6.1. Кодирование сигнала и структурированные последовательности
6.1.1. Антиподные и ортогональные сигналы
6.1.2. М-арная передача сигналов
6.3. Структурированные последовательности
6.3.1.1. Дискретный канал без памяти
6.3.2. Степень кодирования и избыточность
6.3.3. Коды с контролем четности
6.3.4. Зачем используется кодирование с коррекцией ошибок
6.3.4.1. Компромисс 1: достоверность илиполоса пропускания
6.3.4.2. Компромисс 2: мощность или полоса пропускания
6.3.4.3. Эффективность кодирования
6.3.4.4. Компромисс 3: скорость передачи данных или полоса пропускания
6.3.4.5. Компромисс 4: пропускная способность или ширина полосы пропускания
6.4.2. Векторные подпространства
6.4.3. Пример линейного блочного кода (6, 3)
6.4.5. Систематические линейные блочные коды
6.4.7. Контроль с помощью синдромов
6.4.8.1. Синдром класса смежности
6.4.8.2. Декодирование с исправлением ошибок
6.5. Возможность обнаружения и исправления ошибок
6.5.1. Весовой коэффициент двоичных векторов и расстояние между ними
6.5.2. Минимальное расстояние для линейного кода
6.5.3. Обнаружение и исправление ошибок
6.6. Полезность нормальной матрицы
6.6.1. Оценка возможностей кода
6.7.1. Алгебраическая структура циклических кодов
6.7.2. Свойства двоичного циклического кода
6.7.3. Кодирование в систематической форме
6.7.4. Логическая схема для реализации полиномиального деления
6.7.5. Систематическое кодирование с (n-k)-разрядным регистром сдвига
6.7.6. Обнаружение ошибок с помощью (n-k)-разрядного регистра сдвига
6.1. Кодирование сигнала и структурированные последовательности
Тему канального кодирования можно условно разделить на два раздела: кодирование (или обработка) сигнала и структурированные последовательности (или структурированная избыточность), как это показано на рис. 6.1. Кодирование сигнала означает преобразование сигнала в некий "улучшенный сигнал", позволяющий сделать процесс, обнаружения менее подверженным ошибкам. Метод структурированных последовательностей — это преобразование последовательности данных в новую, "улучшенную последовательность", обладающую структурной избыточностью (которая вмешает избыточные биты). Эти избыточные разряды служат для определения и исправления ошибок. На выходе процедуры кодирования получается закодированный (формой сигнала или структурированной последовательностью) сигнал, имеющий лучшие пространственные характеристики, чем некодированный. Итак, сначала рассмотрим некоторые методы кодирования сигнала, а затем, начиная с раздела 6.3, обсудим суть структурированных последовательностей.
6.1.1. Антиподные и ортогональные сигналы
Антиподные и ортогональные сигналы уже обсуждались ранее, поэтому мы лишь напомним их основные особенности. В примере, приведенном на рис. 6.2, показано аналитическое представление набора синусоидальных антиподных сигналов (![]() ), а также его векторное и графическое представление. Какие существуют альтернативные определения антиподных сигналов? О таких сигналах можно сказать, что они либо являются зеркальными отображениями друг друга, либо один сигнал является отрицательным по отношению к другому, либо они различаются между собой на 180°.
), а также его векторное и графическое представление. Какие существуют альтернативные определения антиподных сигналов? О таких сигналах можно сказать, что они либо являются зеркальными отображениями друг друга, либо один сигнал является отрицательным по отношению к другому, либо они различаются между собой на 180°.
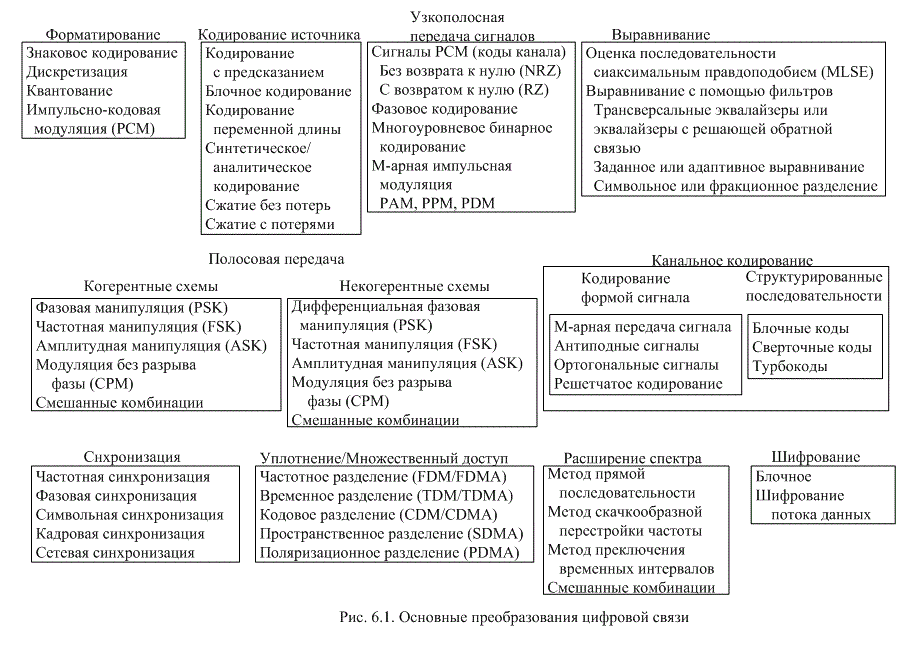
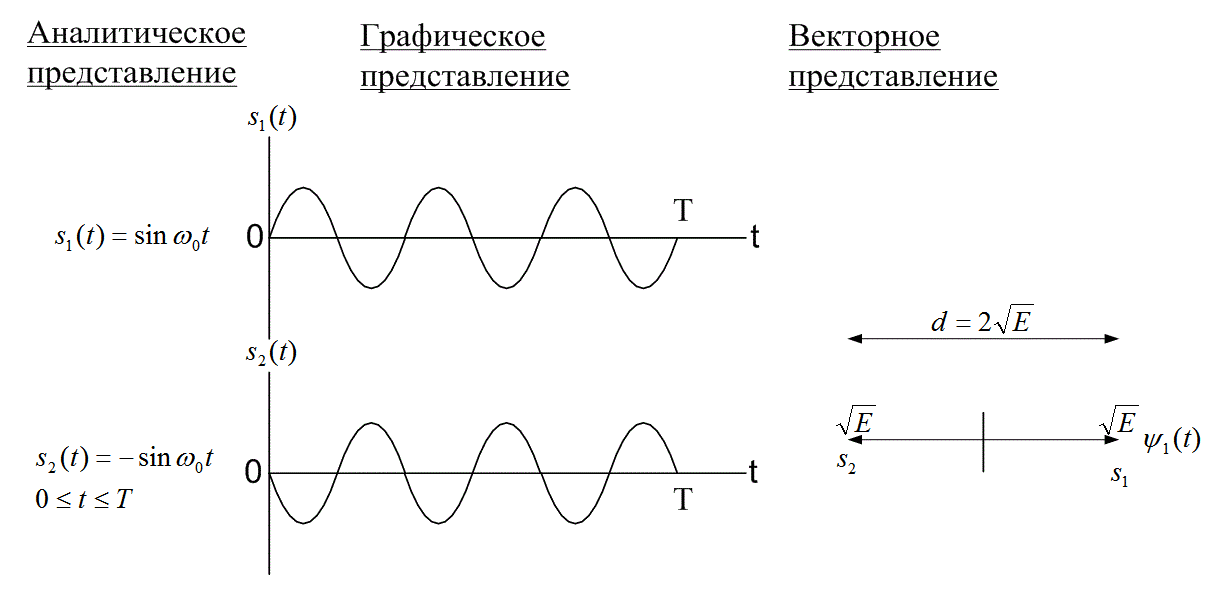
Рис. 6.2. Пример антиподного набора сигналов
В примере, приведенном рис. 6.3, показан набор ортогональных сигналов, которые имеют вид импульсов описывающихся следующими выражениями.
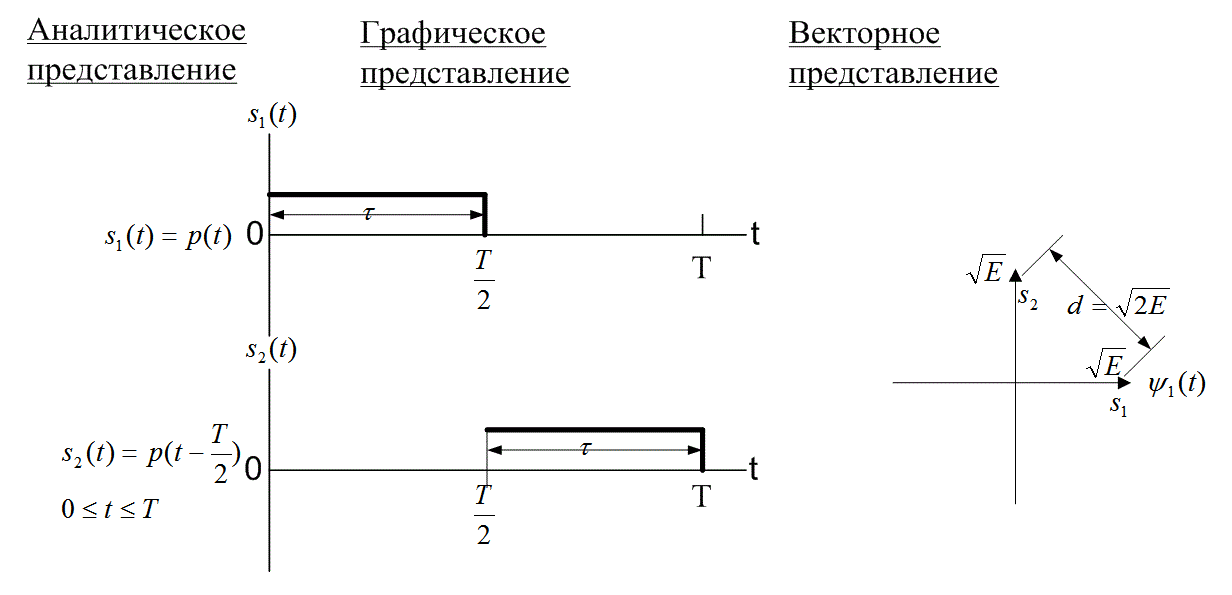
Рис. 6.3. Пример двоичного набора ортогональных сигналов
![]()
![]()
В данном случае p(t) — импульс длительностью ![]() , где Т— период. В системах связи .возможны и другое наборы ортогональных сигналов, например часто используемые sin x и cos x Любой набор равноэнергетических сигналов si(t), i = l,2,...,M, будет ортонормированным (ортогональным и нормированным на 1),тогда и только тогда, когда
, где Т— период. В системах связи .возможны и другое наборы ортогональных сигналов, например часто используемые sin x и cos x Любой набор равноэнергетических сигналов si(t), i = l,2,...,M, будет ортонормированным (ортогональным и нормированным на 1),тогда и только тогда, когда
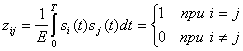 (6.1)
(6.1)
где zij является коэффициентом взаимной корреляции (cross-correlation coefficient), а величина Е — энергией сигнала, выражаемой следующим образом.
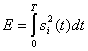 (6.2)
(6.2)
Из графического представления на рис. 6.3 видно, что s1(t) и s2(t) не могут взаимодействовать, поскольку они разнесены во времени. Векторное представление показывает, что ортогональные сигналы перпендикулярны. Посмотрим на другие, альтернативные определения ортогональных сигналов или, векторов. Можно сказать, например, что скалярное произведение двух разных векторов в ортогональном наборе должно быть равно нулю. В двух- и трехмерных декартовых системах координат векторы сигналов можно представить геометрически, как взаимно ортогональные друг к другу. Можно также сказать, что один вектор имеет нулевую проекцию на другой или один сигнал не может взаимодействовать с другим, поскольку они"не принадлежат одному и тому же пространству сигналов.
6.1.2. M-арная передача сигналов
При M-арной передаче сигналов процессор за один такт работы принимает k бит данных. После этого он указывает модулятору произвести один из M = 2k сигналов; частным случаем k = 1 является двоичная передача сигнала. Для k > 1 М-арную передачу сигналов можно рассматривать как процедуру кодирования формы сигнала. При ортогональной передаче сигналов (например, сигналов MFSK) увеличение k приводит к повышению достоверности передачи или уменьшению требуемого Eb/NQ за счет увеличения полосы пропускания; при неортогональной передаче сигналов (например, сигналов MPSK) улучшение эффективности использования полосы пропускания происходит за счет снижения достоверности передачи или возрастания требуемого Eb/NQ. Подходящий выбор формы сигнала позволяет найти компромисс между вероятностью ошибки, Eb/NQ и эффективностью использования полосы пропускания. Более подробно такие компромиссы рассмотрены в главе 9.
6.1.3. Кодирование сигнала
Процедура кодирования сигнала состоит в преобразовании набора сигналов (представляющих набор сообщений) в усовершенствованный набор сигналов. Этот улучшенный набор можно использовать для получения более приемлемой величины РВ, соответствующей исходному набору. Наиболее популярные из таких кодов сигнала называются ортогональными (orthogonal) и биортогональными кодами (biorthogonal). В процессе кодирования каждый сигнал набора пытаются сделать настолько непохожим на другие, насколько это возможно, чтобы для всех пар сигналов коэффициент взаимной корреляции zij (см. уравнение 6.1) имел наименьшее возможное значение. Строго это условие выполняется тогда, когда сигналы антикоррелируют (zij = -1); этого можно добиться только в том случае, если в наборе всего два значения (М =2) и они антиподны друг другу. Вообще, все коэффициенты взаимной корреляции можно сделать равными нулю [1]. В этом случае набор будет ортогональным. Наборы антиподных сигналов являются оптимальными в том смысле, что все сигналы максимально удалены друг от друга, как можно видеть на рис. 6.2. Расстояние d между векторами сигналов определяется как ![]() , где Е— энергий сигнала на интервале T, как показано а уравнении (6.2). Сравнив пространственные характеристики ортогональных сигналов с характеристиками антиподных сигналов, приходим к выводу, что о первых можно сказать нечто вроде "довольно хорошо" (при данном уровне энергии сигнала). На рис. 6.3 расстояние между векторами ортогональных сигналов составляет
, где Е— энергий сигнала на интервале T, как показано а уравнении (6.2). Сравнив пространственные характеристики ортогональных сигналов с характеристиками антиподных сигналов, приходим к выводу, что о первых можно сказать нечто вроде "довольно хорошо" (при данном уровне энергии сигнала). На рис. 6.3 расстояние между векторами ортогональных сигналов составляет ![]()
Взаимная корреляция между двумя сигналами является мерой расстояния между двумя векторами сигналов. Чем меньше взаимная корреляция, тем больше векторы удалены друг от друга. Это можно проверить с помощью рис. 6.2, где антиподные сигналы (для которых zij =-l) представлены векторами, наиболее удаленными друг от друга, и рис. 6.3, где ортогональные сигналы (для которых zij = 0) представлены векторами, расположенными ближе друг к другу, чем антиподные векторы. Очевидно, что расстояние между идентичными сигналами (zij = 1) должно быть равно нулю.
Условие ортогональности в уравнении 6.1 записано через сигналы si(t) и sj(t), где i,j = 1, 2, ...,М (М — количество сигналов в наборе). Каждый сигнал набора ![]() может содержать последовательность импульсов с уровнями +1 или -1, которые представляют двоичную 1 или 0. Если выразить набор в таком виде, уравнение (6.1) можно упростить, положив, что
может содержать последовательность импульсов с уровнями +1 или -1, которые представляют двоичную 1 или 0. Если выразить набор в таком виде, уравнение (6.1) можно упростить, положив, что ![]() состоит из ортогональных сигналов тогда и только тогда, когда
состоит из ортогональных сигналов тогда и только тогда, когда
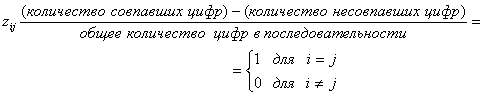 (6.3)
(6.3)
6.1.3.1. Ортогональные коды
Набор однобитовых данных можно преобразовать с помощью ортогональных кодовых слов, состоящих из двух разрядов каждое, которые описываются строками показанной ниже матрицы Н1.
Набор данных Набор ортогональных кодовых слов
![]()
![]() (6.4,а)
(6.4,а)
В этом и следующих примерах проверка ортогональности набора кодовых слов производится с помощью уравнения (6.3). Для кодирования набора двухбитовых данных упомянутый выше набор следует расширить по горизонтали и вертикали, что дает матрицу Н2.
Набор данных Набор ортогональных кодовых слов
![]()
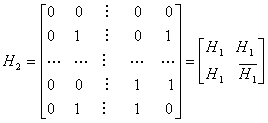 (6.4,б)
(6.4,б)
Правый нижний квадрант является дополнением к исходному набору кодовых слов. С помощью подобной процедуры можно определить и ортогональный набор Н3для набора 3-битовых данных.
Набор данных Набор ортогональных кодовых слов

 (6.4,в)
(6.4,в)
Вообще, для набора k-битовых данных из матрицы Hk-1, можно построить набор кодовых слов Hk размерностью 2k х 2k, который называется матрицей Адамара (Hadamard matrix).
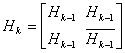 (6.4,г)
(6.4,г)
Каждая пара слов в каждом наборе кодовых слов H1, H2, H3, …, Hk, … содержит одинаковое количество совпадающих и несовпадающих разрядов [2]. Поэтому, в соответствии с уравнением (6.3), zij = 0 (при ![]() ) и каждый из этих наборов ортогонален.
) и каждый из этих наборов ортогонален.
Точно так же, как М-арная передача сигналов с ортогональной модуляцией (такой, как MFSK) понижает РB, кодирование информации ортогональным набором сигналов при когерентном обнаружении дает абсолютно такой же результат. Для одинаковых, равноэнергетических ортогональных сигналов вероятность ошибки в кодовом слове (символе), РЕ, можно оценить сверху, как [2]
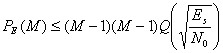 , (6.5)
, (6.5)
где размер набора кодовых слов М равен 2k, a k — это число информационных бит в кодовом слове. Функция Q(x) определена в уравнении (3.43), Es=kEb является энергией кодового слова. При фиксированном М с ростом Eb/N0 оценка становится все более точной; уже для РE(М)![]() 10-3 уравнение (6.5) является довольно хорошим приближением. Для выражения вероятности появления ошибочного бита мы будем использовать связь между рв и РЕ, которая дается уравнением (4.112). Приведем ее повторно.
10-3 уравнение (6.5) является довольно хорошим приближением. Для выражения вероятности появления ошибочного бита мы будем использовать связь между рв и РЕ, которая дается уравнением (4.112). Приведем ее повторно.
![]() (6.6)
(6.6)
В результате объединения уравнений (6.5) и (6.6) вероятность появления ошибочного бита можно оценить следующим образом.
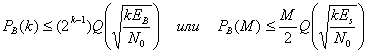 (6.7)
(6.7)
6.1.3.2. Биортогональные коды
Биортогональный набор сигналов, состоящий из М сигналов или кодовых слов, получается из ортогонального набора, состоящего из M/2 сигналов, путем дополнения последнего сопряженными значениями каждого сигнала.
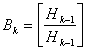
Например, набор 3-битовых данных можно преобразовать в биортогональный набор кодовых слов следующим образом.
Набор данных Набор ортогональных кодовых слов
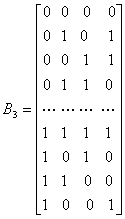
В действительности биортогональный набор состоит из двух ортогональных кодов, таких, что для каждого кодового слова в одном наборе имеется 'антиподное ему слово в другом. Биортогональный набор состоит из комбинации ортогональных и антиподных сигналов. Если использовать коэффициенты zij, введенные в уравнении (6.1), то биортогональные коды можно представить следующим образом.
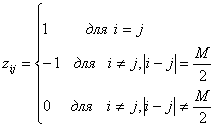 (6.8)
(6.8)
Одно из преимуществ биортогональных кодов перед ортогональными заключается в том, что при передаче аналогичной информации размер кодового слова биортогональных кодов вдвое меньше размера кодового слова ортогональных кодов (сравните строки матрицы В3со строками представленной ранее матрицы Н3). Следовательно, при использовании биортогональных кодов требования к полосе пропускания вдвое слабее, чем при использовании ортогональных кодов. Поскольку антиподные векторы сигналов имеют лучшие пространственные характеристики, чем ортогональные, не должно удивлять, что биортогональные коды лучше ортогональных. Для одинаковых, равноэнергетических биортогональных сигналов вероятность ошибки в кодовом слове (символе) можно оценить [2] следующим образом.
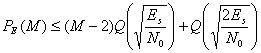 (6.9)
(6.9)
При фиксированном М с ростом En/N0 оценка становится все более точной. Зависимость РB(М) от PE(м) является довольно сложной, но ее, согласно [2], можно аппроксимировать следующим образом.
![]()
Это приближение становится достаточно хорошим при M>8. Таким образом, Можно записать следующее.
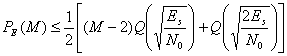 (6.10)
(6.10)
Описанные биортогональные коды значительно снижают РB по сравнению с ортогональными кодами и требуют только вдвое меньшей полосы пропускания, чем аналогичные ортогональные коды.
6.1.3.3. Трансортогональные (симплексные) коды
Код, получаемый из ортогонального путем удаления первого разряда каждого кодового слова, называется трансортогональным (transorthogonal), или симплексным (simplex) кодом. Такой код описывается следующими значениями zij.
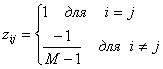 (6.11)
(6.11)
С точки зрения минимальной энергии, необходимой для поддержания заданной вероятности ошибки, симплексный код эквивалентен равновероятному ортогональному набору. Сравнивая достоверность передачи ортогонального, биортогонального и симплексного кодов, можно сказать, что симплексный код имеет наименьшее требуемое Eb/N0 для получения определенной частоты появления символьных ошибок. Впрочем, при больших М все три схемы очень похожи между собой в смысле достоверности передачи. При этом биортогональное кодирование, по сравнению с другими методами, требует лишь половины полосы пропускания. В то же время для каждого из этих кодов требования к полосе пропускания (и сложность системы) экспоненциально растут с увеличением М; так что подобные схемы кодирования годятся лишь тогда, когда доступна значительная полоса пропускания.
6.1.4. Примеры системы кодирования сигналов
На рис. 6.4 дается пример присвоения k-битовому сообщению из набора размером M = 2k кодированной последовательности импульсов из кодового набора аналогичного размера. Каждое из k-битовых сообщений выбирает один генератор, производящий кодированную последовательность или кодовое слово. Последовательности в кодированном наборе, заменяющие исходные сообщения, формируют набор сигналов с хорошими Пространственными характеристиками (например, ортогональный, биортогональный). Для ортогонального кода, описанного в разделе 6.1.3.1, каждое кодовое слово состоит из М = 2k импульсов (представляющих кодовые биты). Таким образом, 2k кодовых бит заменяют k информационных бит. Затем выбранная последовательность с использованием двоичной PSK модулируется несущей волной, так что фаза (φj = 0 или я) несущей волны в течение каждого интервала передачи кодированного бита, ![]() .соответствует амплитуде (j=-1 или 1) j-го биполярного импульса в кодовом слове. В приемнике, показанном на рис. 6.5, сигнал демодулируется и подается на М корреляторов (или согласованных фильтров). Для ортогональных кодов, таких как описаны в разделе 6.1.3.1 (которые определяются матрицей Ада-мара), за период передачи кодового слова (
.соответствует амплитуде (j=-1 или 1) j-го биполярного импульса в кодовом слове. В приемнике, показанном на рис. 6.5, сигнал демодулируется и подается на М корреляторов (или согласованных фильтров). Для ортогональных кодов, таких как описаны в разделе 6.1.3.1 (которые определяются матрицей Ада-мара), за период передачи кодового слова (![]() ) определяются корреляции принятого сигнала. Для систем связи реального времени сообщения не могут опаздывать, поэтому время передачи кодового слова должно совпадать е длительностью сообщения. Следовательно, T также можно выразить как
) определяются корреляции принятого сигнала. Для систем связи реального времени сообщения не могут опаздывать, поэтому время передачи кодового слова должно совпадать е длительностью сообщения. Следовательно, T также можно выразить как ![]() , где Тb — длительность битов сообщения. Отметим, что длительность бита сообщения в M/k раз больше, чем у кодового бита. Другими словами, кодовые биты или кодированные импульсы (сигналы PSK) должны перемещаться со скоростью, в M/k раз большей, чем биты сообщения. Для ортогонально кодированных сигналов и каналов с шумом AWGN математическое ожидание выходной мощности для каждого коррелятора в момент времени Т равно нулю; исключением является только коррелятор, соответствующий переданному кодовому слову.
, где Тb — длительность битов сообщения. Отметим, что длительность бита сообщения в M/k раз больше, чем у кодового бита. Другими словами, кодовые биты или кодированные импульсы (сигналы PSK) должны перемещаться со скоростью, в M/k раз большей, чем биты сообщения. Для ортогонально кодированных сигналов и каналов с шумом AWGN математическое ожидание выходной мощности для каждого коррелятора в момент времени Т равно нулю; исключением является только коррелятор, соответствующий переданному кодовому слову.
