1.1. Информация в материальном мире
1.1.4. Диалектическое единство данных и методов в информационном процессе
1.2.3. Кодирование данных двоичным кодом
1.2.4. Кодирование целых и действительных чисел
1.2.5. Кодирование текстовых данных
1.2.6. Универсальная система кодирования текстовых данных
1.2.7. Кодирование графических данных
1.2.8. Кодирование звуковой информации
1.2.9. Основные структуры данных
1.2.10. Линейные структуры (списки данных, векторы данных)
1.2.11. Табличные структуры (таблицы данных, матрицы данных)
1.3. Файлы и файловая структура
1.3.1. Единицы представления данных
1.3.2. Единицы измерения данных
1.1. Информация в материальном мире
1.1.1. Сигналы и данные
Мы живем в материальном мире. Все, что нас окружает и с чем мы сталкиваемся ежедневно, относится либо к физическим телам, либо к физическим полям. Из курса физики мы знаем, что состояния абсолютного покоя не существует и физические объекты находятся в состоянии непрерывного движении и изменения, которое сопровождается обменом энергией и ее переходом из одной формы в другую.
Все виды энергообмена сопровождаются появлением сигналов, то есть, все сигналы имеют в своей основе материальную энергетическую природу. При взаимодействии сигналов с физическими телами в последних возникают определенные изменения свойств — это явление называется регистрацией сигналов. Такие изменения можно наблюдать, измерять или фиксировать иными способами — при этом возникают и регистрируются новые сигналы, то есть, образуются данные.
Данные — это зарегистрированные сигналы.
1.1.2. Данные и методы
Обратим внимание на то, что данные несут в себе информацию о событиях, произошедших в материальном мире, поскольку они являются регистрацией сигналов, возникших в результате этих событий. Однако данные не тождественны информации. Наблюдая излучения далеких звезд, человек получает определенный поток данных, но станут ли эти данные информацией, зависит еще от очень многих обстоятельств. Рассмотрим ряд примеров.
Наблюдая за состязаниями бегунов, мы с помощью механического секундомера регистрируем начальное и конечное положение стрелки прибора. В итоге мы замеряем величину ее перемещения за время забега — это регистрация данных. Однако информацию о времени преодоления дистанции мы пока не получаем. Для того чтобы данные о перемещении стрелки дали информацию о времени забега, необходимо наличие метода пересчета одной физической величины в другую. Надо знать цену деления шкалы секундомера (или знать метод ее определения) и надо также знать, как умножается цена деления прибора на величину перемещения, то есть надо еще обладать математическим методом умножения.
Если вместо механического секундомера используется электронный, суть дела не меняется. Вместо регистрации перемещения стрелки происходит регистрация количества тактов колебаний, произошедших в электронной системе за время измерения. Даже если секундомер непосредственно отображает время в секундах и нам не нужен метод пересчета, то метод преобразования данных все равно присутствует — он реализован специальными электронными компонентами и работает автоматически, без нашего участия.
Прослушивая передачу радиостанции на незнакомом языке, мы получаем данные, но не получаем информацию в связи с тем, что не владеем методом преобразования данных в известные нам понятия. Если эти данные записать на лист бумаги или на магнитную ленту, изменится форма их представления, произойдет новая регистрация и, соответственно, образуются новые данные. Такое преобразование можно использовать, чтобы все-таки извлечь информацию из данных путем подбора метода, адекватного их новой форме. Для обработки данных, записанных на листе бумаги, адекватным может быть метод перевода со словарем, а для обработки данных, записанных на магнитной ленте, можно пригласить переводчика, обладающего своими методами перевода, основанными на знаниях, полученных в результате обучения или предшествующего опыта.
Если в нашем примере заменить радиопередачу телевизионной трансляцией, ведущейся на незнакомом языке, то мы увидим, что наряду с данными мы все-таки получаем определенную (хотя и не полную) информацию. Это связано с тем, что люди, не имеющие дефектов зрения, априорно владеют адекватным методом восприятия данных, передаваемых электромагнитным сигналом в полосе частот видимого спектра с интенсивностью, превышающей порог чувствительности глаза. В таких случаях говорят, что метод известен по контексту, то есть данные, составляющие информацию, имеют свойства, однозначно определяющие адекватный метод получения этой информации. (Для сравнения скажем, что слепому “телезрителю” контекстный метод неизвестен, и он оказывается в положении радиослушателя, пример с которым был рассмотрен выше.)
1.1.3. Понятие об информации
Несмотря на то, что с понятием информации мы сталкиваемся ежедневно, строгого и общепризнанного ее определения до сих пор не существует, поэтому вместо определения обычно используют понятие об информации. Понятия, в отличие от определений, не даются однозначно, а вводятся на примерах, причем каждая научная дисциплина делает это по-своему, выделяя в качестве основных компонентов те, которые наилучшим образом соответствуют ее предмету и задачам. При этом типична ситуация, когда понятие об информации, введенное в рамках одной научной дисциплины, может опровергаться конкретными примерами и фактами, полученными в рамках другой науки. Например, представление об информации как о совокупности данных, повышающих уровень знаний об объективной реальности окружающего мира, характерное для естественных наук, может быть опровергнуто в рамках социальных наук. Нередки также случаи, когда исходные компоненты, составляющие понятие информации, подменяют свойствами информационных объектов, например, когда понятие информации вводят как совокупность данных, которые “могут быть усвоены и преобразованы в знания”.
Для информатики как технической науки понятие информации не может основываться на таких антропоцентрических понятиях, как знание, и не может опираться только на объективность фактов и свидетельств. Средства вычислительной техники обладают способностью обрабатывать информацию автоматически, без участия человека, и ни о каком знании или незнании здесь речь идти не может. Эти средства могут работать с искусственной, абстрактной и даже с ложной информацией, не имеющей объективного отражения ни в природе, ни в обществе.
В этой работе мы даем новое определение информации, основанное на ранее продемонстрированном факте взаимодействия данных и методов в момент ее образования.
Информация — это продукт взаимодействия данных и адекватных им методов.
Поскольку в такой форме определение информации дается впервые, читатель приглашается для его всесторонней проверки в рамках других известных ему научных дисциплин, а мы рассмотрим пример, в свое время использованный Норбертом Винером для того, чтобы показать, как информация отдельных членов популяции становится информацией общества.
Н. Винер. Кибернетика
Анализируя этот пример, мы видим, что здесь речь идет о данных и методах. Прежде всего, здесь автор прямо говорит о целой группе методов, связанных с наблюдением и анализом, и даже приводит вариант конкретного алгоритма, адекватного рамкам его гипотетического эксперимента (посмотреть, запомнить, открыть...). Автор неоднократно подчеркивает требование адекватности метода (дикарь должен быть смышленым, а наблюдатель должен быть особо внимательным), без которого информация может и не образоваться.
