3.1. Общие сведения и терминология
3.3. Переключение в защищенный режим
3.5. Механизмы адресации в защищенном режиме
3.8. Формат элемента PTE (PDE)
3.9. Особенности страничного механизма в Pentium и Р6
3.11. Методы обработки прерываний, возникших в режиме V86
3.12. Механизм переключения задач. Формат сегмента TSS
3.13. Битовая карта ввода-вывода
3.14. Действия процессора при переключении задач
3.17. Программная модель 32-разрядного МП
3.18. Регистры системного программиста
3.19. Буфер TLB (кэш-память страниц)
3.20. Общие сведения о кэш-памяти
3.22. Сведения о кэшах в процессорах фирмы Intel
3.23. Инициализация процессора
3.24. Некоторые сведения о внутренней организации 32-разрядных процессоров
3.26. Система прерываний 32-разрядных процессоров
3.1. Общие сведения и терминология
Среди 32-разрядных процессоров фирмы Intel различают процессоры 386, 486, Pentium, семейство Р6 (процессоры Pentium Pro, Pentium II, Celerone и Pentium III, в котрых фирма реализует микроархитектуру Р6) и Pentium IV, в котором реализована NetBurst-микроархитектура. Базовые механизмы, реализуемые всеми этими процессорами,практически идентичны. При употреблении термина «процессор» речь будет идти обо всех вышеперечисленных процессорах, а конкретные особенности для отдельного процессора будут оговариваться дополнительно.
Итак, процессор имеет 32-адресные линии (А31-0) и, следовательно, может адресовать 232 байта (4 Гбайта) оперативной памяти. Начиная с Р6, в регистре cr4 (control register – регистр управления) введен специальный бит PAE (physical address extension – расширение физического адреса). Если этот бит установлен в единицу, то к процессору добавляются еще 4 адресные линии (А35-32) и он может адресовать 64 Гбайта оперативной памяти. Но при этом обязательно должен быть включен страничный механизм, так как, несмотря на наличие 36-адресных линий, сегментный механизм процессора продолжает вырабатывать 32-разрядный адрес, т.е. продолжает адресовать 4 Гбайта ОП. И только наличие страничного механизма позволяет транслировать эти 4 Гбайта в любое место 64-Гбайтного пространства.
Шина данных у процессоров 386 и 486 32-разрядная, начиная с Pentium – 64-разрядная. При этом во всех процессорах (в отличие от ВМ86) шины адреса и данных раздельные (не мультиплексные). Процессор может работать в следующих режимах.
1. Реальный режим. С точки зрения пользователя, МП в этом режиме представляет из себя аналог МП 8086, только более быстрый и с расширенной системой команд. Механизм формирования физического адреса в реальном режиме аналогичен подобному механизму МП 8086:
Аф = (sr)×16+Аэф.
Надо отметить, что сами процессы формирования Аф в 8086 и реальном режиме различны, а результат ‑ один и тот же. Так как сегментные регистры (sr) и Аэф ‑ 16-разрядные, то формируемый таким образом Аф будет 20-разрядным. Следовательно, в реальном режиме МП адресует 1Мбайт оперативной памяти (младший мегабайт 4-Гбайтного пространства памяти). Сегменты, как и в ВМ86 имеют фиксированный размер 64 Кбайта.
2. Режим виртуального 86-го процессора (V86). Этот режим предназначен для того, чтобы в защищенном режиме была возможность выполнять программы, написанные для ВМ86 (DOS-задачи). Работа процессора в этом режиме похожа на работу ВМ86, но сам режим V86 является подмножеством защищенного режима.
3. Режим SMM (system management mode – режим управления системой). Работа процессора в этом режиме «не видна» ни прикладным программам, ни даже операционной системе. Связано это с тем, что в этом режиме процессор адресует область памяти, недоступную в других режимах. Обычно в этом режиме процессор выполняет программу, написанную разработчиками аппаратуры. Чаще всего эта программа реализует системные функции пониженного энергопотребления. Попасть в режим SMM можно только по специальному внешнему аппаратному прерыванию SMI (system mode interrupt). Выход из режима SMM осуществляется специальной командой RSM (resume system mode).
4. Защищенный режим. В этом режиме раскрываются все возможности МП. В режиме используются все 32 адресных линии и может адресоваться память объемом до 4 Гбайт. Сегменты в защищенном режиме имеют переменный объем (1 байт ‑ 4 Гбайта). Одновременно МП может работать с 214 таких сегментов. Очевидно, что все сегменты могут не поместиться в реально существующей оперативной памяти (ОП), поэтому часть из них (а скорее всего большинство) находится на диске. Когда процессор обращается к сегменту, которого нет в ОП, происходит прерывание. Обработчик этого прерывания должен подка-чать с диска в ОП нужный сегмент, после чего происходит рестарт «виноватой» команды. От пользователя этот процесс скрыт и у него создается впечатление что в его распоряжении находится память объемом 64 Тбайта (214 сегментов по 4 Гбайта каждый, т.е. 246 байта). Такая память называется виртуальной (кажущаяся).
В защищенном режиме МП аппаратно поддерживает многозадачность. То есть в системе одновременно может находиться множество задач, а МП обеспечивает быстрое переключение между этими задачами. Наличие многозадачности приводит к ряду проблем, основные две из которых следующие: как переключаться с задачи на задачу и как защитить задачи друг от друга.
Для решения первой проблемы для каждой задачи в системе создается так называемый сегмент состояния задачи (TSS – task state segment). Размер этого сегмента должен быть не менее 104-х байт. Когда МП переключается с задачи А на задачу В, то он автоматически запоминает контекст задачи А (содержимое почти всех своих внутренних регистров) в TSS задачи А, а затем также автоматически загружает в свои регистры контекст задачи В (из TSS задачи В). Тем самым обеспечивается переключение на задачу В и в то же время возможность возврата и продолжения выполнения задачи А. Под задачей понимается любой программный код, для которого в системе создан свой TSS. Создание TSS ‑ это функция ОС.
Для решения проблемы защиты задач друг от друга всем создаваемым в системе сегментам присваивается уровень привилегий. Возможно четыре уровня привилегий: 0,1,2 и 3, причем 0-й уровень самый старший. Уровень 3 (самый низкий) присваивается обычно сегментам пользователя, уровень 0 ‑ сегментам ОС, а уровни 1 и 2 предназначены для расширения ОС и на практике часто не используются.
Если программа с уровнем привилегий А обращается к сегменту с уровнем привилегий В, то процессор проверяет условие А£В. Если условие выполняется, то доступ к сегменту предоставлен, если же условие не выполняется, то будет прерывание (нарушены права доступа к сегменту).
Механизм формирования физического адреса в защищенном режиме радикально отличается от механизма МП 8086. Для каждого создаваемого в системе сегмента создается (как правило, ОС) специальная структура, называемая дескриптором этого сегмента. Дескриптор занимает в памяти 8 байт и содержит все необходимые сведения о сегменте: начальный адрес сегмента, размер сегмента, уровень привилегий, атрибуты сегмента и.т.д. МП вычисляет физический адрес по формуле
Аф = начальный адрес сегмента+Аэф.
В отличие от 8086, начальный адрес сегмента не вычисляется, а берется готовым из дескриптора.
Все созданные в системы дескрипторы сводятся в дескрипторные таблицы. Любая задача может одновременно работать с двумя такими таблицами. Одна из них называется глобальной (GDT ‑ global descriptor table), а другая ‑ локальной (LDT ‑ local descriptor table). В GDT собраны дескрипторы сегментов, разделяемых всеми задачами в системе, а в LDT располагаются дескрипторы сегментов, с которыми работает только данная задача. GDT в системе одна и всегда должна находиться в ОП, а LDT может быть столько же, сколько и задач (для любой задачи LDT может быть создана, а может и не создаваться), и располагаться эти таблицы могут как в ОП, так и на диске.
Для того чтобы перейти к новому сегменту, надо обратиться к его дескриптору, т.е. надо найти этот дескриптор в дескрипторной таблице. Для этого необходимо знать начальный адрес таблицы и внутритабличное смещение (это смещение принято называть селектором дескриптора). Начальные адреса таблиц процессору известны, они хранятся в специальных внутренних регистрах МП, а смещение берется из сегментного регистра. Любой сегментный регистр в МП имеет формат, приведенный на рис. 3.1.
| Видимая часть | Теневая часть | |
|
16 бит |
64 бита |
Рис. 3.1
Видимая часть доступна программисту, а с теневой частью работает сам МП. Видимая часть имеет формат, приведенный на рис. 3.2. Старшие 13 разрядов (биты 15 ‑ 3) занимает селектор, определяющий местоположение дескриптора в одной из двух дескрипторных таблиц ( в какой именно задает бит TI (table indicator)).
|
15 3 |
2 |
1 0 |
|
Селектор |
TI | RPL |
Рис. 3.2
При обращении к дескрипторной таблице к селектору справа дописываются три нуля и он становится 16-разрядным. Дело здесь в том, что размер дескриптора 8 байт и его смещение в таблице всегда кратно восьми. Биты 1 и 0 задают запрашиваемый уровень привилегий (RPL ‑ requested privilege level). Нетрудно видеть, что максимальное число дескрипторов в любой дескрипторной таблице 213 (поскольку селектор 13-разрядный), а максимальный размер таблицы равен 8×213 = 64 Кбайт. Так как одновременно процессору доступны две такие таблицы, то МП одновременно доступны 214 сегментов.
При обращении к новому сегменту в видимую часть сегментного регистра загружается новый селектор. По этому селектору в дескрипторной таблице МП находит дескриптор нового сегмента.
Проверяются права доступа и, если они не нарушены, то найденный дескриптор копируется (кэшируется) в теневую часть сегментного регистра (с тем чтобы в дальнейшем он был у МП «под рукой» и не требовалось каждый раз обращаться за ним в память).
Например, выполняется команда jmp 0008 : 00000002h. При этом 00000002h – это смещение в новом кодовом сегменте, и эта величина будет загружена (если не нарушены права доступа и другие условия) в регистр eip. Величина 0008h представляет из себя селектор, ссылающийся на 1-й дескриптор в GDT, TI = 0, RPL = 0 (рис. 3.3).
|
GDT |
|
0-й дескриптор |
|
1-й дескриптор |
|
.. . . |
Рис. 3.3
Очевидно, что таким способом (из-за проверки прав доступа) нельзя обратиться к более привилегированному сегменту, поскольку при этом будет прерывание (нарушены права доступа). В то же время должна быть возможность обращения к привилегированным сегментам, потому что в противном случае задачам пользователя вообще будут недоступны средства ОС. Для предоставления такой возможности в системе создаются специальные структуры называемые шлюзами (вентилями) (gate).
Шлюз ‑ структура, подобная дескриптору. Так же, как и дескрипторы, шлюзы занимают в памяти по 8 байт и располагаются в дескрипторных таблицах. Однако, если через дескриптор обращаемся к сегменту и при этом проверяется уровень привилегий, записанный в этом дескрипторе (рис. 3.4), то через шлюз обращаемся к дескриптору, на который ссылается этот шлюз (и далее через этот дескриптор к сегменту). При этом проверяется уровень привилегий, записанный в шлюзе, а уровень привилегий, записанный в дескрипторе, игнорируется (рис. 3.5). Здесь cpl (current privilege level) ‑ текущий уровень привилегий задачи, dpl (descriptor privilege level) – уровень привилегий сегмента, записанный в его дескрипторе. Уровень привилегий, записанный в шлюзе (dpl шлюза), задает минимальный уровень привилегий, на котором разрешается «проход» через данный шлюз.
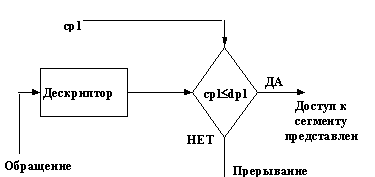
Рис. 3.4
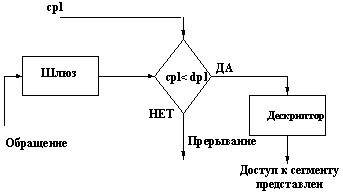
Рис. 3.5
Отметим также, что проверки, приведенные на рис. 3.4 и 3.5, для простоты картины показаны несколько упрощенно. Более полно они будут рассмотрены позднее.
Обращаться через шлюзы можно только к исполняемым сегментам. К последним относятся сегменты кода и сегменты TSS.
Например, пусть выполняется программа с уровнем привилегий 3. В какой-то момент программа обращается к сегменту, в дескрипторе которого записан уровень приви-легий 0. Это обращение окончится неудачно (прерывани-ем). Однако, если в системе есть шлюз, ссылающийся на этот дескриптор и имеющий уровень привилегий 3, и нашей программе известно его месторасположение в таблице, то она может обратиться к этому шлюзу. Права доступа для шлюза нарушены не будут, что позволит программе обратиться к дескриптору. Права доступа дескриптора проверяться не будут и программа получит доступ к сегменту с уровнем привилегий 0.
Шлюзы бывают четырех типов.
1. Шлюз вызова. Может располагаться в таблицах GDT и LDT. Предназначен для вызова привилегированных подпрограмм.
2. Шлюз задачи. Может располагаться в GDT, LDT и IDT (interrupt descriptor table) (дескрипторная таблица прерываний). Предназначен для переключения на привилегированную задачу.
3. Шлюз прерываний. Может располагаться только в IDT. Служит для вызова обработчика внешнего прерыва-ния. При переходе через этот шлюз флаг if сбрасывается в ноль, т.е. запрещаются внешние прерывания.
4. Шлюз ловушки. Может располагаться только в IDT. Служит для вызова обработчика внутреннего прерывания (особого случая). Практически аналогичен шлюзу прерываний, только внешние прерывания не запрещаются.
Некоторые сегменты кода могут быть отмечены как согласованные (подчиненные) (conforming). Если обычный сегмент кода всегда выполняется на том уровне привилегий, который записан в его дескрипторе, то согласованный сегмент кода выполняется на том уровне привилегий, с которого он был вызван. То есть уровень привилегий, записанный в дескрипторе согласованного сегмента, в расчет не принимается и к такому сегменту можно обратиться с любого уровня привилегий.
Имеется одно исключение – ни к какому кодовому сегменту, в том числе и согласованному, нельзя обратиться с более высокого уровня привилегий. Обычно в согласованных сегментах располагаются системные библиотеки. Большинство сегментов в системе, как правило, согласованными не являются.
Зачастую для одного и того же сегмента в системе создаются сразу несколько дескрипторов. Такие дескрипторы называют альтернативными (или псевдонимами) (alias). Например, пусть некоторый сегмент данных разделяется задачей пользователя и ОС. При этом ОС может менять данные в этом сегменте, а задача пользователя может только считывать информацию из этого сегмента. Для того чтобы такая организация была возможна, придется создать два дескриптора этого сегмента. Одному сегменту будет присвоен 0-й уровень привилегий, и этот сегмент будет описан как доступный для чтения/записи, другому будет присвоен 3-й уровень привилегий и сегмент будет отмечен доступным только для чтения.
3.2. Реальный режим
МП автоматически переходит в этот режим при приходе сигнала RESET (сброс). В реальный режим можно попасть и из защищенного режима, если установить в ноль бит PE в регистре cr0 (рис. 3.6).
|
31 1 |
0 |
||
| PE | |||
|
cr0 |
|||
Рис. 3.6
Сбросить этот бит можно командой mov cr0 , r32 , где r32 ‑ любой 32-разрядный регистр МП. Выполнить такую команду в защищенном режиме можно только находясь на уровне привилегий 0. Если сбросить этот бит «в лоб», то перейдем в реальный режим, но где при этом окажемся ‑ неизвестно (скорее всего «повесим» систему). Поэтому перед переключением из защищенного режима в реальный требуется большая подготовительная работа со стороны системного программиста, с тем чтобы обеспечить реальную точку входа в реальный режим.
Как уже отмечалось ранее, механизм формирования Аф в реальном режиме совпадает с аналогичным механизмом МП 8086. Вернее, совпадает конечный результат (Аф), а сами механизмы отличаются друг от друга.
МП 8086 при обращении внутри текущего сегмента считает Аф по следующей схеме. Сначала он считает Аэф. Затем он берет содержимое соответствующего сегментного регистра и сдвигает его на 4 разряда влево (умножает на 16), получая начальный адрес сегмента. К этому начальному адресу МП прибавляет Аэф и получает Аф.
32-разрядный МП в реальном режиме действует несколько иначе. Отличие заключается в том, что начальный адрес сегмента рассчитывается здесь не при каждом обращении к данному сегменту, а всего один раз, при загрузке в сегментный регистр новой информации. То есть, когда содержимое какого-либо сегментного регистра меняется, МП умножает загружаемую в этот регистр информацию на 16 и полученный начальный адрес сегмента загружает в теневую часть сегментного регистра.
Далее при любом обращении внутри текущего сегмента МП берет готовый начальный адрес сегмента из теневой части соответствующего сегментного регистра. Можно сделать вывод, что механизмы обращения в текущем сегменте в реальном и защищенном режимах в принципе одинаковы, а все различие заключается в механизмах смены сегмента, которые в этих режимах кардинально отличаются друг от друга.