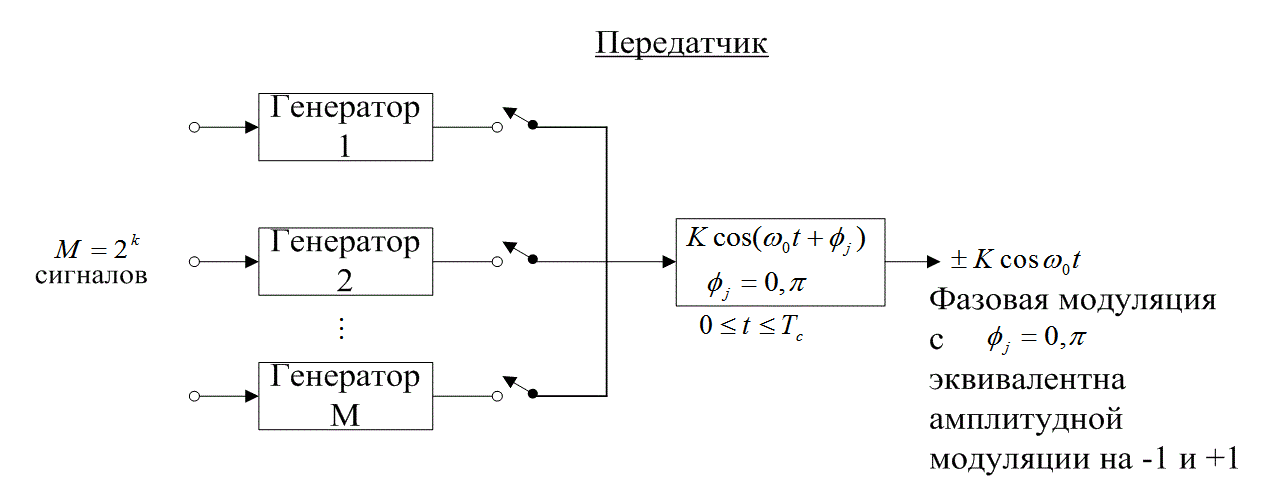
Рис. 6.4. Система кодирования сигналов (передатчик)
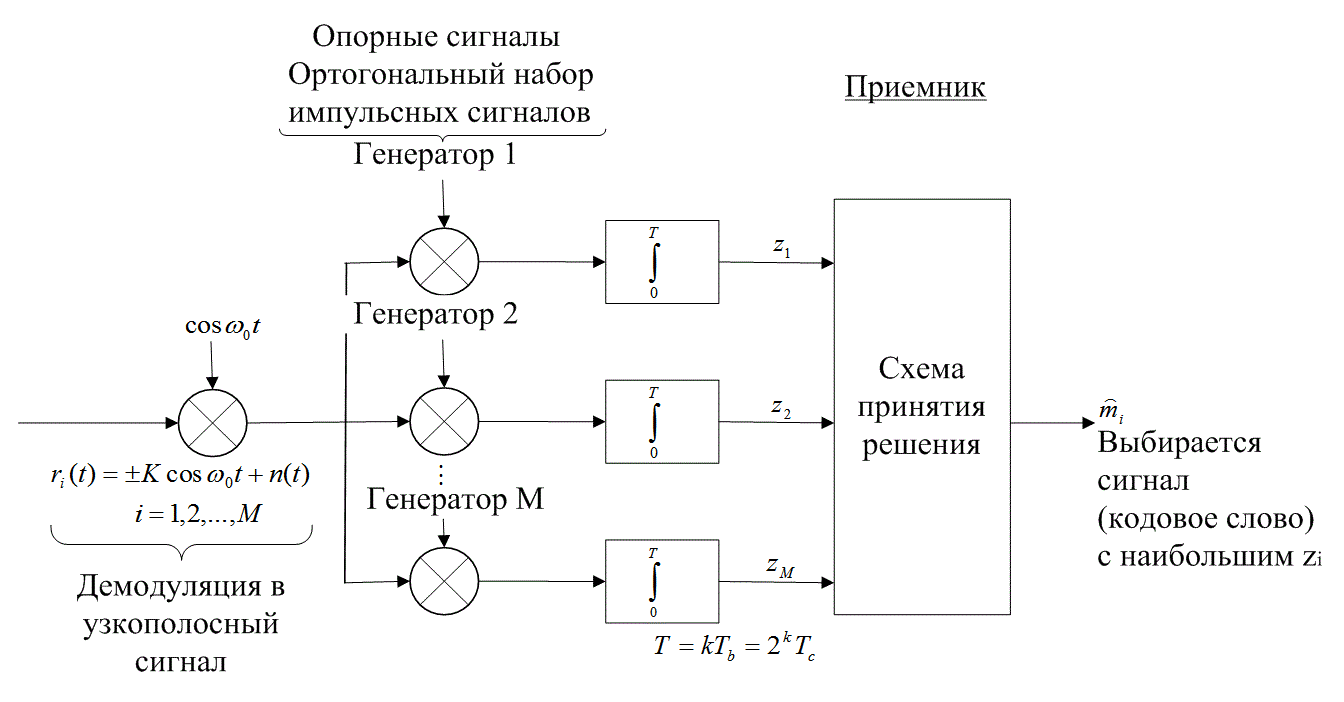
Рис. 6.5. Система кодирования сигналов с когерентным обнаружением (приемник)
Каковы преимущества описанного ортогонального кодирования сигналов по сравнению с обычным поступлением в каждую единицу времени одного бита или одного импульса? Можно оценить достоверность передачи с таким кодированием и без него, сравнив уравнение (4.79) для когерентного обнаружения антиподных сигналов с уравнением (6.7) для когерентного обнаружения ортогональных кодовых слов. При данном размере k-битового сообщения (скажем, k = 5) и желаемой вероятности появления ошибочного бита (например, 10-5), обнаружение ортогональных кодовых слов (каждое из которых состоит из 5 бит) может выполняться с приблизительно на 2,9 дБ меньшим отношением Eb/N0, чем побитовое обнаружение антиподных сигналов. (Проверить этот факт предоставляется читателю в качестве задачи 6.28.) Данный результат можно было предвидеть, сравнив рабочие характеристики ортогональной передачи сигналов на рис. 4.28 с характеристиками бинарной (антиподной) передачи на рис. 4.29. Чем мы платим за такой уровень достоверности передачи? Плата выражается в увеличении полосы пропускания. В приведенном примере передача некодированного сообщения — это посылка 5 бит. Сколько кодированных импульсов необходимо отправить для передачи с кодированием каждой последовательности сообщения? В данном примере каждая 5-битовая последовательность сообщения представлена М = 2k = 25 = 32 кодовыми битами или кодированными импульсами. 32 кодированных импульса, составляющих кодовое слово, нужно отправить за то же время, что и соответствующие исходные 5 бит. Таким образом, требуемая ширина полосы пропускания составляет 32/5 от ширины полосы пропускания в случае без кодирования. Вообще, полоса пропускания, необходимая для подобных ортогонально кодированных сигналов, в M/k раз больше требуемой в случае передачи без кодирования. Далее мы рассмотрим более выгодные и эффективные способы получения компромиссов между шириной полосы пропускания и схемой кодирования [3, 4].
6.2. Типы защиты от ошибок
Перед тем как начать обсуждение структурированной избыточности, рассмотрим два основных метода использования избыточности для защиты от ошибок. В первом методе, обнаружение ошибок и повторная передача, для проверки на наличие ошибки используется контрольный бит четности (дополнительный бит, присоединяемый к данным). При этом приемное оконечное устройство не предпринимает попыток исправить ошибку, оно просто посылает передатчику запрос на повторную передачу данных. Следует заметить, что для такого диалога между передатчиком и приемником необходима двухсторонняя связь. Второй метод, прямое исправление ошибок (forward error correction — FEC), требует лишь односторонней линии связи, поскольку в этом случае контрольный бит четности служит как для обнаружения, так и исправления ошибок. Далее мы увидим, что не все комбинации ошибок можно исправить, так что коды коррекции классифицируются в соответствии с их возможностями исправления ошибок.
6.2.1. Связность оконечных устройств
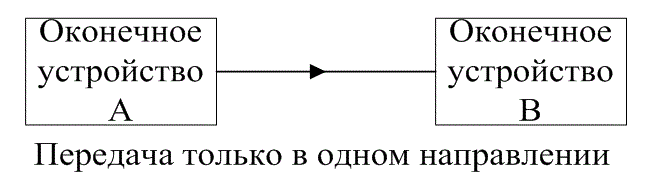
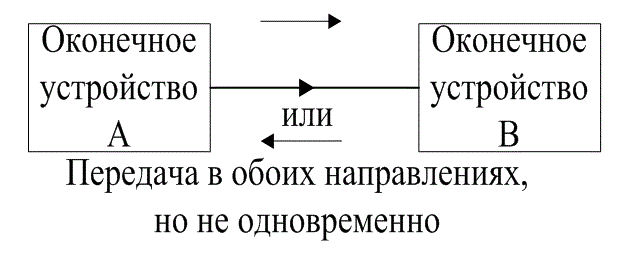
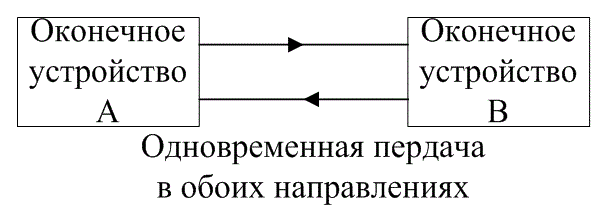
Оконечные устройства систем связи часто классифицируют согласно их связности с другими оконечными устройствами. Возможные типы соединения, показанные на рис. 6.6, называются симплексными (simplex) (не путайте с симплексными, или трансортогональными кодами), полудуплексными (half-duplex) и полнодуплексными (full-duplex). Симплексное соединение на рис. 6.6, а — это односторонняя линия связи.
Передача сигналов производится только от оконечного устройства А к оконечному устройству В. Полудуплексное соединение на рис. 6.6,б это линии связи, посредством которой можно осуществлять передачи сигналов в обоих направлениях, но не одновременно. И наконец, полнодуплексное соединение (рис. 6.6, в) — это двусторонняя связь, где передача сигналов происходит одновременно в обоих направлениях.
Передача только в одном направлении а)
а)
б)
в)
Рис. 6.6. Классификация связности оконечных устройств: а) симплексная; б) полудуплексная; в) полнодуплексная
6.2.2. Автоматический запрос повторной передачи
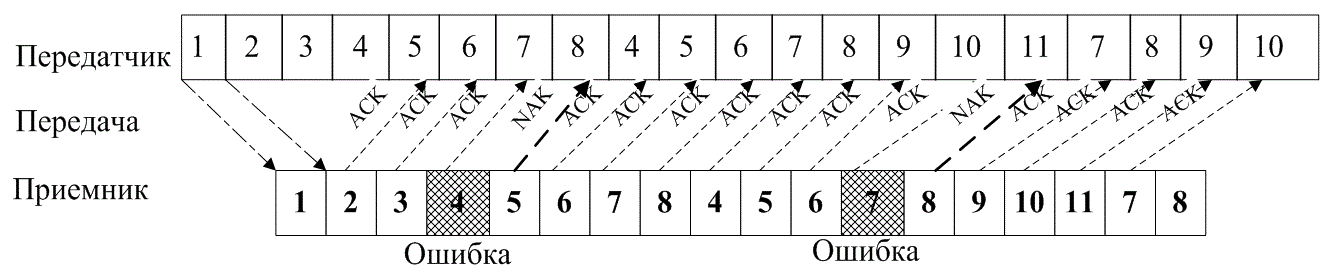
Если зашита от ошибок заключается только в их обнаружении, система связи должна обеспечить средства предупреждения передатчика об опасности, сообщающие, что была обнаружена ошибка и требуется повторная передача. Подобные процедуры защиты от ошибок известны как методы автоматического запроса повторной передачи (Automatic Repeat Request — ARQ). На рис. 6.7 показаны три наиболее распространенные процедуры ARQ. На каждой схеме ось времени направлена слева направо. Первая процедура ARQ, запрос ARQ с остановками (stop-and-wait ARQ), показана на рис. 6.7, а. Ее реализация требует только полудуплексного соединения, поскольку передатчик перед началом очередной передачи ожидает подтверждения об успешном приеме (acknowledgement — АСК) предыдущей. В примере, приведенном на рисунке, третий блок передаваемых данных принят с ошибкой. Следовательно, приемник передает отрицательное подтверждение приема (negative acknowledgment — NAK); передатчик повторяет передачу третьего блока сообщения и только после этого передает следующий по очередности блок. Вторая процедура ARQ, непрерывный запрос ARQ с возвратом (continuous ARQ with pullback), показана на рис. 6.7,б. Здесь требуется полно-дуплексное соединение. Оба оконечных устройства начинают передачу одновременно: передатчик отправляет информацию, а приемник передает подтверждение о приеме данных. Следует .отметить,„что каждому блоку передаваемых данных присваивается порядковый номер. Кроме того, номера кадров АСК и NAK должны быть согласованы; иначе говоря, задержка распространения сигнала должна быть известна априори, чтобы передатчик знал, к какому блоку сообщения относится данный кадр подтверждения приема. В примере на рис. 6,7,б время подобрано так, что между отправленным блоком сообщений и полученным подтверждением о приеме существует постоянный интервал в четыре блока. Например, после отправки сообщения 8, приводит сигнал NAK, сообщающий об ошибке в блоке 4. При использовании процедуры ARQ передатчик "возвращается" к сообщению с ошибкой и снова передает всю информацию, начиная с поврежденного сообщения. И наконец, третья процедура, именуемая непрерывным запросом ARQ с выборочным повторением (continuous ARQ with selective repeat), показана на рис. 6.7, в. Здесь, как и во второй процедуре, требуется полнодуплексное соединение. Впрочем, в этой процедуре повторно передается только искаженное сообщение; затем передатчик продолжает передачу с того места, где она прервалась, не выполняя повторной передачи правильно принятых сообщений.

а)
б)

в)
Рис. 6.7. Автоматический запрос повторной передачи (ARQ): а) запрос
ARQ с остановками (полудуплексная связь); б) непрерывный запрос ARQ с возвратом (полнодуплексная связь); в) непрерывный запрос ARQ с выборочным повторением (полнодуплексная связь)
Выбор конкретной процедуры ARQ является компромиссом между требованиями эффективности применения ресурсов связи и необходимостью полнодуплексной связи. Полудуплексная связь (рис. 6.7, а) требует меньших затрат, нежели полнодуплексная; в то же время она менее эффективна, что можно определить по количеству пустых временных интервалов. Более эффективная работа, показанная на рис. 6.7, б, требует более дорогой полнодуплексной связи.
Главное преимущество схем ARQ перед схемами прямого исправления ошибок (forward error correction — FEC) заключается в том, что "обнаружение ошибок требует более простого декодирующего оборудования и меньшей избыточности, чем коррекция ошибок. Кроме того, она гибче; информация передается повторно только при обнаружении ошибки. С другой стороны, метод FEC может оказаться более приемлемым (или дополняющим) по какой-либо из следующих причин.
1. Обратный канал недоступен или задержка при использовании ARQ слишком велика.
2. Алгоритм повторной передачи нельзя реализовать удобным образом.
3. При ожидаемом количестве ошибок потребуется слишком много повторных передач.
6.3. Структурированные последовательности
В разделе 4.8 мы рассмотрели цифровую передачу данных посредством M=2k сигналов (М-арная передача сигнала), где каждый сигнал содержит k бит информации. Было показано, что при ортогональной M-арной передаче сигналов уменьшения вероятности ошибки РB можно добиться путем увеличения М (расширения полосы пропускания). В разделе 6.1 мы показали, что РB можно уменьшить за счет кодирования k двоичных битов в одно из М ортогональных кодовых слов. Одним из основных недостатков ортогонального кодирования является неэффективное использование полосы пропускания. При наборе ортогональных кодов, включающем М=2k сигналов, требуемая ширина полосы пропускания в M/k раз больше необходимой для передачи некодированного сигнала. В этом и последующих разделах мы отойдем от рассмотрения ортогональных или антиподных свойств сигналов и сосредоточим внимание на классе процедур кодирования, известных как коды с контролем четности (parity-check codes). Эти процедуры канального кодирования относятся к структурированным последовательностям, поскольку они представляют методы введения в Исходные данные структурированной избыточности таким образом, что это позволяет обнаруживать или исправлять ошибки. Как показано на рис. 6.1, структурированные последовательности делятся на три подкатегории: блочные, сверточные и турбокоды. Блочное кодирование рассматривается в этой главе, а другие описываются в главах 7 и 8.
6.3.1. Модели каналов
6.3.1.1. Дискретный канал без памяти
Дискретный канал без памяти (discrete memoryless channel — DMC) характеризуется дискретным входным алфавитом, дискретным выходным алфавитом и набором условных вероятностей ![]() где i представляет модулятор M-арного входного символа, j — демодулятор Q-арного выходного символа, a P(i\j) — это вероятность приема символа j при переданном символе i. Каждый выходной символ канала зависит только от соответствующего входного символа, так что для данной входной последовательности
где i представляет модулятор M-арного входного символа, j — демодулятор Q-арного выходного символа, a P(i\j) — это вероятность приема символа j при переданном символе i. Каждый выходной символ канала зависит только от соответствующего входного символа, так что для данной входной последовательности ![]() условную вероятность соответствующей выходной последовательности Z = z1,z2,...,zm,..., zn можно записать следующим образом.
условную вероятность соответствующей выходной последовательности Z = z1,z2,...,zm,..., zn можно записать следующим образом.
![]() (6.12)
(6.12)
Если же канал имеет память (т.е. в пакете данных имеются помехи или канал подвергается воздействию замирания), условную вероятность последовательности Z нужно выражать как совместную вероятность всех элементов последовательности. Уравнение (6.12) — это условие отсутствия памяти у канала. Поскольку считается, что шум в канале без памяти влияет на каждый символ независимо от других, то в этом случае условная вероятность Z является произведением вероятностей независимых элементов.
6.3.1.2. Двоичный симметричный канал
Двоичный симметричный канал (binary symmetric channel — BSC) является частным случаем дискретного канала без памяти, входной и выходной алфавиты которого состоят из двоичных элементов (0 и 1). Условные вероятности имеют симметричный вид.
![]()
и (6.13)
![]()
Уравнение (6.13) выражает так называемые вероятности перехода. Иными словами, при передаче канального символа вероятность принятия его с ошибкой равна р (относительно значения энергии), а вероятность того, что он передан без ошибки, — (1-р). Поскольку на выход демодулятора поступают дискретные элементы 0 или 1, говорят, что по отношению к каждому символу демодулятор принимает жесткое решение (hard decision). Рассмотрим наиболее распространенную схему кодирования — данные в формате BPSK плюс демодуляция по принципу жесткого решения. Вероятность появления ошибки в канальном символе находится с использованием метода, обсуждавшегося в разделе 4.7.1, и дается уравнением (4.79).
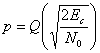
Здесь EJN0 — отношение энергии канального символа к плотности помех, а функция Q(x) была определена в уравнении (3.43).
Если описанная схема жестких решений применяется в системах с бинарными кодировками, то с демодулятора на декодер поступают двоичные кодовые символы или биты канала. Поскольку декодер работает на основе жестких решений, определяемых демодулятором, декодирование в двоичном симметричном канале называется также жестким декодированием.
6.3.1.3. Гауссов канал
Определение двоичного симметричного канала можно использовать и для каналов с недискретным алфавитом. Пример — гауссов канал с дискретным входным алфавитом и непрерывным выходным алфавитом, лежащим в диапазоне (![]() ). Этот канал добавляет шум ко всем передаваемым символам. Поскольку шум — это гауссова случайная переменная с нулевым средним и дисперсией σ2, результирующую функцию плотности вероятности принятой случайной величины z при условии передачи символа uk (правдоподобие uk) можно записать следующим образом.
). Этот канал добавляет шум ко всем передаваемым символам. Поскольку шум — это гауссова случайная переменная с нулевым средним и дисперсией σ2, результирующую функцию плотности вероятности принятой случайной величины z при условии передачи символа uk (правдоподобие uk) можно записать следующим образом.
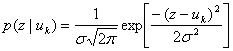 (6.14)
(6.14)
для всех z, где k = 1,2,..., М.
В этом случае отсутствие памяти имеет то же значение, что и в разделе 6.3.1.1, а само уравнение (6.12) можно использовать при вычислении условной вероятности для последовательности Z.
Если на выходе демодулятора находится непрерывный алфавит или его квантовое приближение (с более чем двумя квантовыми уровнями), говорят, что демодулятор принимает мягкое решение (soft decision). Если в системе используется кодирование, демодулятор подает такие квантовые кодовые символы на декодер. Поскольку декодер работает на основе мягких решений, определяемых демодулятором, декодирование в гауссовом канале называется мягким.
В канале с жестким решением процесс обнаружения можно описать через вероятность символьной ошибки. Но в канале с мягкими решениями выбор детектора нельзя однозначно отнести к верному или неверному. Таким образом, поскольку определенного решения не существует, не может быть и выражения для вероятности ошибки; детектор может только определять семейство условных вероятностей или правдоподобий разных типов символов.
В принципе, декодеры с мягкими решениями можно сделать, но для блочных кодов они будут значительно сложнее декодеров с жесткими решениями; поэтому, как правило, блочные коды реализуются в системах с декодерами, работающими по принципу жесткого решения. Для свёрточных кодов реализация и жестких, и мягких решений одинаково популярна. В этой главе мы предполагаем, что каналы являются двоичными симметричными и, следовательно, декодеры используют жесткие решения. В главе 7 мы перейдем к обсуждению жесткого и мягкого декодирования для свёрточных кодов, а также продолжим обсуждение моделей канала.
6.3.2. Степень кодирования и избыточность
При использовании блочных кодов исходные данные делятся на блоки из k бит, которые иногда называют информационными битами, или битами сообщения; каждый блок может представлять любое из 2k отдельных сообщений. В процессе кодирования каждый k-битовый блок данных преобразуется в больший блок из п бит, который называется кодовым битом, или канальным символом. К каждому блоку данных кодирующее устройство прибавляет (n - k) бит, которые называются избыточными битами (redundant bits), битами четности (parity bits), или контрольными битами (check bits); новой информации они не несут. Для обозначения описанного кода используется запись (n, k). Отношение числа избыточных бит к числу информационных бит, (n - k)/k, называется избыточностью (redundancy) кода; отношение числа бит данных к общему числу бит, k/n, именуется степенью кодирования (code rate). Под степенью кодирования подразумевается доля кода, которая приходится на полезную информацию. Например, в коде со степенью 1/2, каждый кодовый бит несет 1/2 бит информации.
В этой главе и в главах 7 и 8 мы рассмотрим методы кодирования, получающие избыточность за счет увеличения необходимой ширины полосы. Например, метод защиты от ошибок, использующий код со степенью 1/2 (100%-ная избыточность), будет требовать двойной, по сравнению с некодированной передачей, полосы пропускания. В то же время, если использовать код со степенью 3/4, то избыточность составит 33%, и увеличение полосы пропускания будет всего 4/3. В главе 9 мы рассмотрим методы модуляции/кодирования для узкополосных каналов, где защита от ошибок происходит не за счет увеличения полосы пропускания, а за счет усложнения метода (и, как следствие, его аппаратной реализации).
6.3.2.1. Терминология в кодировании
Разные авторы по-разному называют элементы на выходе кодирующего устройства: кодовые биты (code bits), канальные биты (channel bits), кодовые символы (code symbols), канальные символы (channel symbols), биты четности (parity bits), символы четности (parity symbols). Вообще, по смыслу эти термины очень похожи между собой. В этой книге для двоичных кодов .термины "кодовые биты", "канальные биты", "кодовые символы" и "канальные символы" употребляются как синонимы. Следует уточнить, что названия "кодовые биты" и "канальные биты" подходят для описания только двоичных кодов. Такие общие названия, как "кодовые символы" и "канальные символы", зачастую более предпочтительны, поскольку они могут означать как двоичное, так и любое другое кодирование. Отметим, что эти понятия не следует путать с тем, что получается при группировке битов в передаваемые символы, о которых шла речь в предыдущей главе. Термины "биты четности" k "символы четности" применяются только к тем составляющим кода; которые представляют избыточные компоненты, прибавляемые к исходным данным.
6.3.3. Коды с контролем четности
6.3.3.1. Код с одним контрольным битом
Коды с контролем четности (parity-check code) для обнаружения или исправления ошибок используют линейные суммы информационных битов, которые называются символами (parity symbols), или битами четности (parity bits). Код с одним контрольным битом — это прибавление к блоку информационных битов одного контрольного бита. Этот бит (бит четности) может быть равен нулю или единице, причем его значение выбирается так, чтобы сумма всех битов в кодовом слове была четной или нечетной. В операции суммирования используется арифметика по модулю 2 (операция исключающего ИЛИ), описанная в разделе 2.9.3. Если бит четности выбран так, что результат четный, то говорят, что схема имеет положительную четность (even parity); если при добавлении бита четности результирующий блок данных является нечетным, то говорят, что он имеет отрицательную четность (odd parity). На рис. 6.8, а показана последовательная передача данных (первым является крайний справа бит). К каждому блоку добавляется один бит четности (крайний слева бит в каждом блоке), дающий положительную Четность.
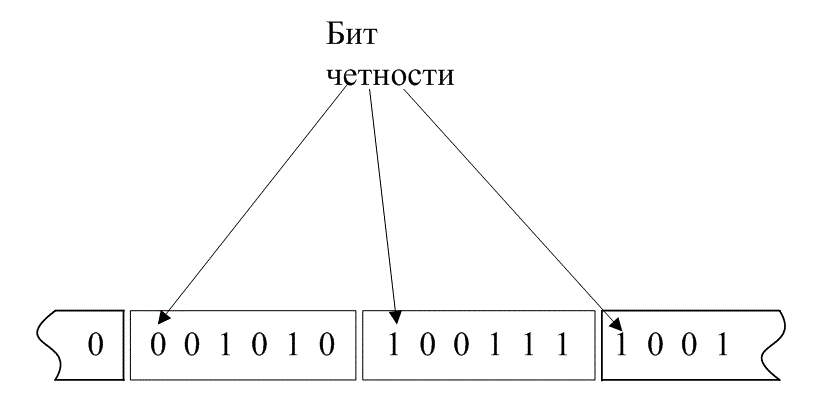
а)

б)
Рис. 6.8. Проверка четности для последовательной и параллельной структуры кода: а) последовательная структура; б) параллельная структура
В приемном оконечном устройстве производится декодирование, заключающееся в проверке, дают ли нуль суммы принятых битов кодового слова по модулю 2 (положительная четность). Если полученный результат равен 1, то кодовое слово заведомо содержит ошибки. Степень кодирования такого кода можно записать как k/(k + 1). Как вы думаете, может ли декодер автоматически исправить цифру, полученную с ошибкой? Нет, это невозможно. Можно только обнаружить, что в кодовом символе присутствует нечетное количество ошибок. (Если ошибка была внесена в четное число битов, то проверка четности покажет отсутствие ошибок; данный случай — это пример необнаруженной ошибки.) Предполагая, что ошибки во всех разрядах равновероятны и появляются независимо, можно записать вероятность появления у ошибок в блоке, состоящем из я символов.
![]() (6.15)
(6.15)
Здесь р — вероятность получения канального символа с ошибкой, а через
![]() (6.16)
(6.16)
— обозначается число различных способов выбора из и бит j ошибочных. Таким образом, для кода с одним битом четности вероятность необнаруженной ошибки Рnd в блоке из п бит вычисляется следующим образом.
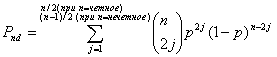 (6.17)
(6.17)
Пример 6.1. Код положительной четности
Нужно создать код обнаружения ошибок (4, 3) положительной четности, причем символ четности должен располагаться на крайней левой позиции кодового слова. Какие ошибки может обнаружить код? Вычислите вероятность необнаруженной ошибки сообщения, предполагая, что все символьные ошибки являются независимыми событиями и вероятность ошибки в канальном символе равна р = 10-3.
Решение
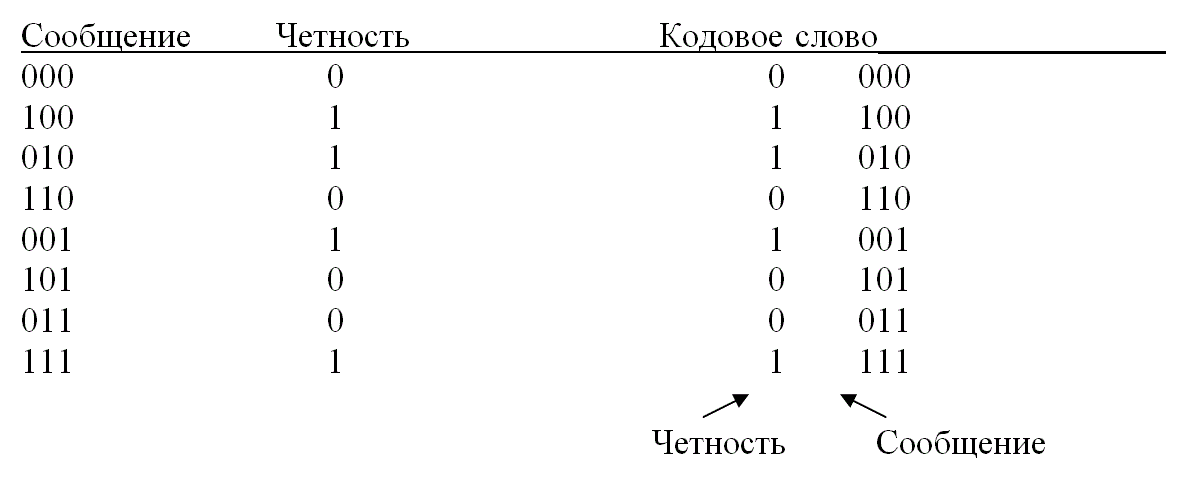
Код может выявлять все комбинации с одной или тремя ошибками. Вероятность необнаруженной ошибки равна вероятности появления где-либо в кодовом слове двух или четырех ошибок.
