1.1. Структура ЭВМ общего назначения
1.1. Структура ЭВМ общего назначения
Любая ЭВМ содержит два основных блока ‑ центральный процессор (ЦП) и оперативную память (ОП).
Задачей ЦП является выполнение машинных команд, которые он выбирает из ОП. Внутренняя организация различных ЦП может отличаться, однако любой ЦП содержит ряд стандартных блоков, к которым относятся:
- дешифратор команд, позволяющий декодировать считанную из ОП команду;
- арифметико-логическое устройство (АЛУ), позволяю-щее реализовать заданную в команде операцию;
- блок регистров общего назначения (блок РОН), предназначенных для временного хранения информации, причем наличие РОН позволяет резко снизить количество обращений к ОП, повышая тем самым общее быстродействие ЭВМ;
- устройство управления (УУ), обеспечивающее на всех этапах выполнения команды выработку необходимых управляющих сигналов.
Оперативная память состоит из ПЗУ и ОЗУ и предназначена для хранения программ, исходных данных, промежуточных и конечных результатов вычислений.
Обычно ЭВМ общего назначения организуется по так называемой схеме с общей шиной, показанной на рис. 1.1.
Системная шина (СШ) подразделяется на шину адреса (ША), шину данных (ШД) и шину управления (ШУ). На ША процессор выставляет адреса ячеек памяти и портов внешних устройств (ВУ), к которым он обращается. На шине управления процессор формирует сигналы, управляющие передачей информации. Сама передача информации производится по ШД.
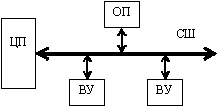
Рис. 1.1
В любой момент к СШ может быть подключено не более двух устройств. Одно из этих устройств передает информацию, другое ее принимает. Как правило, одним из этих устройств является ЦП, который и управляет передачей информации по шине. Исключением является режим прямого доступа к памяти, когда ЦП в обмене участия не принимает, а управление обменом берет на себя стоящий в системе контроллер прямого доступа к памяти.
1.2. Арифметико-логические устройства
АЛУ выполняет операции по преобразованию поступающей в него информации. В машинах малой и средней мощности, не имеющих отдельного блока для формирования физических адресов ОП, на АЛУ также возлагаются операции адресной арифметики.
Алгоритмы операций, выполняемых на АЛУ, включают определенную последовательность элементарных действий (микроопераций), среди которых различают прием кода операнда, преобразование этого кода, суммирование кодов двух операндов, сдвиг кода, логические операции над кодами и ряд других. Для выполнения этих действий в АЛУ имеются следующие функциональные узлы:
- регистры для временного хранения операндов;
- сдвигатели;
- преобразователи прямого кода в дополнительный и наоборот;
- сумматор, на котором реализуются арифметические и логические операции.
Существует много типов АЛУ. Например, по системам счисления различают АЛУ с двоичной и десятичной арифметикой, по формам представления числовых данных – АЛУ с фиксированной и плавающей запятой и т.д.
1.3. Устройства управления
Каждая машинная команда требует для своей реализации несколько машинных тактов. В каждом такте УУ обеспечивает выдачу необходимого набора управляющих сигналов. Такой набор управляющих сигналов принято называть микрокомандой, а последовательность микрокоманд, необходимую для выполнения какой-либо машинной команды, - микропрог-раммой этой команды. Существует два основных способа построения логики управляющего устройства:
- устройство с «жесткой логикой», в котором для каждой реализуемой в процессоре операции строится набор схем, в нужных тактах возбуждающих соответствующие управляю-щие сигналы;
- микропрограммное устройство управления, в котором все необходимые микропрограммы хранятся в памяти (как правило, в ПЗУ) в виде последовательностей микрокоманд, а любая микрокоманда при этом несет в себе информацию обо всех вырабатываемых в данном такте управляющих сигналах и об адресе следующей микрокоманды.