Так же, как и МП 8086, 32разрядный МП в реальном режиме адресует 1Мбайт оперативной памяти (младший мегабайт 4гигабайтного пространства защищенного режима). Таблица прерываний в реальном режиме (так же, как в МП 8086) располагается в младшем килобайте ОП. Тут надо отметить, что имеется возможность (в отличие от МП 8086) переместить эту таблицу в другое место памяти, но на практике эта возможность не используется.
Существует еще ряд небольших отличий между 32-разрядным МП в реальном режиме и МП 8086. Рассмотрим эти отличия.
1. Система команд 32-разрядного МП значительно шире, и большинство этих команд можно использовать в реальном режиме.
2. Добавлено два новых сегментных регистра fs и gs. К ним можно обращаться с помощью префиксов замены сегментов.
3. Внутренние регистры МП 32-разрядные. Их можно использовать в реальном режиме. То есть допустима, например, команда
mov eax , ebx.
4. 32-разрядные регистры можно использовать и для формирования Аэф (например, mov al , [esi+2] ). Однако при этом если сформированный Аэф окажется больше 0000ffffh, будет прерывание. То есть в отличие от МП 8086 здесь отсутствует кольцевая организация сегментов. Вычислив Аэф, МП проверяет (как в реальном, так и в защищенном режимах), не выводит ли этот адрес за заданные границы сегмента. Заданный размер сегмента МП берет из теневой части соответствующего сегментного регистра. При приходе сигнала RESET МП, переходя в реальный режим, автоматически загружает в теневые части всех своих сегментных регистров в качестве размера сегмента величину ffffh. Именно поэтому, если Аэф превышает эту величину, то происходит прерывание. Такая организация приводит к тому, что у пользователя (вернее, у системного программиста) появляется возможность заставить МП в реальном режиме адресовать больше 1Мбайта оперативной памяти (вплоть до 4 Гбайт). Для этого надо переключиться в защищенный режим, обеспечить загрузку в теневые части нужных сегментных регистров дескрипторов, в которых задан соответствующий размер сегмента (например, 10 Мбайт) и вернуться обратно в реальный режим. После этого через данные сегментные регистры можно будет обращаться к памяти объемом 10 Мбайт (только не надо менять содержимое этих сегментных регистров).
5. При формировании Аф может возникнуть перенос из старшего разряда (из разряда А19 в разряд А20). В МП 8086 этот перенос попросту отбрасывается, в результате получается кольцевая организация памяти. В 32-разрядном МП этот перенос не отбрасывается, а выставляется на адресную линию А20. Таким образом, в отличие от МП 8086, 32-разрядный МП в реальном режиме адресует не 1 Мбайт ( 00000000h ‑ 000fffffh) памяти, а 1 Мбайт плюс еще 64 Кбайта (00000000h ‑ 0010ffefh). Здесь и в тех, и в других скобках приводится диапазон адресуемой памяти. Эти дополнительные 64 Кбайта памяти называют верхней памятью и активно используют при работе под DOS, загружая в нее различные драйверы. В IBM-подобных ПЭВМ предусмотрена возможность реализации кольцевой организации памяти в реальном режиме. Для этого надо замаскировать адресную линию А20. Это можно сделать следующими четырьмя командами:
| mov al , 0d1h
out 64h , al mov al , 0ddh out 60h , al |
;команда управления линией А20
;передается в статус порт 64h ;закрыть линию А20 |
Для того чтобы открыть эту адресную линию, используются такие же четыре команды, только в третьей команде вместо 0ddh надо написать 0dfh.
3.3. Переключение в защищенный режим
Процессор переходит в этот режим, когда бит PE в регистре cr0 устанавливается в единицу. Установить этот бит можно командами mov cr0 , r 32 или командой lmsw r16/m16 . Последняя команда загружает из памяти или 16-разрядного регистра младшую половину регистра cr0. Обе команды доступны в реальном режиме.
После перехода в защищенный режим МП ожидает наличия в памяти по крайней мере двух таблиц: GDT и IDT. Поэтому эти таблицы должны быть созданы заранее ещё в реальном режиме, например, с помощью ассемблерных директив db, dw и dd. Что касается LDT, то её (их) можно создать как заранее в реальном режиме, так и позднее, когда мы уже находимся в защищенном режиме. Зачастую LDT вообще не создаются.
В общем случае переключение в защищенный режим требует серьезной подготовительной работы со стороны программиста, который должен выполнить примерно следующую последовательность действий.
1. Создать в памяти таблицы GDT и IDT.
2. Запретить внешние прерывания, в том числе и по входу NMI (если последний в системе используется). Связано это с тем, что в процессе переключения есть временной интервал, когда таблица векторов прерываний реального режима уже не действует, а таблица IDT ещё не действует. Если на этом интервале МП воспримет любое прерывание, наступит крах системы.
3. Перенастроить контроллеры прерываний на новые типы (номера) прерываний, с тем чтобы исключить конфликты между внутренними и внешними прерыва-ниями. Этот пункт не имеет никакого отношения к самому МП, а связан с особенностями функционирования IBM-подобных ПЭВМ. Когда фирма Intel выпустила МП 8086, она заняла под внутренние прерывания типы 0 ‑ 4, но предупредила, что типы 5 ‑ 31 резервируются для внутрен-них прерываний будущих процессоров. По каким-то причинам фирма IBM это предупреждение проигнори-ровала и отвела типы 8 ‑ 15 внешним прерываниям. В результате, например, тип 8 присвоен внешнему прерыванию от таймера (этот тип выдает на МП контроллер прерываний) и одновременно в 32-разрядных МП этот тип отведен особому случаю (внутреннему прерыванию) «двойная ошибка». Получается конфликт, так как МП не знает, какой обработчик он должен выполнять.
4. Открыть линию А20 (если она была закрыта).
5. Во внутренние регистры процессора gdtr и idtr загрузить начальные адреса и размеры таблиц GDT и IDT.
6. Установить бит РЕ. С этого момента мы в защищенном режиме.
7. Обычно первой командой в защищенном режиме ставится команда jmp far next (дальний переход на следующую команду программы). Команда очищает очередь команд от команд защищенного режима, а также заносит в видимую часть cs правильный селектор, по которому в дескрипторной таблице GDT отыскивается дескриптор сегмента кода. Далее этот дескриптор копи-руется в теневую часть cs. Очистка очереди команд нужна исходя из следующих соображений. Во всех рассматриваемых процессорах реализован конвейер команд. В любой момент времени внутри процессора обрабатывается сразу несколько команд, находящихся на разных стадиях выполнения. Отсюда, при переключении режимов возникает ситуация, когда с конвейера еще сходят команды одного режима, а на конвейер уже поступают команды другого режима. Поскольку в разных режимах одни и те же команды выполняются по-разному, такая ситуация иногда может приводить к различным коллизиям. Использование команды jmp снимает эту проблему. Начиная с Pentium, использование команды jmp для рассмотренной выше цели необязательно, поскольку команды, меняющие содержимое регистров управления cr0-cr4, гарантируют, что все команды, идущие перед ними, будут завершены (так называемые «сериалайзд» ‑ команды – serialized instruction).
8. Разрешить внешние прерывания.
Не следует считать, что все эти пункты всегда обязательны к исполнению. Это только общая схема действий, причем подразумевающая, что мы переключаемся в защищенный режим «всерьёз и надолго». Если же требуется только «нырнуть» в защищенный режим и тут же вернуться обратно, то многие пункты можно исключить. В частности, можно не создавать IDT, не загружать IDTR, и вообще не выполнять пп. 3,4 и 7.
Далее приведен пример программы, переключающей процессор из реального режима в защищенный и обратно. Находясь в защищенном режиме, программа очищает экран и выводит надпись «МЫ В ЗАЩИЩЕННОМ РЕЖИМЕ». Кроме того, после возврата в реальный режим, программа выводит на экран числовое значения поля TYPE дескриптора видеопамяти (смотри формат дескриптора). Программу надо запускать, находясь в «чистой» DOS (без EMM и других подобных драйверов). Программу можно было написать значительно проще, но здесь преследовалась цель продемонстрировать общие принципы переключения в защищенный режим:
|
code segment |
|
|
p486 |
|
|
org 100h |
|
|
assume cs:code, ds:code |
|
|
start: jmp begin |
|
|
mess db 'Ура, мы в ЗР!' |
|
|
gdt dd 0 |
|
|
dd 0 |
; пустой дескриптор |
|
dw 0ffffh |
; дескриптор видеопамяти |
|
dw 8000h |
|
|
db 0bh |
|
|
db 92h |
|
|
dw 0 |
|
|
desc_gdt dq 0 |
;заготовка под дескриптор ;GDT |
|
begin: |
|
|
mov si,offset desc_gdt |
; заносим в заготовку размер ;и адрес GDT |
|
mov word ptr [si],15 |
; это размер |
|
mov ebx,0 |
|
|
mov bx,offset gdt |
|
push cs |
|
|
mov eax,0 |
|
|
pop ax |
|
|
shl eax,4 |
|
|
add ebx,eax |
|
|
mov [si+2],ebx |
; а это адрес |
|
lgdt pword ptr [si] |
; а теперь перекидываем ;заготовку в GDTR |
|
mov eax,cr0 |
|
|
mov edx,eax |
|
|
cli |
|
|
or eax,1 |
|
|
mov cr0,eax |
; переключение в ;защищенный режим |
|
mov ax,8 |
|
|
mov es,ax |
; заносим в ES дескриптор ;видеопамяти |
|
cld |
;чистим экран |
|
mov di,0 |
|
|
mov ax,7020h |
|
|
mov cx,2000 |
|
|
rep stosw |
;выводим надпись |
|
mov bx,offset mess |
|
|
mov si,1010 |
|
|
mov cx,22 |
|
|
m: |
|
|
mov al,[bx] |
|
|
mov es:[si],al |
|
|
add si,2 |
|
|
inc bx |
|
loop m |
|
|
mov cr0,edx |
;выходим обратно в ;реальный режим |
|
sti |
|
|
mov si,1348 mov di,offset gdt mov al,[di+13] and al,0fh add al,30h mov es:[si],al mov ah,7 int 21h mov ah,4ch int 21h code ends end start |
; этот фрагмент доказывает, ;что МП использует в РР ;начальный адрес из теневой ;части сегментного регистра, ;а не из видимой ( в видимой ;части ES - 8, а значение ;выводится в видеопамять!!) ;и также показывает, что ;МП сам устанавливает бит ;А в дескрипторе ;(было 92,стало 93 (на экран ;выводится 3)) |
3.4. Системные таблицы
Таблица GDT. Эта таблица создается еще в реальном режиме и содержит следующие виды дескрипторов:
- дескрипторы сегментов ОС;
- дескрипторы сегментов, разделяемых задачами;
- дескриптор самой GDT, где она описана как сегмент данных ( с тем чтобы мы могли вносить в GDT изменения);
- дескриптор таблицы IDT, где она описана как сегмент данных (причины те же);
- дескрипторы всех созданных в системе таблиц LDT;
- альтернативные дескрипторы для всех LDT, где эти таблицы описаны как сегменты данных;
- дескрипторы всех сегментов TSS;
- альтернативные дескрипторы для всех TSS, где TSS описаны как сегменты данных;
- возможно другие дескрипторы и шлюзы.
Не все перечисленные дескрипторы должны обязательно присутствовать в GDT. Нулевой (первый дескриптор) дескриптор в GDT обязательно должен быть пустым (одни нули). Его использует МП для системных целей.
Для того чтобы МП знал, где в ОП располагается таблица GDT, внутри МП имеется специальный регистр gdtr. Его формат приведен на рис. 3.7.
|
47 16 |
15 0 |
|
Начальный адрес GDT |
Размер GDT |
Рис. 3.7
Размер GDT задается в байтах. Для загрузки регистра используется команда lgdt m40/m48. Команда загружает в регистр 5 или 6 байтов из памяти. Например, следующая команда загружает в регистр gdtr 6 байтов из области памяти, на которую указывает регистр si:
lgdt pword ptr [si].
Команда lgdt допустима как в реальном, так и в защищенном режимах, но в защищенном она доступна только на 0-м уровне привилегий. При первом использовании этой команды задается местоположение таблицы в памяти и ее размер. В дальнейшем эта команда может использоваться для изменения размера GDT, например, если понадобилось добавить в GDT новые дескрипторы. Менять местоположение GDT в памяти не имеет никакого смысла (хотя рассматриваемая команда и предоставляет такую возможность).
Таблица GDT в системе всегда одна и всегда должна находиться в ОП. Содержимое этой таблицы постоянно обновляется ОС и самим МП. Например, отправив сегмент из ОП на диск, ОС должна соответствующим образом пометить дескриптор этого сегмента. Чтобы можно было изменять содержимое GDT, должен быть создан дескриптор, где эта таблица была бы описана как сегмент данных. Этот дескриптор располагают в самой GDT.
Таблица IDT ‑ дескрипторная таблица прерываний, и в ней располагаются только шлюзы. Связано это с тем, что прерывание может произойти, когда находимся на любом уровне привилегий (может на 0-м, а может на 3-м). При этом, на каком бы уровне не находились, должны получить доступ к обработчику. Иначе говоря, обработчик любого прерывания должен быть доступен (через IDT) с любого уровня привилегий. Это можно осуществить только через шлюз. В данной таблице могут располагаться шлюзы трех типов: шлюзы задач; шлюзы ловушки; шлюзы прерывания.
Таблица IDT, так же, как и таблица прерываний МП 8086, задает 256 (или меньше) обработчиков прерываний. Для каждого имеющегося в системе обработчика в таблице должен быть шлюз. Учитывая что шлюз занимает в памяти 8 байт, можно сделать вывод что максимальный размер IDT равен 256×8 = 2 Кбайта. В реальном режиме и в МП 8086 размер таблицы векторов прерываний 1 Кбайт.
Таблица IDT может располагаться в любом месте ОП (в отличие от МП 8086, где подобная таблица фиксируется в младшем килобайте ОП). Для того чтобы МП 486 знал, где находится IDT и каков ее размер, внутри МП имеется регистр idtr. Его формат аналогичен рассмотренному выше формату регистра gdtr. Отсюда следует (смотри формат регистра), что можем задать размер IDT больше 2 Кбайт (вплоть до 64 Кбайт), но смысл будут иметь не более двух младших килобайт этой области, так как обработчиков не может быть больше 256-ти. Загрузка регистра idtr производится командой lidt m40/m48. Для этой команды справедливо все сказанное выше о команде lgdt.
Таблица IDT в системе всегда одна и всегда должна находиться в ОП. Содержимое этой таблицы по ходу работы может меняться. Чтобы можно было менять содержимое IDT, для нее должен быть создан дескриптор, в котором эта таблица описана как сегмент данных. Этот дескриптор размещается в GDT.
Таблицы LDT. Для каждой задачи в системе может быть создана своя таблица LDT. В нее сводятся дескрипторы всех сегментов, с которыми работает только эта задача. В LDT могут находиться дескрипторы сегментов кода, данных и стека, а также шлюзы вызова и задач.
Подобных таблиц в системе может быть много и располагаться они могут и в ОП, и на диске. Для того чтобы МП знал, где находится LDT текущей задачи, в его состав введен специальный регистр ldtr. Формат этого регистра не похож на формат gdtr, а скорее похож на формат обычного сегментного регистра (рис. 3.8).
|
15 0 |
63 0 |
|
| Селектор LDT |
Дескриптор LDT |
|
|
Видимая часть |
Теневая часть |
Рис. 3.8
Смена LDT происходит при смене задачи. МП загружает в ldtr новый селектор, задающий дескриптор LDT в таблице GDT, т.е. «с точки зрения GDT» таблица LDT представляет из себя сегмент специального вида. У этого сегмента есть дескриптор, который располагается в GDT и в котором задан начальный адрес LDT, ее размер и т.д.
В видимую часть загружается селектор, адресующий дескриптор LDT в таблице GDT. При правильном обращении из этого дескриптора берутся начальный адрес и размер LDT и копируются в теневую часть ldtr, с тем чтоб дальше эта информация была у МП «под рукой». В процессе работы системы загрузка нового селектора в видимую часть ldtr (следовательно, и смена LDT) происходит при переходе на новую задачу. Новый селектор берется из соответствующего поля сегмента TSS входящей задачи. Для первоначальной загрузки регистра ldtr применяется команда lldt r16/m16. Эта команда загружает в ldtr новый селектор из любого 16-разрядного регистра МП или из памяти. Эта команда доступна только в защищенном режиме и только на 0-м уровне привилегий.
Содержимое таблиц LDT может меняться по ходу работы. Чтобы была возможность вносить изменения в LDT, для каждой из них должен быть создан альтернативный дескриптор, где эти таблицы описаны как сегменты данных. Такие дескрипторы располагаются в GDT.