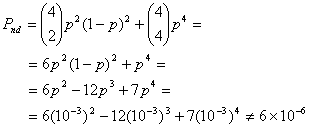
6.3.3.2. Прямоугольный код
Прямоугольный код (rectangular code), называемый также композиционным (product code), можно представить в виде параллельной структуры кода, изображенной на рис. 6.8, б. Код создается следующим образом. Вначале из битов сообщения строятся прямоугольники, состоящие из М строк и N столбцов; затем к каждой строке и каждому столбцу прибавляется бит четности, что в результате дает матрицу размером (М+ 1) х (N+1). Степень кодирования прямоугольного кода, k/n, может быть записана следующим образом.
![]()
Насколько прямоугольный код мощнее кода, который имеет один контрольный бит и предоставляет только возможность обнаружить ошибку? Отметим, что любая отдельная ошибка в разряде приведет к нарушению четности в одном столбце и в одной из строк матрицы. Следовательно, прямоугольный код может исправить любую единичную ошибку, поскольку расположение такой ошибки однозначно определяется пересечением строки и столбца, в которых была нарушена четность. В примере, показанном на рис. 6.8, б, размеры матрицы равны М= N = 5; следовательно, на рисунке отображен код (36, 25), способный исправлять единичные ошибки, расположенные, в любом из 36 двоичных разрядов. Вычислим для такого блочного кода с коррекцией ошибок вероятность появления неисправленной ошибки, для чего учтем все способы появления ошибки сообщения. Исходя из вероятности наличия j ошибок в блоке из п символов, записанной в выражении (6.5), можно записать вероятность ошибки сообщения, называемой также блочной ошибкой или ошибочным словом, для кода, который может исправить ошибочные комбинации, состоящие из t или менее ошибочных битов.
![]() (6-18)
(6-18)
Здесь р — вероятность получения ошибочного канального символа. В примере на рис. 6.8, б код может исправить все однобитовые ошибки (t = 1) в прямоугольном блоке, состоящем из n = 36 бит. Следовательно, суммирование в уравнении (6.18) начинается с j = 2.
![]()
При достаточно малом р, наибольший вклад дает первое слагаемое суммы. Следовательно, для примера с прямоугольным кодом (36, 25) можно записать следующее.
![]()
Точная вероятность битовой ошибки РВзависит от конкретного кода и используемого декодера. Приближенные значения РB приводятся в разделе 6.5.3.
6.3.4. Зачем используется кодирование с коррекцией ошибок?
Кодирование с коррекцией ошибок можно рассматривать как инструмент, реализующий различные компромиссы системы. На рис. 6.9 приведен сравнительный вид двух кривых, описывающих зависимость достоверности передачи от отношения Eb/N0 Одна кривая соответствует обычной схеме модуляции без кодирования, а вторая представляет такую же модуляцию, но уже с использованием кодирования; Ниже подробно рассмотрено четыре компромисса, имеющие место при канальном кодировании.
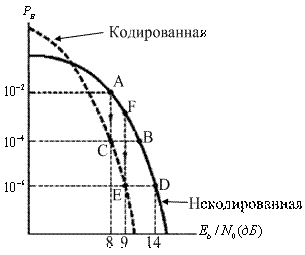
Рис. 6.9. Сравнение типичной достоверности передачи при использовании схемы с кодированием и схемы без кодирования
6.3.4.1. Компромисс 1: достоверность или полоса пропускания
Представим себе, что разработана простая, недорогая система речевой связи, которая была установлена у заказчика. Система не использует кодирование с коррекцией ошибок. Пусть рабочая точка системы совпадает с точкой А на рис. 6.9 (Eb/N0 = 8 дБ, РВ - 10-2). После нескольких испытаний у заказчика появляются жалобы на качество связи; Он полагает, что вероятность появления битовой ошибки должна быть не выше 10-4. Обычным способом удовлетворения требования заказчика является сдвиг рабочей точки из точки А, например, в точку В (рис. 6.9). В то же время допустим, что Eb/N0, равное 8 дБ, — это максимальное значение, возможное в данной системе. Из рис. 6.9 видим, что один из возможных выходов из ситуации (компромиссов) — это сдвиг рабочей точки из точки А в точку С. Иными словами, "съехав" по вертикали вниз в точку С на кривой, отвечающей кодированному случаю, можно предоставить заказчику более высокую достоверность передачи данных. Чего это будет стоить? Помимо введения новых компонентов (кодера и декодера), это приведет к увеличению необходимой полосы пропускания. Кодирование с коррекцией ошибок требует избыточности. Если предположить, что связь будет происходить в реальном времени (так что сообщения не могут задерживаться), добавление избыточных битов потребует увеличения, скорости передачи и, конечно же, большей полосы пропускания.
6.3.4.2. Компромисс 2: мощность или полоса пропускания
Допустим, заказчику установлена система без кодирования £ рабочей точкой, совпадающей с точкой D на рис. 6.9 (Eb/N0 = 14 дБ, РB = 10-6). Заказчик не имеет претензий к качеству связи, но с помощью данного оборудования затруднительно получить требуемые Eb/N0 = 14 дБ. Иными словами, оборудование постоянно работает на грани отказа. Если снизить требования к Eb/N0 или мощности, то проблем с надежностью оборудования можно избежать. В контексте рис. 6.9 данные меры выглядят как сдвиг рабочей т,очки из D в E. Другими, словами, требуемое значение Eb/N0 можно получить, если применить кодирование с коррекцией ошибок. Таким образом, при фиксированном качестве связи компромисс заключается в получении большей производительности при снижении требований к мощности или Eb/N0. Чем за это приходится платить? Тем же, чем и в прошлый раз, — большей полосой пропускания.
Заметим, что в системах, где не используется связь в реальном времени, применение кодирования с коррекцией ошибок даст несколько отличные результаты. Повышение достоверности передачи или понижение потребляемой мощности (подобное описанным выше случаям 1 или 2) будет достигаться за счет увеличения времени задержки, а не за счет расширения полосы пропускания.
6.3.4.3. Эффективность кодирования
Пример компромиссных решений, рассмотренный в предыдущем разделе, позволяет понизить Eb/N0 с 14 до 9 дБ при поддержании той же достоверности передачи. В контексте этого примера и с помощью рис. 6.9 мы можем ввести понятие эффективность кодирования (coding gain). Итак, при данной вероятности битовой ошибки эффективность кодирования определяется как уменьшение Eb/N0, которое достигается при использовании кодирования. Эффективность кодирования G, как правило, выражается в децибелах.
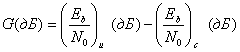 (6.19)
(6.19)
Здесь (Eb/N0)u и (Eb/N0)с— требуемые некодированное и кодированное значения.
6.3.4.4. Компромисс 3: скорость передачи данных или полоса пропускания
Пусть разработана система без кодирования с рабочей точкой, совпадающей с точкой D на рис. 6.9 (Eb/N0 = 14 дБ, РB =10-6). Допустим, что с качеством данных нет никаких проблем и нет особой нужды в снижении мощности. Однако у заказчика возросли требования к скорости передачи данных. Напомним в связи с этим уравнение (5.20,6).
Если в системе ничего не менять, кроме скорости передачи данных R, то из приведенного выше выражения видно, что это приведет к уменьшению значения Eb/N0 и перемещению рабочей точки вверх, например из точки D в некоторую точку F. А теперь представим, что она "съезжает" вниз по вертикали в точку Е на кривую, которая представляет кодированную модуляцию. Возрастание скорости передачи данных плохо отражается на качестве их передачи. В то же время применение кодирования с коррекцией ошибок восстанавливает утраченное качество, сохраняя при этом прежний уровень мощности (Pr/N0). Итак, значение Eb/N0 понижено, но код способствует получению той же вероятности ошибки при сниженном значении Eb/N0. Какова цена такого увеличения скорости передачи данных или увеличения емкости? Как и раньше, это увеличение полосы пропускания.
6.3.4.5. Компромисс 4: пропускная способность или ширина полосы пропускания
Компромисс 4 сходен с компромиссом 3 в том, что оба дают возрастание пропускной способности. Метод множественного доступа, именуемый множественным доступом с кодовым разделением каналов (code-division multiple access — CDMA), который описывается в главе 12, — это один из стандартов, используемых в сотовой связи. При CDMA, когда все клиенты совместно используют общий спектр частот, каждый клиент является источником помех для других пользователей в той же ячейке или соседних. Поэтому пропускная способность (максимальное число клиентов) ячейки обратно пропорциональна значению Eb/N0 (см. раздел 12.8). При этом снижение Eb/N0 дает в итоге увеличение пропускной способности; код позволяет снизить мощности, используемые каждым клиентом, что, в свою очередь, приводит к увеличению общего числа клиентов. И снова платой за это является увеличение полосы пропускания. Но в этом случае увеличение полосы сигнала, получаемое при переходе к кодированию с коррекцией ошибок, незначительно, по сравнению с существенным увеличением полосы пропускания, получаемым при расширении спектра сигнала; поэтому при передаче данных оно не оказывает влияния на полосу пропускания.
В каждом из упомянутых выше компромиссов предполагалось использование "традиционного" кода с избыточными битами и более быстрая передача сигналов (для систем связи реального времени); следовательно, в каждом случае платой было расширение полосы передачи. В то же время существуют методы коррекции ошибок, называемые решетчатым кодированием (trellis-coded modulation), которые не требуют увеличения скорости передачи сигналов или расширения полосы частот для систем связи реального времени. (Эти методы рассмотрены в разделе 9.10.)
Пример 6.2. Связь вероятности ошибки с использованием кодирования
Сравните вероятность ошибки в сообщении для двух каналов связи — обычного и использующего кодирование с коррекцией ошибок. Пусть некодированная передача имеет следующие характеристики: модуляция BPSK, гауссов шум, Pr/N0 = 43 776, скорость передачи данных R — 4800 бит/с. Для случая с кодированием предполагается использование кода с коррекцией ошибок (15, 11), предоставляющего возможность исправления любых однобитовых ошибочных комбинаций кода в блоке из 15 бит. Будем считать, что демодулятор принимает жесткие решения и передает демодулированный код прямо на декодер, который, в свою очередь, определяет исходное сообщение.
Решение
Используем уравнение (4.79). Пусть ![]() и
и ![]() —вероятности символьных ошибок в канале без кодирования и в канале с кодированием, где
—вероятности символьных ошибок в канале без кодирования и в канале с кодированием, где ![]() — отношение энергии бита к спектральной плотности мощности шума, a
— отношение энергии бита к спектральной плотности мощности шума, a ![]() — отношение энергии кодированного бита к спектральной плотности мощности шума.
— отношение энергии кодированного бита к спектральной плотности мощности шума.
Без кодирования
![]()
и
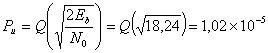 (6.20)
(6.20)
Для Q(x) используется следующее приближение, приведенное в уравнении (3.44).
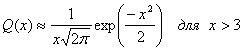
Вероятность того, что некодированный блок сообщений ![]() будет принят с ошибкой, равна 1 минус произведение вероятностей того, что каждый бит будет обнаружен правильно. Таким образом,
будет принят с ошибкой, равна 1 минус произведение вероятностей того, что каждый бит будет обнаружен правильно. Таким образом,
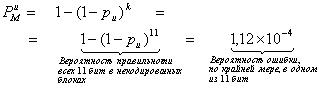 (6.21)
(6.21)
С кодированием
Допустим, рассматриваемая система — это система связи реального времени, где задержки недопустимы, а скорость передачи канальных символов, или скорость передачи кодированных битов, равна Rc = 15/11 скорости некодированной передачи.
![]()
и
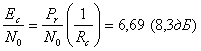
Для каждого кодового бита значение ![]() меньше, чем в случае с некодированными битами данных. Это объясняется тем, что скорость передачи канальных битов возросла, а мощность передатчика при этом не изменилась.
меньше, чем в случае с некодированными битами данных. Это объясняется тем, что скорость передачи канальных битов возросла, а мощность передатчика при этом не изменилась.
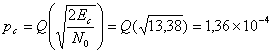 (6.22)
(6.22)
Сравнивая выражения (6.20) и (6.22), можно видеть, что вследствие внесения избыточности вероятность ошибки в канальном бите уменьшилась. За то же время и с теми же номинальными мощностями нужно обнаружить большее число бит; повышение производительности в результате кодирования еще не очевидно. Вычислим теперь с помощью уравнения (6.18) частоту появления ошибок в кодированном сообщении Рсм.
Суммирование начинается с j = 2, поскольку код позволяет исправлять все однобитовые ошибки в блоках из n = 15 бит. Достаточно хорошее приближение можно получить, используя только первый член суммы. Для рс используем значение, полученное из уравнения (6.22).
![]() (6.23)
(6.23)
Сравнивая выражения (6.21) и (6.23), можно видеть, что вследствие применения кода с коррекцией ошибок вероятность ошибки сообщения была уменьшена примерно в 58 раз. Данный пример иллюстрирует типичное поведение систем связи реального времени при использовании кодирования с коррекцией ошибок. Введение избыточности означает увеличение скорости передачи сигналов, уменьшение энергии, приходящейся на канальный символ, и увеличение числа ошибок вне демодулятора. Преимуществом такого подхода является то, что декодер (при разумном значении ![]() ) позволяет с лихвой компенсировать слабую производительность демодулятора.
) позволяет с лихвой компенсировать слабую производительность демодулятора.
6.3.4.6. Характеристики кода при низком значении 
В конце данной главы читателю предлагается решить задачу 6.5, сходную с примером 6.2. В п. а задачи 6.5, где значение ![]() принимается равным 14 дБ, кодирование дает повышение достоверности передачи сообщения. В то же время в п. б, где значение
принимается равным 14 дБ, кодирование дает повышение достоверности передачи сообщения. В то же время в п. б, где значение ![]() снижается до 10 дБ, кодирование не дает улучшения; фактически происходит ухудшение. Может возникнуть вопрос, почему в п. б происходит такое ухудшение? По сути, в обоих пунктах задачи применяется одна и та же процедура. Ответ можно найти на рис. 6.9, который наглядно показывает связь между кодированными и некодированными вероятностями ошибки. Хотя в задаче 6.5 речь идет о вероятности ошибки сообщения, а на рис. 6.9 приведен график битовой ошибки, следующее объяснение остается в силе. Итак, на подобных графиках кривые пересекаются (как правило, при низких значениях
снижается до 10 дБ, кодирование не дает улучшения; фактически происходит ухудшение. Может возникнуть вопрос, почему в п. б происходит такое ухудшение? По сути, в обоих пунктах задачи применяется одна и та же процедура. Ответ можно найти на рис. 6.9, который наглядно показывает связь между кодированными и некодированными вероятностями ошибки. Хотя в задаче 6.5 речь идет о вероятности ошибки сообщения, а на рис. 6.9 приведен график битовой ошибки, следующее объяснение остается в силе. Итак, на подобных графиках кривые пересекаются (как правило, при низких значениях ![]() ). Смысл этого пересечения (порога) в том, что у всех систем кодирования имеется ограниченная способность к коррекции ошибок. Если в блоке имеется больше ошибок, чем способен исправить код, система будет работать плохо. Представим себе, что значение
). Смысл этого пересечения (порога) в том, что у всех систем кодирования имеется ограниченная способность к коррекции ошибок. Если в блоке имеется больше ошибок, чем способен исправить код, система будет работать плохо. Представим себе, что значение ![]() снижается непрерывно. Что мы увидим на выходе демодулятора? Демодулятор будет допускать все больше и больше ошибок. Следовательно, такое постепенное уменьшение
снижается непрерывно. Что мы увидим на выходе демодулятора? Демодулятор будет допускать все больше и больше ошибок. Следовательно, такое постепенное уменьшение ![]() должно в конце концов создать пороговую ситуацию, когда декодер будет переполнен ошибками. При достижений этого порога снижение производительности можно объяснить поглощением энергии избыточными битами, которые не дают никакого выигрыша. Не удивляет ли читателя то, что в области (низких значений
должно в конце концов создать пороговую ситуацию, когда декодер будет переполнен ошибками. При достижений этого порога снижение производительности можно объяснить поглощением энергии избыточными битами, которые не дают никакого выигрыша. Не удивляет ли читателя то, что в области (низких значений ![]() ), где больше всего следовало бы ожидать улучшения достоверности передачи, код имеет наименьшую эффективность? Впрочем, существует класс мощных кодов, называемых турбокодами (turbo code), которые позволяют повысить надежность передачи при низких значениях
), где больше всего следовало бы ожидать улучшения достоверности передачи, код имеет наименьшую эффективность? Впрочем, существует класс мощных кодов, называемых турбокодами (turbo code), которые позволяют повысить надежность передачи при низких значениях ![]() ; у турбо-кодов точка пересечения графиков находится значительно ниже, чем у сверточных кодов. (Турбокоды рассматриваются в разделе 8.4.)
; у турбо-кодов точка пересечения графиков находится значительно ниже, чем у сверточных кодов. (Турбокоды рассматриваются в разделе 8.4.)
6.4. Линейные блочные коды
Линейные блочные коды (подобные коду, описанному в примере 6.2) — это класс кодов с контролем четности, которые можно описать парой чисел (п, k) (объяснение этой формы записи приводилось выше). В процессе кодирования блок из k символов сообщения (вектор сообщения) преобразуется в больший блок из п символов кодового слова (кодовый вектор), образованного с использованием элементов данного алфавита. Если алфавит состоит только из двух элементов (0 и 1), код является двоичным и включает двоичные разряды (биты). Если не будет оговорено противное, наше последующее обсуждение линейных блочных кодов будет подразумевать именно двоичные коды.
k-битовые сообщения формируют набор из 2k последовательностей сообщения, называемых k-кортежами (k-tuple) (последовательностями k цифр), k-битовые блоки могут формировать 2n последовательности, также именуемые k-кортежами. Процедура кодирования сопоставляет с каждым из 2k Л-кортежей сообщения один из 2k л-кортежей. Блочные коды представляют взаимно однозначное соответствие, в силу чего 2k k-кортежей сообщения однозначно отображаются в множество из 2k л-кортежей кодовых слов; отображение производится согласно таблице соответствия. Для линейных кодов преобразование отображения является, конечно же, линейным.
6.4.1. Векторные пространства
Множество всех двоичных n-кортежей, Vn, называется векторным пространством над двоичным полем двух элементов (0 и 1). В двоичном поле определены две операции, сложение и умножение, причем результат этих операций принадлежит этому же множеству двух элементов. Арифметические операции сложения и умножения определяются согласно обычным правилам для алгебраического поля [4]. Например, в двоичном поле правила сложения и умножения будут следующими.
Сложение Умножение
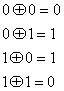
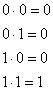
Операция сложения, обозначаемая символом “![]() ”, — это та же операция сложения по модулю 2, которая описывалась в разделе 2.9.3. Суммирование двоичных n-кортежей всегда производится путем сложения по модулю 2. Хотя для простоты мы чаще будем использовать для этой операции обычный знак +.
”, — это та же операция сложения по модулю 2, которая описывалась в разделе 2.9.3. Суммирование двоичных n-кортежей всегда производится путем сложения по модулю 2. Хотя для простоты мы чаще будем использовать для этой операции обычный знак +.
6.4.2. Векторные подпространства
Подмножество S векторного пространства Vn называется подпространством, если для него выполняются следующие условия.
1. Множеству S принадлежит нулевой вектор.
2. Сумма любых двух векторов в S также принадлежит S (свойство замкнутости).
При алгебраическом описании линейных блочных кодов данные свойства являются фундаментальными. Допустим, Vi и Vj — два кодовых слова (или кодовых вектора) в двоичном блочном коде (n, k). Код называется линейным тогда и только тогда, когда (Vi ![]() Vj) также является кодовым вектором. Линейный блочный код — это такой код, в котором вектор, не принадлежащий подпространству, нельзя получить путем сложения любых кодовых слов, принадлежащих этому подпространству.
Vj) также является кодовым вектором. Линейный блочный код — это такой код, в котором вектор, не принадлежащий подпространству, нельзя получить путем сложения любых кодовых слов, принадлежащих этому подпространству.
Например, векторное пространство V4 состоит из следующих шестнадцати 4-кортежей.
0000 0001 0010 0011 0100 0101 0110 0111
1000 1001 1010 1011 1100 1101 1110 1111
Примером подмножества V4, являющегося подпространством, будет следующее.
0000 0101 1010 1111
Легко проверить, что сложение любых двух векторов подпространства может дать в итоге лишь один из векторов подпространства. Множество из 2k n-кортежей называется линейным блочным кодом тогда и только тогда, когда оно является подпространством векторного пространству Vn всех n-коргежей. На рис. 6.10 показана простая геометрическая аналогия, представляющая структуру линейного блочного кода. Векторное пространство Vn можно представить как составленное из 2n n-кортежей. Внутри этого векторного пространства существует подмножество из 2k л-кортежей, образующих подпространство. Эти 2k вектора или точки показаны разбросанными среди более многочисленных 2n точек, представляющих допустимые или возможные кодовые слова. Сообщение кодируется одним из 2k возможных векторов кода, после чего передается. Вследствие наличия в канале шума приниматься может измененное кодовое слово (один из 2n векторов пространства n-кортежей). Если измененный вектор не слишком отличается (лежит на небольшом расстоянии) от действительного кодового слова, декодер может обнаружить сообщение правильно. Основная задача выбора конкретной части кода подобна цели выбора семейства модулирующих сигналов, и в контексте рис. 6.10 ее можно определить следующим образом.
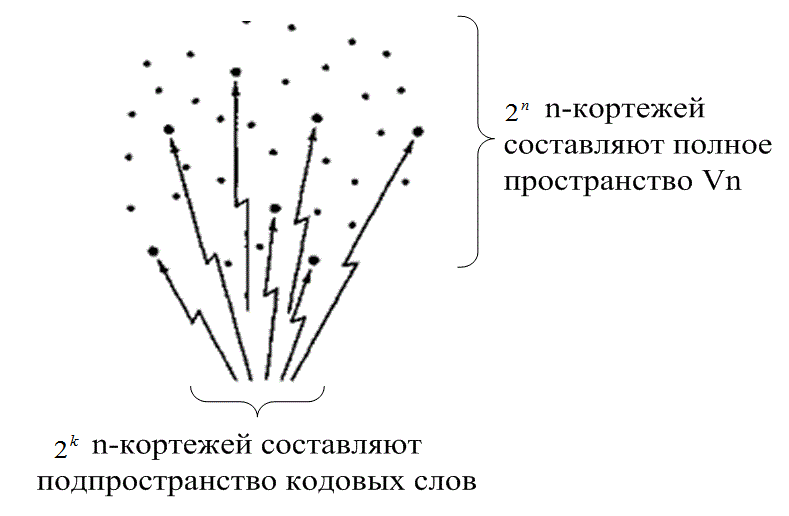
Рис. 6.10. Структура линейного блочного кода
1. Наполняя пространство Vn максимальным количеством кодовых слов, мы боремся за эффективность кодирования. Это равносильно утверждению, что мы хотим ввести лишь небольшую избыточность (избыток полосы).
2. Мы хотим, чтобы кодовые слова были максимально удалены друг от друга, так что даже если векторы будут искажены в ходе передачи, их все еще можно будет с высокой вероятностью правильно декодировать.
6.4.3. Пример линейного блочного кода (6,3)
Приведем необходимые предварительные замечания относительно кода (6,3). Он состоит из 2k = 23 = 8 векторов сообщений и, следовательно, восьми кодовых слов. В векторном пространстве V6 имеется 2n (26 = шестьдесят четыре) 6-кортежей.
Нетрудно убедиться, что восемь кодовых слов, показанных в табл. 6.1, образуют в V6 подпространство (есть нулевой вектор, сумма любых двух кодовых слов дает кодовое слово этого же подпространства). Таким образом, эти кодовые слова представляют линейный блочный код, определенный в разделе 6.4.2. Может возникнуть естественный вопрос о соответствии кодовых слов и сообщений для этого кода (6, 3). Однозначного соответствия для отдельных кодов (n, k) не существует; хотя, впрочем, здесь нет полной свободы выбора. Подробнее о требованиях и ограничениях, сопровождающих разработку кода, будет рассказано в разделе 6.6.3.
Таблица 6.1. Соответствие кодовых слов и сообщений

6.4.4. Матрица генератора
При больших k реализация таблицы соответствия кодера становится слишком громоздкой. Для кода (127,92) существует 292 или приблизительно 5 х 1027 кодовых векторов. Если кодирование выполняется с помощью простой таблицы соответствия, то представьте, какое количество памяти нужно для такого огромного числа кодовых слов! К счастью, задачу можно значительно упростить, по мере необходимости генерируя необходимые кодовые слова, вместо того чтобы хранить их в памяти постоянно. Поскольку множество кодовых слов, составляющих линейный блочный код, является k-мерным подпространством n-мерного двоичного векторного пространства (k < n), всегда можно найти такое множество n-кортежей (с числом элементов, меньшим 2k), которое может генерировать все 2k кодовых слова подпространства. О генерирующем множестве векторов говорят, что оно охватывает подпространство. Наименьшее линейно независимое множество, охватывающее подпространство, называется базисом подпространства, а число векторов в этом базисном множестве является размерностью подпространства. Любое базисное множество k линейно независимых n-кортежей V1, V2,..., Vk можно использовать для генерации нужных векторов линейного блочного кода, поскольку каждый вектор кода является линейной комбинацией V1, V2,..., Vk. Иными словами, каждое из множества 2k кодовых слов {U} можно представить следующим образом.
![]()
Здесь mi = (0 или 1) — цифры сообщения, a i = 1,..., k.
Вообще, матрицу генератора можно определить как массив размером k x n.
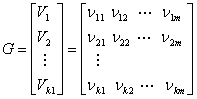 (6.24)
(6.24)
Кодовые векторы принято представлять векторами-строками. Таким образом, сообщение m (последовательность k бит сообщения) представляется как вектор-строка (матрица 1 x k, в которой 1 строка и k столбцов).
![]()
В матричной записи генерация кодового слова U будет выглядеть как произведение m и G
U = mG, (6.25)
где умножение матриц С = АВ выполняется по следующему правилу.
![]()
Здесь А — матрица размером l х п, В — матрица размером n х т, а результирующая матрица С имеет размер l х т. Для примера, рассмотренного в предыдущем разделе, матрица генератора имеет следующий вид.
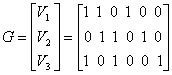 (6.26)
(6.26)
Здесь V1, V2 и V3 — три линейно независимых вектора (подмножество восьми кодовых векторов), которые могут сгенерировать все кодовые векторы. Отметим, что сумма любых двух генерирующих векторов в результате не дает ни одного генерирующего вектора (противоположность свойству замкнутости). Покажем, как с использованием матрицы генератора, приведенной в выражении (6.26), генерируется кодовое слово U4 для четвертого вектора сообщения 110 в табл. 6.1.
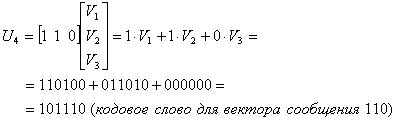
Таким образом, кодовый вектор, соответствующий вектору сообщения, является линейной комбинацией строк матрицы G. Поскольку код полностью определяется матрицей G, кодеру нужно помнить лишь k строк матрицы G, а не все 2k кодовых вектора. Из приведенного примера можно видеть, что матрица генератора размерностью 3 x 6, приведенная в уравнении (6.26), полностью заменяет исходный массив кодовых слов размерностью 8 x 6, приведенный в табл. 6.1, что значительно упрощает систему.
6.4.5. Систематические линейные блочные коды
Систематический линейный блочный код (systematic linear block code) (n, k) — это такое отображение n-мерного вектора сообщения в n-мерное кодовое слово, что часть генерируемой последовательности совмещается с k символами сообщения. Остальные (n - k) бит — это биты четности. Матрица генератора систематического линейного блочного кода имеет следующий вид.
