2. Абонентские терминалы систем связи с подвижными объектами
3. Речеобразование и характеристики речи
4. Характеристики слуха и разборчивость речи
5. Акустоэлектрические и электроакустические преобразователи
6. Передача речевых сигналов по сетям связи
7. Основы цифрового представления речевых сигналов: импульсно-кодовая модуляция
8. Дифференциальные методы кодовой модуляции
9. Адаптивные методы кодирования формы речевого сигнала
10. Основы параметрического кодирования речи
11. Вокодеры с линейным предсказанием (липредеры)
12. Кодирование речи в гибридных кодерах
13. Речевые кодеки для абонентского терминала стандарта GSM
14. Оценка качества передачи речи
15. Повышение помехоустойчивости цифрового канала передачи
16. Цифровая модуляция в системах подвижной связи
1. Введение
Одним из наиболее динамично развивающихся видов связи является связь с подвижными объектами, значительно расширяющая рамки традиционной услуги телефонной связи. Применение радиосвязи на абонентском участке позволяет иметь доступ к каналу связи при перемещениях в пространстве. При этом сохраняется возможность соединения с подвижным абонентом по его неизменному номеру.
Радиотелефонная связь с подвижными объектами в районах с относительно высокой плотностью населения реализуется посредством наземных систем подвижной радиосвязи (СПРС). Однако в районах с низкой плотностью населения естественно применять системы персональной спутниковой связи (СПСС) - различные по построению спутниковые системы с космическими аппаратами на орбитах разного типа, работающие в различных диапазонах частот и предоставляющие пользователю различные услуги связи с помощью персонального терминала - как правило, вне зоны действия СПРС.
Основной тенденцией развития систем подвижной радиосвязи в целом является использование цифровых методов передачи. Наиболее привлекательные стороны цифровых методов передачи состоят в том, что они более эффективны в условиях сильных помех, обеспечивают рациональное использование радиочастотного ресурса и, кроме того, цифровая техника характеризуется высокими темпами улучшения характеристик, снижения стоимости и потребляемой мощности. Успехи технологии сверхвысокого порядка интеграции элементов сделали цифровую обработку сигналов связи и их цифровую передачу по радиоканалам более эффективной, нежели аналоговая обработка и аналоговые методы передачи. К наиболее эффективным методам цифровой обработки и передачи речевых сигналов относятся:
- преобразование и кодирование (кодирование источника), позволяющие эффективно устранить избыточность в таких сигналах, благодаря чему в несколько раз уменьшить скорость передаваемого цифрового потока по сравнению с методами ИКМ;
- помехоустойчивое кодирование канала - кодирование с исправлением ошибок, представляющее собой метод обработки сигналов, предназначенный для увеличения надежности их передачи по цифровым каналам за счет специально вводимой избыточности;
- методы цифровой модуляции, которые позволяют повысить эффективность использования радиочастотного ресурса по сравнению с аналоговыми методами.
Использование цифровых методов передачи и временного разделения каналов (ВРК) в системах подвижной радиосвязи позволяет обеспечить: повышенную скорость передачи сообщений; одновременную передачу в стандартном формате речевых сообщений и данных; совместную передачу информационных сообщений и сигналов управления без взаимного мешающего влияния; стабильно высокий уровень разборчивости передаваемых речевых сообщений в условиях всего диапазона дальности связи; надежную и технически несложную защиту передаваемых сообщений; непрерывный контроль качества функционирования каналов связи.
Ведущее положение на рынке систем связи с подвижными объектами занимают:
- профессиональные СПРС - транковая (транкинговая) связь;
- системы сотовой подвижной радиосвязи - сотовая связь;
- системы персонального радиовызова - пейджинговая связь;
- системы беспроводных телефонов.
Профессиональные СПРС, как правило, имеют радиальную или радиально-зоновую структуру сети и, в отличие от сотовых систем, не обеспечивают непрерывности связи при пересечении абонентами границ зон радиопокрытия (передача обслуживания - handover) и не имеют автоматического роуминга - автоматической регистрации и поддержания связи при перемещении в другую зону обслуживания. Наиболее полно перечисленные выше достоинства цифровых технологий присущи перспективной транкинговой СПРС стандарта TETRA.
Основные усилия при разработке новых СПРС сосредоточены на обеспечении высоких показателей в части помехоустойчивости и пропускной способности системы передачи, эффективности использования выделенного спектра частот (частотной эффективности). В этом отношении наиболее перспективными признаны сотовые системы подвижной связи (ССПС) - системы связи с пространственно-разнесенным повторным использованием частот, когда выделенные частотные каналы многократно используются абонентами в ячейках, разнесенных друг от друга на необходимое защитное расстояние. Сеть ССПС состоит из множества приемо-передающих базовых станций (БС), которые обеспечивают все физические функции, требуемые для приема и передачи сообщений через радиоинтерфейс. Зона действия одной БС называется «сотой».
В настоящее время внедрены три стандарта цифровых ССПС второго поколения. Они разработаны и приняты в разных странах, отличаются своими характеристиками, но построены на единых принципах - используют макросотовую топологию сети с радиусом сот до 35 км, ВРК и отвечают требованиям современных информационных технологий. Это: общеевропейский стандарт GSM; американский стандарт ADC (D-AMPS) и японский стандарт JDC (PDC). Основные характеристики указанных стандартов приведены в табл.1.1.
Таблица 1.1.
| Характеристики стандарта |
GSM |
D-AMPS |
PDC |
|
|
1 |
Метод доступа |
ВРК |
ВРК |
ВРК |
|
2 |
Разнос частот, кГц |
200 |
30 |
25 |
|
3 |
Общая полоса частот, МГц |
25 |
25 |
25 |
|
4 |
Эквивалентная полоса частот на речевой канал, кГц |
25 |
10 |
8,3 |
|
5 |
Число речевых каналов связи |
1000 |
2500 |
3000 |
|
6 |
Число каналов на соту |
500 |
357 |
750 |
|
7 |
Скорость преобразования речи, кбит/с |
13 |
8 |
11,2 |
|
8 |
Алгоритм преобразования речи |
RPE-LTP |
VSELP |
VSELP |
|
9 |
Общая скорость передачи, кбит/с |
270 |
48 |
42 |
|
10 |
Вид модуляции |
0,3 GMSK |
DQPSK |
DQPSK |
|
11 |
Радиус соты, км |
0,5...35 |
0,5...20 |
0,5...20 |
|
12 |
Частотный диапазон, МГц |
900 |
800 |
800...1500 |
В настоящее время в мире доминирует общеевропейский стандарт GSM. В рамках этого стандарта абонент может воспользоваться более чем 60 услугами, среди которых наиболее востребованы: глобальный роуминг, определитель номера, короткие текстовые сообщения (SMS), система голосовых сообщений, улучшенное полноскоростное кодирование речи и ряд других. Одним из последних достижений техники подвижной радиосвязи является технология пакетной передачи данных по радиоканалу GPRS. Основные преимущества этой технологии: весьма высокая скорость передачи данных (до 171,2 кбит/с), аппарат постоянно подключен к сети Интернет, а оплата осуществляется не за время работы в глобальной сети, а за объем переданных данных.
Дальнейшее развитие систем сотовой подвижной связи осуществляется в рамках проекта ССПС третьего поколения (IMT-2000) под эгидой Международного союза электросвязи (МСЭ). В настоящее время определились три основных направления развития систем третьего поколения: эволюция систем на базе технологии ВРК (GSM, IS-136) и технологии IS-95 (проект cdma2000), а также проекты новых стандартов на основе технологии широкополосной W-CDMA. Универсальная система подвижной связи 3-го поколения будет обладать качественно новыми возможностями. В результате для многих пользователей мобильный абонентский терминал (АТ) или портативное абонентское устройство станет единственным универсальным устройством доступа к услугам связи.
Современный рынок услуг подвижной связи характеризуется высокими темпами развития систем персонального радиовызова (СПРВ), обеспечивающих передачу сообщений ограниченного объема в пределах обслуживаемой зоны. Эти системы гармонично сопрягаются с системами радиосвязи и передачи данных, как по ценовым показателям, так и по разнообразию требуемых пользователю услуг мобильной связи.
Требования к функциональному развитию сетей СПРВ, увеличению скорости передачи сообщений, а также интеграции национальных сетей СПРВ в транснациональные привели к созданию в 1992 г. общеевропейского стандарта ERMES. Фирма Motorola разработала свой протокол передачи сигналов СПРВ, получивший наименование FLEX, основными достоинствами которого являются повышенная скорость передачи сообщений (до 6400 бит/с), большая емкость системы и обеспечение экономичного режима работы пейджера.
Системы беспроводных телефонов (Cordless Telephony) общего пользования, обеспечивающим своим абонентам выход на телефонную сеть общего пользования (ТфОП), составляют значительную конкуренцию сотовым системам связи. Внедрение систем беспроводных телефонов рассматривается в рамках реализации концепции персональной связи, предусматривающей предоставление услуг "всегда и в любом месте" при использовании легких малогабаритных АТ в рамках микро- и пикосотовых сетей связи. Европейская система стандарта DECT предназначена для передачи речевых сообщений и данных; технические решения и службы в этом стандарте близки принятым в стандарте GSM.
Размышления по поводу будущих систем связи привели к появлению концепции универсальной персональной связи (UPT). Согласно этой концепции несколько коммуникационных сетей - фиксированные сети, системы наземной подвижной связи и спутниковые сети подвижной связи - будут взаимодействовать друг с другом, образуя интегрированную систему, поддерживающую широкий спектр персональных услуг. Каждый пользователь определяется уникальным абонентским номером, не зависящим от сети, в которой находится в текущий момент.
Системы персональной спутниковой связи (СПСС) играют важную роль в концепции UPT. Эти системы нацелены на обеспечение доступа к телекоммуникационной сети из любой точки Земли, особенно из районов, не охваченных другими системами связи, такими, как сеть ТфОП или системы наземной подвижной связи. По сравнению с наземными системами подвижной радиосвязи системы СПСС в своем развитии задержались. Это объясняется тем, что энергетический баланс линий спутниковой связи до последнего времени не позволял уменьшить АТ до размеров телефонной трубки. Однако применение спутников на низких орбитах создает энергетические преимущества перед геостационарными спутниками и дает возможность организовать сети СПСС с персональными телефонами с ненаправленными антеннами. На вес и размеры АТ не всегда накладываются жесткие ограничения, свойственные сотовому телефону. Поэтому под СПСС понимаются различные по построению спутниковые системы с космическими аппаратами (КА) на геостационарной круговой (GEO) - высотой около 36 тыс. км, средневысотных круговых (MEO) - высотой порядка 10 тыс. км, низких круговых (LEO) - высотой 700...1500 км и вытянутых высокоэллиптических орбитах (HEO), работающие в различных диапазонах частот и предоставляющие пользователю различные услуги связи с помощью персонального терминала (портативного, мобильного, стационарного) - как правило, вне зоны действия наземных сотовых систем.
В основу классификации таких систем положены два основных признака: информационная скорость в абонентской линии и тип орбиты КА. Наибольшее распространение нашли низкоскоростные СПСС (информационная скорость передачи от 1,2 кбит/с до 9,6 кбит/с) и высокоскоростные СПСС (64 кбит/с и выше).
Низкоскоростные СПСС предназначены как для передачи данных, так и для организации персональной радиотелефонной и пейджинговой связи в глобальном масштабе. Наиболее известными системами данного класса являются системы Iridium и Globalstar. Отличительными особенностями таких систем радиотелефонной связи являются: совместимость с наземными сетями сотовой телефонной связи; передача данных со скоростью от 1,2 до 9,6 кбит/с, в том числе передача коротких однопакетных сообщений типа пейджинговых; определение координат подвижного объекта (с помощью приемника глобальной навигационной системы - GPS); возможность обеспечения связи в любое время суток в режиме реального времени; обеспечение глобального покрытия земной поверхности без мертвых зон в наиболее обжитых районах мира.
К высокоскоростным СПСС относятся глобальные системы широкополосной связи, использующие все типы орбит и предназначенные для передачи высококачественной речи, высокоскоростных потоков данных, мультимедиа, организации конференц-связи, доступа в Интернет, интерактивной связи.
2. Абонентские терминалы систем связи с подвижными объектами
Абонентские терминалы (АТ) - называемые также абонентскими устройствами и терминалами пользователя, а также подвижной станцией или подвижным терминалом - являются неотъемлемой частью любой системы связи с подвижными объектами. Именно через посредство АТ осуществляется "вхождение" пользователя в Систему связи, реализуются услуги подвижной связи. Номенклатура этих услуг определяет возможные виды передаваемой информации (речь, данные, неподвижные изображения) и, следовательно, типы терминального оборудования АТ, осуществляющего преобразование информации в электрические сигналы.
Помимо терминального, абонентский терминал содержит оконечное оборудование, которое служит для организации доступа абонентов сетей подвижной связи к существующим фиксированным сетям электросвязи. В числе основных функций оконечного оборудования: радиопередача и радиоприем, управление радиоканалами, защита от ошибок в радиоканале, кодирование - декодирование речи, текущий контроль и распределение данных пользователя и вызовов, адаптация по скорости передачи между радиоканалом и данными, обеспечение параллельной работы нагрузок (терминалов), обеспечение непрерывной работы в процессе движения.
На рис.2.1 изображена упрощенная функциональная схема сотового радиотелефона. Приведенная комплектация АТ является минимально необходимой; она характерна для абонентских устройств всех известных цифровых СПРС - и наземных, и спутниковых. В состав терминала входят следующие основные блоки: блок управления, приемопередающий блок и антенный блок. Способ реализации этих блоков определяется типом СПРС.
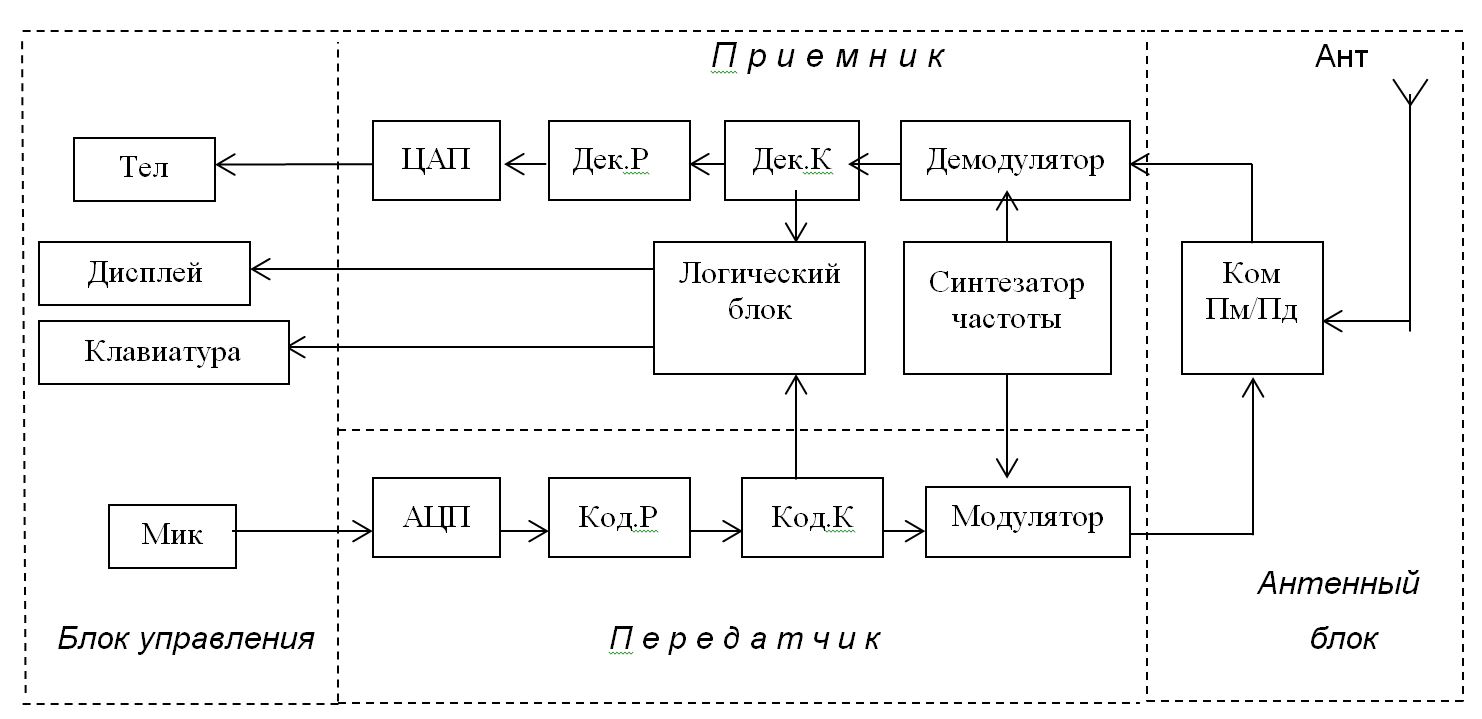
Рис. 2.1. Функциональная схема сотового радиотелефона.
На схеме приняты следующие сокращения: Тел - телефон (громкоговоритель); АЦП/ЦАП - аналого-цифровой и цифро-аналоговый преобразователи; Дек.Р - декодер речи; Дек.К - декодер канала; Ант - антенна; Ком. Пм/Пд - коммутатор прием/передача; Код.Р - кодер речи; Код.К - кодер канала; Мик - микрофон.
Антенный блок содержит собственно антенну и электронный коммутатор, подключающий антенну либо на выход передатчика, либо на вход приемника. Функционально несложен и блок управления, включающий микротелефонную трубку (микрофон + телефон), клавиатуру и дисплей. Микрофон и телефон выполняют соответственно функции акустоэлектрического и электроакустического преобразователей. Клавиатура (тестатура) служит для набора номера телефона вызываемого абонента, а также команд, определяющих режим работы АТ. Дисплей (как правило - жидкокристаллический) служит для отображения различной информации, предусматриваемой устройством и режимом работы АТ.
Приемопередающий блок - "сердце" абонентской станции - значительно сложнее. Дадим краткое упрощенное описание функций его основных компонентов:
- АЦП - преобразует в цифровую форму сигнал с выхода микрофона - в результате вся последующая обработка и передача сигнала речи производится в цифровой форме;
- кодер речи - осуществляет кодирование речевого сигнала - преобразование по определенным законам с целью сокращения его избыточности, т.е. с целью сокращения объема информации, передаваемой по каналу;
- кодер канала - добавляет в цифровой сигнал дополнительную (избыточную) информацию, предназначенную для защиты от ошибок при передаче сигнала по линии связи; а также вводит в состав передаваемого сигнала информацию управления от логического блока;
- модулятор - осуществляет перенос кодированного сигнала на несущую частоту;
- демодулятор - выполняет функцию, обратную функции модулятора, - выделяет из модулированного сигнала кодированную цифровую последовательность;
- декодер канала - выделяет из входного цифрового потока служебную и дополнительную информацию, используя последнюю для обнаружения и исправления (по возможности) ошибок, внесенных в цифровой сигнал в процессе его передачи по радиоканалу;
- декодер речи - восстанавливает цифровой речевой сигнал;
- ЦАП - преобразует принятый цифровой речевой сигнал в аналоговую форму.
В приемопередающий блок входят также синтезатор частоты и микропроцессорный логический блок, управляющий работой терминала (входные каскады приемника и выходные каскады передатчика на схеме не показаны). Синтезатор частот является источником высокостабильных колебаний; он позволяет получить высокостабильную сетку частот, необходимых для реализации дуплексного режима работы АТ в используемом диапазоне.
Логический блок сотового радиотелефона состоит из цифрового сигнального процессора, памяти, канального эквалайзера, канального кодера/декодера, SIM-карты, преобразователей АЦП и ЦАП, наборного поля и дисплея. Цифровой логический блок выполняет все функции, связанные с цифровой обработкой сигнала (демодуляция, кодирование / декодирование канала, сжатие и восстановление речевого сигнала) и обработкой информации, вводимой с наборного поля клавиатуры. Она выводит необходимую информацию на экран дисплея, производит обмен информацией с SIM-картой - специальным съемным модулем идентификации абонента, обеспечивающим аутентификацию абонента и шифрование данных.
В качестве примера АТ на рис. 2.2 приведена упрощенная структурная схема сотового радиотелефона, работающего в стандарте GSM. Часто в таких радиотелефонах имеется аналоговая и цифровая части, которые выполняются на отдельных платах. Устройство приема – супергетеродинный приемник с двойным преобразованием частоты. Принимаемый сигнал с антенны поступает на керамический полосовой фильтр, выделяющий принимаемый сигнал fc и ослабляющий помехи. Отфильтрованный сигнал усиливается в малошумящем усилителе МШУ и подается на смеситель. На второй вход смесителя с синтезатора частот поступает первый сигнал гетеродина fпрм. Выходной сигнал смесителя первой промежуточной частоты fпр1 выделяется фильтром на поверхностных акустических волнах ПАВ, усиливается в усилителе промежуточной частоты УПЧ1 и поступает на второй смеситель. На второй вход этого смесителя подается сигнал гетеродина fг. Полученный в результате преобразования сигнал второй промежуточной частоты fпр2 (450 кГц) фильтруется фильтром на ПАВ и усиливается в УПЧ2 до необходимого уровня. Затем сигнал преобразуется в цифровую форму в АЦП и поступает в центральный процессор CPU, где последовательно осуществляются демодуляция, канальный эквалайзинг, канальное декодирование и декодирование речи. Восстановленный цифровой речевой сигнал преобразуется блоком ЦАП в аналоговую форму, усиливается и поступает на громкоговоритель (телефон).
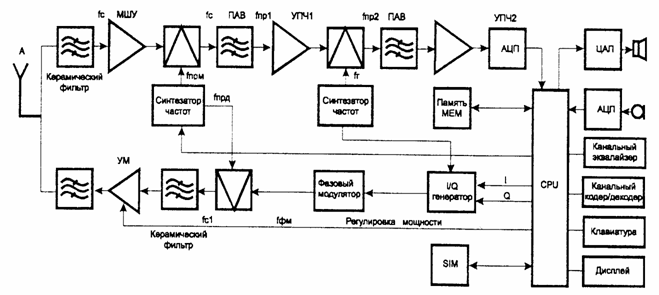
Рис. 2.2. Упрощенная структурная схема сотового радиотелефона стандарта GSM
В передающей части АТ сигнал с выхода микрофона усиливается, преобразуется блоком АЦП в цифровую форму и поступает на центральный процессор CPU, где последовательно осуществляются кодирование речи, канальное кодирование и формирование информационных цифровых потоков I и Q. В фазовом модуляторе осуществляется манипуляция фазы квадратурных несущих, сформированных в I/Q – генераторе на частоте fфм, определяемой синтезатором частот. Фазоманипулированный сигнал подается на смеситель, где осуществляется его перенос на несущую частоту fс1 с помощью частоты fпрд, поступающей от синтезатора частот. После полосовой фильтрации сигнал усиливается в регулируемом усилителе мощности УМ и через полосовой фильтр поступает в антенну для излучения в пространство.
При передаче сообщений предусматривается адаптивная регулировка уровня мощности передатчика, обеспечивающая требуемое качество связи. Обработка сигналов управления, опрос клавиатуры, формирование необходимых частот и вывод информации на дисплей происходят под управлением центрального процессора CPU, который выполняет здесь роль логического блока.
В рамках стандарта GSM приняты пять классов АТ, различающихся уровнем выходной мощности радиопередатчика, - от модели 1-го класса с мощностью Рвых= 20 Вт, устанавливаемой на транспортном средстве, до портативной модели 5-го класса, характеризуемой Рвых= 0,6 Вт.
Фактически в описанном терминале абонента совмещены все функции станций спутниковой связи (АЦП/ЦАП, модуляция, демодуляция, кодирование, декодирование, усиление мощности и т.п.). Разработка двухрежимного АТ - для наземной и спутниковой систем связи - представляет собой сложную технологическую задачу. В отличие от систем наземной персональной связи, в СПСС информационный обмен обеспечивается преимущественно только с открытого пространства. Возможность связи из зданий (при расположении антенн на подоконнике и т.п.) ограничена. Персональная спутниковая связь в городских условиях затруднена из-за затенения городскими застройками, а следовательно, работа возможна только при больших углах возвышения спутника.
Теоретически терминалы радиотелефонной связи СПСС обеспечивают практически те же виды услуг, что и в наземных сетях, но в глобальном масштабе. Аналогично, как и в наземных сетях, предполагается использование многорежимных терминалов, ориентированных на работу в сотовых сетях разных стандартов. Таким образом, наметилась тенденция к интеграции наземных систем и систем персональной спутниковой связи.
Отдельную группу АТ составляют алфавитно-цифровые и цифровой пейджеры. Скорость передачи информации составляет обычно 2400 бит/с, однако АТ Globalstar в некоторых режимах способны обеспечивать до 9600 бит/с. Передаче информации предшествует процесс установления соединения, занимающий по времени от 2 до 30 с.
3. Речеобразование и характеристики речи
Один из распространенных способов описания речи заключается в представлении ее в виде сигнала, т.е. акустического колебания, или некоторой параметрической модели.
Под речевым сигналом (РС) понимают электрическое колебание, наблюдаемое на выходе формирующего устройства (акустоэлектрического преобразователя) при воздействии на его вход акустического речевого колебания. Сообщение, передаваемое с помощью РС, является дискретным, т.е. может быть представлено в виде последовательности символов из конечного их числа. Символы, из которых состоит РС, называются фонемами. Фонемой также называют наименьшую звуковую единицу данного языка, существующую в целом ряде конкретных звуков речи. Между буквами и фонемами одного и того же языка нет однозначной связи (буквы - это то, что мы читаем, фонемы - то, что произносим), поэтому число фонем и число букв неодинаково во всех языках. В каждом языке имеется присущее ему множество фонем, обычно от 30 до 50 (в русском языке насчитывается 42 звука речи - 6 гласных и 36 согласных).
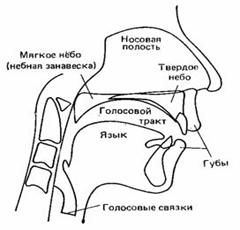
Рис. 3.1. Артикуляционный аппарат человека
Механизм речеобразования. Речь предназначена для общения. Речевое общение начинается с того, что в мозгу человека возникает в абстрактной форме некоторое сообщение. В процессе речеобразования это сообщение преобразуется в акустическое речевое колебание. Информация, содержащаяся в сообщении, представлена в акустическом колебании весьма сложным образом. Сообщение сначала преобразуется в последовательности нервных импульсов, управляющих артикуляционным аппаратом человека (рис. 3.1.). Под воздействием нервных импульсов артикуляционный аппарат приходит в движение, результатом которого является акустическое речевое колебание, несущее информацию об исходном сообщении. Знание механизма речеобразования играет важную роль для понимания методов обработки речи.