В настоящее время УУ с «жесткой логикой» используются довольно редко, так как любые изменения в системе команд приводят к переделке УУ с «жесткой логикой», в то время как для микропрограммного УУ достаточно будет перепрограммировать ПЗУ. Типичная структура микропрограммного УУ приведена на рис. 1.2.
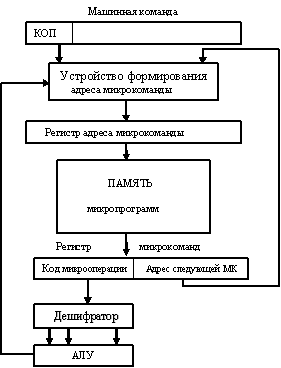
Рис. 1.2
Работа схемы осуществляется следующим образом. Из ОП считывается очередная машинная команда. Код операции этой команды дешифрируется и подается на устройство формирования адреса микрокоманд, которое вырабатывает адрес первой микрокоманды соответствующей микропрограммы. Эта микрокоманда считывается из памяти и помещается в регистр микрокоманд. Операционная часть микрокоманды дешифрируется (в общем случае) и соответствующие управляющие сигналы подаются на АЛУ (вернее на операционный блок). Адресная часть микрокоманды определяет адрес следующей микрокоманды.
Также в процессе формирования адреса следующей микрокоманды могут принимать участие и снимаемые с АЛУ признаки, например признак «нулевого результата» и другие подобные. Эти признаки позволяют организовывать в микропрограммах условные переходы. Последняя микрокоманда микропрограммы несет в себе информацию о том, что она является последней и, следовательно, можно считывать из ОП следующую машинную команду.
В зависимости от способа формирования управляющих сигналов различают горизонтальное, вертикальное и смешанное микропрограммирование. При горизонтальном микропрограммировании каждый разряд кода микрооперации микрокоманды ставится в соответствие одному из возможных управляющих сигналов или одной из возможных микроопераций. Если в разряде стоит единица, то соответствующая микрооперация в данном такте выполняется, если ноль – нет. При таком способе операционная часть микрокоманды содержит m разрядов, где m – общее число микроопераций в процессоре.
Достоинством такого способа является возможность одновременного выполнения в одном такте любого набора микроопераций и простота формирования управляющих сигналов, которые просто снимаются из соответствующих разрядов микрокоманды. Указанный на рис. 1.2 дешифра-тор оказывается не нужен. У этого способа имеется недостаток, так как при большом числе управляющих сигналов (несколько сотен) формат микрокоманды становится недопустимо большим. В этом случае следует использовать вертикальное микропрограммирование.
При вертикальном микропрограммировании код микрооперации в микрокоманде задает одну из микроопераций. Длина операционной части микрокоманды значительно сокращается и составляет log2m, однако такая микрокоманда требует дешифрации. При таком способе невозможно задать в одном такте более одного управляю-щего сигнала, что снижает быстродействие процессора.
В настоящее время наибольшее распространение имеет смешанное микропрограммирование, в котором сочетаются методы горизонтального и вертикального микропрограм-мирования. Например, можно разбить все микрооперации на группы и внутри любой группы использовать вертикальное, а между группами – горизонтальное микропрограммирование.
1.4. RISC- и CISC - процессоры
Начиная с 50-х и до середины 80-х гг. XX века развитие архитектуры процессоров усложнялось в основном за счет развития технологии, а не за счет принципиально новых идей. Система машинных команд процессоров также постоянно усложнялась, что было обусловлено стремлением обеспечить поддержку новых сложных языков высокого уровня (ЯВУ). Все разработанные за этот период процессоры относятся к типу CISC (common instruction set computer – «процессор с полным набором команд»). В середине 80-х этот путь развития был поставлен под сомнение, что привело к появлению RISC-процессоров (reduce instruction set computer – «процессор с сокращенным набором команд»). Рассмотрим причины, которые привели к этому повороту.
С уменьшением стоимости аппаратной части CISC-процессоров увеличивались затраты на программное обеспечение. Помимо высокой стоимости и неудобств в использовании, к недостаткам программного обеспечения относится наличие элемента ненадежности: для всех программ характерно выявление все новых и новых ошибок даже после нескольких лет эксплуатации. Фирмы решали эту проблему путем создания все более сложных ЯВУ, которые помогали программистам избегать ошибок.