1.1.4. Диалектическое единство данных и методов в информационном процессе
Рассмотрим данное выше определение информации и обратим внимание на следующие обстоятельства.
1. Динамический характер информации. Информация не является статичным объектом — она динамически меняется и существует только в момент взаимодействия данных и методов. Все прочее время она пребывает в состоянии данных. Таким образом, информация существует только в момент протекания информационного процесса. Все остальное время она содержится в виде данных.
2. Требование адекватности методов. Одни и те же данные могут в момент потребления поставлять разную информацию в зависимости от степени адекватности взаимодействующих с ними методов. Например, для человека, не владеющего китайским языком, письмо, полученное из Пекина, дает только ту информацию, которую можно получить методом наблюдения (количество страниц, цвет и сорт бумаги, наличие незнакомых символов и т. п.). Все это информация, но это не вся информация, заключенная в письме. Использование более адекватных методов даст иную информацию.
3. Диалектический характер взаимодействия данных и методов. Обратим внимание на то, что данные являются объективными, поскольку это результат регистрации объективно существовавших сигналов, вызванных изменениями в материальных телах или полях. В то же время, методы являются субъективными. В основе искусственных методов лежат алгоритмы (упорядоченные последовательности команд), составленные и подготовленные людьми (субъектами). В основе естественных методов лежат биологические свойства субъектов информационного процесса. Таким образом, информация возникает и существует в момент диалектического взаимодействия объективных данных и субъективных методов.
Такой дуализм известен своими проявлениями во многих науках. Так, например, в основе важнейшего вопроса философии о первичности материалистического и идеалистического подходов к теории познания лежит не что иное, как двойственный характер информационного процесса. В обоснованиях обоих подходов нетрудно обнаружить упор либо на объективность данных, либо на субъективность методов. Подход к информации как к объекту особой природы, возникающему в результате диалектического взаимодействия объективных данных с субъективными методами, позволяет во многих случаях снять противоречия, возникающие в философских обоснованиях ряда научных теорий и гипотез.
1.1.5. Свойства информации
Итак, информация является динамическим объектом, образующимся в момент взаимодействия объективных данных и субъективных методов. Как и всякий объект, она обладает свойствами (объекты различимы по своим свойствам). Характерной особенностью информации, отличающей ее от других объектов природы и общества, является отмеченный выше дуализм: на свойства информации влияют как свойства данных, составляющих ее содержательную часть, так и свойства методов, взаимодействующих с данными в ходе информационного процесса. По окончании процесса свойства информации переносятся на свойства новых данных, то есть свойства методов могут переходить на свойства данных.
Можно привести немало разнообразных свойств информации. Каждая научная дисциплина рассматривает те свойства, которые ей наиболее важны. С точки зрения информатики наиболее важными представляются следующие свойства: объективность, полнота, достоверность, адекватность, доступность и актуальность информации.
Объективность и субъективность информации. Понятие объективности информации является относительным. Это понятно, если учесть, что методы являются субъективными. Более объективной принято считать ту информацию, в которую методы вносят меньший субъективный элемент. Так, например, принято считать, что в результате наблюдения фотоснимка природного объекта или явления образуется более объективная информация, чем в результате наблюдения рисунка того же объекта, выполненного человеком. В ходе информационного процесса степень объективности информации всегда понижается. Это свойство учитывают, например, в правовых дисциплинах, где по-разному обрабатываются показания лиц, непосредственно наблюдавших события или получивших информацию косвенным путем (посредством умозаключений или со слов третьих лиц). В не меньшей степени объективность информации учитывают в исторических дисциплинах. Одни и те же события, зафиксированные в исторических документах разных стран и народов, выглядят совершенно по-разному. У историков имеются свои методы для тестирования объективности исторических данных и создания новых, более достоверных данных путем сопоставления, фильтрации и селекции исходных данных. Обратим внимание на то, что здесь речь идет не о повышении объективности данных, а о повышении их достоверности (это совсем другое свойство).
Полнота информации. Полнота информации во многом характеризует качество информации и определяет достаточность данных для принятия решений или для создания новых данных на основе имеющихся. Чем полнее данные, тем шире диапазон методов, которые можно использовать, тем проще подобрать метод, вносящий минимум погрешностейв ход информационного процесса.
Достоверность информации. Данные возникают в момент регистрации сигналов, но не все сигналы являются “полезными” — всегда присутствует какой-то уровень посторонних сигналов, в результате чего полезные данные сопровождаются определенным уровнем “информационного шума”. Если полезный сигнал зарегистрирован более четко, чем посторонние сигналы, достоверность информации может быть более высокой. При увеличении уровня шумов достоверность информации снижается. В этом случае для передачи того же количества информации требуется использовать либо больше данных, либо более сложные методы.
Адекватность информации — это степень соответствия реальному объективному состоянию дела. Неадекватная информация может образовываться при создании новой информации на основе неполных или недостоверных данных. Однако и полные, и достоверные данные могут приводить к созданию неадекватной информации в случае применения к ним неадекватных методов.
Доступность информации — мера возможности получить ту или иную информацию. На степень доступности информации влияют одновременно как доступность данных, так и доступность адекватных методов для их интерпретации. Отсутствие доступа к данным или отсутствие адекватных методов обработки данных приводят к одинаковому результату: информация оказывается недоступной. Отсутствие адекватных методов для работы с данными во многих случаях приводит к применению неадекватных методов, в результате чего образуется неполная, неадекватная или недостоверная информация.
Актуальность информации — это степень соответствия информации текущему моменту времени. Нередко с актуальностью, как и с полнотой, связывают коммерческую ценность информации. Поскольку информационные процессы растянуты во времени, то достоверная и адекватная, но устаревшая информация может приводить к ошибочным решениям. Необходимость поиска (или разработки) адекватного метода для работы с данными может приводить к такой задержке в получении информации, что она становится неактуальной и ненужной. На этом, в частности, основаны многие современные системы шифрования данных с открытым ключом. Лица, не владеющие ключом (методом) для чтения данных, могут заняться поиском ключа, поскольку алгоритм его работы доступен, но продолжительность этого поиска столь велика, что за время работы информация теряет актуальность и, соответственно, связанную с ней практическую ценность.
1.2. Данные
1.2.1. Носители данных
Данные — диалектическая составная часть информации. Они представляют собой зарегистрированные сигналы. При этом физический метод регистрации может быть любым: механическое перемещение физических тел, изменение их формы или параметров качества поверхности, изменение электрических, магнитных, оптических характеристик, химического состава и (или) характера химических связей, изменение состояния электронной системы и многое другое. В соответствии с методом регистрации данные могут храниться и транспортироваться на носителях различных видов.