При произнесении звуков речи поток воздуха нагнетается из легких, проталкивается через трахею, гортань, полости рта и носа и затем излучается через губы и ноздри. Одну из главных ролей в образовании звуков речи играют голосовые связки, расположенные в гортани. Гортань и ротовую полость называют голосовым трактом. Голосовой тракт начинается с прохода между голосовыми связками (голосовая щель) и заканчивается у губ. Он состоит из гортани и ротовой полости. Общая длина голосового тракта у взрослого человека примерно 17 см. Площадь поперечного сечения голосового тракта определяется положением языка, губ, челюстей, небной занавески и может изменяться от 0 до 20 см2.
Изменения конфигурации голосового тракта в процессе произнесения звуков речи воздействуют на проходящую через тракт акустическую волну. При образовании носовых звуков к голосовому тракту, благодаря опущенной небной занавеске, подключается носовая полость. Изменения конфигурации голосового тракта и колебания голосовых связок взаимосвязаны, в результате вся речеобразующая система функционирует как единый сложный объект.
Голосовой тракт и носовую полость обычно представляют в виде секций цилиндрических труб (системы резонаторов) с переменной по продольной оси площадью поперечного сечения. Изменение конфигурации тракта вдоль его продольной оси и во времени описывают функцией площади поперечного сечения. В простейшем случае необходимо иметь три основные секции (отрезка трубы) и дополнительную секцию для имитации округлости губ. Такая модель (рис. 3.2) достаточно хорошо имитирует голосовой аппарат человека от голосового источника до выхода из ротовой полости. Первый резонатор (с площадью поперечного сечения A1 и длиной l1) имитирует гортань и ротовую полость до сужения, создаваемого языком (задняя полость), второй (A2 и l2) —участок сужения между языком и твердым небом, третий (A3 и l3) — переднюю ротовую полость и, наконец, четвертый (A4 и l4) — проход между губами. У каждого человека эти размеры индивидуальны и в процессе речеобразования состояние голосового тракта (т.е. сечение входящих в него труб) постоянно меняется. Каждому элементарному звуку речи (т.е. фонеме) соответствует определенная форма акустических резонаторов, обусловленная положением языка, губ, нижней челюсти и т. д. При переходе от одного звука к другому форма резонаторов плавно изменяется, подчиняясь индивидуальным особенностям голосового аппарата.
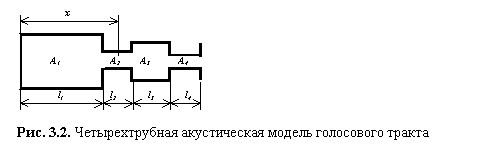
При описании речеобразования резонансные частоты трубы голосового тракта называются формантными частотами или просто формантами. Формантные частоты зависят от размеров и формы голосового тракта, который формирует формантную структуру. Произвольная форма голосового тракта может быть описана набором формантных частот, спектр которой при произнесении речи непрерывно изменяется, образуя формантные переходы.
Все звуки речи могут быть разделены на три четко выраженные группы по виду сигнала возбуждения голосового тракта: вокализованные, невокализованные, взрывные.
При произношении звонких звуков, называемых вокализованными (гласные, звонкие согласные: а, о, у, з,...), голосовые связки вибрируют (колеблются), в результате чего непрерывный воздушный поток, идущий из легких, преобразуется в импульсный. Возникающая таким образом квазипериодическая последовательность импульсного потока воздуха, возбуждает голосовой тракт. В результате акустическое колебание, излучаемое через ноздри, губы и зубы, представляет собой квазипериодический сигнал. В модели речеобразования (рис. 3.2) периодическое сокращение голосовых связок моделируется двумя резонансными контурами. Их совместное колебание управляет площадью отверстия, формирующего сигнал возбуждения.
Невокализованные звуки (глухие согласные ф, х, ш,...) образуются при сужении голосового тракта в каком-либо месте (обычно это рот) и проталкивании воздуха через суженное место с высокой скоростью, достаточной для образования вихревого воздушного потока, создающего широкополосный шум со сплошным спектром. После этого происходит перераспределение энергии шумового сигнала возбуждения по частотному диапазону в соответствии с частотной избирательностью голосового тракта. Такой шум, возбуждая голосовой тракт, создает фрикативные и взрывные звуки. При произнесении последних (п, б, ...) голосовой тракт полностью закрывается, обычно в начале. За этим местом возникает повышенное сжатие воздуха. Затем воздух резко высвобождается и формируется акустическое колебание, излучаемое голосовым трактом.
Характеристики речи. Речь представляет собой колебания сложной формы, зависящей от произносимых слов, тембра голоса, интонации, пола и возраста говорящего. Основными параметрами, используемыми при описании речевого сигнала, являются:
- статистическое распределение звуков, слогов и слов при произношении речи;
- временные характеристики звуков;
- основной тон речи;
- спектр речи;
- распределение формантных частот.
Эти параметры играют важную роль при построении систем кодирования речи.
Звуки речи разделяют на гласные и согласные. В русском языке принято выделять шесть гласных звуков: а, и, о, у, ы, э. Их классифицируют по произношению (ударные, безударные) и местоположению в словах. Согласные звуки также разделяют на несколько подгрупп — твердые, мягкие и др. Гласные звуки составляют примерно 43,5 %, а согласные — 56,5 % общего числа звуков, при этом невокализованные звуки составляют 32 %. Наиболее распространенный гласный звук — это а, самый распространенный согласный звук — г. Среди гласных звуков наиболее редким является звук э, среди согласных — фь.
Согласные фонемы (звуки) по типу делят на звонкие и глухие, а по способу образования - на щелевые (звонкие - в, з, ж и глухие – ф, с, ш, х,), взрывные, т.е. смычные (звонкие - б, г, д и глухие - п, т, к,), сонаты (носовые - м, н, щелевые -л, й, дрожащие - р) и аффрикаты (ц, ч).
Каждый звук является реализацией случайного процесса с определенными характеристиками. Длительность отдельных звуков речи составляет 20...350 мс. При этом гласные звуки имеют большую длительность (в среднем около 200 мс), чем согласные (около 80 мс, а звук "п" - около 30 мс). Звонкие звуки речи, особенно гласные, имеют высокий уровень интенсивности, глухие - низкий - в среднем на 20 дБ ниже уровня гласных. Динамический диапазон уровней речи находится в пределах 35...45 дБ.
Речь с физической точки зрения состоит из последовательности звуков речи с паузами между их группами. Паузой считается отсутствие речи в течение времени, большего 350 мс. В целом средняя длительность пауз составляет приблизительно 16 % длительности речи, а средняя скорость речи 10... 15 звуков/с. Темп речи может изменяться в широких пределах, длительность фонем, слогов и пауз также изменяется, причем длительность гласных звуков изменяется в большей степени.
Важной характеристикой вокализованных звуков является частота основного тона (ОТ) FО.Т. - частота колебаний голосовых связок или частота первой гармоники спектра вокализованных звуков; Т0 = 1 / FО.Т.- период основного тона голоса. У вокализованных звуков спектр является дискретным с большим числом (до 40) гармоник, которые имеют частоту, кратную частоте основного тона. Частота ОТ изменяется в пределах от 60...70 Гц для низких мужских голосов до 450...500 Гц для высоких женских голосов. Средняя частота ОТ для мужских голосов 130... 150 Гц, для женских — 250 Гц. Медленное изменение частоты основного тона при произнесении речи создает эмоциональную окраску и называется интонацией. У каждого человека свой диапазон изменения основного тона (немного более октавы) и своя интонация, играющая большую роль в процессе узнавания говорящего. Пример плотности распределения вероятности частоты ОТ, представлен на рис. 3.3.
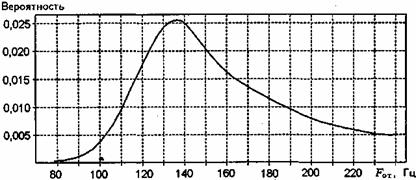
Рис. 3.3. Плотность распределения вероятности частоты основного тона (получено в течение 15 мин для речи 15 мужчин – дикторов в возрасте около 20 лет)
Спектр речи — зависимость среднего в течение длительного времени наблюдения спектрального уровня речи от частоты Вр(f) - весьма широк (примерно от 50 до 10000 Гц). Спектр русской речи, усредненный для мужских и женских голосов, представлен на рис. 3.4. Как отсюда следует, основная энергия в спектре речи сосредоточена в области низких частот. Максимальный уровень спектральной плотности речи лежит вблизи частоты 300 Гц, а наиболее «мощные» спектральные составляющие человеческого голоса сосредоточены в узкой полосе 200...600 Гц. Каждому звуку речи соответствует свое распределение энергии по частотному диапазону, называемое формантным рисунком. Формантные частоты, на которых происходит максимальное увеличение амплитуды спектральных составляющих, образуют формантные области частотного диапазона.
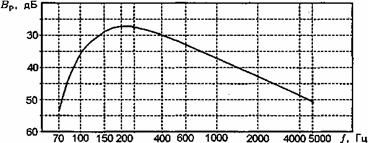
Рис. 3.4. Спектр русской речи
Спектральный состав звуков речи различен. Например, для гласных и звонких согласных (вокализованных звуков речи) энергетический спектр (формантный рисунок) имеет вид, представленный на рис. 3.5. Звонкие звуки имеют ярко выраженный дискретный спектр. Это объясняется природой образования гласных звуков, а дискретность определяется частотой основного тона: чем меньше частота ОТ, тем чаще будет заполнение спектра звука.
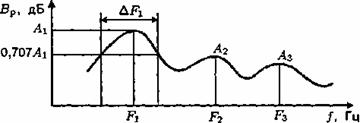
Рис. 3.5. Формантный рисунок вокализованных звуков: А1-А3 - амплитуды формант; F1-F3 - частоты формант; DF1 - ширина первой форманты
Форманта характеризуется амплитудой Аi, частотой Fi, и шириной полосы DFi. Различные звуки имеют разное число формант: гласные - до четырех формант, глухие согласные до 5-6 формант. Наиболее информативны первые три форманты: F1, F2 и F3. Наиболее вероятные частоты расположения: первой форманты F1 –150 – 900 Гц; второй форманты F2 – 550 – 2800 Гц; третьей форманты F3 – 1500 – 3400 Гц. Изменение положения формант происходит с частотой 10 – 20 Гц, а их интенсивности - с частотой 20 – 40 Гц. Первые две (основные) форманты определяют произносимый звук речи, а остальные (вспомогательные) характеризуют индивидуальную для каждого человека окраску, тембр речи. Если фильтром нижних частот отрезать вспомогательные форманты спектра речевого сигнала, то исчезнет индивидуальная для каждого человека окраска произносимых звуков, но само речевое сообщение будет понятно. Некоторые звуки отчетливо распознаются по одной первой форманте F1 ("а", "о", "у"). Это происходит потому, что низкие частоты обладают большой энергией.
Формантный рисунок глухих звуков выражен слабо. У них спектр не дискретный, а сплошной и характеризуется только огибающей спектра. Так, для звука "С" максимум спектральной плотности лежит вблизи частот 5000 – 8000 Гц. В полосе частот 1500 – 8000 Гц находится спектр согласных звуков и, в частности, фрикативных согласных ("в", "ф", "з", "с", "ж", "ш", "х", "щ"). Восприятие их особенно важно для разборчивости речи.
4. Характеристики слуха и разборчивость речи
При восприятии переданной речевой информации в качестве приемника выступает слуховой аппарат человека - речевое колебание воздействует на органы слуха человека, вызывая определенные слуховые ощущения. Первичный акустический преобразователь, используемый человеком при слуховом восприятии, - ухо разделяют на три области: наружное, среднее и внутреннее. Эти периферические отделы слуховой системы доводят звуковые колебания воздушной среды до чувствительных окончаний слуховых волокон нервной системы. Здесь акустический сигнал преобразуется в электрический и в результате сложного взаимодействия в сфере высшей нервной деятельности происходит восприятие речи, заключающееся в распознавании смысловых элементов речи. При этом слуховой аппарат человека позволяет решать следующие задачи слухового восприятия: распознавать речь (фонемы, слоги, слова); определять направление источника звука; адаптироваться к шумам и тишине (регулировка чувствительности); идентифицировать говорящего по речевым сигналам и т.д.
Восприятие по частоте. Ухо человека обладает свойствами частотного анализатора, дискретным восприятием по частотному и динамическому диапазонам. Границы воспринимаемого слухом частотного диапазона довольно широки - от приблизительно 20 до 20000 Гц. Избирательность (разрешающая способность) слухового анализатора невелика: полосы пропускания резонаторов слухового анализатора, определенные на уровне - 3 дБ от своего максимального значения, составляют на частотах 250, 1000 и 4000 Гц около 35, 50 и 200 Гц соответственно. Эти полосы пропускания - ряд выделяемых слуховым анализатором человека специфических поддиапазонов частотного спектра - носят название критических полосок слуха или частотных групп. Слуховым анализатором человека образуется 24 критических полоски слуха.
Субъективную оценку восприятия звука по частотному диапазону называют высотой звука. Так как ширина критической полоски слуха на средних и высоких частотах примерно пропорциональна частоте, то субъективный масштаб восприятия по частоте близок к логарифмическому закону.
Порог слышимости и уровень громкости. Человек ощущает звук в чрезвычайно широком диапазоне звуковых давлений (или интенсивностей). Чувствительность к чистым тонам (гармоническим колебаниям) является одной из основных характеристик слуха. Воспринимаемое ухом значение спектрального уровня чистого тона принято называть порогом слышимости, а наибольшее значение спектрального уровня чистого тона данной частоты, которое человек воспринимает без болевого ощущения, — болевым порогом (порогом осязания). Область, ограниченная кривыми порога слышимости β0 и болевого порога γ, называется областью слухового восприятия, или областью слышимых звуков (рис. 4.1). Порогом слышимости также называют наименьшее значение раздражающей силы чистого тона, которое вызывает ощущение звука. Это скачкообразный переход из слышимого состояния в неслышимое и обратно. Под раздражающей силой подразумевают интенсивность звука или звуковое давление. Порог слышимости зависит от частоты: при 1000 Гц ему соответствует интенсивность звука 10-12 Вт/м 2 или звуковое давление 2´10-5 Па.
Принцип квантования ощущений является одним из важнейших свойств слуха. Этот принцип в полной мере характеризует и восприятие по амплитуде. Так, изменение ощущения (например, уровня громкости) возникает лишь тогда, когда изменение соответствующего ему раздражителя (уровня звукового давления или интенсивности звука) превысит определенное пороговое значение. При этом порог различения интенсивности зависит от уровня громкости, а слуховые ощущения громкости почти пропорциональны логарифму интенсивности воздействия. Вблизи абсолютного порога слышимости порог различения интенсивности составляет 2...3 дБ, в области средних уровней громкости он существенно меньше: 0,4 дБ, а среднее его значение около 0,8...1 дБ. Другими словами: едва заметное на слух изменение уровня в процессе передачи не превышает ±1 дБ. Динамический диапазон по уровню звука от порога слышимости до болевого порога на частотах 1...3 кГц составляет приблизительно 130 дБ (для частоты 100 Гц это около 90 дБ).
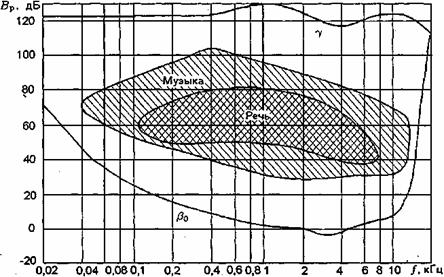
Рис. 4.1. Область слухового восприятия
Громкость звуков определяется как субъективное ощущение уровня речи (В). Для численной оценки громкости принято сравнивать уровень речи В с чистым тоном частотой 1000 Гц. Значение звукового давления эталонного сигнала, равногромкого данному звуку, называется уровнем громкости этого звука. За единицу уровня громкости принят фон. Таким образом, величина уровня громкости какого-либо звука численно равна уровню эталонного тона 1000 Гц, если на слух его громкость одинакова с громкостью определяемого звука.
Маскировка звуков. Порог слышимости существенно зависит от условий прослушивания: в тишине или же на фоне шума (или другого мешающего звука). В последнем случае порог слышимости повышается. Это говорит о том, что помеха маскирует полезный сигнал. Количественно повышение порога выражают уровнем маскировки, который определяют как разность: М = β – β0 , где β - порог слышимости при воздействии помех; β0 - порог слышимости в тишине. При существенной величине М полезный звук может оказаться неслышным, т.е. замаскированным помехой.
Явление маскировки проявляется во всех частотных группах слуха по-разному в зависимости от соотношения уровней и спектральных особенностей полезного сигнала и помехи. Эффект маскировки играет важную роль при слуховом восприятии смеси речевого и шумового колебаний. Современные модели механизма слуха основаны на свойстве слухового аппарата проводить кратковременный спектральный анализ, осуществляемый посегментно на отрезках времени около 20 мс. В каждой из частотных полосок присутствуют компоненты сигнала и шума, причем порог слышимости зависит от мощности сигнала. Поэтому в пределах каждой из критических полосок слуха, образованных слуховым анализатором, наибольшая по абсолютной величине спектральная составляющая маскирует рядом стоящие компоненты спектра, если ее уровень превышает некоторое пороговое значение.
Временные характеристики слуха. При исчезновении раздражающей силы слуховое ощущение исчезает не сразу, а постепенно уменьшается до нуля. Этот эффект называется слуховым впечатлением. Время, в течение которого ощущение по уровню громкости падает на 8,7 фон, считается постоянной времени слуха. Ее величина составляет в среднем при нарастании звука 20...30 мс, при спаде - 100...200 мс.
Разборчивость речи. При реализации цифровых преобразований речевых сигналов (РС) возникают специфические искажения, влияющие на качество речи. Одним из критериев качества речи является ее разборчивость. Разборчивость — есть объективная количественная мера, характеризующая способность тракта электросвязи передавать содержащуюся в речи смысловую информацию в данных конкретных акустических условиях окружающей среды. Эта мера является объективной в том смысле, что величина разборчивости зависит от физических параметров тракта, а также от среды, в которой ведется разговор, и не зависит от субъективных свойств конкретных, измеряющих разборчивость операторов.
Под мерой разборчивости понимается выраженное в процентах отношение числа правильно принятых элементов речи (звуков, слогов, слов, фраз) к достаточно большому общему числу переданных. На практике используют преимущественно слоговую (S), звуковую (D) и словесную (W) разборчивость. Они поддаются непосредственному измерению с помощью артикуляционных таблиц.
Существуют однозначные зависимости для указанных видов разборчивости. Это объясняется тем, что для нахождения их значений используются определенные выборки из одной и той же совокупности, представляющей собой речь, в которой звуки, слоги, слова и фразы встречаются в определенных фонетических и статистических соотношениях и взаимосвязях. Пример одной из этих зависимостей приведен на рис. 4.2.
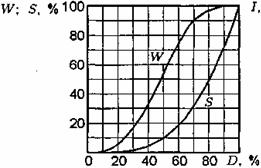
Рис. 4.2. Взаимосвязь между различными видами разборчивости
Принято считать, что разборчивость речевого сигнала и передача смысловой информации определяются огибающей амплитудного спектра сигнала. В процессе речеобразования широкополосный гармонический сигнал (при произнесении звонких звуков) или шумовой (при произнесении глухих согласных), проходя через набор акустических резонаторов, образуемых в ротовой и носовой полости, приобретает ряд максимумов огибающей спектра - формант, положение которых на оси частот определено для отдельных звуков - фонем.
Установлено, что у звонких (вокализованных) звуков положение первой форманты, расположенной ниже 1000 Гц, на 60% определяет характер фонемы; положение второй, лежащей в диапазоне от 1000 до 2800 Гц, - на 20%; и третьей (диапазон 1500-3400 Гц) - на 10%. Положение четвертой форманты, расположенной выше 3000 Гц, как считается, определяется размером головы. Последующие форманты при анализе сигнала не используются и в системах телефонной связи не передаются. Разборчивость же согласных, чей энергетический максимум в спектре сигнала расположен в диапазоне 1500-8000 Гц, сильно зависит от верхней граничной частоты полосы пропускания звукового (речевого) тракта.
Известна необычайно высокая устойчивость РС к помехам и искажениям канала передачи, как акустического, так и электрического. Очевидно, что в процессе эволюции природой был создан чрезвычайно устойчивый канал связи. Из опыта работы с речевым сигналом известно также, что он остается разборчивым при существенном ограничении полосы частот, нелинейных искажениях, искажениях АЧХ и даже инверсии спектра. В системах связи почти полное разрушение формантной структуры не приводит к потере связи. Тем не менее, даже для стационарных звуков — гласных, на основании формантной теории удается распознать 60-80% фонем. Распознаваемость согласных гораздо ниже. Современные системы распознавания успешно работают, в основном, за счет большой избыточности речевого сигнала (лингвистической, грамматической, смысловой), ограничения словаря, количества пользователей.
Рассмотренные выше характеристики речи и слуха играют важную роль при создании различных устройств и систем обработки и передачи речи, таких, как системы идентификации диктора по голосу, распознавания речи, низкоскоростного кодирования и передачи речи, систем компьютерной телефонии и др. Современные технологии реализации этих систем основаны на цифровых алгоритмах обработки сигналов.
5. Акустоэлектрические и электроакустические преобразователи
Акустоэлектрические и электроакустические преобразователи в абонентских устройствах СПРС выполняют роль интерфейса «пользователь-система связи», обеспечивая важные физические функции при реализации голосовой связи по радиоканалу. Так, важным звеном любого электроакустического тракта является микрофон - устройство для преобразования акустических колебаний воздушной среды в электрические сигналы.
Среди основных технических показателей микрофонов: чувствительность E – отношение напряжения на выходе микрофона к звуковому давлению, действующему на микрофон; динамический диапазон – разность между уровнем предельного звукового давления Nmax и уровнем собственных шумов Nш: D = Nmax – Nш, дБ (для непрофессиональных микрофонов Nmax = 114 дБ в диапазоне частот 250…8000 Гц); характеристика направленности, которая оценивается отношением чувствительности микрофона Еq, измеренной при приходе звука под углом q, к осевой чувствительности Ео: D(q) = Е(q) / Ео. Характеристику направленности, представленную в полярных координатах, называют диаграммой направленности (ДН). Классификация микрофонов по виду ДН включает: ненаправленные (круговые); двусторонне направленные (восьмерочные); односторонне направленные (кардиоидные).
Микрофон характеризуется также рядом других показателей, среди которых важнейшими являются: номинальный диапазон частот с допустимой неравномерностью частотной характеристики (от 4 до 20 дБ в зависимости от назначения микрофона), модуль полного электрического сопротивления на частоте 1 кГц (обычно от 50 до 2000 Ом), сопротивление номинальной нагрузки (150…3000 Ом), типовая частотная характеристика чувствительности.
Любой микрофон состоит из двух систем: акустико-механической и механоэлектрической. В зависимости от способа преобразования механических колебаний в электрические микрофоны делятся на электродинамические, конденсаторные, электромагнитные, пьезоэлектрические, угольные, транзисторные. По признаку приема звуковых колебаний микрофоны могут быть либо приемниками давления, либо приемниками градиента давления.
Свойства акустико-механической (т.е. подвижной) системы – диафрагмы зависят от того, как воздействует звуковое давление на диафрагму: если она открыта для звуковых волн только с одной стороны, то это приемник давления (рис. 5.1а), если же звуковые волны воздействуют на обе ее стороны, то это микрофон-приемник градиента давления (рис. 5.1б).
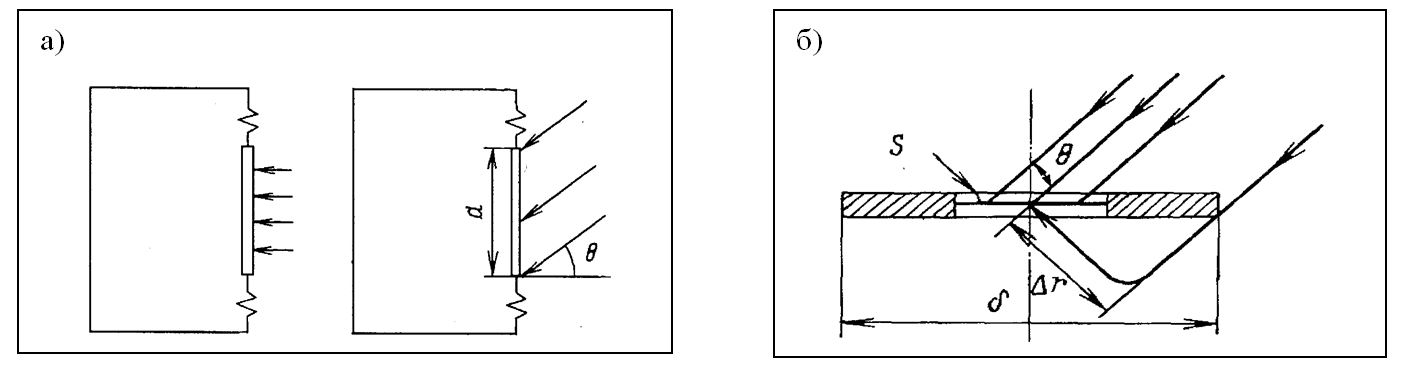
Рис. 5.1. Схематичное изображение микрофона-приемника давления (а) и микрофона-приемника градиента давления (б)
Для микрофона - приемника давления характерно увеличение чувствительности с ростом частоты. Характеристики такого микрофона также сильно зависят от размеров диафрагмы (относительно длины падающей звуковой волны) и его формы. Микрофон-приемник градиента давления можно представить в виде диафрагмы, размещенной в экране конечных размеров. Диафрагма открыта для звуковых волн с обеих сторон, поэтому на нее воздействует разность сил, обусловленная разностью хода звуковых лучей. Поэтому ДН такого микрофона имеет вид «восьмерки», т.е. микрофон не воспринимает звуковые колебания, падающие на него сбоку.