Сегменты TSS. Сегмент TSS (сегмент состояния задачи) создается для каждой задачи в системе. Размер TSS должен быть не менее 104 байт (67h). В этот сегмент в определенном порядке загружается содержимое почти всех внутренних регистров процессора. Эта информация называется текущим состоянием задачи или контекстом задачи. При переключении на новую (входящую) задачу МП автоматически копирует содержимое своих регистров в TSS выходящей задачи и загружает в эти регистры информацию из TSS входящей задачи. Происходит переключение на новую задачу. МП при этом должен знать, где в ОП находятся сегменты TSS и входящей и выходящей задач.
Переключиться на новую задачу можно только, обратившись к дескриптору TSS задачи (такие дескрипторы располагаются в GDT). Это можно сделать, обратившись к такому дескриптору либо напрямую, либо косвенным образом через шлюз задачи (командами jmp far, call far, retf иiret). Так как в дескрипторе TSS располагается начальный адрес этого сегмента, то процессору известно, где в памяти находится TSS входящей задачи. Чтобы МП знал, где в ОП находится TSS текущей задачи (при переключении задач текущая задача становится выходящей), внутри МП есть регистр tr (регистр задачи). Формат регистра tr аналогичен формату регистра ldtr. В видимой части регистра tr располагается селектор, адресующий дескриптор сегмента TSS в таблице GDT, а в теневой части ‑ копия этого дескриптора (начальный адрес этого TSS в ОП и его размер). Таким образом, адрес TSS выходящей задачи МП тоже известен.
Содержимое регистра tr в процессе работы меняется при смене задач, когда в видимую часть этого регистра загружается новый селектор. Для начальной загрузки этого регистра используется команда ltr r16/m16. Эта команда аналогична рассмотренной выше команде lldt.
Сегменты TSS сильно привилегированны, с ними может работать только сам МП. Часто необходимо внести изменения во внутреннее содержимое сегмента TSS (например, при задании исходного контекста задачи). Поэтому для любого TSS создается альтернативный дескриптор, в который этот сегмент описан как обычный сегмент данных.
3.5. Механизмы адресации в защищенном режиме
В защищенном режиме существуют три различных механизма формирования физического адреса:
- сегментный механизм;
- страничный механизм;
- механизм виртуального 86-го процессора (V86).
Механизм V86 представляет специфическую форму сегментного механизма. В защищенном режиме работает либо сегментный механизм, либо механизм V86. Страничный механизм (в отличие от сегментного) можем включать и отключать. Страничный механизм не может работать сам по себе, так как исходной информацией для него является адрес, вырабатываемый сегментным механизмом (или механизмом V86). Страничный механизм всегда работает после сегментного. Далее рассмотрим подробно работу всех этих механизмов, но прежде отметим что в МП 286 страничный механизм и механизм V86 не реализованы.
3.6. Сегментный механизм
Рассмотрим более подробно формат сегментного регистра, показанный на рис. 3.9.
|
15 3 |
2 |
1 0 |
63 0 |
|
|
Селектор |
TI | RPL |
Копия дескриптора |
|
|
Видимая часть |
Теневая часть |
|||
Рис. 3.9
Тринадцать старших разрядов видимой части занимает селектор, адресующий дескриптор в одной из двух дескрипторных таблиц. В какой именно таблице находится этот дескриптор, определяет бит TI. Если он равен 0, то адресуется GDT, при TI = 1 адресуется LDT. В теневой части МП хранит копию этого дескриптора.
Поле RPL задает «запрашиваемый уровень привилегий». Существуют три структуры, связанные с понятием уровня привилегий:
- DPL ‑ это два бита в дескрипторе, задающие уровень привилегий сегмента;
- CPL ‑ это два младших бита видимой части сегментного регистра cs, т.е. это текущий уровень привилегий, на котором выполняется текущая программа (задача);
- RPL ‑ это два младших бита слова (селектора), загружаемого в видимую часть любого сегментного регистра при смене сегмента.
При смене сегмента данных МП проверяет права доступа к новому сегменту, реализуя проверку неравенства:
DPL³max {CPL, RPL}.
Если это условие не выполняется, то доступ к новому сегменту данных предоставлен не будет, а будет прерывание. При смене сегмента кода проводится более жесткая проверка:
DPL = max {CPL, RPL}.
Из всего сказанного выше можно сделать следующие выводы. Можно перейти к новому сегменту данных, уровень привилегий которого равен нашему CPL или ниже его (по смыслу ниже, а по величине больше), путем непосредственного обращения к дескриптору этого сегмента. Перейти же к более привилегированному (чем текущий CPL) сегменту данных не удастся, поскольку шлюзов для сегментов данных не существует. Для сегментов кода ситуация иная. Можно перейти к сегменту кода с таким же уровнем привилегий (совпадающим с CPL), обратившись к его дескриптору, или перейти к более привилегированному сегменту кода через шлюз. Невозможно перейти к менее привилегированному сегменту кода, даже если он помечен как согласованный. Кроме того, существует правило, согласно которому текущий DPL стека должен равняться CPL. То есть уровень привилегий стека должен быть таким же, как уровень привилегий текущей программы (сегменты данных могут быть менее привилегированными). За соблюдением этого правила следит сам МП, автоматически меняя стек при изменении уровня CPL на более высокий. Как он это делает, будет показано в дальнейшем.
Поле RPL иногда используется для понижения текущего уровня привилегий. Если хотим, чтобы RPL ни на что не влияло, надо брать RPL = 0. Например, RPL может использоваться в следующей ситуации. Пусть имеется привилегированная подпрограмма (нулевого уровня), к которой можем обратиться с пользовательского (третьего) уровня через известный нам шлюз. Пусть эта подпрограмма записывает информацию в заказанную область памяти. Параметром, передаваемым в эту подпрограмму, является селектор дескриптора сегмента данных, в который запрашиваем запись. Поскольку этот селектор формирует программист перед обращением к подпрограмме, то может возникнуть соблазн «обмануть» систему. Для этого записываем в этот селектор RPL = 0 и «просим» подпрограмму записать информацию в какой-нибудь системный сегмент (сегмент данных нулевого уровня).
Если не предпринимать никаких мер, эта попытка будет успешной, так как подпрограмма имеет CPL = 0 и RPL = 0. Процессор отследить такие ситуации не может, они для него слишком сложные. Однако эту ситуацию может отследить сама подпрограмма. Для этого, получив селектор, она определяет CPL задачи, которая ее вызвала. Сделать это ей нетрудно, поскольку в ее стеке лежит адрес возврата в исходную программу. Определив, что вызов был с третьего уровня, подпрограмма меняет RPL в переданном ей селекторе с нуля на тройку, понижая тем самым собственный уровень привилегий. В результате мы не сможем обратиться к заказанному сегменту данных, если его уровень привилегий выше трех.
Далее рассмотрим работу сегментного механизма при обращении в текущем сегменте, допустим, на примере выполнения команды mov [bx+2] ,al.
1. МП вычисляет Аэф, для нашей команды Аэф = (bx)+2.
2. МП проверяет, не выводит ли полученный Аэф за заданные границы сегмента. Размер сегмента МП (для рассматриваемой команды) возьмет из теневой части сегментного регистра ds.
3. МП проверяет соответствие выполняемой команды заданным атрибутам сегмента. Атрибуты он также возьмет из теневой части ds. Для рассматриваемой команды будет произведена проверка «разрешен ли сегмент для записи».
4. Если обе проверки прошли успешно, то МП формирует физический адрес по формуле Аф = начальный адрес сегмента + Аэф. Начальный адрес сегмента он также возьмет из теневой части ds.
5. Если какая-то из проверок была неудачной, то МП генерирует соответствующее прерывание.
Рассмотрим далее работу сегментного механизма при смене сегмента. Чтобы перейти к новому сегменту (сменить сегмент), надо загрузить новый селектор в видимую часть соответствующего сегментного регистра. Для регистра cs здесь можно использовать команды jmp far, call far и другие, а для остальных сегментных регистров ‑ mov sr , r16; pop sr и ряд других.
МП берет загружаемый селектор и по биту TI определяет, на какую дескрипторную таблицу он ссылается. Затем МП проверяет, не выводит ли этот селектор за заданные (в gdtr или ldtr) размеры таблицы. Если не выводит, МП обращается в таблицу и находит там адресуемый дескриптор. Производится ряд проверок (в частности, проверяются права доступа) и, если все они прошли удачно, в теневую часть сегментного регистра (в который команда загружает селектор) копируется найденный дескриптор, а в видимую часть этого регистра из команды загружается селектор.
Рассмотрим примерную последовательность действий МП при выполнении команды pop ds. Эта команда выталкивает из стека в видимую часть ds новый селектор и, следовательно, должна (если все проверки пройдут успешно) привести к смене сегмента данных. Однако сначала МП еще должен найти в стеке этот селектор. Поэтому вначале выполнения этой команды идет обращение в текущем сегменте стека.
1. МП вычисляет Аэф = (sp).
2 Проверяет, не выводит ли этот адрес за заданные границы стека. Размер стека он берет из теневой части ss.
3. Если проверка прошла удачно, то МП берет из теневой части ss начальный адрес сегмента стека и формирует Аф = начальный адрес + Аэф. По этому адресу из ОП считывается слово, представляющее собой (по смыслу команды) новый селектор. Только с этого момента начинается смена сегмента.
3. По биту TI определяется дескрипторная таблица.
4. Проверяется, не выводит ли селектор за заданные размеры таблицы.
5. В таблице отыскивается адресуемый дескриптор.
6. Проверяется, находится ли сегмент в ОП (по информации в дескрипторе).
7. Проверяются права доступа.
8. Проверяется, отмечен ли адресуемый дескриптор как дескриптор сегмента данных (поскольку в команде указан ds) или как сегмент кода, разрешенный для чтения.
9. Если все проверки прошли успешно, то в теневую часть ds загружается копия найденного дескриптора и далее мы работаем с новым сегментом данных.
Приведем требования к сегментам, загружаемым в различные сегментные регистры процессора:
- в cs можно загружать только дескрипторы сегментов кода, причем запись в кодовый сегмент всегда запрещена;
- в ds, es, fs и gs можно загружать дескрипторы сегментов данных и дескрипторы сегментов кода, но последние должны обязательно быть разрешены для чтения;
- наиболее жесткими являются требования для регистра ss, в этот регистр можно загружать только дескрипторы сегментов данных, обязательно разрешенные для записи, у которых dpl = cpl и биты G и D в дескрипторе (см. формат дескриптора ) равны между собой.
При любом нарушении вышеперечисленных условий будет прерывание.
Сегментный механизм в защищенном режиме выключить нельзя, но его можно подавить. Для этого надо обеспечить загрузку в теневые части всех сегментных регистров дескрипторов, описывающих один и тот же сегмент. Обычно берется сегмент с начальным адресом 00000000h, имеющий размер 4 Гбайта и уровень привилегий 0 или 3. После этого содержимое сегментных регистров не меняется. Таким образом, все время работаем в одном сегменте, в котором располагаются и программа, и стек, и данные. Так как начальный адрес этого сегмента равен нулю, то адрес, поставленный программистом в команде, будет сразу физическим адресом и при этом адресуемый объем памяти равен 4 Гбайта. Это удобно. Такая бессегментная память называется линейной (или плоской – flat) памятью. Однако такой способ организации памяти имеет и недостатки: теряются механизм защиты и многозадачность.
Страничный механизм при такой организации использовать можно. Появляется механизм защиты на уровне страниц. В минимальном случае при организации линейной памяти достаточно иметь GDT, содержащую два дескриптора (один ‑ кода, а другой ‑ данных).
3.7. Страничный механизм
Этот механизм, в отличие от сегментного, можно включать и выключать по желанию, но задача относится к прерогативе системного программиста, а не пользователя. Для того чтобы включить страничный механизм, достаточно установить в единицу бит PG в регистре cr0. Это старший (31-й) бит этого регистра. Сделать это можно только командой mov cr0 , r3 . Команда lmsw r16/m 16 здесь не годится, так как она загружает только младшую половину cr0. При попытке включить страничный механизм в реальном режиме будет прерывание.
К серьезным недостаткам сегментного механизма относится трудность организации подкачки сегментов с диска, поскольку сегменты имеют разные размеры и могут быть очень большими по объему. В отличие от сегментов страницы имеют фиксированный размер 4 Кбайта и располагаются в строго определенных местах ОП. Нулевая страница располагается в адресах 00000000h ‑ 00000fffh, первая ‑ в адресах 00001000h ‑ 00001fffh и т.д. Пересекаться страницы не могут. Отметим, что в Pentium используются страницы размером 4 Кбайта и 4 Мбайта, а в Р6 – 4 Кбайта, 4 Мбайта и 2 Мбайта. В дальнейшем будем называть страницы объемом 4 Кбайта обычными, а 4 Мбайта и 2 Мбайта – большими. В данном разделе речь пойдет только об обычных страницах.
Двенадцать младших разрядов начального адреса любой обычной страницы всегда равны нулю. Поэтому любой объект в памяти, имеющий подобный начальный адрес, называется выровненным по границе страницы.
Всего в ОП может быть создано 220 страниц (4 Гбайта делить на 4 Кбайта). Все страницы объединяются в блоки. В один блок может входить до 210 страниц, при этом совсем необязательно подряд идущих. Иначе говоря, в блок могут входить 100-я страница, 5-я страница, 346-я страница и т.д. Для каждого блока создается таблица страниц. Каждый элемент этой таблицы описывает одну из входящих в блок страниц. Элемент таблицы страниц занимает в памяти 4 байта и называется элементом PTE (page table entry). Элемент PTE содержит начальный адрес (20 старших разрядов этого адреса, поскольку 12 младших все равно равны нулю) и атрибуты страницы, которую это элемент описывает. Одна таблица страниц занимает в памяти одну страницу (210×4 байта = 4 Кбайта). Соответственно, любая таблица страниц выровнена по границе страницы, т.е. 12 младших разрядов ее начального адреса равны нулю. Легко видеть, что блоков, а следовательно и таблиц страниц может быть создано до 210.
Для всех таблиц страниц в памяти создается каталог таблиц. Он также занимает в памяти ровно одну страницу и выровнен по ее границе. Элементы каталога (они называются PDE (page directory entry)) аналогичны элементам PTE, только описывают они не страницы, а таблицы страниц. Начальный адрес (вернее, его 20 старших разрядов) каталога задаются МП в регистре cr3. При включенном страничном механизме каталог всегда должен находиться в ОП, а таблицы и страницы могут находиться как в памяти, так и на диске. Если идет обращение к странице (или таблице), которая находится на диске, то происходит прерывание. Обработчик этого прерывания должен подкачать страницу с диска, после чего производится рестарт команды.
При включенном страничном механизме адрес, вырабатываемый сегментным механизмом (раньше мы его все время называли физическим), еще не является физическим адресом. Этот адрес принято называть линейным (Ал). Линейный адрес условно разбивается на три части (поля). Поле DIR задает смещение в каталоге, поле PAGE ‑ смещение в таблице, а поле OFFSET ‑ смещение в самой странице. На рис. 3.10 ‑ 3.12 приводится графическая интерпретация работы страничного механизма с соответствующими пояснениями.
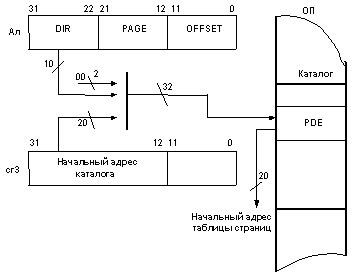
Рис. 3.10
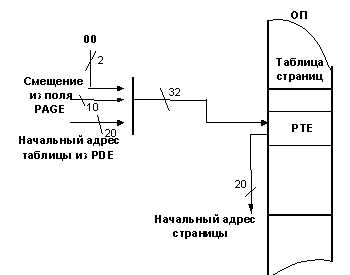
Рис. 3.11
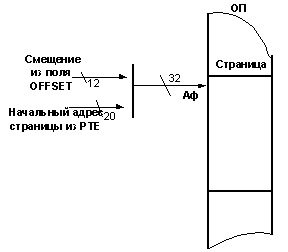
Рис. 3.12
Итак, вначале работает сегментный механизм, который формирует линейный адрес Ал. Затем начинает работать страничный механизм. МП берет из регистра CR3 20 старших разрядов начального адреса каталога, «пристыковывает» к ним 10 разрядов из поля DIR линейного адреса и в младшие разряды добавляет два нуля (см. рис. 3.10). Тем самым МП формирует адрес элемента PDE. Элемент PDE занимает в памяти 4 байта и всегда выровнен по границе двойного слова, поэтому два младших разряда его адреса берутся равными нулю. Из найденного в памяти элемента PDE процессор извлекает начальный адрес таблицы страниц (20 старших разрядов этого адреса) и переходит к следующему этапу (см. рис. 3.11).