Самым распространенным носителем данных, хотя и не самым экономичным, по-видимому, является бумага. На бумаге данные регистрируются путем изменения оптических характеристик ее поверхности. Изменение оптических свойств (изменение коэффициента отражения поверхности в определенном диапазоне длин волн) используется также в устройствах, осуществляющих запись лазерным лучом на пластмассовых носителях с отражающим покрытием (CD ROM). В качестве носителей, использующих изменение магнитных свойств, можно назвать магнитные ленты и диски. Регистрация данных путем изменения химического состава поверхностных веществ носителя широко используется в фотографии. На биохимическом уровне происходит накопление и передача данных в живой природе.
Носители данных интересуют нас не сами по себе, а постольку, поскольку свойства информации весьма тесно связаны со свойствами ее носителей. Любой носитель можно характеризовать параметром разрешающей способности (количеством данных, записанных в принятой для носителя единице измерения) и динамическим диапазоном (логарифмическим отношением интенсивности амплитуд максимального и минимального регистрируемого сигналов). От этих свойств носителя нередко зависят такие свойства информации, как полнота, доступность и достоверность. Так, например, мы можем рассчитывать на то, что в базе данных, размещаемой на компакт-диске, проще обеспечить полноту информации, чем в аналогичной по назначению базе данных, размещенной на гибком магнитном диске, поскольку в первом случае плотность записи данных на единице длины дорожки намного выше. Для обычного потребителя доступность информации в книге заметно выше, чем той же информации на компакт-диске, поскольку не все потребители обладают необходимым оборудованием. И, наконец, известно, что визуальный эффект от просмотра слайда в проекторе намного больше, чем от просмотра аналогичной иллюстрации, напечатанной на бумаге, поскольку диапазон яркостных сигналов в проходящем свете на два-три порядка больше, чем в отраженном.
Задача преобразования данных с целью смены носителя относится к одной из важнейших задач информатики. В структуре стоимости вычислительных систем устройства для ввода и вывода данных, работающие с носителями информации, составляют до половины стоимости аппаратных средств.
1.2.2. Операции с данными
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью методов. Обработка данных включает в себя множество различных операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе трудозатраты на обработку данных неуклонно возрастают. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, тоже связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие основные:
- сбор данных — накопление информации с целью обеспечения достаточной полноты для принятия решений;
- формализация данных — приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
- фильтрация данных — отсеивание “лишних” данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень “шума”, а достоверность и адекватность данных должны возрастать;
- сортировка данных — упорядочение данных по заданному признаку с целью удобства использования; повышает доступность информации;
- архивация данных — организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
- защита данных — комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
- транспортировка данных— прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя — клиентом;
- преобразование данных — перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства — телефонные модемы.
Приведенный здесь список типовых операций с данными далеко не полон. Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно. Следовательно, можно сделать вывод: работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
1.2.3. Кодирование данных двоичным кодом
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления — для этого обычно используется прием кодирования, то есть выражение данных одного типа через данные другого типа. Естественные человеческие языки — это не что иное, как системы кодирования понятий для выражения мыслей посредством речи. К языкам близко примыкают азбуки (системы кодирования компонентов языка с помощью графических символов). История знает интересные, хотя и безуспешные попытки создания “универсальных” языков и азбук. По-видимому, безуспешность попыток их внедрения связана с тем, что национальные и социальные образования естественным образом понимают, что изменение системы кодирования общественных данных непременно приводит к изменению общественных
методов (то есть норм права и морали), а это может быть связано с социальными потрясениями.
Та же проблема универсального средства кодирования достаточно успешно реализуется в отдельных отраслях техники, науки и культуры. В качестве примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое.
Своя система существует и в вычислительной технике — она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски — binary digit или сокращенно bit (бит).
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т. п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
00 01 10 11
Тремя битами можно закодировать восемь различных значений:
000 001 010 011 100 101 110 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид:
N = 2m,
где N — количество независимых кодируемых значений;
m — разрядность двоичного кодирования, принятая в данной системе.
1.2.4. Кодирование целых и действительных чисел
Целые числа кодируются двоичным кодом достаточно просто — достаточно взять целое число и делить его пополам до тех пор, пока частное не будет равно единице. Совокупность остатков от каждого деления, записанная справа налево вместе с последним частным, и образует двоичный аналог десятичного числа.
19:2 = 9+1
9:2 = 4+1
4:2 = 2+0
2:2 = 1+0
Таким образом, 1910 = 100112.
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют закодировать целые числа от 0 до 65 535, а 24 бита — уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму:
3,1415926 = 0,31415926•101
300 000= 0,3 •106
123 456 789 = 0,123456789 • 1010
Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики (тоже со знаком).
1.2.5. Кодирование текстовых данных
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы, например символ “§”.
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера.
Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI — American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования — базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII приведена в таблице 1.1.
Таблица 1.1 Базовая таблица кодировки ASCII
|
32 |
пробел |
48 |
0 |
64 |
@ |
80 |
P |
96 |
˙ |
112 |
p |
|
33 |
! |
49 |
1 |
65 |
A |
81 |
Q |
97 |
a |
113 |
q |
|
34 |
“ |
50 |
2 |
66 |
B |
82 |
R |
98 |
b |
114 |
r |
|
35 |
# |
51 |
3 |
67 |
C |
83 |
S |
99 |
c |
115 |
|
|
36 |
$ |
52 |
4 |
68 |
D |
84 |
T |
100 |
d |
116 |
t |
|
37 |
% |
53 |
5 |
69 |
E |
85 |
U |
101 |
e |
117 |
u |
|
38 |
& |
54 |
6 |
70 |
F |
86 |
V |
102 |
f |
118 |
v |
|
39 |
‘ |
55 |
7 |
71 |
G |
87 |
W |
103 |
g |
119 |
w |
|
40 |
( |
56 |
8 |
72 |
H |
88 |
X |
104 |
h |
120 |
x |
|
41 |
) |
57 |
9 |
73 |
I |
89 |
Y |
105 |
i |
121 |
y |
|
42 |
* |
58 |
: |
74 |
J |
90 |
Z |
106 |
j |
122 |
z |
|
43 |
+ |
59 |
; |
75 |
K |
91 |
[ |
107 |
k |
123 |
{ |
|
44 |
, |
60 |
< |
76 |
L |
92 |
\ |
108 |
l |
124 |
|
|
45 |
- |
61 |
= |
77 |
M |
93 |
] |
109 |
m |
125 |
} |
|
46 |
. |
62 |
> |
78 |
N |
94 |
^ |
110 |
n |
126 |
~ |
|
47 |
/ |
63 |
? |
79 |
O |
95 |
_ |
111 |
o |
127 |
Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось “отступить” во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена “извне” — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 1.2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица1.3). Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных — это одна из распространенных задач информатики.