Большое влияние на характеристики микрофона оказывает его механоэлектрическая часть. В электродинамических и электромагнитных микрофонах выходное электрическое напряжение пропорционально скорости колебаний подвижной системы, а в микрофонах остальных типов – пропорционально колебательному смещению.
Для систем связи рекомендуются электромагнитные и угольные микрофоны. Они характеризуются полосой эффективно передаваемых частот от 300 до 5000…8000 Гц и достаточно высокой чувствительностью – от 10 мВ/Па (электромагнитные) до 400 мВ/Па (угольные).
Действие угольного микрофона (рис. 5.2а) основано на изменении сопротивления между зернами угольного порошка: при действии звукового давления на диафрагму (3) она начинает колебаться, в такт с этими колебаниями изменяется сила сжатия зерен угольного порошка (2), в результате чего изменяется сопротивление между электродами (1 и 4) и ток через микрофон. Основное преимущество такого микрофона – высокая чувствительность, позволяющая использовать его без усилителя. Недостатки – большой уровень шума, большая неравномерность частотной характеристики и значительные нелинейные искажения.
В электромагнитном микрофоне (рис. 5.2б) ферромагнитная диафрагма располагается перед полюсами магнита (2). При колебаниях диафрагмы (1) изменяется магнитное сопротивление воздушного зазора, а значит и магнитный поток через витки обмотки, намотанной на магнитопровод (3) этой системы. Благодаря этому возникает переменное напряжение звуковой частоты, являющееся выходным сигналом микрофона.
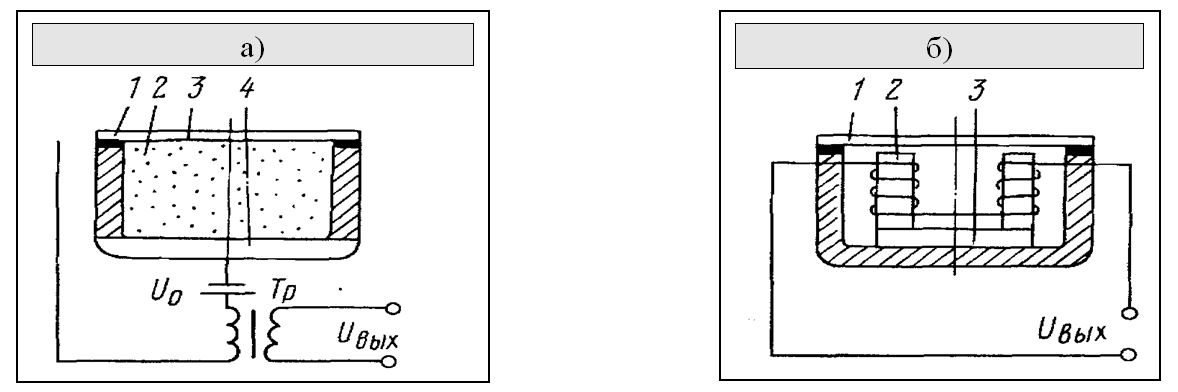
Рис. 5.2. Схематичное изображение угольного (а) и электромагнитного (б) микрофонов
Такие микрофоны стабильны в работе, однако им свойственны большая неравномерность частотной характеристики и значительные нелинейные искажения. С целью повышения разборчивости речи частотную характеристику этих микрофонов корректируют (поднимают) в области высоких частот с крутизной 6 дБ/октава.
В качестве электроакустических преобразователей, превращающих электрические колебания в звуковые, акустические колебания воздушной среды (т.е. акустические волны), используют громкоговорители и телефоны. В настоящее время наиболее распространены электродинамические громкоговорители непосредственного излучения (диффузорные). Однако в абонентских устройствах СПРС они находят ограниченное применение. В отличие от громкоговорителя задачей телефона является не излучение акустической энергии в окружающее воздушное пространство, а подведение ее непосредственно к уху. Это определяет конструкцию головного телефона, который состоит из электроакустического преобразователя, капсюля, корпуса, а также эластичной раковины, являющейся элементом, связывающим его с ухом (рис. 5.3). Здесь: 1 – раковина, 2 – капсуль, 3 – преобразователь, 4 – канал уха.
В телефонах, в основном, применяются электромагнитные преобразователи, а также электродинамические, электростатические, и угольные. На рис. 5.4 показаны варианты конструкций телефонов: 1 — электродинамического с сосредоточенной звуковой катушкой; 2 — электродинамического с распределенной звуковой катушкой; 3 — электростатического; 4 — электретного (близкого по конструкции к конденсаторному). Катушку в электродинамических преобразователях телефонов выполняют либо в традиционной форме, когда она намотана проводом на каркас, либо в варианте, в котором она состоит из концентрических плоских колец, напыленных или нанесенных другим методом на плоскую диафрагму.
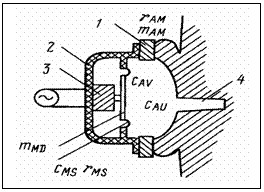
Рис. 5.3. Конструкция головного телефона
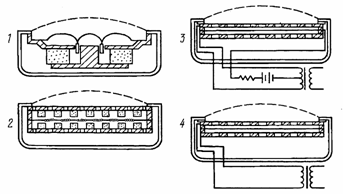
Рис. 5.4. Варианты конструкций телефонов
Важными характеристиками телефона являются его чувствительность и частотная характеристика чувствительности – фактически АЧХ по звуковому давлению, создаваемому телефоном в слуховом канале человека. Чувствительность измеряется в Па/В, т.е. в единицах звукового давления на 1 В подведенного напряжения сигнала. Типичные значения чувствительности (иногда называемой в справочниках – отдачей) – от 5…8 до 15…21 Па/В. Типичные полосы частот, эффективно воспроизводимые телефонами, составляют 300…3400 Гц, в то же время для контроля звукозаписи выпускаются телефоны с полосой 100…5000 Гц и даже 40…16000 Гц, а стереофонические телефоны характеризу-ются полосой 20…20000 Гц.
Технические характеристики громкоговорителя и телефона должны соответствовать характеристикам канала, передающего речевой сигнал. Этому требованию довольно трудно удовлетворить, поскольку громкоговоритель работает в относительно широкой полосе частот, в которой отношение граничных частот достигает 1000 (длина акустической волны изменяется примерно от 17 м до 17 мм), а у телефонов это отношение изменяется от 10 до 400.
6. Передача речевых сигналов по сетям связи
Рассмотрим общую модель цифровой системы связи, представленную на рис. 6.1. Структура системы определяет необходимые процедуры обработки речевого сигнала, а её характеристики - основные свойства СПРС и прежде всего – энергетические и спектральные.
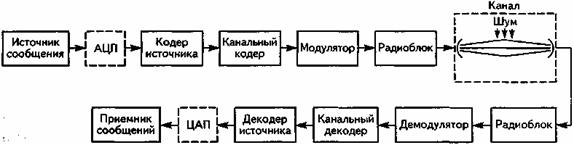
Рис. 6.1. Модель цифровой системы связи
Источник сообщения генерирует сообщения, представляющие собой либо непрерывные функции от времени, либо потоки дискретных сигналов. Пример непрерывного во времени сообщения - волновой сигнал, передающий человеческую речь. Чтобы передать такой аналоговый сигнал через цифровую систему связи, его необходимо преобразовать в цифровую форму. С этой целью сигнал последовательно подвергается аналого-цифровому преобразованию (АЦП) и кодированию с устранением избыточности в кодере источника. Хороший кодер источника «подгоняет» длину двоичных последовательностей под статистические свойства источника сообщений. В случае передачи речевого сигнала, кодер источника принято называть кодером речи. Важной характеристикой сигнала, преобразованного в цифровую форму, является цифровая скорость передачи (скорость цифрового представления), измеряемая числом формируемых на выходе АЦП двоичных символов в единицу времени - Rц, бит/с. В результате сжатия информации кодером речи скорость цифрового потока многократно уменьшается при сохранении приемлемого качества передачи речи.
На следующем этапе компактно представленный речевой сигнал подвергается ряду преобразований, основное из которых – помехоустойчивое (избыточное) кодирование. Дело в том, что некоторые физические явления, происходящие в каналах связи, приводят к возникновению ошибок при приеме сигналов. Эти ошибки можно представить как разность переданной и восстановленной из принятого сигнала двоичными последовательностями. Для того чтобы обнаружить и по возможности исправить ошибки, применяются канальный кодер в передатчике и канальный декодер в приемнике. К информационным блокам добавляется определенное число выбранных особым образом дополнительных битов. Значения этих битов рассчитываются путем сложения по модулю двух информационных битов, подбираемых таким образом, чтобы между ними существовала алгебраическая взаимосвязь, позволяющая обнаружить и скорректировать возможные ошибки.
Следующая процедура преобразования речевого сигнала на передающей стороне канала связи – модуляция, которой на приемной стороне соответствует демодуляция. Модем, реализующий эти процедуры, является своеобразным интерфейсом, согласующим дискретную часть системы с её непрерывной частью, которая представлена на рис. 6.1 радиоблоком и физическим каналом. Модулятор - это блок, формирующий синусоидальный сигнал, параметры которого (частота, амплитуда и/или фаза) являются функциями поданной на его вход цифровой последовательности. В результате модуляции несущий информацию сигнал переносится в соответствующую часть радиодиапазона и приобретает четко сформированные спектральные параметры. Это свойство сигнала — важнейшее для систем подвижной связи. Здесь необходимо эффективно использовать выделенные спектральные ресурсы, чтобы не искажать сигналы, передаваемые пользователями соседних областей спектра. Электромагнитный спектр - ценный и ограниченный ресурс, поэтому каждая система должна использовать максимально возможное количество своих собственных каналов в выделенном ей частотном диапазоне.
Радиоблок, иначе – высокочастотый (ВЧ) блок, работает в радиочастотном диапазоне и усиливает радиосигнал до требуемого уровня. Ширина полосы сигнала зависит от выбранного типа модуляции и используемого метода многостанционного доступа. Обычным требованием к применяемому в системе подвижной связи усилителю ВЧ является ограничение энергопотребления. Поэтому усилитель ВЧ должен обладать большим динамическим диапазоном и вынужден функционировать в нелинейной области своих характеристик. Компенсировать нелинейные искажения, вносимые усилителем ВЧ, позволяет применение методов модуляции с постоянной или слабо меняющейся огибающей.
В системах подвижной связи передатчик излучает сигнал в пространство с помощью антенны. Свойства канала тесно связаны с типами передающей и приемной антенн. Особенно важную роль играют параметры направленного действия и усиления антенны. Характеристики антенны определяют рабочий диапазон системы и ее эффективность.
Преобразования, производимые в приемнике, имеют обратное соответствие процессам, происходящим в передатчике. После усиления и фильтрации в каскадах ВЧ блока принятый сигнал демодулируется. Характер преобразования зависит от применяемого метода цифровой модуляции и параметров канала. Сильное влияние на выбор типа применяемого демодулятора оказывает фактор стоимостной реализации приемника. Основная задача демодулятора - выделить последовательность импульсов из модулированного сигнала, полученного после ВЧ обработки. На основе этих импульсов демодулятор выделяет из принятого сигнала переданные символы данных и преобразует их в двоичные последовательности.
Канальный декодер, используя добавленные канальным кодером избыточные биты, а также дополнительную информацию о достоверности принятого сигнала, определяет кодовую последовательность. Из полученной кодовой последовательности выделяется двоичная информационная составляющая. Именно она является основной целью декодирования.
Декодированный сигнал преобразуется в декодере источника (в СПРС – в декодере речи) и после цифро-аналогового преобразования (ЦАП) попадает через усилитель и громкоговоритель (телефон) в приемник сообщений - ухо пользователя.
Основные требования, предъявляемые к процессу передачи речи по сетям связи, — это высокое качество сигнала и низкая системная (временная) задержка. При этом качество речи по большей части напрямую связано со скоростью цифрового потока на выходе кодера речи, в то же время более сложные алгоритмы кодирования речи способны достичь более высоких отношений качества к скорости цифрового потока.
Сжатие речи при ее передаче сокращает объем передаваемых данных, затраты и, благодаря этому, позволяет снижать цены на услуги. Очевидно, чем изощренней алгоритм кодирования речевого сигнала, тем сложнее его реализовать. Сложность связана с вычислениями, необходимыми для воспроизведения процессов кодирования и декодирования сигналов в реальном времени в микросхемах АТ. Скорость обработки измеряется миллионами операций в секунду (MIPS). Достижения в технологии сигнальных процессоров (DSP), сверхбольших интегральных схем (VLSI) и увеличение емкости элементов памяти позволяют выполнять более сложные алгоритмы кодирования-декодирования речи даже в однокристальных микропроцессорах. Сложность обработки влияет на физические размеры кодека речи, на его стоимость, потребляемую мощность, а также отражается на величине коммутационной задержки – временной задержке сигнала при его обработке и буферизации в кодере и декодере. Задержка речевого сигнала в трактах передачи и приема не имеет большого значения в системах вещания, однако в телефонном канале значительное запаздывание сигнала заметно снижает качество восприятия речи. Реальные коммутационные задержки (при кодировании и декодировании) составляют от 125 мкс (в линиях с ИКМ) до 100 мс (в некоторых низкоскоростных системах кодирования). Предельно допустимой в телефонии считается общая задержка порядка 400 мс. Например, в стандарте GSM система синхронизации рассчитана на компенсацию абсолютного времени задержки сигналов до 233 мкс, что соответствует максимальному радиусу соты 35 км.
Исторически сложились два направления кодирования речи: кодирование формы сигнала (КФС), называемое также аппроксимацией формы речевой волны, и параметрическое компандирование речи, иногда называемое кодированиемисточника сигнала. В первом методе кодер формы волны аппроксимирует форму речевого сигнала во времени. Этот метод основан на использовании статистических характеристик речевого сигнала (РС) и практически не зависит от механизма его формирования. Кодеры этого типа обеспечивают высокое качество передачи речи, но скорость цифрового потока редко бывает меньше 32 кбит/с. Поэтому для кодирования речи со скоростью передачи 16 кбит/с и меньше – прежде всего для цифровых систем сотовой и персональной спутниковой связи - получили мощное развитие разнообразные методы параметрического компандирования речи (табл. 6.1).
Таблица 6.1.
|
Вид преобразования речи |
Устройства преобра- зования |
Алгоритмы кодирования -декодирования речи |
Скорость передачи, кбит/с |
|
Кодирование формы сигнала |
Кодеры формы сигнала |
Импульсно - кодовая модуляция (ИКМ) |
64 |
|
Дифференциальная ИКМ (ДИКМ) |
48/52/56 |
||
|
Адаптивная дельта-модуляция (АДМ) |
40 |
||
|
Адаптивная дифференциальная ИКМ (АДИКМ) |
32 |
||
|
Парамет- рическое компандирование (кодирование) речи |
Вокодеры |
Спектрально-временные (полосный, формантный, гармонический) |
1,2-4,8 |
|
Кодирование на основе линейного предсказания (LPC) |
|||
|
Гибридные кодеры |
Линейное предсказание с возбуждением от остатка предсказания (RELP) |
4,8-16 |
|
|
Линейное предсказание с многоимпульсным возбуждением (MPE-LPC) |
|||
|
Линейное предсказание с долговременным предсказанием (LTP-LPC) |
|||
|
Линейное предсказание с регулярным импульсным возбуждением (RPE-LPC) |
|||
|
Линейное предсказание с кодовым возбуждением (CELP) |
|||
|
Линейное предсказание с кодовым возбуждением и малой задержкой (LD-CELP) |
|||
|
Линейное предсказание с возбуждением алгебраическим кодом (ACELP) |
|||
|
Линейное предсказание с векторным возбуждением (VSELP) |
|||
|
Адаптивное кодирование с предсказанием (АРС) |
|||
|
Метод квантования по максимуму правдоподобия (MP-MLQ) |
Трудность создания кодеков, обеспечивающих минимально возможную скорость передачи для речевого источника, обусловлена рядом причин. Во-первых, речь представляет собой колебания сложной формы, зависящей от произносимых слов, тембра голоса, интонации, пола и возраста говорящего, а речевой сигнал не является стационарным процессом. Законы изменения его вероятностных характеристик на участках произнесения гласных и согласных звуков существенно различаются, не говоря уже о паузах и смычках (участки звучания согласных типа «м», «н», «п» и т. п.), где характеристики могут изменяться почти скачком.
Вторая причина связана с определением (формализацией) критерия верности передачи, свойственным получателю. Действительный критерий восприятия, который характеризует качество слухового приема речевого сигнала человеком, отличается от распространенного критерия среднеквадратической ошибки или от какого-либо другого критерия, контролирующего отклонение «формы реализаций». Поэтому воспользоваться непосредственно результатами теории передачи информации для расчета качественных характеристик источника речевого сигнала затруднительно. Однако, можно попытаться получить оценки минимально возможной скорости передачи из других соображений, используя физические свойства получателя и источника речевых акустических колебаний.
При параметрическом компандировании моделируется процесс речеобразования человека. Для этого в кодере из речевого сигнала вычисляются определенные параметры, которые передаются к декодеру, где они используются для восстановления формы сигнала. Восстановленная форма сигнала очень часто отличается от формы исходного сигнала; при этом звук подобен или близок к оригиналу. Использование полностью параметрических методов в настоящее время ограничено, так как они приводят к заметному ухудшению натуральности звучания голоса и чрезвычайно чувствительны к фоновому шуму. Один из способов снижения скорости передачи речи и повышения эффективности использования полосы пропускания канала связи состоит в применении гибридных методов, основанных на принципах линейного предсказания и объединяющих параметрическое компандирование и кодирование формы волны (табл. 6.1).
7. Основы цифрового представления речевых сигналов: импульсно-кодовая модуляция
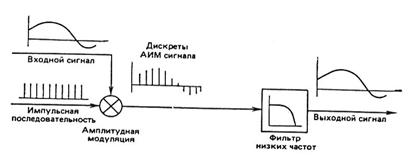
Рис. 7.1. Иллюстрация процедуры дискретизации аналогового сигнала
Под цифровым представлением речевых сигналов (РС) будем понимать их аналого-цифровое преобразование (АЦП). Первый шаг при АЦП РС состоит в его периодической дискретизации - замене непрерывной функции её дискретными значениями. Процесс базируется на теореме отсчетов (теорема В.А. Котельникова), в соответствии с которой произвольный сигнал со спектром, ограниченным некоторой частотой Fв, может быть полностью восстановлен (т.е. преобразован в аналоговую форму с помощью линейной интерполяции) по последовательности своих отсчетов, следующих с интервалом времени Тд = 1 / (2Fв). Здесь Fв - наивысшая частота спектра (ширина полосы) входного сигнала. Обычно за наивысшую частоту спектра (называемую частотой Найквиста) принимают частоту, ниже которой максимумы спектра имеют уровень не более – 40 дБ. На практике неискаженная передача непрерывного (аналогового) сигнала с полосой частот, ограниченной значением Fв, дискретной последовательностью его отсчетов возможна, если Fд = kFв, где k>2, а для восстановления используется идеальный фильтр (рис. 7.1). Метод, представленный на этом рисунке, называют обычно амплитудно-импульсной модуляцией (АИМ).
В соответствии с описанием гласных и фрикативных звуков РС не ограничен по полосе частот, хотя его спектр быстро спадает в области высоких частот. На рис. 7.2 изображены спектры типичных звуков речи. Видно, что для вокализованных звуков наивысшая частота, ниже которой максимумы спектра меньше уровня -40 дБ, составляет около 4 кГц. С другой стороны, для невокализованных звуков спектр не затухает даже на частотах выше 8 кГц. Таким образом, для точного воспроизведения всех звуков речи требуется частота дискретизации около 20 кГц. В большинстве приложений такая частота дискретизации, однако, не требуется. Например, если дискретизация предшествует оцениванию трех первых формантных частот вокализованной речи, то достаточно располагать частью спектра до частоты около 3,5 кГц. Следовательно, если перед дискретизацией РС пропускается через ФНЧ так, что Fв = 4 кГц, то частота дискретизации должна составлять 8 кГц.
Этот результат поясняет рис. 7.3, где представлен спектр входного сигнала и результирующий спектр импульсной последовательности АИМ сигнала, состоящий из дискретных гармоник частоты дискретизации. Входной сигнал модулирует каждую из этих гармоник отдельно. В результате этого создаются две боковые полосы около каждой дискретной частоты в спектре импульсной последовательности. ФНЧ, восстанавливающий исходный сигнал, рассчитывается на подавление всех частот, кроме частот исходного сигнала. Как показано на рис.7.3, такой фильтр должен иметь частоту среза, которая расположена между Fв и Fд – Fв. Следовательно, разделение возможно, если выполняется неравенство Fд > 2 Fв.
Входной сигнал перед дискретизацией должен быть ограничен по полосе, чтобы можно было удалить из него составляющие с частотой выше, чем Fд/2, даже если этими составляющими, как неслышимыми, можно было бы пренебречь. Таким образом, полная АИМ-система должна иметь фильтр, ограничивающий полосу сигнала перед дискретизацией, для гарантии того, что никакие ложные или связанные с источником сигналы не приведут к появлению помех в требуемой полосе вследствие наложения спектров после дискретизации. Поэтому этот фильтр часто называют фильтром защиты от перекрытия спектров.
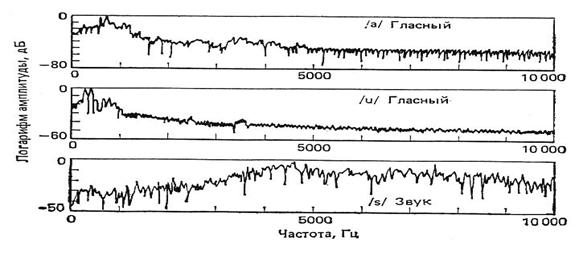
Рис. 7.2. Спектры типичных звуков речи
Второй шаг в процессе АЦП состоит в квантовании, когда непрерывному множеству мгновенных значений отсчетов аналогового сигнала ставят в соответствие конечное множество значений - уровней квантования. Набор разрешенных уровней квантования называется шкалой квантования. Расстояние между разрешенными уровнями - это шаг квантованияD. Разность d между исходным и квантованным сигналами называется ошибкой или шумом квантования. Мощность шумов квантования при наличии сигнала не зависит от сигнала и определяется шагом квантования: Рш.кв = D2 / 12.
Для передачи квантованные по амплитуде отсчеты преобразуются в двоичные кодовые комбинации - кодовые слова, которые передаются затем в виде потока двоичных импульсов - бит. Эта операция называется кодированием. Необходимое число разрядов для кодирования m при заданном максимальном числе уровней шкалы квантования nмакс определяется из выражения m = log2nмакс. В цифровых системах связи и вещания распространены двоичные симметричные коды, характеризуемые тем, что первый символ (т.е. старший значащий бит) кодовой комбинации определяется полярностью кодируемого отсчета сигнала, а остальные символы несут информацию об абсолютном значении отсчета.
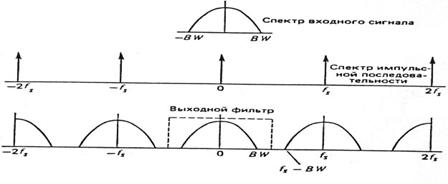
Рис. 7.3. Спектры входного сигнала и импульсной последовательности АИМ сигнала
При цифровой передаче сигналов речи по ТФ каналам общепринятой является Fд = 8 кГц, а число двоичных разрядов АЦП обычно выбирается равным m = 8, включая знаковый разряд. Поэтому диапазон чисел (исключая ноль) на выходе АЦП составляет от -127 до +127. В результате на выходе АЦП формируется последовательность 8-разрядных кодовых слов (т.е. 8-битовых чисел), следующих с частотой 8 кГц. Следовательно, цифровая скорость передачи сигнала на выходе АЦП составляет
Rц = Fд ´ m = 8 ´ 8 = 64 кбит/с. (7.1)
Эта величина представляет собой информационный объем цифрового представления РС (система ИКМ-64), который необходимо знать при его передаче или хранении.
На приемной стороне линии цифровой передачи в декодере битовый поток восстанавливается и формируются величины квантованных отсчетов. Затем для интерполяции между величинами отсчетов и восстановления исходной формы сигнала используется ФНЧ. Декодер и ФНЧ образуют цифро-аналоговый преобразователь (ЦАП). Если ошибок в передаче не было, то сигнал на выходе идентичен входному - за исключением шума квантования Рш.кв. Структурная схема системы ИКМ приведена на рис. 7.4.
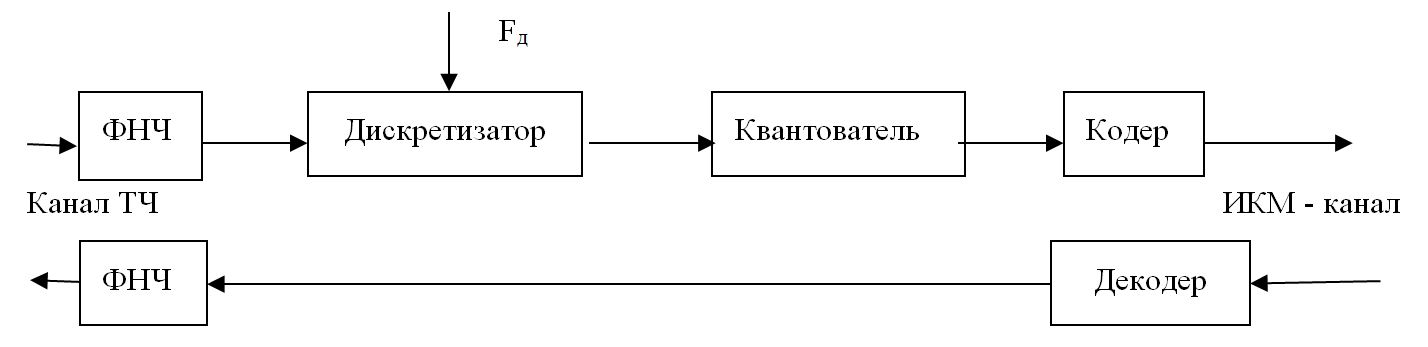
Рис. 7.4. Структурная схема системы ИКМ
Искажения (шум) квантования, возникающие при преобразовании аналогового сигнала в цифровую форму, обычно выражаются в виде отношения средних мощностей сигнала и шума, т.е. отношения сигнал-шум квантования (ОСШК) Рс/Рш.кв. ОСШК, выраженное в децибелах, при равномерном квантовании определяется соотношением:
Рс / Рш.кв = 6m + 4,8 – 20 lg Q, дБ, (7.2)
где Q – значение пик-фактора сигнала. Отсюда имеем:
- для гармонического сигнала (Q = Ö2) Рс / Рш.кв = 6m + 1,8, дБ;
- для речевого сигнала (Q = 12 дБ) Рс / Рш.кв = 6m – 7,2, дБ.