Этот этап очень похож на предыдущий. К 20-ти старшим разрядам начального адреса страницы, взятым из PDE, МП «пристыковывает» 10-разрядное смещение из поля PAGE линейного адреса Ал и в младшие разряды дописывает два нуля. Таким образом, МП формирует адрес элемента PTE, из которого он извлекает начальный адрес страницы (20 старших разрядов этого адреса). Затем МП переходит к последнему этапу формирования физического адреса (см. рис. 3.12). На этом этапе к 20 старшим разрядам начального адреса страницы, взятым из PTE, «пристыковывается» 12-разрядное внутристраничное смещение из поля OFFSET линейного адреса Ал. В результате получается физический адрес Аф.
Как видно, страничный механизм весьма громоздкий и требует только для формирования физического адреса двух обращений в память. Если это механизм будет всегда работать, то ожидать от МП высокого быстродействия не приходится. Поэтому для повышения быстродействия в состав МП введена кэш-память страниц (буфер TLB (translation lookaside buffer – буфер предыстории трансляции)). В этом буфере хранятся начальные адреса 32-х страниц, к которым были последние обращения процессора. После того как сегментный механизм выработал Ал, МП прежде всего ищет начальный адрес нужной страницы в буфере TLB, и только если его там не окажется (а это бывает крайне редко, так как процент кэш-попаданий в буфер составляет 95 %), включается рассмотренный выше страничный механизм.
Страничный механизм предоставляет программисту (системному) следующие возможности.
1. Дает возможность упростить алгоритмы подкачки информации с диска, поскольку обмен информацией с диском ведется страницами, имеющими одинаковый небольшой размер.
2. Устраняет возможность возникновения фрагментации памяти (при обмене с диском разноразмерными сегментами в памяти неизбежно возникают «дыры»).
3. Позволяет «транслировать» вырабатываемые процессором линейные адреса в другие области ОП. Когда программист пишет команду, адресующую ОП, он задает в этой команде адрес. Сегментный механизм преобразует этот адрес в Ал, а страничный механизм преобразует Ал в Аф. При этом, как правило, Аф совсем не похож на Ал. Поэтому и говорят, что процессор транслирует Ал в другое место ОП. Например, пусть сегментный механизм выработал Ал = 00000008h, а в элементе PTE, к которому обратимся по ходу работы страничного механизма (кстати, из Ал видно, что этот PTE будет 0-м элементом соответствующей таблицы страниц), в поле «начальный адрес страницы» задано 777ffh. Тогда Аф будет равен 777ff008h. Нетрудно создать страницу, для которой линейные адреса будут совпадать с физическими, для этого надо записать соответствующую информацию в соответствующие элементы PDE и PTE. Такие страницы называются страницами с прямым отображением в память. Возможность трансляции адресов является важным свойством страничного механизма и широко используется на практике.
Приведем простой пример. Если какую-то страницу из ОП сбросили на диск, а потом вернули обратно в память, то эта страница скорее всего окажется совсем в другом месте ОП. Ничего страшного. Достаточно изменить информацию в PTE, и вырабатываемые при обращении к этой странице адреса будут транслироваться в новое место ОП.
3.8. Формат элемента PTE (PDE)
Формат элемента PTE (PDE) приведен на рис. 3.13.
|
31 12 |
11 9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
Нач. адр. |
avl |
g |
ps |
d |
a |
Pcd |
pwt |
u/s |
r/w |
p |
Рис. 3.13
Для обычных страниц поле «начальный адрес» в PTE задает начальный адрес страницы, а такое же поле в PDE – начальный адрес таблицы страниц. Для больших страниц начальный адрес страницы задается в PDE, а таблицы страниц и PTE для таких страниц отсутствуют.
AVL (available ‑ свободный) ‑ 3 бита системного программиста. МП с этими битами не работает и их может использовать по своему усмотрению системный программист. Обычно в этих битах накапливают некоторую статистику (число обращений к данной странице и т.д.). В дальнейшем эту статистику можно использовать при решении вопроса о том, какую страницу лучше сбросить на диск.
G (global) – глобальная страница. Бит появился в Р6. Если страница отмечена как глобальная, то при очистке буфера TLB начальный адрес такой страницы из буфера не удаляется. Так как очистка TLB обычно происходит при смене задач, получается, что глобальная страница как бы передается из задачи в задачу. Для обычных страниц бит G определен в PTE, а для больших – в PDE. Процессор обращает внимание на бит G только, если бит PGE в регистре cr4 установлен в единицу.
PS (page size) – размер страницы. Для любых страниц этот бит определен в PDE. При PS = 0 ‑ обычная страница, при PS = 1 – большая страница. Бит PS появился в Pentium. Процессор обращает на него внимание, если один из битов PSE или PAE в регистре cr4 установлен в единицу.
D (dirty) ‑ «грязный бит». МП автоматически устанавливает этот бит в единицу, если в данную страницу была запись. Сбрасывать этот бит МП не умеет и если это нужно сделать ‑ это задача системного программиста. Бит D проверяют, когда страница сбрасывается на диск. При этом если в страницу не было записи, ее не надо физически переписывать на диск (она там уже есть, причем точно такая же), а достаточно отметить ее как отсутствующую в ОП. Если же запись в страницу была, то ее надо переписать на диск физически. Для больших страниц бит D определен в PDE, для обычных ‑ в PTE.
A (accessed) ‑ бит обращения. Этот бит также устанавливает сам МП (сбрасывает системный программист), если к странице было обращение. Этот бит можно привлекать при решении задачи о том, какую страницу лучше отправить на диск.
Биты PCD (page-level cache disable) и PWT (page ‑ level write through) задают стратегию кэширования данной страницы (таблицы). Если PCD = 1, то страница запрещена к кэшированию. При PWT = 0 используется так называемая «обратная запись», а при PWT = 1 ‑ «сквозная запись». Что это такое, будет объяснено позже. Эти биты появились в МП 486.
U/S (user/supervisor) ‑ пользователь/супервизор. Если U/S = 1, то с данной страницей можно работать на любом уровне привилегий, в том числе и на 3-м (пользовательском). При U/S = 0 страница доступна только с уровней 0, 1 и 2 (уровни ОС).
R/W (read/write) ‑ чтение/запись. Если R/W = 1, то для страницы разрешены и чтение и запись. Если R/W = 0, то запись в страницу запрещена. Бит R/W имеет смысл только на уровне пользователя. На уровнях ОС страница всегда доступна для записи (это не совсем точно, начиная с МП 486 имеется возможность запретить ОС запись в страницу). Таким образом, биты U/S и R/W совместно организуют защиту на уровне страниц.
P (present) ‑ бит присутствия. Если Р = 1, то страница присутствует в ОП, при Р = 0 – отсутствует, находится на диске. В последнем случае вся остальная информация в PTE не имеет приведенного выше смысла. Обычно если Р = 0, то в остальные разряды РТЕ системный программист записывает информацию о том, где на диске искать эту страницу. Процессор этот бит только проверяет. Изменять значение этого бита – прерогатива ОС.
3.9. Особенности страничного механизма в Pentium и Р6
В Pentium реализовано два варианта страничного механизма.
1. При PSE = 0 все страницы в системе 4-Кбайтов и механизм работы с ними ничем не отличается от рассмотренного выше.
2. При PSE = 1 одновременно могут использоваться 4-Кбайтовые и 4-Мбайтовые страницы. Обращение к 4 Мбайтовым страницам пояснено на рис. 3.14.
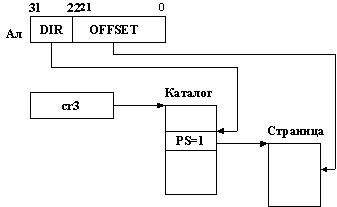
Рис. 3.14
Как видно из рис. 3.14, содержимое регистра cr3 задает (как и ранее) начальный адрес каталога, поле DIR адресует элемент PDE в каталоге. Если в этом элементе PDE бит PS = 1, то из PDE берется начальный адрес страницы, а поле OFFSET задает смещение в странице.
В Р6 реализовано три варианта страничного механизма:
1. PAE = PSE = 0 – только 4-Кбайтовые страницы.
2. PAE = 0, PSE = 1 – и 4-Кбайтовые, и 4-Мбайтовые одновременно.
3. PAE = 1, PSE = безразлично – и 4-Кбайтовые, и 2-Мбайтовые одновременно.
Первые два варианта ничем не отличаются от рассмотренных выше. Рассмотрим третий вариант.
Бит PAE – расширение физического адреса. Если этот бит установлен в единицу, то к процессору добавляются четыре адресные линии А35-32 и он начинает адресовать 64 Гбайта оперативной памяти. Сегментный механизм продолжает вырабатывать 32-разрядный адрес, т.е. реально процессор адресует все те же 4 Гбайта ОП. Однако страничный механизм дает возможность транслировать эти 4 Гбайта в любое место 64-Гбайтового пространства.
Поскольку формат физического адреса увеличивается до 36 бит, то четырех байт, отводимых под элементы PTE и PDE, оказывается недостаточно, и эти элементы стано-вятся восьмибайтными (рис. 3.15). Размер каталога и таблиц страниц при этом не меняется (остается равным 4 Кбайта), следовательно количество элементов (соответ-ственно, PDE и PTE) в каждой из этих структур уменьшается в два раза.
|
63 36 |
35 12 |
11 9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
|
Рез-т |
Нач. адр. |
avl |
g |
ps |
d |
a |
pcd |
pwt |
u/s |
r/w |
p |
|
Рис. 3.15
Иначе говоря, получается, что процессор может адресовать только 218 страниц. Для того чтобы он мог адресовать, как и положено, 220 страниц, в систему вводится не один, а четыре каталога. Для их адресации вводится еще одна структура, называемая таблицей указателей на каталог, включающая в себя четыре восьмибайтов указателя DPE (directory pointer entry). Формат DPE представлен на рис. 3.16.
|
63 36 |
35 12 |
11 9 |
8 5 |
4 |
3 |
2 1 |
0 |
|
Рез-т |
Нач. адр. катал. |
AVL |
Рез-т |
PCD |
PWT |
Рез-т |
1 |
Рис. 3.16
Регистр cr3 задает начальный адрес таблицы указателей, при этом этот адрес занимает разряды 31‑5 данного регистра. Можно сделать вывод, что таблица указателей на каталог всегда занимает в памяти 32 байта (четыре элемента по восемь байт каждый) и всегда должна быть выровнена по 32-байтовой границе (пять младших разрядов начального адреса таблицы указателей равны нулю).
Рис. 3.17 и 3.18 поясняют работу страничного механизма при РАЕ = 1, соответственно, для 4-Кбайтовых и 2-Мбайтовых страниц. Как видно из рис. 3.17, 3.18, разряды 31‑30 линейного адреса теперь задают один из четырех элементов DPE в таблице указателей на каталог.
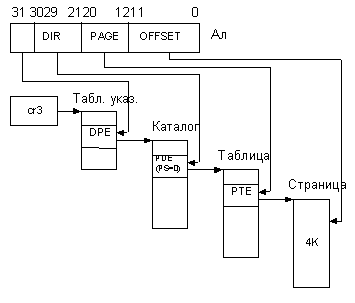
Рис. 3.17
Работа с 4-Кбайтовыми и 2-Мбайтовыми страницами требует, как видно из рис. 3.17 и 3.18, трехуровневой структуры таблиц и расширения форматов PTE и PDE до 8 байтов. Эти отличия от исходного алгоритма работы страничного механизма на практике приводят к трудностям в реализации операционных систем.
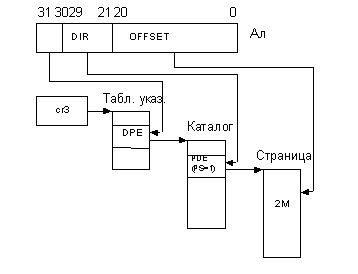
Рис. 3.18
Для того чтобы исключить этот недостаток и в то же время сохранить возможность адресации 64 Гбайт памяти, начиная со старших моделей Р6 введен еще один вариант страничного механизма, который фирма назвала PSE-36. Этот вариант позволяет использовать 36-разрядную адресную шину и адресовать 64 Гбайт памяти. В то же время в этом варианте используется двухуровневая структура таблиц, а элементы этих таблиц имеют формат 4 байта.
Для того чтобы установить, поддерживает ли данный процессор механизм PSE-36, надо выполнить команду cpuid приeax = 1. Если после выполнения этой команды в бите 17 регистра edx вернулась единица, значит рассматриваемый механизм поддерживается. Подробней см. разд. 3.29.
Необходимо отметить, что механизм PSE-36 отменяет вариант, когда 4-Кбайтовые и 4-Мбайтовые страницы адресуют 4 Гбайта памяти (вариант 2 для Р6, см. выше в этом же разделе), вернее этот вариант просто вырождается в частный случай PSE-36. В механизме PSE-36 используются 4-Кбайтовые и 4-Мбайтовые страницы, при этом 4-Кбайтовые страницы позволяют обратиться только к 4-Гбайтовому адресному пространству, а страницы 4-Мбайтовые – к 64-Гбайтовому адресному пространству. В табл. 3.9 приведены варианты страничной трансляции для процессоров, поддерживающих PSE-36.
Таблица 3.9
|
бит PG (cr0) |
бит PAE (cr4) |
бит PSE (cr4) |
бит PS (PDE) |
размер страницы |
Шина адреса |
|
0 |
* |
* |
* |
нет |
32 бита (страничный механизм выключен) |
|
1 |
0 |
0 |
* |
4 Кб |
32 бита |
|
1 |
0 |
1 |
0 |
4 Кб |
32 бита |
|
1 |
0 |
1 |
1 |
4 Мб |
36 бит |
|
1 |
1 |
* |
0 |
4 Кб |
36 бит |
|
1 |
1 |
* |
1 |
2 Мб |
36 бит |
Вариант PSE-36 выделен в табл. 3.9 жирной строкой. Рассмотрим этот вариант. Для адресации 64 Гбайт памяти адрес должен быть 36-разрядным. Двадцать два младших разряда начального адреса любой 4-Мбайтовой страницы всегда равны нулю. Следовательно, в поле начального адреса страницы в элементе PDE (при PS = 1) должны быть записаны 14 старших разрядов этого адреса. В то же время это поле начального адреса имеет формат 20 бит (биты 31 ‑ 12), так как столько разрядов необходимо для задания адреса 4-Кбайтовой страницы. Для 4-Мбайтовых страниц биты 21 ‑ 12 поля начального адреса являются резервными. Этот факт и использован в PSE-36, поскольку появляется возможность (за счет резервных битов) не увеличивать формат элемента PDE, что определяет двухуровневую структуру таблиц. Старшие разряды адреса (А35-32) располагаются в резервных битах 16 ‑ 13 поля начального адресаа. Для 4-Мбайтовых страниц есть два формата поля начального адреса в PDE:
- PSE-36 не поддеррживается, разряды 31 ‑ 22 – начальный адрес (А31-22), разряды 21 ‑ 12 – резерв.
- PSE-36 поддерживается, разряды 31 ‑‑22 – адрес (А31 ‑ 22), разряды 21 ‑ 17 – резерв, разряды 16 ‑ 13 – адрес (А35 ‑ 32) и бит 12 используется для специальных целей, связанных со стратегией кэширования (можно считать его резервным).
За исключением использования бит 16 ‑ 13 PDE работа механизма PSE-36 совпадает с работой механизма, показанного на рис. 3.14. Эти механизмы полностью идентичны, если при использовании PSE-36 в биты 16 ‑‑13 PDE записать нули. Страницы 4 Кбайт невозможно использовать аналогичным образом, поскольку у них нет в поле начального адреса резервных битов и, следовательно негде располагать разряды А35-32.
3.10. Механизм V86
Пусть надо выполнить на 32-разрядном МП программу, написанную для МП 8086. Это можно сделать в реальном режиме, но на практике это оказывается крайне неудобно. Представьте себе, что надо покидать Windows при запуске любого DOS-приложения. Кроме того, в реальном режиме теряются такие преимущества защищенного режима, как многозадачность и защита сегментов. Все это привело к тому, что начиная с МП 386, был введен механизм V86, как бы эмулирующий в защищенном режиме работу МП 8086.
МП, работая в режиме V86, формирует физический адрес таким же способом, что и МП 8086. Берется содержимое сегментного регистра (его видимой части), умножается на 16, к полученному числу прибавляется Аэф, в результате получается Аф (это не совсем так, здесь используется несколько иная схема с тем же конечным результатом).
При смене содержимого сегментного регистра ни к каким дескрипторным таблицам МП не обращается, а просто загружает в видимую часть сегментного регистра новое число, которое задает начальный адрес нового сегмента. В то же время режим V86 представляет собой подмножество защищенного режима и позволяет использовать многозадачность, защиту сегментов и даже включать страничный механизм.
МП переходит в режим V86, если установить в единицу флаг VM в регистре флагов (ef). Однако сделать это совсем непросто, поскольку ни одна команда на состояние этого флага не влияет. Существует всего два способа переключения в режим V86 (из обычного защищенного режима) и всего один способ выхода из этого режима в обычный защищенный режим.