Таблица 1.2. Кодировка Windows 1251
|
128 |
Ђ |
144 |
ђ |
160 |
176 |
· |
192 |
А |
208 |
Р |
224 |
а |
240 |
р |
|
|
129 |
Ѓ |
145 |
‘ |
161 |
Ў |
177 |
± |
193 |
Б |
209 |
С |
225 |
б |
241 |
с |
|
130 |
, |
146 |
’ |
162 |
ў |
178 |
І |
194 |
В |
210 |
Т |
226 |
в |
242 |
т |
|
131 |
ѓ |
147 |
“ |
163 |
J |
179 |
i |
195 |
Г |
211 |
У |
227 |
г |
243 |
у |
|
132 |
” |
148 |
” |
164 |
¤ |
180 |
ґ |
196 |
Д |
212 |
Ф |
228 |
д |
244 |
ф |
|
133 |
… |
149 |
• |
165 |
Ґ |
181 |
µ |
197 |
Е |
213 |
Х |
229 |
е |
245 |
х |
|
134 |
† |
150 |
– |
166 |
¦ |
182 |
¶ |
198 |
Ж |
214 |
Ц |
230 |
ж |
246 |
ц |
|
135 |
‡ |
151 |
— |
167 |
§ |
183 |
· |
199 |
З |
215 |
Ч |
231 |
з |
247 |
ч |
|
136 |
‘ |
152 |
´ |
168 |
Ё |
184 |
ё |
200 |
И |
216 |
Ш |
232 |
и |
248 |
ш |
|
137 |
‰ |
153 |
тм |
169 |
© |
185 |
№ |
201 |
Й |
217 |
Щ |
233 |
й |
249 |
щ |
|
138 |
Љ |
154 |
љ |
170 |
Є |
186 |
є |
202 |
К |
218 |
Ъ |
234 |
к |
250 |
ъ |
|
139 |
‹ |
155 |
› |
171 |
“ |
187 |
” |
203 |
Л |
219 |
Ы |
235 |
л |
251 |
ы |
|
140 |
Њ |
156 |
њ |
172 |
¬ |
188 |
ј |
204 |
М |
220 |
Ь |
236 |
м |
252 |
ь |
|
141 |
Ќ |
157 |
ќ |
173 |
- |
189 |
Ѕ |
205 |
Н |
221 |
Э |
237 |
н |
253 |
э |
|
142 |
Ћ |
158 |
ћ |
174 |
® |
190 |
ѕ |
206 |
О |
222 |
Ю |
238 |
о |
254 |
ю |
|
143 |
Џ |
159 |
џ |
175 |
Ї |
191 |
ї |
207 |
П |
223 |
Я |
239 |
п |
255 |
я |
Таблица 1.3. Кодировка КОИ-8
|
128 |
144 |
░ |
160 |
- |
176 |
├ |
192 |
ю |
208 |
п |
224 |
Ю |
240 |
П |
|
|
129 |
| |
145 |
▒ |
161 |
Ё |
177 |
╞ |
193 |
а |
209 |
я |
225 |
А |
241 |
Я |
|
130 |
┌ |
146 |
▓ |
162 |
┌ |
178 |
┤ |
194 |
б |
210 |
р |
226 |
Б |
242 |
Р |
|
131 |
┐ |
147 |
ó |
163 |
ё |
179 |
Ё |
195 |
ц |
211 |
с |
227 |
Ц |
243 |
С |
|
132 |
└ |
148 |
■ |
164 |
╒ |
180 |
┤ |
196 |
д |
212 |
т |
228 |
Д |
244 |
Т |
|
133 |
┘ |
149 |
× |
165 |
╓ |
181 |
╢ |
197 |
е |
213 |
у |
229 |
Е |
245 |
У |
|
134 |
├ |
150 |
√ |
166 |
╕ |
182 |
┬ |
198 |
ф |
214 |
ж |
230 |
Ф |
246 |
Ж |
|
135 |
┤ |
151 |
≈ |
167 |
╖ |
183 |
╤ |
199 |
г |
215 |
в |
231 |
Г |
247 |
В |
|
136 |
┬ |
152 |
≤ |
168 |
┐ |
184 |
╥ |
200 |
х |
216 |
ь |
232 |
Х |
248 |
Ь |
|
137 |
┴ |
153 |
≥ |
169 |
└ |
185 |
┴ |
201 |
и |
217 |
ы |
233 |
И |
249 |
Ы |
|
138 |
┼ |
154 |
170 |
╘ |
186 |
╨ |
202 |
й |
218 |
з |
234 |
Й |
250 |
З |
|
|
139 |
▀ |
155 |
õ |
171 |
╙ |
187 |
╩ |
203 |
к |
219 |
ш |
235 |
К |
251 |
Ш |
|
140 |
▄ |
156 |
· |
172 |
┘ |
188 |
┼ |
204 |
л |
220 |
э |
236 |
Л |
252 |
Э |
|
141 |
█ |
157 |
² |
173 |
╛ |
189 |
╪ |
205 |
м |
221 |
щ |
237 |
М |
253 |
Щ |
|
142 |
▌ |
158 |
· |
174 |
╜ |
190 |
╫ |
206 |
н |
222 |
ч |
238 |
Н |
254 |
Ч |
|
143 |
▐ |
159 |
÷ |
175 |
├ |
191 |
ё |
207 |
о |
223 |
ъ |
239 |
О |
255 |
Ъ |
1.2.6. Универсальная система кодирования текстовых данных
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостаточных ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее). Во второй половине 90-х годов технические средства достигли необходимого уровня обеспеченности ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования. Для индивидуальных пользователей это еще больше добавило забот по согласованию документов, выполненных в разных системах кодирования, с программными средствами, но это надо понимать как трудности переходного периода.
1.2.7. Кодирование графических данных
Если рассмотреть с помощью увеличительного стекла черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, образующих характерный узор, называемый растром.
Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных. Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие. В качестве таких составляющих используют три основные цвета: красный (Red, R), зеленый (Green, G) и синий (Blue, В). На практике считается, что любой цвет, видимый человеческим глазом, можно получить путем механического смешения этих трех основных цветов. Такая система кодирования называется системой RGB по первым буквам названий основных цветов.
Если для кодирования яркости каждой из основных составляющих использовать по 256 значений (восемь двоичных разрядов), как это принято для полутоновых черно-белых изображений, то на кодирование цвета одной точки надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 млн различных цветов, что на самом деле близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color).