Система ИКМ с линейным квантованием практически не применяется, поскольку для достижения приемлемого качества восприятия восстановленного речевого сигнала при равномерном квантовании необходимо обеспечить m ≥ 12. Столь большое число уровней квантования nмакс = 212 при Fд = 8 кГц требует, чтобы скорость Rц передачи символов в канале была не менее 96 кбит/с. Для существенного уменьшения скорости Rц цифрового потока прибегают к нелинейному квантованию (рис. 7.5а) в процессе мгновенного компандирования(МК), когда на передающей стороне РС подвергают компрессии по логарифмическому закону, а на приемной осуществляют обратную операцию – экспандирование с помощью экспоненциального преобразования. При МК устраняется психофизическая избыточность, определяемая низкой заметностью искажений квантования на фоне сильного сигнала.
В электросвязи используется ИКМ с компандированием либо по m - закону, либо по А - закону; характеристика компрессии по m - закону приведена на рис. 7.5б для разных значений коэффициента сжатия. Обычно используют m = 30; 100; 255 или А = 87,6. Структурная схема системы ИКМ с МК дополняется элементами логарифмического компандера (рекомендация ITU-T G.711, 1960 г.). Так, можно либо компрессировать исходный сигнал по логарифмическому закону с последующим равномерным квантованием при сравнительно малом числе уровней (например, при m = 8), либо компрессировать предварительно преобразованный в цифровую форму сигнал при сравнительно большом исходном числе уровней квантования (например, при m = 12) с последующим преобразованием к восьмиразрядному коду (m = 8). Результатом преобразования является двоичная последовательность, передаваемая со скоростью Rц = 64 кбит/с.
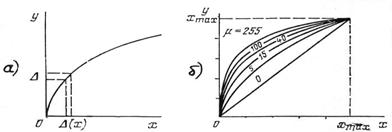
Рис. 7.5. Принцип нелинейного квантования (а) и характеристики компрессии по m - закону (б)
Из-за трудностей реализации неравномерного квантования с аналоговыми компрессорами переходят к цифровым, у которых плавная характеристика компрессии заменяется линейно-ломанной аппроксимирующей функцией с различным числом сегментов.
8. Дифференциальные методы кодовой модуляции
В обычной системе с ИКМ каждый отсчет входного сигнала кодируется независимо от всех остальных. В то же время анализ показывает, что речевой сигнал (РС) характеризуется сильной автокорреляцией - коэффициент корреляции (мера предсказуемости) между соседними отсчетами, следующими с частотой 8 кГц, составляет в общем случае 0,85 или больше. Это означает, что две соседних выборки не могут сильно отличаться друг от друга. Соответственно, если кодировать только разность между ними, то можно снизить скорость передачи двоичных данных, представляющих речевой сигнал. Более того, знание нескольких последовательных отсчетов и их корреляционных свойств позволяет предсказать последующий отсчет. Заметим, что на протяжении некоторого ограниченного промежутка времени РС можно считать квазистационарным. Таким образом, вместо кодирования следующих друг за другом отсчетов или даже их разности, можно кодировать разность между текущим и предсказанным значением, которое предсказатель (варианты: экстраполятор, предиктор) вычисляет на основе информации о нескольких предыдущих отсчетах.
Первым примером «сжимающей» обработки считают дифференциальную ИКМ (ДИКМ). В этой системе предыдущий отсчет берется с определенным весом, формируя прогноз, а разница между предсказанным и реальным отсчетами речи подвергается квантованию по знаку и по величине, после чего формируются двоичные символы (кодовые слова) цифрового сигнала. По существу, здесь кодируется крутизна (производная) сигнала на передающей стороне и восстанавливается сигнал путем интегрирования на приемной стороне.
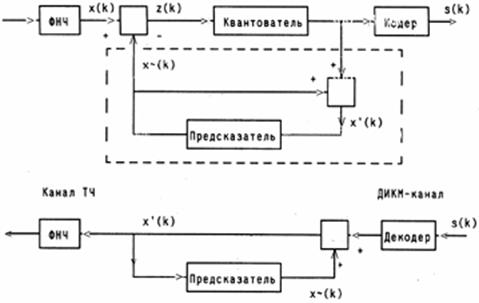
Рис. 8.1. Структурная схема системы ДИКМ
Простейшими средствами получения разности значений отсчетов являются запоминание предыдущего входного отсчета непосредственно в аналоговой памяти и использование аналогового вычитающего устройства для измерения изменения (рис. 8.1). Изменения сигнала затем квантуются и кодируются для передачи.
Таким образом, в дифференциальных кодеках квантованию и передаче по цифровому каналу подвергается разность между текущим отсчетом (выборкой) РС x(k) и его предсказанным значением x~(k), т.е. ошибка предсказания z(k) = x(k) – x~(k). Предсказываемое значение формируется из восстановленного сигнала x`(k) = x~(k) + zq(k); здесь zq(k) – квантованная ошибка предсказания. В качестве предсказываемого значения РС x~(k) в простейшем случае может быть использовано предыдущее отсчетное значение, хотя в общем случае используется выражение
Р
x~(k) = å api x`(k-i), (8.1)
i=1
где api и Р - коэффициенты и порядок предсказания, когда значение сигнала в k-ый тактовый момент определяется через его восстановленные значения в предыдущие (k–1),..., (k–p) моменты. Выходной сигнал предсказывающего устройства представляет собой взвешенную сумму последних Р отсчетов, каждый из которых в свою очередь является суммой выходных сигналов предсказателя и квантователя. Таким образом, предсказанное значение является выходным сигналом фильтра с передаточной функцией вида P(z) = å ak Z-k, на вход которого поступает восстановленный сигнал x`(k). Здесь символ Z-1 означает задержку на период дискретизации. Так что предсказатель может быть реализован в виде трансверсального фильтра на основе М-отводной линии задержки (регистра сдвига) с временем задержки между отводами, равным периоду временной дискретизации Тд.
Классификационными признаками кодеров ДИКМ считаются наличие блока линейного предсказания и использование многоуровневого (больше двух уровней) квантователя. Блок линейного предсказания может состоять из двух частей — долговременного и кратковременного предсказателей. Если предсказатель хороший, то дисперсия sz2 разности z(k) будет существенно меньше, чем дисперсия sx2 отсчета речевого сигнала x(k), в результате квантователь с заданным шагом (или количеством уровней квантования) даст меньшую погрешность при квантовании разности, чем при квантовании исходного сигнала. Следовательно, шум квантования при подаче на вход квантователя z(k) будет меньше, чем при непосредственном квантовании (в обычной ИКМ). При одинаковом уровне шума число уровней квантования z(k) будет меньше, а длина кодового слова (число разрядов m) и необходимая скорость передачи Rц (7.1) будут снижены.
На приемной стороне из принятого цифрового сигнала аналогичным образом формируется квантованный аппроксимирующий сигнал, который после низкочастотной фильтрации и усиления поступает на выход ТФ канала.
Концепцию ДИКМ можно расширить таким образом, чтобы включить в цепь предсказания значения более чем одного предшествующего отсчета. За счет этого дополнительная избыточность, извлекаемая из всех предшествующих отсчетов, может быть взвешена и суммирована для получения лучшей оценки значения следующего входного отсчета. В связи с улучшенной оценкой диапазон ошибок предсказания уменьшается, что дает возможность кодировать с меньшим числом разрядов. Для систем с постоянными коэффициентами предсказания большая часть реализуемого выигрыша достигается, когда используются значения только трех последних отсчетов.
При анализе систем с ДИКМ и предсказанием первого порядка обычно получается уменьшение длины кодовой комбинации, соответствующей отсчету, на один разряд по сравнению с ее длиной в системах с ИКМ при эквивалентных показателях систем. В системах с ДИКМ с предсказанием третьего порядка может быть реализовано уменьшение на 1,5 - 2 разряда на отсчет. Таким образом, обычная система с ДИКМ может обеспечить то же качество, что и система с ИКМ-64 при скорости передачи 56 кбит/с, а в системе с предсказанием третьего порядка можно получить сопоставимое качество при скорости передачи 48 кбит/с.
Величина отношения сигнал-шум квантования (ОСШК) в такой системе увеличивается (по сравнению с оценкой (7.2) в системе ИКМ) пропорционально уменьшению дисперсии погрешности предсказания. Выигрыш в ОСШК (или коэффициент, характеризующий эффективность предсказания): Gp = sx2 / sz2, где sz2 – дисперсия погрешности предсказания. Квантователь может быть адаптивный или неадаптивный, равномерный или неравномерный. ДИКМ обеспечивает выигрыш Gp @ 6 дБ (в случае неадаптивного равномерного квантования РС с частотой дискретизации 8 кГц) по сравнению с прямым квантованием (т.е. ИКМ).
Как и в системах с ИКМ, процесс АЦП в ДИКМ может осуществляться с компандированием, а также может использоваться техника адаптации для подстройки размеров шагов квантования в соответствии с уровнем средней мощности сигнала. Эти способы адаптации называют слоговым компандированиемв соответствии с интервалом времени между подстройками усиления.
Дельта-модуляция (ДМ) считается частным случаем ДИКМ-кодирования. В методе ДМ вычисляется разница между текущим и предыдущим отсчетами. Затем эта разница подвергается квантованию в одноразрядном (двухуровневом) квантователе. Этот единственный разряд просто показывает полярность отсчета разностного сигнала и посредством этого указывает на то, увеличился или уменьшился сигнал за время, прошедшее после последнего отсчета. За упрощение схемы кодирования приходится платить необходимостью увеличения частоты дискретизации по сравнению с минимально возможной частотой дискретизации, используемой в ИКМ-кодере. В простейшем ДМ-кодере частота дискретизации представляет собой компромисс между скоростью выходного потока данных и приемлемым уровнем ошибок квантования. Наиболее значительные ошибки дискретизации сигнала вызываются двумя явлениями - перегрузкой по крутизне и шумом дробления. Суть первого явления заключается в том, что при кодировании быстро изменяющегося сигнала возникают ошибки, обусловленные невозможностью изменения аппроксимирующего сигнала более чем на один шаг квантования.
В простейшем случае линейной ДМ-квантователь имеет только два уровня (+ D и – D) и фиксированный шаг квантования, а предсказатель представляет собой цифровое интегрирующее устройство, в котором сигнал x`(k) задерживается на время dt и умножается на коэффициент a, где 0 < a £ 1. На выходе интегратора образуется ступенчатое напряжение, крутизна которого не может превышать значение Fд D = D/dt, при котором кодированный сигнал отстоит от входного сигнала не более, чем на размер шага. Если дельта-модулятор не в состоянии отслеживать быстрые изменения во входном сигнале, то возникает "отставание" восстановленного сигнала от исходного (рис. 8.2), характеризуемое как искажение перегрузки по крутизне.
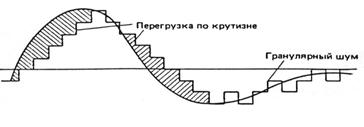
Рис. 8.2. Искажение перегрузки по крутизне при дельта-модуляции
Фактически, ДМ-кодер не успевает отслеживать быстрые изменения уровня сигнала и генерирует линейно изменяющийся квантованный сигнал. Шум дробления или гранулярный шум возникает при квантовании квазистационарного сигнала. При ДМ-кодировании постоянного сигнала результат представляет собой неравномерно чередующиеся положительные и отрицательные двоичные импульсы. Как показано на рис. 8.2, для медленно меняющихся сигналов основное значение имеет гранулярный шум, в то время как для быстро меняющихся сигналов - шум перегрузки по крутизне. Последний достигает пиковых значений непосредственно перед тем, как достигает максимумов кодируемый сигнал. Поэтому шум перегрузки по крутизне эффективно маскируется энергией речи, вследствие чего он менее заметен, чем шумы дробления.
Перегрузка по крутизне является не только ограничивающим фактором для системы с дельта-модуляцией, но и проблемой, присущей любой системе, когда кодируется разность значений соседних отсчетов. Система, оперирующая разностью, кодирует крутизну входного сигнала конечным числом разрядов и имеет, следовательно, конечный диапазон. Если крутизна превышает этот диапазон, происходит перегрузка по крутизне. В противоположность этому в обычной системе с ИКМ ограничена не скорость изменения входного сигнала, а максимальная кодируемая амплитуда. А дифференциальная система может кодировать сигналы с произвольно большими амплитудами, лишь бы эти большие амплитуды достигались постепенно.
Расчеты ОСШК при дельта-модуляции показывают, что последняя уступает ИКМ при больших скоростях передачи и превосходит ее при скоростях около 40 кбит/с. Так, для получения ОСШК, равного 35 дБ при частоте Найквиста (т.е. Fв) 3 кГц, требуется скорость передачи 200 кбит/с. Для улучшения эффективности ДМ применяют адаптацию - изменение шага D в соответствии с нестационарными свойствами сигнала и прежде всего - в зависимости от усредненного за короткое время значения крутизны входного сигнала.
Системы с ДИКМ обеспечивают такое качество восстановления сигнала, которое сопоставимо с качеством ИКМ-кодирования, и на порядок более высокую помехоустойчивость. Для снижения погрешности передачи при ДИКМ и повышения эффективности ДМ параметры квантователя и предсказателя должны быть согласованы со статистическими характеристиками сигнала, а поскольку последние изменяются во времени - алгоритмы должны быть адаптивными.
9. Адаптивные методы кодирования формы речевого сигнала
Неадаптивное построение систем с дифференциальной ИКМ, когда предсказатель и квантователь рассчитаны на средние статистические характеристики речи, недостаточно эффективно (см. материал разд.8). Это обусловлено тем, что для сообщений, содержащих долговременную избыточность, кратковременный предсказатель не обеспечивает существенного уменьшения динамического диапазона входного сигнала квантователя, что является причиной значительных искажений. Эффективность метода ДИКМ может быть повышена путем перехода к адаптивной дифференциальной импульсно-кодовой модуляции (АДИКМ). При этом производится автоматическое регулирование величины шага квантования сигнала ошибки предсказания, а также автоматическая подстройка коэффициентов ci трансверсального фильтра устройства предсказания (рис. 9.1) в соответствии с изменением текущего спектра сообщения. Для этого как в передающее, так и в приемное устройства вводятся дополнительные цепи автоматической регулировки усиления и подстройки параметров предсказателя на основе статистического оценивания параметров передаваемого сообщения.
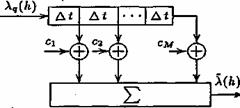
Рис. 9.1. Структурная схема трансверсального фильтра устройства предсказания
Амплитуда речевого сигнала (РС) может изменяться в широких пределах в зависимости от диктора, условий передачи, а также внутри фразы при переходе от вокализованного к невокализованному сегменту. Один из методов учета этих флуктуаций состоит в адаптации свойств квантователя к уровню входного сигнала. Учесть нестационарный характер РС, в частности медленное изменение его мощности (дисперсии), позволяет адаптивный квантователь.
Основная идея адаптивного квантования состоит в том, что шаг квантования изменяется таким образом, чтобы соответствовать изменяющейся дисперсии кодируемого сигнала. В результате размеры шкалы квантования подстраивают в соответствии с энергией речи так, чтобы слабые сигналы квантовались малыми ступенями квантования, а сильные сигналы - большими. Благодаря непрерывной подстройке шага квантования к текущей мощности речи, разрядность шкалы квантования при АДИКМ удалось снизить до четырех бит.
Адаптивная дифференциальная ИКМ была стандартизирована в 1984 г. (Рек. ITU-T G.721) для скорости передачи речи 32 кбит/с, и включает в себя два метода обработки сигнала: дифференциальное кодирование с предсказанием и адаптивное квантование (рис. 9.2).
Рис. 9.2. Схема кодирования речи по Рек. ITU-T G.721
Аналоговый сигнал дискретизируется и линейно обрабатывается в 12-битном (b = 12) квантователе. На следующем этапе вычисляется ошибка предсказания как разность между реальным и предсказанным значениями сигнала. Представленный 12-битным словом разностный сигнал обрабатывается в квантователе, имеющим логарифмическую (по основанию 2) характеристику и 16 порогов квантования (b = 4). В результате формируется 4-битовое представление ошибки отсчета, что при частоте дискретизации 8 кГц обеспечивает скорость цифрового потока на выходе кодера АДИКМ равной 32 кбит/с. 4-битовый разностный сигнал на основе статистического оценивания его параметров позволяет определить коэффициенты предсказания, используемые как в адаптивном квантователе, так и в схеме адаптивного предсказания. Кроме того, квантованная ошибка добавляется к сигналу, снимаемому с выхода адаптивного предсказателя, и направляется на его вход.
Оценка дисперсии может осуществляться в результате анализа либо входного, либо выходного сигнала квантователя. Соответственно имеем прямое и обратное управление квантованием, что отражается в обозначении метода: АДИКМ-П (АДИКМ с прямой адаптацией) и АДИКМ-О (АДИКМ с обратной адаптацией). В первом случае адаптивное квантование основано непосредственно на знании характеристик входного сигнала (прямая оценка), а во втором - информация для адаптации квантователя извлекается из передаваемого цифрового потока (задержанная оценка). Когда используется прямая оценка, коэффициент усиления квантователя кодируется в явной форме и передается совместно с коэффициентами предсказания и результатами кодирования разностных сигналов.
В дифференциальных кодеках формируется аппроксимирующее напряжение, сравниваемое с передаваемым сигналом. Процедура предсказания может быть фиксированной и адаптивной. Фиксированное предсказание (ФП) характеризуется постоянными параметрами предсказывающего фильтра с передаточной функцией
Р
P(z) = å bpiz-i. (9.1)
i=1
Здесь z-i- оператор задержки на i интервалов дискретизации, а bpi и Р - коэффициенты и порядок предсказания, которые выбираются исходя из свойств долговременной корреляционной функции РС. Наибольшее распространение при дифференциальном кодировании получило линейное предсказание, при котором предсказанное значение сигнала формируется как линейная комбинация предыдущих отсчетов на анализируемом сегменте РС длительностью 20...30 мс.
Адаптивное предсказание (АП), реализующее адаптацию коэффициентов предсказателя bpi(k) (9.1), основано на слежении за изменением кратковременной дисперсии РС. В этом случае оценивается кратковременная корреляционная функция речевого сигнала в предположении его локальной стационарности, т.е. предполагается, что свойства РС не меняются в течение короткого интервала времени. Другими словами, коэффициенты предсказания выбираются так, чтобы минимизировать средний квадрат погрешности предсказания на коротком интервале времени. Параметры адаптивного предсказателя определяются в результате анализа (измерений) либо исходного РС (АП-П), либо квантованного (выходного) сигнала (АП-О). Адаптивное квантование может быть основано на оценке огибающей или структуры кратковременной спектральной плотности мощности речевого сигнала. В первом случае существенна в основном частотная характеристика голосового тракта, а во втором - период основного тона речи.
Структурная схема кодека АДИКМ-АП-П первого типа приведена на рис. 9.3. Она содержит адаптивно управляемые АЦП (на стороне передачи) и ЦАП (на приемной стороне) и отличается от схемы на рис. 8.1 наличием блока адаптации, реализующего алгоритмы адаптации квантователя (Q) и предсказателя (P). Предсказывающий фильтр вместе с сумматором, на второй вход которого подается выходной сигнал адаптивного АЦП, образует оценивающий фильтр с передаточной функцией H(z) = 1 / [1 – P(z)]. В таких системах на приемную сторону передаются: 1 - результаты кодирования разностных сигналов; 2 - параметры квантователя (коэффициент усиления); 3 - коэффициенты предсказания. Для передачи параметров 2 и 3 предусматривается дополнительный низкоскоростной канал связи (2...3 бит/с).
Для преобразования ошибки (остатка) предсказания z(k) в цифровую форму обычно используют симметричные квантователи с постоянным числом уровней квантования и переменным шагом квантования Di, где i - дискретное время. Процесс адаптации заключается в изменении шага квантования в соответствии с алгоритмом адаптации. Известны различные алгоритмы адаптации квантователей. Один из них - "мгновенно адаптирующийся квантователь" или "квантователь с памятью на одно слово". В этом случае размер шага квантования вычисляется согласно алгоритму Di+1 = Di M(i), где M - множитель, зависящий от номера уровня квантования (т.е. от абсолютной величины отсчета), переданного в момент i.
Алгоритмы адаптации при АДИКМ построены так, что при обнаружении ошибок передачи в кодированном двоичном сигнале происходит восстановление работы, не приводящее к сбою. При отсутствии ошибок в канале системы АДИКМ-П и АДИКМ-О имеют приблизительно одинаковые характеристики. Адаптивное квантование может обеспечить выигрыш около 5 дБ по сравнению со стандартной неадаптивной ИКМ-МК. С учетом дополнительного выигрыша в величине ОСШК приблизительно 6 дБ за счет применения дифференциальной (разностной) схемы с неадаптивным квантованием, можно заключить, что системы АДИКМ-П и АДИКМ-О позволят получить ОСШК на 10...11 дБ больше, чем при использовании неадаптивного квантователя с тем же числом уровней.
Рис. 9.3. Структурная схема системы АДИКМ-АП-П первого типа
В кодеке АДИКМ-АП-О с обратной адаптацией коэффициенты адаптивного предсказания формируются в результате анализа цифрового сигнала. В этом случае оценивается кратковременная дисперсия сжатого сигнала - с выхода кодера на передающей стороне и с входа декодера на приемной стороне. Поэтому передавать параметры предсказателя и квантователя на приемную сторону нет необходимости. По тракту связи передается только квантованная ошибка предсказания. Поскольку коэффициенты предсказания изменяются от отсчета к отсчету, то задержка РС значительно меньше, чем в случае предсказания с прямым управлением.
Дельта-модуляцию с адаптивным квантователем называют адаптивной ДМ (АДМ). Она является частным случаем АДИКМ с фиксированным предсказателем первого порядка и адаптивным квантователем с двумя уровнями квантования и обратной адаптацией. Это означает, что информация для определения текущего значения шага квантования Di определяется непосредственно по выходной последовательности кодовых слов.
В системах АДМ важным моментом является выбор алгоритма адаптации квантователя (т.е. шага квантования). По скорости адаптации системы с АДМ подразделяются на системы с мгновенным компандированием (АДМ-МК) и системы со слоговым компандированием (АДМ-СК). В системах АДМ-МК часто применяется алгоритм адаптации Джаянта, когда шаг квантования подчиняется следующему правилу:
D(k) = M´D(k–1); Dmin£ D(k) £ Dmax.
В этом случае множитель М является функцией текущего s(k) и предшествующего s(k–1) кодовых слов. Алгоритм выбора множителя М шага квантования имеет вид
M = p > 1, s(k) = s(k–1); ü
M = 1/p < 1, s(k)¹ s(k–1). þ
Кодовое слово s(k) зависит только от знака z(k), который задается соотношением z(k) = x(k) – ax`(k–1),что соответствует использованию предсказателя первого порядка, описываемого разностным уравнением x~(k) = ax`(k–1). Здесь a - коэффициент предсказания.
Процедура AДИКМ применена также в международном стандарте кодирования речевых сигналов с частотой дискретизации 8 кГц для передачи по каналам со скоростью 16, 24, 32 и 40 кбит/с (Рек. ITU-T G.726). Этот метод кодирования сигнала применяется в некоторых распространенных системах подвижной связи, в частности, в бесшнуровой телефонии и системах абонентского доступа. Субъективно качество речи в результате АДИКМ-кодирования мало отличается от обычной обработки сигнала в системе ИКМ.
10. Основы параметрического кодирования речи
Как отмечалось ранее, при кодировании формы сигнала практически не учитываются свойства артикуляционного аппарата человека и особенности его слухового восприятия. В то же время именно здесь заключен значительный ресурс избыточности речевого сигнала (РС). На использовании этого ресурса избыточности основывается широко распространенное параметрическое представление речевого сигнала. Параметрическое представление РС основывается в первую очередь на данных о механизмах речеобразования, т.е. используется своего рода модель голосового тракта, что привело к разработке систем типа анализ-синтез, получившим название вокодерных систем или вокодеров (сокращение от voice coder). Описание первого вокодера было опубликовано Г. Дадли более 60 лет назад. Восстановленная речь была достаточно разборчивой, но звучала ненатурально. Значительного улучшения качества передаваемой речи удалось достичь только с появлением методов, основанных на линейном предсказании (LPC). Именно вокодерные методы на основе линейного предсказания и применяются в сотовой связи.
Линейное предсказание (ЛП) является одним из наиболее эффективных методов анализа речевого сигнала. Этот метод становится доминирующим при оценке основных параметров РС, таких, как период основного тона, форманты, спектр, а также при сокращенном представлении речи с целью ее низкоскоростной передачи и экономного хранения. Важность метода обусловлена высокой точностью получаемых оценок и простотой вычислений.
Основной принцип линейного предсказания состоит в том, что текущий отсчет РС можно аппроксимировать линейной комбинацией предшествующих отсчетов, а именно, очередная k-я выборка РС S(k) может быть приблизительно предсказана путем суммирования с определенным весом некоторого числа предшествующих выборок сигнала:
P
Ś(k) = å api S(k-i), (10.1)
i =1
где - Ś(k) - предсказанное значение РС; k – номер временного отсчета; api - коэффициенты линейного предсказания; Р - порядок предсказания (число коэффициентов линейного предсказания).
При анализе и синтезе речи используется модель речеобразования, представленная на рис. 10.1. Параметры модели обычно разделяются на параметры возбуждения (относящиеся к источнику звуков речи и отвечающие за основной тон, т.е. за возбуждение фильтра) и параметры голосового тракта (относящиеся непосредственно к отдельным звукам речи и определяющие формантную структуру сигнала). А отрезки глухой речи при моделировании заменяют шумом.