Этот подход породил другую проблему ‑ «семантичес-кий разрыв», которая заключается в существенном различии между операторами ЯВУ и машинными командами процессоров. Разрыв привел к неэффективному выполнению операторов, чрезмерному объему программ и сложности компиляторов. Пришлось искать архитектурные решения, направленные на устранение этого разрыва.
К основным особенностям CISC-архитектур относятся:
- использование сложных машинных команд;
- большое число используемых способов адресации;
- аппаратная реализация некоторых операторов ЯВУ.
Эти особенности способствуют достижению целей:
- облегчение труда разработчиков компиляторов;
- повышение эффективности выполнения операторов;
- обеспечение базы для использования гораздо более изощренных ЯВУ.
Этот подход также породил сомнения у разработчиков, и они провели анализ программ, написанных на ЯВУ. Выяснилось, что 2/3 операторов ‑ простейшие операторы вида А = В. Был сделан вывод, что подгонка системы команд под ЯВУ не самая лучшая стратегия. Гораздо более эффективным может оказаться путь оптимизации наиболее часто встречающихся в программах операторов.
Обобщение этих и других исследований привело к тому, что были сформулированы три принципиальные особенности архитектуры RISC-процессоров:
- использование большого числа (до нескольких сотен) внутренних регистров, с целью снижения числа обращений к ОП;
- использование эффективного конвейера команд, эффективность которого обеспечивается простотой форматов машинных команд;
- использование сокращенного набора машинных команд, что и позволяет использовать их простые форматы.
Существует много подходов к построению RISC-процессоров, однако у них у всех есть общие характеристики:
- одна машинная команда выполняется за один машинный цикл, что позволяет реализовать большинство машинных команд аппаратным образом и, следовательно, обеспечить более высокое быстродействие, по сравнению с CISC-процессорами, в которых большинство команд требуют использования микропрограмм;
- большинство операций имеют тип «регистр ‑ регистр», что позволяет упростить УУ и повысить быстродействие;
- используются только простые способы адресации, что можно считать и достоинством и недостатком, так как формат команды упрощается, но более сложные способы адресации приходится организовывать программно;
- применяются простые форматы машинных команд.
Обычно используется один или несколько (два-три) формата. Все команды имеют фиксированную длину и фиксированное расположение полей. Этот подход дает возможность легко реализовать конвейер команд, упростить УУ и повысить быстродействие процессора.
Выпускаемые в настоящее время процессоры сочетают в своей архитектуре особенности RISC- и CISC- процессоров.
1.5. Форматы машинных команд
Машинной командой называется двоичное слово, содержащее всю информацию, необходимую процессору для выполнения заданной операции. А именно: тип операции, адреса операндов, адрес приемника результата. Для фиксации этой информации в машинной команде выделяются группы разрядов, называемые полями. Любая машинная команда состоит из поля кода операций (КОП) и ряда адресных полей. Форматом машинной команды называется заранее оговоренная структура ее полей.
В наиболее общем случае машинная команда должна иметь формат, представленный на рис. 1.3.
![]()
Рис. 1.3
На рис. 1.3 А1 – поле адреса первого операнда, А2 – поле адреса второго операнда, А3 – поле адреса приемника результата, А4 – поле адреса следующей машинной команды. Это четырехадресная машинная команда.
Чем больше в команде полей, тем больше места она занимает в оперативной памяти (ОП). Это приводит к непроизводительному расходу памяти и снижению общего быстродействия ЭВМ, так как считывание таких команд из ОП требует больших временных затрат.
На практике четырехадресные машинные команды никогда не использовались. Машинные команды любой программы располагаются в ОП не хаотично, а последовательно, одна за другой, поэтому в состав процессора вводится специальный регистр, называемый программным счетчиком. Перед началом выполнения программы в него заносится адрес первой команды программы. После считывания очередной машинной команды из ОП содержимое программного счетчика автоматически увеличивается на число считанных байт.