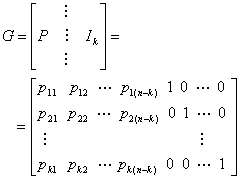 (6.27)
(6.27)
Здесь Р — массив четности, входящий в матрицу генератора, pij = (0 или 1), а Ik — единичная матрица размерностью k x k (у которой диагональные элементы равны 1, а все остальные — 0). Заметим, что при использовании этого систематического генератора процесс кодирования еще больше упрощается, поскольку нет необходимости хранить ту часть массива, где находится единичная матрица. Объединяя выражения (6.26) и (6.27), можно представить каждое кодовое слово в следующем виде.
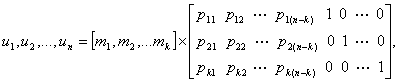
где
![]()
Для данного k-кортежа сообщения
![]()
и k-кортежа кодовых векторов
![]()
систематический кодовый вектор можно записать в следующем виде.
![]() (6.28)
(6.28)
где
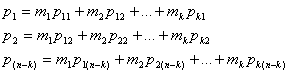 (6.29)
(6.29)
Систематические кодовые слова иногда записываются так, чтобы биты сообщения занимали левую часть кодового слова, а биты четности — правую. Такая перестановка не влияет на свойства кода, связанные с процедурами обнаружения и исправления ошибок, поэтому далее рассматриваться не будет.
Для кода (6,3), рассмотренного в разделе 6.4.3, кодовое слово выглядит следующим образом.
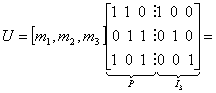 (6.30)
(6.30)
![]() (6.31)
(6.31)
Выражение (6.31) позволяет получить некоторое представление о структуре линейных блочных кодов. Видно, что избыточные биты имеют разное происхождение. Первый бит четности является суммой первого и третьего битов сообщения; второй бит четности — это сумма первого и второго битов сообщения; а третий бит четности — сумма второго и третьего битов сообщения. Интуитивно понятно, что, по сравнению с контролем четности методом дублирования разряда или с помощью одного бита четности, описанная структура может предоставлять более широкие возможности обнаружения и исправления ошибок.
6.4.6. Проверочная матрица
Определим матрицу Н, именуемую проверочной, которая позволит нам декодировать полученные вектора. Для каждой матрицы (k х n) генератора G существует матрица Н размером (n - k) х n, такая, что строки матрицы G ортогональны к строкам матрицы Н. Иными словами, GHT=0, где НT — транспонированная матрица Н, а 0 — нулевая матрица размерностью k x (n-k). НT— это матрица размером n x (n-k), строки которой являются столбцами матрицы Н, а столбцы — строками матрицы Н. Чтобы матрица Н удовлетворяла требованиям ортогональности систематического кода, ее компоненты записываются в следующем виде.
![]() (6.32)
(6.32)
Следовательно, матрица НT имеет следующий вид.
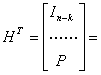 (6.ЗЗ,а)
(6.ЗЗ,а)
 (6.33,6)
(6.33,6)
Нетрудно убедиться, что произведение UHT любого кодового слова U, генерируемого G, и матрицы HT дает следующее.
![]()
где биты четности ![]() определены в уравнении (6.29). Таким образом, поскольку проверочная матрица Н создана так, чтобы удовлетворять условиям ортогональности, она позволяет проверять принятые векторы на предмет их принадлежности заданному набору кодовых слов. U будет кодовым словом, генерируемым матрицей G, тогда и только тогда, когда UHT=0.
определены в уравнении (6.29). Таким образом, поскольку проверочная матрица Н создана так, чтобы удовлетворять условиям ортогональности, она позволяет проверять принятые векторы на предмет их принадлежности заданному набору кодовых слов. U будет кодовым словом, генерируемым матрицей G, тогда и только тогда, когда UHT=0.
6.4.7. Контроль с помощью синдромов
Пусть ![]() — принятый вектор (один из 2n n-кортежей), полученный после передачи
— принятый вектор (один из 2n n-кортежей), полученный после передачи ![]() (один из 2n n-кортежей). Тогда r можно представить в следующем виде.
(один из 2n n-кортежей). Тогда r можно представить в следующем виде.
![]() (6.34)
(6.34)
Здесь ![]() — вектор ошибки или ошибочная комбинация, внесенная каналом. Всего в пространстве из 2n n-кортежей существует 2n -1 возможных ненулевых ошибочных комбинаций. Синдром сигнала r определяется следующим образом.
— вектор ошибки или ошибочная комбинация, внесенная каналом. Всего в пространстве из 2n n-кортежей существует 2n -1 возможных ненулевых ошибочных комбинаций. Синдром сигнала r определяется следующим образом.
![]() (6.35)
(6.35)
Синдром — это результат проверки четности, выполняемой над сигналом r для определения его принадлежности заданному набору кодовых слов. При положительном результате проверки синдром S равен 0. Если r содержит ошибки, которые можно исправить, то синдром (как и симптом болезни) имеет определенное ненулевое значение, что позволяет отметить конкретную ошибочную комбинацию. Декодер, в зависимости от того, производит ли он прямое исправление ошибок или использует запрос ARQ, участвует в локализации и исправлении ошибки (прямое исправление ошибок) или посылает запрос на повторную передачу (ARQ). Используя уравнения (6.34) и (6.35), мы можем представить синдром r в следующем виде.
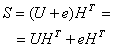 (6.36)
(6.36)
Но для всех элементов набора кодовых слов UHT = 0. Поэтому
![]() (6.37)
(6.37)
Из сказанного выше очевидно, что контроль с помощью синдромов, проведенный над искаженным вектором кода или над ошибочной комбинацией, вызвавшей его появление, даст один и тот же синдром. Важной особенностью линейных блочных кодов (весьма важной в процессе декодирования) является взаимно однозначное соответствие между синдромом и исправимой ошибочной комбинацией.
Интересно также отметить два необходимых свойства проверочной матрицы.
1. В матрице Н не может быть столбца, состоящего из одних нулей, иначе ошибка в соответствующей позиции кодового слова не отразится в синдроме и не будет обнаружена.
2. Все столбцы матрицы Н должны быть различными. Если в матрице Н найдется два одинаковых столбца, ошибки в соответствующих позициях кодового слова будут неразличимы.
Пример 6.3. Контроль с помощью синдромов
Пусть передано кодовое слово U=101110 из примера в разделе 6.4.3 и принят вектор r=001110, т.е. крайний левый бит принят с ошибкой. Нужно найти вектор синдрома S = rHT и показать, что он равен eHT.
Решение
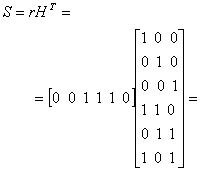
= [l, 1 + 1, l + l] = [l 0 l] (синдром искаженного вектора кода)
Далее проверим, что синдром искаженного вектора кода равен синдрому ошибочной комбинации, которая вызвала эту ошибку.
![]() (синдром ошибочной комбинации)
(синдром ошибочной комбинации)
6.4.8. Исправление ошибок
Итак, мы обнаружили отдельную ошибку и показали, что контроль с помощью синдромов, выполняемый как на искаженном кодовом слове, так и на соответствующей ошибочной комбинации, дает один и тот же синдром. Этот момент является ключевым, поскольку мы имеем возможность не только определить ошибку, но и (поскольку существует взаимно однозначное соответствие между исправимой ошибочной комбинацией и синдромом) исправить подобные ошибочные комбинации. Давайте так расположим 2" л-кортежей, которые представляют собой возможные принимаемые векторы, в так называемой нормальной матрице, чтобы первый ряд содержал все кодовые слова, начиная с кодового слова с одними нулями, а первый столбец — все исправимые ошибочные комбинации. Напомним, что в число основных свойств линейного кода входит то, что набор кодовых слов должен содержать член в виде вектора, состоящего из одних нулей. Каждая строка сформированной матрицы, именуемая классом смежности, состоит из ошибочной комбинации в первом столбце, называемой образующим элементом класса смежности, за которой следуют кодовые слова, подвергающиеся воздействию этой ошибочной комбинации. Нормальная матрица для кода (и, k) имеет следующий вид.
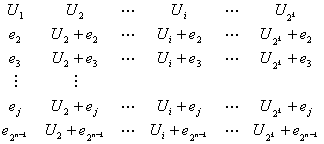 (6.38)
(6.38)
Отметим, что кодовое слово U1 (кодовое слово со всеми нулями) имеет два значения. Оно является кодовым словом, а также может рассматриваться как ошибочная комбинация е, — комбинация, означающая отсутствие ошибки, так что r = U. Матрица содержит все 2n n-кортежей, имеющихся в пространстве Vn. Каждый n-кортеж упомянут только один раз, причем ни один не пропущен и не продублирован. Каждый класс смежности содержит 2k n-кортежей. Следовательно, всего классов смежности будет (2n/2k) = 2n-k.
Алгоритм декодирования предусматривает замену искаженного вектора (любого п-кортежа, за исключением указанного в первой строке) правильным кодовым словом, указанным вверху столбца, содержащего искаженный вектор. Предположим, что кодовое слово Ui (i = 1,..., 2k) передано по каналу с помехами, в результате чего принят (искаженный) вектор Ui + еj. Если созданная каналом ошибочная комбинация еj является образующим элементом класса смежности с индексом j = 1,...,2n-k, принятый вектор будет правильно декодирован в переданное кодовое слово Ui. Если ошибочная комбинация не является образующим элементом класса, то декодирование даст ошибочный результат.
6.4.8.1. Синдром класса смежности
Если еj является образующим элементом класса смежности или ошибочной комбинацией j-го класса смежности, то вектор Ui + еj является n-кортежем в этом классе смежности. Синдром этого n-кортежа можно записать в следующем виде.
![]()
Поскольку Ui — это вектор кода и UiHT = 0, то, как и в уравнении (6.37), мы можем записать следующее.
![]() (6.39)
(6.39)
Вообще, название класс смежности (или сомножество) — это сокращение от "множество чисел, имеющих совместные свойства". Что же все-таки общего между членами каждой данной строки (класса смежности)? Из уравнения (6.39) видно, что каждый член класса смежности имеет один и тот же синдром. Синдром каждого класса смежности отличается от синдромов других классов смежности; именно этот синдром используется для определения ошибочных комбинаций.
6.4.8.2. Декодирование с исправлением ошибок
Процедура декодирования с исправлением ошибок состоит из следующих этапов.
1. С помощью уравнения S = rНT вычисляется синдром r.
2. Определяются образующие элементы класса смежности (ошибочные комбинации) е,, синдром которых равен rHT.
3. Полагается, что эти ошибочные комбинации вызываются искажениями в канале.
4. Полученный исправленный вектор, или кодовое слово, определяется как U = r + еj. Можно сказать, что в результате вычитания определенных ошибок мы восстановили верное кодовое слово. (Замечание: в арифметических операциях по модулю 2 операция вычитания равносильна операции сложения.)
6.4.8.3. Локализация ошибочной комбинации
Возвращаясь к примеру из раздела 6.4.3, мы составляем матрицу из 26 = шестидесяти четырех 6-кортежей, как это показано на рис. 6.11. Правильные кодовые слова — это восемь векторов в первой строке, а исправимые ошибочные комбинации — это семь ненулевых образующих элементов классов смежности в первом столбце. Заметим, что все однобитовые ошибочные комбинации являются исправимыми. Отметим также, что после того, как исчерпываются все однобитовые ошибочные комбинации, еще остаются некоторые возможности для исправления ошибок, поскольку учтены еще не все шестьдесят четыре 6-кортежа. Имеется один образующий элемент класса смежности, с которым ничего не сопоставлено; а значит, остается возможность исправления еще одной ошибочной комбинации. Эту ошибочную комбинацию (один из n-кортежей в оставшемся образующем элементе класса смежности) можно выбрать произвольным образом. На рис. 6.11 эта последняя исправимая ошибочная комбинация выбрана равной комбинации с двумя ошибочными битами 010001. Декодирование будет правильным тогда и только тогда, когда ошибочная комбинация, введенная каналом, будет одним из образующих элементов классов смежности.
000000 110100 011010 101110 101001 011101 110011 000111
![]()
000001 110101 011011 101111 101000 011100 110010 000110
000010 110110 011000 101100 101011 011111 110001 000101
000100 110000 011110 101010 101101 011001 110111 000011
001000 111100 010010 100110 100001 010101 111011 001111
010000 100100 001010 111110 111001 001101 100011 010111
100000 010100 111010 001110 001001 111101 010011 100111
010001 100101 001011 111111 111000 001100 100010 010110
Рис. 6.11. Пример нормальной матрицы для кода (6, 3)
Определим синдром, соответствующий каждой последовательности исправимых ошибок, вычислив еjНT для каждого образующего элемента.
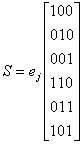
Результаты приводятся в табл. 6.2. Поскольку все синдромы в таблице различны, декодер может определить ошибочную комбинацию е, которой соответствует каждый синдром.
Таблица 6.2. Таблица соответствия синдромов
![]()
Ошибочная комбинация Синдром
![]()
000000 000
000001 101
000010 011
000100 110
001000 001
010000 010
100000 100
010001 111
6.4.8.4. Пример исправления ошибки
Как говорилось в разделе 6.4.8.2, мы принимаем вектор г и рассчитываем его синдром с помощью выражения S = rHT. Затем, используя таблицу соответствия синдромов (табл. 6.2), составленную в предыдущем разделе, находим соответствующую ошибочную комбинацию, которая является оценкой ошибки (далее будем обозначать ее через ![]() ). Затем декодер прибавляет
). Затем декодер прибавляет ![]() к r и оценивает переданное кодовое слово U.
к r и оценивает переданное кодовое слово U.
![]() (6.40)
(6.40)
Если правильно вычислили ошибку: ![]() = е, тогда оценка
= е, тогда оценка ![]() совпадает с переданным кодовым словом U. С другой стороны, если оценка ошибки неверна, декодер неверно определит переданное кодовое слово и мы получим необнаружимую ошибку декодирования.
совпадает с переданным кодовым словом U. С другой стороны, если оценка ошибки неверна, декодер неверно определит переданное кодовое слово и мы получим необнаружимую ошибку декодирования.
Пример 6.4. Исправление ошибок
Пусть передано кодовое слово U=101110 из примера в разделе 6.4.3 и принят вектор r = 001 ПО. Нужно показать, как декодер, используя таблицу соответствия синдромов (табл. 6.2), может исправить ошибку.
Решение
Рассчитывается синдром r.
S = [001 1 10]НT=[100]
С помощью табл. 6,2 оценивается ошибочная комбинация, соответствующая приведенному выше синдрому.
![]()
Исправленный вектор равен следующему.

Поскольку оцененная ошибочная комбинация в этом примере совпадает с действительной ошибочной комбинацией, процедура исправления ошибки дает ![]() = U. Можно видеть, что процесс декодирования искаженного кодового слова путем предварительного обнаружения и последующего исправления ошибки можно сравнить с аналогичной медицинской процедурой. Пациент (потенциально искаженный вектор) приходит в медицинское учреждение (декодер). Врач проводит серию тестов (умножение на НT), чтобы определить симптомы болезни (синдром). Допустим, врач нашел характерные пятна на рентгенограмме пациента. Опытный врач может непосредственно установить связь между симптомом и болезнью (ошибочной комбинацией). Начинающий врач может обратиться к медицинскому справочнику (табл. 6.2) для определения соответствия между симптомом (синдромом) и болезнью (ошибочной комбинацией). Последний шаг заключается в назначении соответствующего лечения, которое устранит болезнь (уравнение (6.40)). Продолжая аналогию двоичных кодов и медицины, можно сказать, что уравнение (6.40) — это несколько необычный способ лечения. Пациент излечивается в результате повторного заболевания той же болезнью.
= U. Можно видеть, что процесс декодирования искаженного кодового слова путем предварительного обнаружения и последующего исправления ошибки можно сравнить с аналогичной медицинской процедурой. Пациент (потенциально искаженный вектор) приходит в медицинское учреждение (декодер). Врач проводит серию тестов (умножение на НT), чтобы определить симптомы болезни (синдром). Допустим, врач нашел характерные пятна на рентгенограмме пациента. Опытный врач может непосредственно установить связь между симптомом и болезнью (ошибочной комбинацией). Начинающий врач может обратиться к медицинскому справочнику (табл. 6.2) для определения соответствия между симптомом (синдромом) и болезнью (ошибочной комбинацией). Последний шаг заключается в назначении соответствующего лечения, которое устранит болезнь (уравнение (6.40)). Продолжая аналогию двоичных кодов и медицины, можно сказать, что уравнение (6.40) — это несколько необычный способ лечения. Пациент излечивается в результате повторного заболевания той же болезнью.
6.4.9. Реализация декодера
Если код небольшой, например рассмотренный ранее код (6, 3), декодер может быть реализован в виде довольно простой схемы. Рассмотрим шаги, которые должны быть предприняты декодером: (1) вычислить синдром, (2) локализовать ошибочную комбинацию и (3) осуществить сложение по модулю 2 ошибочной комбинации и принятого вектора (что приводит к устранению ошибки). В примере 6.4, имея искаженный вектор, мы покажем, как с помощью последовательности этих шагов можно получить исправленное кодовое слово. Сейчас мы рассмотрим схему, показанную на рис. 6.12, где реализованы логические элементы исключающего ИЛИ и И, которые позволяют получить тот же результат для любой комбинации с одним ошибочным битом в коде (6, 3). Из табл. 6.2 и уравнения (6.39) можно записать все разряды синдрома через разряды принятых кодовых слов.
![]()
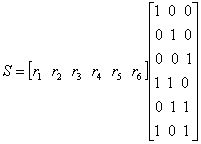
и
Мы используем эти выражения для синдромов при связывании схемы на рис. 6.12. Логический элемент "исключающее ИЛИ" — это и есть реализация той самой операции сложения (или вычитания) по модулю 2, поэтому он обозначен тем же символом "+". Маленький кружок в конце каждой линии, входящей в элемент И, означает операцию логического дополнения сигнала.
Искаженный сигнал подается на декодер одновременно в верхней части схемы, где происходит вычисление синдрома, и в нижней, где синдром преобразуется в соответствующую ошибочную комбинацию. Ошибка устраняется путем повторного добавления ее к принятому вектору, что дает в итоге исправленное кодовое слово.
Заметим, что с методической точки зрения рис. 6.12 составлен так, чтобы выделить алгебраические этапы декодирования — вычисление синдрома и ошибочной комбинации, а также выдачу исправленных выходных данных. В реальной ситуации код (n, k) обычно конфигурируется в систематическом виде.
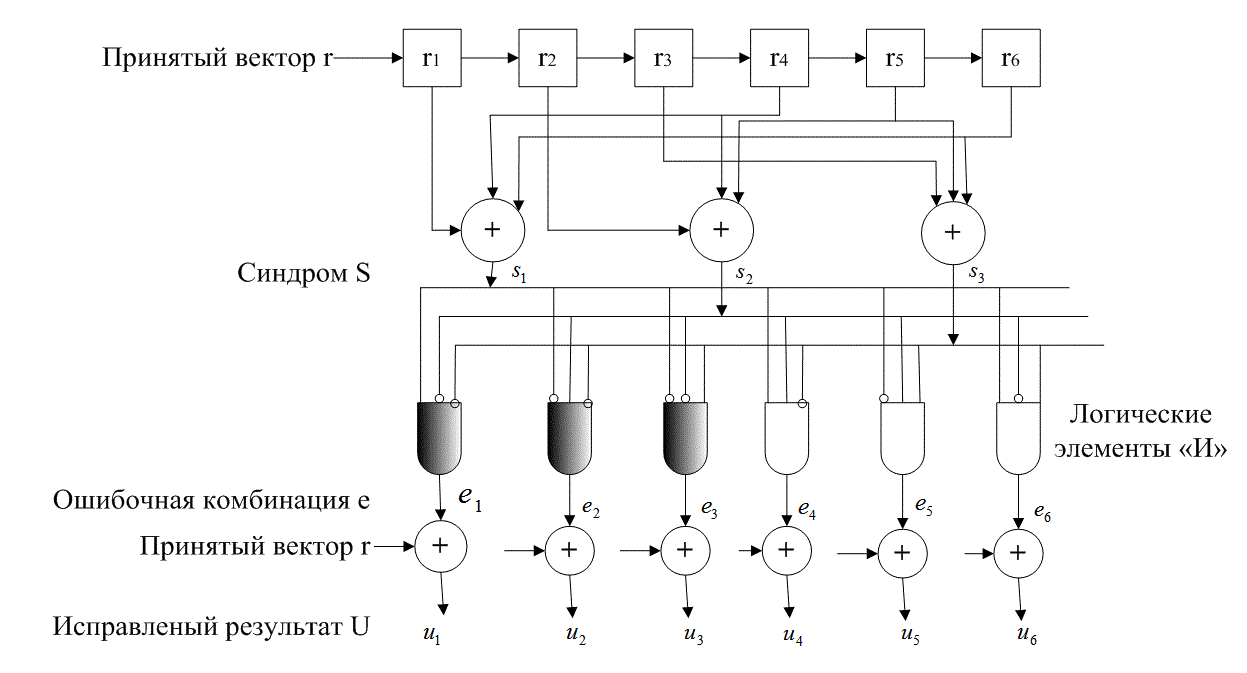
Рис. 6.12. Схема реализации декодера для кода (6, 3)
Декодеру не нужно выдавать полное кодовое слово; на выходе у него должны быть только биты данных. Поэтому схема на рис. 6.12 упрощается за счет удаления заштрихованных элементов. Для более длинных кодов такая реализация намного сложнее; в данной ситуации более предпочтительной методикой декодирования является последовательная схема, а не рассмотренный здесь параллельный метод [4]. Важно также подчеркнуть, что схема на рис. 6.12 позволяет определять и исправлять только комбинации кода (6, 3) с одним ошибочным битом. Исправление комбинаций с двумя ошибочными битами потребует дополнительной схемы.
6.4.9.1. Векторные обозначения
Выше кодовые слова, ошибочные комбинации, принятые векторы и синдромы обозначались как векторы U, e, r и S. Для упрощения записи индексы, сопутствующие конкретному вектору, в основном, опускались. Хотя, если быть точным, каждый из векторов U, е, г и S должен записываться в следующем виде.
![]()
Рассмотрим диапазон индексов j и i в контексте кода (6, 3), приведенного в табл. 6.1. Для кодового слова Uj индекс j = 1,...2k показывает, что имеется 23 = 8 отдельных кодовых слов, а индекс j= 1,...,n демонстрирует, что каждое кодовое слово составлено из п = 6 бит. Для исправимой ошибочной комбинации еj индекс j = 1,...,2n-k означает, что имеется 23 = 8 образующих элементов классов смежности (7 ненулевых исправимых ошибочных комбинаций), а индекс i= 1,...,n указывает, что каждая ошибочная комбинация составлена из п = 6 бит. Для принятого вектора r, индекс j = 1,...,2n показывает, что имеется 26 = 64 n-кортежей, прием которых возможен, а индекс i=1,...,n указывает, что каждый принятый n-кортеж состоит из п = 6 бит. И наконец, для синдрома Sj индекс j = 1,...,n - k означает, что каждый синдром состоит из n - k = 3 бит. В этой главе индексы часто опускаются, и векторы Uj, еj, гj и Sj зачастую обозначаются как U, e, r, и S. Читателю следует помнить, что для этих векторов индексы всегда подразумеваются, даже в тех случаях, когда они опущены для простоты записи.
6.5. Возможность обнаружения и исправления ошибок
6.5.1. Весовой коэффициент двоичных векторов и расстояние между ними
Конечно же, понятно, что правильно декодировать можно не все ошибочные комбинации. Возможности кода для исправления ошибок в первую очередь определяются его структурой. Весовой коэффициент Хэмминга (Hamming weight) w(U) кодового слова U определяется как число ненулевых элементов в U. Для двоичного вектора это эквивалентно числу единиц в векторе. Например, если U=100101101, то w(U) = 5. Расстояние Хэмминга (Hamming distance) между двумя кодовыми словами U и V, обозначаемое как d(U, V), определяется как количество элементов, которыми они отличаются.
U=100101101
V=011110100
d(U,V)=6
Согласно свойствам сложения по модулю 2, можно отметить, что сумма двух двоичных векторов является другим двоичным вектором, двоичные единицы которого расположены на тех позициях, которыми эти векторы отличаются.
U + V=111011001
Таким образом, можно видеть, что расстояние Хэмминга между двумя векторами равно весовому коэффициенту Хэмминга их суммы, т.е. d(U, V) = w(U + V). Также видно, что весовой коэффициент Хэмминга кодового слова равен его расстоянию Хэмминга до нулевого вектора.
6.5.2. Минимальное расстояние для линейного кода
Рассмотрим множество расстояний между всеми парами кодовых слой в пространстве Vn. Наименьший элемент этого множества называется минимальным расстоянием кода и обозначается dmin. Как вы думаете, почему нас интересует именно минимальное расстояние, а не максимальное? Минимальное расстояние подобно наиболее слабому звену в цепи, оно дает нам меру минимальных возможностей кода и, следовательно, характеризует его мощность.
Как обсуждалось ранее, сумма двух произвольных кодовых слов дает другой элемент пространства кодовых слов. Это свойство линейных кодов формулируется просто: если U и V — кодовые слова, то и W = U + V тоже должно быть кодовым словом. Следовательно, расстояние между двумя кодовыми словами равно весовому коэффициенту третьего кодового слова, т.е. d(U, V) = w(U + V) = w(W). Таким образом, минимальное расстояние линейного кода можно определить, не прибегая к изучению расстояний между всеми комбинациями пар кодовых слов. Нам нужно лишь определить вес каждого кодового слова (за исключением нулевого вектора) в подпространстве; минимальный вес соответствует минимальному расстоянию dmin. Иными словами, dmin соответствует наименьшему из множества расстояний между нулевым кодовым словом и всеми остальными кодовыми словами.
6.5.3. Обнаружение и исправление ошибок
Задача декодера после приема вектора r заключается в оценке переданного кодового слова Ui. Оптимальная стратегия декодирования может быть выражена в терминах алгоритма максимального правдоподобия (см. приложение Б); считается, что передано было слово Ui, если
![]() (6.41)
(6.41)
Поскольку для двоичного симметричного канала (binary symmetric channel — BSC) правдоподобие Ui относительно r обратно пропорционально расстоянию между r и U, можно сказать, что передано было слово Ui, если
![]() (6.42)
(6.42)
Другими словами, декодер определяет расстояние между r и всеми возможными переданными кодовыми словами Uj, после чего выбирает наиболее правдоподобное Uj, для которого
![]() (6.43)
(6.43)
где М = 2k — это размер множества кодовых слов. Если минимум не один, выбор между минимальными расстояниями является произвольным. Наше обсуждение метрики расстояний будет продолжено в главе 7.
На рис. 6.13 расстояние между двумя кодовыми словами U и V показано как расстояние Хэмминга. Каждая черная точка обозначает искаженное кодовое слово. На рис. 6.13, а проиллюстрирован прием вектора r1 находящегося на расстоянии 1 от кодового слова U и на расстоянии 4 от кодового слова V. Декодер с коррекцией ошибок, следуя стратегии максимального правдоподобия, выберет при принятом векторе r1 кодовое слово U. Если r1 получился в результате появления одного ошибочного бита в переданном векторе кода U, декодер успешно исправит ошибку. Но если же это произошло в результате 4-битовой ошибки в векторе кода V, декодирование будет ошибочным. Точно так же, как показано на рис. 6.13, б, двойная ошибка при передаче U может привести к тому, что в качестве переданного вектора будет ошибочно определен вектор r2, находящийся на расстоянии 2 от вектора U и на расстоянии 3 от вектора кода V. На рис. 6.13 показана ситуация, когда в качестве переданного вектора ошибочно определен вектор r3, который находится на расстоянии 3 от вектора кода U и на расстоянии 2 от вектора V. Из рис. 6.13 видно, что если задача состоит только в обнаружении ошибок, а не в их исправлении, то можно определить искаженный вектор — изображенный черной точкой и представляющий одно-, двух-, трех- и четырехбитовую ошибку. В то же время пять ошибок при передаче могут привести к приему кодового слова V, когда в действительности было передано кодовое слово U; такую ошибку невозможно будет обнаружить.