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Нетрудно заметить, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных основных цветов. Соответственно, дополнительными цветами являются: голубой (Cyan, С), пурпурный (Magenta, М) и желтый (Yellow, Y). Принцип декомпозиции произвольного цвета на составляющие компоненты можно применять не только для основных цветов, но и для дополнительных, то есть любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющей. Такой метод кодирования цвета принят в полиграфии, но в полиграфии используется еще и четвертая краска — черная (Black, К). Поэтому данная система кодирования обозначается четырьмя буквами CMYK (черный цвет обозначается буквой К, потому, что буква В уже занята синим цветом), и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим тоже называется полноцветным (True Color).
Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color.
При кодировании информации о цвете с помощью восьми бит данных можно передать только 256 цветовых оттенков. Такой метод кодирования цвета называется индексным. Смысл названия в том, что, поскольку 256 значений совершенно недостаточно, чтобы передать весь диапазон цветов, доступный человеческому глазу, код каждой точки растра выражает не цвет сам по себе, а только его номер (индекс) в некоей справочной таблице, называемой палитрой. Разумеется, эта палитра должна прикладываться к графическим данным — без нее нельзя воспользоваться методами воспроизведения информации на экране или бумаге (то есть, воспользоваться, конечно, можно, но из-за неполноты данных полученная информация не будет адекватной: листва на деревьях может оказаться красной, а небо — зеленым).
1.2.8. Кодирование звуковой информации
Приемы и методы работы со звуковой информацией пришли в вычислительную технику наиболее поздно. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но если говорить обобщенно, то можно выделить два основных направления.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства — аналого-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки. В то же время данный метод кодирования обеспечивает весьма компактный код, и потому он нашел применение еще в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
Метод таблично-волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них). В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются “реальные” звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
1.2.9. Основные структуры данных
Работа с большими наборами данных автоматизируется проще, когда данные упорядочены, то есть образуют заданную структуру. Существует три основных типа структур данных: линейная, иерархическая и табличная. Их можно рассмотреть на примере обычной книги.
Если разобрать книгу на отдельные листы и перемешать их, книга потеряет свое назначение. Она по-прежнему будет представлять набор данных, но подобрать адекватный метод для получения из нее информации весьма непросто.
Если же собрать все листы книги в правильной последовательности, мы получим простейшую структуру данных — линейную. Такую книгу уже можно читать, хотя для поиска нужных данных ее придется прочитать подряд, начиная с самого начала, что не всегда удобно.
Для быстрого поиска данных существует иерархическая структура. Так, например, книги разбивают на части, разделы, главы, параграфы и т. п. Элементы структуры более низкого уровня входят в элементы структуры более высокого уровня: разделы состоят из глав, главы из параграфов и т. д.
Для больших массивов поиск данных в иерархической структуре намного проще, чем в линейной, однако и здесь необходима навигация, связанная с необходимостью просмотра. На практике задачу упрощают тем, что в большинстве книг есть вспомогательная перекрестная таблица, связывающая элементы иерархической структуры с элементами линейной структуры, то есть связывающая разделы, главы и параграфы с номерами страниц. В книгах с простой иерархической структурой, рассчитанных на последовательное чтение, эту таблицу принято называть оглавлением, а в книгах со сложной структурой, допускающей выборочное чтение, ее называют содержанием.
1.2.10. Линейные структуры (списки данных, векторы данных)
Линейные структуры — это хорошо знакомые нам списки. Список — это простейшая структура данных, отличающаяся тем, что каждый элемент данных однозначно определяется своим номером в массиве. Проставляя номера на отдельных страницах рассыпанной книги, мы создаем структуру списка. Обычный журнал посещаемости занятий, например, имеет структуру списка, поскольку все студенты группы зарегистрированы в нем под своими уникальными номерами. Мы называем номера уникальными потому, что в одной группе не могут быть зарегистрированы два студента с одним и тем же номером.
При создании любой структуры данных надо решить два вопроса: как разделять элементы данных между собой и как разыскивать нужные элементы. В журнале посещаемости, например, это решается так: каждый новый элемент списка заносится с новой строки, то есть разделителем является конец строки. Тогда нужный элемент можно разыскать по номеру строки.
|
N п/п |
Фамилия, Имя, Отчество |
|
1 |
Аистов Александр Алексеевич |
|
2 |
Бобров Борис Борисович |
|
3 |
Воробьева Валентина Владиславовна |
|
… |
…………………………………………. |
|
27 |
Сорокин Сергей Семенович |
Разделителем может быть и какой-нибудь специальный символ. Нам хорошо известны разделители между словами — это пробелы. В русском и во многих европейских языках общепринятым разделителем предложений является точка. В рассмотренном нами классном журнале в качестве разделителя можно использовать любой символ, который не встречается в самих данных, например символ “*”. Тогда наш список выглядел бы так:
Аистов Александр Алексеевич * Бобров Борис Борисович * Воробьева Валентина Владиславовна *... * Сорокин Сергей Семенович
В этом случае для розыска элемента с номером n надо просмотреть список начиная с самого начала и пересчитать встретившиеся разделители. Когда будет отсчитано n-1 разделителей, начнется нужный элемент. Он закончится, когда будет встречен следующий разделитель.
Еще проще можно действовать, если все элементы списка имеют равную длину. В этом случае разделители в списке вообще не нужны. Для розыска элемента с номером n надо просмотреть список с самого начала и отсчитать а(n-1) символ, где а — длина одного элемента. Со следующего символа начнется нужный элемент. Его длина тоже равна а, поэтому его конец определить нетрудно. Такие упрощенные списки, состоящие из элементов равной длины, называют векторами данных. Работать с ними особенно удобно.
Таким образом, линейные структуры данных (списки) — это упорядоченные структуры, в которых адрес элемента однозначно определяется его номером.
1.2.11. Табличные структуры (таблицы данных, матрицы данных)
С таблицами данных мы тоже хорошо знакомы, достаточно вспомнить всем известную таблицу умножения. Табличные структуры отличаются от списочных тем, что элементы данных определяются адресом ячейки, который состоит не из одного параметра, как в списках, а из нескольких. Для таблицы умножения, например, адрес ячейки определяется номерами строки и столбца. Нужная ячейка находится на их пересечении, а элемент выбирается из ячейки.
При хранении табличных данных количество разделителей должно быть больше, чем для данных, имеющих структуру списка. Например, когда таблицы печатают в книгах, строки и столбцы разделяют графическими элементами — линиями вертикальной и горизонтальной разметки (рис. 1.1).
|
Планета |
Расстояние до Солнца, а.е. |
Относительная масса |
Количество спутников |
|
Меркурий |
0,39 |
0,056 |
0 |
|
Венера |
0,67 |
0,88 |
0 |
|
Земля |
1,0 |
1,0 |
1 |
|
Юпитер |
5,2 |
318 |
16 |
Рис.1.1. В двумерных таблицах, которые печатаются в книгах, применяется два типа разделителей – вертикальные и горизонтальные
Если нужно сохранить таблицу в виде длинной символьной строки, используют один символ-разделитель между элементами, принадлежащими одной строке, и другой разделитель для отделения строк, например так:
Меркурий*0,39*0,056*0#Венера*0,67*0,88*0#Земля*1,0*1,0*1# Юпитер*5,2*318*16#...