Таким образом в программном счетчике автоматически формируется адрес следующей машинной команды программы. При таком подходе поле А4 становится ненужным и команда становится трехадресной.
Если результат операции всегда помещать на место одного из операндов, например первого, отпадает необходимость в поле А3 и команда становится двухадресной. Хотя при таком подходе команды несколько теряют в гибкости и создаются определенные неудобства при программировании, практика показала, что выигрыш здесь значительно превышает проигрыш. Иногда в состав процессора вводят специальный регистр, называемый аккумулятором, и оговаривают, что один из операндов всегда берется из аккумулятора и в него загружается результат операции. При такой ситуации команды становятся одноадресными. Существуют и безадресные команды, например команды, реализующие стековые операции. В современных процессорах используются, как правило, двух-, одно- и безадресные команды. Например команды микропроцессора К1810ВМ86:
add dx, [234h] – двухадресная;
inc byte ptr [40h] – одноадресная;
push bx – безадресная.
1.6. Способы адресации
Физическим адресом (Аф) будем называть двоичный номер ячейки памяти, к которой мы обращаемся. Адресным кодом (Ак) будем называть двоичное число, которое записано в адресном поле команды. Как правило, в современных ЭВМ Ак не совпадает с Аф.
Способ формирования Аф по заданному в команде Ак и называется способом (методом) адресации. Далее рассмотрим наиболее часто используемые на практике способы адресации.
Непосредственная адресация. В адресном поле команды задается не адрес операнда, а непосредственно сам операнд. Например, sub bl, 25.
Прямая адресация. В адресном поле команды задается адрес ячейки памяти. То есть в этом случае Аф = Ак. Например, mov [200h],al. Прямая адресация не дает возможности для организации циклов.
Косвенная адресация. Адресный код задает регистр процессора. Содержимое этого регистра берется в качестве Аф. Например, add ax, [bx]. Косвенная адресация предоставляет программисту простую возможность организации циклов.
Базовая адресация. Адресный код задает регистр процессора, откуда берется так называемый «базовый адрес», и некоторую величину, называемую смещением. Процессор вычисляет Аф путем сложения базового адреса со смещением. Например, add di, [si+100]. Базовая адресация удобна при работе с одномерными массивами. Базовый адрес при этом задает начальный адрес массива, а смещение указывает на элемент внутри массива. Кроме того, базовая адресация обеспечивает простую возможность перемещения программы в ОП без модификации этой программы.
Базово-индексная адресация. Адресный код задает два регистра процессора и смещение. Процессор вычисляет Аф, складывая смещение и содержимое обоих регистров. Например, mov dx, [bp+si+2]. Такая адресация удобна при работе с двухмерными массивами.
1.7. Стековая адресация
Стек – это особый вид памяти. Если при обращении к обычной памяти необходимо задавать адрес ячейки, к которой производится обращение, то при обращении к стеку адрес задавать не надо.
Различают два вида стеков:
- стек, реализующий процедуру LIFO (last input-first output ‑ последним пришел – первым ушел);
- стек, реализующий процедуру FIFO (first input-first output ‑ первым пришел – первым ушел).
Стек, реализующий процедуру LIFO, организуется, как правило, на обычной оперативной памяти. В состав процессора вводится специальный регистр, называемый указателем стека. Его содержимое адресует ячейку ОП, которую принято называть вершиной стека. После любой стековой операции содержимое указателя стека изменяется, соответственно меняется и вершина стека.
Например, в микропроцессорах фирмы Intel в качестве указателя стека используется регистр sp (esp). При выполнении команды push dx вначале из содержимого sp вычитается двойка и затем по полученному адресу в ОП записывается содержимое регистра dx. При выполнении команды pop bx в регистр bx выталкивается слово из вершины стека, а затем к sp прибавляется двойка.
Стек, реализующий процедуру FIFO, обычно организуется аппаратным образом на регистрах.