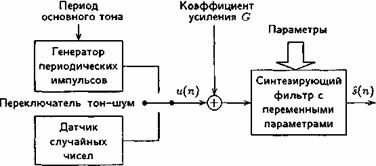
Рис. 10.1. Модель речеобразования, используемая в методе линейного предсказания
В соответствии с таким подходом, компрессия РС осущест-вляется на передающем конце канала в анализаторе, выделяющем из сигнала сравнительно медленно меняющиеся параметры выбранной модели. Затем эти параметры передаются по каналу связи. На приемном конце с помощью местных источников сигналов, управляемых принятыми параметрами (в соответствие с моделью), синтезируется речевой сигнал. При этом синтез речи осуществляется согласно разностному уравнению
P
Ŝ(k) = å api Ŝ(k-i) + Gu(n), (10.2)
i =1
где - Ŝ(k) - синтезированное значение речевого сигнала; и(п) - либо периодическая последовательность импульсов, следующих с периодом основного тона в случае синтеза вокализованных сегментов, либо случайная последовательность импульсов для синтеза невокализованных сегментов; Р - порядок синтезирующего фильтра; api - коэффициенты линейного предсказания, используемые в качестве параметров синтезирующего фильтра; G - коэффициент усиления, регулирующий интенсивность сигнала возбуждения для получения речевого сигнала заданной громкости. Коэффициенты линейного предсказания определяются однозначно минимизацией среднего квадрата разности между отсчетами РС и их предсказанными значениями на некотором конечном интервале. Коэффициенты линейного предсказания - это весовые коэффициенты, используемые в линейной комбинации.
Вокодеры на основе линейного предсказания обеспечивают высокую разборчивость передаваемой речи и иногда вполне удовлетворительную натуральность ее звучания. Одним из основных факторов, определяющих качество речи в этих вокодерах, является выделение основного тона речи и других параметров возбуждения в классической модели голосового аппарата. Для адекватного “отражения” этими параметрами модели постоянно изменяющегося РС, последний разбивается на сегменты по 20 ÷ 30 мс (длительность выбрана исходя из периода локальной стационарности РС), на каждом из которых и происходит описанная выше процедура. Характерной чертой вокодерных систем (по сравнению с кодеками формы сигнала) является то, что они производят все операции анализа, кодирования, декодирования сразу для целого сегмента отсчетов, а не для каждого отсчета в отдельности, как в ДИКМ и АДИКМ.
Таким образом, в процессе параметрического представления РС в кодере источника определяются коэффициенты предсказания, а в декодере на основе этих коэффициентов с помощью рекурсивного цифрового фильтра синтезируется эквивалент голосового тракта. Посредством возбуждения этого “эквивалента тракта” формируется синтезированная речь.
Разность между истинным (известным точно) S(k) и предсказанным Ś(k) значениями выборки определяет ошибку предсказания, которую также называют остатком предсказания или первым остаточным сигналом r1(k):
z(k) = r1(k) = S(k) - Ś(k). (10.3)
На базе линейного предсказателя в системе кодер/декодер строятся два цифровых фильтра: инверсный (обратный) фильтр-анализатор A(z) и формирующий фильтр-синтезатор H(z).
В результате z-преобразования разностного уравнения (10.3) имеем
R(z) = X(z) ´ A(z), (10.4)
где X(z) – z-преобразование выборки РС S(k) на входе фильтра-анализатора, а R(z) может интерпретироваться как выходной сигнал этого фильтра, имеющего передаточную функцию
p
A(z) = 1 - å api z-i = 1 - P(z). (10.5)
i=1
Здесь z-1 соответствует задержке РС на одну выборку; P(z) – коэффициент передачи предсказывающего устройства – предиктора.
Цифровой фильтр-анализатор A(z) – рис. 10.2 - называют инверсным, поскольку АЧХ такого фильтра должна быть обратной частотной характеристике голосового тракта (следовательно, обратной и огибающей спектра входного сигнала). Значения коэффициентов предсказания apiявляются параметрами этого фильтра. Они остаются постоянными на интервале анализируемого сегмента речи (как правило, 20 мс), поскольку линейный предсказатель перенастраивается (т.е. адаптируется) не под каждый речевой отсчет, а под их последовательность, вследствие чего ошибка минимизируется на протяжении всего сегмента.
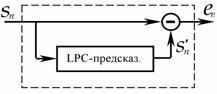
Рис. 10.2. Инверсный фильтр-анализатор A(z)
Инверсный фильтр применяется в кодере для устранения избыточности РС. Пропуская через него исходный РС, на выходе фильтра получаем сигнал остатка предсказания z(k) (иначе - первый остаточный сигнал -r1(k)). В этом “остатке” устранены внутренние корреляционные связи, он имеет спектр с плоской огибающей.
Коэффициенты предсказания api можно подобрать таким образом, чтобы ошибка z(k) была минимальной. Чаще всего в качестве критерия используется минимум среднеквадратической ошибки. В этом случае требуется определить такие значения api , чтобы величина
p
å z 2 (k)
k=1
была минимальной.
При подаче речевого сигнала на вход фильтра-анализатора с оптимально подобранными параметрами его выходной сигнал будет представлять собой сигнал возбуждения R(z), подобный (с точностью до ошибок, определяемых конечностью порядка предсказания Р и погрешностью оценки коэффициентов предсказания) сигналу возбуждения u(k) на входе фильтра голосового тракта на рис. 10.1. На выходе этого фильтра остается только периодическая составляющая РС, соответствующая основному тону. Это модель фильтра - анализатора РС, описываемая уравнением (10.5).
Синтезирующий фильтр выполняет противоположные функции. Он находится в декодере и осуществляет формирование речевого сигнала с заданной огибающей спектра. “Нужная“ настройка этого фильтра в декодере обеспечивается передачей на приемную сторону коэффициентов предсказателя, используемых в этот момент в кодере. Подаваемый на вход синтезирующего фильтра сигнал называется “сигналом возбуждения” R(z). Является очевидным, что он должен быть максимально “похож” на сигнал остатка предсказания, полученный в кодере. Из выражения (10.4) можно получить модель фильтра-синтезатора, который находится в декодере (рис. 10.3)
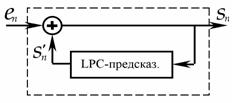
Рис. 10.3. Модель фильтра-синтезатора X(z)
X(z) = R(z) / A(z) = R(z) ´ H(z), (10.6)
где H(z) = G / A(z) - передаточная функция синтезирующего фильтра, обратная передаточной характеристике фильтра-анализатора с точностью до скалярного коэффициента усиления G. Фильтр H(z) - это линейная система с переменными параметрами (фактически - модель фильтра голосового тракта), которая возбуждается импульсной последовательностью для вокализованных звуков и шумом для невокализованных (см. рис.10.1). Фильтр-анализатор и фильтр-синтезатор являются рекурсивными, поскольку значение сигнала на их выходах определяется лишь предшествующими выходными выборками речевого сигнала.
Такая модель имеет следующие параметры: классификатор вокализованных и невокализованных звуков, период основного тона для вокализованных сегментов, коэффициент усиления G и коэффициенты api цифрового фильтра. Все эти параметры, разумеется, медленно изменяются во времени.
11. Вокодеры с линейным предсказанием (липредеры)
Кодирование речи на основе метода линейного предсказания заключается в том, что по линии связи передаются не параметры речевого сигнала (РС), как такового, а параметры некоторого фильтра, в известном смысле эквивалентного голосовому тракту, и параметры сигнала возбуждения этого фильтра. В качестве такого фильтра используется фильтр линейного предсказания (ФЛП), названный ранее фильтром-анализатором с передаточной функцией A(z). При кодировании (на передаче) производится оценка параметров ФЛП и параметров сигнала возбуждения, а при декодировании (на приеме) - сигнал возбуждения пропускается через фильтр-синтезатор, на выходе которого получается восстановленный сигнал речи. Различные варианты алгоритмов кодирования отличаются набором передаваемых параметров фильтра, методом формирования сигнала возбуждения и рядом других деталей, а процедура кодирования речи сводится к следующему (рис. 11.1):
- оцифрованный сигнал речи "нарезается" на сегменты длительностью 20 мс;
- для каждого сегмента оцениваются параметры ФЛП и параметры сигнала возбуждения; в качестве сигнала возбуждения в простейшем (по идее) случае может выступать остаток предсказания, получаемый при пропускании сегмента речи через фильтр A(z) с параметрами, полученными из оценки для данного сегмента;
- параметры фильтра и параметры сигнала возбуждения кодируются по определенному закону и передаются в канал связи.
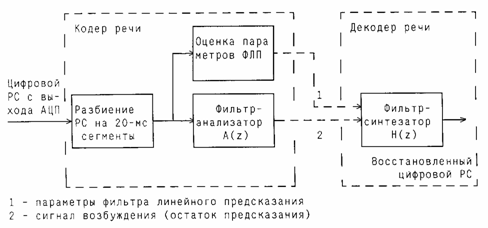
Рис. 11.1. Кодирование речи на основе метода линейного предсказания
Процедура декодирования речи заключается в пропускании принятого сигнала возбуждения через синтезирующий фильтр известной структуры, параметры которого переданы одновременно с сигналом возбуждения. Сигнал на вход анализирующего фильтра поступает непосредственно с выхода АЦП, а выходной сигнал синтезирующего фильтра попадает на вход ЦАП. Приведенное описание процессов кодирования и декодирования речи не является исчерпывающим, оно объясняет лишь принцип действия кодека. Практические схемы заметно сложнее, и это связано в основном со следующими двумя моментами.
Во-первых, речевой сигнал обладает двумя видами внутренних корреляционных связей, кратковременной и долговременной избыточностью, поэтому в подавляющем большинстве современных речевых кодеков используется два предсказателя: кратковременный (SHORT-TERM) и долговременный (LONG-TERM). Первый предсказатель (STP), учитывающий кратковременную избыточность РС, связан с корреляциями между близко расположенными отсчетами сигнала и определяет огибающую спектра. Его порядок обычно бывает 6÷10. Второй, долговременный, предсказатель (LTP) определяет тонкую структуру РС и связан с корреляцией двух отрезков сигнала между собой, реально - двух соседних периодов основного тона (ОТ). Период основного тона речи изменяется в широких пределах. На практике обеспечивается формирование частоты ОТ в пределах 57 ё 500 Гц , что соответствует изменению периода от 2 до 17,5 мс.
Сочетание двух предсказателей с разными характеристиками позволяет в значительной мере устранить остаточную избыточность и приблизить остаток предсказания по своим статистическим характеристикам к белому шуму. При этом на приемную сторону передаются остаток предсказания и коэффициенты обоих (STP и LTP) предсказаний.
Во-вторых, использование остатка предсказания в качестве сигнала возбуждения оказывается недостаточно эффективным, так как требует для кодирования слишком большого числа бит. Поэтому практическое применение находят более экономичные (по загрузке канала связи, но отнюдь не по вычислительным затратам) методы формирования сигнала возбуждения.
Рассмотрим структурную схему вокодера с линейным предсказанием более подробно (рис. 11.2). На подготовительном этапе выполняют аналого-цифровое преобразование РС и сегментацию цифрового потока: для последующей обработки выбирают отсчеты сигнала на интервале длительностью 20 мс, что при Fд = 8 кГц обеспечивает число обрабатываемых отсчетов равное 160. После сегментации отсчетов РС в кодере последовательно выполняются следующие три процедуры:
- кратковременный (формантный) анализ с использованием процедуры линейного предсказания, в результате чего получают первый остаточный сигнал r1(k);
- долговременный анализ с использованием линейного предсказания для определения параметров ОТ, в результате чего получают второй остаточный сигнал r2(k), близкий по своим характеристикам к шумовому, поскольку между отсчетами этого сигнала корреляция мала;
- аппроксимация второго остаточного сигнала с целью формирования сигнала возбуждения.
В первой процедуре оценку текущего отсчета Ś(k) определяют в соответствии с (10.1) как сумму P предшествующих отсчетов. При формантном анализе порядок предсказания P выбирают равным 8 – 12. Определение коэффициентов предсказания apiфильтра-анализатора (10.5) производят в блоке формантного анализа из условия минимизации среднеквадратичного значения ошибки предсказания (т.е. первого остаточного сигнала) на интервале сегмента.
Вычисленные значения коэффициентов предсказания используют в фильтре удаления формант кодера, на выходе которого получают сигнал, свободный от квазипериодических составляющих – формант; его называют первым остаточным сигналом. Информацию о формантах несут переданные на приемный конец параметры фильтра api, либо связанные с ними коэффициенты частичной корреляции (коэффициенты отражения). Иногда используют функции от коэффициентов отражения - так называемые логарифмические отношения площадей.
Во второй процедуре с учетом того, что основной тон характеризуется всего двумя параметрами, - амплитудой и периодом, передаточная функция фильтра удаления ОТ A2(z) описывается более простым, по сравнению с (10.4), выражением
![]() , (11.1)
, (11.1)
где G - единственный коэффициент предсказания, характеризующий амплитуду основного тона. Задержка a определяет период основного тона, ее значение обычно заключается в пределах от 20 до 160 интервалов дискретизации сигнала, что соответствует диапазону частот основного тона 50 - 400 Гц. Известно, что значение основного тона для разных голосов может изменяться почти в 10 раз - от 2 до 18 мс. Это обстоятельство создает немало трудностей при оценке ОТ, так как слух очень чувствителен к его искажениям. Методов измерения ОТ известно очень много и, вместе с тем, метод, не требующий чрезмерной задержки, пока не появился.
Несмотря на относительную простоту выражения (11.1), анализ и удаление ОТ является более сложной процедурой по сравнению с формантным анализом. Это обусловлено существенно большим периодом ОТ и сложностью выявления корреляции между отсчетами на большом временном интервале. Кроме того, период и амплитуда ОТ очень важны для точного восстановления речи. Именно поэтому на этапе долговременного анализа сегмент речи разделяют на 4 подсегмента. Каждый подсегмент имеет длительность 5 мс и содержит 40 отсчетов. Значения G и a определяют для каждого подсегмента по отдельности. Найденные параметры G и a используют в фильтре удаления основного тона. Их также передают на приемный конец в декодер, где используют при синтезе речевого сигнала.
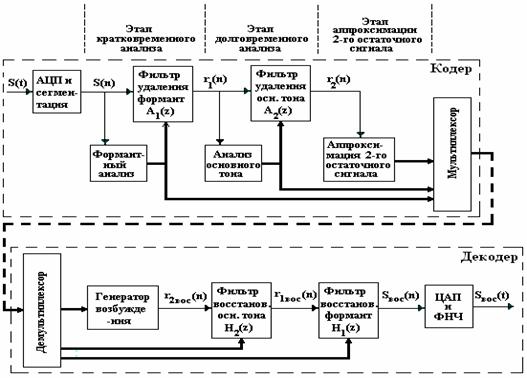
Рис. 11.2. Структурная схема липредора
Решаемая задача третьей процедуры - при минимальном объеме информации о сигнале возбуждения обеспечить приемлемое качество восстановленного сигнала. Для достижения этого обработку второго остаточного сигнала производят отдельно для каждого подсегмента из 40 отсчетов. Суть аппроксимации состоит в том, что второй остаточный сигнал моделируют в виде определенного числа импульсов на интервале подсегмента.
Переданные по каналу связи параметры аппроксимации второго остаточного сигнала, параметры основного тона G и a, коэффициенты формантного фильтра apiпоступают на соответствующие блоки декодера (рис. 11.2). В любом случае по каналу связи вместо самой речи передают так или иначе выделенные и квантованные параметры кратковременного и долговременного предсказания, интервал и усиление ОТ, параметры возбуждения. В декодере ЛП по принятым параметрам восстанавливают сигнал возбуждения, пропускают его через синтезирующий фильтр и восстанавливают речь.
Синтез сигнала начинают с восстановления второго остаточного сигнала, выполняемого генератором возбуждения. Восстановленный сигнал r2вос(k) несколько отличается от второго остаточного сигнала в кодере из-за погрешности аппроксимации.
Восстановленный второй остаточный сигнал пропускают через фильтр восстановления основного тона, передаточную характеристику которого H2(z) устанавливают обратной характеристике фильтра удаления основного тона кодера:
![]() .
.
На выходе этого фильтра получают восстановленный первый остаточный сигнал r1вос(k), который включает основной тон. Наконец, фильтр восстановления формант с передаточной функцией H(z) восстанавливает формантные составляющие сигнала.
Восстановленный сигнал Sвос(n) достаточно близок к исходному сигналу на входе кодера S(n). Выполнив цифро-аналоговое преобразование и пропустив сигнал через ФНЧ, получают восстановленный аналоговый сигнал.
Все процедуры обработки сигнала в кодере и декодере выполняются цифровыми методами. Кодер и декодер реализуют на высокопроизводительном сигнальном процессоре. Показанные на рис. 11.2 модули липредора фактически являются блоками программного обеспечения.
12. Кодирование речи в гибридных кодерах
Гибридные кодеры речевой информации основаны на комбинации линейного предсказания с элементами кодирования формы сигнала, т.е. звуковой волны. Так, в алгоритме линейного предсказания с возбуждением от остатка предсказания (RELP) (см. табл. 6.1) наряду с передачей вокодерных параметров (коэффициентов линейного предсказания и усиления) осуществляется передача сигнала остатка (ошибки) предсказания в полосе частот 0...800 Гц. Сигнал остатка предсказания приблизительно равен сигналу возбуждения голосового тракта модели речеобразования (см. рис. 10.1), поэтому в алгоритме RELP он используется в синтезаторе декодера для возбуждения синтезирующего фильтра. Формируемый в результате речевой сигнал звучит более естественно.
Большинство гибридных кодеров используют замкнутое кодирование на основе линейного предсказания, называемое также методом «анализ через синтез» (AbS). Этот метод характеризуется исчерпывающей самооптимизирующейся процедурой поиска. Ее выполняет аппаратура передачи, которая находит наилучшую аппроксимацию каждого речевого сегмента исходного речевого сигнала (РС). Как только такая аппроксимация определена, представляющий ее код передается на приемную сторону, где используется для синтеза РС.
Одной из первых реализаций метода анализа через синтез ( 1982 г.) является алгоритм линейного предсказания с многоимпульсным возбуждением (MPE), используемый в системах спутниковой связи. В многоимпульсном возбуждении сигнал остатка линейного предсказания представляется в виде последовательности импульсов с неравномерно распределенными интервалами и с разными амплитудами. Число импульсов в каждом кадре речевого сигнала зависит от требуемого качества речи, чем больше импульсов, тем выше качество речи. На каждом кадре в 10 мс речевого сигнала считается достаточным 6...8 импульсов (или 8 импульсов на период основного тона) для получения высокого качества синтезированной речи.
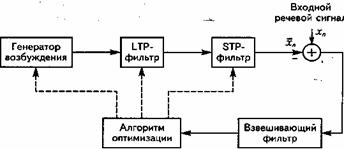
Рис. 12.1. Схема речевого кодера, использующего метод «анализ через синтез»
Согласно этому алгоритму (рис. 12.1), амплитуды и положения импульсов сигнала многоимпульсного возбуждения определяются на покадровой основе (кадр за кадром): на передающей стороне генератор возбуждения создает неравномерно распределенную последовательность импульсов и(п), которая в качестве сигнала возбуждения поступает на вход синтезирующего фильтра, на выходе которого возникают выборки речи Ŝ(n). Эти выборки сравниваются с соответствующими выборками S(n) исходного РС и находится ошибка предсказания z(n).
Кодер, реализованный на основе метода «анализ через синтез», - это речевой синтезатор, который генерирует сигнал, подобный объекту кодирования - речевому сигналу. Синтезатор состоит из генератора возбуждения и фильтров долговременного (LTP) и кратковременного (STP) предсказания. STP-фильтр моделирует краткосрочную корреляцию РС (восстанавливает огибающую спектра), порядок адаптации при этом составляет 20…30 мс, а порядок предсказания P обычно выбирается равным 8-12. LTP-фильтр формирует долгосрочную корреляцию РС (точную структуру спектра); период его адаптации – каждые 5…10 мс. Из-за рекурсивной природы обоих фильтров они содержат память-буфер, содержимое которого переносится из предыдущего анализируемого кадра.
В процессе кодирования каждого речевого сегмента (кадра) для него находятся такие “наилучшие” положения импульсов в последовательности и(п) и их амплитуды, которые обеспечивают минимальную ошибку. Алгоритм оптимизации, используя уравнение (10.2), минимизирует разность z(n) между исходным и синтезированным сигналами путем изменения возбуждающего сигнала и коэффициентов линейного предсказания api фильтров STP и LTP. Это достигается выполнением последовательных процедур – сначала определяются параметры нестационарного (т.е. синтезирующего) фильтра, затем по ним оптимизируется возбуждение.
Метод “анализа через синтез” дает весьма высокое качество синтезированной кодеком речи, поскольку учитывает процессы квантования коэффициентов вокодера, возникающие ошибки квантования, их влияние на синтезированную речь. К тому же, при вычислении величины ошибки между синтезированной и исходной речью используют не среднеквадратический критерий, а критерий, учитывающий особенности субъективного восприятия слушателем (в частности, эффект маскировки сигнала малого уровня сигналом большого уровня). Для этого перед вынесением решения о величине средней ошибки на речевом сегменте сигнал ошибки пропускают через взвешивающий фильтр, т.е. в алгоритме оптимизации используется не сама погрешность, а ее взвешенное значение zw(n). Этот фильтр перестраивается одновременно с синтезирующим фильтром и перераспределяет энергию ошибки по частотному диапазону (где-то усиливает, а где-то ослабляет). В результате большая часть шума квантования попадает в места расположения формантных областей (максимумов спектра) РС, а меньшая — между областями. В этом случае в формантных областях происходит маскировка шума речевым сигналом, в результате чего общая заметность шума в синтезированной речи уменьшится.
На сторону приема передаются параметры LTP- и STP-фильтров, а также параметры сигнала возбуждения. Представление сигнала возбуждения и(п) в виде последовательности импульсов с неравномерно распределенными интервалами и различными амплитудами позволяет более точно учесть особенности возбуждения голосового тракта человека.
Метод “анализа через синтез” применяется почти в каждом вокодере. Это обусловлено тем, что оптимальные значения для некоторых параметров, участвующих в синтезе речи, можно найти только методом перебора (внутри заданного заранее множества их значений).
Установлено, что для вокализованного РС многоимпульсное возбуждение можно упростить, представив его в виде последовательности равномерно расположенных импульсов (обычно 10 импульсов на интервале 5 мс). В методе возбуждения регулярной импульсной последовательностью (RPE) взаимное положение импульсов предопределено заранее - используют решетку равноотстоящих импульсов, а оптимизируют расположение решетки и амплитуды импульсов. В этом методе число импульсов определяется интервалом между ними. Экспериментально установлено, что интервал, равный четырем отсчетам (4*0,125 = 0,5 мс) РС, является оптимальным. Интервал больше, чем 5 отсчетов ухудшает звучание, особенно женских голосов. Местоположение первого импульса должно определяться каждые 5 мс минимизацией сигнала остатка.
Качество речи, синтезированной с использованием этого метода возбуждения, конечно, не имеет той полноты звучания, которое получается при многоимпульсном возбуждении. Однако алгоритм обработки при RPE значительно проще. Это и определяет широкое распространение данного метода аппроксимации второго остаточного сигнала.
В 1984 году, как естественное развитие многоимпульсного метода возбуждения, было предложено так называемое векторное кодирование (VQ), когда кодируется одновременно группа параметров, характеризующих позиции импульсов и их амплитуды. В этом случае в качестве сигнала возбуждения используется последовательность отсчетов (т.е. “вектор”), взятая из заданного набора этих последовательностей (т.е. из “кодовой книги векторов”). Входной вектор, представляющий собой образец входного РС, сравнивается с векторами, находящимися в кодовой книге, и находится вектор, наиболее близкий к входному. Критерием выбора вектора часто становится минимизация среднеквадратичной ошибки между образцом входного сигнала и вектором. Каждому “вектору” из этой “книги” соответствует свой адрес - индекс (номер), который и передается по каналу связи на приемную сторону. На рис. 12.2 изображен процесс кодирования. На приемной стороне в декодере используется точно такая же кодовая книга, из которой по индексу извлекается требуемый вектор. Таким образом, снижение скорости в результате использования VQ достигается путем передачи на прием только номера (индекса) вектора с масштабным коэффициентом.
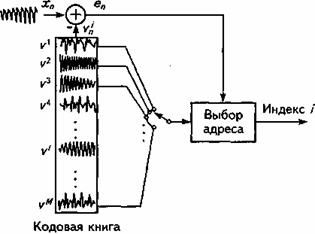
Рис. 12.2. Принцип векторного кодирования
Как правило, кодовая книга состоит из большого количества векторов, т.к. ее размер оказывает значительное влияние на качество речи. В виду очень больших вычислительных затрат прямой перебор векторов для отыскания среди них оптимального оказывается очень часто не возможен. Поэтому прибегают к различным ухищрениям в виде разбиения одной книги на несколько и последовательного поиска в каждой из них, а также структурирования содержания книги. Чтобы уменьшить время поиска подходящего вектора в кодовой книге, используют также так называемый древовидный поиск. В этом случае число вычислительных операций равно log2N, где N - число векторов. Однако при этом требуется большой объем памяти. Как правило, создаются две кодовые книги: одна для образцов сигнала возбуждения, другая - для образцов огибающей спектра.
Наиболее подходящий вектор возбуждения выбирается из заранее составленных кодовых книг, содержащих обычно 27 -210 квазислучайных векторов заданной длины с элементами, нормированными по амплитуде. Амплитуда вектора возбуждения кодируется отдельно в соответствии с громкостью передаваемого сегмента речи. Векторное кодирование лежит в основе метода стохастического кодирования, или метода линейного предсказания с кодовым возбуждением (CELP). Частными случаями CELP являются методы VSELP и ACELP.
Кодер CELP реализует процедуру анализа через синтез (рис.12.3). Сигнал возбуждения u(h) формируется путем сложения масштабированного сигнала из адаптивной кодовой книги (добавляются долговременные частотные составляющие речевого сигнала) и масштабированного сигнала из большой фиксированной кодовой книги. Полученный сигнал возбуждения управляет синтезирующим фильтром, который моделирует эффекты голосового тракта. В декодере сигнал возбуждения проходит через синтезирующий фильтр, формируя восстановленный речевой сигнал Ŝ(n).
Очевидно, что сначала определяются параметры фильтра, а затем уже находятся индексы кодовых книг а и k и соответствующие коэффициенты усиления G1 и G2. Параметры кодовых книг выбираются так, чтобы минимизировать взвешенную ошибку между исходным речевым сигналом S(n) и восстановленным Ŝ(n), что достигается подачей содержимого каждой «ячейки» кодовой книги на синтезирующий фильтр с целью выявления максимально похожего (по восприятию) образца.
