования. Аналогично результаты предшествующих преобразований аналоговой информации в цифровую могут использовать для уменьшения неопределенности, которая должна быть разрешена во время следующего преобразования. Эта редукция неопределенности достигается путем передачи каждой последующей выборке вспомогательной информации из более ранних выборок. Эта информация называется избыточной частью сигнала, и с помощью ее передачи сокращается интервал неопределенности, в котором квантующее устройство и кодер должны вести поиск следующей выборки сигнала. Передача данных — это один из методов, с помощью которых достигается снижение избыточности.
13.3. Дифференциальная импульсно-кодовая модуляция
Используя прошлые данные для измерения (т.е. квантования) новых переходим от обычной импульсно-кодовой модуляции (pulse-code modulation — PCM) к дифференциальной (differential PCM — DPCM). В DPCM предсказание следующего выборочного значения формируется на основании предыдущих значений. Для квантующего устройства это предсказание можно рассматривать в качестве инструкции по руководству при поиске следующего выборочного значения в конкретном интервале. Если для предсказания используется избыточность сигнала, область неопределенности сокращается и квантование можно проводить с уменьшенным числом решений (или бит) для данного уровня квантования или с уменьшенным числом уровней квантования для данного числа решений (или бит). Сокращение избыточности реализуется путем вычитания предсказания из следующего выборочного значения. Эта разность называется ошибкой предсказания (prediction error).
Устройства квантования, описанные в разделе 13.2, называются мгновенными устройствами квантования или устройствами квантования без памяти, так как цифровые преобразования основаны на единичной (текущей) входной выборке. В разделе 13.1 были определены свойства источников, которые допускают сокращение интенсивности источника. Этими свойствами были неравновероятные уровни источника и зависимые выборочные значения. Мгновенные квантующие устройства кодируют источник, принимая во внимание плотность вероятности, сопоставленную с каждой выборкой. Методы квантования, которые принимают во внимание корреляцию между выборками, являются квантующими устройствами с памятью. Эти квантующие устройства уменьшают избыточность источника сначала посредством превращения коррелированной входной последовательности в связанную последовательность с уменьшенной корреляцией, уменьшенной дисперсией и уменьшенной полосой частот. Затем эта новая последовательность квантуется с использованием меньшего количества бит.
Корреляционные характеристики источника можно представить во временной области с помощью выборки его автокорреляционной функции и в частотной области — его спектром мощности. Если изучается спектр мощности Gx(f) кратковременного речевого сигнала, как изображено на рис. 13.18, то видим, что спектр имеет глобальный максимум в окрестности от 300 до 800 Гц и убывает со скоростью от 6 до 12 дБ/октаву. Изучая этот спектр, можно взглянуть на определенные свойства временной функции, из которой он получен. Видим, что большие изменения сигнала происходят медленно (низкая частота), а быстрые (высокая частота) должны иметь малую амплитуду. Эквивалентная интерпретация может быть дана в терминах автокорреляционной функции сигнала Rx(T), как изображено на рис. 13.19. Здесь широкая, медленно меняющаяся автокорреляционная функция свидетельствует о том, что при переходе от выборки к выборке будет только слабое изменение и что для полного изменения амплитуды требуется временной интервал, превышающий интервал корреляции. Интервал (или радиус) корреляции, рассмотренный на рис. 13.19, является временной разностью между максимальной и первой нулевой корреляцией. В частности, значение корреляции для типичного единичного выборочного запаздывания лежит в диапазоне примерно от 0,79 до 0,87, а радиус корреляции имеет порядок от 4 до 6 выборочных интервалов, равных Т секунд на интервал.
Поскольку разность между соседними временными выборками для речи мала, используемый метод кодирования базируется на передаче от выборки к выборке разностей, а не действительных выборочных значений. В действительности, последовательные разности представляют собой частный случай класса преобразователей с памятью, называемых N-отводными линейными кодерами с предсказанием. Эти кодеры, иногда именуемые кодерами с предсказаниями и поправками, предсказывают следующее входное выборочное значение на основании предыдущих входных выборочных значений. Эта структура показана на рис. 13.20. В этом типе преобразователя передатчик и приемник имеют одинаковую модель предсказания, которая получена из корреляционных характеристик сигнала. Кодер дает ошибку предсказания (или остаток) как разность между следующим измеренным и предсказанным выборочными значениями. Математически контур предсказания описывается следующим образом.
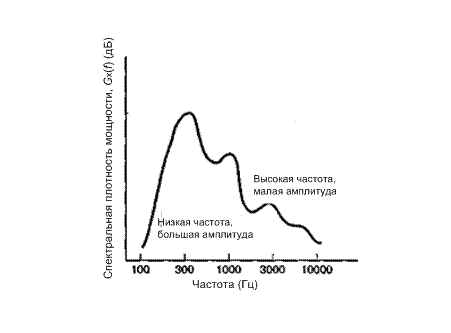
Рис. 13.18. Типичный спектр мощности для речевых сигналов
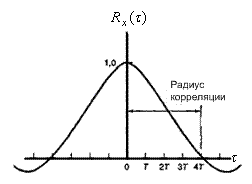
Рис. 13.19. Автокорреляционная функция для типичных речевых сигналов
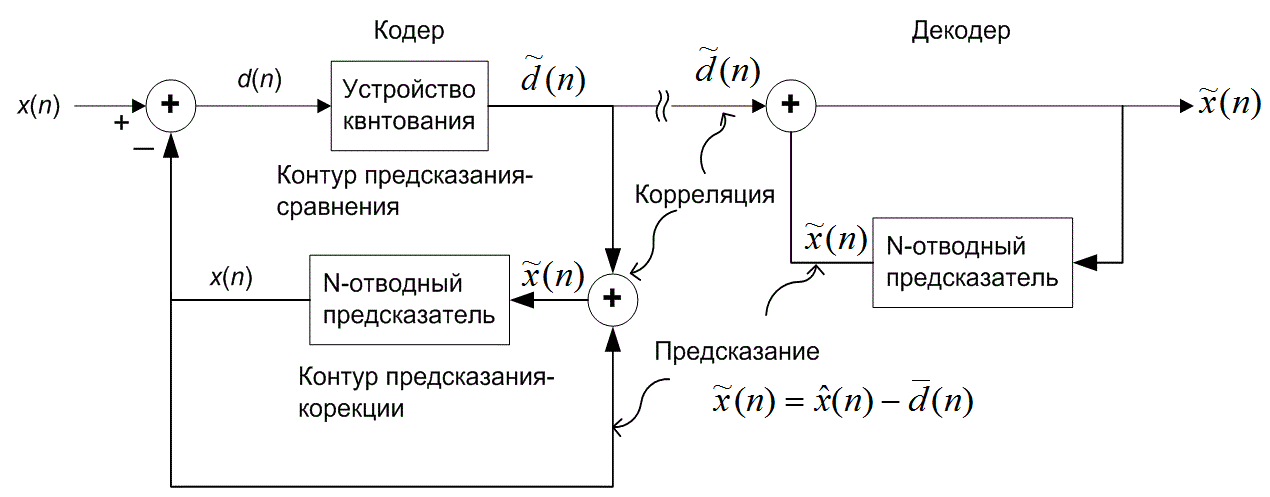
Рис. 13.20. N-отводный дифференциальный импульсно-кодовый модулятор с предсказанием
![]()
где х(п) — n-я входная выборка, ![]() (п) — предсказанное значение выборки, a d(n) — соответствующая ошибка предсказания. Эта операция производится в контуре предсказания и сравнения, верхний контур кодера изображен на рис. 13.20. Кодер корректирует свои предсказания, составляя сумму предсказанного значения и ошибки предсказания. Математически контур коррекции описывается следующим образом.
(п) — предсказанное значение выборки, a d(n) — соответствующая ошибка предсказания. Эта операция производится в контуре предсказания и сравнения, верхний контур кодера изображен на рис. 13.20. Кодер корректирует свои предсказания, составляя сумму предсказанного значения и ошибки предсказания. Математически контур коррекции описывается следующим образом.
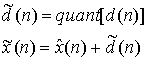
Здесь quant(![]() ) представляет операцию квантования, d(n) — квантованная версия ошибки предсказания, а
) представляет операцию квантования, d(n) — квантованная версия ошибки предсказания, а ![]() (п) — скорректированная и квантованная версия входной выборки. Это делается в контуре предсказания и поправок, в нижнем цикле кодера и в единственном контуре декодера на рис. 13.20. Декодер должен быть также проинформирован об ошибках предсказания, чтобы использовать свой контур коррекции для поправки своего предсказания. Декодер "повторяет" обратный цикл кодера. Задача связи состоит в передаче разности (ошибки сигнала) между предсказанными и действительными выборочными данными. По этой причине описанный класс кодеров часто называется дифференциальным импульсно-кодовым модулятором (differential pulse code modulator — DPCM). Если модель предсказания дает предсказания, близкие к действительным выборочным значениям, для остатков будет характерна уменьшающаяся дисперсия (по отношению к исходному сигналу). Из раздела 13.2 известно, что число бит, которое требуется для перемещения данных через канал с заданной точностью, связано с дисперсией сигнала. Следовательно, уменьшенная последовательность остатков может быть передана через канал с уменьшенной скоростью.
(п) — скорректированная и квантованная версия входной выборки. Это делается в контуре предсказания и поправок, в нижнем цикле кодера и в единственном контуре декодера на рис. 13.20. Декодер должен быть также проинформирован об ошибках предсказания, чтобы использовать свой контур коррекции для поправки своего предсказания. Декодер "повторяет" обратный цикл кодера. Задача связи состоит в передаче разности (ошибки сигнала) между предсказанными и действительными выборочными данными. По этой причине описанный класс кодеров часто называется дифференциальным импульсно-кодовым модулятором (differential pulse code modulator — DPCM). Если модель предсказания дает предсказания, близкие к действительным выборочным значениям, для остатков будет характерна уменьшающаяся дисперсия (по отношению к исходному сигналу). Из раздела 13.2 известно, что число бит, которое требуется для перемещения данных через канал с заданной точностью, связано с дисперсией сигнала. Следовательно, уменьшенная последовательность остатков может быть передана через канал с уменьшенной скоростью.
Преобразователи с предсказанием должны иметь кратковременную память, которая поддерживает проводимые в реальном времени операции, требуемые для алгоритма предсказания. Кроме того, они часто будут иметь долгосрочную память, которая поддерживает медленные, зависимые от данных операции, такие как автоматическая регулировка усиления, коррекция коэффициентов фильтра. Предсказатели, которые включают медленные, зависимые от данных регулирующие алгоритмы, называются адаптивными.
13.3.1. Одноотводное предсказание
Одноотводный линейный кодирующий фильтр с предсказанием (linear prediction coding filter — фильтр LPC) в процессе модуляции DPCM предсказывает последующее входное выборочное значение, основываясь на предшествующем входном выборочном значении. Уравнение предсказания имеет следующий вид.
![]() (13.44)
(13.44)
Здесь х(п|т) — оценка х в момент п при данных всех выборках, собранных за время т и а — параметр, используемый для минимизации ошибки предсказания. Полученная после измерений ошибка предсказания имеет следующий вид.
![]() (13.45,а)
(13.45,а)
![]() (13.45,б)
(13.45,б)
Среднеквадратическая ошибка имеет следующий вид.
![]() (13.46)
(13.46)
Если ![]() является несмещенной оценкой х(п-1), равенство (13.46) может быть записано следующим образом.
является несмещенной оценкой х(п-1), равенство (13.46) может быть записано следующим образом.
![]() (13.47,а)
(13.47,а)
![]() (13.47,б)
(13.47,б)
В данном случае Rd(n) и Rx(n) являются автокорреляционными функциями ошибки предсказания и входного сигнала. Rd(0) — мощность ошибки, Rx(0) — мощность сигнала, а Сх(п) = Rx(n)/Rx(0) — нормированная автокорреляционная функция. Параметр а можно выбрать так, чтоб он минимизировал мощность ошибки предсказания, указанную в формуле (13.47). Для этого нужно частную производную по а от Rd(0) положить равной нулю.
![]() (13.48)
(13.48)
Решая данное уравнение, получим оптимальное значение ![]() .
.
![]() (13.49)
(13.49)
Подставляя aopt в уравнение (13.47), получим следующее.
![]() (13.50,а)
(13.50,а)
![]() (13.50,б)
(13.50,б)
![]() (13.50,в)
(13.50,в)
Усиление предсказания (prediction gain) кодера можно определить как отношение входной и выходной дисперсий, ![]() Для фиксированной частоты передачи бит этот коэффициент представляет собой увеличение в выходном SNR, а для фиксированного выходного SNR — сокращение описания скорости передачи бит. Отметим, что, как использовалось в равенстве (13.50,6), усиление предсказания для оптимального предсказателя всегда больше единицы для любого значения корреляции сигнала Rx(0). С другой стороны, как использовалось в равенстве (13.47,6), оно больше единицы для неоптимального одноотводного единичного предсказателя, только если корреляция сигнала превышает 0,5.
Для фиксированной частоты передачи бит этот коэффициент представляет собой увеличение в выходном SNR, а для фиксированного выходного SNR — сокращение описания скорости передачи бит. Отметим, что, как использовалось в равенстве (13.50,6), усиление предсказания для оптимального предсказателя всегда больше единицы для любого значения корреляции сигнала Rx(0). С другой стороны, как использовалось в равенстве (13.47,6), оно больше единицы для неоптимального одноотводного единичного предсказателя, только если корреляция сигнала превышает 0,5.
Пример 13.7. Усиление предсказания для одноотводного фильтра LPC
Сигнал с коэффициентом корреляции Сx(1), равным 0,8, должен квантоваться одноотводным фильтром LPC. Определите усиление предсказания, если коэффициент предсказания 1) оптимизирован по отношению к минимальной ошибке предсказания; 2) положен равным единице.
Решение
а) Из уравнения (13.50,в) имеем следующее.
![]() (13.51,а)
(13.51,а)
Усиление предсказания = 1/(0,36) = 2,78 или 4,44 дБ (13.51,б)
б) Из уравнения (13.47,6) имеем
![]() (13.51,в)
(13.51,в)
Усиление предсказания = 1/(0,40) = 2,50 или 3,98 дБ (13.51,г)
13.3.2. N-отводное предсказание
N-отводный фильтр LPC предсказывает последующее выборочное значение на основании линейной комбинации предшествующих N выборочных значений. Будем предполагать, что квантованные оценки, которые используются предсказывающими фильтрами, являются несмещенными и безошибочными. Приняв это предположение, можно опустить двойные индексы (использованные в разделе 13.3.1) для данных в фильтре, но использовать их для предсказания. Тогда уравнение N-отводного предсказания принимает следующий вид.
![]() (13.52)
(13.52)
Ошибка предсказания принимает следующий вид.
![]() (13.53.а)
(13.53.а)
![]() (13.53.б)
(13.53.б)
Среднеквадратическая ошибка предсказания имеет вид
![]() (13.54)
(13.54)
Ясно, что Среднеквадратическая ошибка предсказания выражается через квадрат коэффициентов фильтра aj. Можно образовать частные производные от среднеквадратических ошибок по каждому коэффициенту, как это делалось в разделе 13.3.1, и найти коэффициенты, которые обращают частные производные в нуль. Формально, вычисляя частные производные по j-му коэффициенту (до раскрытия х(п|п -1)), получим следующее.
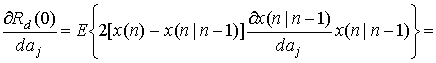 (13.55,а)
(13.55,а)
![]() (13.55,б)
(13.55,б)
![]() (13.55,в)
(13.55,в)
![]() (13.55,г)
(13.55,г)
Эта система уравнений (по одному для каждого j) может быть записана в матричной форме, и тогда она будет называться нормальными уравнениями.
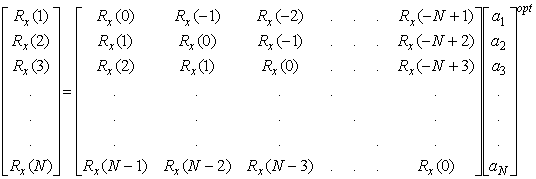 (13.56.a)
(13.56.a)
Нормальные уравнения могут быть записаны более компактно.
![]() (13.56,б)
(13.56,б)
где ![]() — это корреляционный вектор задержек от 1 до N, Rxx — корреляционная матрица (предполагается процесс с нулевым среднем), a aopt — вектор оптимальных весовых коэффициентов фильтра.
— это корреляционный вектор задержек от 1 до N, Rxx — корреляционная матрица (предполагается процесс с нулевым среднем), a aopt — вектор оптимальных весовых коэффициентов фильтра.
Чтобы изучить решения нормальных уравнений, запишем уравнение (13.54) для среднеквадратической ошибки в матричной форме.
![]() (13.57,а)
(13.57,а)
![]() (13.57,б)
(13.57,б)
где ![]() — транспонированная матрица для матрицы к. Замена aopt на а в равенстве (13.57,б) с последующей заменой
— транспонированная матрица для матрицы к. Замена aopt на а в равенстве (13.57,б) с последующей заменой ![]() на
на ![]() дает следующее.
дает следующее.
![]() (13.58,а)
(13.58,а)
![]() (13.58,б)
(13.58,б)
Теперь можем перенести правую часть уравнения (13.56) в левую и использовать уравнение (13.58,б) для дополнения верхней строки матрицы, чтобы получить "чистый" вид оптимального предсказателя.
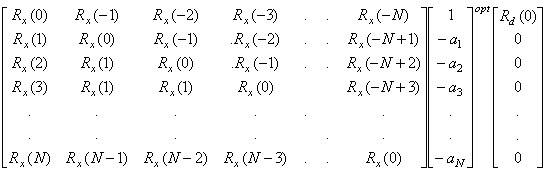 (13.59)
(13.59)
В этой форме ненулевой выход матричного произведения имеет место только в момент нуль, что подобно выходному импульсу.
Верхняя строка уравнения (13.59) свидетельствует о том, что мощность ошибки предсказания имеет следующий вид.
![]() (13.60)
(13.60)
Сравните это равенство с (13.50,6). Интересное свойство оптимального N-отводного фильтра с предсказанием состоит в том, что множество коэффициентов, которое задает минимальную среднеквадратическую ошибку предсказания, с нулевой ошибкой предсказывает также последующие N-1 корреляционных выборок на основании предшествующих N-1 корреляционных выборок. Для фиксированных коэффициентов фильтра кодер DPCM может давать усиление предсказания относительно линейного квантования от 6 до 8 дБ [9, 10]. Это усиление, по сути, независимо от длины фильтра, если длина превосходит три или четыре отвода. Дополнительное усиление имеет место, если кодер обладает медленными адаптивными свойствами.
13.3.3. Дельта-модуляция
Дельта-модуляция, часто обозначаемая как Δ-модуляция, представляет собой процесс внедрения низкой разрешающей способности аналого-цифрового преобразователя в контур обратной связи дискретных данных, работающий со скоростью, значительно превышающей частоту Найквиста. Причиной возникновения этой технологии стало то, что в процессе преобразования скорость — это менее дорогой ресурс, чем точность, и разумнее будет использовать более быстрые процессы обработки сигналов для получения более высокой точности.
Из равенства (13.50,в) следует, что усиление предсказания для одноотводного предсказателя могло бы быть большим, если бы нормированный коэффициент корреляции Сx(1) был близок к единице. Для того чтобы увеличить корреляцию выборок, фильтр с предсказанием обычно работает со скоростью, которая далеко превосходит частоту Найквиста. Например, частота произведения выборок может быть выбрана в 64 раза большей, чем частота Найквиста. Тогда для полосы частот в 20 кГц с номинальной частотой выборки 48 кГц фильтр с сильно корреляционным предсказанием будет работать с частотой 3 072 МГц. Причина выбора такой высокой частоты дискретизации заключается в следующем: необходимо убедиться, что выборочные данные имеют высокую корреляцию, так что простой одноотводный предсказатель будет давать малую ошибку предсказания, которая, в свою очередь, допускает работу устройства квантования с очень малым количеством бит в контуре коррекции ошибок. Простейшей формой устройства квантования является однобитовый преобразователь; по сути, это просто компаратор, который обнаруживает и сообщает знак разности сигнала. Как следствие, ошибкой предсказания сигнала является 1-битовое слово, которое имеет интересное преимущество — оно не требует следить за порядком слов при последовательной обработке.