Первый способ входа предполагает смену задачи. Когда из TSS входящей задачи в регистры МП загружается новая информаци, то она загружается и в регистр флагов. Если при этом в новом образе ef бит VM будет установлен, новая задача будет выполняться в режиме V86. Для переключения на новую задачу надо обратиться к ее сегменту TSS (напрямую или через шлюз) в дескрипторной таблице GDT. Это можно сделать командами jmp far или call far.
Выйти из режима V86 в обычный защищенный режим таким способом невозможно. Как уже говорилось выше, в режиме V86 МП не обращается в дескрипторные таблицы, следовательно, нельзя обратиться к TSS и сменить задачу. Единственный способ выхода из режима V86 заключается в следующем. При любом прерывании МП, как и в любом другом режиме, автоматически сохраняет содержимое регистра в стеке, а затем сбрасывает флаг VM. Таким образом, после любого прерывания автоматически оказываемся в защищенном режиме. Отметим также, что хотя МП в режиме V86 работает так же, как и МП 8086, в качестве таблицы прерывания он использует таблицу IDT!
Из сказанного выше вытекает второй способ входа в режим V86. Команда iret (возврат из прерывания) автоматически восстанавливает из стека содержимое регистра флагов, в том числе и флаг VM, при этом если VM становится равен единице,то попадаем в режим V86. Здесь надо отметить, что такой возврат в режим V86 возможен только, если команда iret выполняется на нулевом уровне привилегий.
Итак, можно сделать следующие выводы. В режиме V86 МП формирует физический адрес по схеме МП 8086. Единственным серьезным отличием от МП 8086 является использование таблицы прерываний IDT (имеется еще ряд очень мелких отличий, но здесь они не рассматриваются). Так же, как МП 8086, 32-разрядный МП в режиме V86 адресует младший мегабайт ОП, однако если использовать страничный механизм, этот мегабайт можно транслировать в любое место ОП. Более того, используя многозадачность, можно запустить сразу несколько задач V86, выделив каждой свой мегабайт памяти, и переключаться между этими задачами.
Обычно для обслуживания режима V86 в системе создается специальная программа, называемая «монитор V86». Как правило, монитор является частью обработчика прерывания типа 13 – «общая защита» (#GP). Важным является тот факт, что в режиме V86 текущий уровень привилегий задачи (CPL) всегда равен 3!
3.11. Методы обработки прерываний, возникших в режиме V86
По терминологии фирмы Intel все прерывания делятся следующмим образом:
- немаскируемые аппаратные прерывания (NMI);
- маскируемые аппаратные прерывания (hardware interrupt);
- исключения (особые случаи) (exception);
- программные прерывания (команды int n) (software interrupt).
Используемый метод зависит от желания системного программиста, от возможностей процессора и от установки некоторых флагов и полей. Рассмотрим эти флаги и поля.
Поле IOPL (input-output privilege level) – это биты 12 и 13 регистра флагов ef. Когда процессор выполняет команду, которая является чувствительной к уровню привилегий, то он проверяет условие: текущий уровень привилегий задачи (CPL) должен быть не ниже IOPL:
CPL£IOPL.
Если это условие не выполняется, то возникает исключение #GP. Помните, что в режиме V86 CPL всегда равен 3!
В защищенном режиме к чувствительным командам относятся команды ввода/вывода (in; out; ins; outs) и команды, влияющие на состояние флага разрешения прерывания if (cli; sti). В режиме V86 к чувствительным относятся только команды: cli; sti; pushf; popf; int n и iret.
Флаг VME (0-й бит регистра cr4) (virtual mode extension – расширенный V86). Этот флаг появился в Pentium.
Флаги VIF и VIP (соответственно, биты 19 и 20 в регистре флагов ef). Процессор, находясь в V86, работает с этими флагами только при VME = 1. VIF – virtual interrupt flag (виртуальное разрешение прерываний). VIP – virtual interrupt pending (виртуальный флаг отложенного прерывания). Наличие этих флагов позволяет легче контролировать работу программ 86-го процессора, выполняющихся в V86 и меняющих состояние флага IF. То есть, если IOPL<3, то программе не позволят менять IF, но, если доступен VIF, то позволят поменять VIF и при этом не будет #GP. Более подробно работа с этими флагами описана ниже.
Битовая карта перенаправления программных прерываний (Redirection bitmap). Используется только при VME = 1. Смысл здесь в следующем. Когда процессор находится в режиме V86, все прерывания (в том числе и программные по командам int n) переводят его в защищенный режим.
Чаще всего, когда обработчик защищенного режима определяет, что прерывание вызвано командой int n, возникшей в V86, то он возвращает это прерывание в V86 для его обработки стандартными средствами DOS и BIOS. На этих переключениях между режимами теряется время, поэтому, начиная с Pentium, была введена возможность (если VME = 1) сразу оставлять прерывания по некоторым командам int n для обработки в V86. Какие при этом команды сразу перенаправляются в V86, а какие идут в защищенный режим, определяют соответствующие биты битовой каты перенаправления. Каждый бит этой карты соответствует своему типу прерывания (n). Если бит = 1, то int n выводит в защищенный режим, если бит = 0, то int n обрабатывается в V86. То есть всего в этой карте 256 бит (32 байта). Располагается карта в TSS текущей задачи непосредственно перед битовой картой ввода/вывода (см. разд. 3.13). Таким образом, бит для int 0 имеет адрес:
База битовой карты ввода /вывода минус 32 байта.
Соответственно бит для int 255 имеет адрес:
База битовой карты ввода /вывода минус 1 бит.
Перейдем к методам обработки прерываний, возникающих в режиме V86. Все прерывания удобно разбить на три пересекающихся класса (т.е. одно и то же прерывание может входить сразу в несколько классов). Разбиение на классы приведено в табл.3.10.
Таблица 3.10
|
Класс 1 |
NMI |
Маскируемые аппаратные внешние прерывания |
Особые случаи |
Программные прерывания |
| Класс 2 |
Нет |
Маскируемые аппаратные внешние прерывания |
Нет |
Нет |
|
Класс 3 |
Нет |
Нет |
Нет |
Программные прерывания |
Существует три основных способа обработки Класса 1.
Первый способ заключается в следующей последовательности действий.
1. Произошло прерывание в режиме V86.
2. Процессор устанавливает TF = 0, VM = 0 и, если переход к обработчику происходит через шлюз прерываний, то IF = 0.
3. Процессор переходит к обработчику защищенного режима. Поскольку при этом уровень привилегий меняется (с 3 на 0), процессор автоматически меняет стек на более привилегированный (уровня 0).
4. Процессор автоматически запоминает в новом стеке содержимое видимых частей сегментных регистров gs, fs, ds, es.
5. Процессор очищает эти регистры (сбрасывает в ноль).
6. Процессор запоминает в новом стеке ss:esp, ef, cs:eip и код ошибки, если, конечно, этот код есть.
7. Далее начинается работа системного программиста. Обработчик проверяет флаг VM (не в регистре ef, а в образе этого регистра, лежащем в стеке!) и определяет, что прерывание произошло в V86. Далее как раз и существуют три пути.
Первый путь. Обработать все в обработчике защищенного режима (в этом обработчике мы как раз сейчас и находимся) и, выполнив iret, вернуться в V86. При этом iret проверит VM (в образе ef в стеке) и восстановит все регистры надлежащим образом.
Второй путь. Обработчик вызывает командой call монитор V86 (обычно это специальная программа, тесно связанная с обработчиком #GP). Последний обрабатывает прерывание и возвращает (по ret) прерывание обработчику. Обработчик выполняет iret и т.д.
Третий путь связан с программными прерываниями, обработка которых имеет специфику и будет рассмотрена ниже.
Класс 2. К этому классу относятся маскируемые внешние аппаратные прерывания (hardware interrupt) при VME = 1, т.е. разрешены VIF и VIP и IOPL<3. Напомним о сути проблемы. Так как в V86 CPL = 3 (a IOPL<3) , то попытка выполнения команды, изменяющей значение флага IF, приведет к #GP. Действительно, программе можно разрешить менять этот флаг только в однозадачной системе. В многозадачной же системе запрет внешних прерываний какой-либо задачей может привести к монопольному захвату системы со стороны этой задачи. С другой стороны, многие задачи, написанные для 8086 и реального режима, работают с этим флагом. Если VME = 1, то то выполнение команды cli или sti, несмотря на IOPL<3, не приводит к #GP, хотя IF при этом не изменяется, но зато изменяется VIF.
Итак пусть IF = 1, а VIF = 0 и произошло аппаратное прерывание. Оно будет воспринято (так как IF = 1). Далее осуществляется та же последовательность действий, что и для Класса 1 (см. пп. 1 ‑ 7 для Класса 1).
8. Обработчик (знает, что это аппаратное прерывание, так как он обработчик этого аппаратного прерывания) проверяет флаг VIF (в образе, взятом из стека). Если этот флаг равен единице, то далее все идет обычным образом (как в Классе 1), если же этот флаг равен нулю, обработка прерывания не производится! В последнем случае обработчик просто устанавливает в хранящемся в стеке образе ef флаг VIP = 1 (имеется отложенное прерывание) и по iret уходит назад в V86.
Когда задача V86 установит флаг VIF (командой sti), то процессор проверит флаг VIP. Если при этом он окажется в единице, то произойдет #GP и отложенное прерывание можно будет обработать по Классу 1 с единственной отличительной чертой: перед возвратом в V86 надо установить VIP = 0 (в образе ef в стеке).
Класс 3. К классу 3 относятся программные прерывания (по int n). Программные прерывания могут также относиться к Классу1. В зависимости от значений флагов и полей можно выделить шесть методов обработки программных прерываний, показанных в табл. 3.11.
Метод 1. Программное прерывание обрабатывается в рамках Класса 1.
Metoд 2. Выполнениеint n приводит к #GP. Далее см. пп. 1 ‑ 7 для Класса 1. Обработчик #GP, определив, что прерывание пришло из V86, передает управление монитору V86, который есть часть обработчика #GP.
Таблица 3.11
|
Метод |
VME |
IOPL |
Бит в карте перенаправления |
|
1 |
0 |
3 |
Безразлично |
|
2 |
0 |
<3 |
Безразлично |
|
3 |
1 |
<3 |
1 |
|
4 |
1 |
3 |
1 |
|
5 |
1 |
3 |
0 |
|
6 |
1 |
<3 |
0 |
Монитор либо сам обрабатывает прерывание, либо, что чаще, передает его обратно в V86 для обработки средствами DOS и BIOS. Для этого монитор:
- находит в таблице прерываний V86 (не вIDT!!) вектор «местного» обработчика и по нему определяет начальный адрес этого обработчика;
- переписывает f, cs и eip, пришедшие из V86, из своего стека 0-го уровня в стек V86 (3-го уровня);
- подменяет в своем стеке 0-го уровня адрес возврата на найденный адрес обработчика V86;
- выполняет iret и мы в обработчике V86;
- когда обработчик V86 выполнит команду возврата iret, произойдет #GP (так как IOPL<3), то вновь окажемся в мониторе;
- восстановит адрес возврата;
- перепишет f из стека 3 в стек 0 (эта операция связана с тем, что многие DOS-обработчики возвращают результат в регистре флагов);
- выполнит iret для возврата в V86.
Метод 3. Полностью идентичен Методу 2.
Метод 4. Идентичен Методу 1.
Метод 5. Отличается от всего изложенного выше. Здесь нет перехода в защищенный режим, так как прерывание перенаправляется в V86 (остается и обрабатывается в V86 как в 8086). Действия процессора при этом тоже отличаются:
- процессор сохраняет в стеке (уровня 3) f с NT = 0 и IOPL = 0;
- процессор сохраняет в стеке cs иip;
- процессор устанавливает в f флагиTF = 0 иIF = 0;
- процессор берет вектор из таблицы V86 (не IDT) и переходит на обработчик, далее стандарт для 8086.
Метод 5 совпадает с обработкой прерываний в Реальном режиме.
Метод 6. Незначительно отличается от Метода 5 действиями процессора:
- сохраняет f сIOPL = 3 иIF = VIF;
- сохраняет cs иip;
- устанавливает VIF = TF = 0;
- переходит на обработчик.
При возврате по команде iret из Методов 5 и 6 процессор понимает, что он в режиме V86 по VM = 1. Сами Методы 5 и 6 он при этом не различает, но возврат получается правильным, поскольку флаги VIF, VIP, IOPL, VM при этом возврате не модифицируются.
3.12. Механизм переключения задач. Формат сегмента TSS
Как отмечалось ранее, размер сегмента TSS должен быть не менее 104 байт. При обращении к дескриптору TSS МП проверяет записанный в дескрипторе размер, и если он меньше 104 байт, то генерируется прерывание. Однако сегмент TSS может иметь больший размер.
В этой дополнительной области сегмента TSS может, например, располагаться битовая карта ввода-вывода ‑ input-output map (см. ниже). Эту дополнительную область может использовать в своих целях системный программист. Например, в этой области системный программист может сохранять содержимое регистров арифметического сопроцессора. Переключая задачи, МП, для экономии времени, не сохраняет контекст сопроцессора. Если задача А переключилась на задачу В и обе они работают с сопроцессором, то очевидно, что задача В (если не принять мер) испортит контекст задачи А. Поэтому, переключаясь на новую задачу, МП автоматически устанавливает бит TS (задача переключена) в регистре CR0. При выполнении любой команды сопроцессора МП проверяет бит TS, и, если он установлен, то будет прерывание. Обработчик этого прерывания должен сохранить контекст сопроцессора, сбросить бит TS и обеспечить рестарт команды.
Далее рассмотрим формат сегмента TSS (рис. 3.19).
Дадим необходимые пояснения к рис. 3.19. Формат рисунка ‑ 4 байта по горизонтали. Слева от полей приведено смещение (0h, 4h и.т.д) относительно начала сегмента TSS. Назначение таких полей как EIP ‑ EDI и ES ‑ GS очевидно и их рассматривать не будем. Остальные поля либо неочевидны, либо имеют свою специфику.
Поле «обратной связи» (previous task link). Пусть задача А вызвала задачу В в качестве подпрограммы (командой call far). Естественно предполагать, что когда-нибудь потребуется возврат в задачу А. Чтобы куда-нибудь вернуться, нам потребуется адрес возврата. Адресом возврата будет селектор дескриптора сегмента TSS задачи А.
Однако задачи А и В ничем между собой не связаны и в общем случае задаче В этот селектор неизвестен. Поэтому, когда задача А вызывает задачу В командой call far, то МП автоматически загружает в поле обратной связи задачи В (входящей задачи) селектор дескриптора TSS задачи А.
|
31 16 |
15 0 |
|||
|
0h |
Поле обратной связи |
|||
|
4h |
esp0 |
|||
|
8h |
ss0 | |||
|
0ch |
esp1 |
|||
|
10h |
ss1 |
|||
|
14h |
esp2 |
|||
|
18h |
ss2 |
|||
|
1ch |
cr3 |
|||
|
20h |
Eip |
|||
|
24h |
Ef |
|||
|
28h |
eax |
|||
|
2ch |
ecx |
|||
|
30h |
edx |
|||
|
34h |
ebx |
|||
|
38h |
esp |
|||
|
3ch |
ebp |
|||
|
40h |
esi |
|||
|
44h |
edi |
|||
|
48h |
es |
|||
|
4ch |
cs |
|||
|
50h |
ss |
|||
|
54h |
ds |
|||
|
58h |
fs |
|||
|
5ch |
gs |
|||
|
60h |
ldtr |
|||
|
64h |
База битовой карты ввода-вывода |
T |
||
Рис. 3.19
Этот селектор МП берет из видимой части регистра tr. Тем самым обеспечивается возможность возврата в задачу А. Если переключение задач идет по команде jmp far, поле обратной связи входящей задачи заполняется нулями, так как возврат куда-либо не предполагается.
CR3. Наличие этого поля показывает что при переключении задач меняется содержимое регистра cr3, а следовательно, происходит переход к новому каталогу таблиц (если конечно, страничный механизм включен).
LDTR. Из поля LDTR TSS входящей задачи загружается видимая часть регистра ldtr. Происходит переключение на новую таблицу LDT. Старое содержимое видимой части регистра ldtr в поле LDTR TSS выходящей задачи не сохраняется (для экономии времени), поскольку подразумевается, что задача работает с одной и той же LDT.
Бит Т (trap – ловушка). Если в TSS задачи В этот бит установлен в единицу, то при переключении на задачу В будет прерывание типа 1. Этот бит используется для отладки.