Для розыска элемента, имеющего адрес ячейки (m, n), надо просмотреть набор данных с самого начала и пересчитать внешние разделители. Когда будет отсчитан m-1 разделитель, надо пересчитывать внутренние разделители. После того как будет найден n-1 разделитель, начнется нужный элемент. Он закончится, когда будет встречен любой очередной разделитель.
Еще проще можно действовать, если все элементы таблицы имеют равную длину. Такие таблицы называют матрицами. В данном случае разделители не нужны, поскольку все элементы имеют равную длину и количество их известно. Для розыска элемента с адресом (m, n) в матрице, имеющей М строк и N столбцов, надо просмотреть ее с самого начала и отсчитать а [N(m -1) + (n -1)] символ, где а — длина одного элемента. Со следующего символа начнется нужный элемент. Его длина тоже равна а, поэтому его конец определить нетрудно.
Таким образом, табличные структуры данных (матрицы) — это упорядоченные структуры, в которых адрес элемента определяется номером строки и номером столби/а, на пересечении которых находится ячейка, содержащая искомый элемент.
Многомерные таблицы. Выше мы рассмотрели пример таблицы, имеющей два измерения (строка и столбец), но в жизни нередко приходится иметь дело с таблицами, у которых количество измерений больше. Вот пример таблицы, с помощью которой может быть организован учет учащихся.
| Номер факультета: |
3 |
| Номер курса (на факультете): |
2 |
| Номер специальности (на курсе): |
2 |
| Номер группы в потоке одной специальности: |
1 |
| Номер учащегося в группе: |
19 |
Размерность такой таблицы равна пяти, и для однозначного отыскания данных об учащемся в подобной структуре надо знать все пять параметров (координат).
1.2.12. Иерархические структуры данных
Нерегулярные данные, которые трудно представить в виде списка или таблицы, часто представляют в виде иерархических структур. С подобными структурами мы очень хорошо знакомы по обыденной жизни. Иерархическую структуру имеет система почтовых адресов. Подобные структуры также широко применяют в научных систематизациях и всевозможных классификациях (рис. 1.2).
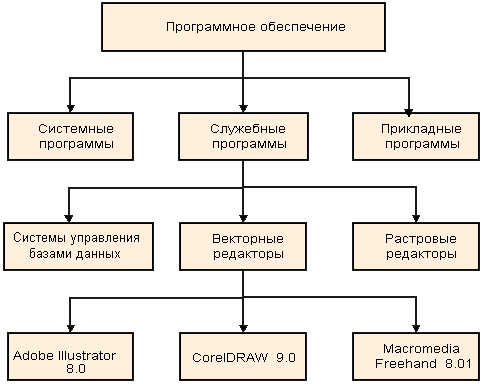
Рис. 1.2. Пример иерархической структуры данных
В иерархической структуре адрес каждого элемента определяется путем доступа (маршрутом), ведущим от вершины структуры к данному элементу. Вот, например, как выглядит путь доступа к команде, запускающей программу Калькулятор (стандартная программа компьютеров, работающих в операционной системе Windows 98):
Пуск > Программы > Стандартные > Калькулятор
1.2.13. Упорядочение структур данных
Списочные и табличные структуры являются простыми. Ими легко пользоваться, поскольку адрес каждого элемента задается числом (для списка), двумя числами (для двумерной таблицы) или несколькими числами для многомерной таблицы. Они также легко упорядочиваются. Основным методом упорядочения является сортировка. Данные можно сортировать по любому избранному критерию, например:по алфавиту, по возрастанию порядкового номера или по возрастанию какого-либо параметра.
Несмотря на многочисленные удобства, у простых структур данных есть и недостаток — их трудно обновлять. Если, например, перевести студента из одной группы в другую, изменения надо вносить сразу в два журнала посещаемости; при этом в обоих журналах будет нарушена списочная структура. Если переведенного студента вписать в конец списка группы, нарушится упорядочение по алфавиту, а если его вписать в соответствии с алфавитом, то изменятся порядковые номера всех студентов, которые следуют за ним.
Таким образом, при добавлении произвольного элемента, в упорядоченную структуру списка может происходить изменение адресных данных у других элементов. В журналах успеваемости это пережить нетрудно, но в системах, выполняющих автоматическую обработку данных, нужны специальные методы для решения этой проблемы.
Иерархические структуры данных по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных. Их легко развивать путем создания новых уровней. Даже если в учебном заведении будет создан новый факультет, это никак не отразится на пути доступа к сведениям об учащихся прочих факультетов.
Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочения. Часто методы упорядочения в таких структурах основывают на предварительной индексации, которая заключается в том, что каждому элементу данных присваивается свой уникальный индекс, который можно использовать при поиске, сортировке и т. п. Ранее рассмотренный принцип дихотомии на самом деле является одним из методов индексации данных в иерархических структурах. После такой индексации данные легко разыскиваются по двоичному коду связанного с ними индекса.
Адресные данные. Если данные хранятся не как попало, а в организованной структуре (причем любой), то каждый элемент данных приобретает новое свойство (параметр), который можно назвать адресом. Конечно, работать с упорядоченными данными удобнее, но за это приходится платить их размножением, поскольку адреса элементов данных — это тоже данные, и их тоже надо хранить и обрабатывать.
1.3. Файлы и файловая структура
1.3.1. Единицы представления данных
Существует множество систем представления данных. С одной из них, принятой в информатике и вычислительной технике, двоичным кодом, мы познакомились выше. Наименьшей единицей такого представления является бит (двоичный разряд).
Совокупность двоичных разрядов, выражающих числовые или иные данные, образует некий битовый рисунок. Практика показывает, что с битовым представлением удобнее работать, если этот рисунок имеет регулярную форму. В настоящее время в качестве таких форм используются группы из восьми битов, которые называются байтами.
|
Десятичное число |
Двоичное число |
Байт |
|
1 |
1 |
0000 0001 |
|
2 |
10 |
0000 0010 |
|
… |
… |
… |
|
255 |
11111111 |
1111 1111 |
Выше мы видели, что во многих случаях целесообразно использовать не восьмиразрядное кодирование, а 16-разрядное, 24-разрядное, 32-разрядное и более. Группа из 16 взаимосвязанных бит (двух взаимосвязанных байтов) в информатике называется словом. Соответственно, группы из четырех взаимосвязанных байтов (32 разряда) называются удвоенным словом, а группы из восьми байтов (64 разряда) — учетверенным словом. Пока, на сегодняшний день, такой системы обозначения достаточно.