Блок-схема одноотводного линейного предсказателя, изображенного на рис. 13.20, с небольшой модификацией показана на рис. 13.21. Отметим, что одноотводный контур предсказания-коррекции является сейчас просто интегратором и в декодере за контуром предсказания-коррекции следует восстанавливающий фильтр нижних частот. Этот фильтр устраняет выходящий за полосу частот шум квантования, который генерируется двухуровневым кодированием и распространяется за пределы информационной полосы частот этого кодирующего процесса. Кодер полностью описывается частотой дискретизации, размером шага квантования (для разрешения ошибки предсказания или допустимой ошибки контура) и восстанавливающим фильтром. Уравнения для предсказания и остаточной ошибки модулятора имеют следующий вид.
![]() (13.61,а)
(13.61,а)
![]() (13.61,6)
(13.61,6)
где п — выборочный индекс. Эта структура, иногда называемая дельта-модулятором, представляет собой процесс DPCM, при котором контур предсказания-коррекции состоит из цифрового аккумулятора.
13.3.4. Сигма-дельта-модуляция
Структура ![]() -Δ-модулятора может быть изучена с помощью различных средств; наиболее привлекательными являются модифицированный одноотводный преобразователь DPCM, а также преобразователь с обратной связью по ошибке. Начнем с модифицированного одноотводного преобразователя DPCM. Как указывалось ранее, контур зависит от высокой корреляции последовательных выборок, чего можно достичь за счет передискретизации.
-Δ-модулятора может быть изучена с помощью различных средств; наиболее привлекательными являются модифицированный одноотводный преобразователь DPCM, а также преобразователь с обратной связью по ошибке. Начнем с модифицированного одноотводного преобразователя DPCM. Как указывалось ранее, контур зависит от высокой корреляции последовательных выборок, чего можно достичь за счет передискретизации.
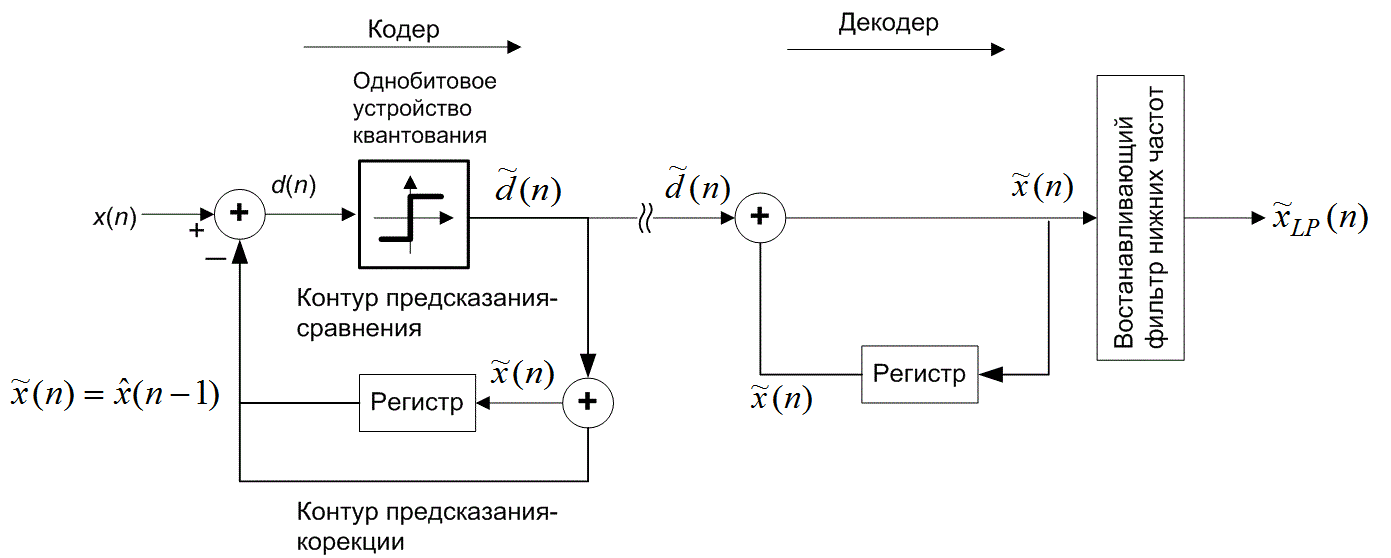 Рис. 13.21. Одноотводный, однобитовый кодер DPCM (дельта-модулятор)
Рис. 13.21. Одноотводный, однобитовый кодер DPCM (дельта-модулятор)
Корреляцию поступающих на модулятор выборочных данных можно усилить посредством предварительной фильтрации данных интегратором и компенсации этой фильтрации с помощью выходного фильтра-дифференциатора. Эта структура изображена на рис. 13.22, где интеграторы, дифференциатор и задержка выражены в терминах z-преобразования (см. приложение Д). Затем для получения выигрыша от реализации можно перегруппировать блоки прохождения сигнала. На вход кодера поступают сигналы с выходов двух цифровых интеграторов, которые затем суммируются и вводятся в контур квантования. Первая модификация состоит в том, чтобы использовать один цифровой интегратор, сдвигая два интегратора через суммирующее устройство в кодер. Вторая модификация состоит в том, что выходной фильтр-дифференциатор может быть сдвинут в декодер, что делает ненужным цифровой интегратор на входе в декодер. Все, что остается от декодера, — это восстанавливающий фильтр нижних частот. Полученная упрощенная форма модифицированной системы DPCM изображена на рис. 13.23. Эта форма, названная сигма-дельта-модулятором, содержит интегратор (сигма) и модулятор DPCM (дельта) [11].
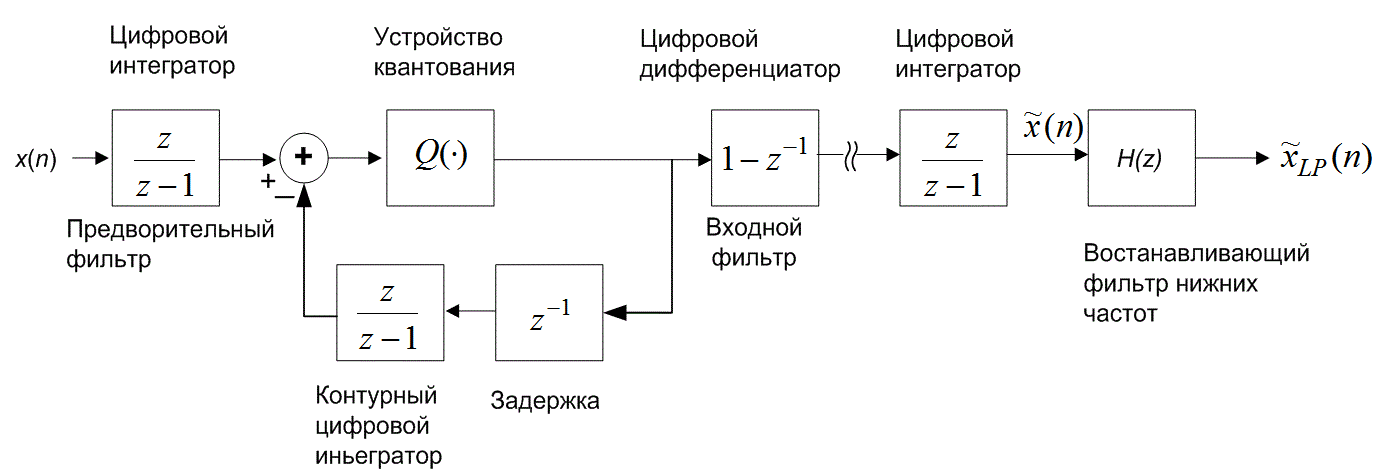
Рис. 13.22. Однобитовый дельта-модулятор
Понять ![]() -Δ-модулятор можно путем рассмотрения контура обратной связи по шуму. Понятно, что устройство квантования для получения выходного сигнала добавляет ошибку к своему входному сигналу. Когда выборки образовываются со значительным запасом, то высоко коррелируют не только выборки, но и ошибки. Когда ошибки высоко коррелируют, они предсказуемы, и, таким образом, они могут быть вычтены из сигнала, отправленного на устройство квантования прежде, чем произойдет процесс квантования. Когда сигнал и ошибка представляются передискретизованными выборками, предшествующая ошибка квантования может быть использована как хорошая оценка текущей ошибки.
-Δ-модулятор можно путем рассмотрения контура обратной связи по шуму. Понятно, что устройство квантования для получения выходного сигнала добавляет ошибку к своему входному сигналу. Когда выборки образовываются со значительным запасом, то высоко коррелируют не только выборки, но и ошибки. Когда ошибки высоко коррелируют, они предсказуемы, и, таким образом, они могут быть вычтены из сигнала, отправленного на устройство квантования прежде, чем произойдет процесс квантования. Когда сигнал и ошибка представляются передискретизованными выборками, предшествующая ошибка квантования может быть использована как хорошая оценка текущей ошибки.
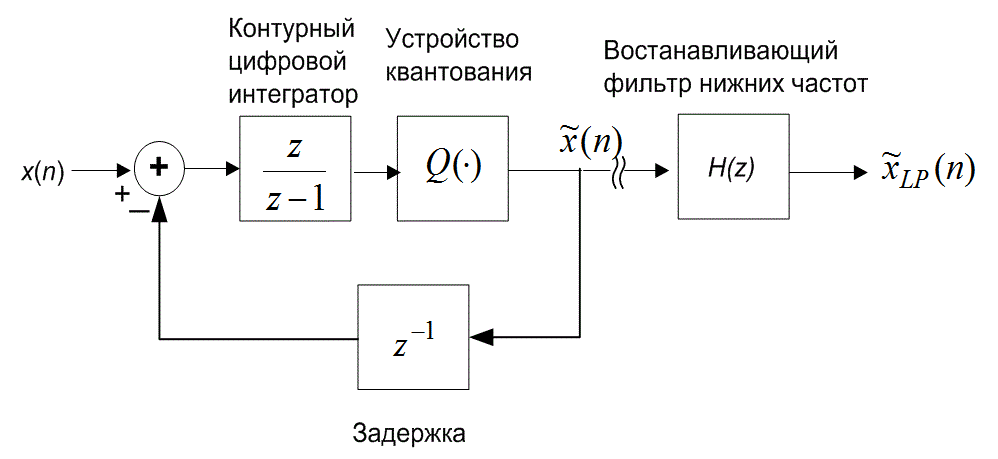
Рис. 13.23. ![]() -Δ -модулятор как перегруппированный Δ-модулятор
-Δ -модулятор как перегруппированный Δ-модулятор
Предшествующая ошибка, образованная как разность между входом и выходом устройства квантования, помещается в регистр запаздывания для использования в качестве оценки следующей ошибки квантования. Эта структура изображена на рис. 13.24. Схему прохождения сигнала на рис. 13.24 можно перерисовать так, чтобы акцентировать внимание на двух входах (сигнал и шум квантования) и на двух контурах (включающий устройство квантования и не включающий его). Эта форма изображена на рис. 13.25 и является общепринятой для точного изображения участка обратной связи цифрового интегратора. Эта схема имеет ту же структуру, что и представленная на рис. 13.23. Из рис. 13.25 видно, что выход ![]() -Δ-модулятора и его z-преобразование (см. приложение Д) могут быть записаны в следующем виде.
-Δ-модулятора и его z-преобразование (см. приложение Д) могут быть записаны в следующем виде.
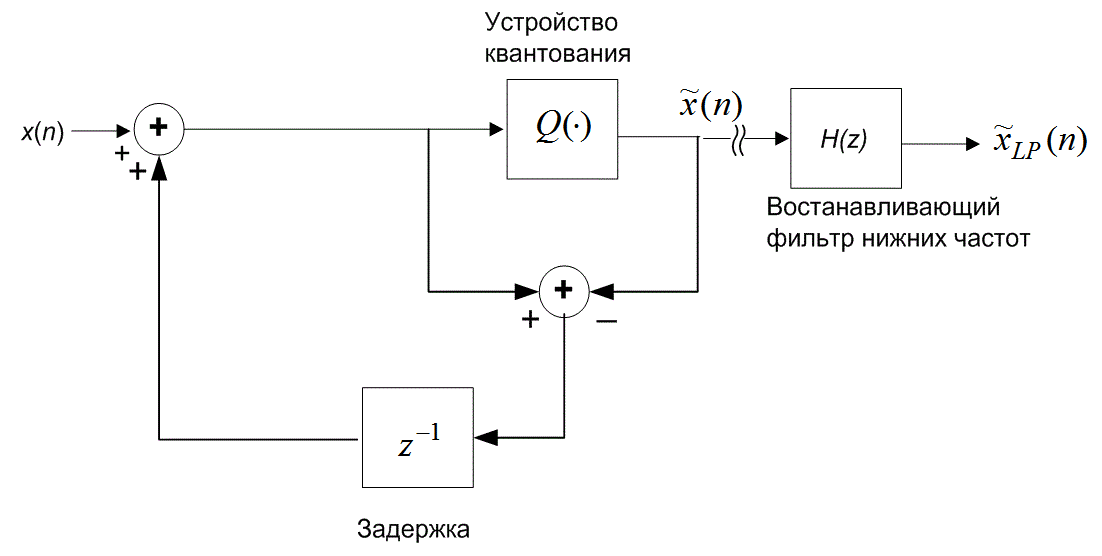
Рис. 13.24. ![]() -Δ-модулятор как процесс обратной связи по шуму
-Δ-модулятор как процесс обратной связи по шуму
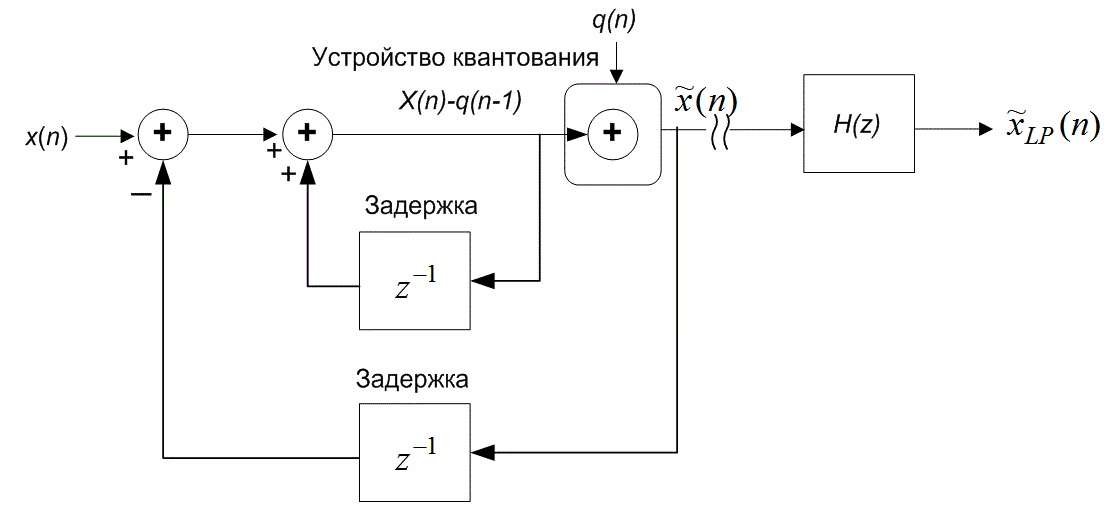
Рис. 13.25. Устройство квантования с обратной связью по шуму, изображенное как ![]() -Δ -модулятор
-Δ -модулятор
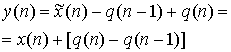 (13.62)
(13.62)
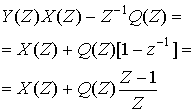 (13.63)
(13.63)
Равенство (13.63) свидетельствует о том, что контур не влияет на входной сигнал, поскольку в контуре циркулирует только шум, и только шум испытывает влияние контура. Интегратор в обратной связи по шумовому сигналу превращается (с помощью контура обратной связи единичного усиления) в дифференциатор источника шума.
Удобный механизм отображения частотной передаточной функции предлагает z-плоскость (подобно своему эквиваленту, j-плоскости) (см. приложение Д). Такая функция обычно описывается как дробь, числитель и знаменатель которой имеют форму полиномов, причем корни последних считаются, соответственно, нулями и полюсами передаточной функции. Эти нули и полюсы могут рассматриваться как поверхность над плоскостью, представляющей модуль передаточной функции. Эту поверхность можно представить в виде резинового полотна, натянутого относительно земли на столбики, расположенные в полюсах, и притянутого к земле в нулевых положениях. Модуль частотной характеристики представляет собой уровень этой поверхности при обходе единичной окружности в z-плоскости (или ось iω в s-плоскости). Отметим, что передаточная функция шума (noise transfer function — NTF), которая представляет собой функцию преобразования частоты контура, примененную к шуму, имеет полюс в начале координат и переходит через нуль в точке постоянной составляющей (z = e![]() ,
, ![]() = 0, так что z = 1). График, изображающий полюс и нуль функции NTF, спектральную характеристику NTF, а также типичный спектр входного сигнала представлены на рис. 13.26. Отметим, что нуль функции NTF расположен на постоянной составляющей, в окрестности которой шум квантования подавляется NTF. Таким образом, благодаря NTF возле постоянной составляющей нет значительного шума, и при этом спектр сигнала ограничен значительной передискретизацией, выполненной для того, чтобы спектр принадлежал малой окрестности вокруг постоянной составляющей с шириной примерно в 1,5% частоты дискретизации. Функцией восстанавливающего фильтра является подавление шума квантования вне полосы частот сигнала. Частота дискретизации на выходе фильтра теперь снижена для согласования с сокращенной полосой частот сигнала, практически свободного от шума. Дополнительное подавление шума может быть получено с помощью повышения порядка нуля функции NTF. Многие
= 0, так что z = 1). График, изображающий полюс и нуль функции NTF, спектральную характеристику NTF, а также типичный спектр входного сигнала представлены на рис. 13.26. Отметим, что нуль функции NTF расположен на постоянной составляющей, в окрестности которой шум квантования подавляется NTF. Таким образом, благодаря NTF возле постоянной составляющей нет значительного шума, и при этом спектр сигнала ограничен значительной передискретизацией, выполненной для того, чтобы спектр принадлежал малой окрестности вокруг постоянной составляющей с шириной примерно в 1,5% частоты дискретизации. Функцией восстанавливающего фильтра является подавление шума квантования вне полосы частот сигнала. Частота дискретизации на выходе фильтра теперь снижена для согласования с сокращенной полосой частот сигнала, практически свободного от шума. Дополнительное подавление шума может быть получено с помощью повышения порядка нуля функции NTF. Многие ![]() -Δ-модуляторы созданы с функциями NTF, которые имеют нули второго или третьего порядка. Поскольку нули NTF обращают мощность выходного шума в нуль, вряд ли имеет значение, какой уровень мощности шума подан в контур обратной связи. Следовательно, большинство
-Δ-модуляторы созданы с функциями NTF, которые имеют нули второго или третьего порядка. Поскольку нули NTF обращают мощность выходного шума в нуль, вряд ли имеет значение, какой уровень мощности шума подан в контур обратной связи. Следовательно, большинство ![]() -Δ-модуляторов создается для работы в системах, состоящих из 1-битовых преобразователей плюс несколько высокоточных модуляторов, каждый из которых работает с 4-битовыми преобразователями.
-Δ-модуляторов создается для работы в системах, состоящих из 1-битовых преобразователей плюс несколько высокоточных модуляторов, каждый из которых работает с 4-битовыми преобразователями.
13.3.4.1. Шум Z-Д-модулятора
В предыдущем разделе упоминалось, что с помощью Z-Д-модулятора можно добиться улучшения SNR в квантованных данных за счет передискретизации. Рассмотрим, как это происходит при передискретизованных фильтрованных данных с шумом AWGN, а затем изучим тот же процесс со сформированным шумом.