Из рис. 6.13 можно видеть, что способность кода к обнаружению и исправлению ошибок связана с минимальным расстоянием между кодовыми словами. Линия решения на рисунке служит той же цели, что и в процессе демодуляции, — для разграничения областей решения.
а)
б)
в)
Рис. 6.13. Возможности определения и исправления ошибок: а) принятый вектор r1; б) принятый вектор r2; в) принятый вектор r3
В примере, приведенном на рис. 6.13, критерий принятия решения может быть следующим: выбрать U, если r попадает в область 1, и выбрать V, если r попадает в область 2. Выше показывалось, что такой код (при dmin = 5) может исправить две ошибки. Вообще, способность кода к исправлению ошибок t определяется, как максимальное число гарантированно исправимых ошибок на кодовое слово, и записывается следующим образом [4].
![]() (6.44)
(6.44)
Здесь ![]() означает наибольшее целое, не превышающее х. Часто код, который исправляет все искаженные символы, содержащие ошибку в t или меньшем числе бит, также может исправлять символы, содержащие t +1 ошибочных бит. Это можно увидеть на рис. 6.11. В этом случае dmin = 3, поэтому из уравнения (6.44) можно видеть, что исправимы все ошибочные комбинации из t = 1 бит. Также исправима одна ошибочная комбинация, содержащая / +1 (т.е. 2) ошибочных бит. Вообще, линейный код (n, k), способный исправлять все символы, содержащие t ошибочных бит, может исправить всего 2n-k ошибочных комбинаций. Если блочный код с возможностью исправления символов, имеющих ошибки в t бит, применяется для исправления ошибок в двоичном симметричном канале с вероятностью перехода р, то вероятность ошибки сообщения Рм(вероятность того, что декодер совершит неправильное декодирование и п-битовый блок содержит ошибку) можно оценить сверху, используя уравнение (6.18).
означает наибольшее целое, не превышающее х. Часто код, который исправляет все искаженные символы, содержащие ошибку в t или меньшем числе бит, также может исправлять символы, содержащие t +1 ошибочных бит. Это можно увидеть на рис. 6.11. В этом случае dmin = 3, поэтому из уравнения (6.44) можно видеть, что исправимы все ошибочные комбинации из t = 1 бит. Также исправима одна ошибочная комбинация, содержащая / +1 (т.е. 2) ошибочных бит. Вообще, линейный код (n, k), способный исправлять все символы, содержащие t ошибочных бит, может исправить всего 2n-k ошибочных комбинаций. Если блочный код с возможностью исправления символов, имеющих ошибки в t бит, применяется для исправления ошибок в двоичном симметричном канале с вероятностью перехода р, то вероятность ошибки сообщения Рм(вероятность того, что декодер совершит неправильное декодирование и п-битовый блок содержит ошибку) можно оценить сверху, используя уравнение (6.18).
![]() (6.45)
(6.45)
Оценка переходит в равенство, если декодер исправляет все ошибочные комбинации, содержащие до t ошибочных бит включительно, но не комбинации с числом ошибочных бит, большим t. Такие декодеры называются декодерами с ограниченным расстоянием. Вероятность ошибки в декодированном бите РB зависит от конкретного кода и декодера. Приближенно ее можно выразить следующим образом [5].
![]() (6.46)
(6.46)
В блочном коде, прежде чем исправлять ошибки, необходимо их обнаружить. (Или же код может использоваться только для определения наличия ошибок.) Из рис. 6.13 видно, что любой полученный вектор, который изображается черной точкой (искаженное кодовое слово), можно определить как ошибку. Следовательно, возможность определения наличия ошибки дается следующим выражением.
![]() (6.47)
(6.47)
Блочный код с минимальным расстоянием dmin гарантирует обнаружение всех ошибочных комбинаций, содержащих dmin - 1 или меньшее число ошибочных бит. Такой код также способен обнаружить и большую ошибочную комбинацию, содержащую dmin или более ошибок. Фактически код (n, k) может обнаружить 2n – 2k ошибочных комбинаций длины п. Объясняется это следующим образом. Всего в пространстве 2n n-кортежей существует 2n -1 возможных ненулевых ошибочных комбинаций. Даже правильное кодовое слово — это потенциальная ошибочная комбинация. Поэтому всего существует 2k -1 ошибочных комбинаций, которые идентичны 2k -1 ненулевым кодовым словам. При появлении любая из этих 2k - 1 ошибочных комбинаций изменяет передаваемое кодовое слово Uj на другое кодовое слово Uj. Таким образом, принимается кодовое слово Uj и его синдром равен нулю. Декодер принимает Uj за переданное кодовое слово, и поэтому декодирование дает неверный результат. Следовательно, существует 2k -1 необнаружимых ошибочных комбинаций. Если ошибочная комбинация не совпадает с одним из 2k кодовых слов, проверка вектора r с помощью синдромов дает ненулевой синдром и ошибка успешно обнаруживается. Отсюда следует, что существует ровно 2n-2k выявляемых ошибочных комбинаций. При больших n, когда 2k<<2n, необнаружимой будет только незначительная часть ошибочных комбинаций.
6.5.3.1. Распределение весовых коэффициентов кодовых слов
Пусть Aj — количество кодовых слов с весовым коэффициентом j в линейном коде (п, k). Числа A0,A1,…,An называются распределением весовых коэффициентов этого кода. Если код применяется только для обнаружения ошибок в двоичном симметричном канале, то вероятность того, что декодер не сможет определить ошибку, можно рассчитать, исходя из распределения весовых коэффициентов кода [5].
![]() (6.48)
(6.48)
где р — вероятность перехода в двоичном симметричном канале. Если минимальное расстояние кода равно dmin значения от А1 до ![]() , равны нулю.
, равны нулю.
Пример 6.5. Вероятность необнаруженной ошибки в коде
Пусть код (6,3), введенный в разделе 6.4.3, используется только для обнаружения наличия ошибок. Рассчитайте вероятность необнаруженной ошибки, если применяется двоичный симметричный канал, а вероятность перехода равна 10-2.
Решение
Распределение весовых коэффициентов этого кода выглядит следующим образом: A0=1, А1= А2 = 0, A3 = 4, A5 = 0, A6 = 0. Следовательно, используя уравнение (6.48), можно записать следующее.
![]()
Для р = 10-2 вероятность необнаруженной ошибки будет равна 3,9 х 10-6.
6.5.3.2. Одновременное обнаружение и исправление ошибок
Возможностями исправления ошибок с максимальным гарантированным (t), где t определяется уравнением (6.44), можно пожертвовать в пользу определения класса ошибок. Код можно использовать для одновременного исправления α и обнаружения β ошибок, причем ![]() , а минимальное расстояние кода дается следующим выражением [4].
, а минимальное расстояние кода дается следующим выражением [4].
![]() (6.49)
(6.49)
При появлении t или меньшего числа ошибок код способен обнаруживать и исправлять их. Если ошибок больше t, но меньше е+1, где е определяется уравнением (6.47), код может определять наличие ошибок, но исправить может только некоторые из них. Например, используя код с dmin = 7. можно выполнить обнаружение и исправление со следующими значениями α и β.
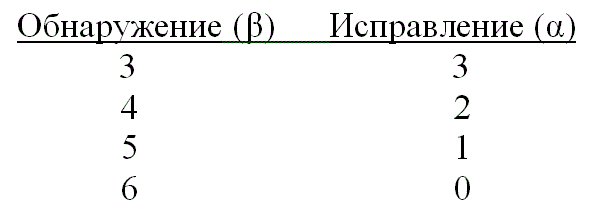
Заметим, что исправление ошибки подразумевает ее предварительное обнаружение. В приведенном выше примере (с тремя ошибками) все ошибки можно обнаружить и исправить. Если имеется пять ошибок, их можно обнаружить, но исправить можно только одну из них.
6.5.4. Визуализация пространства 6-кортежей
На рис. 6.14 визуально представлено восемь кодовых слов, фигурирующих в примере из раздела 6.4.3. Кодовые слова образованы посредством линейных комбинаций из трех независимых 6-кортежей, приведенных в уравнении (6.26); сами кодовые слова образуют трехмерное подпространство. На рисунке показано, что такое подпространство полностью занято восемью кодовыми словами (большие черные круги); координаты подпространства умышленно выбраны неортогональными. На рис. 6.14 предпринята попытка изобразить все пространство, содержащее шестьдесят четыре 6-кортежей, хотя точно нарисовать или составить такую модель невозможно. Каждое кодовое слово окружают сферические слои или оболочки. Радиус внутренних непересекающихся слоев — это расстояние Хэмминга, равное 1; радиус внешнего слоя — это расстояние Хэмминга, равное 2. Большие расстояния в этом примере не рассматриваются. Для каждого кодового слова два показанных слоя заняты искаженными кодовыми словами. На каждой внутренней сфере существует шесть таких точек (всего 48 точек), представляющих шесть возможных однобитовых ошибок в векторах, соответствующих каждому кодовому слову. Эти кодовые слова с однобитовыми возмущениями могут быть соотнесены только с одним кодовым словом; следовательно, такие ошибки могут быть исправлены. Как видно из нормальной матрицы, приведенной на рис. 6.11, существует также одна двухбитовая ошибочная комбинация, которая также поддается исправлению. Всего существует ![]() разных двухбитовых ошибочных комбинаций, которыми может быть искажено любое кодовое слово, но исправить можно только одну из них (в нашем примере это ошибочная комбинация 010001). Остальные четырнадцать двухбитовых ошибочных комбинаций описываются векторами, которые нельзя однозначно сопоставить с каким-либо одним кодовым словом; эти не поддающиеся исправлению ошибочные комбинации дают векторы, которые эквивалентны искаженным векторам двух или большего числа кодовых слов. На рисунке все (56) исправимые кодовые слова с одно- и двухбитовыми искажениями показаны маленькими черными кругами. Искаженные кодовые слова, не поддающиеся исправлению, представлены маленькими прозрачными кругами.
разных двухбитовых ошибочных комбинаций, которыми может быть искажено любое кодовое слово, но исправить можно только одну из них (в нашем примере это ошибочная комбинация 010001). Остальные четырнадцать двухбитовых ошибочных комбинаций описываются векторами, которые нельзя однозначно сопоставить с каким-либо одним кодовым словом; эти не поддающиеся исправлению ошибочные комбинации дают векторы, которые эквивалентны искаженным векторам двух или большего числа кодовых слов. На рисунке все (56) исправимые кодовые слова с одно- и двухбитовыми искажениями показаны маленькими черными кругами. Искаженные кодовые слова, не поддающиеся исправлению, представлены маленькими прозрачными кругами.
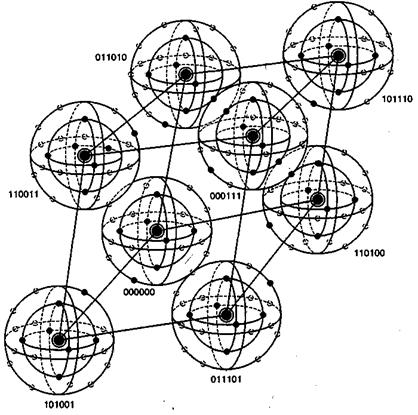
Рис, 6.14. Пример восьми кодовых слов в пространстве 6-кортежей
При представлении свойств класса кодов, известных как совершенные коды (perfect code), рис. 6.14 весьма полезен. Код, исправляющий ошибки в t битах, называется совершенным, если нормальная матрица содержит все ошибочные комбинации из t или меньшего числа ошибок и не содержит иных образующих элементов классов смежности (отсутствует возможность исправления остаточных ошибок). В контексте рис. 6.14 совершенный код с коррекцией ошибок в t битах — это такой код, который (при использовании обнаружения по принципу максимального правдоподобия) может исправить все искаженные кодовые слова, находящиеся на расстоянии Хэмминга t (или ближе) от исходного кодового слова, и не способен исправить ни одну из ошибок, находящихся на расстоянии, превышающем t.
Кроме того, рис. 6.14 способствует пониманию основной цели поиска хороших кодов. Предпочтительным является пространство, максимально заполненное кодовыми словами (эффективное использование введенной избыточности), а также желательно, чтобы кодовые слова были по возможности максимально удалены друг от друга. Очевидно, что эти цели противоречивы.
6.5.5. Коррекция со стиранием ошибок
Приемник можно сконструировать так, чтобы он объявлял символ стертым, если последний принят неоднозначно либо обнаружено наличие помех или кратковременных сбоев. Размер входного алфавита такого канала равен Q, а выходного —Q + 1; лишний выходной символ называется меткой стирания (erasure flag), или просто стиранием (erasure). Если демодулятор допускает символьную ошибку, то для ее исправления необходимы два параметра, определяющие ее расположение и правильное значение символа. В случае двоичных символов эти требования упрощаются — нам необходимо только расположение ошибки. В то же время, если демодулятор объявляет символ стертым (при этом правильное значение символа неизвестно), расположение этого символа известно, поэтому декодирование стертого кодового слова может оказаться проще исправления ошибки. Код защиты от ошибок можно использовать для исправления стертых символов или одновременного исправления ошибок и стертых символов. Если минимальное расстояние кода равно dmin, любая комбинация из ρ или меньшего числа стертых символов может быть исправлена при следующем условии [6].
![]() (6.50)
(6.50)
Предположим, что ошибки появляются вне позиций стирания. Преимущество исправления посредством стираний качественно можно выразить так: если минимальное расстояние кода равно dmin, согласно уравнению (6.50), можно восстановить dmin-1 стирание. Поскольку число ошибок, которые можно исправить без стирания информации, не превышает (dmin-1)/2, то преимущество исправления ошибок посредством стираний очевидно. Далее, любую комбинацию из α ошибок и γ стираний можно исправить одновременно, если, как показано в работе [6],
![]() (6.51)
(6.51)
Одновременное исправление ошибок и стираний можно осуществить следующим образом. Сначала позиции из у стираний замещаются нулями, и получаемое кодовое слово декодируется обычным образом. Затем позиции из у стираний замещаются единицами, и декодирование повторяется для этого варианта кодового слова. После обработки обоих кодовых слов (одно с подставленными нулями, другое — с подставленными единицами) выбирается то из них, которое соответствует наименьшему числу ошибок, исправленных вне позиций стирания. Если удовлетворяется неравенство (6.51), то описанный метод всегда дает верное декодирование.
Пример 6.6. Коррекция со стиранием ошибок
Рассмотрим набор кодовых слов, представленный в разделе 6.4.3.
000000 110100 011010 101110 101001 011101 110011 000111
Пусть передано кодовое слово 110011, в котором два крайних слева разряда приемник объявил стертыми. Проверьте, что поврежденную последовательность хx0011 можно исправить.
Решение
Поскольку ![]() , код может исправить
, код может исправить ![]() = 2 стирания. В этом легко убедиться из рис. 6.11 или приведенного выше перечня кодовых слов, сравнивая 4 крайних правых разряда xx00l1 с каждым из допустимых кодовых слов. Действительно переданное кодовое слово — это ближайшее (с точки зрения расстояния Хэмминга) к искаженной последовательности.
= 2 стирания. В этом легко убедиться из рис. 6.11 или приведенного выше перечня кодовых слов, сравнивая 4 крайних правых разряда xx00l1 с каждым из допустимых кодовых слов. Действительно переданное кодовое слово — это ближайшее (с точки зрения расстояния Хэмминга) к искаженной последовательности.
6.6. Полезность нормальной матрицы
6.6.1. Оценка возможностей кода
Нормальную матрицу можно представлять как организационный инструмент, картотеку, содержащую все возможные ![]() записи в пространстве n-кортежей, в которой ничего не упущено и не продублировано. На первый взгляд может показаться, что выгода от использования этого инструмента ограничена малыми блочными кодами, поскольку для кодов длиной более n=20 пространство n-кортежей насчитывает миллионы элементов. Впрочем, даже для больших кодов нормальная матрица позволяет определить важные исходные характеристики, такие как возможные компромиссы между обнаружением и исправлением ошибок и пределы возможностей кода в коррекции ошибок. Одно из таких ограничений, называемое пределом Хэмминга [7], описывается следующим образом.
записи в пространстве n-кортежей, в которой ничего не упущено и не продублировано. На первый взгляд может показаться, что выгода от использования этого инструмента ограничена малыми блочными кодами, поскольку для кодов длиной более n=20 пространство n-кортежей насчитывает миллионы элементов. Впрочем, даже для больших кодов нормальная матрица позволяет определить важные исходные характеристики, такие как возможные компромиссы между обнаружением и исправлением ошибок и пределы возможностей кода в коррекции ошибок. Одно из таких ограничений, называемое пределом Хэмминга [7], описывается следующим образом.
Количество бит четности: 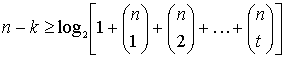 (6.52,а)
(6.52,а)
или
Количество классов смежности: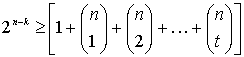 (6.52,6)
(6.52,6)
Здесь величина ![]() , определяемая уравнением (6.16), представляет число способов выбора из п бит j ошибочных. Заметим, что сумма членов уравнения (6.52), находящихся в квадратных скобках, дает минимальное количество строк, которое должно присутствовать в нормальной матрице для исправления всех комбинаций ошибок, вплоть до t-битовых ошибок. Неравенство определяет нижнюю границу числа п-k бит четности (или
, определяемая уравнением (6.16), представляет число способов выбора из п бит j ошибочных. Заметим, что сумма членов уравнения (6.52), находящихся в квадратных скобках, дает минимальное количество строк, которое должно присутствовать в нормальной матрице для исправления всех комбинаций ошибок, вплоть до t-битовых ошибок. Неравенство определяет нижнюю границу числа п-k бит четности (или ![]() классов смежности) как функцию возможностей кода в коррекции t-битовых ошибок. Аналогичным образом можно сказать, что неравенство дает верхнюю границу возможностей кода в коррекции t-битовых ошибок как функцию числа n-k бит четности (или
классов смежности) как функцию возможностей кода в коррекции t-битовых ошибок. Аналогичным образом можно сказать, что неравенство дает верхнюю границу возможностей кода в коррекции t-битовых ошибок как функцию числа n-k бит четности (или ![]() классов смежности). Для обеспечения возможности коррекции t-битовых ошибок произвольных линейных блочных кодов (п, k) необходимым условием является удовлетворение предела Хэмминга.
классов смежности). Для обеспечения возможности коррекции t-битовых ошибок произвольных линейных блочных кодов (п, k) необходимым условием является удовлетворение предела Хэмминга.
Чтобы показать, как нормальная матрица может обеспечить визуальное представление этого предела, возьмем в качестве примера код БХЧ (127,106). Матрица содержит все ![]() = 2127= 1,70 х 1038n- кортежей пространства. Верхняя строка матрицы содержит
= 2127= 1,70 х 1038n- кортежей пространства. Верхняя строка матрицы содержит ![]() = 2106 = 8,11 x 1031 кодовых слов; следовательно, это число столбцов в матрице. Крайний левый столбец содержит
= 2106 = 8,11 x 1031 кодовых слов; следовательно, это число столбцов в матрице. Крайний левый столбец содержит ![]() 2 097 152 образующих элемента классов смежности; следовательно, это количество строк в матрице. Несмотря на то что число n-кортежей и кодовых слов просто огромно, нас не интересует конкретный вид каждого элемента матрицы. Основной интерес представляет количество классов смежности. Существует 2 097 152 класса смежности и, следовательно, 2 097 151 ошибочная комбинация, которую способен исправить, этот код. Далее показано, каким образом это число классов смежности определяет верхний предел возможностей кода в коррекции t-битовых ошибок.
2 097 152 образующих элемента классов смежности; следовательно, это количество строк в матрице. Несмотря на то что число n-кортежей и кодовых слов просто огромно, нас не интересует конкретный вид каждого элемента матрицы. Основной интерес представляет количество классов смежности. Существует 2 097 152 класса смежности и, следовательно, 2 097 151 ошибочная комбинация, которую способен исправить, этот код. Далее показано, каким образом это число классов смежности определяет верхний предел возможностей кода в коррекции t-битовых ошибок.
Поскольку каждое кодовое слово содержит 127 бит, существует 127 возможностей допустить ошибку в одном бите. Рассчитываем количество возможностей появления двух ошибок — ![]() = 8 001. Затем переходим к трехбитовым ошибкам, поскольку ошибки, упомянутые выше, — это лишь незначительная часть всех 2 097 151 ошибочных комбинаций. Итак, существует
= 8 001. Затем переходим к трехбитовым ошибкам, поскольку ошибки, упомянутые выше, — это лишь незначительная часть всех 2 097 151 ошибочных комбинаций. Итак, существует ![]() = 333 375 возможностей совершить трехбитовую ошибку.
= 333 375 возможностей совершить трехбитовую ошибку.
Эти расчеты приведены в табл. 6.3; там же показано, что нулевая ошибочная комбинация требует наличия первого класса смежности. Затем перечислены требования одно-, двух- и трехбитовых ошибок. Также показывается количество классов смежности, необходимое для коррекции каждого типа ошибок, и общее количество классов смежности, необходимых для коррекции ошибок всех типов, вплоть до требуемого типа ошибки. Из этой таблицы можно видеть, что код (127,106) способен исправить все комбинации, содержащие 1, 2 или 3 ошибочных бита, причем это составляет только 341504 из 2 097 152 возможных классов смежности. Неиспользованные 1 755 648 строк говорят о больших потенциальных возможностях в коррекции ошибок, чем было использовано. Действительно, в матрицу можно попытаться втиснуть все возможные 4-битовые ошибки. Но при взгляде на табл. 6.3 становится совершенно ясно, что это невозможно, поскольку, как показывает последняя строка таблицы, число оставшихся в матрице классов смежности значительно меньше общего числа классов смежности, требуемого для коррекции 4-битовых ошибок. Следовательно, предел Хэмминга описанного кода (127,106) гарантирует исправление всех ошибок вплоть до 3-битовых.
Таблица 6.3. Предел возможностей коррекции для кода (127, 106)
Количество битовых ошибок Количество необходимых Общее число необходимых
классов смежности классов смежности
|
0 |
1 |
1 |
|
1 |
127 |
128 |
|
2 |
8001 |
8129 |
|
3 |
333375 |
341504 |
|
4 |
10334625 |
10676129 |
6.6.2. Пример кода (n, k)
Нормальная матрица дает возможность взглянуть на возможные компромиссы между исправлением и обнаружением ошибок. Рассмотрим пример кода (n, k) и факторы, определяющие выбор конкретных значений (n, k).
Для получения нетривиального соотношения между исправлением и обнаружением ошибок желательно, чтобы код имел возможности коррекции ошибок, по крайней мере, с t = 2. Согласно уравнению (6.44), минимальное расстояние при этом равно ![]() .
.
Чтобы кодовая система была нетривиальной, желательно, чтобы количество бит данных было не менее k = 2. Следовательно, число кодовых слов ![]() . Далее будем считать наш код следующим: (п, 2).
. Далее будем считать наш код следующим: (п, 2).
Нас интересует минимальное значение п, которое позволит исправлять все одно- и двухбитовые ошибки. В этом примере каждый из ![]() n-кортежей в матрице будет табулирован. Минимальное значение n нас интересует потому, что при каждом увеличении n на единицу число n-кортежей в нормальной матрице удваивается. Это условие, разумеется, диктуется только соображениями удобства использования таблицы. Для реальных прикладных кодов минимальное значение n выбирается по разнымпричинам—эффективность использования полосы пропускания и простота системы. Если при выборе n используется предел Хэмминга, то n следует выбрать равным 7. В то же время размерность полученного кода (7,2) не соответствует указанным выше требованиям t = 2 и
n-кортежей в матрице будет табулирован. Минимальное значение n нас интересует потому, что при каждом увеличении n на единицу число n-кортежей в нормальной матрице удваивается. Это условие, разумеется, диктуется только соображениями удобства использования таблицы. Для реальных прикладных кодов минимальное значение n выбирается по разнымпричинам—эффективность использования полосы пропускания и простота системы. Если при выборе n используется предел Хэмминга, то n следует выбрать равным 7. В то же время размерность полученного кода (7,2) не соответствует указанным выше требованиям t = 2 и ![]() . Чтобы увидеть это, следует ввести другую верхнюю границу возможностей кода в коррекции t-битовых ошибок (или
. Чтобы увидеть это, следует ввести другую верхнюю границу возможностей кода в коррекции t-битовых ошибок (или ![]() ) Эта граница, называемая предел Плоткина [7], определяется следующим образом.
) Эта граница, называемая предел Плоткина [7], определяется следующим образом.
![]() (6.54)
(6.54)
Вообще, линейный код (n, k) должен удовлетворять всем перечисленным выше условиям, включая возможности коррекции ошибок (или минимальное расстояние). Для высокоскоростных кодов из удовлетворения предела Хэмминга следует удовлетворение предела Плоткина; это справедливо, например, для рассмотренного ранее кода (127,106). Для кодов с низкими скоростями передачи существует обходной путь удовлетворения названных требований [7]. Поскольку в нашем примере речь идет именно о таких кодах, важно оценить их возможности в коррекции ошибок с помощью предела Плоткина. Поскольку ![]() , из уравнения (6.53) получаем, что n должно быть равно 8; следовательно, для удовлетворения всех требований, поставленных в этом примере, минимальная размерность кода равна (8,2). Можно ли практически использовать подобный код (8,2)? Этого делать не стоит, поскольку это потребует слишком большой полосы пропускания; лучше выбрать более эффективный код. Данный код мы используем только с методической целью, единственным его преимуществом являются удобные размеры его нормальной матрицы.
, из уравнения (6.53) получаем, что n должно быть равно 8; следовательно, для удовлетворения всех требований, поставленных в этом примере, минимальная размерность кода равна (8,2). Можно ли практически использовать подобный код (8,2)? Этого делать не стоит, поскольку это потребует слишком большой полосы пропускания; лучше выбрать более эффективный код. Данный код мы используем только с методической целью, единственным его преимуществом являются удобные размеры его нормальной матрицы.
6.6.3. Разработка кода (8, 2)
Ответ на вопрос, как выбираются кодовые слова из пространства ![]() 8-кортежей, неоднозначен, хотя определенные ограничения выбора все же существуют. Ниже перечислены некоторые моменты, которые могут указать наилучшее решение.
8-кортежей, неоднозначен, хотя определенные ограничения выбора все же существуют. Ниже перечислены некоторые моменты, которые могут указать наилучшее решение.
1. Количество кодовых слов ![]() .
.
2. Среди кодовых слов должен быть нулевой вектор.
3 Следует учесть свойство замкнутости — сумма двух любых кодовых слов в пространстве должна давать кодовое слово из этого же пространства.
4. Каждое кодовое слово содержит 8 двоичных разрядов.
Поскольку ![]() , весовой коэффициент каждого кодового слова (за исключением нулевого) также должен быть не менее 5 (в силу свойства замкнутости). Весовой коэффициент вектора определяется как число ненулевых компонентов этого вектора.
, весовой коэффициент каждого кодового слова (за исключением нулевого) также должен быть не менее 5 (в силу свойства замкнутости). Весовой коэффициент вектора определяется как число ненулевых компонентов этого вектора.
5. Предположим, что код является систематическим; значит, 2 крайних правых бита каждого кодового слова являются соответствующими битами сообщения.
Далее предлагается вариант набора кодовых слов, удовлетворяющих всем перечисленным выше требованиям.
Сообщения Кодовые слова
|
00 |
00000000 |
|
01 |
11110001 |
|
10 |
00111110 |
|
11 |
11001111 |
Создание набора кодовых слов может выполняться совершенно произвольно; нужно только неуклонно следовать свойствам весовых коэффициентов и придерживаться систематической формы кода. Выбор первых нескольких кодовых слов обычно очень прост. Далее процесс, как правило, усложняется и возможность выбора все больше ограничивается за счет свойства замкнутости.