1.3.2. Единицы измерения данных
Существует много различных систем и единиц измерения данных. Каждая научная дисциплина и каждая область человеческой деятельности может использовать свои, наиболее удобные или традиционно устоявшиеся единицы. В информатике для измерения данных используют тот факт, что разные типы данных имеют универсальное двоичное представление, и потому вводят свои единицы данных, основанные на нем.
Наименьшей единицей измерения является байт. Поскольку одним байтом, как правило, кодируется один символ текстовой информации, то для текстовых документов размер в байтах соответствует лексическому объему в символах (пока исключение представляет рассмотренная выше универсальная кодировка UNICODE).
Более крупная единица измерения — килобайт (Кбайт). Условно можно считать, что 1 Кбайт примерно равен 1000 байт. Условность связана с тем, что для вычислительной техники, работающей с двоичными числами, более удобно представление чисел в виде степени двойки, и потому на самом деле 1 Кбайт равен 210 байт (1024 байт). Однако всюду, где это не принципиально, с инженерной погрешностью (до 3 %) “забывают” о “лишних” байтах.
В килобайтах измеряют сравнительно небольшие объемы данных. Условно можно считать, что одна страница неформатированного машинописного текста составляет около 2 Кбайт.
Более крупные единицы измерения данных образуются добавлением префиксов мега-, гига-, тера-; в более крупных единицах пока нет практической надобности.
1 Мбайт = 1024 Кбайт = 1020 байт
1 Гбайт = 1024 Мбайт = 1030 байт
1 Тбайт = 1024 Гбайт = 1040 байт
Особо обратим внимание на то, что при переходе к более крупным единицам “инженерная” погрешность, связанная с округлением, накапливается и становится недопустимой, поэтому на старших единицах измерения округление производится реже.
1.3.3. Единицы хранения данных
При хранении данных решаются две проблемы: как сохранить данные в наиболее компактном виде и как обеспечить к ним удобный и быстрый доступ (если доступ не обеспечен, то это не хранение). Для обеспечения доступа необходимо, чтобы данные имели упорядоченную структуру, а при этом, как мы уже знаем, образуется “паразитная нагрузка” в виде адресных данных. Без них нельзя получить доступ к нужным элементам данных, входящих в структуру.
Поскольку адресные данные тоже имеют размер и тоже подлежат хранению, хранить данные в виде мелких единиц, таких, как байты, неудобно. Их неудобно хранить и в более крупных единицах (килобайтах, мегабайтах и т. п.), поскольку неполное заполнение одной единицы хранения приводит к неэффективности хранения.
В качестве единицы хранения данных принят объект переменной длины, называемый файлом. Файл — это последовательность произвольного числа байтов, обладающая уникальным собственным именем. Обычно в отдельном файле хранят данные, относящиеся к одному типу. В этом случае тип данных определяет тип файла.
Проще всего представить себе файл в виде безразмерного канцелярского досье, в которое можно по желанию добавлять содержимое или извлекать его оттуда. Поскольку в определении файла нет ограничений на размер, можно представить себе файл, имеющий 0 байтов (пустой файл), и файл, имеющий любое число байтов.
В определении файла особое внимание уделяется имени. Оно фактически несет в себе адресные данные, без которых данные, хранящиеся в файле, не станут информацией из-за отсутствия метода доступа к ним. Кроме функций, связанных с адресацией, имя файла может хранить и сведения о типе данных, заключенных в нем. Для автоматических средств работы с данными это важно, поскольку по имени файла они могут автоматически определить адекватный метод извлечения информации из файла.
1.3.4. Понятие о файловой структуре
Требование уникальности имени файла очевидно — без этого невозможно гарантировать однозначность доступа к данным. В средствах вычислительной техники требование уникальности имени обеспечивается автоматически — создать файл с именем, тождественным уже имеющемуся, не может ни пользователь, ни автоматика.
Хранение файлов организуется в иерархической структуре, которая в данном случае называется файловой структурой. В качестве вершины структуры служит имя носителя, на котором сохраняются файлы. Далее файлы группируются в каталоги (папки), внутри которых могут быть созданы вложенные каталоги (папки). Путь доступа к файлу начинается с имени устройства и включает все имена каталогов (папок), через которые проходит. В качестве разделителя используется символ “\” (обратная косая черта).
Уникальность имени файла обеспечивается тем, что полным именем файла считается собственное имя файла вместе с путем доступа к нему. Понятно, что в этом случае на одном носителе не может быть двух файлов с тождественными полными именами.
Пример записи полного имени файла:
<имя носителя>\<имя каталога-1 >\...\<имя каталога-М>\<собственное имя файла>
Вот пример записи двух файлов, имеющих одинаковое собственное имя и размещенных на одном носителе, но отличающихся путем доступа, то есть полным именем. Для наглядности имена каталогов (папок) напечатаны прописными буквами.
С:\ЭЛЕКТРОННАЯ КОММЕРЦИЯ\ДОКЛАДЫ\БЕЗОПАСНОСТЬ\Цифровая подпись
С:\ТЕЛЕКОММУНИКАЦИИ\РАДИОСВЯЗЬ\Результаты исследований
О том, как на практике реализуются файловые структуры, мы узнаем несколько позже, когда познакомимся со средствами вычислительной техники и с понятием файловой системы.
1.4. Информатика
1.4.1. Предмет и задачи информатики
Информатика — это техническая наука, систематизирующая приемы создания, хранения, воспроизведения, обработки и передачи данных средствами вычислительной техники, а также принципы функционирования этих средств и методы управления ими.
Из этого определения видно, что информатика очень близка к технологии, поэтому ее предмет нередко называют информационной технологией.
Предмет информатики составляют следующие понятия:
- аппаратное обеспечение средств вычислительной техники;
- программное обеспечение средств вычислительной техники;
- средства взаимодействия аппаратного и программного обеспечения;
- средства взаимодействия человека с аппаратными и программными средствами.
Как видно из этого списка, в информатике особое внимание уделяется вопросам взаимодействия. Для этого даже есть специальное понятие — интерфейс. Методы и средства взаимодействия человека с аппаратными и программными средствами называют пользовательским интерфейсом. Соответственно, существуют аппаратные интерфейсы, программные интерфейсы и аппаратно-программные интерфейсы.
Основной задачей информатики является систематизация приемов и методов работы с аппаратными и программными средствами вычислительной техники. Цель систематизации состоит в выделении, внедрении и развитии передовых, наиболее эффективных технологий, в автоматизации этапов работы с данными, а также в методическом обеспечении новых технологических исследований.