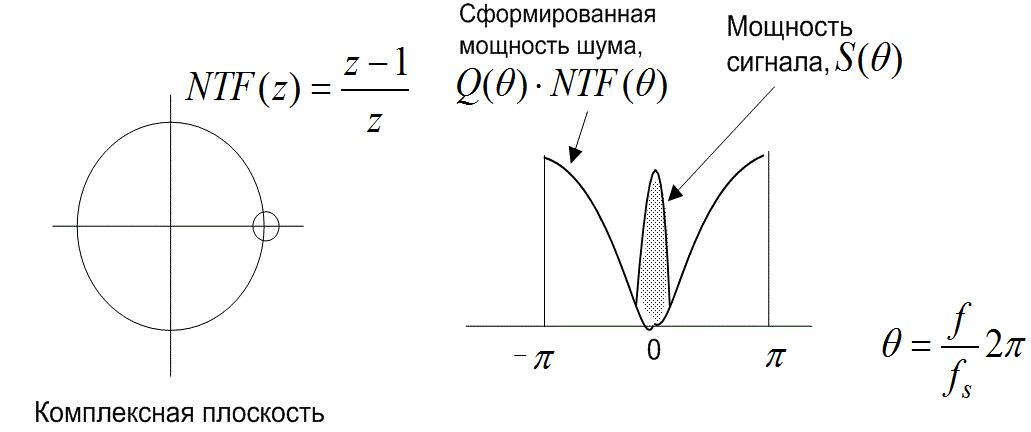
Рис. 13.26. Передаточная функция шума в z-плоскости, спектр мощности сигнала и сформированный шум ![]() -Δ-модулятора
-Δ-модулятора
Если шум квантования белый, а сигнал дискретизуется с частотой, превосходящей частоту Найквиста, белый шум равномерно распределен в спектральном интервале, равном частоте дискретизации. Этот интервал называется первой зоной Найквиста, или основной полосой. Поскольку энергия шума квантования зафиксирована на величине q2/12 (см. формулу (13.12)), спектральная плотность мощности шума квантования для сигнала, дискретизованного с частотой fx, должна быть q2/(12fx) Вт/Гц. Работа устройства квантования с повышенной частотой дискретизации уменьшает спектральную плотность мощности шума квантующего устройства в полосе частот сигнала. Передискретизованные данные могут численно фильтроваться с целью отсечения выходящего за полосу шума квантования, после чего можно снизить частоту дискретизации до частоты Найквиста. Если сигнал выбирается с частотой, вдвое превышающей частоту Найквиста, фильтрация отбросит половину мощности шума. Отсечение половины мощности шума сокращает среднеквадратическоезначение амплитуды квантованного шума в ![]() раз или мощности на 3 дБ. Чтобы уменьшить мощность шума на 6 дБ и таким образом улучшить шум квантования на 1 бит (см. формулу (13.24)), необходимо осуществить выборку с четырехкратной частотой и отсечь фильтром три четверти шума квантования. Итак, каждое удвоение частоты произведения выборки относительно частоты Найквиста приводит к улучшению SNR преобразователя белого шума на 3 дБ (или половину бита).
раз или мощности на 3 дБ. Чтобы уменьшить мощность шума на 6 дБ и таким образом улучшить шум квантования на 1 бит (см. формулу (13.24)), необходимо осуществить выборку с четырехкратной частотой и отсечь фильтром три четверти шума квантования. Итак, каждое удвоение частоты произведения выборки относительно частоты Найквиста приводит к улучшению SNR преобразователя белого шума на 3 дБ (или половину бита).
Рассмотрим частоту, на которой можно улучшить SNR уже сформированного шума преобразователя, производящего выборку с повышенной частотой. Передаточная функция шума формирующего ![]() -Δ-фильтра имеет нуль на постоянной составляющей, что приводит к нулю второго порядка в спектральной характеристике мощности фильтра. Если разложить спектральную характеристику фильтра в ряд Тейлора и отбросить все члены после первого ненулевого слагаемого, получим следующую простую аппроксимацию зависимости фильтра, справедливую в окрестности спектра сигнала.
-Δ-фильтра имеет нуль на постоянной составляющей, что приводит к нулю второго порядка в спектральной характеристике мощности фильтра. Если разложить спектральную характеристику фильтра в ряд Тейлора и отбросить все члены после первого ненулевого слагаемого, получим следующую простую аппроксимацию зависимости фильтра, справедливую в окрестности спектра сигнала.
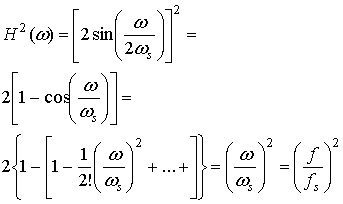 (13.64)
(13.64)
Здесь fs— частота дискретизации модулятора.
Мощность сформированного шума, "выжившая" после прохождения фильтра нижних частот, который следует за ![]() -Δ-модулятором, имеет следующий вид.
-Δ-модулятором, имеет следующий вид.
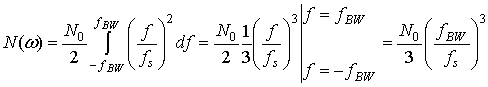 (13.65)
(13.65)
Отношение слагаемого шума для сигнала, выбранного с частотой fs к слагаемому шума для сигнала, выбранного с частотой 2 fs ,с последующей фильтрацией до той же выходной полосы частот сигнала fBW равно порядка 8-9 дБ. Таким образом, ![]() -Δ -модулятор с единственным нулем в функции NTF улучшает SNR на 9 дБ или на 1,5 бит при удвоении частоты дискретизации. Сигма-дельта-модуляторы, созданные с множественными цифровыми интеграторами и контурами обратной связи, имеют большее число переходов через нуль в NTF. Выполнив аналогичные выкладки, можно найти, что NTF
-Δ -модулятор с единственным нулем в функции NTF улучшает SNR на 9 дБ или на 1,5 бит при удвоении частоты дискретизации. Сигма-дельта-модуляторы, созданные с множественными цифровыми интеграторами и контурами обратной связи, имеют большее число переходов через нуль в NTF. Выполнив аналогичные выкладки, можно найти, что NTF ![]() -Δ-модулятора с 2 и 3 нулями улучшает SNR на 15 и 21 дБ (или 2,5 и 3,5 бит). Таким образом, двухнулевой
-Δ-модулятора с 2 и 3 нулями улучшает SNR на 15 и 21 дБ (или 2,5 и 3,5 бит). Таким образом, двухнулевой ![]() -Δ-модулятор, работающий с частотой, в 64 раза (или удвоенной шесть раз) превышающей частоту Найквиста, дает улучшение SNR на 90 дБ. Спектр, изображенный на рис. 13.27, был образован двухнулевым
-Δ-модулятор, работающий с частотой, в 64 раза (или удвоенной шесть раз) превышающей частоту Найквиста, дает улучшение SNR на 90 дБ. Спектр, изображенный на рис. 13.27, был образован двухнулевым ![]() -Δ-модулятором, и если учесть (1) потери в 6 дБ вследствие спектрального разложения реального сигнала, (2) уменьшение на 2 дБ амплитуды относительно полномасштабного сигнала, (3) потери в 3 дБ вследствие отбрасывания членов дискретного преобразования Фурье, то уровень шума на 79 дБ находится ниже спектрального максимума.
-Δ-модулятором, и если учесть (1) потери в 6 дБ вследствие спектрального разложения реального сигнала, (2) уменьшение на 2 дБ амплитуды относительно полномасштабного сигнала, (3) потери в 3 дБ вследствие отбрасывания членов дискретного преобразования Фурье, то уровень шума на 79 дБ находится ниже спектрального максимума.
a)
б)
Рис. 13.27. Однобитовый ![]() -Δ-модулятор: а) входной и выходной временные ряды; б) спектральная характеристика
-Δ-модулятор: а) входной и выходной временные ряды; б) спектральная характеристика
13.3.5. Сигма-дельта-аналого-цифровой преобразователь
![]() -Δ-аналого-цифровой преобразователь (analog-to-digital converter — ADC, АЦП) обычно реализуется как интегральная схема, построенная на основе
-Δ-аналого-цифровой преобразователь (analog-to-digital converter — ADC, АЦП) обычно реализуется как интегральная схема, построенная на основе ![]() -Δ-модулятора. Для образования полной системы схема должна содержать вспомогательные подсистемы: аналоговый фильтр защиты от наложения спектров (anti-alias filter), схему выборки-запоминания (sample-and-hold circuit), интегратор на переключаемых конденсаторах для модулятора (switched-capacitor integrator), цифро-аналоговый преобразователь (digital-to-analog converter — DAC, ЦАП) с обратной связью и цифровой фильтр повторной выборки (resampling filter). Вследствие высокой передискретизации, аналоговый фильтр защиты от наложения спектров может представлять собой просто RС-цепь с широкой полосой перехода, захватывающей многие октавы. Цифро-аналоговый преобразователь необходим для формирования аналогового сигнала обратной связи. Поскольку ЦАП включен в контур обратной связи, он не выигрывает от изменения коэффициента обратной связи, и, следовательно, его линейность и точность должны соответствовать уровню производительности всей системы.
-Δ-модулятора. Для образования полной системы схема должна содержать вспомогательные подсистемы: аналоговый фильтр защиты от наложения спектров (anti-alias filter), схему выборки-запоминания (sample-and-hold circuit), интегратор на переключаемых конденсаторах для модулятора (switched-capacitor integrator), цифро-аналоговый преобразователь (digital-to-analog converter — DAC, ЦАП) с обратной связью и цифровой фильтр повторной выборки (resampling filter). Вследствие высокой передискретизации, аналоговый фильтр защиты от наложения спектров может представлять собой просто RС-цепь с широкой полосой перехода, захватывающей многие октавы. Цифро-аналоговый преобразователь необходим для формирования аналогового сигнала обратной связи. Поскольку ЦАП включен в контур обратной связи, он не выигрывает от изменения коэффициента обратной связи, и, следовательно, его линейность и точность должны соответствовать уровню производительности всей системы. ![]() -Δ-модулятор сохраняет точность сигнала в ограниченном сегменте дискретного спектра. Для доступа к этому сегменту спектра высокой точности выход модулятора должен быть отфильтрован и дискретизован с пониженной частотой. Фильтр последующей обработки, расположенный за схемой модуляции, отбрасывает внешний шум, расположенный в полосе частот, существующей вследствие передискретизации. Обычно это фильтр повторной выборки с линейным изменением фазы и конечной импульсной характеристикой.
-Δ-модулятор сохраняет точность сигнала в ограниченном сегменте дискретного спектра. Для доступа к этому сегменту спектра высокой точности выход модулятора должен быть отфильтрован и дискретизован с пониженной частотой. Фильтр последующей обработки, расположенный за схемой модуляции, отбрасывает внешний шум, расположенный в полосе частот, существующей вследствие передискретизации. Обычно это фильтр повторной выборки с линейным изменением фазы и конечной импульсной характеристикой.
На рис. 13.27, а изображен входной синусоидальный сигнал, выбираемый с повышенной частотой, и соответствующий выходной сигнал однобитового ![]() -Δ-модулятора с двумя нулями. На рис. 13.27, б представлена спектральная характеристика выходного ряда. Отметим, что спектр сформированного шума в окрестности сигнала находится приблизительно на 80 дБ ниже максимума спектра входной синусоиды. Отметим также, что амплитуды выходного сигнала ограничены диапазоном ±1 и контур, по сути, выполняет модуляцию квадратного сигнала пропорционально амплитуде входного сигнала. На рис. 13.28 представлены временной ряд и спектр, полученный на выходе фильтра с дискретизацией на пониженной частоте, следующего за модулятором.
-Δ-модулятора с двумя нулями. На рис. 13.27, б представлена спектральная характеристика выходного ряда. Отметим, что спектр сформированного шума в окрестности сигнала находится приблизительно на 80 дБ ниже максимума спектра входной синусоиды. Отметим также, что амплитуды выходного сигнала ограничены диапазоном ±1 и контур, по сути, выполняет модуляцию квадратного сигнала пропорционально амплитуде входного сигнала. На рис. 13.28 представлены временной ряд и спектр, полученный на выходе фильтра с дискретизацией на пониженной частоте, следующего за модулятором.
13.3.6. Сигма-дельта-цифро-аналоговый преобразователь
S-Д-модулятор, изначально разрабатываемый как блок в АЦП, выполняет основную часть цифро-аналогового преобразования. Практически все высококачественное аудиооборудование и большинство цифро-аналоговых преобразователей систем связи снабжены ![]() -Δ-конвертерами. Процесс использует
-Δ-конвертерами. Процесс использует ![]() -Δ-модулятор как цифро-цифровое преобразование, которое преобразует высокоточное (скажем, 16-битовое) представление передискретизованных цифровых данных в представление низкой точности (скажем, 1-битовое). Передискретизованный однобитовый поток данных затем доставляется в 1-битовый ЦАП с двумя аналоговыми выходными уровнями, определенными с той же точностью, что и 16-битовый преобразователь. Преимущество использования однобитового ЦАП с высокой скоростью, но только с двумя уровнями, состоит в том, что скорость — это менее дорогой ресурс, чем точность. 2-уровневый высокоскоростной ЦАП заменяет ЦАП низкой скорости, который мог бы разрешить 65 536 различных уровней.
-Δ-модулятор как цифро-цифровое преобразование, которое преобразует высокоточное (скажем, 16-битовое) представление передискретизованных цифровых данных в представление низкой точности (скажем, 1-битовое). Передискретизованный однобитовый поток данных затем доставляется в 1-битовый ЦАП с двумя аналоговыми выходными уровнями, определенными с той же точностью, что и 16-битовый преобразователь. Преимущество использования однобитового ЦАП с высокой скоростью, но только с двумя уровнями, состоит в том, что скорость — это менее дорогой ресурс, чем точность. 2-уровневый высокоскоростной ЦАП заменяет ЦАП низкой скорости, который мог бы разрешить 65 536 различных уровней.
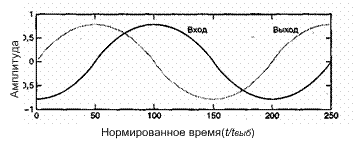
а)
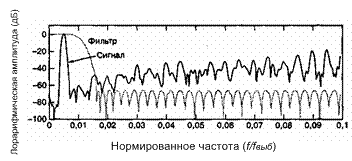
б)
Рис. 13.28. Фильтр последующей обработки, следующий за ![]() -Δ-модулятором: а) входной и выходной временные ряды; б) спектральная характеристика
-Δ-модулятором: а) входной и выходной временные ряды; б) спектральная характеристика
Очень простая аналоговая фильтрация низкого уровня, следующая за 1-битовым ЦАП, подавляет спектр внеполосного шума и выдает исходные цифровые данные с высокой точностью и в сокращенной полосе частот. Повторное квантование перевыбранных данных представляет собой обработку сигнала с использованием цифрового ![]() -Δ-модулятора. Единственная дополнительная задача, которую требуется выполнить при использовании
-Δ-модулятора. Единственная дополнительная задача, которую требуется выполнить при использовании ![]() -Δ-ЦАП, состоит в необходимости увеличения частоты произведения выборки в 64 раза, по сравнению с частотой Найквиста. Это выполняется с помощью интерполирующего фильтра, работающего на основе методов цифровой обработки сигналов; этот фильтр представляет собой стандартный блок, который имеется в большинстве систем, использующих ЦАП для перехода между источником цифрового сигнала и аналоговым выходом [12].
-Δ-ЦАП, состоит в необходимости увеличения частоты произведения выборки в 64 раза, по сравнению с частотой Найквиста. Это выполняется с помощью интерполирующего фильтра, работающего на основе методов цифровой обработки сигналов; этот фильтр представляет собой стандартный блок, который имеется в большинстве систем, использующих ЦАП для перехода между источником цифрового сигнала и аналоговым выходом [12].
В качестве стандартной иллюстрации процесса рассмотрим проигрыватель компакт-дисков, использующий интерполирующий фильтр для реализации преобразования с четырехкратным повышением частоты, приводящего к отделению периодического спектра, который связан с дискретными данными. Это позволяет сглаживающему фильтру, который следует за ЦАП, иметь более широкую полосу частот и, следовательно, меньшее число компонентов и меньшую стоимость реализации. Спецификация компакт-диска содержит такие термины, как, например, "4-to-1 oversampled" ("перевыбран с четырехкратной частотой"), чтобы отразить наличие интерполирующих фильтров. После того как с помощью интерполятора 1:4 будет выполнено четырехкратное увеличение частоты дискретизации, дальнейшее преобразование с использованием недорогого интерполирующего фильтра 1:16 является простой задачей. Для завершения аналогового процесса преобразования данные (теперь выбранные с 64-кратной частотой) подаются на полноцифровой ![]() -Δ-модулятор и однобитовый ЦАП. Эта структура изображена на рис. 13.29.
-Δ-модулятор и однобитовый ЦАП. Эта структура изображена на рис. 13.29.
Рис. 13.29. Схема прохождения сигнала в ![]() -Δ-цифро-аналоговом преобразователе
-Δ-цифро-аналоговом преобразователе
Существует много сигналов, которые по отношению к полосе частот сигнала выбираются с очень большой частотой. Эти сигналы могут быть легко преобразованы в аналоговую форму с использованием ![]() -Δ-модулятора и 1-битового ЦАП. Примерами являются контрольные сигналы схем АРУ, несущие ГУН и сигналы синхронизации ГУН. Многие системы используют
-Δ-модулятора и 1-битового ЦАП. Примерами являются контрольные сигналы схем АРУ, несущие ГУН и сигналы синхронизации ГУН. Многие системы используют ![]() -Δ-модулятор и 1-битовый ЦАП для генерации и формирования аналоговых сигналов управления.
-Δ-модулятор и 1-битовый ЦАП для генерации и формирования аналоговых сигналов управления.
13.4. Адаптивное предсказание
Усиление предсказания, которое получается в классических кодерах с предсказанием, пропорционально отношению дисперсии сигнала к дисперсии ошибки предсказания. Это объясняется тем, что при фиксированном уровне шума квантования требуется меньше бит для описания сигнала с меньшей энергией. Полезность кодера с предсказанием ограничена возможными рассогласованиями между сигналом источника и предсказывающим фильтром. Источники рассогласования связаны с переменным во времени поведением (т.е. нестационарностью) распределения амплитуды и спектральных или корреляционных свойств сигнала. Адаптивные кодеры (медленного действия) включают вспомогательные схемы для оценки параметров, требуемых для получения локальной оптимальной производительности. Эти вспомогательные цепи периодически программируют модификации для предсказания параметров цепи и таким образом избегают рассогласования предсказания. Комитет CCITT (International Telegraph and Telephone Consultative Committee — Международный консультативный комитет по телеграфии и телефонии, МККТТ) в качестве стандарта качественной телефонной связи выбрал адаптивную дифференциальную импульсно-кодовую модуляцию (Adaptive Differential Pulse Code Modulation — ADPCM) со скоростью 32 Кбит/с. Это дает экономию скорости передачи бит 2:1 по сравнению с 64 Кбит/с схемы РСМ с логарифмическим сжатием.
13.4.1. Прямая адаптация
В алгоритмах прямой адаптации входные данные, которые должны быть закодированы, буферизуются и обрабатываются с целью получения локальных статистик, таких как первые N выборочных значений автокорреляционной функции. Корреляционное значение Rx(0) с нулевым запаздыванием является кратковременной оценкой
дисперсии. Эта оценка используется для согласования автоматической регулировки усиления с целью получения оптимального согласования масштабированного входного сигнала с динамической областью устройства квантования. Этот процесс обозначается "AQF" от "adaptive quantization forward control" — контроль прямым адаптивным квантованием. Остающиеся N-1 корреляционных оценок используются для получения новых коэффициентов для фильтра с предсказанием. Этот процесс называется контролем прямым адаптивным предсказанием (adaptive prediction forward — APF). На рис. 13.30 изображена эта форма адаптивного алгоритма. Это расширение структуры, представленной на рис. 13.20. Здесь предсказывающие коэффициенты выводятся из входных данных, теперь называемых побочной информацией (side information). Они должны быть переданы вместе с ошибками предсказания с кодера на декодер. Скорость изменения этих адаптивных коэффициентов связана со временем, в течение которого входной сигнал может считаться локально стационарным. Например, речь, вызываемая механическим смещением речевых артикуляторов (язык, губы, зубы и т.д.), не может изменять характеристики быстрее, чем 10 или 20 раз за секунду. Это дает интервал обновления от 50 до 100 мс. Использование арифметически простых, но субоптимальных алгоритмов оценивания для вычисления локальных параметров фильтра делает необходимым более высокую скорость изменения. Для вычисления параметров 10-12-отводного фильтра принят интервал изменения 20 мс. На 10-отводных фильтрах можно получить усиление предсказания от 10 до 16 дБ, если используется адаптация с прямой связью и кодеры с предсказанием [13].