6.6.4. Соотношение между обнаружением и исправлением ошибок
Для кодовой системы (8,2), выбранной в предыдущем разделе, матрицу генератора ![]() можно записать в следующем виде.
можно записать в следующем виде.

Декодирование начинается с расчета синдрома, что можно представлять как изучение "симптомов" ошибки. Для кода (п, k) ![]() -битовый синдром S является произведением принятого n-битового вектора r и транспонированной проверочной матрицы Н размерностью
-битовый синдром S является произведением принятого n-битового вектора r и транспонированной проверочной матрицы Н размерностью ![]() . Проверочная матрица Н построена таким образом, что строки матрицы G ортогональны строкам матрицы Н, т.е.
. Проверочная матрица Н построена таким образом, что строки матрицы G ортогональны строкам матрицы Н, т.е.![]() . В нашем примере кода (8, 2) S — это 6-битовый вектор, а Н — матрица размером 6 х 8, где
. В нашем примере кода (8, 2) S — это 6-битовый вектор, а Н — матрица размером 6 х 8, где
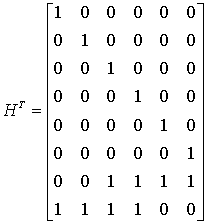
Синдром для каждой ошибочной комбинации можно рассчитать, исходя из уравнения (6.37), а именно
![]()
![]() ,
,
где ![]() — один из
— один из ![]() синдромов, а
синдромов, а ![]() — один из 64 образующих элементов классов смежности (ошибочных комбинаций) в нормальной матрице. На рис. 6.15, помимо самой нормальной матрицы, показаны все 64 синдрома для кода (8, 2). Набор синдромов рассчитывался с помощью уравнения (6.37); позиции произвольной строки (смежный класс) нормальной матрицы имеют один и тот же синдром. Исправление искаженного кодового слова осуществляется путем расчета его синдрома и локализации ошибочной комбинации, соответствующей этому синдрому. В заключение ошибочная комбинация прибавляется (по модулю 2) к поврежденному кодовому слову, что и дает правильное кодовое слово. Из уравнения (6.49), повторно приведенного ниже, видно, что между возможностями обнаружения и исправления ошибок существует некий компромисс, ограничиваемый расстоянием.
— один из 64 образующих элементов классов смежности (ошибочных комбинаций) в нормальной матрице. На рис. 6.15, помимо самой нормальной матрицы, показаны все 64 синдрома для кода (8, 2). Набор синдромов рассчитывался с помощью уравнения (6.37); позиции произвольной строки (смежный класс) нормальной матрицы имеют один и тот же синдром. Исправление искаженного кодового слова осуществляется путем расчета его синдрома и локализации ошибочной комбинации, соответствующей этому синдрому. В заключение ошибочная комбинация прибавляется (по модулю 2) к поврежденному кодовому слову, что и дает правильное кодовое слово. Из уравнения (6.49), повторно приведенного ниже, видно, что между возможностями обнаружения и исправления ошибок существует некий компромисс, ограничиваемый расстоянием.
![]()
Здесь ![]() представляет количество исправляемых битовых ошибок, а
представляет количество исправляемых битовых ошибок, а ![]() — количество обнаруживаемых битовых ошибок, причем
— количество обнаруживаемых битовых ошибок, причем ![]() . В коде (8,2) возможны следующие компромиссы между этими двумя величинами.
. В коде (8,2) возможны следующие компромиссы между этими двумя величинами.
Обнаружение ![]() Исправление
Исправление![]()
|
2 |
2 |
|
3 |
1 |
|
4 |
0 |
Из данной таблицы видно, что код (8,2) можно использовать только для исправления ошибок; это означает, что код вначале обнаруживает ![]() ошибки, после чего они исправляются. Если пожертвовать возможностью исправления и использовать код для исправления только однобитовых ошибок, то возможность обнаружения ошибки возрастает до
ошибки, после чего они исправляются. Если пожертвовать возможностью исправления и использовать код для исправления только однобитовых ошибок, то возможность обнаружения ошибки возрастает до ![]() ошибок. И наконец, если целиком отказаться от исправления ошибок, то декодер сможет обнаруживать ошибки с
ошибок. И наконец, если целиком отказаться от исправления ошибок, то декодер сможет обнаруживать ошибки с ![]() . В случае, если ошибки только обнаруживаются, реализация декодера будет очень простой: производится вычисление синдрома и обнаруживается ошибка при появлении любого ненулевого синдрома.
. В случае, если ошибки только обнаруживаются, реализация декодера будет очень простой: производится вычисление синдрома и обнаруживается ошибка при появлении любого ненулевого синдрома.
Для исправления однобитовых ошибок декодер может реализовываться с логическими элементами [4], подобными приведенным на рис. 6.12, где принятый вектор кода ![]() поступал в схему в двух точках. В верхней части рисунка принятые символы поступают на логический элемент исключающего ИЛИ, который и определяет синдром. Для любого принятого вектора синдром рассчитывается согласно уравнению (6.35).
поступал в схему в двух точках. В верхней части рисунка принятые символы поступают на логический элемент исключающего ИЛИ, который и определяет синдром. Для любого принятого вектора синдром рассчитывается согласно уравнению (6.35).
![]()
![]()
| 000000 | 1. | 00000000 | 11110001 | 00111110 | 11001111 |
| 111100 | 2. | 00000001 | 11110000 | 00111111 | 11001110 |
| 001111 | 3. | 00000010 | 11110011 | 00111100 | 11001101 |
| 000001 | 4. | 00000100 | 11110101 | 00111010 | 11001011 |
| 000010 | 5. | 00001000 | 11111001 | 00110110 | 11000111 |
| 000100 | 6. | 00010000 | 11100001 | 00101110 | 11011111 |
| 001000 | 7. | 00100000 | 11010001 | 00011110 | 11101111 |
| 010000 | 8. | 01000000 | 10110001 | 01111110 | 10001111 |
| 100000 | 9. | 10000000 | 01110001 | 10111110 | 01001111 |
| 110011 | 10. | 00000011 | 11110010 | 00111101 | 11001100 |
| 111101 | 11. | 00000101 | 11110100 | 00111011 | 11001010 |
| 111110 | 12. | 00001001 | 11111000 | 00110111 | 11000110 |
| 111000 | 13. | 00010001 | 11100000 | 00101111 | 11011110 |
| 110100 | 14. | 00100001 | 11010000 | 00011111 | 11101110 |
| 101100 | 15. | 01000001 | 01110000 | 01111111 | 10001110 |
| 011100 | 16. | 10000001 | 11110111 | 10111111 | 01001110 |
| 001110 | 17. | 00000110 | 11111011 | 00111000 | 11001001 |
| 001101 | 18. | 00001010 | 11111011 | 00110100 | 11000101 |
| 001011 | 19. | 00010010 | 11100011 | 00101100 | 11011101 |
| 000111 | 20. | 00100010 | 11010011 | 00011100 | 11101101 |
| 011111 | 21. | 01000010 | 10110011 | 01111100 | 10001101 |
| 101111 | 22. | 10000010 | 01110011 | 10111100 | 01001101 |
| 000011 | 23. | 00001100 | 11111101 | 00110010 | 11000011 |
| 000101 | 24. | 00010100 | 11100101 | 00101010 | 11011011 |
| 001001 | 25. | 00100100 | 11010101 | 00011010 | 11101011 |
| 010001 | 26. | 01000100 | 10110101 | 01111010 | 10001011 |
| 100001 | 27. | 10000100 | 01110101 | 10111010 | 01001011 |
| 000110 | 28. | 00011000 | 11101111 | 00001110 | 11010111 |
| 001010 | 29. | 00101000 | 11011001 | 00010110 | 11100111 |
| 010010 | 30. | 01001000 | 10111001 | 01110110 | 10000111 |
| 100010 | 31. | 10001000 | 01111001 | 10110110 | 01000111 |
| 001100 | 32. | 00110000 | 01000001 | 00001110 | 11111111 |
| 010100 | 33. | 01010000 | 10100001 | 01101110 | 10011111 |
| 100100 | 34. | 10010000 | 01100001 | 10101110 | 01011111 |
| 011000 | 35. | 01100000 | 10010001 | 01011110 | 10101111 |
| 101000 | 36. | 10100000 | 01010001 | 10011110 | 01101111 |
| 110000 | 37. | 11000000 | 00110001 | 11111110 | 00001111 |
| 110010 | 38. | 00000111 | 11100010 | 00111001 | 01101000 |
| 110111 | 39. | 00010011 | 11100010 | 00101101 | 11011100 |
| 111011 | 40. | 00100011 | 11010010 | 00011101 | 11101100 |
| 100011 | 41. | 01000011 | 10110010 | 01111101 | 10001100 |
| 010011 | 42. | 11000011 | 01110010 | 10111101 | 01001100 |
| 111111 | 43. | 10000011 | 11111100 | 00110011 | 11000010 |
| 111001 | 44. | 00010101 | 11100100 | 00101011 | 11011010 |
| 110101 | 45. | 00100101 | 11010100 | 00011011 | 11101010 |
| 101101 | 46. | 01000101 | 10110100 | 01111011 | 10001010 |
| 011101 | 47. | 10000101 | 01110100 | 10111011 | 01001010 |
| 011110 | 48. | 01000110 | 10110111 | 01111000 | 10001001 |
| 101110 | 49. | 10000110 | 01110111 | 10111000 | 01001001 |
| 100101 | 50. | 10010100 | 01100101 | 10101010 | 01011011 |
| 011001 | 51. | 01100100 | 10010101 | 01011010 | 10101011 |
| 110001 | 52. | 11000100 | 00110101 | 11111010 | 00001011 |
| 011010 | 53. | 01101000 | 10011001 | 01010110 | 10100111 |
| 010110 | 54. | 01011000 | 10101001 | 01100110 | 10010111 |
| 100110 | 55. | 10011000 | 01101001 | 10100110 | 01010111 |
| 101010 | 56. | 10101000 | 01011001 | 10010110 | 01100111 |
| 101001 | 57. | 10100100 | 01010101 | 10011010 | 01101011 |
| 100111 | 58. | 10100010 | 01010011 | 10011100 | 01101101 |
| 010111 | 59. | 01100010 | 10010011 | 01011100 | 10101101 |
| 010101 | 60. | 01010100 | 10100101 | 01101010 | 10011011 |
| 011011 | 61. | 01010010 | 10100011 | 01101100 | 10011101 |
| 110110 | 62. | 00101001 | 11011000 | 00010111 | 11100110 |
| 111010 | 63. | 00011001 | 11101000 | 00100111 | 11010110 |
| 101011 | 64. | 10010010 | 01100011 | 10101100 | 01011101 |
Рис. 6.15. Синдромы и нормальная матрица для кода(8, 2)
С помощью значений Нгдля кода (8,2), необходимо так соединить элементы схемы (подобно тому, как это было сделано на рис. 6.12), чтобы вычислялось следующее.
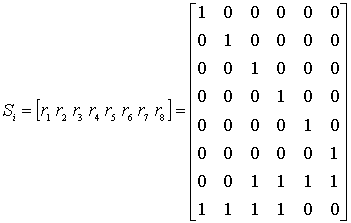
Каждая из цифр ![]() определяет синдром
определяет синдром ![]() , связанный с входным принятым вектором кода следующим образом.
, связанный с входным принятым вектором кода следующим образом.
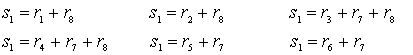
Для реализации схемы декодера для кода (8,2), подобной представленной на рис. 6.12, необходимо, чтобы восемь принятых разрядов соединялись с шестью сумматорами по модулю 2 (см. выше), выдающими цифры синдрома. Соответственно, потребуются и другие модификации схемы, приведенной на рисунке.
Если декодер реализован так, чтобы исправлять только однобитовые ошибки (т.е. ![]() ), это эквивалентно ограничению матрицы на рис. 6.15 девятью первыми классами смежности, а исправление ошибок происходит, только когда один из восьми синдромов соответствует появлению однобитовой ошибки. Затем схема декодирования (подобная изображенной на рис. 6.12) преобразует синдром в соответствующую ошибочную комбинацию. Далее ошибочная комбинация прибавляется по модулю 2 к "потенциально" искаженному принятому вектору, т.е. происходит исправление ошибки. Для проверки ситуаций, когда синдром не равен нулю, а схемы коррекции нет, нужно вводить дополнительные логические элементы (например, для однобитовых ошибок, соответствующих синдромам 10-64).
), это эквивалентно ограничению матрицы на рис. 6.15 девятью первыми классами смежности, а исправление ошибок происходит, только когда один из восьми синдромов соответствует появлению однобитовой ошибки. Затем схема декодирования (подобная изображенной на рис. 6.12) преобразует синдром в соответствующую ошибочную комбинацию. Далее ошибочная комбинация прибавляется по модулю 2 к "потенциально" искаженному принятому вектору, т.е. происходит исправление ошибки. Для проверки ситуаций, когда синдром не равен нулю, а схемы коррекции нет, нужно вводить дополнительные логические элементы (например, для однобитовых ошибок, соответствующих синдромам 10-64).
Если декодер реализован так, чтобы исправлять одно- и двухбитовые ошибки (а это означает, что обнаруживается, а затем исправляется ![]() ошибки), это эквивалентно ограничению матрицы (рис. 6.15) 37 классом смежности. Хотя код (8,2) может исправлять некоторые комбинации трехбитовых ошибок, соответствующие образующим элементам классов смежности под номерами 38-64, декодер чаще всего реализуется как декодер с ограниченным расстоянием; это означает, что он исправляет все искаженные символы, содержащие ошибку только в t или меньшем числе бит. Нереализованные возможности используются для некоторого улучшения процесса обнаружения ошибок. Как и ранее, реализация декодера подобна схеме, изображенной на рис. 6.12.
ошибки), это эквивалентно ограничению матрицы (рис. 6.15) 37 классом смежности. Хотя код (8,2) может исправлять некоторые комбинации трехбитовых ошибок, соответствующие образующим элементам классов смежности под номерами 38-64, декодер чаще всего реализуется как декодер с ограниченным расстоянием; это означает, что он исправляет все искаженные символы, содержащие ошибку только в t или меньшем числе бит. Нереализованные возможности используются для некоторого улучшения процесса обнаружения ошибок. Как и ранее, реализация декодера подобна схеме, изображенной на рис. 6.12.
6.6.5. Взгляд на код сквозь нормальную матрицу
В контексте рис. 6.15 код (8,2) удовлетворяет пределу Хэмминга. Иными словами, из нормальной матрицы можно видеть, что код (8,2) способен исправлять все комбинации одно- и двухбитовых ошибок. Рассмотрим следующее: пусть передача происходит по каналу, который всегда вносит ошибки в виде пакета 3-битовых ошибок, и, следовательно, нет необходимости в исправлении одно- или двухбитовых ошибок. Можно ли настроить образующие элементы классов смежности так, чтобы они соответствовали только трехбитовым ошибкам? Нетрудно определить, что в последовательности из 8 бит существует  возможностей произвести трехбитовую ошибку. Если единственным нашим желанием является коррекция только этих 56 комбинаций трехбитовых ошибок, то кажется, что в нормальной матрице достаточно места (достаточное количество классов смежности), поскольку всего в ней имеется 64 строки. Будет ли это работать? Однозначно, нет. Для любого кода главным параметром, определяющим способности кода к коррекции ошибок, является
возможностей произвести трехбитовую ошибку. Если единственным нашим желанием является коррекция только этих 56 комбинаций трехбитовых ошибок, то кажется, что в нормальной матрице достаточно места (достаточное количество классов смежности), поскольку всего в ней имеется 64 строки. Будет ли это работать? Однозначно, нет. Для любого кода главным параметром, определяющим способности кода к коррекции ошибок, является ![]() . Для кода (8, 2)
. Для кода (8, 2) ![]() , а это означает, что возможно исправление только 2-битовых ошибок.
, а это означает, что возможно исправление только 2-битовых ошибок.
Как стандартная матрица может помочь разобраться, почему эта схема не будет работать? Чтобы осуществить исправление x-битовых ошибок для группы x-битовых ошибочных комбинаций, полная группа векторов с весовым коэффициентом х должна быть классом смежности, т.е. они должны находиться только в крайнем левом столбце. На рис. 6.15 можно видеть, что все векторы с весовым коэффициентом 1 и 2 находятся в крайнем левом столбце нормальной матрицы и нигде более. Если мы даже и втиснем все векторы с весовым коэффициентом 3 в строку со второго номера по 57-й, увидим, что некоторые из этих векторов снова появятся в матрице где-нибудь еще (что нарушит основное свойство нормальной матрицы). На рис. 6.15 затененные блоки обозначают те 56 векторов, которые имеют весовой коэффициент 3. Взгляните на образующие элементы классов смежности, представляющие 3-битовые ошибочные комбинации, в строках 38, 41-43, 46-49 и 52 нормальной матрицы. Потом посмотрите на позиций в тех же строках в крайнем правом столбце, где затененные блоки показывают другие векторы с весовым коэффициентом 3. Видите некоторую неопределенность, существующую для каждой строки, о которых говорилось выше, и понятно ли теперь, почему нельзя исправить все 3-битовые ошибочные комбинации с помощью кода (8,2)? Допустим, декодер принял вектор с весовым коэффициентом 3 — 11001000, размещенный в строке 38 в крайнем правом столбце. Это искаженное кодовое слово могло появиться, во-первых, при передаче кодового слова 1 1 0 0 1 1 1 1, искаженного 3-битовой ошибочной комбинацией 0 0 0 0 0 1 1 1, а во-вторых, при передаче кодового слова 00000000, искаженного 3-битовой ошибочной комбинацией 1 1 0 0 1 0 0 0.
6.7. Циклические коды
Важным подклассом линейных блочных кодов являются двоичные циклические коды (cyclic codes). Код легко реализуется на регистре сдвига с обратной связью; на подобных регистрах сдвига с обратной связью вычисляется синдром; алгебраическая структура циклического кода естественным образом позволяет эффективно реализовать методы декодирования. Итак, линейный код (n, k) называется циклическим, если он обладает следующим свойством. Если n-кортеж ![]() является кодовым словом в подпространстве S, тогда
является кодовым словом в подпространстве S, тогда ![]() , полученный из U с помощью циклического сдвига, также является кодовым словом в S. Или, вообще,
, полученный из U с помощью циклического сдвига, также является кодовым словом в S. Или, вообще, ![]() , полученный i циклическими сдвигами, является кодовым словом в S.
, полученный i циклическими сдвигами, является кодовым словом в S.
Компоненты кодового слова ![]() можно рассматривать как коэффициенты полинома
можно рассматривать как коэффициенты полинома ![]() .
.
![]() (6.54)
(6.54)
Полиномиальную функцию U(X) можно рассматривать как "заполнитель" разрядов кодового слова U, т.е. вектор n-кортежа описывается полиномом степени ![]() или меньше. Наличие или отсутствие каких-либо членов в полиноме означает наличие 1 или 0 в соответствующем месте n-кортежа. Если
или меньше. Наличие или отсутствие каких-либо членов в полиноме означает наличие 1 или 0 в соответствующем месте n-кортежа. Если ![]() -й компонент отличен от нуля, порядок полинома равен
-й компонент отличен от нуля, порядок полинома равен ![]() . Удобство такого полиномиального представления кодового слова станет более понятным по мере дальнейшего обсуждения алгебраических свойств циклических кодов.
. Удобство такого полиномиального представления кодового слова станет более понятным по мере дальнейшего обсуждения алгебраических свойств циклических кодов.
6.7.1. Алгебраическая структура циклических кодов
В кодовых словах, выраженных в полиномиальной форме, циклическая природа кода проявляется следующим образом. Если U(X) является кодовым словом, представленным полиномом порядка ![]() , то
, то ![]() — остаток от деления
— остаток от деления ![]()
![]() на
на ![]() — также является кодовым словом. Иными словами,
— также является кодовым словом. Иными словами,
![]() (6.55,a)
(6.55,a)
или, умножая обе части уравнения на ![]() ,
,
![]() , (6.55,б)
, (6.55,б)
что в модульной арифметике можно описать следующим образом.
![]() по модулю
по модулю ![]() (6.56)
(6.56)
Здесь "х по модулю у" означает остаток от деления х на у. Ниже справедливость выражения (6.56) демонстрируется для случая i = 1.
![]()
![]()
К последнему выражению прибавим и вычтем ![]() или, поскольку мы пользуемся арифметическими операциями по модулю 2, можем прибавить
или, поскольку мы пользуемся арифметическими операциями по модулю 2, можем прибавить ![]() дважды.
дважды.
![]()
Поскольку порядок ![]() равен
равен ![]() , этот полином не делится на
, этот полином не делится на ![]() . Таким образом, используя уравнение (6.55,а), можно записать следующее.
. Таким образом, используя уравнение (6.55,а), можно записать следующее.
![]() по модулю
по модулю ![]()
Обобщая, приходим к уравнению (6.56).
![]() по модулю
по модулю ![]()
Пример 6.7. Циклический сдвиг вектора кода
Пусть U = 1 1 0 1 для n = 4. Выразите кодовое слово в полиномиальной форме и, используя уравнение (6.56), выполните третий циклический сдвиг кодового слова.
Решение
![]()
![]() полином записан в порядке возрастания степени
полином записан в порядке возрастания степени
![]() , где
, где ![]()
Разделим ![]() на
на ![]() и найдем остаток, используя полиномиальное деление.
и найдем остаток, используя полиномиальное деление.
| X6 + X4 + X3 | X4 + 1 | ||
| X2 + 1 остаток U(3)(X) | |||
| X6 + X2 | + 1 | ||
| X4 + X3 + X2 X4 | |||
| X3 + X2 + 1 | |||
Записываем остаток в порядке возрастания степеней: 1 + X2 + X3, кодовое слово U=1011 представляет собой три циклических сдвига U= 1 1 0 1. Напомним, что для двоичных кодов операция сложения выполняется по модулю 2, так что + 1 = -1, и, следовательно, в расчетах знаки "минус" не отражены.
6.7.2. Свойства двоичного циклического кода
С помощью полиномиального генератора можно создать циклический код, почти так же как создавались блочные коды с использованием матрицы генератора. Полиномиальный генератор g(X) для циклического кода (n, k) является единственным и имеет следующий вид.
![]() (6.57)
(6.57)
Здесь ![]() и gp должны быть равны 1. Каждый полином кодового слова в подпространстве имеет вид
и gp должны быть равны 1. Каждый полином кодового слова в подпространстве имеет вид ![]() , где U(X) — полином степени
, где U(X) — полином степени ![]() или меньше. Следовательно, полином сообщения т(Х) будет иметь следующий вид.
или меньше. Следовательно, полином сообщения т(Х) будет иметь следующий вид.
![]() (6.58)
(6.58)
Всего в коде (n, k) существует ![]() полинома кодовых слов и
полинома кодовых слов и ![]() вектора кода. Поэтому на каждый вектор кода должен приходиться один полином кодового слова.
вектора кода. Поэтому на каждый вектор кода должен приходиться один полином кодового слова.
![]()
или
![]()
Отсюда следует, что g(X), как показано в уравнении (6.57), должен иметь степень ![]() , и каждый полином кодового слова в коде (п, k) можно выразить следующим образом.
, и каждый полином кодового слова в коде (п, k) можно выразить следующим образом.
![]() (6.59)
(6.59)
U будет считаться действительным кодовым словом из подпространства S тогда и только тогда, когда U(Х) делится на g(X) без остатка.
Полиномиальный генератор g(X) циклического кода (n,k) является множителем ![]() , т.е.
, т.е. ![]() . Например,
. Например,
![]()
Используя ![]() как полиномиальный генератор степени
как полиномиальный генератор степени ![]() , можно получить циклический код (n, k) = (7,4). Или же с помощью
, можно получить циклический код (n, k) = (7,4). Или же с помощью ![]() , где
, где ![]() , можно получить циклический код (7,3). Итак, если g(X) является полиномом степени
, можно получить циклический код (7,3). Итак, если g(X) является полиномом степени ![]() и множителем
и множителем ![]() , то g(X) однозначным образом генерирует циклический код (n, k).
, то g(X) однозначным образом генерирует циклический код (n, k).
6.7.3. Кодирование в систематической форме
В разделе 6.4.5 мы ввели понятие систематическая форма и рассмотрели уменьшение сложности, которое делает эту форму кодирования более привлекательной. Теперь мы хотим использовать некоторые алгебраические свойства циклического кода для развития процедуры систематического кодирования. Итак, вектор сообщения можно записать в полиномиальной форме следующим образом.
![]() (6.60)
(6.60)
В систематической форме символы сообщения используются как часть кодового слова. Мы можем сдвинуть символы сообщения в k крайних правых разряда кодового слова, а затем прибавить биты четности, разместив их в крайние левые ![]() разряды. Таким образом, осуществляется алгебраическая манипуляция полиномом сообщения, и он оказывается сдвинутым вправо на
разряды. Таким образом, осуществляется алгебраическая манипуляция полиномом сообщения, и он оказывается сдвинутым вправо на ![]() позиций. Если теперь умножить т(Х) на
позиций. Если теперь умножить т(Х) на ![]() , мы получим сдвинутый вправо полином сообщения.
, мы получим сдвинутый вправо полином сообщения.
![]() (6.61)
(6.61)
Если далее разделить уравнение (6.61) на g(X), результат можно представить в следующем виде.
![]() (6.62)
(6.62)
Здесь остаток р(Х) записывается следующим образом.
![]()
Также можно записать следующее.
![]() по модулю
по модулю ![]() (6.63)
(6.63)
Прибавляя р(Х) к обеим частям уравнения (6.62) и используя сложение по модулю 2, получаем следующее.
![]() (6.64)
(6.64)
Левая часть уравнения (6.64) является действительным полиномом кодового слова, так как это полином степени ![]() или менее, который при делении на g(X) дает нулевой остаток. Это кодовое слово можно записать через все члены полинома.
или менее, который при делении на g(X) дает нулевой остаток. Это кодовое слово можно записать через все члены полинома.
![]()
Полином кодового слова соответствует вектору кода.
![]() (6.65)
(6.65)
бит четности бит сообщения
Пример 6.8. Циклический код в систематической форме
С помощью полиномиального генератора ![]() получите систематическое кодовое слово из набора кодовых слов (7,4) для вектора сообщения m = 1 0 0 1 1.
получите систематическое кодовое слово из набора кодовых слов (7,4) для вектора сообщения m = 1 0 0 1 1.
Решение
![]()
![]()
Разделив ![]() на g(X), можно записать следующее.
на g(X), можно записать следующее.
![]()
Используя уравнение (6.64), получаем следующее.
![]()
![]()
6.7.4. Логическая схема для реализации полиномиального деления
Выше показывалось, что при циклическом сдвиге полинома кодового слова и кодировании полинома сообщения применяется операция деления полиномов друг на друга. Такие операции легко реализуются в схеме деления (регистр сдвига с обратной связью). Итак, пусть даны два полинома V(Х) и g(X), где
![]()
и
![]() ,
,
причем ![]() . Схема деления, приведенная на рис. 6.16, выполняет полиномиальное деление V(X) на g(X), определяя, таким образом, частное и остаточное слагаемое.
. Схема деления, приведенная на рис. 6.16, выполняет полиномиальное деление V(X) на g(X), определяя, таким образом, частное и остаточное слагаемое.