Информатика — практическая наука. Ее достижения должны проходить подтверждение практикой и приниматься в тех случаях, когда они соответствуют критерию повышения эффективности. В составе основной задачи информатики сегодня можно выделить следующие направления для практических приложений:
- архитектура вычислительных систем (приемы и методы построения систем, предназначенных для автоматической обработки данных);
- интерфейсы вычислительных систем (приемы и методы управления аппаратным и программным обеспечением);
- программирование (приемы, методы и средства разработки компьютерных программ);
- преобразование данных (приемы и методы преобразования структур данных);
- защита информации (обобщение приемов, разработка методов и средств защиты данных);
- автоматизация (функционирование программно-аппаратных средств без участия человека);
- стандартизация (обеспечение совместимости между аппаратными и программными средствами, а также между форматами представления данных, относящихся к различным типам вычислительных систем).
На всех этапах технического обеспечения информационных процессов для информатики ключевым понятием является эффективность. Для аппаратных средств под эффективностью понимают отношение производительности оборудования к его стоимости (с учетом стоимости эксплуатации и обслуживания). Для программного обеспечения под эффективностью понимают производительность лиц, работающих с ними (пользователей). В программировании под эффективностью понимают объем программного кода, создаваемого программистами в единицу времени.
В информатике все жестко ориентировано на эффективность. Вопрос, как сделать ту или иную операцию, для информатики является важным, но не основным. Основным же является вопрос, как сделать данную операцию эффективно.
1.4.2. Истоки и предпосылки информатики
Слово информатика происходит от французского слова Informatique, образованного в результате объединения терминов Informacion (информация) и Automatique (автоматика), что выражает ее суть как науки об автоматической обработке информации. Кроме Франции термин информатика используется в ряде стран Восточной Европы. В то же время, в большинстве стран Западной Европы и США используется другой термин — Computer Sience (наука о средствах вычислительной техники).
В качестве источников информатики обычно называют две науки — документалистику и кибернетику. Документалистика сформировалась в конце XIX века в связи с бурным развитием производственных отношений. Ее расцвет пришелся на 20-30-е годы XX века, а основным предметом стало изучение рациональных средств и методов повышения эффективности документооборота.
Основы близкой к информатике технической науки кибернетики были заложены трудами по математической логике американского математика Норберта Винера, опубликованными в 1948 году, а само название происходит от греческого слова (kyberneticos — искусный в управлении).
Впервые термин кибернетика ввел французский физик Андре Мари Ампер в первой половине XIX веке. Он занимался разработкой единой системы классификации всех наук и обозначил этим термином гипотетическую науку об управлении, которой в то время не существовало, но которая, по его мнению, должна была существовать.
Сегодня предметом кибернетики являются принципы построения и функционирования систем автоматического управления, а основными задачами — методы моделирования процесса принятия решений техническими средствами, связь между психологией человека и математической логикой, связь между информационным процессом отдельного индивидуума и информационными процессами в обществе, разработка принципов и методов искусственного интеллекта. На практике кибернетика во многих случаях опирается на те же программные и аппаратные средства вычислительной техники, что и информатика, а информатика, в свою очередь, заимствует у кибернетики математическую и логическую базу для развития этих средств.
Итоги
Все процессы в природе сопровождаются сигналами. Зарегистрированные сигналы образуют данные. Данные преобразуются, транспортируются и потребляются с помощью методов. При взаимодействии данных и адекватных им методов образуется информация. Информация — это динамический объект, образующийся в ходе информационного процесса. Он отражает диалектическую связь между объективными данными и субъективными методами. Свойства информации зависят как от свойств данных, так и от свойств методов.
Данные различаются типами, что связано с различиями в физической природе сигналов, при регистрации которых образовались данные. В качестве средства хранения и транспортировки данных используются носители данных. Для удобства операций с данными их структурируют. Наиболее широко используются следующие структуры: линейная, табличная и иерархическая — они различаются методом адресации к данным. При сохранении данных образуются данные нового типа — адресные данные.
Вопросами систематизации приемов и методов создания, хранения, воспроизведения, обработки и передачи данных средствами вычислительной техники занимается техническая наука — информатика. С целью унификации приемов и методов работы с данными в вычислительной технике применяется универсальная система кодирования данных, называемая двоичным кодом. Элементарной единицей представления данных в двоичном коде является двоичный разряд (бит). Другой, более крупной единицей представления данных является байт.
Основной единицей хранения данных является файл. Файл представляет собой последовательность байтов, имеющую собственное имя. Совокупность файлов образует файловую структуру, которая, как правило, относится к иерархическому типу. Полный адрес файла в файловой структуре является уникальным и включает в себя собственное имя файла и путь доступа к нему.
Вопросы для самоконтроля
- Как вы можете объяснить бытовой термин “переизбыток информации”? Что имеется в виду: излишняя полнота данных; излишняя сложность методов; неадекватность поступающих данных и методов, имеющихся в наличии?
- Как вы понимаете термин “средство массовой информации”? Что это? Средство массовой поставки данных? Средство, обеспечивающее массовое распространение методов? Средство, обеспечивающее процесс информирования путем поставки данных гражданам, обладающим адекватными методами их потребления?
- Как вы полагаете, являются ли данные товаром? Могут ли методы быть товаром?
- На примере коммерческих структур, обеспечивающих коммуникационные услуги, покажите, как взаимодействуют между собой маркетинг данных и маркетинг методов? Можете ли вы привести примеры лизинга данных и методов?
- Как вы понимаете диалектическое единство данных и методов? Можете ли вы привести примеры аналогичного единства двух понятий из других научных дисциплин: естественных, социальных, технических?
- Как вы понимаете динамический характер информации? Что происходит с ней по окончании информационного процесса?
- Можем ли мы утверждать, что данные, полученные в результате информационного процесса, адекватны исходным? Почему? От каких свойств исходных данных и методов зависит адекватность результирующих данных?
- Что такое вектор данных? Является ли список номеров телефонов населенного пункта вектором данных? Является ли вектором данных текстовый документ, закодированный двоичным кодом, если он не содержит элементов оформления?
- Является ли цифровой код цветного фотоснимка вектором данных? Если нет, то чего ему не хватает?
- Как вы понимаете следующие термины: аппаратно-программный интерфейс, программный интерфейс, аппаратный интерфейс? Как бы вы назвали специальность людей, разрабатывающих аппаратные интерфейсы? Как называется специальность людей, разрабатывающих программные интерфейсы?
- На основе личных наблюдений сделайте вывод о том, какими средствами может пользоваться преподаватель для обеспечения интерфейса с аудиторией. Можете ли вы рассмотреть отдельно методические и технические средства, имеющиеся в его распоряжении? Может ли преподаватель рассматривать вашу тетрадь и авторучку как свое средство обеспечения интерфейса? Если да, то в какой мере?