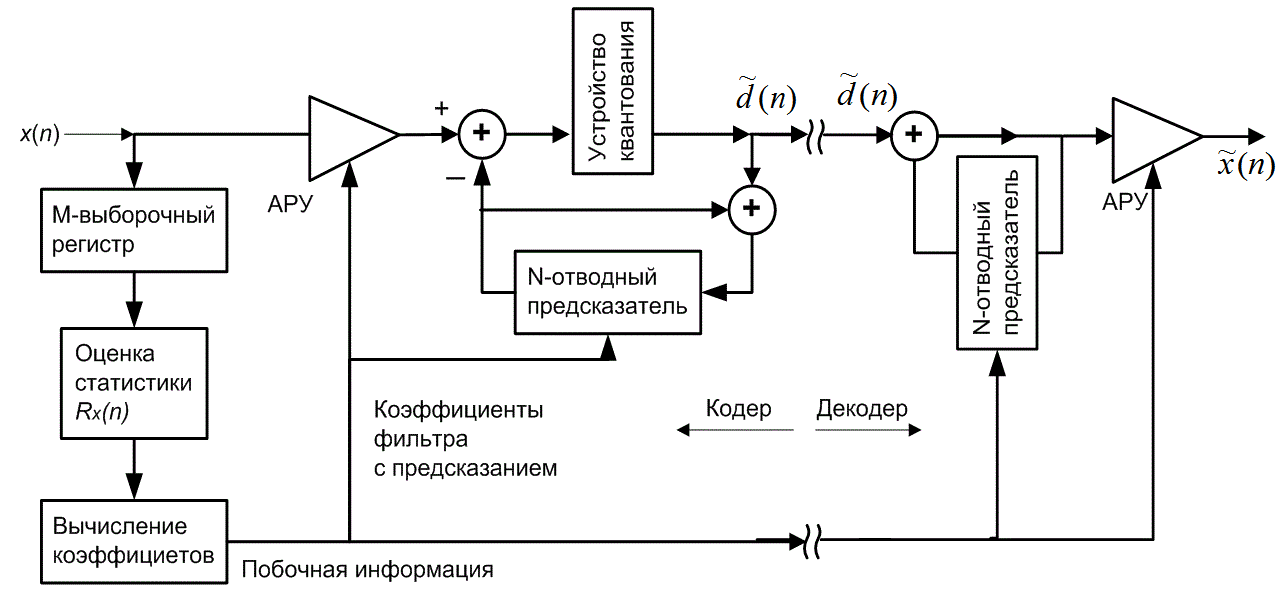
Рис. 13.30. Прямое адаптивное предсказание и кодирование квантования
13.4.2. Синтетическое/аналитическое кодирование
Изучаемые до сих пор схемы кодирования можно назвать кодерами формы сигналов. Они создают аппроксимации входных сигналов, минимизирующие некоторую меру расстояния между сигналом и аппроксимацией. Эти технологии являются общими и могут применяться к любому источнику сигнала. С другой стороны, синтетические/аналитические кодеры являются сильно сигнально-зависимыми. В частности, они созданы в основном для речевых сигналов. Эти кодеры играют на том, что слуховой механизм реагирует на амплитудное содержание кратковременного спектра сигнала, но при этом почти нечувствителен к его фазовой структуре.
Таким образом, этот класс кодеров формирует восстановленный сигнал, аппроксимирующий амплитуду и изменяющуюся во времени характеристику последовательности кратковременного спектра сигнала, но не делает попыток сохранить его относительную фазу.
Спектральные характеристики речи кажутся стационарными в течение порядка 20-50 мс. Существует множество технологий, которые анализируют спектральные характеристики голоса каждые 20 мс и используют результаты этого анализа для синтеза сигнала, дающего тот же кратковременный спектр мощности. Некоторые методы применяют модель механизма генерации речи, для которого параметры модели должны быть оценены с частотой обновления. Этот тип кодера наилучшим образом представлен в своих различных формах как линейный кодер с предсказанием (linear predictive coder — LPC). Разновидности кодеров LPC оперируют сигналом с помощью комбинаций спектральных модификаций и временных делений, которые, используя побочную информацию, сокращают количество временных выборок, требуемых для правильного воссоздания исходного спектра. Общим для всех синтетических/аналитических кодеров, используемых для речевых сигналов, является отсутствие необходимости в том, чтобы голосовой сигнал "выглядел" как оригинальный; достаточно, чтобы он "звучал" подобно ему.
13.4.2.1. Линейное кодирование с предсказанием
Адаптивные предсказатели, были созданы для предсказания или создания хороших оценок входного сигнала. В адаптивной форме предсказываемые коэффициенты вычисляются как побочная информация на основе периодического изучения входных данных. Затем разность между входом и предсказанием передается получателю для разрешения ошибки предсказания. Линейные кодеры с предсказанием (linear predictive coder — LPC) являются естественным расширением W-отводных кодеров с предсказанием. Если коэффициенты фильтра периодически вычисляются с помощью оптимального алгоритма, предсказание является настолько хорошим, что (в основном) информации об ошибке предсказания, которую нужно передавать приемнику, не существует. Вместо того чтобы передавать эти ошибки предсказания, система LPC передает коэффициенты фильтра и озвученное/неозвученное руководство к действию для фильтра. Таким образом, единственными данными, посланными в LPC, является высококачественная побочная информация классического адаптивного алгоритма. Модель LPC для синтеза голоса изображена на рис. 13.31. Кодеры LPC представляют собой ядро из смешанных кодеров, которое включает в себя кодер и управляющий генератор в контуре анализа через синтез, предназначенном для минимизации разности между входным и синтезированным сигналами. В сотовых телефонах для получения качественной связи со скоростью передачи данных ниже 9,6 Кбит/с используются кодеры PRE (Regular-Pulse Excited — активация регулярными импульсами) и CELP (Codebook-Excited Linear Predictive — линейное предсказание, активируемое кодовой книгой). В системе GSM (Global Systems for Mobile — глобальная система мобильной связи) используется сжатие RPE, тогда как для мобильных телефонных систем, созданных согласно стандарту IS-95 относительно множественного доступа с кодовым разделением каналов (code division multiple access — CDMA), применяется вариант CELP.
Эта модель, использующая 12-отводный синтезатор речи, нашла применение в детских говорящих играх.
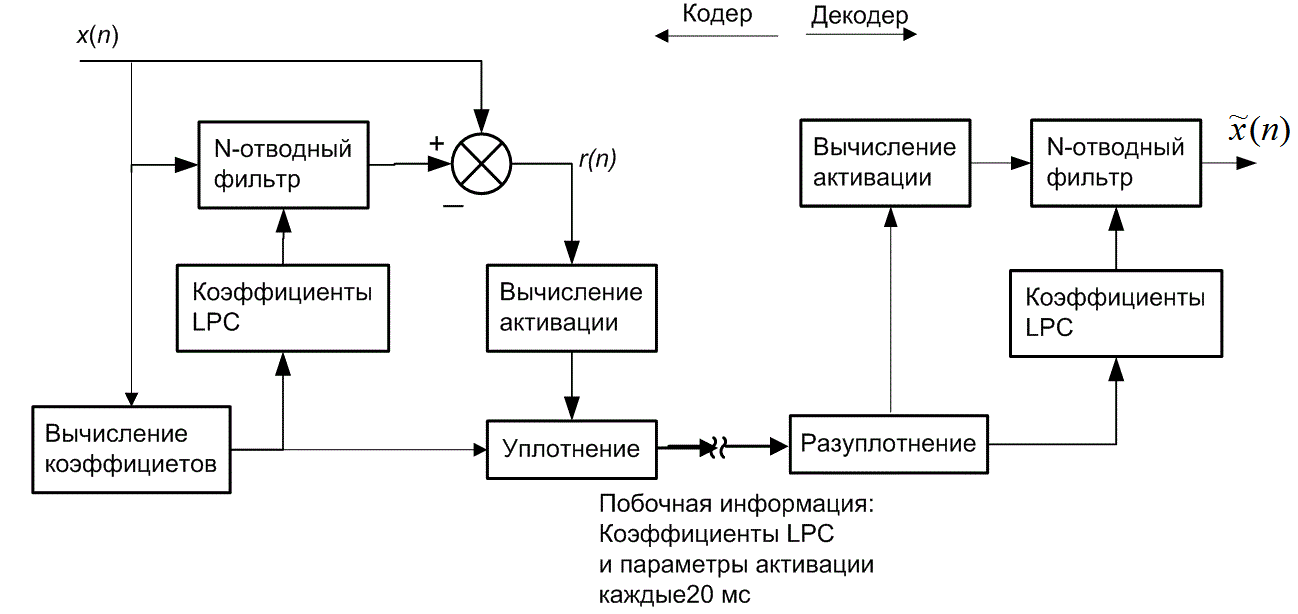
Рис. 13.31. Блочная диаграмма: моделирование речи с помощью линейного кодера с предсказанием
13.5. Блочное кодирование
Изучаемые до сих пор устройства квантования были скалярными по своей природе, поскольку они образовывали единственную выходную выборку, основанную на настоящей входной выборке и (возможно) N предшествующих выходных выборках. С другой стороны, блочные кодеры образуют вектор выходных выборок, основанный на настоящей и N предшествующих входных выборках. Эффективность кодирования (coding gain) сигнала представляет собой отношение входного SNR кодера к выходному. Если дисперсии шума на входе и выходе равны, эта эффективность просто представляет собой отношение входной дисперсии сигнала к выходной. Из данного отношения следует, что каждый бит разности между числом входных бит на выборку и средним числом выходных бит на выборку равносилен изменению эффективности на 6 дБ. Блочные кодеры могут давать впечатляющую эффективность кодирования. В среднем они могут представлять последовательности, квантованные по 8 бит, всего с 1 или 2 бит на выборку [8]. Технология блочного кодирования меняется, но общим является отображение входной последовательности в альтернативную систему координат. Это может быть отображение в подпространство большего пространства, так что отображение может быть необратимым [8]. В качестве альтернативы может быть использована информационно-зависимая схема редактирования для идентификации подпространства отображения, из которого получены квантованные данные. Технологии блочного кодирования часто классифицируются по своим схемам отображения, которые включают, например, векторные устройства квантования, кодеры различных ортогональных преобразований, кодеры с разделением по каналам, такие как кодер с многополосным кодированием. Блочные кодеры далее описываются через свои алгоритмические структуры, такие как кодовая книга, дерево, решетка, дискретное преобразование Фурье, дискретное косинус-преобразование, дискретное преобразование Уолша-Адамара (Walsh-Hadamard), дискретное преобразование Карунена-Лоэва (Karhunen-Loeve) и кодеры с блоком квадратурных зеркальных фильтров. Итак, изучим некоторые схемы блочного кодирования.
13.5.1. Векторное квантование
Векторные устройства квантования представляют собой, обобщение общепринятых скалярных устройств квантования. При скалярном квантовании для представления входной выборки скалярное значение выбирается из конечного множества возможных значений. Значение выбирается близким (в некотором смысле) к выборке, которую оно представляет. Мерой точности являются различные взвешенные среднеквадратические меры, которые поддерживают интуитивную концепцию расстояния в терминах обычной векторной длины. Обобщая, имеем, что в векторном квантовании вектор выбирается из конечного перечня возможных векторов, представляющих входной вектор выборки. Вектор выборки является близким (в некотором смысле) к вектору, который он представляет.
Каждый входной вектор может быть представлен точкой в N-мерном пространстве. Устройство квантования определяется с помощью деления этого пространства на множество неперекрывающихся объемов [14]. Эти объемы называются интервалами, полигонами и политопами, соответственно, для одно-, двух- и N-мерных векторных пространств. Задача векторного квантующего устройства состоит в определении объема, в котором расположен входной вектор. Выходом оптимального квантующего устройства является вектор, определяющий центр тяжести этого объема. Как и в одномерном квантующем устройстве, среднеквадратичсская ошибка зависит от расположения границы деления и многомерной функции плотности вероятности входного вектора.
Описание векторyого устройства квантования может рассматриваться как две точные задачи. Первая — это задача создания кода. Она связана с созданием многомерного объема квантования (или деления) и выбором допустимых выходных последовательностей. Вторая задача состоит в использовании кода и связана с поиском определенного объема при данном делении, который соответствует (согласно некоторому критерию точности) наилучшему описанию источника. Форма алгоритма, выбранного для контроля сложности кодирования и декодирования, может объединять две задачи — деление и поиск. Стандартными методами векторного кодирования являются алгоритмы кодовых книг, древовидные и решетчатые алгоритмы кодирования [15, 16].
13.5.1.1. Кодовые книги, древовидные и решетчатые кодеры
Кодеры, использующие кодовые книги, — это, по сути, алгоритмы поиска в таблице. Перечень возможных шаблонов (кодовых слов) внесен в память кодовой книги. Каждый шаблон снабжен адресом или точечным индексом. Программа кодирования ищет среди шаблонов тот, что расположен ближе всего к входному шаблону, и передает получателю адрес, сообщающий, где этот шаблон может быть найден в его кодовой книге. Древовидные и решетчатые кодеры являются последовательными. Таким образом, допустимые кодовые слова кода не могут выбираться независимо, они должны иметь структуру, которой можно управлять с помощью узловых точек. Это подобно структуре последовательных алгоритмов обнаружения-коррекции ошибок, которые обходят граф при образовании ветвящейся весовой аппроксимации входной последовательности. Древовидный граф подвержен экспоненциальному росту памяти при увеличении размерности или глубины. Решетчатый граф снижает проблему размерности, поскольку позволяет одновременно отслеживать выбранные траектории и связанные с ними траекторно-весовые метрики, называемые интенсивностью.
13.5.1.2. Совокупность кода
Кодовые векторы, внесенные в кодовую книгу, дерево или решетку, являются подобными или типичными векторами. Первый этап создания кода, в котором определяются вероятные кодовые векторы, называется заселением кода. Классические методы определения совокупности кодов есть детерминированными, стохастическими и итеративными. Детерминированная совокупность является перечнем предопределенных возможных выходов, основанных на простом субоптимальном или принятом пользователем критерии точности или на простом алгоритме декодирования. Примером детерминированного метода может служить кодирование выборок в трехмерном пространстве красного, зеленого и синего (RGB) компонентов цветного телевизионного сигнала. Для глаза не характерна одинаковая разрешающая способность для каждого цвета, так что кодирование может быть применено независимо к каждому цвету, чтобы отразить эту особенность восприимчивости. Результирующими объемами квантования могут быть прямоугольные параллелепипеды. Проблемой при независимом квантовании является то, что образы видны не в этой системе координат, а в координатах яркости, оттенка и насыщенности. Например, черно-белая фотография использует только координату яркости. Таким образом, независимо квантованные координаты RGB не приводят к уменьшению объема воспринимаемого пользователем искажения данного числа бит. Чтобы получить уменьшенное искажение, квантующие устройства должны разделить свое пространство на области, которые отражают деление в альтернативном пространстве. В качестве альтернативы, квантование может производиться независимо в альтернативном пространстве с использованием преобразующего кодирования, изучаемого в разделе 13.6. Детерминированное кодирование является наиболее простым для реализации, но дает наименьшую эффективность кодирования (наименьшее сокращение в скорости передачи бит при данном SNR).
Стохастическая совокупность должна выбираться на основании предполагаемой функции плотности вероятности входных выборок. Итеративные решения для оптимальных делений существуют и могут быть определены для любых предполагаемых функций плотности вероятности. Общие выборки моделируются с помощью предполагаемых функций плотности вероятности. При отсутствии таких функций могут использоваться итеративные методы, основанные на большой совокупности последовательностей испытаний, для получения разбиения и выходной совокупности. Последовательности испытаний могут включать в себя десятки тысяч входных выборок.
13.5.1.3. Поиск
При данном входном векторе и заселенной кодовой книге, дереве или решетке, алгоритм кодера должен производить поиск для определения наиболее адекватного векторного представителя. Исчерпывающий поиск среди всех возможных представителей будет гарантировать наилучшее отображение. Работа кодера улучшается для пространств большей размерности, но это приводит к росту сложности. Исчерпывающий поиск в пространстве большей размерности может быть весьма трудоемким. Альтернатива — следовать неисчерпывающей, субоптимальной схеме поиска с приемлемо малыми ухудшениями формы оптимальной траектории. Вообще, при выборе алгоритмов поиска основными аргументами часто являются требования памяти и вычислительной сложности. Примеры алгоритмов поиска включают в себя алгоритмы единичной траектории (ветвь наилучшего, выживания), алгоритмы множественной траектории и двоичные (метод последовательной аппроксимации) алгоритмы кодовой книги. Большинство алгоритмов поиска делают попытку определить и отбросить нежелательные модели без проверки всей модели.
13.6. Преобразующее кодирование
Одной из мер качества аппроксимации является взвешенная среднеквадратическая ошибка.
![]() (13.76)
(13.76)
где В(Х) — это весовая матрица, а ХT— транспонированный вектор X. Минимизация может быть вычислительно проще, если весовая матрица является диагональной. Диагональная весовая матрица дает координатное множество с нарушенной связью (некоррелированное), так что ошибка минимизации вследствие квантования может находиться независимо по каждой координате.
Таким образом, преобразующее кодирование включает следующую последовательность операций, которые изображены на рис. 13.32.
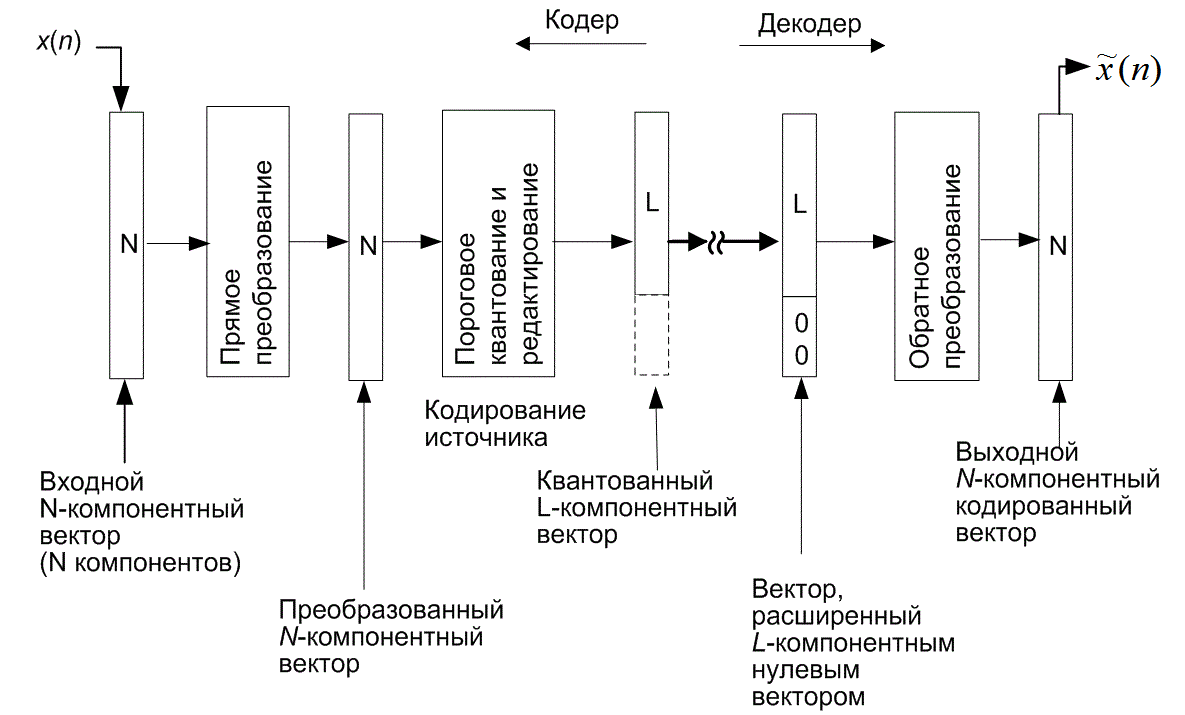
Рис. 13.32. Блочная диаграмма: преобразующее кодирование
1. К входному вектору применяется обратимое преобразование.