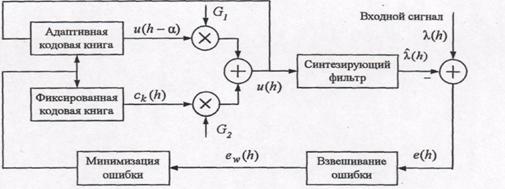
Рис. 12.3. Блок-схема кодера CELP
В алгоритме VSELP используется не одна большая стохастическая кодовая книга, а две, меньшего размера (128 векторов в каждой). Для эффективности кодирования эти две книги также образуются с помощью нескольких базовых векторов (базиса книги). Базовые вектора взаимно ортогональны друг другу, что обеспечивает и ортогональность самих книг кодовых книг между собой. Структура кодовой книги алгоритма ACELP (с речевой скоростью 7,4 кбит/c) следующая: существует 4 базовых вектора. Различной линейной комбинацией этих векторов и образуются все вектора кодовой книги. Такая жесткая структуризация книги позволяет резко снизить требуемые вычислительные затраты на поиск в ней оптимального вектора.
Кодовые книги бывают детерминированными и стохастическими. Детерминированные книги образуется посредством процесса “обучения”, т.е. заполнения книги векторами, полученными из реальных речевых сигналов. Обучение проводится на достаточно большой длительности (30..40 мин) для нескольких дикторов, на мужских и женских голосах. В отличие от детерминированных, стохастические книги не требуют обучения. Они заполняются случайными гауссовскими последовательностями (отрезками белого шума с нулевым средним и единичной дисперсией). Основанием для использования такой книги в качестве возбуждающей является то, что в системах с линейным предсказанием с двумя предсказателями (кратковременным и долговременным) в сигнале остатка на выходе этих предсказателей практически устранены все корреляционные связи, он имеет случайный характер.
13. Речевые кодеки для абонентского терминала стандарта GSM
Кодер речи является первым элементом собственно цифрового участка передающего тракта, следующим после АЦП (рис.2.1). Основная задача кодера - предельно возможное сжатие сигнала речи, представленного в цифровой форме, - при сохранении приемлемого качества передачи речи. Компромисс между степенью сжатия и сохранением качества отыскивается экспериментально, а проблема получения высокой степени сжатия без чрезмерного снижения качества составляет основную трудность при разработке кодера. В приемном тракте перед ЦАП размещен декодер речи, задача которого - восстановление обычного цифрового сигнала речи, с присущей ему естественной избыточностью, по принятому кодированному сигналу.
В предыдущих лекциях было показано, что кодирование речи на самом деле представляет собой процесс сжатия данных, при котором вместо преобразованных отсчетов входного сигнала для передачи подбираются кодированные параметры модели источника речи, позволяющие приемнику генерировать речевой сигнал (РС), чрезвычайно похожий на исходный. В системе GSM определены три стандарта кодирования речи:
- кодирование речи с полной скоростью (GSM FR);
- кодирование речи с половинной скоростью(GSM HR);
- улучшенноекодирование речи с полной скоростью (GSM EFR).
Современные мобильные телефоны имеют речевые кодеры и декодеры, позволяющие применять любой из перечисленных стандартов.
Кодирование речи с полной скоростью. Этот тип кодирования речи использует модифицированный метод RPE-LTP - линейное предсказание с возбуждением регулярной последовательностью импульсов и долговременным предсказателем (см. раздел 12). Упрощенная блок-схема кодера представлена на рис.13.1.
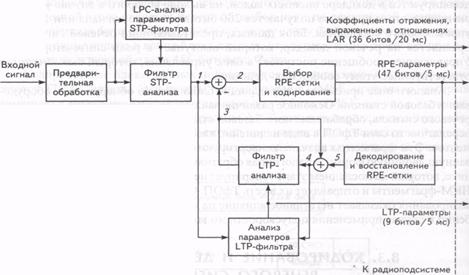
Рис. 13.1. Блок-схема полноскоростного кодера речи в системе GSM(FR)
Основные требования к кодеру состоят в сокращении избыточности речевого сигнала и обеспечении в перерывах во время пауз передачи речи. Поэтому при передаче речи в системе GSM используется техника прерывистой передачи DTX, означающая, что каждый речевой канал активен не непрерывно.
Блок предварительной обработки кодера осуществляет предыскажение входного сигнала при помощи цифрового фильтра восприятия, подчеркивающего верхние частоты, нарезание сигнала на сегменты по 160 выборок (20 миллисекунд) и взвешивание каждого из сегментов окном Хэмминга. Сигнал с выхода фильтра предыскажений подвергается анализу в соответствии с методом линейного предсказания, в результате чего определяются коэффициенты кратковременного линейного предсказания (STP). Полученные параметры, представляющие собой восемь коэффициентов отражения STP-фильтра, преобразуются в логарифмические отношения площадей (LAR), которые могут быть представлены более компактно, нежели сами коэффициенты отражения. Значения LAR в цифровой форме представляются 36 битами.
Затем найденные коэффициенты кратковременного линейного предсказания используются в фильтре-анализаторе STP для обработки того же самого сегмента входных отсчетов. В результате получаются 160 отсчетов остатка кратковременного предсказания сигнала.
Для дальнейшей обработки 20-мс сегмент остатка кратковременного предсказания z(n) делится на четыре подсегмента длительностью 5 мс, по 40 выборок в каждом. Каждый подсегмент последовательно обрабатывается в блоках кодера по отдельности.
Перед обработкой каждого подсегмента речевой кодер определяет параметры фильтра долгосрочного предсказания (LTP) – (весовой) коэффициент предсказания g и задержку d. Операция выполняется на основе текущего подсегмента остатка STP-предсказания (см. сигнал 1 на рис.13.1) и сохраненной последовательности из трех восстановленных предшествующих подсегментов остатка кратковременного предсказания (см. сигнал 4 на рис.13.1). Подсегмент остатка сигнала (2), прошедшего LTP-фильтр, представляет собой разность между подсегментом приближенных значений прошедшего STP-фильтр остатка сигнала (3) и подсегментом точных STP-фильтрованных значений остатка этого сигнала (1). В результате получается субсегмент остатка долговременного предсказания. После отбрасывания последнего отсчета этот подсегмент направляется в блок-анализатор с возбуждением последовательностью регулярных импульсов (RPE). RPE-анализатор разделяет обрабатываемый подсегмент на три последовательности возбуждения, каждая из которых состоит из 13 импульсов. Для этого производится децимация отсчетов и выбор сигнальной сетки (интервал следования импульсов возбуждения обычно втрое превышает период дискретизации исходного сигнала). Затем вычисляется энергия трех прореженных последовательностей. Последовательность с самой большой энергией выбирается как представляющая весь блок прошедших LTP-фильтр остатков. Выбранные импульсы возбуждения нормируются по отношению к наибольшей амплитуде и кодируется. Сдвиг сетки также кодируется и вместе со значениями импульсов возбуждения передается на приемник. В результате представление каждого 5-мс подсегмента производится 47-битовым блоком.
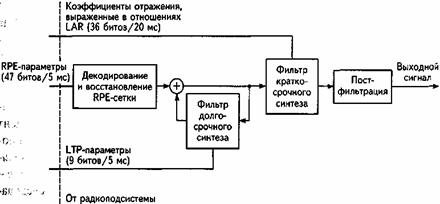
Рис. 13.2. Блок-схема RPE-LTP-декодера речи
Эти же RPE параметры подаются на блок декодирования и восстановления сетки RPE, который выдает подсегмент LTP-остатка (5). После прибавления отсчетов этого сегмента к приближенным значениям STP-остатка получаются реконструированные отсчеты STP-остатка, которые и направляются на вход фильтра долговременного анализа. В результате фильтрации получается новый подсегмент приближенных значений отсчетов остатка кратковременного предсказания, которые используются при обработке следующего подсегмента. В результате применения алгоритма кодирования 20-мс сегмент речи передается 260 битами информации, т.е. кодер речи осуществляет сжатие информации почти в 5 раз (1280 : 260 = 4,92), что обеспечивает цифровую скорость передачиRц = 64/5 @ 13 кбит/с. На рис.13.2 изображена упрощенная схема RPE-LTP-декодера. Он содержит такой же контур обратной связи, как и кодер.
В случае отсутствия ошибок передачи, выходной сигнал этой части декодера восстанавливает последовательность отсчетов остатка кратковременного предсказания. Затем эти отсчеты направляются на вход STP фильтра-синтезатора, после чего обрабатываются блоком постфильтрации для компенсации предыскажений, внесенных фильтром на входе кодера. Сигнал на выходе блока постфильтрации представляет собой восстановленные фрагменты речевого сигнала.
Кодирование речи с половинной скоростью. В GSM-кодере речи с половинной скоростью используется подход «анализ через синтез», рассмотренный в разделе 12, в версии VSELP. На рис. 13.3 изображена упрощенная блок-схема кодера с половинной скоростью.
Процедура «анализ через синтез» используется для поиска наилучшего кодового слова (вектора), характеризующего сигнал возбуждения для каждого 20-мс сегмента. Такое кодовое слово находится путем применения каждого кодового слова из словаря для возбуждения CELP-синтезатора. Затем синтезированный РС сравнивается с входным сигналом и вычисляется их разность. Разностный сигнал взвешивается спектральным взвешивающим фильтром с характеристикой W(z) и вторичным взвешивающим фильтром C(z). В результате получается сигнал ошибки е(п). Кодовое слово, обеспечивающее наименьшую среднюю мощность сигнала ошибки е(п), выбирается как наиболее точно соответствующее данному сегменту. Характеристики взвешивающего фильтра выбираются таким образом, чтобы обеспечить наилучшее субъективное восприятие синтезируемого РС человеческим ухом. Второй взвешивающий фильтр C(z) контролирует количество ошибок в гармониках речевого сигнала.
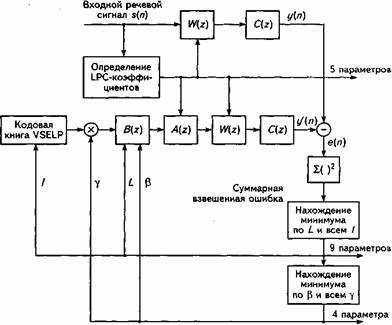
Рис. 13.3. Упрощенная блок-схема GSM-кодера речи с половинной скоростью
A(z) - кратковременный спектральный фильтр; B(z) - долговременный фильтр
с задержкой L
В процессе «анализа через синтез» кодер вычисляет 18 параметров, которые характеризуют каждый 20-мс сегмент. Параметры единичного сегмента представляются 112 битами, что эквивалентно скорости передачи данных 5,6 кбит/с на выходе полускоростного кодера.
Декодер с половинной скоростью представляет собой усечённый вариант кодера. На основе принятых параметров речь генерируется тем же синтезатором, что и в кодере.
При кодировании речи с половинной скоростью количество битов, представляющих 20-мс сегмент, значительно меньше, чем при кодировании с полной скоростью; следовательно, необходим более высокий уровень их защиты в канале передачи. Применение более эффективного канального кодирования приводит к увеличению числа битов в 20-мс сегменте до 228. Это равнозначно скорости потока данных 11,4 кбит/с на выходе канального кодера, что составляет ровно половину скорости на выходе канального кодера, работающего совместно с полноскоростным кодером речи.
Основное преимущество кодера речи с половинной скоростью заключается в удвоении емкости физического канала. Один и тот же временной слот может использоваться чередующимися полускоростными каналами трафика. Внедрение кодирования речи с половинной скоростью связано с попытками обойти проблемы с емкостью системы в густонаселенных районах. Это привело к необходимости внедрить в мобильные телефоны кодеры, которые могут работать с обоими стандартами. Основной недостаток кодирования речи с половинной скоростью - ухудшение качества передачи речи.
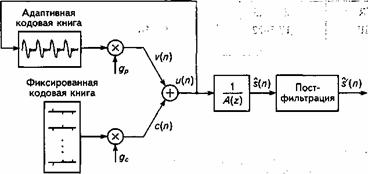
Рис. 13.4. Упрощенная блок-схема GSM-EFR - кодера
Улучшенное кодирование речи с полной скоростью. В основе такого кодера лежит модель линейного предсказания с кодовым возбуждением (CELP). В этой модели речевой сигнал синтезируется в линейном фильтре синтеза с кратковременным предсказанием (STP) 1/A(z) 10-го порядка (рис.13.4). Сигнал u(n) для его возбуждения формируется путем сложения двух векторов возбуждения из адаптивной и фиксированной кодовых книг. LTP-фильтр синтеза реализован с использованием адаптивной кодовой книги. Оптимальный вектор возбуждения ищется в кодовой книге с помощью процедуры «анализ через синтез» - аналогичной той, которая используется в кодировании речи с половинной скоростью.
Для каждого сегмента (20 мс, 160 отсчетов) определяются такие параметры модели CELP, как коэффициенты фильтра линейного предсказания, адреса в адаптивной и фиксированной кодовой книгах, а также весовые коэффициенты. Затем они кодируются и пересылаются на приемник. Декодер использует принятые параметры для восстановления речевого сигнала в CELP-синтезаторе, идентичном применяемому в передатчике при анализе речи.
EFR-кодер генерирует поток данных со скоростью 13 кбит/с. Тесты показали, что EFR-кодирование позволяет получить намного лучшее качество передачи речи, чем RPE-LTP-коди-рование. Такой тип кодеров в основном используется во вновь разворачиваемых сетях, в частности, в сетях PCS-1900 в Северной Америке.
14. Оценка качества передачи речи
Поскольку человек как получатель информации является ключевым элементом любой телекоммуникационной системы, качество сигнала оценивается по его субъективному восприятию речи. К основным показателям качества принимаемой речи относят: разборчивость (понятность), громкость и натуральность.
Понятность речи - определяющая характеристика тракта передачи речи, так как если тракт не обеспечивает полной понятности речи, то никакие другие его преимущества не имеют значения - он не пригоден к эксплуатации. Для непосредственного определения этой качественной характеристики есть только один метод – субъективно-статистические испытания (ССИ), требующий большого количества речевого материала, обработанного кодеками и трактом передачи, и привлечения группы экспертов (тренированных слушателей и дикторов). Разработан косвенный, объективный количественный метод определения понятности речи через ее разборчивость.
Громкость речи определяет желательный уровень принимаемых сигналов, при котором разборчивость (понятность) речи достигается без напряжения слухового аппарата со стороны принимающего. Натуральность речиоценивает способность системы воспроизводить не только смысл передаваемой речи, но и ее тембр и индивидуальные особенности голосов говорящих, т.е. способность обеспечить узнаваемость говорящего по голосу.
Наиболее распространенным объективным методом оценки качества передачи речи является метод артикуляции. Он основан на оценке степени выполнения главного требования, предъявляемого к разговорным трактам, - обеспечения разборчивой передачи речи. Мерой разборчивости является здесь разборчивость элементов речи. Процесс произнесения речевых элементов называется артикуляцией - отсюда и название метода.
Для измерений разборчивости разработаны специальные (артикуляционные) таблицы слогов, звукосочетаний и слов с учетом их встречаемости в русской речи (аналогичные таблицы есть и для других языков). Звуковых таблиц нет, так как звуки, кроме гласных, отдельно не произносятся, а для измерений звуковой разборчивости пользуются слоговыми таблицами или таблицами звукосочетаний. Пусть, например, в процессе измерения было передано 1200 слогов, из них правильно принято 840 и искажено 360. Тогда слоговая разборчивость составит S = 840´100/1200 = 70%. Из всех типов артикуляционных таблиц (слоговых, словесных, фразовых) практическое применение находят первые две. При этом слоговые артикуляционные таблицы считаются основными, так как на практике в большинстве случаев рассматривается именно слоговая разборчивость.
Измеряют разборчивость экспериментально (в соответствии с ГОСТ 16600-73) с помощью артикуляционной бригады - группы тренированных слушателей и дикторов - молодых людей без нарушений слуха и речи. Ограничение влияния субъективных факторов достигается путем строгой регламентации артикуляционных измерений. Регламентация касается вопросов комплектования и тренировки артикуляционных бригад, порядка проведения передачи, записи и проверки артикуляционных таблиц, обработки результатов измерения разборчивости.
В табл. 14.1 приведены градации понятности речи и соответствующие им величины разборчивости. Словесная разборчивость ниже 75% оценивается как "срыв связи".
Таблица 14.1
|
Понятность |
Разборчивость, % |
|
|
слоговая |
словесная |
|
|
Предельно допустимая |
25…40 |
75…87 |
|
Удовлетворительная |
40…50 |
87…93 |
|
Хорошая |
50…80 |
93…98 |
|
Отличная |
80 и выше |
98 и выше |
Эти данные были получены для широкого словаря, т.е. при передаче самой разнообразной информации. В тех же случаях, когда идет обмен информацией с гораздо меньшим объемом (т.е. при ограниченном словаре), понятность речи будет лучше, чем в общем случае при той же разборчивости речи. Так, для диспетчерской связи 40%-ная слоговая разборчивость уже соответствует полной понятности речи, хотя в общем случае она соответствует удовлетворительной понятности. Для передачи цифрами полная понятность достигается при 30% слоговой разборчивости.
По результатам проведения артикуляционных испытаний разборчивости различают классы качества речевых трактов по процентам правильно принятых элементов речи: слабое, удовлетворительное, хорошее и отличное (табл. 14.2).
Таблица 14.2
|
Вид разборчи- вости |
Качество речевых трактов, % |
|||
|
Слабое |
Удовлетворительное |
Хорошее |
Отличное |
|
|
Звуковая |
25. ..40 |
40.. .55 |
55. ..80 |
>80 |
|
Слоговая |
64.. .75 |
75. ..82 |
82. ..90 |
>90 |
|
Словесная |
75. ..87 |
87.. .93 |
93. ..98 |
>98 |
|
Фразовая |
90. ..95 |
87.. .93 |
97.. .99 |
>99 |
При оценке качества кодирования и сопоставлении различных кодеков оцениваются разборчивость речи и качество синтеза (качество звучания) речи. За рубежом для оценки разборчивости речи используется метод DRT (диагностический рифмованный тест). В этом методе подбираются пары близких по звучанию слов, отличающихся отдельными согласными в начале слова (типа "дот - тот", "кол - гол"), которые многократно произносятся рядом дикторов, и по результатам испытаний оценивается доля искажений. Метод позволяет получить как оценку разборчивости отдельных согласных, так и общую оценку разборчивости речи.
Для оценки качества звучания используется критерий DAM (диагностическая мера приемлемости). Испытания заключаются в чтении несколькими дикторами, мужчинами и женщинами, ряда специально подобранных фраз (12 фонетически сбалансированных 6-слоговых предложений), которые прослушиваются на выходе тракта связи рядом экспертов-слушателей, выставляющих свои оценки по 5-балльной шкале MOS (средняя субъективная оценка или средняя оценка мнений) в соответствии с данными табл. 14.3. Затем результаты усредняются. Хотя этот метод является субъективным по своей сути (аналог ССИ), его результаты по сопоставлению различных типов кодеков при проведении испытаний одними и теми же группами дикторов и экспертов-слушателей являются достаточно объективными, и на них основываются практически все выводы и решения.
Экспериментальные субъективно-статистические способы определения оценок качества чрезмерно громоздки и дают достоверные результаты лишь при большом объеме обработанного речевого материала. Поэтому весьма актуально создание объективного метода оценки качества с меньшими затратами труда и времени. Так, при исследовании речевых кодеков (а в последние годы эти исследования стали проводиться с помощью ЭВМ) желательно использовать объективные (формализованные) критерии качества, отличающиеся оперативностью и не требующие привлечения экспертов. Однако существующие объективные критерии качества слабо отражают свойства слухового восприятия. Поэтому критерий качества, используемый для оценивания кодеков одного типа, может оказаться некорректным для кодеков иного типа. Например, такой широко используемый критерий, как отношение сигнал-шум квантования (ОСШК), вполне удовлетворительно оценивающий качество неадаптивных, инвариантных к спектру передаваемого сигнала кодеков, становится некорректным при сравнении адаптивных дифференциальных речевых кодеков. Это связано с различием в характере искажений сигналов.
Таблица 14.3.
|
Субъективная оценка качества звучания речи |
Уровень восприятия речевой информации |
Оценка по шкале MOS |
|
Очень плохо |
Речь не воспринимается полностью или частично |
1 |
|
Плохо (слабо) |
Речь воспринимается затрудненно, с напряженным вниманием |
2 |
|
Удовлетворительно (Разборчиво) |
Речь воспринимается свободно, но наличие дефектов неоспоримо |
3 |
|
Хорошо |
Речь воспринимается свободно, определение дефектов затруднительно |
4 |
|
Отлично |
Речь воспринимается полностью и без искажений |
5 |
В табл.14.4 представлена сводная информация о наиболее распространенных способах кодирования речи. Здесь оценка различных методов кодирования связана с восприятием речи человеком, т.е. со средними субъективными оценками по шкале MOS.
Таблица 14.4.
|
Метод кодирования РС |
Стандарт / Год принятия |
Цифровая скорость, кбит/с |
Оценка качества по шкале MOS |
|
ИКМ (PCM) |
ITU-T G.711/1960 |
64 |
4,1…4,5 |
|
АДИКМ (ADPCM) |
ITU-T G.726/1984 |
32/64 |
3,8 / 4,6 |
|
IMBE |
INMARSAT-M/1990 |
6,4 |
3,1 |
|
LD-CELP |
ITU-T G.728/1992 |
16 |
3,8 |
|
RPE-LTP |
ETSI GSM/1992 |
13 |
3,6 |
|
VSELP |
EIA/TIA IS54/1992 |
8 |
3,45 |
|
CELP |
FS-1016 (США) |
4,8 |
3,15 |
|
MP-MLQ |
ITU-T G.723.1/1996 |
6,4 |
3,9 |
|
ACELP |
ETSI TETRA/1996 |
4,8 |
3,4 |
|
MELP |
США/1998 |
2,4 |
3,5 |
|
LPC-10 |
ANSI |
2,4 |
2,9 |
Так, при точном квантовании в ИКМ шум можно считать стационарным процессом с равномерной спектральной плотностью мощности (СПМ). В то же время при адаптивном квантовании, когда шаг квантования изменяется в соответствии с дисперсией нестационарного РС, дисперсия ошибки квантования оказывается с ней связанной, т.е. шум квантования становится также нестационарным. Обычно ОСШК не учитывает ни спектральных соотношений сигнала и шума, ни их нестационарного характера. При субъективном же восприятии важно соотношение не только дисперсий, но и СПМ РС и шума. Поэтому за основу объективного критерия, учитывающего свойства слухового восприятия, должны быть приняты оценки кратковременных СПМ РС и ошибки квантования. Корректность критерия качества передачи характеризуется корреляцией объективных оценок, вычисленных с его использованием, и субъективных оценок качества передачи.
Объективная оценка качества РС может производиться как во временной области, так и в частотной области. Во временной области критерием качества является ОСШК. В адаптивных речевых кодеках шаг квантования изменяется в соответствии с дисперсией РС, поэтому дисперсия ошибки квантования зависит от дисперсии РС. При исследованиях таких кодеков важны значения кратковременных ОСШК, вычисленных на коротких сегментах РС длительностью 10...30 мс. Такое сегментное ОСШКучитывает сегментный характер слухового восприятия элементов речи и является лучшей мерой искажений, при которой паузы в РС не учитываются. Однако чтобы их игнорировать, они должны быть обнаружены.
При кодировании с адаптивным предсказанием параметры предсказателя изменяются в соответствии с кратковременной СПМ РС, что делает необходимым учет сегментно-спектрального характера слухового восприятия в пределах временного сегмента РС. Так как область слышимых частот разделяется на критические полоски, то в каждой из них установлено оптимальное для слухового восприятия соотношение спектральных мощностей сигнала и ошибки квантования. С точки зрения простоты вычислений, длительности необходимого для анализа речевого материала (около 3 с, т.е. одна - две фразы), а также хорошей корреляцией с объективными оценками качества показатель качества на основе сегментного ОСШК может рассматриваться как весьма эффективный инструмент при исследованиях кодеков различных типов.
В частотной области критерием качества является степень искажения спектральной огибающей. Было установлено, что использование критерия качества в частотной области в большей степени соответствует субъективным оценкам, чем критериям во временной области. Так, при оценке качества звучания сигнала в вокодерных методах передачи, где форма реализаций речевых сигналов в дискретном времени на входе кодера xt и выходе декодера xt* может существенно различаться, основным показателем является близость оценок СПМ xt и x*t. Существует множество показателей, контролирующих эту близость. В частности, определение критерия качества в частотной области базируется на LPC кепстральном расстоянии (CD). (Термин "кепстр" был введен в США в начале 60-ых годов и является в настоящее время общепринятым для обозначения обратного преобразования Фурье логарифма спектра мощности сигнала). Спектральное искажение как мера качества речи определяется здесь через спектральное расстояние между спектром входного и выходного сигналов. В свою очередь, мерой спектрального расстояния служит кепстральное расстояние CD.
Этот метод используют для оценки качества РС в системе линейного предсказания. Он незначительно отличается от субъективного метода MOS (коэффициент корреляции между этими методами около 0,96) - чем больше кепстральное расстояние CD, тем ниже средняя оценка мнений MOS. Такая зависимость справедлива не только для систем LPC, но и ИКМ, АДИКМ и других систем.
15. Повышение помехоустойчивости цифрового канала передачи
При передаче цифровых данных по каналу с шумом и, тем более, с замираниями, обусловленными многолучевым распространением радиоволн, всегда существует вероятность того, что принятые данные будут содержать ошибки. Частота появления ошибок, при превышении которой принятые данные использовать нельзя, определяется свойствами слухового восприятия человека. А именно - должна быть установлена допустимая вероятность ошибок Рош, не приводящая к заметным на слух искажениям на аналоговом выходе. Поэтому средняя вероятность ошибочного приема элемента сигнала Рош является основной характеристикой помехоустойчивости цифрового канала связи. Снижение вероятности ошибок может быть достигнуто путем повышения требований к энергетическим характеристикам радиосистемы передачи – мощности радиопередатчиков, коэффициенту усиления антенн, шумовой температуре приемников. Однако далеко не всегда эти меры экономически оправданы и позволяют снизить вероятность ошибок до пренебрежимо малой величины.