SSi ‑ ESPi. Каждая пара такого вида задает вершину стека для одного из уровней привилегий. Всего в TSS задаются три такие пары для уровней привилегий 2, 1 и 0. Для 3-го уровня привилегий вершина стека в TSS не задается. Содержимое этих полей при переключении задач не меняется. Эти поля используются не в процессе переключения задач, а в процессе выполнения задач. Существует правило, согласно которому уровень привилегий текущего сегмента стека (DPL стека) должен быть всегда равен CPL. Пусть мы работаем на уровне привилегий i (CPL = i). Пусть затем через шлюз вызова вызвали подпрограмму с более высоким уровнем привилегий (теперь CPL<i). Согласно рассмотренному правилу, мы обязаны сменить стек (на более привилегированный). В этом случае МП и возьмет вершину стека соответствующего уровня из TSS текущей задачи и автоматически сохранит вершину старого стека в новом стеке, чтобы ее можно было восстановить при возврате из подпрограммы. Поскольку никаким способом мы не можем перейти к менее привилегированной программе, то на 3-й уровень можем попасть только с 3-го уровня. Именно поэтому в TSS отсутствуют поля SS3:ESP3.
Поле битовой карты ввода-вывода задает смещение этой карты (если она есть) относительно начала TSS.
Процессор может работать с сегментами TSS микропроцессора i286. Формат сегмента отличается от рассмотренного хотя бы потому, что регистры МП 286 16-разрядные. TSS МП 286 содержит следующую последовательность полей (полей, заполненных нулями в нем нет и по объему он меньше рассмотренного TSS): поле обратной связи, sp0, ss0, sp1, ss1, sp2, ss2, ip, f, ax, ..., ds, ldtr.
3.13. Битовая карта ввода-вывода
В регистре флагов (ef) имеется двухбитовое поле IOPL, задающее уровень привилегий, на котором задаче разрешены операции ввода/вывода. Например, если CPL = 3, а в поле IOPL задана двойка при попытке выполнить команду in (out или аналогичные), то будет прерывание. Связано это с тем, что операции ввода/вывода ‑ «опасные» операции и могут вывести систему из строя. Система принимает меры защиты. Скорее всего команда in все же будет выполнена, но не напрямую. Обработчик прерывания запросит ОС и она, если это допустимо, выполнит команду корректно. Сменить содержимое поля IOPL можно, только находясь на 0-м уровне привилегий.
Такое ограничение на операции ввода/вывода зачастую оказывается излишне жестким. Например, имеет смысл ограничить доступ пользователя к 0-му каналу таймера (порт 40h), на работе которого базируется служба системного времени. Однако нет никакого смысла ограничивать доступ ко 2-му каналу таймера (порт 42h), заведующему генерацией звука. Для решения этой проблемы в TSS может быть создана битовая карта ввода/вывода.
Карта содержит в себе столько бит, сколько в системе портов. Каждый бит карты соответствует одному восьмиразрядному порту. Максимально в карте может быть 64 Кбита. Если в i-м бите записан 0, то доступ к i-му порту разрешен всегда (IOPL игнорируется), если же там записана единица, то доступ к порту будет предоставлен только если не нарушаются права, заданные полем IOPL.
Процессор может работать не только с восьмиразрядными но и 16- и 32-разрядными портами. 16-разрядному порту в карте ставятся в соответствие два смежных бита, начинающихся с четного номера. Аналогично 32-разрядному порту соответствуют четыре смежных бита, начинающихся с номера, кратного четырем.
Пример карты показан на рис. 3.20. Из примера видно, что в системе доступны 8-разрядные порты с адресами 1h, 2h, 3h, 4h и 6h, а также один 16-разрядный порт с адресом 2h. Остальные порты защищены полем IOPL.
В режиме V86 условие CPL£IOPL при выполнении команд in и out не проверяется и доступ к портам определяется битом в битовой карте ввода-вывода, т.е. последняя для задач V86 создается обязательно. Кроме того, в TSS задачи V86 непосредственно перед битовой картой ввода-вывода может располагаться битовая карта перенаправления прерываний.
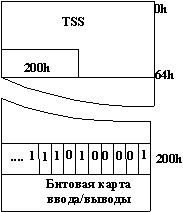
Рис. 3.20
3.14. Действия процессора при переключении задач
Введем понятие занятой задачи. Задача называется занятой, если она в данный момент выполняется. Если одна задача вызвала другую задачу в качестве подпрограммы, то обе задачи будут занятыми. При обращении к занятой задаче генерируется прерывание. То есть задача не может переключиться сама на себя. В дескрипторе TSS в четырехбитовом поле TYPE есть бит В (формат поля TYPE для дескриптора TSS ‑ x x B x). Если этот бит установлен в единицу, то задача является занятой. С этим битом работает сам МП. Он этот бит и устанавливает и сбрасывает.
Для того чтобы переключиться на новую задачу, надо обратиться к дескриптору TSS этой задачи. Это можно сделать следующими четырьмя способами.
1. Команда jmp far или call far адресует дескриптор TSS в таблице GDT. В любой из этих команд присутствует селектор и смещение (например, jmp 0010:00222222h – здесь 0010 – селектор, 00222222 – смещение). Если при этом селектор адресует дескриптор TSS, то смещение, заданное в команде, игнорируется.
2. Те же команды адресуют шлюз задачи. Селектор, заданный в команде, адресует при этом шлюз задачи в GDT или LDT, а смещение, как и ранее, игнорируется. Селектор дескриптора TSS берется из шлюза.
3. Прерывание через шлюз задачи. В принципе, подобен второму варианту.
4. Переключение задачи происходит при выполнении команды iret, если флаг NT (флаг вложенной задачи) в регистре флагов ef установлен в единицу (это возврат из вложенной задачи). Селектор дескриптора TSS входящей задачи при этом берется из поля обратной связи TSS текущей (выходящей) задачи.
Приведем несколько упрощенную последовательность действий процессора при переключении задач.
1. По известному селектору (взятому из команды, или из шлюза, или из поля обратной связи) процессор находит дескриптор TSS в таблице GDT.
2. Процессор производит ряд проверок:
- проверяет права доступа;
- проверяет размер TSS;
- проверяет входящую задачу на занятость, при этом входящая задача должна быть занята, если переключение инициировано командой iret, и свободна во всех остальных случаях.
- проверяет, присутствуют ли структуры, необходимые при переключении задач (TSS входящей и TSS выходящей задач), в ОП.
3. Если переключение инициировано командой call или прерыванием, то в поле обратной связи записывается селектор дескриптора TSS выходящей задачи (адрес возврата), который процессор берет из видимой части регистра tr.
4. В TSS выходящей задачи процессор копирует содержимое своих внутренних регистров.
5. Выходящая задача помечается как свободная, если переключение инициировано командой jmp или iret, если же переключение инициировано командой call или прерыванием, выходящая задача остается занятой. До этого момента любое прерывание воспринимается в контексте выходящей задачи, начиная со следующего пункта прерывания воспринимаются уже в контексте новой задачи.
6. Из TSS входящей задачи в регистры процессора загружается новая информация (контекст входящей задачи).
7. Входящая задача помечается занятой.
8. Если переключение инициировано командой call или прерыванием, то флаг NT в регистре флагов устанавливается в единицу.
9. Бит TS (задача переключена) в регистре cr0 устанавливается в единицу. Напомним, что этот бит связан с математическим сопроцессором (см. разд. 3.12).
3.15. Формат дескриптора
Все создаваемые в системе дескрипторы можно разделить на системные и несистемные. К системным относятся шлюзы, дескрипторы TSS и дескрипторы LDT. К несистемным относятся дескрипторы сегментов кода, данных и стеков. Как системные, так и не системные дескрипторы занимают в памяти 8 байт и имеют примерно одинаковый формат (рис. 3.21).
|
7 0 |
|||||
|
0h |
Limit 7-0 |
||||
|
1h |
Limit 15-8 |
||||
|
2h |
Base 7-0 |
||||
|
3h |
Base 15-8 |
||||
|
4h |
Base 23-16 |
||||
|
5h |
P |
DPL |
S |
TYPE |
|
|
6h |
G |
D |
0 |
U |
Limit 19-16 |
|
7h |
Base 31-24 |
||||
Рис. 3.21
Поле BASE задает 32-разрядный начальный адрес сегмента.
Поле LIMIT задает размер сегмента. Этот размер может измеряться в байтах или страницах. Если размер сегмента задается в байтах, размер сегмента может меняться от 1 байта до 1 Мбайта. Если размер задается в страницах, он может меняться от 4 Кбайт до 4 Гбайт (от одной страницы до 220 страниц). Если размер сегмента стека задается в байтах, то этот размер лежит в более ограниченных пределах: от 1 байта до 64 Кбайт. Размеры сегментов TSS и таблиц LDT задаются только в байтах.
Бит гранулярности G (granularity) задает единицы измерения размера сегмента. Если G = 0, то размер измеряется в байтах, при G = 1 ‑ в страницах.
Бит P (present) ‑ бит «присутствия». Если Р = 1, то сегмент присутствует в ОП, а при Р = 0 ‑ отсутствует, т.е. находится на диске. При Р = 0 поля BASE и LIMIT не имеют вышеописанного смысла.
Бит U (user) ‑ бит «пользователя». МП с этим битом не работает, и системный программист может его использовать для набора статистических сведений о сегментах.
Бит D (default operation size) ‑бит «размерности». Это более сложный для описания бит. Возьмем для примера 3 команды: mov al, bl ; mov ax , bx и mov eax , ebx. Первая из этих команд имеет код операции (КОП) 88h, а вот у двух последующих команд КОП одинаковый, он равен 89h. По коду операции возможно отличить 8-разрядные команды от не 8-разрядных, а вот 16-разрядные команды от 32-разрядных по КОП отличить невозможно (речь идет об «аналогичных» командах).
Для того чтобы МП мог отличить эти команды друг от друга? перед одной из них транслятор поставит «префикс размера операнда» (66h). Перед какой из двух этих команд транслятор поставит префикс, зависит от того, как пользователь описал свою программу. У него для этого есть ассемблерные директивы use16 и use32. МП проинтерпретирует эти команды в зависимости от бита D, который он возьмет в теневой части регистра cs. При D = 0 МП интерпретирует код 89h как команду mov ax, bx, а код 66h 89h ‑ как команду mov eax, ebx. При D = 1 интерпретация таких кодов будет прямо противоположной.
Кроме префикса размера операнда есть еще «префикс размера адреса» (67h). Его тоже ставит транслятор, например, перед одной из двух команд: mov al, [bx+2] и mov al, [ebx+2]. Интерпретация таких команд процессором аналогичным образом зависит от значения бита D в регистре cs. Отметим, что перед командой могут стоять оба префикса одновременно. Эта несколько запутанная ситуация с префиксами и битом D связана с желанием уменьшить расход памяти и повысить быстродействие МП. Если было бы однозначно задано, что префиксы, допустим, ставятся перед всеми 32-разрядными командами, а все 16-разрядные команды идут без префиксов, казалось, было бы проще.
Однако если большинство команд программы 32-разрядные, такая программа будет в этом случае (за счет префиксов) занимать значительно больше памяти и медленнее выполняться. Бит D предоставляет возможность как бы сообщать МП, каких команд в программе будет меньше ‑ 16- или 32-разрядных. Перед теми, которых меньше, и будут стоять префиксы. Как уже отмечалось в основном для интерпретации префиксов привлекается бит D из регистра cs. Биты D в регистрах ds, es, fs и gs по-видимому ни на что не влияют. Бит D в регистре ss определяет размер указателя стека (D = 0 ‑sp, D = 1 ‑ esp).
В дескрипторах, копируемых в сегментный регистр стека ss, биты D и G должны быть согласованы (равны между собой), кроме того бит D в подобных дескрипторах принято называть битом В (big – бит большого сегмента). Отметим также, что в дескрипторах «системных» сегментов биты D и G смысла не имеют.
Бит S (system) ‑ бит «системного сегмента». При S = 0 дескриптор описывает системный сегмент. В зависимости от значения бита S процессор интерпретирует поле TYPE. При S = 1 (не системный сегмент) поле TYPE может иметь один из двух форматов. Первый формат приведен на рис. 3.22.
|
1 |
C |
R |
A |
Рис. 3.22
Здесь единица в старшем разряде поля TYPE означает, что это сегмент кода. Бит А (accessed) ‑ бит обращения. МП устанавливает этот бит при обращении к сегменту. Сбрасывать этот бит процессор сам не умеет, это делает системный программист. Бит R (read enable) ‑ бит разрешения считывания. При R = 0 запрещается считывание информации из этого сегмента (программу можно выполнять, но нельзя копировать). Бит C (conforming) ‑ бит «согласованного» сегмента. Понятие согласованного сегмента кода было введено раньше (см. разд. 3.2). Второй формат поля TYPE при S = 1 приведен на рис. 3.23.
|
0 |
E |
W |
A |
Рис. 3.23
Здесь 0 в старшем разряде говорит о том, что это сегмент данных. Бит A ‑ бит обращения, такой же, как и для сегментов кода. Бит W (write enable) ‑ бит разрешения записи. При W = 0 сегмент запрещен для записи. Бит Е (expansion direction – направление расширения) – позволяет различать сегменты данных и сегменты стека (Е = 0 ‑ это сегмент данных). Вернее, бит Е влияет на то, как МП интерпретирует поле LIMIT. Продемонстрируем это с помощью рис. 3.24.
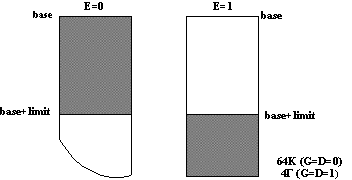
Рис. 3.24
Как видно из рис. 3.24, при Е = 0 МП считает, что сегмент располагается в границах base ‑ base+limit, и если Аэф>base+limit, то выходим за заданные границы сегмента. При Е = 1 сегмент для МП располагается в границах base+limit – 64 Kбайта (4 Гбайта) и выход за границы сегмента будет при Аэф<base+limit. Связано это с тем, что, если не хватает заданного размера сегмента, то сегменты данных удобней расширять в сторону старших адресов ОП (вверх), а сегменты стека, поскольку стек растет в сторону младших адресов, ‑ вниз. Отметим, что в сегментный регистр стека ss можно загружать дескрипторы сегментов и с Е = 0, и с Е = 1. Но при этом сегмент стека должен быть в любом случае разрешен для записи (W = 1) и биты G и D должны быть согласованы. Например, хотим организовать стек в области ОП от второго до третьего Мбайта. Можно пойти двумя путями.
1. Задаем Е = 0, G = D = 1, base задаем 2 Мбайта, limit – 1 Мбайт и указатель стека (esp) устанавливаем на 1 Мбайт.
2. Задаем Е = 1, G = D = 1, base задаем равным нулю (можно и не нулю, но обязательно меньше или равно 2 Мбайта), limit – 2 Мбайта (если base равен нулю) и esp указывает на 3 Мбайта (если base взяли равным нулю). При этом esp «обрезает» сегмент со стороны старших адресов ОП.
В заключение этого раздела приведем форматы поля TYPE для системных сегментов (S = 0):
- 0000 ‑ запрещенная комбинация;
- 0001 ‑ свободный TSS МП 286;
- 0010 ‑ таблица LDT;
- 0011 ‑ занятый TSS МП 286;
- 0100 ‑ шлюз вызова МП 286;
- 0101 ‑ шлюз задачи (одинаков для МП 286 и для 32-разрядных процессоров);
- 0110 ‑ шлюз прерывания МП 286;
- 0111 ‑ шлюз ловушки МП 286;
- 1000 ‑ запрещенная комбинация;
- 1001 ‑ свободный TSS 32-разрядного процессора;
- 1010 ‑ зарезервировано фирмой;
- 1011 ‑ занятый TSS 32-разрядного процессора;
- 1100 ‑ шлюз вызова 32-разрядного процессора;
- 1101 ‑ зарезервировано фирмой;
- 1110 ‑ шлюз прерываний 32-разрядного процессора;
- 1111 ‑ шлюз ловушки 32-разрядного процессора.
3.16. Форматы шлюзов
Шлюзы, их назначение и использование были подробно рассмотрены ранее в разд. 3.1. Ограничимся рассмотрением их форматов. Напомним, что через шлюзы можно обратиться к «исполняемым» сегментам и нельзя обратиться к сегментам данных.
Шлюз вызова имеет формат, приведенный на рис. 3.25.
|
7 0 |
||||
|
0h |
Смещение 7-0 |
|||
|
1h |
Смещение 15-8 |
|||
|
2h |
Селектор 7-0 |
|||
|
3h |
Селектор 15-8 |
|||
|
4h |
0 0 0 |
PC | ||
|
5h |
P |
DPL |
0 |
1 1 0 0 |
|
6h |
Смещение 23-16 |
|||
|
7h |
Смещение 31-24 |
|||
Рис. 3.25
Поле селектор адресует дескриптор, на который ссылается шлюз. Поле смещение задает достоверную точку входа в привилегированную подпрограмму. Бит Р аналогичен такому же биту в дескрипторах, но называется он не битом «присутствия» (здесь нечему присутствовать !), а битом «достоверности шлюза». Поле DPL задает уровень привилегий шлюза. Назначение поляPC (parameter counter – счетчик параметров) рассмотрим позже. В поле TYPE для шлюза вызова должно быть задано 1100 (шлюзы МП 286 не рассматриваем, существенно они не отличаются).