2. Коэффициенты преобразования квантуются.
3. Квантованные коэффициенты передаются и получаются.
4. Преобразование обращается с использованием квантованных коэффициентов.
Отметим, что при преобразовании не выполняется никакого кодирования источника; просто допускается более удобное описание вектора сигнала, которое позволяет легче
использовать кодирование источника. Задача преобразования состоит в отображении коррелированной входной последовательности в другую систему координат, в которой координаты имеют меньшую корреляцию. Напомним, что это в точности представляет собой задачу, выполняемую кодером с предсказанием. Кодирование источника происходит посредством присвоения битового значения различным коэффициентам преобразования. Как часть этого присвоения, коэффициенты могут быть разделены на подмножества, которые квантуются с помощью различного числа бит, но не с помощью различных размеров шага квантования. Это присвоение отражает динамическую область (дисперсию) каждого коэффициента и может быть взвешено мерой, отражающей важность (относительно человеческого восприятия) элемента, переносимого каждым коэффициентом [17]. Например, подмножество коэффициентов может быть сведено к нулевой амплитуде или может быть квантовано с помощью 1 или 2 бит.
Преобразование может быть независимым от вектора данных. Примерами таких преобразований являются дискретное преобразование Фурье (discrete Fourier transform — DFT, ДПФ), дискретное преобразование Уолша-Адамара (discrete Walsh-Hadamar transform — DWHT), дискретное косинус-преобразование (discrete cosine transform — DCT, ДКП) и дискретное наклонное преобразование (discrete slant transform — DST). Преобразование может быть также получено из вектора данных, как это делается в дискретном преобразовании Карунена-Лоэва (discrete Karhunen-Loeve transform — DKLT), иногда называемом преобразованием основного компонента (principal component transform — РСТ) [18]. Независимые от данных преобразования являются самыми простыми в реализации, но они не так хороши, как информационно-зависимые. Зачастую вычислительная простота является достаточным оправданием для использования независящих от данных преобразований. При хорошем субоптимальном преобразовании потери эффективности кодирования незначительны (как правило, меньше 2 дБ), и обычно при демонстрации рабочих характеристик упоминается ухудшение качества.
13.6.1. Квантование для преобразующего кодирования
Преобразующие кодеры обычно называются спектральными, поскольку сигнал описывается через свое спектральное разложение (в выбранном базисном множестве). Спектральные члены вычисляются для неперекрывающихся последовательных блоков входных данных. Таким образом, выход преобразующего кодера может рассматриваться как множество временных рядов, один ряд для каждого спектрального члена. Дисперсия каждого ряда может быть определена, и каждый ряд может быть квантован с использованием разного числа бит. Допуская независимое квантование каждого коэффициента преобразования, имеем возможность распределения фиксированного числа бит среди коэффициентов преобразования для получения минимальной ошибки квантования.
13.6.2. Многополосное кодирование
Преобразующие кодеры в разделе 13.6 были описаны как выполняющие деление входного сигнала на множество медленно изменяющихся временных рядов, каждый из которых связан с определенным базисным вектором преобразования. Спектральные члены (скалярные произведения данных с базисными векторами) вычисляются с помощью множества скалярных произведений. Множество скалярных произведений может быть вычислено с помощью множества фильтров с конечной импульсной характеристикой [19]. С этой целью преобразующий кодер может рассматриваться как выполняющий разделение полосы частот входных данных на отдельные каналы. Обобщая, получим, что многополосный кодер, который выполняет спектральное разделение полосы частот на отдельные каналы с помощью набора непрерывных узкополосных фильтров, может рассматриваться в качестве частного случая преобразующего кодера. (Типичный многополосный кодер изображен на рис. 13.33.)
Рис. 13.33. Многополосное кодирование
Спектральное разложение данных (как и фильтрование) допускает различное формирование класса специальных базисных множеств (т.е. спектральных фильтров), в частности базисных множеств, которые отражают приемлемые предпочтения пользователя и модели источника. Например, шум квантования, сгенерированный в полосе частот с большой дисперсией, будет ограничен этой полосой частот; он не будет проникать в соседнюю полосу частот, имеющую низкую дисперсию и, следовательно, уязвимую для низкоуровневых сигналов, которые замаскированы шумом. Имеем также выбор формирующих фильтров с равными или неравными полосами частот (рис. 13.33). Таким образом, можно независимо каждой подполосе приписать выборочную частоту, соответствующую ее ширине полосы частот, и число бит квантования, соответствующее ее дисперсии. Для сравнения, в общепринятом преобразующем кодировании амплитуда каждого базисного вектора выбирается с одинаковой частотой.
Многополосный кодер может быть создан как трансмультиплексор (преобразователь вида уплотнения). Здесь входной сигнал рассматривается в виде составленного из множества базисных функций, моделированных как независимые подканалы узкой полосы частот. Кодер разделяет входной сигнал на множество каналов с низкой скоростью передачи данных, уплотненных с временным разделением (time-division multiplexing — TDM). После квантования и передачи декодер обращает процесс фильтрации и повторной выборки, преобразуя каналы TDM обратно в исходный сигнал. При классическом подходе к этому процессу можно использовать множество узкополосных фильтров с этапами смешивания, фильтрации нижних частот и дискретизации на пониженной частоте (часто называемой децимацией, или прореживанием). Эта операция фильтрации сокращает входную полосу частот до выбранной полосы частот канала и повторно выбирает сигнал до самой низкой частоты, что позволяет избежать наложения разделенных полос частот данных. В приемнике производится обратный процесс. Разделенные на полосы данные для увеличения их частоты до желаемой частоты дискретизации проходят через интерполирующие фильтры и смешиваются обратно до их соответствующего спектрального положения. Чтобы создать исходный смешанный сигнал, они объединяются. Для кодирования речи или, в более общем смысле, для сигналов, которые связаны с механическим резонансом, желательны группы фильтров с неравными центральными частотами и неравными полосами частот. Такие фильтры называются пропорциональными наборами фильтров. Эти фильтры имеют логарифмически расположенные центральные частоты и полосы частот, пропорциональные центральным частотам. При рассмотрении на логарифмической шкале такое пропорциональное размещение выглядит как равномерное расположение полос частот и отражает спектральные свойства многих физических акустических источников.
13.7. Кодирование источника для цифровых данных
Кодирование с целью сокращения избыточности источника данных обычно влечет за собой выбор эффективного двоичного представления этого источника. Часто это требует замены двоичного представления символов источника альтернативным представлением. Замена обычно является временной и производится, для того чтобы достичь экономии при запоминании или передаче символов дискретного источника. Двоичный код, присвоенный каждому символу источника, должен удовлетворять определенным ограничениям, чтобы позволить обращение замены. К тому же код может быть далее ограничен спецификацией системы, например ограничениями памяти и простотой реализации.
Мы настолько привыкли к использованию двоичных кодов для представления символов источника, что можем забыть о том, что это всего лишь один из вариантов присвоения. Наиболее общим примером этой процедуры является двоичное присвоение количественным числительным (даже не будем рассматривать отрицательные числа). Можно прямо переводить в двоичную систему счисления, двоичные коды восьмеричных чисел, двоичные коды десятичных чисел, двоичные коды шестнадцате-ричных чисел, десятичные коды "два из пяти", десятичные коды с избытком три и т.д. В этом примере при выборе соответствия учитывается простота вычисления, определения ошибки, простота представления или удобство кодирования. Для определенной задачи сжатия данных основной целью является сокращение количества бит.
Конечные дискретные источники характеризуются множеством различных символов, Х(п), где п=1, 2,..., N — алфавит источника, a n - индекс данных. Полное описание требует вероятности каждого символа и совместных вероятностей символов, выбранных по два, три и т.д. Символы могут представлять двухуровневый (двоичный) источник, такой как черно-белые уровни факсимильного изображения, или многосимвольный источник, такой как 40 общих знаков санскрита. Еще одним общим многосимвольным алфавитом является клавиатура компьютерного терминала. Эти недвоичные символы отображаются посредством словаря, называемого знаковым кодом, в описание с помощью двоичного алфавита. (На рис. 2.2 представлен код ASCII, а на рис. 2.3 — код EBCDIC.) Стандартные знаковые коды имеют фиксированную длину, такую как 5-7 бит. Длина обычно выбирается так, чтобы существовало достаточно двоичных знаков для того, чтобы присвоить единственную двоичную последовательность каждому входному знаку алфавита. Это присвоение может включать большие и маленькие буквы алфавита, цифры, знаки пунктуации, специальные знаки и знаки управления, такие как знак забоя, возврата и т.д. Коды фиксированной длины обладают следующим свойством: знаковые границы отделены фиксированным числом бит. Это допускает превращение последовательного потока данных в параллельный простым счетом бит.
Двухкодовые стандарты могут определять один и тот же символ разными способами. Например, (7-битовый) код ASCII имеет достаточно бит, чтобы присвоить различные двоичные последовательности большой и маленькой версиям каждой буквы. С другой стороны, (5-битовый) код Бодо, который обладает только 32 двоичными последовательностями, не может сделать то же самое. Для подсчета полного множества знаков код Бодо определяет два контрольных знака, называемых переключением на печатание букв (letter shift — LS) и переключением на печатание цифр (figure shift — FS), которые должны использоваться как префиксы. При использовании эти контрольные знаки переопределяют отображение символа в двоичную форму. Это напоминает клавишу переключения регистра (shift key) на печатающем устройстве; эта клавиша полностью переопределяет новое множество символов на клавиатуре. Клавиатуры некоторых калькуляторов также имеют две клавиши переключения регистров, так что каждое нажатие клавиши имеет три возможных значения. Кроме того, некоторые команды текстового процессора используют двойные и тройные командные функции. В некотором смысле эти двух- и трехсловные команды представляют собой кодовое присвоение переменной длины. Эти более длинные кодовые слова присваиваются знакам (или командам), которые не встречаются так часто, как присвоенные отдельным кодовым словам. В обмен на использование соответствующих случаю более длинных слов получаем более эффективное запоминание (меньшая клавиатура) или более эффективную передачу источника.
Коды сжатия данных часто имеют переменную длину. Интуитивно ясно, что длина двоичной последовательности, присвоенной каждому символу алфавита, должна обратно зависеть от вероятности этого символа. Из всего сказанного очевидно, что если символ появляется с высокой вероятностью, он содержит мало информации и ему не должен выделяться значительный ресурс системы. Аналогично не будет казаться неразумным, что когда все символы одинаково вероятны, код должен иметь фиксированную длину. Возможно, наиболее известным кодом переменной длины является код (или азбука) Морзе (Morse code). Самуэль Морзе, чтобы определить относительную частоту букв в нормальном тексте, вычислил количество букв в шрифтовой секции печатающего устройства. Кодовое присвоение переменной длины отражает эту относительную частоту.
Если имеется существенное различие в вероятностях символов, может быть получено значительное сжатие данных. Чтобы достичь этого сжатия, необходимо достаточно большое число символов. Иногда, чтобы иметь достаточно большое множество символов, образуется новое множество символов, определенное из исходного множества и называемое кодом расширения. Эта процедура уже рассматривалась в примере 13.3, а общая технология будет изучена в следующем разделе.
13.7.1. Свойства кодов
Ранее обращалось внимание на свойства, которым должен удовлетворять полезный код. Некоторые из этих свойств являются очевидными, а некоторые — нет. Желаемые свойства стоят того, чтобы их перечислить и продемонстрировать. Рассмотрим следующий трехсимвольный алфавит со следующими вероятностными соответствиями.
|
|
|
|
a |
0.73 |
|
b |
0.25 |
|
c |
0.02 |
Входному алфавиту сопутствуют следующие шесть двоичных кодовых соответствий, где крайний правый бит является наиболее ранним.
|
Символ |
Код 1 |
Код 2 |
Код 3 |
Код 4 |
Код 5 |
Код 6 |
|
a |
00 |
00 |
0 |
1 |
1 |
1 |
|
b |
00 |
01 |
1 |
10 |
00 |
01 |
|
c |
11 |
10 |
11 |
100 |
01 |
11 |
Изучите предлагаемые соответствия и попытайтесь определить, какие коды являются практичными.
Свойство единственности декодирования. Единственным образом декодируемые коды позволяют обратить отображение в исходный символьный алфавит. Очевидно, код 1 в предыдущем примере не является единственным образом декодируемым, так как символам а и b соответствует одна и та же двоичная последовательность. Таким образом, первым требованием полезности кода является то, чтобы каждому символу соответствовала уникальная двоичная последовательность. При этих условиях все другие коды оказываются удовлетворительными до тех пор, пока мы внимательно не изучим коды 3 и 6. Эти коды действительно имеют уникальную двоичную последовательность, соответствующую каждому символу. Проблема возникает при попытке закодировать последовательность символов. Например, попытайтесь декодировать двоичное множество 10111 при коде 3. Это b, a, b, b, b; b, a, b, с или b, а, с, b? Попытка декодировать ту же последовательность в коде 6 вызывает аналогичные сложности. Эти коды не являются единственным образом декодируемыми, даже если отдельные знаки имеют единственное кодовое соответствие.
Отсутствие префикса. Достаточным (но не необходимым) условием того, что код единственным образом декодируем, является то, что никакое кодовое слово не является префиксом любого другого кодового слова. Коды, которые удовлетворяют этому условию, называются кодами, свободными от префикса. Отметим, что код 4 не является свободным от префикса, но он единственным образом декодируем. Свободные от префикса коды также обладают таким свойством — они мгновенно декодируемы. Код 4 имеет свойство, которое может быть нежелательным. Он не является мгновенно декодируемым. Мгновенно декодируемый код — это такой код, для которого граница настоящего кодового слова может быть определена концом настоящего кодового слова, а не началом следующего кодового слова. Например, при передаче символа b с помощью двоичной последовательности 10 в коде 4, получатель не может определить, является ли это целым кодовым словом для символа b или частью кодового слова для символа с. В противоположность этому, коды 2 и 5 являются свободными от префикса.
13.7.1.1. Длина кода и энтропия источника
В начале главы были описаны формальные концепции информационного содержания и энтропии источника. Самоинформация символа Хn в битах была определена следующим образом: I(Хn)=log2[1/P(Xn)]. С точки зрения того, что информация разрешает неопределенность, было осознано, что информационное содержание символа стремится к нулю, когда вероятность этого символа стремится к единице. Кроме того, была определена энтропия конечного дискретного источника как средняя информация этого источника. Поскольку информация разрешает неопределенность, энтропия является средним количеством неопределенности, разрешенной с использованием алфавита. Она также представляет собой среднее число бит на символ, которое требуется для описания источника. В этом смысле это также нижняя граница, которая может быть достигнута с помощью некоторых кодов сжатия данных, имеющих переменную длину. Действительный код может не достигать граничной энтропии входного алфавита, что объясняется множеством причин. Это включает неопределенность в вероятностном соответствии и ограничения буферизации. Средняя длина в битах, достигнутая данным кодом, обозначается как ![]() . Эта средняя длина вычисляется как сумма длин двоичных кодов, взвешенных вероятностью этих кодовых символов P(Xt).
. Эта средняя длина вычисляется как сумма длин двоичных кодов, взвешенных вероятностью этих кодовых символов P(Xt).
![]()
Когда говорится о поведении кода переменной длины, массу информации можно получить из знания среднего числа бит. В кодовом присвоении переменной длины некоторые символы будут иметь длины кодов, превосходящие среднюю длину, в то время как некоторые будут иметь длину кода, меньшую средней. Может случиться, что на кодер доставлена длинная последовательность символов с длинными кодовыми словами. Кратковременная скорость передачи битов, требуемая для передачи этих символов, будет превышать среднюю скорость передачи битов кода. Если канал ожидает данные со средней скоростью передачи, локальный избыток информации должен заноситься в буфер памяти. К тому же на кодер могут быть доставлены длинные модели символов с короткими кодовыми словами. Кратковременная скорость передачи битов, требуемая для передачи этих символов, станет меньше средней скорости кода. В этом случае канал будет ожидать биты, которых не должно быть. По этой причине для сглаживания локальных статистических вариаций, связанных с входным алфавитом, требуется буферизация данных.
Последнее предостережение состоит в том, что коды переменной длины создаются для работы со специальным множеством символов и вероятностей. Если данные, поступившие на кодер, имеют существенно отличающийся перечень вероятностей, буферы кодера могут быть не в состоянии поддержать несоответствие и будет происходить недогрузка или перегрузка буфера.
13.7.2. Код Хаффмана
Код Хаффмана (Huffman code) [20] — это свободный от префикса код, который может давать самую короткую среднюю длину кода ![]() для данного входного алфавита. Самая короткая средняя длина кода для конкретного алфавита может быть значительно больше энтропии алфавита источника, и тогда эта невозможность выполнения обещанного сжатия данных будет связана с алфавитом, а не с методом кодирования. Часть алфавита может быть модифицирована для получения кода расширения, и тот же метод повторно применяется для достижения лучшего сжатия. Эффективность сжатия определяется коэффициентом сжатия. Эта мера равна отношению среднего числа бит на выборку до сжатия к среднему числу бит на выборку после сжатия.
для данного входного алфавита. Самая короткая средняя длина кода для конкретного алфавита может быть значительно больше энтропии алфавита источника, и тогда эта невозможность выполнения обещанного сжатия данных будет связана с алфавитом, а не с методом кодирования. Часть алфавита может быть модифицирована для получения кода расширения, и тот же метод повторно применяется для достижения лучшего сжатия. Эффективность сжатия определяется коэффициентом сжатия. Эта мера равна отношению среднего числа бит на выборку до сжатия к среднему числу бит на выборку после сжатия.
Процедура кодирования Хаффмана может применяться для преобразования между любыми двумя алфавитами. Ниже будет продемонстрировано применение процедуры при произвольном входном алфавите и двоичном выходном алфавите.
Код Хаффмана генерируется как часть процесса образования дерева. Процесс начинается с перечисления входных символов алфавита наряду с их вероятностями (или относительными частотами) в порядке убывания частоты появления. Эти позиции таблицы соответствуют концам ветвей дерева, как изображено на рис. 13.34. Каждой ветви присваивается ее весовой коэффициент, равный вероятности этой ветви. Теперь процесс образует дерево, поддерживающее эти ветви. Два входа с самой низкой относительной частотой объединяются (на вершине ветви), чтобы образовать новую ветвь с их смешанной вероятностью. После каждого объединения новая ветвь и оставшиеся ветви переупорядочиваются (если необходимо), чтобы убедиться, что сокращенная таблица сохраняет убывающую вероятность появления. Это переупорядочение называется методом пузырька [21]. Во время переупорядочения после каждого объединения поднимается ("всплывает") новая ветвь в таблице до тех пор, пока она не сможет больше увеличиваться. Таким образом, если образуется ветвь с весовым коэффициентом 0,2 и во время процесса находятся две другие ветви уже с весовым коэффициентом 0,2, новая ветвь поднимается до вершины группы с весовым коэффициентом 0,2, а не просто присоединяется к ней. Процесс "всплытия" пузырьков к вершине группы дает код с уменьшенной дисперсией длины кода, в противном случае — код с такой же средней длиной, как та, которая получена посредством простого присоединения к группе. Эта сниженная дисперсия длины кода уменьшает шанс переполнения буфера.
Рис. 13.34. Дерево кодирования Хаффмана для шестизначного множества
В качестве примера этой части процесса кодирования применим процедуру Хаффмана к входному алфавиту, изображенному на рис. 13.34. Протабулированный алфавит и связанные с ним вероятности изображены на рисунке. После формирования дерева, чтобы различать две ветви, каждая вершина ветви снабжается двоичным решением "1/0". Присвоение является произвольным, но для определенности на каждой вершине будем обозначать ветвь, идущую вверх как "1", и ветвь, идущую вниз как "0". После обозначения вершин ветвей проследим траектории дерева от основания (крайнее правое положение) до каждой выходной ветви (крайнее левое положение). Траектория — это двоичная последовательность для достижения этой ветви. В следующей таблице для каждого конца ветви указана последовательность, соответствующая каждой траектории, где i = 1,..., 6.