Одним из важнейших средств в обеспечении достоверности передачи цифровых данных является использование канального кодирования с исправлением ошибок (FEC coding). Кодирование канала (иначе – избыточное или помехоустойчивое кодирование), основанное на применении специальных корректирующих кодов, реализуется путем добавления по определенному алгоритму в каждый кодовый блок некоторого количества поверочных символов. Эта избыточность позволяет корректирующему ошибки декодеру детектировать и исправлять неверно дошедшие данные и восстанавливать исходный поток данных по принятому потоку.
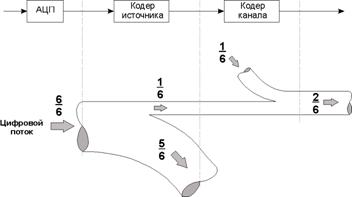
Рис. 15.1. Иллюстрация процессов кодирования источника и канала
Выбор типа корректирующего кода и его параметров зависит от требуемой достоверности приема, допустимой скорости передачи, вида ошибок в канале, сложности (стоимости) реализации схем декодирования. Учитывается также, что в результате эффективного устранения избыточности в процессе кодирования источника, предшествующего кодированию канала, информационная ценность каждого передаваемого в канал бита резко возрастает. Приблизительное соотношение естественной избыточности речевого сигнала и искусственной избыточности, вносимой в канал кодером канала, иллюстрирует рис. 15.1.
Обсудим простые модели канала, описывающие процессы, происходящие между кодером и декодером (см. также рис. 6.1). На рис. 15.2 представлено несколько базовых моделей каналов, применимых для анализа канального кодирования. Наиболее простая модель называется двоичным симметричным каналом (ДСК) без памяти (рис. 15.2,а). Входы и выходы этого канала - двоичные. Переданные и принятые блоки данных соблюдают побитовый порядок и на входе, и на выходе модели канала. Каждый бит кодируемой последовательности приходит на выход канала в неизменном виде с вероятностью 1 – Рош. С вероятностью Рош передаваемые биты инвертируются, т.е. возникают битовые ошибки. Декодер принимает решение о переданной закодированной последовательности с по принятой двоичной последовательности г. В процессе принятия решения декодером могут применяться только те отношения алгебраической независимости между отдельными битами переданной последовательности, которые были установлены правилом кодирования. Отсутствие у рассматриваемой модели памяти приводит к тому, что ошибки статистически становятся взаимно независимыми, т.е. возникновение ошибок в предшествующие моменты времени никак не влияет на вероятность появления ошибок в текущий момент.
Очень немногие реальные каналы передачи могут считаться действительно не имеющими памяти. В большинстве случаев ошибки возникают пакетами. С другой стороны, существует множество алгоритмов декодирования, разработанных специально для исправления случайных ошибок, т.е. ориентированных на каналы без памяти. С целью обеспечения достаточно высокой эффективности коррекции ошибок предпринимаются дополнительные меры для разбиения пакетов ошибок в приемнике, в частности, метод перемежения (interleaving) данных.
Вторая модель канала (рис. 15.2,б) учитывает пакетную природу ошибок, возникающих в канале передачи данных. Это значит, что появление одной ошибки в конкретный момент времени увеличивает вероятность появления ошибки в следующий момент. В этом случае говорят, что канал обладает памятью о своих предыдущих состояниях. Для таких ситуаций разработаны специальные коды и алгоритмы декодирования.
В третьей модели (рис. 15.2,в), которая аналогично первой не имеет памяти, декодер использует не только знания об алгебраических соотношениях между отдельными битами, но и дополнительную информацию, поступающую из канала и позволяющую оптимизировать процесс декодирования. Для получения такой информации отсчет сигнала, полученный в приемнике в процессе демодуляции, квантуется в М-уровневом квантователе.
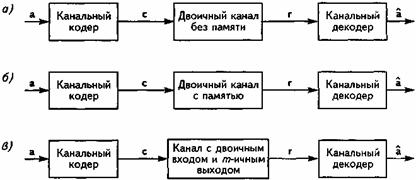
Рис. 15.2. Модели каналов с точки зрения канального кодирования
Если каждому возможному уровню квантования поставить в соответствие число от 0 до М – 1, то будет получена модель канала с двоичным входом и т-ичным выходом (рис. 15.3). В такой модели сигнал на выходе канала измеряется намного точнее, чем в модели двоичного канала. Это позволяет использовать дополнительную информацию, содержащуюся в принятом символе для повышения качества декодирования, т.е. снизить вероятность принятия неверного решения о принимаемой кодированной последовательности. Декодирование, при котором используется дополнительная информация канала, называется декодированием с мягким решением. В противовес ему, декодирование с использованием только информации двоичных символов называется декодированием с жестким решением. В большинстве применяемых в современной цифровой сотовой телефонии алгоритмов декодирования используются мягкие решения.
Рис. 15.3. Модель двоичного канала, обеспечивающего мягкие решения при M = 8.
В современных цифровых системах связи и вещания для обнаружения и исправления ошибок применяют либо блочные (блоковые) корректирующие (n,k)-коды, либо сверточные коды (СК). Определяющее различие между кодерами для кодов этих двух типов состоит в наличии или отсутствии памяти.
Кодер для блокового кода отображает последовательности из k входных символов в последовательности из n выходных символов, причем всегда п > k.. При этом каждый блок из n символов зависит только от соответствующего блока из k символов и не зависит от других блоков. Параметрами блокового кода являются n, k, R = k/n – скорость кода и d - кодовое расстояние. Кодовое расстояние является основным показателем корректирующей способности кода. Оно равно минимальному числу позиций, в которых кодовые комбинации отличаются друг от друга. Если в пределах блока кода при передаче появляется q ошибочных символов, то считают, что произошла ошибка кратности q. Кратность обнаруживаемых qо и исправляемых qи кодом ошибок связаны с кодовым расстоянием соотношением d = qо + qи + 1, причем всегда qо ³ qи. Конкретный тип кода задается тремя параметрами: n, k и d. При q > 3…5 эффективность блоковых кодов заметно снижается, то есть существенно возрастает требуемая при этом избыточность. Поэтому в современных СПРС используются более эффективные сверточные коды.
Сверточный код - это линейный рекуррентный код. В общем случае он образуется следующим образом. В каждый тактовый момент времени на вход кодирующего устройства (регистр сдвига с K ячейками) поступает m символов сообщения; n выходных символов формируются с помощью рекуррентного соотношения из K = m + q символов сообщения, среди которых m поступили в данный тактовый момент времени, а q - в предшествующие. Символы сообщения, из которых формируются выходные символы, хранятся в памяти кодера. Параметр K часто называют длиной кодового ограничения данного кода. СК характеризуются также скоростью R = m / n и свободным расстоянием dсв, аналогичным параметру d блоковых кодов. Типичные значения параметров СК: m,n = 1 - 8, R = 1/4 - 7/8, K = 3 -10.
Введение при кодировании канала в информационный сигнал избыточных символов сопровождается негативным эффектом — снижением, при неизменной скорости цифрового потока (Rц), скорости передачи полезной нагрузки (Сц) обратно пропорционально скорости кода (R): Rц = Сц / R, бит/с. Поэтому для сохранения скорости передачи полезной нагрузки необходимо расширение полосы частот канала в R раз или повышение кратности модуляции.
Положительным эффектом помехоустойчивого кодирования является либо снижение вероятности ошибки, либо снижение энергетики передачи при той же вероятности ошибки, либо и то, и другое одновременно. Таким образом, кодирование расширяет возможности компромисса между полосой и энергетикой канала, присущего любой системе связи.
Обычно качество системы связи характеризуется отношением энергии, приходящейся на один информационный символ, к односторонней спектральной мощности шума, т.е. отношением сигнал-шум (ОСШ) h0 = Еб / N0, которое требуется для достижения заданной вероятности ошибки Рош. Уменьшение ОСШ (при заданном уровне Рош), достигнутое благодаря кодированию канала, характеризует энергетический выигрыш кодирования (ЭВК). При использовании блочных кодов величина ЭВК (при Рош» 1´10-5), как правило, не превышает 2,5...3,5 дБ. Применение сверточных кодов декодируемых по алгоритму Витерби с мягкими решениями позволяет получить оценку для ЭВК 4…6 дБ.
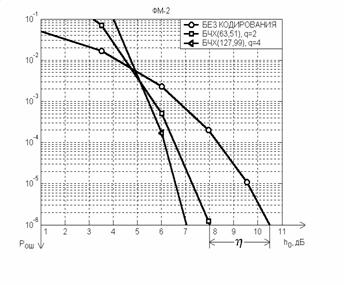
Рис. 15.4. Кривые помехоустойчивости ФМ канала с кодированием
При применении конкретного кода величина ЭВК легко находится по кривым помехоустойчивости, представляющим собой зависимости вероятности ошибки декодирования Рош от ОСШ на входе демодулятора. Реально достижимый ЭВК зависит, в первую очередь, от свойств корректирующего кода и алгоритма его декодирования. В качестве примера на рис. 15.4 кривые помехоустойчивости построены для двух вариантов кода БЧХ в канале с ФМ-2 при использовании жестких решений в корреляционном демодуляторе.
Определение ЭВК осуществляется относительно кривой помехоустойчивости для ФМ канала без кодирования (R=1) - при приемлемом пользователю допустимом долговременном уровне ошибок на бит информации после декодирования (Рош)доп, не приводящем к заметным на слух искажениям на аналоговом выходе. Из построений следует, что при (Рош)доп = 1´10-6 (63,51)-код, обнаруживающий и исправляющий двукратные (q=2) ошибки, обеспечивает ЭВК h » 2,5 дБ, а (127,99)-код при q = 4 - выигрыш h » 3,5 дБ.
Кодирование канала сопровождается двумя весьма простыми, но чрезвычайно эффективными процедурами – перемежением символов и скремблированием цифровых потоков. Использование перемежения как одного из основных методов повышения верности передачи дискретных сообщений в каналах с группирующимися ошибками является характерной особенностью сотовой связи. Это следствие неизбежных глубоких замираний сигнала в условиях многолучевого распространения, которое практически всегда имеет место, особенно в условиях плотной городской застройки. При этом группа следующих один за другим символов, попадающих на интервал замирания (провала) сигнала, с большой вероятностью оказывается ошибочной. Если же перед выдачей информационной последовательности в радиоканал она подвергается процедуре перемежения, а на приемном конце восстанавливается прежний порядок следования символов, то пакеты ошибок с большой вероятностью рассыпаются на одиночные ошибки. Таким образом, простое перемежение (перестановка во времени) символов позволяет декоррелировать ошибки в канале, то есть преобразовать пакеты ошибок большой кратности в одиночные, сведя, в первом приближении, канал с памятью к ДСК без памяти.
Скремблирование (рандомизация), предваряя кодирование канала, превращает цифровой сигнал в квазислучайный. Это, с одной стороны, позволяет создать в цифровом сигнале достаточно большое число перепадов уровня и обеспечить самосинхронизацию - возможность выделения из него тактовых импульсов, а с другой - приводит к более равномерному энергетическому спектру излучаемого радиосигнала. Благодаря этому повышается эффективность работы передатчика и минимизируется мешающее действие радиосигнала цифровой системы передачи по отношению к аналоговым сигналам, излучаемым другими передатчиками в том же частотном диапазоне. Собственно рандомизация осуществляется путем сложения по модулю 2 исходного транспортного потока данных с выхода мультиплексора кодера речи и двоичной псевдослучайной последовательности.
16. Цифровая модуляция в системах подвижной связи
Модуляция – это процесс изменения во времени значений одного или нескольких параметров несущего ВЧ колебания – амплитуды, частоты или фазы - в соответствии с изменениями передаваемого сигнала (сообщения). При простых видах модуляции модулирующее сообщение изменяет только один параметр – как правило, фазу. При комбинированных видах модуляции (или при плохой схемотехнической реализации простых схем) одновременно могут изменяться амплитуда и фаза несущей. Высокая помехоустойчивость, энергетическая эффективность и экономное расходование полосы частот современных СПРС достигаются в значительной степени благодаря рациональному выбору параметров модуляции.
Общая модель процессов, происходящих в модуляторе, характеризует все типы модуляций и описывается формулой
![]()
где Re{∙} - действительная часть комплексного аргумента, а функция x(t) = хI(t) + jxQ (t); при этом хI(t) и xQ(t) - сигналы, модулирующие косинусоидальную и синусоидальную составляющие несущей с частотой fc. При соответствующем выборе этих сигналов можно описать любую цифровую модуляцию. В широко распространенной квадратурной модуляции выходной сигнал образуется суммированием двух различных модулированных сигналов, несущие которых имеют между собой фазовый сдвиг 90°. Модулирующие сигналы называются соответственно синфазной (I) и квадратурной (Q) составляющими.
В СПРС предъявляются весьма жесткие требования к типу используемой модуляции. Прежде всего речь идет о спектральной эффективности сигналов, которая зависит, в конечном счете, от компактности их спектра - относительной величины мощности, сосредоточенной в главном лепестке спектра, то есть в полосе частот по первым "нулям" спектра, равной 2/tс, где tс – длительность сигнала (время, затрачиваемое на передачу одного бита информации). В главном лепестке спектра сигнала после модуляции должно находиться не менее 94…97% всей энергии сигнала. Часто предъявляют высокие требования к скорости убывания составляющих спектра при больших расстройках за пределами главного лепестка спектра. Увеличение скорости спадания внеполосного излучения (ВПИ) обеспечивает непрерывность фазы сигнала в моменты перехода от символа к символу, поскольку скорость спадания ВПИ зависит от числа непрерывных производных текущей фазы сигнала.
Другое требование связано с необходимостью обеспечения постоянной огибающей сигнала и относится к возможности использования в подвижной станции нелинейного усилителя радиодиапазона, что особенно важно для энергетического бюджета подвижной станции.
Обратимся к схеме линейного модулятора для двукратной модуляции (рис. 16.1). Двоичный поток данных (приходящий, как правило, с выхода перемежителя) направляется на вход преобразователя, который преобразует блоки двоичной информации в пары (дибиты) информационных символов - dI и dQ. Эти информационные символы направляются на фильтры модулирующего сигнала с импульсной характеристикой р(t) и q(t). Сигналы, модулирующие синфазную и квадратурную составляющие, описываются формулами
![]()
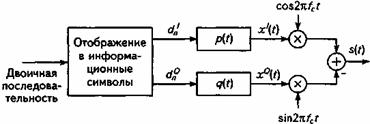
Рис. 16.1. Линейный модулятор для двукратной модуляции
При помощи этих формул можно описать различные типы линейных модуляций. Так, выбор значений q(t) = 0, dI = ±1 и p(t) = rect (t/T) соответствует двухпозиционной ФМ-2, часто называемой двоичной фазовой манипуляцией (BPSK). При выборе значений — dI = dQ = ±1, a p(t) = q(t) = rесt(t/T) получим четырехпозиционную ФМ-4, называемую квадратурной фазовой манипуляцией (QPSK). Обычно число возможных состояний (позиций, уровней) модулируемого параметра обозначают через М. Число сигналов обычно кратно 2, т.е. М = 2 В и В = log2 M ; здесь В - кратность модуляции (В = 2,…8).
Такие виды модуляции, как квадратурная амплитудная модуляция (QAM), у которых В ≥ 2, получаются путем выбора многоуровневых информационных символов dI и dQ. При М = 4 КАМ (4-QAM) совпадает с ФМ-4, однако при М > 8 эффективность квадратурной амплитудной модуляции выше. Стоит упомянуть, что КАМ до сих пор напрямую не применялась в системах подвижной связи, прежде всего, из-за непостоянства огибающей.
Благодаря использованию комплексного сигнала x(t) каждая модуляция представляется в виде набора характеристических точек на комплексной плоскости (так называемого созвездия), траектория которых характеризует движение во времени по комплексной плоскости сигнальной точки с координатами хI(t), xQ(t). Форма сигнального созвездия соответствует виду модуляции. Для адекватного отображения пространства сигналов на выходе квадратурного модулятора обычно используют прямоугольную систему координат, в которой по горизонтальной оси /, которая символизирует нулевой фазовый сдвиг, откладывают уровень сигнала в синфазном канале, а по вертикальной оси Q, символизирующей сдвиг на 90°, уровень сигнала в квадратурном канале. Сигналы отображаются точками, которые являются концами двумерных векторов на квадратурной (иначе - векторной) диаграмме.
На рис. 16.2 изображены созвездия нескольких наиболее важных цифровых модуляций. В случае М-позиционной ФМ М сигнальных точек располагаются на окружности с радиусом R =Ö E (Е - энергия посылки сигнала), на равных расстояниях dM между точками созвездия с угловым интервалом 2п/М радиан. Расстояния dM характеризуют помехоустойчивость при приеме сигнала. Так, максимально возможное значение d2 =2Ö E соответствует максимальной (потенциальной) помехоустойчивости (т.е. наименьшей вероятности ошибочного приема), которой характеризуются т.н. противоположные (манипулированные по фазе на 180о) сигналы ФМ-2 (рис. 16.2а). У двукратной ФМ-4 (рис. 16.2б) минимальное расстояние d4 = Ö2E, что соответствует расстоянию между ортогональными сигналами. Эти сигналы являются наилучшими по помехоустойчивости из всех двумерных четырехпозиционных сигналов.
Рис. 16.2. Примеры сигнальных созвездий: а - BPSK, б - QPSK, в - 16-QAM
Сигналы с фазовой модуляцией обладают высокой помехоустойчивостью, однако у них невелика спектральная эффективность, да и с точки зрения систем подвижной связи такие сигналы обладают существенным недостатком - огибающая имеет переменный характер и может принимать мгновенные значения, близкие к нулю. Чтобы проиллюстрировать это, можно воспользоваться графиком траектории сигнала на I(Q) - диаграмме для всех возможных комбинаций дибитов (пар) входных символов (рис. 16.3). Такая траектория отображает всевозможные линии перехода между символами передаваемого потока, зависящие от его статистических свойств.
Главный лепесток спектра ФМ-4 (QPSK) содержит порядка 90% всей мощности сигнала, в результате чего эффективность использования спектра, показывающая, сколько бит в секунду информации можно передать в одном герце полосы, не превосходит 1,5 бит/с/Гц. При использовании ФМ-2 (или ФМ-4) определение фазы любой принятой посылки производится по отношению к некоторой фиксированной опорной фазе jоп, вследствие чего реализация демодулятора таких сигналов сопровождается известными трудностями. С целью устранения этого недостатка используют относительное кодирование передаваемого сообщения на стороне передачи и относительное декодирование - на приемной стороне. Перекодирование исходной цифровой последовательности осуществляется по правилу: bi = ai Å bi-1, где ai - символ на входе относительного кодера; bi - символ на его выходе; bi-1 - символ с выхода кодера, задержанный на такт, т.е. на длительность tс ; Å - процедура сложения по модулю 2.
Рис. 16.3. Огибающая модуляции ФМ-4 (QPSK) на квадратурной плоскости
Перекодирование исходных данных и как следствие этого переход к сигналам ОФМ, естественно, не повышает эффективность использования спектра при их передаче по каналам связи. Универсальным средством уменьшения полосы, требуемой для передачи модулированных сигналов, является перехода к многократной (В>2) (многопозиционной) модуляции. При этом исходная последовательность символов разбивается на блоки по В = 2,3,4,…соседних символов (соответственно при М = 4,8,16,...), а длительность сигнала оказывается равной Тс = tс ´ В, что приводит к сокращению в В раз полосы занимаемых частот (при сохранении скорости передачи) и возрастанию приблизительно в В раз эффективности использования спектра.
Рис. 16.4. Сигнальное созвездие модуляции p/4-ОФМ-4.
Для повышения спектральной эффективности широко применяется относительная квадратурная ОФМ-4 (DQPSK), а уменьшение изменений огибающей при манипуляции фазы у таких сигналов достигается добавлением фазового сдвига p/4 к дифференциальному сигналу в каждый период манипуляции (рис. 16.4). При реализации дифференциального кодирования в сочетании со сдвигом несущей на π/4 сигнальное созвездие формируется двумя четырехточечными созвездиями QPSK, наложенными со сдвигом 45°. В результате в сигнале присутствуют восемь фазовых сдвигов, причем фазы символов выбираются поочередно - то из одного созвездия QPSK, то из другого. Последовательные символы имеют относительные фазовые сдвиги (относительно предыдущего периода модуляции), соответствующие одному из четырех углов: ± π/4 и ±3 π/4. В результате огибающая не принимает мгновенные значения, равные нулю. Такая модуляция, обозначаемая p/4-ОФМ-4 (p/4-shift DQPSK), достаточно широко применяется в системах подвижной связи, например, в D-AMPS, PDC и ТЕТRА.
Рис. 16.5. Огибающая модуляции p/4-ОФМ-4 на квадратурной плоскости.
На рис. 16.5 изображены траектории сигнала p/4-ОФМ-4 для всех возможных комбинаций дибитов входных символов в случае, когда цифровые символы формируются модулирующим фильтром с характеристикой p(t) (см. рис.16.1) в виде корня квадратного из приподнятого косинуса и коэффициентом сглаживания, равным 0,35. Несмотря на то, что модуляция не обладает постоянной огибающей, ее колебания ограничены, и она никогда не достигает нуля. Это помогает бороться с нелинейными искажениями, вносимыми нелинейностью усилителей мощности подвижных станций.
Весьма эффективной является также частотная модуляция минимальным сдвигом ЧММС (MSK), которая способна обеспечить минимум помех в соседних по частоте каналах. Этот метод представляет собой частотную манипуляцию, при которой несущая частота дискретно – через интервалы времени, кратные периоду Т = tс битовой модулирующей последовательности, принимает значения fн = f0 – F/4 или fв = f0 + F/4, где f0 – центральная частота используемого частотного канала, а F = 1/T. Метод MSK иногда рассматривают как метод квадратурной фазовой манипуляции со смещением (офсетная OQPSK), но с заменой прямоугольных модулирующих импульсов длительности 2Т полуволновыми отрезками синусоид или косинусоид. Разнос частот Df = fв - fн = F/2 - минимально возможный, при котором обеспечивается ортогональность колебаний частот fн и fв на интервале Т длительности одного бита; при этом за время Т между колебаниями частот fн и fв набегает разность фаз, равная p. Таким образом, термин "минимальный сдвиг" в названии метода модуляции относится, в указанном выше смысле, к сдвигу частоты. Поскольку модулирующая частота в этом случае равна F/2, а девиация частоты F/4, индекс частотной модуляции составляет m = (F/4)/(F/2) = 0,5.
MSK реализуется в стандарте GSM как гауссовская манипуляция с минимальным сдвигом (GMSK). Термин «гауссовская» в названии метода модуляции соответствует дополнительной фильтрации модулирующей битовой последовательности относительно узкополосным гауссовским фильтром с импульсной характеристикой h(t); именно эта дополнительная фильтрация отличает метод GMSK от метода MSK. В качестве характеристического параметра GMSK используют произведение ВТ, где В - ширина спектра импульса h(t) по уровню З дБ, а Т- длительность одного бита. На рис. 16.6 изображена спектральная плотность мощности на выходе идеального GMSK-модулятора (ВТ = 0,3), нормализованного по отношению к периоду Т. Сравнение этого графика со спектральной плотностью мощности MSK и BPSK, указывает на серьезное преимущество этой модуляции, прежде всего - в части скорости спадания внеполосного излучения, т.е. скорости снижения уровня мощности боковых спектральных лепестков.
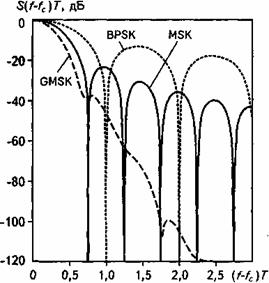
Рис. 16.6. Спектральная плотность мощности сигнала GMSK в сравнении с сигналами MSK и BPSK
17. Вопросы совершенствования обработки информации в СПРС
Важнейшей проблемой на пути создания высокоэффективных систем передачи информации является проблема согласования модемов и кодеков с учётом статистических свойств непрерывного канала. Кодирование и модуляцию необходимо рассматривать как единый процесс формирования наилучшего сигнала, а демодуляцию и декодирование — как процесс наилучшей обработки сигналов. В технике цифровой связи методы модуляции играют весьма значимую роль. Помимо своей основной функции — преобразования символ - сигнал, т.е. выполнения функции интерфейса между дискретным и непрерывным каналами — процесс модуляции является составной частью общего процесса согласования сигнала с характеристиками канала.
Многопозиционные сигналы с плотной упаковкой (например, ФМ и КАМ) обеспечивают высокую удельную скорость за счёт снижения энергетической эффективности. С другой стороны, корректирующие коды позволяют повысить энергетическую эффективность при определённом снижении удельной скорости. Каждый из этих способов даёт выигрыш по одному показателю в обмен на ухудшение другого. Для того чтобы получить одновременно наилучшую энергетическую и частотную эффективность, используется кодированная модуляция или - в другой терминологии – определенные сигнально-кодовые конструкции (СКК), сочетающие в единой конструкции многопозиционные сигналы и корректирующие коды. В качестве помехоустойчивых кодов в СКК обычно используются свёрточные коды, а в качестве многопозиционных сигналов - чаще всего ФМ сигналы.
Создание сигнально-кодовых конструкций с целью обеспечения наилучшего качества передачи данных по каналу осуществляется в рамках многоуровневого кодирования. На практике это означает обеспечение максимальной защиты тех бит ФМ модуляции, которые наиболее подвержены ошибкам. Различные уровни защиты реализуются с помощью различных компонентов свёрточных кодов с индивидуальными скоростями Rp = m/n. Эти компоненты образуются в кодере путем выкалывания символов в первичном (материнском) коде, характеризуемом скоростью R = 1/n. В результате выкалывания формируется перфорированный код, скорость которого, в рамках конкретного блока кода, может изменяться в широких пределах, например от R = 8/9 до R = 1/4. При этом входной байт информационных символов (m = 8) остается неизменным, а выкалыванием варьируется количество избыточных (поверочных) символов. Тем самым меняется уровень защиты информационных бит в конкретном блоке кода – от самого низкого, когда добавляется только один поверочный бит (код (n-1)/n), до максимального, которому соответствуют три поверочных бита на каждый информационный.
В качестве примера совершенствования обработки информации в СПРС при адаптации пропускной способности системы, рассмотрим отдельные аспекты расширения GSM / GPRS, связанные с увеличением скорости передачи данных в рамках технологии, известной под названием EDGE.