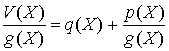
В исходном состоянии разряды регистра содержат нули. Коэффициенты V(X) поступают и продвигаются по регистру сдвига по одному за такт; начиная с коэффициентов более высокого порядка. После р-го сдвига частное на выходе равно ![]() ; это слагаемое наивысшего порядка в частном. Далее для каждого коэффициента частного
; это слагаемое наивысшего порядка в частном. Далее для каждого коэффициента частного ![]() , из делимого нужно вычитать полином
, из делимого нужно вычитать полином ![]() . Это вычитание обеспечивает обратная связь, отображенная на рис. 6.16. Разность крайних слева р слагаемых остается в делимом, а слагаемое обратной связи
. Это вычитание обеспечивает обратная связь, отображенная на рис. 6.16. Разность крайних слева р слагаемых остается в делимом, а слагаемое обратной связи ![]() формируется при каждом сдвиге схемы и отображается в виде содержимого регистра. При каждом сдвиге регистра разность смещается на один разряд; слагаемое наивысшего порядка (которое по построению схемы равно нулю) удаляется, в то время как следующий значащий коэффициент в V(Х) перемещается на его место. После всех
формируется при каждом сдвиге схемы и отображается в виде содержимого регистра. При каждом сдвиге регистра разность смещается на один разряд; слагаемое наивысшего порядка (которое по построению схемы равно нулю) удаляется, в то время как следующий значащий коэффициент в V(Х) перемещается на его место. После всех ![]() сдвигов регистра, на выход последовательно выдается частное, а остаток остается в регистре.
сдвигов регистра, на выход последовательно выдается частное, а остаток остается в регистре.
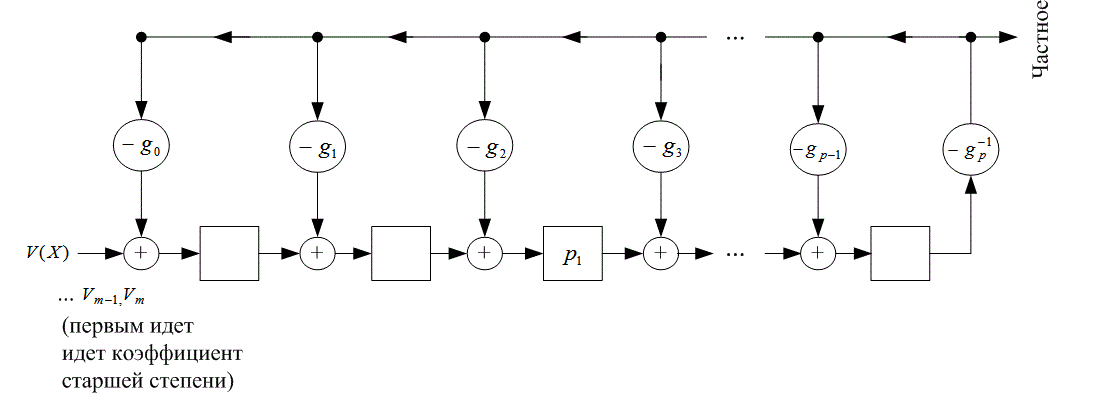
Рис.6.16. Логическая схема для реализации полиномиального деления
Пример 6.9. Схема полиномиального деления
Используя схему деления, показанную на рис. 6.16, разделите ![]()
![]() на
на ![]() ; Найдите частное и остаточное слагаемое. Сравните реализацию схемы и действия, происходящие при прямом делении полиномов.
; Найдите частное и остаточное слагаемое. Сравните реализацию схемы и действия, происходящие при прямом делении полиномов.
Решение
схема деления должна выполнить следующее действие.
![]()
необходимый регистр сдвига с обратной связью показан на рис. 6.17. Предположим, что первоначально регистр содержит нули. Схема выполнит следующие, шаги.
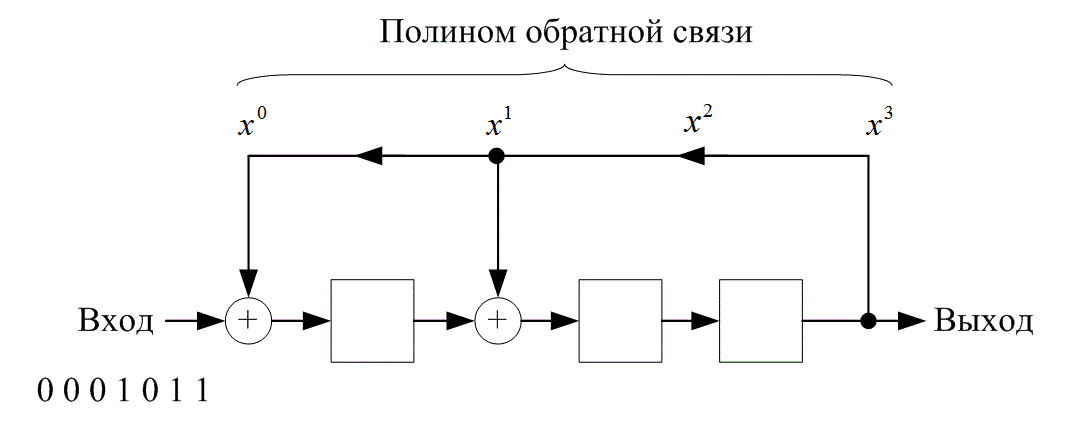
Рис. 6.17. Схема деления для примера 6.9.
Входная очередь Номер сдвига Содержимое регистра Выход и обратная связь
|
0001011 |
0 |
000 |
- |
|
000101 |
1 |
100 |
0 |
|
00010 |
2 |
110 |
0 |
|
0001 |
3 |
011 |
0 |
|
000 |
4 |
011 |
1 |
|
00 |
5 |
111 |
1 |
|
0 |
6 |
101 |
1 |
|
- |
7 |
100 |
1 |
После четвертого сдвига коэффициенты частного ![]() последовательно поступающие с выхода, выглядят как 1 1 1 1 или же полином частного имеет вид
последовательно поступающие с выхода, выглядят как 1 1 1 1 или же полином частного имеет вид ![]() . Коэффициенты остатка
. Коэффициенты остатка ![]() имеют вид 1 0 0 либо полином остатка имеет вид
имеют вид 1 0 0 либо полином остатка имеет вид ![]() . Таким образом, схема выполнила следующие вычисления.
. Таким образом, схема выполнила следующие вычисления.
![]()
Прямое деление полиномов дает результат, показанный ниже.
X6 + X5 + X3 |X3 + X + 1
обратная связь после 4-го сдвига → X6 + X4 + X3 X3+X2+X+1
обратная связь после 4-го сдвига → X5 + X4 ↑ ↑ ↑ ↑
обратная связь после 5-го сдвига → X5+ X3 + X2 4 5 6 7
регистр после 5-го сдвига → X4 + X3 + X2
обратная связь после 6-го сдвига→ X4 + X2 + X
регистр после 6-го сдвига → X3 + X
обратная связь после 7-го сдвига → X3 + X + 1
регистр после 7-го сдвига → 1
(остаток)
6.7.5. Систематическое кодирование с (n-k) - разрядным регистром сдвига
Как было показано в разделе 6.7.3, кодирование с помощью циклического кода в систематической форме включает в себя, как результат вычисления ![]() по модулю g(X), вычисление битов четности; иными словами, деление смещенного вверх (смешенного вправо) полиномиального сообщения на полиномиальный генератор g(X). Сдвиг вверх приводит к освобождению места для битов четности, которые прибавляются к разрядам сообщения, что в результате дает вектор кода в систематической форме. Сдвиг вверх на
по модулю g(X), вычисление битов четности; иными словами, деление смещенного вверх (смешенного вправо) полиномиального сообщения на полиномиальный генератор g(X). Сдвиг вверх приводит к освобождению места для битов четности, которые прибавляются к разрядам сообщения, что в результате дает вектор кода в систематической форме. Сдвиг вверх на ![]() разрядов сообщения является тривиальной операцией и в действительности не выполняется в схеме деления. На самом деле вычисляются только биты четности; затем они помещаются на соответствующие места рядом с битами сообщения. Полином четности — это остаток от деления на полиномиальный генератор; он находится в регистре n сдвигов (
разрядов сообщения является тривиальной операцией и в действительности не выполняется в схеме деления. На самом деле вычисляются только биты четности; затем они помещаются на соответствующие места рядом с битами сообщения. Полином четности — это остаток от деления на полиномиальный генератор; он находится в регистре n сдвигов (![]() )-разрядного регистра сдвига с обратной связью, показанного на рис. 6.17. Отметим, что первые n-k сдвигов по разрядам — это просто заполнение регистра. У нас не может появиться никакой обратной связи, пока не будет заполнен крайний справа разряд; следовательно, мы можем сократить цикл деления, загружая входящие данные с выхода последнего разряда, как показано на рис. 6.18. Слагаемое обратной связи в крайнем левом разряде является суммой входящих данных и крайнего правого разряда. Гарантия создания этой суммы — обеспечение
)-разрядного регистра сдвига с обратной связью, показанного на рис. 6.17. Отметим, что первые n-k сдвигов по разрядам — это просто заполнение регистра. У нас не может появиться никакой обратной связи, пока не будет заполнен крайний справа разряд; следовательно, мы можем сократить цикл деления, загружая входящие данные с выхода последнего разряда, как показано на рис. 6.18. Слагаемое обратной связи в крайнем левом разряде является суммой входящих данных и крайнего правого разряда. Гарантия создания этой суммы — обеспечение ![]() для произвольного полиномиального генератора g(X). Соединения схемы обратной связи соответствуют коэффициентам полиномиального генератора, которые записываются в следующем виде.
для произвольного полиномиального генератора g(X). Соединения схемы обратной связи соответствуют коэффициентам полиномиального генератора, которые записываются в следующем виде.
![]() (6.66)
(6.66)
Следующие шаги описывают, процедуру кодирования, использующую устройство, изображенное на рис. 6.18.
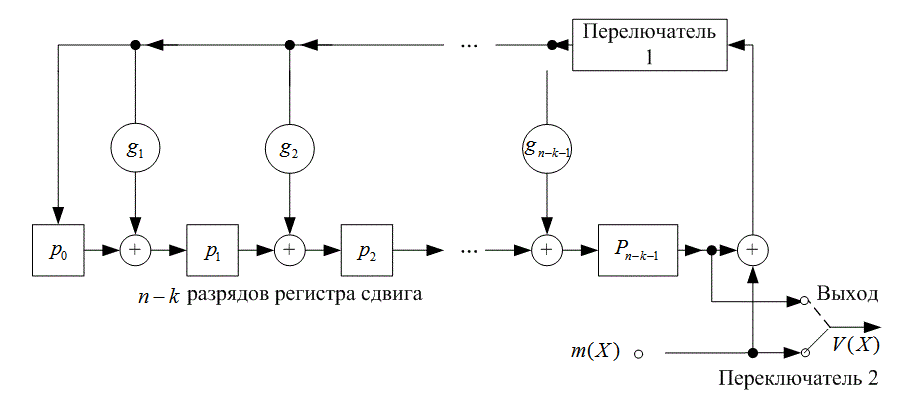
Рис. 6.18. Кодирование с помощью (п - k-разрядного регистра сдвига)
1. При первых k сдвигах ключ 1 закрыт для передачи битов сообщения в (n-k)разрядный регистр сдвига.
2. Ключ 2 установлен в нижнее положение для передачи битов сообщения на выходной регистр в течение первых k сдвигов.
3. После передачи k-го бита сообщения ключ 1 открывается, а ключ 2 переходит вверхнее положение.
4. При остальных n-k сдвигах происходит очищение кодирующих регистров, биты четности перемещаются на выходной регистр.
5. Общее число сдвигов равно n, и содержимое выходного регистра представляет собой полином кодового слова ![]() .
.
Пример 6.10. Систематическое кодирование циклического кода
Используя регистр сдвига с обратной связью, показанный на рис. 6.18, кодируйте вектор сообщения m = 1 0 1 1 в кодовое слово (7,4). Полиномиальный генератор g(X) = 1 + X + X3.
Решение
![]()
![]()
![]()
![]()
![]() по модулю
по модулю ![]()
Для ![]() -разрядного регистра сдвига, показанного на рис. 6.19, действия будут следующими.
-разрядного регистра сдвига, показанного на рис. 6.19, действия будут следующими.
Входная очередь Номер сдвига Содержание регистра Выход и обратная связь
|
1011 |
0 |
000 |
- |
|
101 |
1 |
110 |
1 |
|
10 |
2 |
101 |
1 |
|
1 |
3 |
100 |
0 |
|
- |
4 |
100 |
1 |
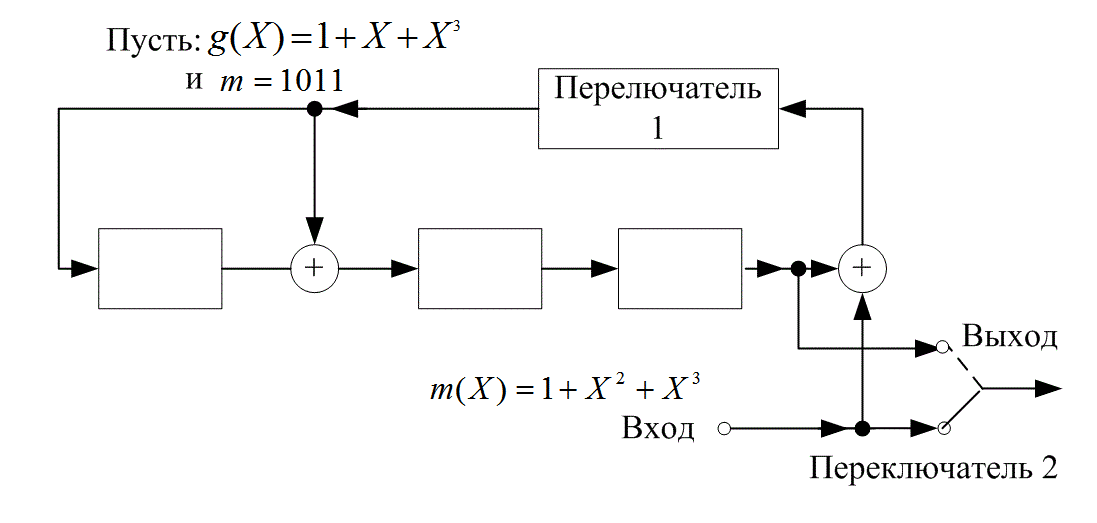
Рис. 6.19. Пример кодирования циклического кода (7, 4) с помощью (п – k)-разрядного регистра сдвига
После четвертого сдвига ключ 1 открывается, ключ 2 переходит в верхнее положение, а биты четности переходят в выходной регистр. Выходное кодовое слово U=1 0 0 1 0 1 1 или, в полиномиальной форме, U(X) = 1 + X3 + X5 + X6.
6.7.6. Обнаружение ошибок с помощью (n-k)-разрядного регистра сдвига
Передаваемое кодовое слово может быть искажено помехами, и, следовательно, принятый вектор будет искаженным вариантом переданного кодового слова. Допустим, что передается кодовое слово, имеющее в полиномиальном представлении вид U(X), a принимается вектор, в полиномиальном представлении имеющий вид Z(X). Поскольку U(X) — это полином кодового слова, он должен без остатка делиться на полиномиальный генератор g(X).
![]() (6.67)
(6.67)
Z(X), искаженную версию U(X), можно представить следующим образом.
![]() (6:68)
(6:68)
Здесь e(Х) — полином ошибочной комбинации. Декодер проверяет, является ли Z(X) полиномом кодового слова, т.е. делится ли он на g(X) без остатка. Это осуществляется путем вычисления синдрома принятого полинома. Синдром S(X) равен остатку от деления Z(X) на g(X).
![]() (6.69)
(6.69)
Здесь S(X) — полином степени ![]() или меньше. Соответственно, синдром — это
или меньше. Соответственно, синдром — это ![]() -кортеж. Используя уравнения (6.67) и (6.69), получаем следующее.
-кортеж. Используя уравнения (6.67) и (6.69), получаем следующее.
![]() (6.70)
(6.70)
Сравнивая уравнения (6.69) и (6.70), видим, что синдром S(X), полученный как Z(X) по модулю g(X), аналогичен остатку деления e(Х) на g(X). Таким образом, синдром принятого полинома Z(X) содержит информацию, необходимую для исправления ошибочной комбинации. Расчет синдрома выполняется с помощью схемы деления, почти аналогичной схеме кодирования, используемой в передатчике. Пример вычисления синдрома со сдвигом на ![]() разрядов регистра приведен на рис. 6.20 с использованием вектора кода, полученного в примере 6.10. В исходном состоянии ключ 1 закрыт, а ключ 2 открыт. Принятый вектор подается во входной регистров в котором в исходном состоянии все разряды имеют нулевое значение. После того как весь принятый вектор будет занесен в регистр сдвига, содержимое регистра — это и есть синдром. Теперь ключ 1 открывается, а ключ 2 закрывается, так что вектор синдрома теперь можно извлечь из регистра. Описанная последовательность действий имеет следующий вид.
разрядов регистра приведен на рис. 6.20 с использованием вектора кода, полученного в примере 6.10. В исходном состоянии ключ 1 закрыт, а ключ 2 открыт. Принятый вектор подается во входной регистров в котором в исходном состоянии все разряды имеют нулевое значение. После того как весь принятый вектор будет занесен в регистр сдвига, содержимое регистра — это и есть синдром. Теперь ключ 1 открывается, а ключ 2 закрывается, так что вектор синдрома теперь можно извлечь из регистра. Описанная последовательность действий имеет следующий вид.
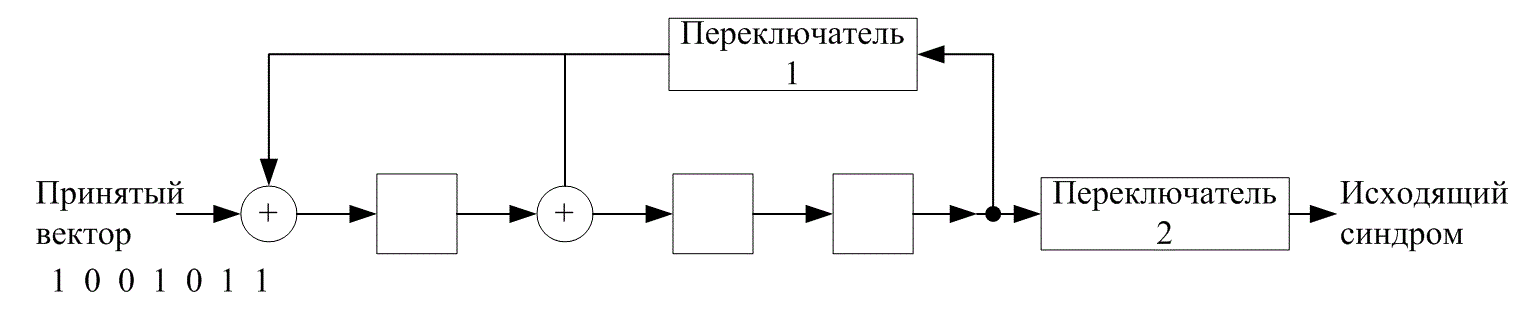
Рис. 6.20. Пример вычисления синдрома с помощью (п–k) -разрядного регистра сдвига
Входная очередь Номер сдвига Содержимое регистра
|
1001011 |
0 |
00 |
|
100101 |
1 |
100 |
|
10010 |
2 |
110 |
|
1001 |
3 |
011 |
|
100 |
4 |
011 |
|
10 |
5 |
111 |
|
1 |
6 |
101 |
|
- |
7 |
000 Синдром |
Если вектор синдрома нулевой, считается, что принятый вектор является правильным кодовым словом. Если синдром отличен от нуля, значит, обнаружена ошибка и принятый вектор — это искаженное кодовое слово; данная ошибка исправляется путем прибавления к принятому вектору вектора ошибки (указанной синдромом), т.е. аналогично процедуре, описанной в разделе 6.4.8. Этот метод декодирования хорош для простых кодов. Более сложные коды для практического использования требуют применения алгебраических методик.
6.8. Известные блочные коды
6.8.1. Коды Хэмминга
Коды Хэмминга (Hamming codes) — это простой класс блочных кодов, которые имеют следующую структуру:
![]() , (6.71)
, (6.71)
где т = 2,3,... . Минимальное расстояние этих кодов равно 3, поэтому, согласно уравнениям (6.44) и (6.47), они способны исправлять все однобитовые ошибки или определять все ошибочные комбинации из двух или менее ошибок в блоке. Декодирование с помощью синдромов особенно хорошо подходит к кодам Хэмминга. Фактически синдром можно превратить в двоичный указатель местоположения ошибки [5]. Хотя коды Хэмминга не являются слишком мощными, они принадлежат к очень ограниченному классу блочных кодов, называемых совершенными; их особенности описывались в разделе 6.5.4.
Если предположить, что используется жесткое декодирование, вероятность появления битовой ошибки можно записать с помощью уравнения (6.46).
Здесь р — вероятность ошибочного приема канального символа (вероятность перехода в двоичном симметричном канале). Вместо уравнения (6.72) мы можем использовать другое эквивалентное уравнение (это уравнение (Г. 16), которое выводится в приложении Г).
![]() (6.73)
(6.73)
На рис. 6.21 приведен график зависимости вероятности ошибки в декодированном бите от вероятности ошибки в канальном символе, на котором сравниваются разные блочные коды. Для кодов Хэмминга на графике взяты значения т = 3, 4 и 5 или (n, k) = (7,4), (15,11), (31,26). Для описания гауссового канала с использованием когерентной демодуляции сигналов BPSK, вероятность ошибки в канальном символе можно выразить через ![]() как это было сделано в уравнении (4.79).
как это было сделано в уравнении (4.79).
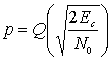 (6.74)
(6.74)
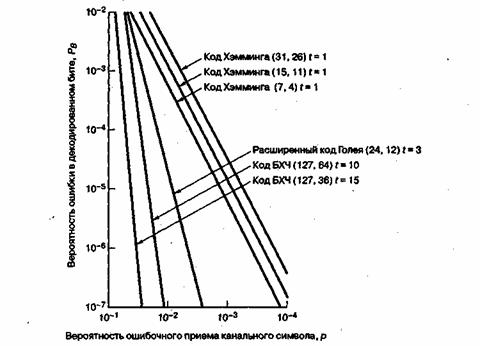
Рис. 6.21. Зависимость вероятности битовой ошибки от вероятности ошибки в канальном символе для нескольких блочных кодов
Здесь ![]() - отношение энергии кодового символа к спектральной плотности мощности шума, a Q(X) определено в уравнении (3.43). Чтобы связать
- отношение энергии кодового символа к спектральной плотности мощности шума, a Q(X) определено в уравнении (3.43). Чтобы связать ![]() с энергией бита информации на единицу плотности спектрального шума (
с энергией бита информации на единицу плотности спектрального шума (![]() ), используем следующее выражение.
), используем следующее выражение.
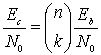 (6.75)
(6.75)
Для кодов Хэмминга уравнение (6.75) принимает следующий вид.
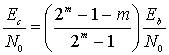 (6.76)
(6.76)
Объединяя уравнения (6.73), (6.74) и (6.76), ![]() при когерентной демодуляции сигналов BPSK в гауссовом канале можно выразить как функцию
при когерентной демодуляции сигналов BPSK в гауссовом канале можно выразить как функцию ![]() . Результаты для различных типов блочных кодов отображены на рис. 6.22. Для кодов Хэмминга взяты следующие значения (n, k) = (7,4), (15,11), (31,26).
. Результаты для различных типов блочных кодов отображены на рис. 6.22. Для кодов Хэмминга взяты следующие значения (n, k) = (7,4), (15,11), (31,26).
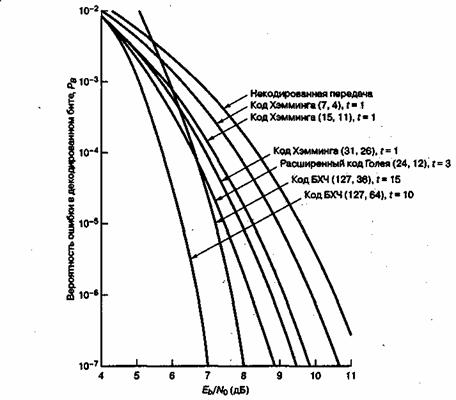
Рис. 6.22. Зависимость ![]() от
от ![]() при когерентной демодуляции сигналов BPSK в гауссовом канале для нескольких блочных кодов
при когерентной демодуляции сигналов BPSK в гауссовом канале для нескольких блочных кодов
Пример 6.11. Вероятность ошибки для модулированных и кодированных сигналов.
Кодированный сигнал с модуляцией BFSK передается по гауссовому каналу. Сигнал некогерентно обнаруживается и жестко декодируется. Найдите вероятность ошибки в декодированном бите, если кодирование осуществляется блочным кодом Хэмминга (7,4), а принятое: значение равно 20.
Решение
Сначала, используя уравнение (6.75), находим ![]() .
.
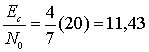
Затем для кодированного некогерентного сигнала BFSK мы можем связать вероятность ошибки в канальном символе с ![]() , подобно тому, как это было сделано в уравнении (4.96).
, подобно тому, как это было сделано в уравнении (4.96).
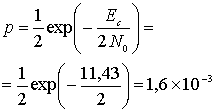
Подставляя этот результат в уравнение (6.73), получаем следующее значение вероятности ошибки в декодированном бите.
![]() ≈
≈![]()
6.8.2. Расширенный код Голея
Одним из наиболее практичных блочных кодов является двоичный расширенный код Голея (extended Golay code) (24, 12), который образован путем прибавления битов четности к совершенному коду (23, 12), известному как код Голея (Golay code). Эти дополнительные биты повышают минимальное расстояние ![]() с 7 до 8, что дает степень кодирования 1/2, реализовать которую проще (с точки зрения системного тактового генератора), чем степень кодирования кода Голея, равную 12/23. Расширенный код Голея значительно мощнее рассмотренного в предыдущем разделе кода Хэмминга. Цена, которую приходится платить за повышение эффективности, заключается в более сложном декодере и, соответственно, более широкой полосе пропускания.
с 7 до 8, что дает степень кодирования 1/2, реализовать которую проще (с точки зрения системного тактового генератора), чем степень кодирования кода Голея, равную 12/23. Расширенный код Голея значительно мощнее рассмотренного в предыдущем разделе кода Хэмминга. Цена, которую приходится платить за повышение эффективности, заключается в более сложном декодере и, соответственно, более широкой полосе пропускания.
Для расширенного кода Голея ![]() , поэтому, исходя из уравнения (6.44), можно сказать, что код гарантирует исправление всех трехбитовых ошибок. Кроме того, декодер можно сконструировать так, чтобы он исправлял некоторые комбинации с четырьмя ошибками. Поскольку исправить можно только 16,7% комбинаций с четырьмя ошибками, декодер, для упрощения, обычно реализуется для исправления только трехбитовых ошибочных комбинаций [5]. Если предположить жесткое декодирование, то вероятность битовой ошибки для расширенного кода Голея можно представить как функцию вероятности p ошибки в канальном символе (см. уравнение (6.46)).
, поэтому, исходя из уравнения (6.44), можно сказать, что код гарантирует исправление всех трехбитовых ошибок. Кроме того, декодер можно сконструировать так, чтобы он исправлял некоторые комбинации с четырьмя ошибками. Поскольку исправить можно только 16,7% комбинаций с четырьмя ошибками, декодер, для упрощения, обычно реализуется для исправления только трехбитовых ошибочных комбинаций [5]. Если предположить жесткое декодирование, то вероятность битовой ошибки для расширенного кода Голея можно представить как функцию вероятности p ошибки в канальном символе (см. уравнение (6.46)).
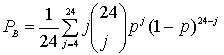 (6.77)
(6.77)
График зависимости (6.77) показан на рис. 6.21; вероятность появления ошибки для расширенного кода Голея значительно меньше, чем у кодов Хэмминга. Исходя из уравнений (6.77), (6,74) и (6.75), можно связать ![]() с
с ![]() для сигнала BPSK в гауссовом канале с кодированием расширенным кодом Голея. Результаты показаны на рис. 6.22.
для сигнала BPSK в гауссовом канале с кодированием расширенным кодом Голея. Результаты показаны на рис. 6.22.