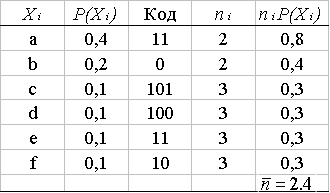
Находим, что средняя длина кода п для этого алфавита равна 2,4 бит на знак. Это не означает, что необходимо найти способ передачи нецелого числа бит. Это означает, что для передачи 100 входных символов через канал связи в среднем должно пройти 240 бит. Для сравнения, код фиксированной длины, требуемый для охвата шестизначного входного алфавита, должен иметь длину 3 бит и энтропию входного алфавита (используем формулу (13.32)), равную 2,32 бит. Таким образом, этот код дает коэффициент сжатия 1,25 (3,0/2,4) и достигает 96,7% (2,32/2,40) возможного коэффициента сжатия. В качестве еще одного примера рассмотрим случай, для которого можно продемонстрировать использование кода расширения. Изучим трехзначный алфавит, представленный в разделе 13.6.1.
|
Xi |
P(Xi) |
|
a |
0.73 |
|
b |
0.25 |
|
c |
0.02 |
Дерево кода Хаффмана для этого алфавита изображено на рис. 13.35, а его элементы протабулированы ниже.
Рис. 13.35. Дерево кодирования Хаффмана для трехзначного множества

Здесь i = 1, 2, 3. Средняя длина кода в приведенном примере равна 1,31 бит; она будет равна 2 бит для кода Хаффмана фиксированной длины. Коэффициент сжатия для этого кода равен 1,53. И снова, используя равенство (13.32), получим, что энтропия для алфавита равна 0,9443 бит, так что эффективность кода (0,944/1,31 = 72%) значительно меньше, чем для предыдущего примера.
Чтобы улучшить эффективность кодирования или достичь большего сжатия, следует переопределить алфавит источника. Больший алфавит источника увеличивает разнообразие, что является одним из требований при сокращении средней длины кода и увеличении числа ветвей дерева для присвоения кода переменной длины. Это делается посредством выбора знаков (по два) из алфавита источника, которые становятся новыми знаками в расширенном алфавите. Если предположить, что .символы независимы, вероятность каждого нового элемента является произведением отдельных вероятностей. Алфавит расширения имеет следующий вид.
Здесь i — 1, ..., 9, а кодовая последовательность для каждого Xi была найдена с использованием выше приведенной процедуры Хаффмана. Коэффициент сжатия для этого кода расширения равен 2,076, а эффективность кодирования — 97,7%. Коды расширения предлагают очень мощную технологию включения эффектов множеств символов, которые не являются независимыми. Например, в английском алфавите соседние буквы являются высоко коррелированными. Очень часто встречаются следующие пары букв.
|
th |
re |
in |
|
sh |
he |
e_ |
|
de |
ed |
s_ |
|
ng |
at |
r_ |
|
te |
es |
d_ |
Здесь подчеркивание представляет пробел. Наиболее общими английскими наборами трех букв являются следующие.
|
the |
and |
For |
|
ing |
ion |
ess |
Таким образом, вместо того чтобы производить кодирование Хаффмана отдельных букв, более эффективно расширить алфавит, включив все 1-кортежи плюс распространенные 2-и 3-кортежи, а затем произвести кодирование с помощью кода расширения.
13.7.3. Групповые коды
Во многих приложениях последовательность символов, которую необходимо передать или запомнить, характеризует последовательное кодирование определенных символов. Иногда, вместо того чтобы кодировать каждый символ последовательности, есть смысл описать группу с помощью подстановочного кода. В качестве примера рассмотрим случай, когда последовательности пробелов (наиболее употребимый символ в тексте) кодируются во многих протоколах связи с помощью символа управления, за которым следует счетчик символов. Протокол IBM 3780 BISYNC имеет опцию замены последовательности пробелов с помощью знака "IGS" (если имеем дело с EBCDIC) или "GS" (если имеем дело с ASCII), за которым следует счетчик от 2 до 63. Более длинные последовательности делятся на серии по 63 знака.
Групповое подстановочное кодирование может быть применено к исходному алфавиту символов или двоичному представлению этого алфавита. В частности, групповое кодирование является удачным для двоичных алфавитов, полученных от специфических источников. Наиболее важным коммерческим примером является факсимильное кодирование, используемое для передачи документов по мгновенной электронной почте [22].
13.7.3.1. Кодирование Хаффмана для факсимильной передачи
Факсимильная передача — это процесс передачи двухмерного образа как последовательности последовательных строчных разверток. В действительности наиболее распространенными образами являются документы, содержащие текст и цифры. Положение строчной развертки и положение вдоль развертки квантуются в пространственные расположения, которые определяют двухмерную координатную сетку элементов картинки, называемых пикселями. Ширина стандартного документа МККТТ определяется равной 8,27 дюймов (20,7 см ), а длина— 11,7 дюймов (29,2 см), почти 8,5 дюймов на 11,0 дюймов. Пространственное квантование для нормального разрешения составляет 1728 пикселей/строку и 1188 строк/документ. Стандарт также определяет квантование с высоким разрешением с теми же 1728 пикселями/строку, но с 2376 строками/документ. Общее число отдельных пикселей для факсимильной передачи с нормальным разрешением составляет 2 052 864, и оно удваивается для высокого разрешения. Для сравнения, число пикселей в стандарте NTSC (National Television Standards Committee — Национальный комитет по телевизионным стандартам) коммерческого телевидения составляет 480 х 460, или 307 200. Таким образом, факсимильное изображение имеет разрешение в 6,7 или 13,4 раза больше разрешения стандартного телевизионного образа.
Относительная яркость или затемненность развернутого образа в каждом положении на строке развертки квантуется в два уровня: Ч (черный) и Б (белый). Таким образом, сигнал, наблюдаемый на протяжении линии развертки, — это двухуровневая модель, представляющая элементы Ч и Б. Легко видеть, что горизонтальная развертка данной страницы будет представлять последовательность, состоящую из длинных групп уровней Ч и Б. Стандарт МККТТ схемы группового кодирования для сжатия отрезков Ч и Б уровней базируется на модифицированном коде Хаффмана переменной длины, который приведен в табл. 13.1. Определяются два типа шаблонов, группы Б и Ч. Каждый отрезок описывается кодовыми словами деления. Первое деление, названное созданное кодовое слово, определяет группы с длинами, кратными 64. Второе деление, именуемое оконечное кодовое слово, определяет длину оставшейся группы. Каждая серия из знаков Ч (или Б), длиной от 0 до 63, обозначает единственное кодовое слово Хаффмана, как и каждая группа длины 64![]() К, где К= 1, 2, ..., 27. Также кодом определен уникальный символ конца строки (end of line — EOL), который указывает, что дальше не следуют черные пиксели. Следовательно, должна начаться следующая строка, что подобно возврату каретки пишущей машинки [23].
К, где К= 1, 2, ..., 27. Также кодом определен уникальный символ конца строки (end of line — EOL), который указывает, что дальше не следуют черные пиксели. Следовательно, должна начаться следующая строка, что подобно возврату каретки пишущей машинки [23].
Таблица 13.1. Модифицированный код Хаффмана для стандарта
|
Длина группы |
Белые |
Черные |
Длина группы |
Белые |
Черные |
||
|
Созданные кодовые слова |
|||||||
|
64 128 192 256 320 384 448 512 576 640 704 768 832 896 |
11011 10010 010111 0110111 00110110 00110111 01100100 01100101 01101000 01100111 011001100 011001101 011010010 011010011 |
0000001111 000011001000 000011001001 000001011011 000000110011 000000110100 000000110101 0000001101100 0000001101101 0000001001010 0000001001011 0000001001100 0000001001101 0000001110010 |
960 1024 1088 1152 1216 1280 1344 1408 1472 1536 1600 1664 1728 EOL |
011010100 011010101 011010110 011010111 011011000 011011001 011011010 011011011 010011000 010011001 010011010 011000 010011011 000000000001 |
0000001110011 0000001110100 0000001110101 0000001110110 0000001110111 0000001010010 0000001010011 0000001010100 0000001010101 0000001011010 0000001011011 0000001100100 000000110010J 000000000001 |
||
|
Длина группы |
Белые |
Черные |
Длина группы |
Белые |
Черные |
||
|
Созданные кодовые слова |
|||||||
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
00110101 000111 0111 1000 1011 1100 1110 1111 10011 10100 00111 01000 001000 000011 110100 110101 101010 101011 0100111 |
000110111 010 11 10 011 ООП 0010 00011 000101 000100 0000100 0000101 0000111 00000100 00000111 000011000 0000010111 0000011000 0000001000 |
32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
00011011 00010010 00010011 00010100 00010101 00010110 00010111 00101000 00101001 00101010 00101011 00101100 00101101 00000100 00000101 00001010 00001011 01010010 01010011 |
000001101010 000001101011 000011010010 000011010011 000011010100 000011010101 000011010110 000011010111 000001101100 000001101101 000011011010 000011011011 000001010100 000001010101 000001010110 000001010111 000001100100 000001100101 000001010010 |
||
|
Длина группы |
Белые |
Черные |
Длина группы |
Белые |
Черные |
||
|
Созданные кодовые слова |
|||||||
|
19 20 21 22 23 24 25 26 27 28 29 30 31 |
0001100 0001000 0010111 0000011 0000100 0101000 0101011 0010011 0100100 0011000 00000010 00000011 00011010 |
00001100111 00001101000 00001101100 00000110111 00000101000 00000010111 00000011000 000011001010 000011001011 000011001100 000011001101 000001101000 000001101001 |
51 52 53 54 55 56 57 58 59 60 61 62 63 |
01010100 01010101 00100100 00100101 01011000 01011001 01011010 01011011 01001010 01001011 00110010 00110011 00110100 |
000001010011 000001000100 000000110111 000000111000 000000100111 000000101000 000001011000 000001011001 000000101011 000000101100 000001011010 000001100110 000001100111 |
||
Пример 13.8. Код группового кодирования
Используйте модифицированный код Хаффмана для сжатия строки
200 Б, 10 Ч, 10 Б, 84 Ч, 1424 Б,
состоящей из 1728 пиксельных элементов.
Решение
Используя табл. 13.1, определим, каким должно быть кодирование для этой модели (для
удобства чтения введены пробелы).
|
010111 192Б |
10011 8Б |
0000100 104 |
00111 10Б |
000000111 644 |
00001101000 204 |
000000000001 EOL |
Итак, требуется всего 56 бит, чтобы послать эту строку, содержащую последовательность 1188 бит.
13.7.3.2. Коды Лемпеля-Зива (ZIP)
Основной сложностью при использовании кода Хаффмана является то, что вероятности символов должны быть известны или оценены и как кодер, так и декодер должны знать дерево кодирования. Если дерево строится из необычного для кодера алфавита, канал, связывающий кодер и декодер, должен также отправлять кодирующее дерево как заголовок сжатого файла. Эти служебные издержки уменьшат эффективность сжатия, реализованную с помощью построения и применения дерева к алфавиту источника. Алгоритм Лемпеля-Зива (Lempel-Ziv) и его многочисленные разновидности используют текст сам по себе для итеративного построения синтаксически выделенной последовательности кодовых слов переменной длины, которые образуют кодовый словарь.
Код предполагает, что существующий словарь содержит уже закодированные сегменты последовательности символов алфавита. Данные кодируются с помощью просмотра существующего словаря для согласования со следующим коротким сегментом кодируемой последовательности. Если согласование найдено, код следует такой философии: поскольку получатель уже имеет этот сегмент кода в своей памяти, нет необходимости пересылать его, требуется только определить адрес, чтобы найти сегмент. Код ссылается на расположение последовательности сегмента и затем дополняет следующий символ в последовательности, чтобы образовать новую позицию в словаре кода. Код начинается с пустого словаря, так что первые элементы являются позициями, которые не ссылаются на более ранние. В одной, форме словаря рекуррентно формируется выполняемая последовательность адресов и сегмент символов алфавита, содержащийся в ней. Закодированные данные состоят из пакета <адрес словаря, следующий знак данных>, а каждый новый входной элемент словаря образован как пакет, содержащий адрес того словаря, за которым следует следующий символ. Рассмотрим пример такой технологии кодирования.
Закодируйте последовательность символов [a b a a b a b b b b b b b a b b b b a]
|
Закодированные пакеты: |
<0,а>, <0,b>, <l,a>, <2,a>, <2,b>, <5,b>, <5,a>, <6,b>, <4,-> |
||||||||
|
Адрес: Содержимое: |
1 a |
2 b |
3 aa |
4 ba |
5 bb |
6 bbb |
7 bba |
8 bbbb |
|
Начальный пакет <0,а> показывает нулевой адрес, потому что в словаре еще нет ни одной позиции. В этом пакете знак "а" является первым в последовательности данных, и он приписан к адресу 1. Следующий пакет <0,b> содержит второй знак данных b, который еще не был в словаре (следовательно, адресное значение есть 0); b приписывается адресу 2. Пакет <1,а> представляет кодирование следующих двух знаков "аа" с помощью вызова адреса 1 для первого и присоединения к этому адресу следующего знака "а". Пара знаков "аа" приписывается адресу 3. Пакет <2,а> представляет кодирование следующих двух знаков данных "bа" с помощью вызова адреса 2 для знака "b" и присоединения к этому адресу следующего знака "а". Пара знаков данных "bа" приписывается адресу 4 и т.д. Отметим, как завершается групповое кодирование. Восьмой пакет составлен из адреса 6, содержащего три знака "b", за которыми следует другой знак "b". В этом примере закодированные данные могут быть описаны с помощью трехбитового адреса с последующим битом 0 или 1 для определения присоединенного знака. В закодированной последовательности существует последовательность из 9 символов для общего содержимого в 36 бит для кодирования данных, содержащих 20 знаков. Как во многих схемах сжатия, эффективность кодирования не достигается для коротких последовательностей, как в этом примере, и имеется только для длинных последовательностей.
В другой форме алгоритма Лемпеля-Зива закодированные данные представлены как три словесных пакета вида <число знаков сзади, длина, следующий знак>. Здесь концепция адреса не используется. Наоборот, имеются ссылки на предшествующие последовательности данных, а также допускаются рекуррентные ссылки на параметр длины. Это показано в следующем примере, представленном как позиция <1,7,а>.
Закодируйте последовательность символов [a b a a b a b b b b b b b a b b b b b a]
|
Закодированные пакеты: |
<0,0,а>, <0,0,b>, <2,1,а>, <3,2,b>, <1,7,а>, <6,5,а> | |||||
|
Содержимое: |
a a |
b ab |
aa abaa |
bab abaabab |
bbbbbbba abaababbbbbbbba |
bbbbba вся последовательность |
Здесь также не видно эффективности кодирования для короткой серии данных. Разновидности кода ограничивают размер обратной ссылки, например 12-битовая для максимума в 4 096 пунктов обратной ссылки. Это ограничение уменьшает размер памяти, требуемой для словаря, и сокращает вероятность перегрузки памяти. Возможны также модификации кода, ограничивающие длину префикса или фразы, определенной первыми двумя аргументами <назад n1, вперед п2, ххх>, которые должны быть меньше некоторого значения (например, 16) с целью ограничения сложности обратного поиска во время кодирования. Алгоритм Лемпеля-Зива присутствует во многих коммерческих и пробных программах, которые включают сжатие LZ77, Gzip, LZ78, LZW и UNIX.
13.8. Примеры кодирования источника
Кодирование источника стало основной подсистемой в современных системах связи. Высокие требования к полосе частот и возможность запоминания явились мотивом его развития, в то время как интегрированные схемы и методы обработки сигналов предоставили такую возможность. Вторичной причиной широкого внедрения процесса в систему связи является определение общеиндустриальных стандартов, которые позволяют множественным поставщикам проводить рентабельную и конкурентоспособную реализацию процесса кодирования. Существуют стандарты МККТТ для кодирования источника или алгоритмов сжатия речи, аудио, неподвижных образов и движущихся изображений. В этом разделе будет изучено множество алгоритмов кодирования источника, основанных на стандартах, что должно продемонстрировать широкую применимость кодирования источника в системах связи и проиллюстрировать типичные уровни производительности.
13.8.1. Аудиосжатие
Аудиосжатие широко применяется в потребительских и профессиональных цифровых аудиопродуктах, таких как компакт-диски (compact disc — CD), цифровая аудиолента (digital audio type— DAT), мини-диск (mini-disk— MD), цифровая компакт-кассета (digital compact cassette — DCC), универсальный цифровой диск (digital versatile disc — DVD), цифровое аудиовешание (digital audio broadcasting — DAB) и аудиопродукция в формате МРЗ от экспертной группы по вопросам движущегося изображения (Motion Picture Experts Group — (MPEG). К тому же сжатие речи в телефонии, в частности сотовой телефонии, требуемое для экономии полосы частот и сбережения времени жизни батареи, дало начало процессу разработки множества стандартов сжатия речи. Различные алгоритмы применимы к речевым и потребительским сигналам более широкой полосы частот. Аудио- и речевые схемы сжатия можно для удобства разделить согласно приложениям, что отражает некоторую меру приемлемого качества. Рассмотрим параметры, описывающие это деление [24, 25].
Типичные значения параметров для трех классов аудиосигналов

13.8.2. Сжатие изображения
Мы часто слышали старое высказывание: Картина стоит тысячи слов. Верно ли оно? 1 000 слов содержит 6 000 знаков, которые, будучи закодированы как 7-битовые символы ASCII, требуют в общей сложности 42 000 бит. Какого размера образ (или картина) может быть описан с помощью 42 000 бит? Если используется монохромный (т.е. черный и белый) образ со стандартной 8-битовой шкалой оттенков серого, образ будет ограничен 5 250 пикселями (или элементами изображения). Этот образ может иметь размерность 70![]() 75 пикселей, и если предположить, что образ среднего качества (разрешение 300 пикселей на дюйм), в результате получаем, что наш образ составляет примерно
75 пикселей, и если предположить, что образ среднего качества (разрешение 300 пикселей на дюйм), в результате получаем, что наш образ составляет примерно ![]() дюйма на
дюйма на ![]() дюйма.
дюйма.
Определенно, требуется какое-то кодирование изображения.
Подойдем к проблеме с другой стороны. Насколько большим является изображение? Выбирая лист бумаги размером 8,5![]() 11,0 дюймов, содержащий изображение с разрешением 300 пикселей на дюйм, получаем образ, содержащий 8,5
11,0 дюймов, содержащий изображение с разрешением 300 пикселей на дюйм, получаем образ, содержащий 8,5![]() 300
300![]() 11,0
11,0![]() 300 или 8,4
300 или 8,4![]() 106 элементов изображения. Если это полноцветная картина с тремя цветами на элемент, каждый из которых описывается с помощью 8-битовых слов, находим, что образ содержит 2
106 элементов изображения. Если это полноцветная картина с тремя цветами на элемент, каждый из которых описывается с помощью 8-битовых слов, находим, что образ содержит 2![]() 108 бит, что эквивалентно 4,8
108 бит, что эквивалентно 4,8![]() 106 6-знаковых слов ASCII. Возможно, старое высказывание стоит обновить в соответствии с современным положением дел, сказав, что: Картина стоит порядка пяти миллионов слов. Для сравнения с другими форматами изображения отметим, что отдельный кадр телевизионного изображения высокой четкости содержит примерно 1,8
106 6-знаковых слов ASCII. Возможно, старое высказывание стоит обновить в соответствии с современным положением дел, сказав, что: Картина стоит порядка пяти миллионов слов. Для сравнения с другими форматами изображения отметим, что отдельный кадр телевизионного изображения высокой четкости содержит примерно 1,8![]() 106 пикселей, стандартное телевизионное изображение — это примерно 0,33
106 пикселей, стандартное телевизионное изображение — это примерно 0,33![]() 106 пикселей, а мониторы компьютера высшего класса содержат от 1,2 до 3,1
106 пикселей, а мониторы компьютера высшего класса содержат от 1,2 до 3,1![]() 106 элементов изображения. Технология дала нам принтеры низкой стоимости с высокой разрешающей способностью, сканеры, камеры и мониторы, позволяющие схватывать и представлять изображения с коммерческой и развлекательной целью. Хранение и передача этих образов существенно зависит от кодирования источника, призванного снизить требования к полосе частот и памяти. Существует множество стандартов, которые были разработаны для сжатия изображений. В следующем разделе будут изучены элементы двух основных схем сжатия [26, 27].