Шлюз вызова может располагаться в GDT или в LDT. Обращаться к нему можно командами jmp far и call far. Обращение к такому шлюзу командой jmp far особого смысла не имеет, так как по этой команде через шлюз вызова не разрешен переход на более высокий уровень привилегий. Поэтому для обращения к шлюзу вызова обычно используют команду call far и, следовательно, шлюз вызова предназначен для вызова привилегированных подпрограмм. Если через шлюз вызова перешли на более высокий уровень привилегий, то, согласно правилу, должны сменить и стек на более привилегированный.
Вершину нового стека МП автоматически извлечет из поля сегмента TSS текущей задачи. В новый стек МП загружает адрес возврата и вершину старого стека. Также в подпрограмму надо передавать ряд параметров. Шлюз вызова позволяет организовать передачу параметров в подпрограмму. Параметры заранее записывают в старый стек, а в поле PC задают количество передаваемых параметров. При переходе через шлюз вызова МП перекачает заданное число параметров из старого стека в новый. Так как размер поля PC ‑ 5 бит, а любой параметр представляет собой слово или двойное слово (для шлюзов вызова 16- и 32-разрядных приложений), то максимально можно передать 31 двойное слово (или 31 слово). Возврат из привилегированной подпрограммы осуществляется как обычно командой retf.
Шлюз задачи приведен на рис. 3.26.
|
7 0 |
||||
|
0h |
Не используется | |||
|
1h |
Не используется | |||
|
2h |
Селектор 7-0 |
|||
|
3h |
Селектор 15-8 |
|||
|
4h |
Не используется | |||
|
5h |
P |
DPL |
0 |
0 1 0 1 |
|
6h |
Не используется | |||
|
7h |
Не используется | |||
Рис. 3.26
Поля «смещение» нет, поскольку в задаче нет точки входа. Нет поля РC, поскольку задачи изолированы друг от друга и параметры между ними не передаются. В поле TYPE должно быть записано 0101. Шлюз задачи может располагаться в GDT, LDT и IDT. К нему можно обратиться командами jmp far, call far (в GDT или LDT) или int n (в IDT).
Шлюз прерывания и Шлюз ловушки приведены на рис. 3.27.
|
7 0 |
||||
|
0h |
Смещение 7-0 |
|||
|
1h |
Смещение 15-8 |
|||
|
2h |
Селектор 7-0 |
|||
|
3h |
Селектор 15-8 |
|||
|
4h |
Не используется | |||
|
5h |
P |
DPL |
0 |
1 1 1 0/1 |
|
6h |
Смещение 23-16 |
|||
|
7h |
Смещение 31-24 |
|||
Рис. 3.27
Поле «смещение» задает достоверную точку входа в обработчик прерывания. В поле TYPE должно стоять 1110 для шлюза прерывания и 1111 для шлюза ловушки. Никакие параметры в обработчик не передаются. Эти шлюзы могут располагаться только в IDT и служат для вызова обработчиков прерываний. Шлюз ловушки предназначен для внутренних прерываний (особых случаев), а шлюз прерываний ‑ для внешних прерываний. Разница между этими шлюзами в одном: при переходе через шлюз прерываний МП сбрасывает флаг разрешения внешних прерываний (IF), а при переходе через шлюз ловушки он этого не делает.
3.17. Программная модель 32-разрядного МП
Под программной моделью будем понимать набор внутренних регистров МП, программным образом доступных программисту. В данном подразделе речь пойдет о регистрах, с которыми работает рядовой пользователь. Кроме этих регистров в МП есть еще системные регистры, которые рассмотрим позже.
Программная модель 32-разрядного процессора, с точки зрения пользователя, практически не отличается от программной модели МП 8086. Единственное существенное отличие состоит в том, что регистры МП 386 и выше ‑ 32-разрядные (в МП 8086 регистры 16-разрядные). Кроме того, в регистр флагов (ef ) добавлен ряд новых флагов. Подробно формат регистра ef будет рассмотрен в конце этого подраздела. Поскольку программная модель МП 8086 рассмотрена ранее, то здесь ограничимся рисунком программной модели 32-разрядного процессора (рис. 3.28) без какого-либо ее описания.
Пользователь должен знать, что ему доступны не все команды. Некоторые команды в защищенном режиме выполняются только на 0-м уровне привилегий. Такие команды называются привилегированными. К ним относятся: lldt; lgdt; lidt; ltr; clts; mov cr, r; mov r , cr; mov dr, r; mov r, dr; mov tr, r; mov r, tr (и ряд других).
|
31 16 |
15 8 |
7 0 | |||
|
eax |
ah |
al |
ax |
||
|
ecx |
ch |
cl |
cx |
||
|
edx |
dh |
dl |
dx |
||
|
ebx |
bh |
bl |
bx |
||
|
esp |
sp |
||||
|
ebp |
bp |
||||
|
esi |
si |
||||
|
edi |
di |
||||
|
ef |
f |
||||
|
eip |
ip |
||||
|
Видимые части à{ |
es |
||||
|
cs |
|||||
|
ss |
|||||
|
ds |
|||||
|
fs |
|||||
|
gs |
|||||
Рис. 3.28
Кроме того, некоторые команды выполняются только если CPL£IOPL. Такие команды называются чувствительными к уровню привилегий. К ним (в защищенном режиме) относятся команды in; out; ins; outs; cli; sti.
На рис. 3.29 приводится форма регистра флагов ef.
|
10 |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
|
df |
if |
tf |
sf |
zf |
- |
af |
- |
pf |
- |
cf |
|
|
21 |
20 |
19 |
18 |
17 |
16 |
15 |
14 |
13 |
12 |
11 |
|
|
if |
vip |
vif |
ac |
vm |
rf |
- |
nt |
iopl |
of |
||
|
31 |
22 |
||||||||||
|
Резерв |
|||||||||||
Рис. 3.29
Большинство флагов хорошо известны еще из МП 8086. Часть флагов была описано ранее. Осталось всего три еще не упоминавшихся флага: RF, AC и ID. Эти три флага далее рассмотрим подробно, а остальные просто перечислим:
- CF ‑ флаг переноса (разд. 2.6);
- PF ‑ флаг четности (разд. 2.6);
- AF ‑ флаг межтетрадного переноса (разд. 2.6);
- ZF ‑ флаг нулевого результата (раздел 2.6);
- SF ‑ флаг отрицательного результата (флаг знака) (разд. 2.6);
- TF ‑ флаг трассировки (флаг «пошагового» выполнения программы) (разд. 2.6);
- IF ‑ флаг разрешения внешних прерываний (разд. 2.2);
- DF ‑ флаг направления. Задает автоинкремент или автодекремент регистров в «строковых» командах (разд. 2.6);
- OF ‑ флаг переполнения разрядной сетки (разд. 2.5);
- IOPL (input-output privilege level fild) ‑ это не флаг, а двух битовое поле, задающее уровень привилегий операций ввода-вывода (разд. 3.11);
- NT (nested task) ‑ флаг вложенной задачи ( проверяется командой iret ) (разд. 3.14);
- VM (virtual mode) ‑ режим V86 (разд. 3.10).
RF (resume) ‑ флаг рестарта (возврата). Внутри МП есть системные регистры отладки DRi . В этих регистрах можем задавать «контрольные точки останова». Когда МП вырабатывает адрес, совпадающий с такой точкой, происходит прерывание типа 1. Обработчик этого прерывания выводит на экран содержимое внутренних регистров МП.
При возврате из обработчика происходит рестарт команды (только если контрольная точка задана «по команде», см. описание регистров dr в разд. 3.18). Однако при этом МП снова выработает тот же адрес и, так как «контрольная точка» не изменилась, снова будет то же самое прерывание. Во избежание подобной ситуации обработчик прерывания по контрольной точке должен либо сменить адрес контрольной точки в регистре dr, либо установить RF в единицу. При RF = 1 прерывание при рестарте будет заблокировано. После выполнения «виноватой» команды МП сбрасывает RF в ноль.
AC (alignment check) ‑ флаг выравнивания. Если этот флаг установлен, то МП генерирует прерывание типа 17 при обращении к не выровненным в памяти данным (например, при обращении к слову по нечетному адресу). Это прерывание генерируется, если кроме установки флага АС выполняются еще два условия: текущий CPL = 3 и бит АМ в регистре cr0 установлены в единицу. Этот флаг появился в МП 486.
VIF (virtual interrupt) – виртуальный флаг прерываний (разд. 3.11).
VIP (virtual interrupt pending) – виртуальный флаг отложенного прерывания (разд. 3.11).
ID (identification) – если программа может изменять значение этого флага, значит процессор поддерживает команду cpuid. Эта команда возвращает сведения о процессоре.
3.18. Регистры системного программиста
Форматы и назначение системных регистров gdtr, idtr, ldtr иtr были рассмотрены ранее в разд. 3.4, поэтому в данном разделе они не приводятся. Кроме них к системным регистрам относятся регистры управления, регистры отладки и регистры, специфичные для модели.
Регистры управления. К ним относятся регистры cr0, cr2, cr3 и cr4. Регистр cr1 зарезервирован фирмой и системному программисту не доступен. Регистр cr0 имеет формат, приведенный на рис. 3.30.
|
31 |
30 |
29 |
18 |
16 |
5 |
4 |
3 |
2 |
1 |
0 |
|||
|
pg |
cd |
nw |
.. |
am |
.. |
wp |
.. |
Ne |
et |
ts |
em |
mp |
pe |
Рис. 3.30
Бит PE (protection enable) ‑ бит защищенного режима. При РЕ = 1 процессор находится в защищенном режиме.
Бит PG (paging) ‑ бит страничного механизма. При PG = 1 включен страничный механизм.
Биты CD (cache disable)и NW (not write-through) управляют работой внутренней кэш-памяти. При CD = 0 разрешена внутренняя кэш-память. При NW = 0 разрешена сквозная запись (понятие сквозной и обратной записи рассматриваются ниже). Комбинация CD = 0, NW = 1 является запрещенной. Несколько упрощенно можно считать что, при CD = 0, NW = 0 внутренняя кэш-память разрешена, а при CD = 1, NW = 1 внутренняя кэш-память запрещена. Несмотря на то, что в последнем случае внутренняя кэш-память запрещена, МП продолжает «видеть» все достоверные строки кэш-памяти. Таким образом, запрещение внутренней кэш-памяти приводит к тому, что прекращается обмен данными между кэш-памятью и ОП, однако обмен данными между кэш-памятью и МП продолжается. Это дает возможность использовать внутреннюю кэш-память как быстродействующее СОЗУ. Для того чтобы действительно полностью отключить внутреннюю кэш-память, надо ее запретить и объявить все ее строки недостоверными (можно сделать командой invd ).
Бит АМ (alignment mask) ‑ бит контроля выравнивания. При АМ = 0 процессор игнорирует флаг АС в регистре флагов. При АМ = 1 флаг АС проверяется, если работаем на 3-м уровне привилегий. Если АС = 1 и идет обращение к не выровненным данным, то происходит прерывание типа 17.
Бит WP (write protect) ‑ бит защиты страницы от записи. В элементах PTE и PDE (см. страничный механизм ) есть бит R/W. Если этот бит = 0, то страница запрещена для записи, но только на уровне пользователя (3-й уровень привилегий). Бит WP позволяет распространить этот запрет и на уровень супервизора. То есть, если WP = 1 и R/W = 0, то запись в страницу запрещена на любом уровне привилегий.
Отметим, что биты CD, NW AM и WP ( а также еще не рассмотренный нами бит NE) в МП 386 отсутствовали.
Все оставшиеся значащие биты регистра CR0 так или иначе связаны с арифметическим сопроцессором, который, начиная с МП 486, встроен внутрь микросхемы и всегда присутствует ( в отличие от МП 386).
Бит МР (monitoring coprocessor) ‑ бит присутствия сопроцессора. Оказывает влияние на восприятие процессором команды wait.
Бит ЕМ (emulation) = 1 ‑ сопроцессор эмулируется. В этом случае любая команда сопроцессора вызывает прерывание типа 7.
Бит TS = 1 ‑ задача переключена. Как уже говорилось раньше, МП автоматически устанавливает этот бит при переключении задач. Если этот бит установлен, то любая команда сопроцессора вызывает прерывание типа 7. Сбросить этот бит в 0 можно командой clts, но она доступна только на нулевом уровне привилегий. В табл. 3.12 показано влияние различных комбинаций TS, EM и MP на восприятие команд сопроцессора, ММХ – команд и команды wait. Здесь #NM – прерывание типа 7 (сопроцессор отсутствует), #UD – прерывание типа 6 (недействительный код операции). Рекомендуемая комбинация: ЕМ = 0, МР = 1.
Таблица 3.12
|
EM |
MP |
TS |
Flo.Point |
WAIT |
MMX |
|
0 |
0 |
0 |
Вып. |
Вып. |
Выполняются |
|
0 |
0 |
1 |
# NM |
Вып. |
#NM |
|
0 |
1 |
0 |
Вып. |
Вып. |
Выполняются |
|
0 |
1 |
1 |
# NM |
# NM |
# NM |
|
1 |
0 |
0 |
# NM |
Вып. |
#UD |
|
1 |
0 |
1 |
# NM |
Вып. |
#UD |
|
1 |
1 |
0 |
# NM |
Вып. |
#UD |
|
1 |
1 |
1 |
# NM |
# NM |
#UD |
Бит ЕТ (extension type) ‑ задает тип сопроцессора. При ЕТ = 0 это 287-й сопроцессор, при ЕТ = 1 ‑ 387-й. Этот бит имел значение только для МП 386 и тех моделей МП 486, в которых отсутствовал встроенный сопроцессор. Начиная с Pentium, этот бит зарезервирован.
Бит NE (numeric error) задает способ реакции на ошибку сопроцессора. При NE = 1 ошибка сопроцессора вызывает прерывание типа 16. При NE = 0 процессор либо игнорирует ошибку сопроцессора (если на его вход IGNNE заведена 1), либо зависает и ждет внешнего прерывания от контроллера прерываний (на вход IGNNE подан 0). Последний вариант (с зависанием) предназначен для эмуляции работы сопроцессора «под руководством» МП 386 – так называемый РС-стиль.
Регистр cr2 используется при включенном страничном механизме. Прерывание типа 14 называется страничным нарушением или отказом страницы. Это прерывание возникает когда страницы нет в ОП, нарушены права доступа к странице и т.д. При возникновении этого прерывания МП автоматически запоминает в регистре cr2 линейный адрес, который привел к отказу страницы. В дальнейшем этот адрес для своих целей может использовать обработчик этого прерывания. Системный программист может только считывать содержимое регистра cr2. Запись в этот регистр запрещена.
Регистр cr3. Старшие 20 разрядов этого регистра содержат 20 старших разрядов начального адреса каталога таблиц (см. страничный механизм). В Р6, если разрешено расширение физического адреса (РАЕ = 1) в cr3, находится начальный адрес таблицы указателей на каталог (27 старших разрядов этого адреса). Помимо этого в данном регистре есть еще два значащих бита: PCD и PWT (в разрядах 4 и 3). Эти биты аналогичны одноименным битам в элементах PTE и PDE и определяют стратегию кэширования для каталога или таблицы указателей. При PCD = 1 кэширование запрещено. При PWT = 1 разрешена сквозная запись.
Регистр cr4 появился в Pentium. Его формат представлен на рис. 3.31.
|
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
mce |
pae |
pse |
de |
tsd |
pvi |
vme |
| 31 |
11 |
10 |
9 |
8 |
7 |
|
|
Резерв |
osxmmexcpt |
osfxsr |
pce |
pge |
||
Рис. 3.31
VME (virtual 8086 mode extension) – расширение режима V86. При VME = 1 в режиме V86 появляются некоторые дополнительные возможности. В частности, разрешается использовать битовую карту перенаправления программных прерываний и виртуальные флаги VIF и VIP.
PVI (protected mode virtual interrupts) – виртуальные прерывания в защищенном режиме. При PVI = 1 разрешено использовать флаги VIF и VIP в защищенном режиме.
TSD (time stamp disable) – запрещение «срезов времени». В процессоре может быть счетчик TSC (time stamp counter), его содержимое можно прочитать командой RDTSC. При TSD = 0 эта команда доступна на любом уровне привилегий, при TSD = 1 ‑ только на нулевом уровне привилегий.
DE (debugging extension) ‑ расширение отладки. При DE = 1 появляются дополнительные возможности в использовании отладочных регистров. Появляется возмож-ность задавать контрольные точки по портам ввода-вывода.
PSE (page size extension) ‑ расширенный размер страниц. При PSE = 0 процессор работает только со страницами объемом 4 Кайта, при PSE = 1 – со страницами объемом 4 Кбайта и 4 Мбайта (см. разд. 3.9).
PAE (physical address extension) – расширение физического адреса. При РАЕ = 1 добавляются четыре адресных линии и процессор становится способен адресовать ОП объемом 64 Гайта (см. разд. 3.9).
MCE (machine check enable) – разрешение контроля аппаратуры. Когда этот флаг установлен в единицу, разрешается генерация прерывания типа 18 при аппаратном сбое внутри процессора или на шине.