Введение услуги пакетной радиопередачи данных GPRS стало значительным улучшением и расширением стандартной системы GSM. Причин для ее возникновения много. Скорости передачи данных в существующих сетях подвижной связи были недостаточными, а время установления соединения - слишком большим. Передача данных по сети с коммутацией каналов не соответствовала пакетному и асимметричному характеру трафика, что приводило к неэффективному использованию существующих ресурсов системы. В конечном итоге было принято решение о применении передачи данных с коммутацией пакетов. В результате в таком режиме абоненты получили возможность задействовать одни и те же физические каналы, а системные ресурсы распределяются более эффективно благодаря статистическому мультиплексированию. Последствием применения пакетной коммутации является принцип оплаты за услугу, базирующийся на количестве переданных пакетов данных.
Физический уровень системы GPRS похож на физический уровень стандартной системы GSM. Тем не менее, пакетная передача и асимметрия трафика потребовали внесения в него некоторых изменений и дополнений. Так, система GPRS позволяет, при необходимости, передавать пакетные данные в режиме коммутации пакетов с использованием более одного временного слота(до восьми временных слотов) в кадре, если это возможно с точки зрения системных ресурсов. Однако скорость такой передачи данных не очень высока по сравнению с проводным подключением к сети Internet. Удовлетворить потребность в более высоких скоростях удалось в рамках новой технологии повышения скорости передачи данных EDGE.
В системе EDGE для GSM (т.н. система EDGE Classic) используются некоторые усовершенствования, которые позволяют передавать пакеты данных с более высокими скоростями, чем в стандартных системах GSM или GPRS. Среди этих усовершенствований: применение модуляции ФМ-8 (8-PSK) в высокоскоростных режимах (в низкоскоростных режимах по-прежнему используется GMSK-модуляция); медленная скачкообразная перестройка частоты, которая представляет собой опцию в стандартной системе GSM; контроль качества радиоканала.
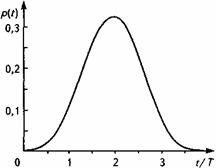
Рис. 17.1. Импульсная характеристика фильтра формирования импульсов в модуляторе сигналов ФМ-8 системы EDGE
Модуляция ФМ-8, по определению, позволяет обеспечить в три раза большую скорость передачи данных по сравнению со стандартной системой GSM при условии использования тех же символьной скорости и полосы частот. Это обусловлено тем, что при ФМ-8 каждый информационный символ представляется тремя битами. Побитовое соответствие блоков символам подчиняется правилу Грея. Помимо фазового сдвига, определяемого информационными битами, фаза дополнительно сдвигается на Зπ/8 на каждый период передачи одного символа. Это позволяет избежать низких уровней огибающей, что негативно сказывается на нелинейном режиме усиления таких сигналов. Для того чтобы привести сигнал в соответствие с шириной спектра канала и сохранить форму GMSK-спектра, используется модулирующий импульс p(t) (рис. 17.1), форма которого похожа на гауссовскую кривую и рассчитана при помощи численных методов.
Важнейшее свойство системы EDGE - контроль качества радиоканала. Подвижные станции передают на базовые станции информацию о качестве канала. На основании этой информации принимается решение о том, какую комбинацию модуляции и канального кодирования следует использовать. В системе EDGE могут применяться два типа модуляции (GMSK и ФМ-8) и девять скоростей кодирования. Каждая комбинация имеет свою характеристику, выражаемую в зависимости пропускной способности (на один временной слот) от отношения сигнал/шум. Переключение между комбинациями кодирования и модуляции позволяет максимизировать пропускную способность. Принцип адаптации к качеству канала радиосвязи иллюстрируется на рис. 17.2. Максимальная скорость передачи данных на одну несущую (когда используются все временные слоты) составляет 556,8 кбит/с для ФМ-8 и 185,6 кбит/с для GMSK. Максимальная доступная пользователю скорость передачи данных будет меньше из-за использования канального кодирования со скоростями в диапазоне от R = 0,38 доR = 1.
Контроль качества радиоканала, реализованный в системе EDGE при помощи адаптивного выбора модуляции и кодирования, подтверждается теорией информации. Так, можно показать, что для достижения максимальной пропускной способности скорость передачи данных должна быть высокой при хорошем качестве радиоканала (при больших отношениях сигнал-шум) и низкой при временном снижении качества канала. Необходимо подчеркнуть, что такая адаптация возможна только при наличии обратной связи между приемником и передатчиком. В табл. 17.1 приведены возможные комбинации кодирования и модуляции.
Радиоблок данных (РБД) - это наименьший элемент передаваемых в рамках системы EDGE данных. Каждый РБД содержит один или два блока пакетных данных (PDU). Количество PDU в радиоблоке зависит от выбранной схемы модуляции и кодирования. В случае использования канала с ошибками, как правило, применяется метод ARQ (автоматический запрос на повторение) - при наличии обратной связи между приемником и передатчиком.
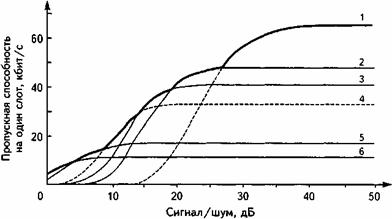
Рис. 17.2. Пропускная способность на один временной слот для различных комбинаций кодирования и модуляции
Передача информационных последовательностей, дополненных CRC-блоками для обнаружения ошибок, часто применяется в системах передачи данных, включая системы подвижной связи. В этом случае необходимо создать канал обратной связи, по которому будет передаваться информация о том, был переданный информационный блок принят или отвергнут. Если такой канал не может быть реализован (например, из-за чрезмерных задержек в сети), то остается единственный способ увеличения производительности передачи данных - применение достаточно строгой упреждающей коррекции ошибок (FEC), т.е. канального кодирования.
На рис. 17.3 представлена схема передачи данных при использовании канала обратной связи. Основной поток данных передается с передатчика на приемник по основному каналу. В основе стандартного метода ARQ лежит добавление CRC-битов четности, вычисленных передатчиком, к концу блока данных. В приемнике CRC-биты заново рассчитываются по принятому блоку данных. Если вычисленные биты совпадают с принятыми, то приемник посылает подтверждение приема (АСК), и передатчик начинает передавать следующий блок. Если рассчитанные приемником CRC-биты не совпадают с принятыми, то весь блок отбрасывается и подлежит повторной передаче. Вместо простой схемы ARQ может использоваться принцип ARQ с нарастающей избыточностью (IR).
Таблица 17.1.
|
Схема |
Модуляция |
Максимальная скорость, кбит/с |
Скорость кода |
PDU / 20 мс |
Размер PDU, байтов |
|
MSC-9 |
ФМ-8 |
473 |
1,0 |
2 |
74 |
|
MSC-8 |
ФМ-8 |
435 |
0,92 |
2 |
68 |
|
MSC-7 |
ФМ-8 |
358 |
0,76 |
2 |
56 |
|
MSC-6 |
ФМ-8 |
234 |
0,49 |
1 |
74 |
|
MSC-5 |
ФМ-8 |
179,2 |
0,37 |
1 |
56 |
|
MSC-4 |
GMSK |
141 |
1,0 |
1 |
44 |
|
MSC-3 |
GMSK |
119 |
0,80 |
1 |
37 |
|
MSC-2 |
GMSK |
90 |
0,66 |
1 |
28 |
|
MSC-1 |
GMSK |
70,4 |
0,53 |
1 |
22 |
В основе метода IR ARQ лежит повторное использование ошибочного блока для детектирования ошибок. В процессе кодирования на выходе сверточного кодера применяется перфорирование по двум или трем различным схемам (Р1, Р2 или РЗ). Вначале передается кодированный блок, подвергнутый перфорированию по схеме Р1. Если в нем обнаружены ошибки, то передаются биты, полученные при перфорировании по схеме Р2, которые добавляются к ранее переданному блоку. Затем этот блок снова декодируется. При этом возрастает количество битов четности (избыточности), и декодирование целого блока приводит к гораздо лучшей коррекции ошибок. Если были получены все биты, рассчитанные по всем схемам перфорирования, а ошибки не были устранены, то повторяется весь процесс передачи блока.
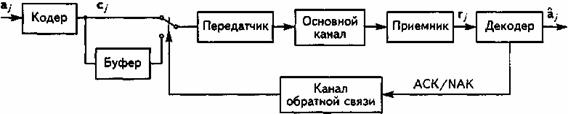
Рис. 17.3. Система передачи данных с повтором блоков и каналом обратной связи
Благодаря высоким скоростям передачи данных, достижимых в системе EDGE, она сегодня рассматривается как одно из возможных предложений к реализации систем третьего поколения (3G). В ближайшем будущем станет ясно, насколько введение EDGE в сети GSM повлияет на распространение системы UMTS.
Приложение
Основные сокращения и определения
|
Сокращения |
|||
| АБГШ |
аддитивный белый гауссовский шум (A) |
||
| АДИКМ |
адаптивная дифференциальная ИКМ (ADPCM) |
||
| АП |
адаптивное предсказание |
||
| АТ |
абонентский терминал, подвижная станция, подвижный терминал (MS- Mobile Station; MT- Mobile Terminal) |
||
| АЦП | аналого-цифровой преобразователь | ||
| АЧХ | амплитудно-частотная характеристика | ||
| БПФ | быстрое преобразование Фурье (FFT) | ||
| БС | приемо-передающая базовая станция (BTS -Base Transceiver Station) | ||
| БЧХ | Боуза-Чоудхури-Хоквингема - корректирующий код (BCH) | ||
| ВПИ | внеполосное излучение | ||
| ВРК | временное разделение каналов (TDM - Time Division Multiple) | ||
| ДИКМ |
дифференциальная импульсно-кодовая модуляция (DPCM) |
||
| ДМ |
дельта-модуляция (DM) |
||
| ДН |
диаграмма направленности |
||
| ДСК |
дискретный (двоичный) симметричный канал |
||
| ЖКД |
жидкокристаллический дисплей |
||
| ИКМ |
импульсно-кодовая модуляция (PCM - Рulse Сode Мodulation) |
||
| КАМ |
квадратурная амплитудная модуляция (QAM) |
||
| КП |
кодовая последовательность |
||
| КС |
кодовое слово |
||
| КФС |
кодирование формы сигнала |
||
| ЛП |
линейное предсказание |
||
| МДКР |
многостанционный доступ с кодовым разделением каналов (CDMA) |
||
| МК |
мгновенное компандирование |
||
| МСЭ |
Международный союз электросвязи (ITU) |
||
| ОСШ |
отношение сигнал-шум |
||
| ОСШК |
отношение сигнал-шум квантования |
||
| ОТ |
основной тон |
||
| ОФМ |
относительная фазовая модуляция (манипуляция) |
||
| ПО |
подвижный объект |
||
| ПСП |
псевдослучайная (двоичная) последовательность (PRBS) |
||
| РС |
речевой сигнал |
||
| РЧС |
радиочастотный спектр |
||
| СБИС |
сверхбольшая интегральная схема (чип) (VLSI) |
||
| СК |
сверточный (древовидный) корректирующий код |
||
| СКК |
сигнально-кодовая конструкция |
||
| СКО |
среднеквадратическое отклонение |
||
| СПРС |
сотовая подвижная радиосвязь |
||
| СПСС |
системы персональной спутниковой связи |
||
| ССИ |
субъективно-статистические испытания |
||
| ССПС |
сотовые системы подвижной связи (Cellular Radio Systems) |
||
| ТФ |
телефон, телефонный |
||
| ТфОП |
телефонная сеть общего пользования |
||
| ФЛП |
фильтр линейного предсказания |
||
| ФМ |
фазовая модуляция (манипуляция) |
||
| ФНЧ |
фильтр нижних частот |
||
| ФЧХ |
фазочастотная характеристика |
||
| ЦАП |
цифроаналоговый преобразователь |
||
| ЧМ |
частотная модуляция (FM) |
||
| ЧММС |
частотная модуляция минимальным сдвигом |
||
| ЧРК |
частотное разделение каналов (FDM - Frequency Division Multiple) |
||
| ЭВК |
энергетический выигрыш кодирования |
||
|
* * * |
|||
| ACELP |
Algebraic Code Excited Linear Prediction - линейное предсказание с возбуждением алгебраическим кодом |
||
| APC |
Adaptive predictive coding - адаптивное кодирование с предсказанием |
||
| ARQ |
Automatic-Repeat-Request - автоматический запрос на повторение |
||
| BER |
Bit Error Rate – вероятность ошибки на бит |
||
| CDMA |
Code Division Multiple Access - многостанционный доступ с кодовым разделением каналов |
||
| CELP |
Code-excited linear prediction - линейное предсказание с кодовым возбуждением |
||
| CRC |
Cycling Redundancy Check - контроль с помощью циклического избыточного кода (помехоустойчивый код) |
||
| CT |
Cordless Telephony - системы беспроводных телефонов |
||
| D-AMPS |
Digital Advanced Mobile Phone Service – цифровая усовершенствованная мобильная телефонная служба (стандарт сотовой связи) |
||
| DECT |
Digital European Cordless Telecommunications -общеевропейская система беспроводных телефонов |
||
| DQPSK |
Differentially Quadrature Phase Shift Keying - дифференциальная квадратурная фазовая манипуляция (ОФМ-4) |
||
| DSP |
Digital Signal Processing - цифровой процессор обработки сигналов (сигнальный процессор) |
||
| EDGE |
Enhanced Data rate for Global Evolution - технология повышения скорости передачи данных для глобальной эволюции |
||
| EFR |
Enhanced Full Rate - расширенное кодирование речи с полной скоростью |
||
| FEC |
Forward Error Correction (coding) - (помехоустойчивое) кодирование канала с упреждающей коррекцией ошибок или обнаружение ошибок |
||
| FM |
Frequency Modulation - частотная модуляция (ЧМ) |
||
| FR |
Full Rate - кодирование речи с полной скоростью |
||
| GMSK |
Gaussian Minimum Shift Keying - гауссовская манипуляция с минимальным сдвигом |
||
| GPRS |
General Packet Radio Service - услуга пакетной передачи данных по радиоканалу |
||
| GSM |
Global System for Mobile Communications – глобальная система мобильной связи |
||
| GPS |
Global Positioning System - система глобального позиционирования (определения координат) |
||
| HEO |
Highly Elliptical Orbit - высокоэллиптическая орбита |
||
| HR |
Half Rate - кодирование речи с половинной скоростью |
||
| HVXC |
Harmonic Vector eXcitation Coding - кодирование (речи) с векторным гармоническим возбуждением |
||
| ITU |
International Telecommunication Union - - Международный Союз Электросвязи (МСЭ) |
||
| LAR |
Logarithmic Area Ratio - логарифмические отношения площадей |
||
| LD-CELP |
Low delay CELP - линейное предсказание с кодовым возбуждением и малой задержкой |
||
| LPC |
Linear Predictive Coding - кодирование (речи) методом линейного предсказания |
||
| LTP |
Long term prediction - долговременное предсказание |
||
| LTP-LPC |
Long Term Predictor LPC - линейное предсказание с долговременным предсказанием |
||
| MBE |
Multi Band Excitation - многополосное возбуждение |
||
| MELP |
Mixed Exitation Linear Prediction - линейное предсказание со смешанным возбуждением |
||
| MIPS |
Millions of Instructions Per Second – единица измерений в миллионах инструкций в секунду |
||
| MOS |
Mean opinion score - средняя оценка мнений; средняя субъективная оценка |
||
| MPE |
Multipulse excited - многоимпульсное возбуждение |
||
| MPE-LPC |
Multi Pulse Excitation LPC - линейное предсказание с многоимпульсным возбуждением |
||
| MP-MLQ |
Multi Pulse Maximum Likelihood Quantization - метод квантования по максимуму правдоподобия |
||
| PCN |
Personal Communications Network - сеть персональной связи |
||
| PDU |
Packet Data Unit - блок пакетных данных |
||
| RELP |
Residual Excited Linear Prediction - линейное предсказание с возбуждением от остатка предсказания |
||
| RPE |
Regular pulse excited - возбуждение регулярной последовательностью импульсов |
||
| RPE-LPC |
Regular Pulse Excitation LPC - линейное предсказание с регулярным импульсным возбуждением |
||
| RPE-LTP |
Regular Pulse Excitation — Long Term Prediction - метод возбуждения регулярной последовательностью импульсов с долговременным предсказанием |
||
| SIM |
Subscriber Identity Module - модуль идентификации абонента (SIM - карта) |
||
| SMS |
Short Message Service - услуга передачи и приема коротких сообщений |
||
| STP |
Short term prediction - кратковременное предсказание |
||
| UMTS |
Universal Mobile Telesystem - универсальная система подвижной электросвязи |
||
| UPT |
Universal Personal Telecommunications - универсальная персональная связь |
||
| VLSI |
Very Large Scale Integration - сверхбольшие интегральные схемы (СБИС) |
||
| VSELP |
Vector sum excited linear prediction - линейное предсказание с возбуждением векторной суммой |
||
| p/4-shift DQPSK |
p/4-shift Differential Quadrature Phase Shift Keying – дифференциальная квадратурная манипуляция фазы со скачком p/4 |
||
|
* * * |
|||
| Определения | |||
| Аутентификация |
- процедура подтверждения подлинности (действительности, законности) абонента системы подвижной связи |
||
| Временной слот |
- временной интервал заданной длины. Последовательность временных слотов, которые передаются на выбранной несущей частоте, в системе GSM называют физическим каналом |
||
| Децимация отсчетов | - прореживание последовательности импульсов | ||
| Дуплексный режим | - режим, при котором передача возможна одновременно в обоих направлениях канала электросвязи | ||
| Защитное расстояние | - расстояние (защитный интервал) между центрами сот, при котором обеспечивается заданный уровень взаимных помех | ||
| Идентификация |
- процедура отождествления подвижной станции (абонентского терминала), т.е. процедура установления принадлежности к одной из групп, обладающих определенными свойствами или признаками |
||
|
Канальный эквалай-зинг |
- средство борьбы с межсимвольными искажениями в канале связи, реализуемое на основе применения адаптивных фильтров |
||
|
Линейная интерполяция |
- процедура, при которой допускают, что приращение функции пропорционально приращению аргумента |
||
|
Многостанционный (множественный) доступ |
- технология связи, обеспечивающая возможность обращения (доступа) нескольких источников информации к среде передачи (к одному радиопередатчику), при котором все источники могут передавать свои сигналы одновременно |
||
| Огибающая спектра |
- линия, соединяющая концы ординат частотных составляющих, называется огибающей спектра |
||
|
Окно (“оконная” функция) |
- применяется с целью уменьшения паразитного обогащения спектра оценки (ценой снижения разрешающей способности анализа): анализируемый отрезок входного сигнала умножается на "оконную" функцию, обеспечивающую спадание его к нулю по краям. Обычно выбирается компромисс между шириной главного лепестка и уровнем подавления боковых лепестков. Самый узкий главный лепесток (и самый высокий уровень боковых лепестков) имеет частотная характеристика прямоугольного окна. Окно Ханна - это окно типа "косинус квадрат" (его часто называют "приподнятый косинус", хотя это синоним окна Хэмминга) |
||
| Пик-фактор |
- отношение максимальной мощности сигнала к его средней мощности. Для случайных сигналов, например для звуковых сигналов, пик-фактором называют разность между квазимаксимальным и усредненным за длительный промежуток времени уровнями |
||
|
Поколение (оборудования) |
- интегральная характеристика техники (технологии), системы или оборудования, отражающая определенный уровень развития. В электросвязи обычно характеризует вид системы передачи (аналог-цифра), объем и номенклатуру услуг, массо-габаритные параметры, энергетическую и частотную эффективность, пропускную способность и другое |
||
|
Помехоустойчивость канала передачи информации |
- характеризует способность системы передачи противостоять воздействию разного рода помех |
||
| Правило Грея |
- предполагает такое использование манипуляционного кода при задании М информационных бит возможными фазами сигнала, при котором соседние фазы соответствуют информационным двоичным блокам, различающимся в одном разряде |
||
|
Цифровые потоки I и Q |
- параллельные потоки данных I(t) и Q(t), используемые для модуляции соответственно синфазного и квадратурного гармонических колебаний, т.е. колебаний, отличающихся начальным фазовым сдвигом, равным π/2 |
||
|
Частотная эффективность |
- характеризует эффективность использования выделенного спектра частот | ||
|
Энергетический баланс |
- баланс между ресурсами передачи и приема, между источниками усиления и потерь передаваемого сигнала, это метод оценки, позволяющий определить достоверность передачи информации по каналу связи |
||
|
* * * |
|||
| Global Roaming |
- глобальный роуминг - обеспечение глобальной (общемировой) мобильности абонента, т.е. процедура предоставления услуг мобильной связи абоненту одного оператора |
||
| Handover |
- передача обслуживания (“эстафетная передача”) абонента из соты в соту в режиме разговора. При удалении от БС, во время перемещения АТ, снижается уровень сигнала и, следовательно, качество передачи. На границе сот возникает необходимость смены БС. Решение о переключении вызова принимается сетью по результатам измерения уровня сигнала в АТ |
||
| IMT-2000 | IMT-2000 (International Mobile Telecommunications) - Международная подвижная электросвязь, где число 2000 символически указывает используемый частотный диапазон (2000 МГц) и предполагаемый год внедрения | ||
Рекомендуемая литература
Основная литература
1. Акустика / Под ред. М.А.Сапожкова: Справочник. - М.: Радио и связь, 1989. - 336 с.
2. Беллами Дж. Цифровая телефония: Пер. с англ. - М.: Радио и связь, 1986. - 544 c.
3. Быков С.Ф., Журавлев В.И., Шалимов И.А. Цифровая телефония: Учеб. пособие для вузов. – М.: Радио и связь, 2003. -144 с.
4. Галкин В.А. Цифровая мобильная радиосвязь. – М.: Горячая линия – Телеком, 2005. – 432 с.
5. Иванова Т.И. Абонентские терминалы и компьютерная телефония. – М.: Эко-Трендз, 1999. – 240 с.
6. Калинцев Ю.К. Конфиденциальность и защита информации. Учебное пособие / МТУСИ. - М., 1997. - 60 с.
7. Маковеева М.М., Шинаков Ю.С. Системы связи с подвижными объектами. Учебное пособие - М.: Радио и связь, 2002. - 440 с.
8. Назаров М.В., Прохоров Ю.Н. Методы цифровой обработки и передачи речевых сигналов. - М.: Радио и связь, 1985. - 176 с.
9. Невдяев Л.М., Смирнов А.А. Персональная спутниковая связь. - М.: Эко-Трендз, 1998. - 216 с.
10. Попов В.И. Основы сотовой связи стандарта GSM. – М.: Эко-Трендз, 2005. – 296 с.
11. Ратынский М.В. Основы сотовой связи / Под ред. Д.Б. Зимина. - М.: Радио и связь, 1998. - 248 с.
12. Рихтер С.Г. Устройства преобразования и обработки информации в системах подвижной радиосвязи. Конспект лекций для дистанционной технологии обучения / МТУСИ. - М.: 2004. – 56 с.
13. Сапожков М.А., Михайлов В.Г. Вокодерная связь. - М.: Радио и связь, 1984. - 248 с.
14. Ситняковский И.В. и др. Цифровая сельская связь / Под ред. М.Д. Венедиктова. - М.: Радио и связь, 1994. - 248 с.
15. Шелухин О.И., Лукьянцев Н.Ф. Цифровая обработка и передача речи. – М.: Радио и связь, 2000. – 456 с.
Дополнительная литература
1. Андрианов В.И., Соколов А.В. Средства мобильной связи. - СПб.: BHV-Санкт-Петербург,1998. – 256 с.
2. Брауде-Золотарев М. Пара слов о речи // Компьютерра, 1999, 15 (293), с.21-33.
3. Варакин Л.Е., Трубин В.Н. Сотовые системы подвижной связи. "Зарубежная радиоэлектроника", 1986, N2, с.3-32.
4. Весоловский Кшиштоф Системы подвижной радиосвязи / Пер. с польск. – М.: Горячая линия – Телеком, 2005. – 536 с.
5. Ворсано Д. Кодирование речи в цифровой телефонии // Сети и системы связи, 1996, N1, с.84-87.
6. Громаков Ю. А. Стандарты и системы подвижной радиосвязи. – М.: Эко-трендз, 1998. – 239 с.
7. Зюко А.Г., Банкет В.Л., Лехан В.Ю. Методы низкоскоростного кодирования при цифровой передаче речи // Зарубежная радиоэлектроника, 1986, N11, с.53-69.
8. Коротаев Г.А. Методы линейного предсказания // Зарубежная радиоэлектроника, 1980, N10, с.49-65.
9. Коротаев Г.А. Анализ и синтез речевого сигнала методом линейного предсказания // Зарубежная радиоэлектроника, 1990, N3, с.31-51.
10. Коротаев Г.А. Некоторые аспекты линейного предсказания при анализе и синтезе речевого сигнала // Зарубежная радиоэлектроника, 1991, N7, с.3-31.
11. Коротаев Г.А. Эффективный алгоритм кодирования речевого сигнала на скорости 4,8 кбит/с и ниже // Зарубежная радиоэлектроника, 1996, N3, с.52-68.
12. Невдяев Л.М. Мобильная спутниковая связь: Справочник. Серия изданий "Связь и бизнес". - М., МЦНТИ, 1998. - 155 с.
13. Невдяев Л.М. Мобильная связь 3-го поколения / Под редакцией Горностаева Ю.М. - М.: Связь и бизнес, 2000. - 208 с.
14. Покровский Н.Б. Расчет и измерение разборчивости речи. - М.: Связьиздат, 1962. - 392 с.
15. Рабинер Л.Р., Шефер Р.В. Цифровая обработка речевых сигналов. - М.: Радио и связь, 1984. - 496 с.
16. Радиовещание и электроакустика: Учебник для вузов / Под ред. Ю.А. Ковалгина. - М.: Радио и связь, 1998. - 792 с.
17. Рихтер С.Г. Цифровое радиовещание. – М.: Горячая линия - Телеком, 2004. – 352 с.
18. Санников В.Г. Методы эффективной обработки и передачи речевых сигналов: Учебное пособие / МТУСИ - М., 1995. - 56 с.
19. Сапожков М.А. Электроакустика. Учебник для вузов. - М.: Связь, 1978. - 272 с.
20. Спутниковая связи и вещание: Справочник. - 3-е изд., перераб. и доп.; Под ред. Л.Я.Кантора. - М.: Радио и связь, 1997.- 528 с.