106 элементов изображения. Технология дала нам принтеры низкой стоимости с высокой разрешающей способностью, сканеры, камеры и мониторы, позволяющие схватывать и представлять изображения с коммерческой и развлекательной целью. Хранение и передача этих образов существенно зависит от кодирования источника, призванного снизить требования к полосе частот и памяти. Существует множество стандартов, которые были разработаны для сжатия изображений. В следующем разделе будут изучены элементы двух основных схем сжатия [26, 27].
13.8.2.1. JPEG
JPEG (Joint Photography Experts Group — объединенная группа экспертов в области фотографии) — это общее название, которое дано стандарту ISO/JPEG 10918-1 и стандарту ITU-T Recommendation T.81 "Цифровое сжатие постоянных изображений непрерывного тона". JPEG, в основном, известен как основанная на преобразовании схема сжатия с потерями. Сжатие с потерями допускает ошибки в построении сигнала. Уровни ошибок должны быть ниже порога восприимчивости человеческого глаза. JPEG поддерживает три режима работы, связанных с дискретным косинус-преобразованием (discrete cosine transform — DCT, ДКП): последовательное ДКП, прогрессивное ДКП и иерархическое, а также режим без потерь с использованием дифференциального предсказания и энтропии кодирования ошибки предсказания. ДКП — это численное преобразование, связанное с дискретным преобразованием Фурье (discrete Fourier transform — DFT, ДПФ) и предназначенное для получения спектрального разложения четно-симметричных последовательностей. Если входная последовательность является четно-симметричной, нет необходимости в синусоидальных компонентах преобразования. Следовательно, ДКП может заменить ДПФ.
Начнем с введения двухмерного преобразования ДКП 8![]() 8. Сначала прокомментируем использование ДКП для образования спектрального описания блока 8
8. Сначала прокомментируем использование ДКП для образования спектрального описания блока 8![]() 8 пикселей. Двухмерное ДКП — это сепарабельное преобразование, которое может быть записано в виде двойной суммы по двум размерностям. Сепарабельное ДКП производит восемь 8-точечных ДКП в каждом направлении. Следовательно, основной компоновочный блок представляет собой единичное 8-точечное ДКП. Возникает вопрос, почему используется ДКП, а не какое-либо другое преобразование, например ДПФ. Ответ связан с теоремой о дискретном представлении и преобразованием Фурье. Преобразование в одной области приводит к периодичности в другой. Если преобразуется временной ряд, его спектр становится периодичным. С другой стороны, если преобразуется спектр временного ряда, временной ряд периодически продолжается. Этот процесс известен как периодическое расширение и обозначается результирующей периодограммой. Периодическое расширение исходных данных (рис. 13.40) демонстрирует разрыв на границах, который ограничивает степень спектрального затухания в спектре величиной 1/f Можно образовать четное расширение данных, отображая данные относительно одной из границ. Если данные являются периодически расширенными, как показано на рис. 13.40, разрывность уже свойственна не амплитуде данных, а ее первой производной, так что степень спектрального затухания увеличивается до 1/f2. Более быстрая скорость спектрального затухания приводит к меньшему числу значимых спектральных членов. Еще одним преимуществом ДКП есть то, что поскольку данные четно-симметричные, их преобразование также является действительным и симметричным; следовательно, отсутствует необходимость в нечетно-симметричных базисных членах — функциях синуса.
8 пикселей. Двухмерное ДКП — это сепарабельное преобразование, которое может быть записано в виде двойной суммы по двум размерностям. Сепарабельное ДКП производит восемь 8-точечных ДКП в каждом направлении. Следовательно, основной компоновочный блок представляет собой единичное 8-точечное ДКП. Возникает вопрос, почему используется ДКП, а не какое-либо другое преобразование, например ДПФ. Ответ связан с теоремой о дискретном представлении и преобразованием Фурье. Преобразование в одной области приводит к периодичности в другой. Если преобразуется временной ряд, его спектр становится периодичным. С другой стороны, если преобразуется спектр временного ряда, временной ряд периодически продолжается. Этот процесс известен как периодическое расширение и обозначается результирующей периодограммой. Периодическое расширение исходных данных (рис. 13.40) демонстрирует разрыв на границах, который ограничивает степень спектрального затухания в спектре величиной 1/f Можно образовать четное расширение данных, отображая данные относительно одной из границ. Если данные являются периодически расширенными, как показано на рис. 13.40, разрывность уже свойственна не амплитуде данных, а ее первой производной, так что степень спектрального затухания увеличивается до 1/f2. Более быстрая скорость спектрального затухания приводит к меньшему числу значимых спектральных членов. Еще одним преимуществом ДКП есть то, что поскольку данные четно-симметричные, их преобразование также является действительным и симметричным; следовательно, отсутствует необходимость в нечетно-симметричных базисных членах — функциях синуса.
Поскольку амплитуда образа имеет сильную корреляцию на небольших пространственных интервалах, значение ДКП блока 8![]() 8 пикселей определяется, в основном, окрестностью постоянной составляющей и относительно небольшим числом иных значимых членов. Типичное множество амплитуд и их преобразование ДКП представлено на рис. 13.41. Отметим, что спектральные члены убывают, по крайней мере, как 1/f2 и большинство членов высокой частоты, в основном, нулевые. Спектр посылается на устройство квантования, которое использует стандартные таблицы квантования для присвоения бит спектральным членам согласно их относительным амплитудам и их психовизуальному значению. Для компонентов яркости и цветности используются различные таблицы квантования.
8 пикселей определяется, в основном, окрестностью постоянной составляющей и относительно небольшим числом иных значимых членов. Типичное множество амплитуд и их преобразование ДКП представлено на рис. 13.41. Отметим, что спектральные члены убывают, по крайней мере, как 1/f2 и большинство членов высокой частоты, в основном, нулевые. Спектр посылается на устройство квантования, которое использует стандартные таблицы квантования для присвоения бит спектральным членам согласно их относительным амплитудам и их психовизуальному значению. Для компонентов яркости и цветности используются различные таблицы квантования.
Рис. 13.41. Пиксели и амплитуды ДКП, описывающие один и тот же блок 8![]() 8 пикселей
8 пикселей
Чтобы использовать преимущество большого числа нулевых позиций в квантованном ДКП, спектральные адреса ДКП сканируются зигзагообразным образом, как изображено на рис. 13.42. Зигзагообразная модель обеспечивает длинную последовательность нулей. Это улучшает эффективность кодирования группового кода Хаффмана, описывающего спектральные выборки. На рис. 13.43 представлена блочная диаграмма кодера JPEG. Сигнал, доставленный на кодер, обычным образом представлен в виде растровой развертки с дискретными основными аддитивными цветами: красным, зеленым и синим (RGB). Цветная плоскость преобразуется в сигнал яркости (Y) и цветности 0,564![]() (В - Y) (обозначено как СB) и 0,713
(В - Y) (обозначено как СB) и 0,713![]() (R - Y) (обозначено как СR), используя преобразование цветового контраста, разработанное для цветного ТВ. Это отображение описывается следующим образом.
(R - Y) (обозначено как СR), используя преобразование цветового контраста, разработанное для цветного ТВ. Это отображение описывается следующим образом.
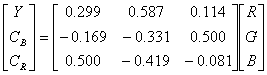
Здесь компонент Y образован для отражения чувствительности человеческого глаза к основным цветам.
Рис. 13.42. Зигзагообразное сканирование спектральных составляющих ДКП
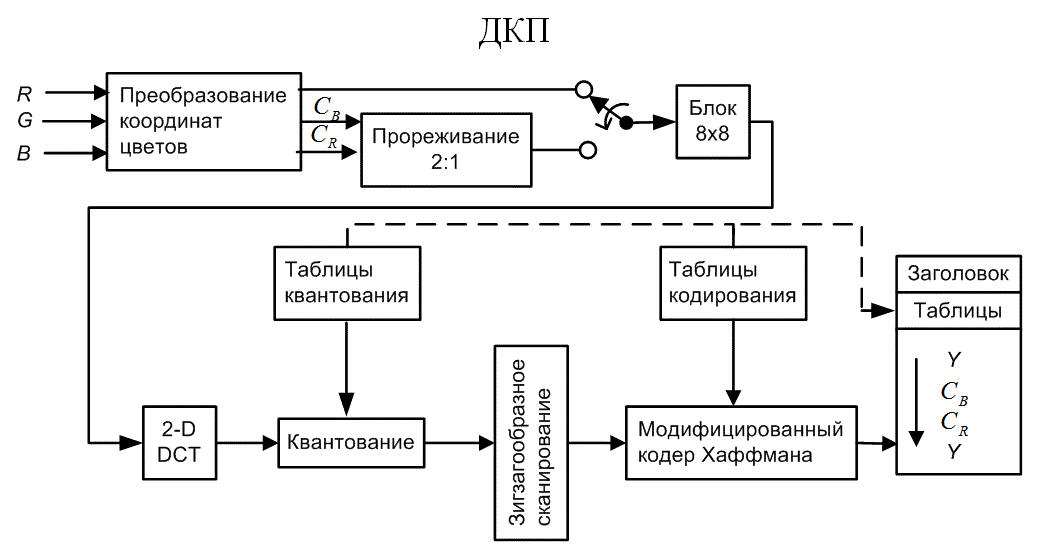
Рис. 13.43. Блочная диаграмма кодера JPEG
Глаз человека имеет разную чувствительность к цветным компонентам и компонентам яркости (черное и белое). Эта разница в способности к разрешению является следствием распределения рецепторов цвета (палочек) и рецепторов яркости (колбочек) на сетчатке. Человеческий глаз может различать 1-дюймовые чередующиеся черные и белые полоски со 180 футов (1/40 градуса). Для сравнения, 1-дюймовые сине-красные или сине-зеленые цветные полоски невозможно различить с расстояний, больших 40 футов (1/8 градуса). Следовательно, трехцветные образы требуют примерно на 1/25 (1/5 в каждом направлении) больше данных, чем нужно для получения черно-белого изображения. В далеком прошлом фотографы знали, что глаз требует очень малого числа цветных деталей. Чтобы придать образу цвет, существовала живая индустрия, в которой от руки раскрашивали черно-белые фотографии и почтовые открытки. Большинство аналоговых и цифровых цветных ТВ используют преимущество этой разницы в остроте восприятия для доставки дополнительных цветных компонентов через значительно сокращенную полосу частот. Стандарт NTSС определяет доставку всех трех цветов через полосу частот в 0,5 МГц, а>не 4,2 МГц, действительно требуемую яркостным компонентом. Аналогично JPEG использует преимущество разницы в восприятии и выбирает компоненты цветового контраста с половинной частотой в направлении сканирования (x), но не в направлении поперек линий развертки (у).
Сигналы цветового контраста и сигналы с пониженной частотой дискретизации последовательно представлены как блоки 8![]() 8 в двухмерном ДКП. Выходы ДКП квантуются с помощью соответствующей таблицы и затем зигзагообразно сканируются для передачи на кодер Хаффмана. JPEG использует кодер Хаффмана для кодирования коэффициентов переменной составляющей сигнала, но поскольку компоненты постоянной составляющей имеют высокую корреляцию между соседними блоками, для них используется дифференциальное кодирование. Разумеется, для формирования образа декодер обращает эти операции.
8 в двухмерном ДКП. Выходы ДКП квантуются с помощью соответствующей таблицы и затем зигзагообразно сканируются для передачи на кодер Хаффмана. JPEG использует кодер Хаффмана для кодирования коэффициентов переменной составляющей сигнала, но поскольку компоненты постоянной составляющей имеют высокую корреляцию между соседними блоками, для них используется дифференциальное кодирование. Разумеется, для формирования образа декодер обращает эти операции.
13.8.2.1.1. Варианты декодирования с помощью JPEG
Во время реконструкции образа декодер может работать последовательно, начиная с верхнего левого угла изображения и образуя блоки 8![]() 8 пикселей по мере их поступления. Это последовательный режим JPEG. В прогрессивном режиме кодирования образ сначала объединяется в блоки 8
8 пикселей по мере их поступления. Это последовательный режим JPEG. В прогрессивном режиме кодирования образ сначала объединяется в блоки 8![]() 8, образованные только компонентом постоянной составляющей в каждом блоке. Это очень быстрый процесс, который представляет крупноблочный, но распознаваемый в результате предварительного просмотра образ, — процесс, часто демонстрируемый в Internet при загрузке файлов GIF (Graphic Interchange Format), которые в начале передачи данных доставляют только компоненты постоянной составляющей. Затем изображение обновляется в каждом блоке 8
8, образованные только компонентом постоянной составляющей в каждом блоке. Это очень быстрый процесс, который представляет крупноблочный, но распознаваемый в результате предварительного просмотра образ, — процесс, часто демонстрируемый в Internet при загрузке файлов GIF (Graphic Interchange Format), которые в начале передачи данных доставляют только компоненты постоянной составляющей. Затем изображение обновляется в каждом блоке 8![]() 8, образованном из компонентов постоянной составляющей и первых двух соседних компонентов, представляющих следующее множество данных, доставленных на декодер. И наконец, образ обновляется при полном разрешении посредством полного множества коэффициентов, связанных с каждым блоком 8
8, образованном из компонентов постоянной составляющей и первых двух соседних компонентов, представляющих следующее множество данных, доставленных на декодер. И наконец, образ обновляется при полном разрешении посредством полного множества коэффициентов, связанных с каждым блоком 8![]() 8.
8.
При иерархическом кодировании образ кодируется и декодируется как перекрывающиеся кадры. Изображение с низким разрешением, выбранное с пониженной частотой (4:1 в каждом направлении), кодируется с использованием ДКП и квантованного коэффициента, образуя первый кадр. Изображение, полученное с помощью этого кадра, выбирается с более высокой частотой и сравнивается с версией исходного изображения большего разрешения (2:1 в каждом направлении), и разность, представляющая ошибку в формировании образа, снова кодируется как изображение MPEG. Два кадра, образованные двумя уровнями кодирования, используются для создания составного образа, который увеличивается и сравнивается с исходным образом. Разность между исходным образом и двумя уровнями реконструкций с более низкой разрешающей способностью формируется с наивысшей доступной разрешающей способностью, и снова применяется кодирование JPEG. Этот процесс полезен при доставке образов с последовательно высоким качеством реконструкции, подобно прогрессивному кодированию. Разница заключается в том, что имеется дополнительная разрешающая способность, но она не может быть послана до тех пор, пока не будет востребована. Пример: сканирование пользователем библиотеки изображений и требование окончательного качества после просмотра множества изображений. Еще одним примером может быть доставка одного уровня качества на дисплей персонального компьютера и более высокого уровня на дисплей рабочей станции с высокой разрешающей способностью.
В заключение отметим, что JPEG-2000 — это предложенный стандарт для определения новой системы кодирования изображения, предназначенной для Internet-приложений и мобильных приложений. В этой системе предлагается узкая полоса частот, множественная разрешающая способность, устойчивость к ошибкам, защищенность изображения и низкая сложность. Она базируется на алгоритмах волнового сжатия, и по отношению к JPEG в ней предлагается улучшенная эффективность сжатия со многими возможностями разрешения [28].
13.8.2.2. MPEG
MPEG (Motion Picture Experts Group — экспертная группа по вопросам движущегося изображения) представляет собой стандарты, созданные для поддержания кодирования движущихся изображений и ассоциированного аудио для среды цифрового запоминания со скоростями до 1,5 Мбит/с. MPEG-1, стандарт ISO 11172, был принят в ноябре 1992 года для разрешения записи полномасштабного видео на CD-плейерах, первоначально созданных для стерео-аудиовоспроизведения. MPEG-2, стандарт ISO 13818 или рекомендация ITU-T H.262, Универсальное кодирование движущихся изображений и ассоциированного аудио, принятый в ноябре 1994 года, дает большую гибкость форматов входа/выхода, большую скорость передачи данных и уделяет больше внимания таким системным требованиям, как передача и синхронизация, темам, не рассмотренным в MPEG-1. MPEG-2 поддерживает разновидности цифрового ТВ, охватывающие оцифрованное видео, которое отображает существующий аналоговый формат с определенным качеством посредством DVD (цифровой видеодиск) и HDTV (телевидение высокой четкости) с различными форматами изображения, частоты развертки, скорости сканирования пикселей, опций обратного сканирования и различными опциями выборки на повышенной частоте для компонентов цветового контраста. Ниже описывается основная теория работы простейшей версии MPEG-2.
MPEG-2. MPEG сжимает последовательность движущихся образов, используя преимущество высокой корреляции между последовательными движущимися изображениями. MPEG создает три типа изображений: интра-изображения (I-изображения), предсказанные (Р-изображения) и изображения двунаправленного предсказания (В-изображения). В MPEG каждое M-е изображение в последовательности может быть полностью сжато с использованием стандартного алгоритма JPEG; это I-изображения. Затем процесс сравнивает последовательные I-изображения и идентифицирует часть образа, которая была перемещена. Части образа, которые не были перемещены, переносятся в промежуточное изображение с помощью памяти декодера. После этого процесс отбирает подмножество промежуточных изображений, а затем предсказывает (посредством линейной интерполяции между I-изображениями) и корректирует расположение частей образа, которые были перемещены. Эти предсказанные и скорректированные образы являются Р-изображениями. Между I - и P-изображениями находятся B-изображения, которые включают стационарные части образа, не охваченные движущимися частями. Относительное расположение этих изображений показано на рис. 13.44. Отметим, что Р- и B-изображения допускаются, но не требуются, и их количество является переменным. Последовательность может быть образована без каких бы то ни было Р- или B-изображений, но последовательность, содержащая только Р-или B-изображения, не может существовать.
Рис. 13.44. Последовательность изображений при сжатии MPEG
I-изображения сжимаются так, как если бы они были изображениями JPEG. Это сжатие применяется к четырем непрерывным блокам 8![]() 8, называемым макроблоками. Макроблоки могут быть выбраны с пониженной частотой для последовательного сжатия цветных компонентов. Макроблоки и их опции выборки с пониженной частотой изображены на рис. 13.45. Сжатие I-кадра производится независимо от ранних или поздних изображений в последовательности кадров. Расстояние в последовательности, рассчитанное между I-изображениями, является регулируемым, и оно может быть сделано малым порядка 1 либо настолько большим, насколько позволяет память. Редактирование сечений в последовательности изображений и локальная программная вставка могут производиться только с I-изображениями. Поскольку одна вторая секунды — это приемлемая временная точность для производства такого дополнения, расстояние между I-изображениями обычно ограничено примерно 15 изображениями для стандарта NTSC (30 изображений в секунду) или 12 изображениями для Британского стандарта PAL (25 изображений в секунду).
8, называемым макроблоками. Макроблоки могут быть выбраны с пониженной частотой для последовательного сжатия цветных компонентов. Макроблоки и их опции выборки с пониженной частотой изображены на рис. 13.45. Сжатие I-кадра производится независимо от ранних или поздних изображений в последовательности кадров. Расстояние в последовательности, рассчитанное между I-изображениями, является регулируемым, и оно может быть сделано малым порядка 1 либо настолько большим, насколько позволяет память. Редактирование сечений в последовательности изображений и локальная программная вставка могут производиться только с I-изображениями. Поскольку одна вторая секунды — это приемлемая временная точность для производства такого дополнения, расстояние между I-изображениями обычно ограничено примерно 15 изображениями для стандарта NTSC (30 изображений в секунду) или 12 изображениями для Британского стандарта PAL (25 изображений в секунду).