6.8.3. Коды БХЧ
Коды Боуза-Чоудхури-Хоквенгема (Bose-Chadhuri-Hocquenghem — ВСН, БХЧ) являются результатом обобщения кодов Хэмминга, которое позволяет исправлять множественные ошибки. Они составляют мощный класс циклических кодов, который обеспечивает достаточную свободу выбора длины блока, степени кодирования, размеров алфавита и возможностей коррекции ошибок. В табл. 6.4 приводятся наиболее часто употребляемые при создании кодов БХЧ генераторы ![]() [8] с разными значениями n, k и t для блоков длиной до 255. Коэффициенты
[8] с разными значениями n, k и t для блоков длиной до 255. Коэффициенты ![]() представлены восьмеричными числами, оформленными так, что при преобразовании их в двоичные символы крайние правые разряды отвечают коэффициенту нулевой степени в
представлены восьмеричными числами, оформленными так, что при преобразовании их в двоичные символы крайние правые разряды отвечают коэффициенту нулевой степени в ![]() . С помощью табл. 6.4 можно легко проверить свойство циклического кода — полиномиальный генератор имеет порядок
. С помощью табл. 6.4 можно легко проверить свойство циклического кода — полиномиальный генератор имеет порядок ![]() . Коды БХЧ очень важны, поскольку при блоках, длина которых равна порядка несколько сотен, коды БХЧ превосходят своими качествами все другие блочные коды с той же длиной блока и степенью кодирования. В наиболее часто применяемых кодах БХЧ используется двоичный алфавит и блок кодового слова длиной
. Коды БХЧ очень важны, поскольку при блоках, длина которых равна порядка несколько сотен, коды БХЧ превосходят своими качествами все другие блочные коды с той же длиной блока и степенью кодирования. В наиболее часто применяемых кодах БХЧ используется двоичный алфавит и блок кодового слова длиной ![]() , где
, где ![]() .
.
Из названия табл. 6.4 ясно, что показаны генераторы только для примитивных кодов БХЧ. Термин "примитивные" (primitive) — это теоретико-числовое понятие, требующее алгебраического рассмотрения [7, 10-11], которое представлено в разделе 8.1.4. На рис. 6.21 и 6.22 изображены графики вероятности ошибки для двух кодов БХЧ: (127, 64) и (127, 36). На рис. 6.21 показана зависимость ![]() от вероятности ошибки в канальном символе при жестком декодировании. На рис. 6.22 показана зависимость
от вероятности ошибки в канальном символе при жестком декодировании. На рис. 6.22 показана зависимость ![]() от
от ![]() для когерентно демодулированного сигнала BPSK в гауссовом канале. Кривые на рис. 6.22 выглядят совсем не так, как можно было бы ожидать. Все они имеют одну и ту же длину блока, но большая избыточность кода (12, 36) не дает той эффективности кодирования, какая имеется у менее избыточного кода (127, 64). Известно, что относительно широкий максимум эффективности кодирования, в зависимости от степени кодирования при фиксированном n, для кодов БХЧ находится примерно между степенью 1/3 и 3/4 [12]. Стоит также отметить, что передача по гауссову каналу сильно ухудшается при переходе от очень высоких до очень низких скоростей [11].
для когерентно демодулированного сигнала BPSK в гауссовом канале. Кривые на рис. 6.22 выглядят совсем не так, как можно было бы ожидать. Все они имеют одну и ту же длину блока, но большая избыточность кода (12, 36) не дает той эффективности кодирования, какая имеется у менее избыточного кода (127, 64). Известно, что относительно широкий максимум эффективности кодирования, в зависимости от степени кодирования при фиксированном n, для кодов БХЧ находится примерно между степенью 1/3 и 3/4 [12]. Стоит также отметить, что передача по гауссову каналу сильно ухудшается при переходе от очень высоких до очень низких скоростей [11].
| k | t | g(x) n | k | t | g(x) | |
| 85 |
6 |
130704476322273 | 55 | 31 | 7315425200350110013301527530 6032054325414326755010557044 426035473617 | |
| 78 |
7 |
26230002166130115 | ||||
| 71 |
9 |
625501010703253127753 | 47 | 42 | 2533542017062646563033041377 4062330751233341454460450050 66024552543173 | |
| 64 |
10 |
1206534025570773100045 | ||||
| 57 |
11 |
335265252505705053517721 | 45 | 43 | 1520205605523416113110134637 6423701563670024470762373033 202157025051541 | |
| 50 |
13 |
54446512523314012421501421 | ||||
| 43 |
14 |
17721772213651227521220574343 | 37 | 45 | 5136330255067007414177447245 4375304207357061743234323476 4354737403044003 | |
| 36 |
15 |
3146074666522075044764574721735 | ||||
| 29 |
21 |
403114461367670603667530141176155 | 29 | 47 | 30257155366730714655270640123 61377115342242324201174114060 254757410403565037 | |
| 22 |
23 |
123376070404722522435445626637647043 | ||||
| 15 |
27 |
22057042445604554770523013762217604353 | ||||
| 8 |
31 |
7047264052751030651476224271567733130217 | 21 | 55 | 12562152570603326560017731536 07612103227341405630745425211 53121614466513473725 | |
| 255 | 247 |
1 |
435 | |||
| 239 |
2 |
267543 | ||||
| 231 |
3 |
156720665 | 13 | 59 | 4641732005052564544426573714 2500660043306774454765614031 7467721357026134460500547 | |
| 223 |
4 |
75625541375 | ||||
| 215 |
5 |
23157564726421 | ||||
| 207 |
6 |
16176560567636227 | 9 | 63 | 1572602521747246320110310432 5535513461416236721204407454 5112766115547705561677516057 | |
| 199 |
7 |
7633031270420722341 | ||||
| 191 |
8 |
2663470176115333714567 | ||||
| 187 |
9 |
52755313540001322236351 | ||||
| 179 |
10 |
22624710717340432416300455 | ||||
| 4 |
1 |
13 | 55 | 31 | 7315425200350110013301527530 6032054325414326755010557044 426035473617 | |
| 11 |
1 |
23 | ||||
| 7 |
2 |
721 | 47 | 42 | 2533542017062646563033041377 4062330751233341454460450050 66024552543173 | |
| 5 |
3 |
2467 | ||||
| 26 |
1 |
45 | 45 | 43 | 1520205605523416113110134637 6423701563670024470762373033 202157025051541 | |
| 21 |
2 |
3551 | ||||
| 16 |
3 |
107657 | 37 | 45 | 5136330255067007414177447245 4375304207357061743234323476 4354737403044003 | |
| 11 |
5 |
5423325 | ||||
| 6 |
7 |
313365047 | 29 | 47 | 30257155366730714655270640123 61377115342242324201174114060 254757410403565037 | |
| 57 |
1 |
103 | ||||
| 51 |
2 |
12471 | ||||
| 45 |
3 |
1701317 | 21 | 55 | 12562152570603326560017731536 07612103227341405630745425211 453121614466513473725 | |
| 255 | 39 |
4 |
166623567 | |||
| 36 |
5 |
1033500423 | ||||
| 30 |
6 |
157464165547 | 13 | 59 | 4641732005052564544426573714 2500660043306774454765614031 7467721357026134460500547 | |
| 24 |
7 |
17323260404441 | ||||
| 18 |
10 |
1363026512351725 | ||||
| 16 |
11 |
6331141367235453 | 9 | 63 | 1572602521747246320110310432 5535513461416236721204407454 5112766115547705561677516057 | |
| 10 |
13 |
472622305527250155 | ||||
| 7 |
8 |
5231045543503271737 | ||||
| 120 |
1 |
211 | ||||
| 113 |
2 |
41567 | ||||
| 106 |
3 |
11554743 | ||||
| 99 |
4 |
3447023271 | ||||
| 92 |
5 |
624730022327 |
На рис. 6.23 показаны расчетные характеристики кодов БХЧ для когерентно демодулированного сигнала BPSK с жестким и мягким декодированием. Мягкое декодирование для блочных кодов не применяется из-за своей сложности, хотя оно и дает увеличение эффективности кодирования порядка 2 дБ по сравнению с жестким декодированием. При данной степени кодирования вероятность ошибки при декодировании уменьшается с ростом длины блока п [4]. Таким образом, при данной степени кодирования интересно рассмотреть необходимую длину блока для сравнения характеристик жесткого и мягкого декодирования. На рис. 6.23 все коды показаны со степенью кодирования, равной приблизительно 1/2. Из рисунка [13] видно, что при фиксированной степени кодирования и жестком декодировании кода БХЧ длиной 8n или более наблюдаются лучшие характеристики, чем при мягком декодировании кода БХЧ длиной n. Существует специальный подкласс кодов БХЧ (которые были разработаны раньше кодов БХЧ), который является недвоичным набором; это коды Рида-Соломона (Reed-Solomon code). Подробнее об этих кодах будет рассказано в разделе 8.1.
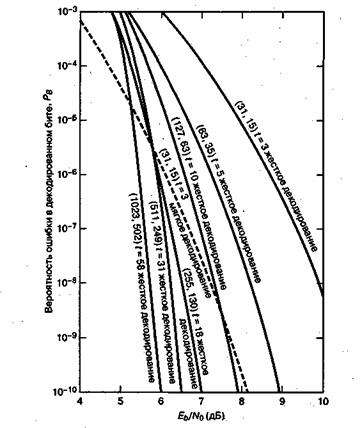
Рис. 6.23. Зависимость ![]() от
от ![]() для когерентно демодулируемого сигнала BPSK в гауссовом канале с использованием кодов БХЧ.
для когерентно демодулируемого сигнала BPSK в гауссовом канале с использованием кодов БХЧ.
Литература
1. Viterbi A. J. On Coded Phase-Coherent Communications. IRE Trans. Space Electron. Telem., vol.SET7, March, 1961, pp. 3-14.
2. Lindsey W. C. and Simon M. K. Telecommunication Systems Engineering. Prentice-Hall, Inc., Englewood Cliffs, N. J., 1973.
3. Proakis J. G. Digital Communications. McGraw-Hill Book Company, New York, 1983.
4. Lin S. and Costello D. J. Jr. Error Control Coding: Fundamentals and Applications. Prentice-Hall, Inc., Englewood Cliffs, N. J., 1983.
5. Odenwalder J. P. Error Control Coding Handbook. Linkabit Corporation, San Diego, Calif., July, 15, 1976.
6. Blahut R. E. Theory and Practice of Error Control Codes. Addison-Wesley Publishing Company, Inc., Reading, Mass, 1983.
7. Peterson W. W. and Weldon E. J. Error Correcting Codes, 2nd ed. The MIT Press, Cambridge, Mass, 1972.
8. Blahut R. E. Algebraic Fields, Signal Processing and Error Control. Proc. IEEE, vol. 73, May, 1985, pp. 874-893.
9. Stenbit J. P. Table of Generators for Base-Chadhuri Codes. IEEE Trans. Inf. Theory, vol. IT10, n. 4, October, 1964, pp. 390-391.
10. Berlekamp E. R. Algebraic Coding Theory. McGraw-Hill Book Company, New York, 1968.
11. Clark G. C. Jr. and Cain J. B. Error-Correction Coding/or Digital Communications. Plenum Press, New York, 1981.
12. Wozencraft J. M. and Jacobs I. M. Principles of Communication Engineering. John Wiley & Sons, Inc., New York, 1965.
13. Weng L. J. Soft and Hard Decoding Performance Comparisons for BCH Codes. Proc. Int. Conf.Commun., 1979, pp. 25.5.1-25.5.5;
Задачи
6.1. Сконструируйте код (n, k) с проверкой на четность, который будет определять все комбинации,содержащие 1, 3, 5 и 7 ошибочных бит. Найдите значения n k и определите вероятность невыявленной ошибки в блоке, если вероятность ошибки в канальном символа равна ![]() .
.
6.2. Определите вероятность ошибки в сообщении для 12-битовой последовательности данных, кодированной линейным блочным кодом (24, 12). Допустим, что код может исправлять одно- и двухбитовые ошибочные комбинации и что ошибочные комбинации с более чем двумя ошибками не подлежат исправлению. Также предположим, что вероятностьошибки в канальном символе равна ![]() .
.
6.3.Рассмотрим линейный блочный код (127, 92), который может исправлять трехбитовые ошибки.
а) Чему равна вероятность ошибки в сообщении для некодированного блока из 92 бит, если вероятность ошибки в канальном символе равна ![]() ?
?
б) Чему равна вероятность ошибки для сообщения, кодированного блочным кодом(127, 92), если вероятность ошибки в канальном символе равна ![]() ?
?
6.4. Рассчитайте уменьшение вероятности ошибки в сообщении, кодированном линейным блочным кодом (24, 12) с коррекцией двухбитовых ошибок, по сравнению с некодированной передачей. Предположим, что используется когерентная модуляция BPSK и принятое ![]() дБ.
дБ.
6.5. Рассмотрим линейный блочный код (24, 12) с возможностью исправления двухбитовых ошибок. Пусть используется модуляция BFSK, а принятое ![]() дБ.
дБ.
а) Дает ли код какое-либо уменьшение вероятности ошибки в сообщении? Если да, то насколько? Если нет, то почему?
б) Повторите п. а при ![]() дБ.
дБ.
6.6. Телефонная компания применяет кодер типа "лучший из пяти" для некоторых цифровыхканалов данных. В такой схеме все биты данных повторяются пять раз, и в приемнике выполняется мажоритарное декодирование сообщения. Если вероятность ошибки в некодированном бите составляет ![]() и используется кодирование "лучший из пяти", чему равна вероятность ошибки в декодированном бите?
и используется кодирование "лучший из пяти", чему равна вероятность ошибки в декодированном бите?
6.7. Минимальное расстояние для конкретного линейного блочного кода равно 11. Найдите максимальные возможности кода при исправлении ошибок, максимальные возможностипри обнаружении ошибок и максимальные возможности этого кода при коррекции стираний для данной длины блока.
6.8. Дается матрица генератора кода (7, 4) следующего вида.

а) Найдите все кодовые слова кода.
б) Найдите проверочную матрицу Н этого кода.
в) Рассчитайте синдром для принятого вектора 1101101. Правильно ли принят этот вектор?
г) Каковы возможности кода при исправлении ошибок?
д) Каковы возможности кода при обнаружении ошибок?
6.9. Рассмотрите линейный блочный код, контрольные уравнения которого имеют следующий вид.
Здесь ![]() — разряды сообщения, а
— разряды сообщения, а ![]() — контрольные разряды.
— контрольные разряды.
а) Найдите для этого кода матрицу генератора и проверочную матрицу.
б) Сколько ошибок может исправить этот код?
в) Является ли вектор 10101010 кодовым - словом?
г) Является ли вектор 01.011100 кодовым словом?
6.10. Рассмотрите линейный блочный код, для которого кодовое слово определяется следующим вектором.
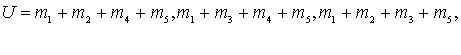
![]()
а) Найдите матрицу генератора.
б) Найдите проверочную матрицу.
в) Найдите n, k и ![]() .
.
6.11. Постройте линейный блочный код (n, k) = (5,2).
а) Выберите кодовые слова в систематической форме так, чтобы получить максимальноезначение ![]() .
.
б) Найдите для этого набора кодовых слов матрицу генератора.
в) Рассчитайте проверочную матрицу.
г) Внесите все n-кортежи в нормальную матрицу.
д) Каковы возможности этого кода в обнаружении и исправлении ошибок?
е) Составьте таблицу синдромов для исправимых ошибочных комбинаций.
6.12. Рассмотрим код с повторениями (S, 1), содержащий два кодовых слова 00000 и 11111, соответствующих передаче 0 и 1. Составьте нормальную матрицу для этого кода. Будет лиэтот код совершенным?
6.13. Постройте код (3, 1), способный исправлять все однобитовые ошибочные комбинации. Подберите набор кодовых слов и составьте нормальную матрицу.
6.14. Будет ли код (7, 3) совершенным? Будет ли совершенным код (7, 4)? А код (15, 11)? Ответ аргументируйте.
6.15. Линейный блочный код (15,11) можно определить следующей матрицей четности.
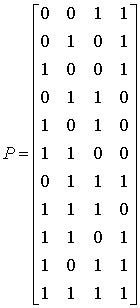
а) Найдите для этого кода проверочную матрицу.
б) Укажите образующие элементы классов смежности в нормальной матрице. Является ли этот код совершенным? Обоснуйте свой ответ.
в) Пусть принят вектор V = 011111001011011. Рассчитайте его синдром. Предположите, что сделана однобитовая ошибка, и найдите правильное кодовое слово.
г) Сколько стираний может исправить это код? Ответ аргументируйте.
6.16. Может ли ненулевая ошибочная комбинация дать синдром S = 0? Если да, то сколько таких комбинаций существует для кода (n, k)? Для объяснения ответа воспользуйтесь рис. 6.11.
6.17. Определите, какие (если таковые есть) из следующих полиномов могут генерировать циклический код с кодовым словом длиной ![]() . Найдите значение (n, k) для каждого из таких кодов.
. Найдите значение (n, k) для каждого из таких кодов.
а) ![]()
б) ![]()
в) ![]()
г) ![]()
д) ![]()
6.18.Используя полиномиальное деление и генератор ![]() , закодируйте в систематической форме сообщение 101.
, закодируйте в систематической форме сообщение 101.
6.19.Сконструируйте кодер на регистрах сдвига с обратной связью для циклического кода (8, 5) с генератором ![]() . С помощью кодера найдите кодовое слово в систематической форме для сообщения 10101.
. С помощью кодера найдите кодовое слово в систематической форме для сообщения 10101.
6.20.На рис. 36.1 сигнал передается в модуляции DPSК, скорость передачи кодовых символов составляет 10 000 кодовых символов в секунду, декодер является декодером (7, 4) с коррекцией однобитовый ошибок. Достаточно ли значения ![]() дБВт на входе для получения на выходе вероятности ошибки в сообщении
дБВт на входе для получения на выходе вероятности ошибки в сообщении ![]() ? Обоснуйте свой ответ. Считайте, что блок сообщения содержит 4 бита данных и что можно исправить любую однобитовую ошибочную комбинацию в блоке длиной 7 бит.
? Обоснуйте свой ответ. Считайте, что блок сообщения содержит 4 бита данных и что можно исправить любую однобитовую ошибочную комбинацию в блоке длиной 7 бит.
![]()
Рис. 36.1
6.21. Циклический код (15, 5) имеет полиномиальный генератор следующего вида.
![]()
а) Нарисуйте схему кодера для этого кода.
б) Найдите полином кода (в систематической форме) для сообщения ![]() .
.
в) Будет ли ![]() полиномом кода в этой системе? Объясните свой ответ.
полиномом кода в этой системе? Объясните свой ответ.
6.22. Рассмотрим циклический код (15, 11), который генерируется генератором ![]() .
.
а) Разработайте для этого кода кодер и декодер на основе регистра с обратной связью.
б) Проиллюстрируйте процедуру кодирования на примере вектора сообщения 11001101011, перечислив все состояния регистра (крайний правый бит является самым первым).
в) Повторите п. б для процедуры декодирования.
6.23.При фиксированной вероятности ошибки в канальном символе вероятность битовой ошибки для кода Хэмминга (15, 11) больше, чем для кода Хэмминга (7, 4). Объясните, почему? В чем тогда заключается преимущество кода (15, 11)? Каков основной компромисс здесь задействован?
6.24.Код БХЧ (63, 36) может исправить пять ошибок. Девять блоков кода (7, 4) могут исправить девять ошибок. Оба кода имеют одинаковую степень кодирования.
a) Код (7, 4) может исправить больше ошибок. Является ли он более мощным? Объясните свой ответ.
б) Сравните оба кода, когда наблюдается пять случайных ошибок в 63 бит.
6.25. Исходная информация разбита на 36-битовые сообщения и передается по каналу AWGN с помощью сигналов в модуляции BFSK.
а) Рассчитайте ![]() , необходимое для получения вероятности ошибки в сообщении
, необходимое для получения вероятности ошибки в сообщении ![]() , если применяется кодирование без защиты от ошибок.
, если применяется кодирование без защиты от ошибок.
б) Пусть при передаче этих сообщений используется линейный блочный код (127, 36). Рассчитайте эффективность кодирования для этого кода при вероятности ошибки в сообщении ![]() . (Подсказка: эффективность кодирования определяется как разность между требуемым
. (Подсказка: эффективность кодирования определяется как разность между требуемым ![]() без кодирования и
без кодирования и ![]() с кодированием.)
с кодированием.)
6.26. а) Пусть последовательность данных кодируется кодом БХЧ (127, 64), а затем модулируется когерентной 16-арной схемой PSK. Если принятое ![]() равно 10 дБ, чему равны вероятность ошибки в принятом символе, вероятность ошибки в кодовом бите (предполагается, что для присвоения символам битового значения используется код Грея) и вероятность ошибки в информационном бите.
равно 10 дБ, чему равны вероятность ошибки в принятом символе, вероятность ошибки в кодовом бите (предполагается, что для присвоения символам битового значения используется код Грея) и вероятность ошибки в информационном бите.
б) Для той же вероятности ошибки в информационном бите, которая была найдена в п. а, определите требуемое значение ![]() , если модуляция в п. а заменена на когерентную ортогональную 16-арную FSK. Объясните отличия.
, если модуляция в п. а заменена на когерентную ортогональную 16-арную FSK. Объясните отличия.
6.27. В сообщении содержится текст на английском языке (предполагается, что каждое слово в сообщении содержит шесть букв). Каждая буква кодируется 7-битовым символом ASCII. Таким образом, каждое слово текста представляется 42-битовой последовательностью. Сообщение передается по каналу с вероятностью ошибки в символе ![]() .
.
а) Какова вероятность того, что слово будет передано с ошибкой?
б) Если применяется код с тройным повторением каждой буквы, а приемник осуществляет мажоритарное декодирование, чему равна вероятность появления ошибки в декодированном слове?
в) Если для кодирования каждого 42-битового слова применяется код БХЧ (126, 42) с возможностью исправления ошибок с t = 14, то какова будет вероятность появления ошибки в декодированном слове?
г) В реальной системе не совсем явно можно сравнить характеристики кодированной и некодированной вероятностей ошибки в сообщении, используя фиксированную вероятность ошибочной передачи канального символа, поскольку это предполагает фиксированныйуровень принятого ![]() для любого способа кодирования (в том числе и без кодирования). Поэтому повторите пп. а—в при условии, что вероятность ошибочной передачи канального символа определяется уровнем принятого
для любого способа кодирования (в том числе и без кодирования). Поэтому повторите пп. а—в при условии, что вероятность ошибочной передачи канального символа определяется уровнем принятого ![]() , равного 12 дБ, где
, равного 12 дБ, где ![]() — это отношение энергии информационного бита к спектральной плотности шума. Предположим, что скорость передачи информации одинакова для всех типов кодирования и для системы без кодирования. Также допустим, что используется некогерентная ортогональная модуляция FSK, а в канале присутствует шум AWGN.
— это отношение энергии информационного бита к спектральной плотности шума. Предположим, что скорость передачи информации одинакова для всех типов кодирования и для системы без кодирования. Также допустим, что используется некогерентная ортогональная модуляция FSK, а в канале присутствует шум AWGN.
д) Обсудите относительные возможности надежной работы описанных выше схем кодирования при двух условиях — фиксированная вероятность ошибки в канальном символе и фиксированное отношение ![]() . В каком случае код с повторением может дать повышение достоверности передачи? В каком случае достоверность снизится?
. В каком случае код с повторением может дать повышение достоверности передачи? В каком случае достоверность снизится?
6.28. Последовательность блоков данных из пяти бит с помощью матрицы Адамара преобразуется в ортогонально кодированную последовательность. Когерентное обнаружение осуществляется в течение периода передачи кодового слова, как показано на рис. 6.5. Считая ![]() , рассчитайте эффективность кодирования для побитовой передачи данных с использованием модуляции BPSK.
, рассчитайте эффективность кодирования для побитовой передачи данных с использованием модуляции BPSK.
629. Для кода (8, 2), описанного в разделе 6.6.3, проверьте правильность величин матрицы генератора, проверочной матрицы и векторов синдромов для каждого класса смежности 1—10.
6.30.Составьте схему на основе логических элементов исключающего ИЛИ и И, аналогичную схеме на рис. 6.12, исправляющую все однобитовые ошибочные комбинации кода (8, 2), определяемые образующими элементами классов смежности 2-9, показанными на рис. 6.15.
6.31.Подробно объясните возможность составления схемы на основе логических элементов исключающего ИЛИ и И (аналогичной схеме на рис. 6.12), исправляющей все одно- и двух битовые ошибочные комбинации кода (8, 2) и обнаруживающей трехбитовые ошибочные комбинации (образующие элементы классов смежности или строки 38-64).
6.32.Проверьте, что все коды БХЧ длиной n = 31, показанные в табл. 6.4, удовлетворяют условиям пределов Хэмминга и Плоткина.
6.33.При кодировании нулевого блока сообщения в результате получается нулевое кодовое слово. Обычно такую последовательность нулей передавать нежелательно. В одном методе циклического кодирования при такой передаче разряды регистра сдвига предварительно (до кодирования) заполняются единицами, а не нулями, как обычно. Получаемая в результате "псевдочетность" гарантированно содержит некоторое количество единиц. В декодере перед началом декодирования производится обратная операция. Постройте общую схему для инверсной обработки псевдочетных битов в каком-либо циклическом декодере. Воспользуйтесь кодером БХЧ (7, 4), заполненным единицами для кодирования сообщения 1011 (самым первым является крайний правый бит). Затем покажите, что составленная вами инверсная схема позволяет получить правильное декодированное сообщение.
6.34. а) В условиях задачи 6.21 кодируйте в систематической форме последовательность сообщения 11011, воспользовавшись полиномиальным генератором для циклического кода (15, 5). Найдите результирующий полином кодового слова. Какой особенностью характеризуется степень полиномиального генератора?
б) Пусть принятое кодовое слово искажено ошибочной комбинацией ![]() .Найдите полином искаженного кодового слова.
.Найдите полином искаженного кодового слова.
в) Исходя из полинома принятого вектора и полиномиального генератора найдите полином синдрома.
г) Исходя из полинома ошибочной комбинации и полиномиального генератора найдите полином синдрома и убедитесь, что это тот же синдром, что и найденный в п. в.
д) Объясните, почему в пп. в и г должен получиться одинаковый результат.
е) Используя свойство нормальной матрицы линейного блочного кода (15, 5), найдите максимальное количество исправлений ошибок, которое может выполнить код с данными параметрами. Является ли код (15, 5) совершенным?
ж) Бели мы хотим применить циклический код (15, 5) для одновременного исправлениядвух стираний и сохранить исправление ошибок, насколько придется пожертвоватьвозможностью исправления ошибок?
Вопросы
6.1. Опишите четыре типа компромиссов, которые могут быть достигнуты при использовании кода коррекции ошибок (см. раздел 6.3.4).
6.2. В системах связи реального времени за получаемую с помощью избыточности эффективность кодирования приходится платить полосой пропускания. Чем приходится жертвовать за полученную эффективность кодирования в системах связи модельного времени (см. раздел 6.3.4.2)? .
6.3. В системах связи реального времени увеличение избыточности означает повышение скорости передачи сигналов, меньшую энергию на канальный символ и больше ошибок на выходе демодулятора. Объясните, как на фоне такого ухудшения характеристик достигается эффективность кодирования (см. пример 6.2).
6.4. Почему эффективность традиционных кодов коррекции ошибок снижается при низких значениях ![]() (см. раздел 6.3.4.6)?
(см. раздел 6.3.4.6)?
6.5. Опишите процесс проверки с использованием синдромов, обнаружения ошибки и ее исправления в контексте примера из области медицины (см. раздел 6.4.8.4).
6.6. Определите место нормальной матрицы в понимании блочного кода и оценке его возможностей (см. раздел 6.6.5).