Рис. 13.45. Обработка макроблока для выборки цветности с пониженной частотой
Первым этапом обработки, производимым MPEG, является определение, какой из макроблоков перемещается между I-изображениями. Это выполняется путем переноса каждого макроблока из одного I-кадра вперед к следующему и вычисления двухмерной взаимной корреляции в окрестности его исходного расположения. Для каждого сдвинутого макроблока определяются векторы движения, которые указывают направление и величину перемещения. Макроблоки, которые не сдвигались, являются стационарными в картинах между I-изображениями и могут быть вынесены вперед в промежуточных изображениях.
Следующий этап обработки в MPEG состоит в образовании Р-кадра между I-изображениями. Сначала предположим, что сдвинутые макроблоки перемещались линейно во времени между двумя положениями, определенными на первом этапе обработки. Каждый макроблок помещается на свое предсказанное положение в Р-кадре. Вычисляется взаимная корреляция в окрестности этого блока для определения истинного расположения макроблока в Р-кадре. Разность между предсказанным и истинным положениями макроблока является ошибкой предсказания, и эта ошибка сжимается с помощью ДКП и используется для коррекции Р-кадра. Та же информация передается на декодер, так что он может корректировать свои предсказания. На рис. 13.46 представлен сдвиг макроблока между I-изображениями и промежуточное Р-изображение.
Рис. 13.46. Движение макроблока между I- и Р-изображениями
В-изображения расположены между I- и Р-изображениями. В этих изображениях векторы движения передвигают сдвинутые макроблоки линейно во времени к их двунаправленным интерполированным положениям в каждом последовательном В-кадре в последовательности, I-изображения требуют максимального количества данных для описания их содержания, сжатого с помощью ДКП. Р-изображения требуют меньше данных. Они служат только для описания пикселей, ошибочно предсказанных на основании движения макроблоков в кадре. Остаток пикселей в кадре выносится вперед в память из предшествующего I-кадра. В-изображения являются наиболее эффективными изображениями множества. Они должны только линейно сдвинуть и скорректировать пиксели, охваченные и неохваченные в результате движения макроблоков через кадры.
Реконструкция образов на декодере требует того, чтобы последовательность образов была доставлена в порядке, необходимом для соответствующей обработки. Например, поскольку вычисление В-изображений требует информации от I- и Р-изображений или Р- и Р-изображений с обеих сторон, I- и Р-изображения должны быть доставлены первыми. Рассмотрим следующий пример требуемого порядка кадров на входе и выходе кодера и декодера.
Порядок изображений на входе кодер
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
I0 |
В1 |
В2 |
Р1 |
В3 |
В4 |
Р2 |
В5 |
В6 |
In+1 |
В1 |
В2 |
Р1 |
Порядок закодированных изображений на выходе кодера и входе декодера
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
I0 |
Р1 |
В1 |
В2 |
Р2 |
В3 |
В4 |
In+1 |
В5 |
В6 |
Р1 |
В1 |
В2 |
Порядок изображений на выходе декодера
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
I0 |
В1 |
В2 |
Р1 |
В3 |
В4 |
Р2 |
В5 |
В6 |
In+1 |
В1 |
В2 |
Р1 |
На рис. 13.47 представлена блочная диаграмма кодера MPEG. Отметим, что его структура представляет собой стандартную модель предсказания-коррекции. Отметим интересное соотношение между воспринимаемой глазом мерой качества изображения и мерой его активности. С одной стороны, когда образ содержит значительное движение, глаз воспринимает образы более низкого качества. С другой стороны, когда образ содержит мало движения, глаз чувствителен к помехам изображения. В кодере отсутствие движения влияет на активность кодирования и приводит к тому, что данные доставляются на выход буфера с более низкой скоростью. Буфер считает это индикатором стационарности образов и контролирует образ, допуская квантование ДКП более высокого качества. Скорость на выходе буфера фиксируется согласно требованиям линий связи. Для отображения средней входной скорости в фиксированную выходную применяется текущий контроль. Текущий контроль регистрирует низкую активность кодера, замечая, что его буфер опустошается быстрее, чем наполняется. Простой индикатор разности между входной и выходной скоростями — это расположение выходного адресного указателя. Если указатель движется по направлению к началу памяти буфера, указателю опустошения памяти, система увеличивает входную скорость, выбирая таблицу квантования, которая дает большее число бит на ДКП. Аналогично, если указатель движется по направлению к концу памяти буфера, указателю переполнения, система увеличивает выходную скорость, выбирая таблицу квантования, которая дает меньшее число бит на ДКП. Этот процесс согласовывает качество изображения с порогом качества, воспринимаемым глазом, сохраняя при этом среднюю выходную скорость канала.
Литература
1. Papoulis A. Probability, Random Variables, and Stochastic Processes McGraw-Hill Book Company, New York, 1965.
2. Hard F. J. Windows, Harmonic Analysis, and the Discrete Fourier Transform. Proc. IEEE, vol. 67, January, 1979.
3. Martin G. Gyroscopes May Cease Spinning. IEEE Spectrum, vol. 23, n. 2, February, 1986, pp. 48-53.
4. Vanderkooy J. and Lipshitz S. T. Resolution beyond the Least Significant Bit with Dither. J. Audio Eng. Soc., n. 3, March, 1984, pp. 106-112.
5. Blesser B. A. Digitization of Audio: A Comprehensive Examination of Theory, Implementation, and Current Practice. J. Audio Eng. Soc., vol. 26, n. 10, October, 1978, pp.739-771.
6. Sluyter R. J. Digitization of Speech. Phillips Tech. Rev., vol. 41, n. 7-8, 1983-84, pp. 201-221.
7. Bell Telephone Laboratories Staff. Transmission Systems for Communications. Western Electric Co. Technicai Publications, Winston-Salem, N. C, 1971.
8. Jayant N. S. and Noil P. Digital Coding of Waveforms/ Prentice-Hall, Inc., Englewood Cliffs, N. J., 1984.
9. Marcel J. D. and Gray A. H. Jr. Linear Prediction of Speech Springer-Verlag, New York, 1976.
10. Deller J., Proakis J. and Hansen J. Discrete-Time Processing of Speech Signals. Macmillan, New York, 1993.
11. Candy J. and'Temes G. Oversampling Delta-Sigma Data Converters. IEEE Press, 1991.
12. Dick С. and Harris F. FPGA Signal Processing Sigma-Delta Modulation IEEE Signal Proc. Mag., Vol. 17., n. 1, January, 2000, pp. 20-35.
13. Cummisky P., Jayant N. and Flanagan J. Adaptive Quantization in Differential PCM Coding of Speech/ Bell Syst. Tec J., Vol. 52, 1973, pp. 115-119.
14. Gersho A. Asymptotically Optimal Block Quantization. IEEE Trans. Inf. Theory, vol. IT25, n. 4, July, 1979, pp. 373-380.
15. Gersho A. On the Structure of Vector Quantizers. IEEE Trans. Inf. Theory, vol. IT28, n. 2, March, 1982, pp. 157-166. i
16. Abut H. Vector Quantization. IEEE Press, 1990.
17. Jeffress L. Mascing; in J. Tobias, ed., Foundations of Modern Auditory Theory. Academic Press, Inc., New York, 1970.
18. Lynch T. J. Data Compression Techniques and Applications. Lifetime Learning Publications, New York, 1985.
19. Schafer R. W. and Rabiner L. R. Design of Digital Filter Banks for Speech Analysis. Bell Syst. Tech. J., vol. 50, n. 10, December, 1971, pp. 3097-3115.
20. Huffman D. A. A Method for the Construction of Minimum Redudancy Codes. Proc. IRE, vol. 40, September, 1952, pp. 1098-1101.
21. Hamming R. W. Coding and Information Theory. Prentice-Hall, Inc., Englewood Cliffs, N.J., 1980.
22. Hunter R. and Robinson A. International Digital Facsimile Coding Standard. Proc. IEEE, Vol. 68, n. , 7, July, 1980, pp. 854-867.
23. McGonnel K., Bodson D. and Urban S. FAX: Facsimile Technology and Systems. Artech House, 1999.
24. Cox R. Three New Speech Coders From the ITU Cover a Range of Applications. IEEE Comm. Mag., Vol. 35, n. 9, September, 1997, pp. 40-47.
25. Noll P. Wideband Speech and Audio Coding. IEEE Comm. Mag., Vol. 31, n. 11, November, 1993, pp. 34-44.
26. Solari S. Digital Video and Audio Compression. McGraw-Hill, New York, 1997.
27. Rzeszewski T. Digital Video: Concepts and Applications Across Industries. IEEE Press, 1995.
28. Ebrahimi Т., Santa Cruz. D., Christopoulos C., Askelof J., Larsson M. JPEG 2000 Still Image Coding Versus Other Standards. SPIE International Symposium, 30 July-4 August 2000, Special Session on JPEG2000, San Diego, CA.
Задачи
13.1. Дискретный источник генерирует три независимых символа А, В и С с вероятностями 0,9, 0,08 и 0,02. Определите энтропию источника.
13.2. Дискретный источник генерирует два независимых символа А и В с следующими условными вероятностями.
P(A|А) = 0,8 Р(В|А) = 0,2
Р(А|В) = 0,6 Р(B|В) = 0,4
а) Определите вероятности символов А и В.
б) Определите энтропию источника.
в) Определите энтропию источника, если символы независимы и имеют те же вероятности.
13.3. 16-битовый аналого-цифровой преобразователь работает с входным диапазоном в ±5,0 В.
а) Определите размер квантили.
б) Определите среднеквадратическое напряжение шума квантования.
в) Определите среднее SNR (вследствие квантования) для полномасштабного входного синусоидального сигнала.
г) Считайте, что расстояние в 100 миль, пройденное автомобилем, измеряется с той же точностью, что и в 16-битовом преобразрвателе. Чему равна среднеквадратическая ошибка в футах?
13.4. 10-битовый АЦП работает с входным диапазоном в ±5,0 В.
а) Определите размер единичного шага квантили.
б) Для (полномасштабной) синусоиды в 5,0 В определите выходное отношение сигнала к шуму квантования.
в) Для синусоиды ( ![]() полного масштаба) в 0,050 В определите выходное отношение сигнала к шуму квантования.
полного масштаба) в 0,050 В определите выходное отношение сигнала к шуму квантования.
г) Для входного сигнала, имеющего гауссово распределение амплитуд, вероятность насыщения контролируется присоединением входного аттенюатора, так что уровень насыщения соответствует четырем среднеквадратическим отклонениям. Определите выходное отношение сигнала к шуму квантования.
д) Определите вероятность насыщения сигнала, описанного в п. г.
13.5. Определите оптимальную характеристику сжатия для входной функции плотности (аппроксимации непрерывной функции плотности), изображенной на рис. 313.1.
Рис. 313.1
13.6. 10-битовый преобразователь, использующий μ-закон, работает с полным диапазоном в ±5,0 В.
а) Если μ = 100, определите выходное отношение сигнала к шуму квантования для синусоиды в 5,0 В (полномасштабной).
б) Если μ = 100, определите выходное отношение сигнала к шуму квантования для синусоиды в 0,050 В (![]() полного масштаба).
полного масштаба).
в) Повторите пп. а и б для μ = 250.
13.7. Записывающая система компакт-диска отображает каждый из двух стереосигналов с помощью 16-битового АЦП в 44,l![]() 103 выборок/с.
103 выборок/с.
а) Определите выходное отношение сигнала к шуму для полномасштабной синусоиды.
б) Если записываемая музыка создана для коэффициента пиковой импульсной нагрузки (отношение максимального значения к среднеквадратическому), равного 20, определите среднее выходное отношение сигнала к шуму квантования.
в) Поток оцифрованных битов дополнен битами коррекции ошибок, битами подстановки (для извлечения сигнала ФАПЧ), полями битов изображения и управления. Эти дополнительные биты составляют 100% служебных издержек, т.е. для каждого бита, генерированного АЦП, сохраняется 2 бит. Определите выходную скорость передачи битов воспроизводящей системы проигрывания компакт-дисков.
г) На компакт-диск можно записать порядка часа музыки. Определите число бит, записанных на компакт-диск.
д) Для сравнения, хороший академический словарь может содержать 1 500 страниц, 2 колонки/страницу, 100 строк/колонку, 7 слов/строку, 6 букв/слово и 6 бит/букву. Определите число битов, требуемое для представления словаря, и оцените число подобных книг, которое может быть записано на компакт-диске.
13.8. 1-битовое устройство квантования дискретизирует входную синусоиду амплитуды А с равномерно распределенной фазой. Определите амплитуду Х0, выходной уровень 1-битового квантующего устройства, минимизирующего среднеквадратическую ошибку квантования.
13.9. Одношаговый линейный фильтр с предсказанием должен использоваться для дискретизации синусоиды постоянной амплитуды. Отношение частоты произведения выборки к частоте синусоиды равно 10,0. Определите коэффициент предсказания фильтра. Определите отношение выходной мощности к входной для одноотводного предсказателя.
13.10. Двухотводный линейный фильтр с предсказанием работает в системе DPCM. Предсказание имеет вид
![]()
а) Определите величины a![]() и а
и а![]() , минимизирующие среднеквадратическую ошибку предсказания.
, минимизирующие среднеквадратическую ошибку предсказания.
б) Определите выражение для среднеквадратической ошибки предсказания.
в) Определите мощность ошибки предсказания, если коэффициент корреляции входного сигнала имеет следующий вид.
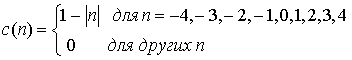
г) Определите мощность ошибки предсказания, если коэффициент корреляции входного сигнала имеет вид ![]() .
.
13.11. Одноконтурный сигма-дельта-модулятор работает с частотой, в 20 раз превышающей частоту Найквиста для сигнала с полосой частот 10 кГц. Преобразователь представляет собой 1-битовый АЦП.
а) Определите максимальное SNR для входного сигнала в 8,0 кГц.
б) Определите максимальное SNR для того же сигнала, если модулятор работает с частотой, в 50 раз превышающей частоту Найквиста.
в) Определите максимальное SNR для того же сигнала, если модулятор заменен на 2-нулевой модулятор, работающий с частотой, в 20 раз превышающей частоту Найквиста.
13.12. Создайте двоичный код Хаффмана для дискретного источника трех независимых символов А, В и С с вероятностями 0,9, 0,08 и 0,02. Определите среднюю длину кода для этого кода.
13.13. Создайте двоичный код расширения первого порядка (кодирование двух символов одновременно) для дискретного источника, описанного в задаче 13.12. Определите среднюю длину кода на символ для этого кода.
13.14. Входной алфавит (клавиатура текстового процессора) состоит из 100 символов.
а) Если нажатие клавиши кодируется с помощью кода фиксированной длины, определите требуемое число бит для кодирования.
б) Сделаем упрощающее предположение, состоящее в том, что 10 нажатий клавиш равновероятны и каждое происходит с вероятностью 0,05. Предположим также, что оставшиеся 90 нажатий клавиш равновероятны. Определите среднее число бит, требуемое для кодирования этого алфавита с использованием кода Хаффмана переменной длины.
13.15. Используйте модифицированный МККТТ факсимильный код Хаффмана для кодирования следующей последовательности единственной строки из 2 047 черных и белых пикселей. Определите отношение закодированных битов к входным.
11Б 1Ч 2Б 2Ч 4Б 4Ч 8Б 8Ч 16Б 16Ч 32Б 32Ч 664Б 64Ч 128Б 128Ч 256Б 256Ч 512Б 512Ч 1Б
13.16. JPEG квантует спектральные составляющие, полученные с помощью ДКП четного расширения обработанных данных. Чтобы показать относительные потери ДКП и БПФ, образуйте четное и скопированное расширения ряда {10 12 14 16 18 20 22 24}, чтобы получить {10 12 14 16 18 20 22 24 10 12 14 16 18 20 22 24} и {10 12 14 16 18 20 22 24 24 22 20 18 16 14 12 10}. Примените ДПФ к двум временным рядам и сравните относительный размер спектральных компонентов (отличных от постоянных составляющих). Теперь дополните спектр, полагая равными нулю все лепестки, кроме 5 спектральных. В четном расширении удерживаются лепестки {1 2 3 15 16}, в то время как в периодическом — {1 3 5 13 15}. Вычислите обратное ДПФ каждого и сравните относительный размер ошибки восстановления для двух преобразований.
13.17. JPEG использует зигзагообразную модель сканирования для обращения к спектральным составляющим ДКП, доставленным квантующим устройством. Альтернативной моделью сканирования будет растровое сканирование, сканирование последовательных строк, обычно выполняемое при сканировании изображения. Сравните эффективность сканирования зигзагообразным методом с эффективностью растрового сканирования, если ненулевыми спектральными членами являются 5(0, 0) = 11001100, 5(1, 0) = 10101 и 5(0, 1) = 110001. Используйте модифицированный код Хаффмана из табл. 13.1 для определения размеров групп нулей. Предположите, что следующая таблица определяет битовое присвоение на спектральный лепесток.
|
8 |
6 |
5 |
4 |
3 |
2 |
2 |
2 |
|
6 |
5 |
4 |
3 |
2 |
2 |
1 |
1 |
|
5 |
4 |
3 |
2 |
2 |
1 |
1 |
1 |
|
4 |
3 |
2 |
2 |
1 |
1 |
1 |
1 |
|
3 |
2 |
2 |
1 |
1 |
1 |
1 |
1 |
|
2 |
2 |
1 |
1 |
1 |
1 |
1 |
1 |
|
2 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
2 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
13.18. ДКП преобразует блок 8![]() 8 пикселей, содержащий 8-битовые слова, в блок 8
8 пикселей, содержащий 8-битовые слова, в блок 8![]() 8 спектральных выборок, содержащих число бит, определенных в таблице квантования задачи 13.17. Предполагается, что не существует последовательностей нулей переменной длины, так что в выходе ДКП представлен каждый лепесток; вычислите коэффициент сжатия (отношение входных битов к выходным), приписанный ДКП. Вычислите коэффициент сжатия, предполагая, что количество значимых коэффициентов ДКП ограничено верхним треугольником таблицы квантования, состоящей из одного 8-битового слова, двух 6-битовых и трех 5-битовых, с оставшимися битами, которые описываются кодом для 101 нуля.
8 спектральных выборок, содержащих число бит, определенных в таблице квантования задачи 13.17. Предполагается, что не существует последовательностей нулей переменной длины, так что в выходе ДКП представлен каждый лепесток; вычислите коэффициент сжатия (отношение входных битов к выходным), приписанный ДКП. Вычислите коэффициент сжатия, предполагая, что количество значимых коэффициентов ДКП ограничено верхним треугольником таблицы квантования, состоящей из одного 8-битового слова, двух 6-битовых и трех 5-битовых, с оставшимися битами, которые описываются кодом для 101 нуля.
Вопросы для самопроверки
13.1. Почему сигналы подвергаются операциям кодирования источника, перед передачей или запоминанием (см. разделы 13.1 и 13.7)?
13.2. Какие свойства непрерывного сигнала позволяют представить его с помощью уменьшенного числа бит на выборку (см. разделы 13.1, 13.3 и 13.7)?
13.3. Какие свойства дискретного сигнала позволяют представить его с помощью уменьшенного числа бит на символ (см. раздел 13.1 и 13.7)?
13.4. Большинство квантующих устройств являются равномерными относительно размера шага. Существуют приложения, для которых требуются неравномерные квантующие устройства. Они иногда называются компандирующими квантующими устройствами. Зачем нужны подобные квантующие устройства (см. раздел 13.2.5)?
13.5. Аналого-цифровой преобразователь (analog-to-digital converter — ADC, АЦП) представляет выборочные данные сигнала с помощью такого числа бит на выборку, которое удовлетворяет требуемой точности. Большинство АЦП являются квантующими устройствами без памяти, что означает, что каждое квантование (преобразование) производится независимо от других преобразований. Как может использоваться память для ограничения числа бит на выборку (см. раздел 13.3)?
13.6. Кодирование источника уменьшает избыточность и отбрасывает несущественное содержимое. В чем состоит разница между избыточностью и несущественностью (см. раздел 3.7)?
13.7. Часто слышим такое высказывание, как "картина стоит тысячи слов". Действительно ли картина стоит тысячи слов (см. раздел 13.8.2)?