PGE (page global enable) – разрешение глобальных страниц (см. разд. 3.8) (появился в Р6).
PCE (performance monitoring counter enable) – разрешение счетчиков производительности. В процессоре есть два счетчика производительности PMC (performance monitoring counter). Их содержимое можно прочитать командой RDPMC. При PCE = 1 эта команда доступна на любом уровне привилегий, при PCE = 0 – только на нулевом уровне.
OSFXSRR (operation system support for FXSAVE and FXSTORE iinstruction) ‑ показывает ОС, что можно использовать команды быстрого сохранения и быстрого восстановления контекста сопроцессора и ММХ-регистров. Показывает, что процессор поддерживает любые SSE- и SSE2-команды.
OSXMMEXCPT (operation system support for unmasked SIMD floating point exception) – показывает поддержку особого случая (прерывания) типа 19 (#XF), вызываемого командами класса SSE и SSE2.
Примечание к последним двум битам (флагам):
- SIMD (single instruction – many data) ‑ преобразование некоторого множества данных одной командой;
- SSE (streaming SIMD extension) – упрощенно, расширение ММХ-команд, появившееся в Pentium III (SSE) и Pentium IV (SSE2).
Все флаги в регистре cr4 являются модельно-зависимыми. То есть в каждой из моделей, например «Пентиума», набор этих флагов может оказаться уникальным. Проверить наличие тех или иных из этих флагов в конкретном процессоре можно командой cpuid.
Регистры отладки. К ним относятся регистры dr0 ‑ dr3, dr6 и dr7. Регистры dr4 и dr5 в МП отсутствуют. Здесь о регистрах отладки и регистрах проверки приводятся самые общие сведения. Для детального знакомства с этими регистрами советуем обратиться к соответствующей литературе.
В регистрах dr0 ‑ dr3 можно задавать адреса четырех контрольных точек. Когда МП вырабатывает адрес, совпадающий с адресом контрольной точки, происходит прерывание типа 1. Контрольные точки могут быть заданы как по командам (прерывание возникнет при выборке команды по заданному адресу), так и по данным (прерывание возникает в процессе выполнения команды, если в ней вырабатывается заданный адрес ОП ). При DE = 1 контрольные точки можно задавать и по портам ввода – вывода (прерывание возникнет при обращении к заданному порту). Наличие контрольных точек оказывается очень удобным при отладке системы, поскольку позволяет «сделать остановку» в критическом месте и посмотреть, что получилось (обработчик прерывания типа 1 обычно выводит на экран текущее содержимое внутренних регистров МП). Более того эту «точку остановки» можно задать даже в ПЗУ, что стало возможным, начиная с МП 386, в котором впервые появились регистры отладки.
Регистр dr6 называется регистром состояния отладки. Прерывание типа 1 может возникнуть по разным причинам: по флагу tf, по контрольной точке или по биту Т (в сегменте TSS) при переключении задач. При прерывании типа 1 процессор автоматически устанавливает в регистре dr6 соответствующий бит, указывающий причину прерывания. Эту информацию может использовать обработчик.
Регистр dr7 ‑ регистр управления отладкой. В частности, в нем для каждой контрольной точки указано, для чего она предназначена ‑ для команд или для данных.
Регистры проверки. К ним относятся регистры tr3 ‑ tr5 и tr6, tr7. Регистры tr3 ‑ tr5 используются для проверки внутренней кэш-памяти. С их помощью можем прочитать содержимое любой строки кэш-памяти, изменить это содержимое, объявить строку достоверной или недостоверной. Регистры tr6 и tr7 используются для проверки буфера TLB (кэш-памяти страниц). Регистры tr0 ‑ tr2 в процессоре отсутствуют. Необходимо отметить, что, начиная с Pentium, регистры проверки в составе процессора отсутствуют и их функции возложены на MSR-регистры.
Регистры MSR (model specific registers) – регистры, специфичные для модели. Как следует из названия, каждый конкретный процессор может включать в себя уникальный набор этих регистров. Проверить наличие тех или иных MSR можно командой cpuid. MSR-регистры можно условно разделить на четыре группы:
- регистры, в которых процессор возвращает причину аппаратного сбоя (при прерывании типа 18);
- регистр TSC – 64-разрядный счетчик времени, который запускается на счет с нуля по сигналу RESET. При непрерывной работе переполнение счетчика может произойти не ранее чем через 2000 лет;
- два счетчика производительности PMC – 40-разрядные счетчики, которые можно настраивать на подсчет количества тех или иных событий, например на подсчет числа произошедших прерываний или декодированных команд.
- регистры MTRR (memory type range registers) ‑ регистры, задающие тип области памяти, причем, используя эти регистры, можно настраивать различные области памяти на различные стратегии кэширования, т.е. одну область можно объявить некэшируемой, другую кэшируемой со сквозной записью и т.д.
В более ранних процессорах (например, МП 486), в которых регистров MTRR не было, стратегию кэширования приходилось задавать аппаратными способами.
3.19. Буфер TLB (кэш-память страниц)
Страничный механизм очень громоздкий и требует больших временных затрат. Поэтому в МП стоит внутренняя кэш-память страниц, в которой хранятся начальные адреса (вернее 20 старших разрядов адреса, поскольку 12 младших разрядов начального адреса страницы равны 0) страниц, с которыми МП работал в последнюю очередь. Процент кэш-попаданий в буфер TLB составляет порядка 95 – 98 %. И только при кэш-промахе включается страничный механизм. На рис. 3.32 поясняется структура и принцип работы буфера TLB.
Кэш-память страниц состоит из трех блоков: блок данных, блок тэгов и блок LRU/достоверности (на рис. 3.32 последний блок из-за недостатка места обозначен просто как блок LRU). Блок данных разбивается на строки (этих строк 4×8 = 32). Каждая строка имеет формат 20 бит. В строку можно загрузить начальный адрес страницы (20 старших разрядов этого адреса). Каждой строке ставится в соответствие свой тэг в блоке тэгов. На рис. 3.32 приведен пример, в котором соответствующие друг другу строка и тэг помечены звездочками. Тэг имеет формат 17 бит.
Всю кэш-память страниц можно условно разбить на 8 горизонталей (на рис. 3.32, соответственно гр. 0 ‑ гр. 7). На каждой горизонтали располагаются 4 строки, соответствующие этим строкам четыре тэга и один 7-битовый элемент LRU/-достоверности.
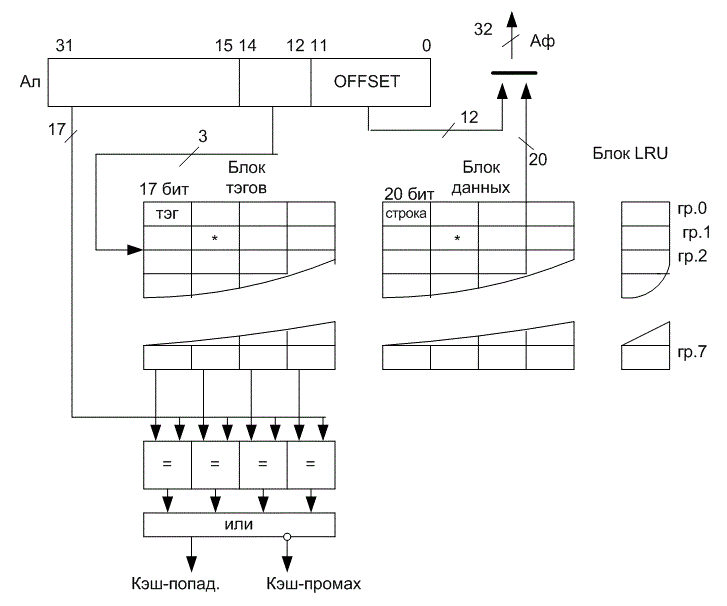
Рис. 3.32
Рассмотрим работу кэш-памяти страниц. Алгоритм ее функционирования прост по сути, но зачастую оказывается сложным для понимания. Начнем с рассмотрения варианта, когда МП ищет в буфере начальный адрес нужной ему страницы и там его не находит (кэш-промах).
Итак, сегментный механизм выработал линейный адрес Ал. Поскольку включен страничный механизм, то этот адрес еще не является физическим (Аф). Пусть при поиске начального адреса страницы (соответствующего Ал) в буфере TLB произошел кэш-промах. Начинает работать громоздкий страничный механизм. Когда МП в соответствующей таблице страниц найдет нужный элемент PTE, то он извлечет из этого элемента 20 старших разрядов начального адреса страницы, пристыкует к ним 12-разрядное смещение OFFSET (из Ал) и сформирует тем самым искомый Аф. Одновременно МП возьмет найденные им в PTE 20 старших разрядов начального адреса страницы и загрузит их в одну из строк блока данных буфера TLB. Важным является то, что данный начальный адрес не может попасть в любую строку блока данных, он может попасть только в одну из четырех строк на конкретной горизонтали! Номер горизонтали определяют разряды 14 ‑ 12 линейного адреса Ал. Например, если
Ал = 11000001111100101010111100111001b
(разряды 14 ‑ 12 выделены жирным шрифтом), то поиск начального адреса страницы, а впоследствии, если он не найден, загрузка этого начального адреса в буфер будет производиться на горизонтали 2.
Когда МП при кэш-промахе загружает в какую-либо строку буфера новый начальный адрес страницы, то он одновременно копирует в соответствующий этой строке тэг 17-ти старших разрядов Ал (разряды 31 ‑ 15). Для рассматриваемого примера (если был кэш-промах) в соответствующий тэг будет записано 11000001111100101. Однако не ясно, а в какую из четырех строк на известной горизонтали попадет (при кэш-промахе) начальный адрес. Решением этой задачи «заведует» расположенный на этой горизонтали элемент LRU/-достоверности. Вернее, задача решается на основании записанной в этом элементе информации. Об этом будет сказано позднее.
Вернемся теперь к началу процесса. Итак включен страничный механизм. Сегментный механизм выработал Ал. МП берет разряды 14 ‑12 этого адреса и определяет горизонталь в буфере TLB. Затем МП берет старшие 17 разрядов Ал и сравнивает их со всеми четырьмя тэгами, расположенными на выбранной горизонтали. При этом возможны два варианта: произошло сравнение с одним из тэгов или сравнений не произошло совсем. Несколько сравнений сразу произойти здесь не может, так как алгоритм заполнения кэш-памяти таков, что на одной горизонтали не может оказаться одинаковых тэгов.
Если сравнений не произошло, то произошел кэш-промах. Действия МП при кэш-промахе уже рассмотрены выше. Если сравнение с одним из тэгов произошло, то это кэш-попадание. МП достает из соответствующей этому тэгу строки 20-ти старших разрядов начального адреса страницы, пристыковывает к ним 12 младших разрядов Ал (OFFSET ) и тем самым формирует искомый Аф.
Любой элемент LRU/-достоверности имеет формат, приведенный на рис. 3.33.
|
b0 |
b1 |
b2 |
a0 |
a1 |
a2 |
a3 |
Рис. 3.33
Здесь a0 ‑ a3 ‑ биты достоверности. Каждый бит достоверности соответствует одной из четырех расположенных на данной горизонтали строк. Когда МП после кэш-промаха загружает «на горизонталь» новый начальный адрес страницы, то он прежде всего последовательно проверяет биты достоверности, расположенные на данной горизонтали. Если при этом МП встречает строку, объявленную недостоверной, то именно в нее и будет загружен новый адрес.
Однако вполне возможно, что все строки на данной горизонтали окажутся достоверными. Тогда информацию из какой-то строки придется удалить, а на ее место загрузить новый начальный адрес. МП при этом стремится удалить начальный адрес той страницы, к которой он обращался наиболее давно. В этом ему «помогают» биты LRU (last recently used ‑ наиболее давно использовал) b0 – b2. Обозначим строки на горизонтали S0, S1, S2 и S3. При кэш-попаданиях МП всегда обновляет биты LRU по следующей схеме:
- при обращении к S0 или S1 бит b0 устанавливается в единицу, а при обращении к S2 или S3 бит b0 сбрасывается в 0;
- при обращении к S0 бит b1 устанавливается, а при обращении к S1 бит b1 сбрасывается;
- при обращении к S2 бит b2 устанавливается, а при обращении к S3 бит b2 сбрасывается;
Алгоритм удаления строк приведен в табл. 3.13.
Таблица 3.1
|
b |
b1 |
b2 |
|
|
0 |
0 |
Безразлично |
Удаляется S0 |
|
0 |
1 |
Безразлично |
Удаляется S1 |
|
1 |
Безразлично |
0 |
Удаляется S2 |
|
1 |
Безразлично |
1 |
Удаляется S3 |
3.20. Общие сведения о кэш-памяти
Рассмотренный в предыдущем разд. 3.19 буфер TLB представляет из себя специфический вид кэш-памяти. Во-первых, в нем хранятся только адреса страниц, во-вторых, информация в кэше модифицируется только со стороны ОП (когда при кэш-промахе в строку из ОП загружается новый начальный адрес страницы).
Стандартная же кэш-память предназначена для хранения кодов и данных. Модификация информации в кэше может происходить как со стороны ОП (кэш-промах при чтении), так и со стороны процессора (кэш-попадание при записи).
Быстродействующие микросхемы ОЗУ стоят дорого, а дешевые микросхемы ОЗУ работают значительно медленнее процессора. Возникает противоречие между стоимостью системы и ее быстродействием. Для решения этой проблемы в систему вводится кэш-память. Она представляет собой высокобыстродействующее ОЗУ сравнительно небольшого объема и располагается в системе между МП и ОП (рис. 3.34).

Рис. 3.34
Использование кэш-памяти базируется на принципе локальности программ и данных. Соседние команды программы располагаются в соседних ячейках памяти. Аналогично и данные, к которым обращается МП по ходу выполнения программы, обычно занимают некоторую локальную область ОП. Пусть надо прочитать байт, расположенный в ячейке ОП с адресом А. Давайте прочтем помимо байта А целый блок информации, включающий в себя нужный нам байт, и поместим этот блок в кэш-память. Велика вероятность того, что при следующем обращении за данными нужная нам информация уже окажется в кэш-памяти. Размер считываемого в кэш-память блока часто называют шириной выборки.
Пусть процессор выполняет команду mov ax,[bx]. При кэш-попадании он просто возьмет нужную информацию из кэша. При кэш-промахе в одну из строк кэша попадет блок информации из ОП. Пусть выполняется команда mov [bx],ax. При кэш-промахе процессор запишет информацию в ОП (в Р6 плюс к этому обновится и некоторая строка кэша). При кэш-попадании процессор запишет информацию в кэш (изменение в такой ситуации информации в ОП рассмотрим позже).
Важнейшей характеристикой любой кэш-памяти является процент кэш-попаданий, который она обеспечивает. Дело в том, что кэш-память дает выигрыш в быстродействии только при кэш-попадании, а при кэш-промахе может даже замедлять работу системы (сначала МП потратит время на поиск данных в кэш-памяти, а затем будет вынужден обычным образом обратиться к ОП). Процент попаданий зависит от многих факторов. Основные факторы следующие.
1. Объем кэш-памяти. Очевидно, что чем он выше, тем выше процент попаданий. Но при этом растет стоимость кэш-памяти. Современная кэш-память уже имеет объем, измеряемый в мегабайтах.
2. Ширина выборки. Чем шире выборка, тем выше процент попаданий. При большой ширине выборки трудно организовать быстрое считывание информации из ОП в кэш-память. Ширина выборки берется от 4 до 64 байт и определяется в основном разрядностью шины данных.
3. Стратегия заполнения кэш-памяти.
Остановимся на последнем факторе подробнее. Любая кэш-память состоит из блока данных, разбитого на строки, и блока тэгов (см. буфер TLB). Формат строки блока данных совпадает с шириной выборки. В зависимости от стратегии заполнения различают три вида кэш-памяти.
1. Кэш-память с прямым отображением. В этой кэш-памяти любой считываемый из ОП блок информации может попасть только в одну конкретную строку кэш-памяти. Однако в эту строку может попасть (отобразиться) не только этот блок, но и ряд других блоков, имеющих в ОП конкретное месторасположение. Поясним структуру такой кэш-памяти на рис. 3.35.
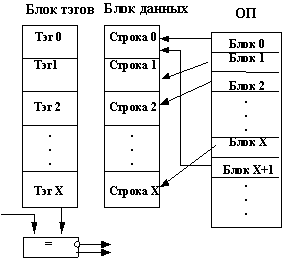
Рис. 3.35
Как видно из рис. 3.25, кэш-память состоит из Х горизонталей. На каждой горизонтали располагается одна строка и один тэг. Принцип работы такой кэш-памяти аналогичен принципу работы рассмотренной выше кэш-памяти страниц. Разница заключается в том, что там любая информация могла попасть в любую из 4-х строк, расположенных на одной горизонтали, а здесь информация попадает только в конкретную строку (поскольку на горизонтали располагается всего одна строка).
Достоинством кэш-памяти с прямым отображением являются малые аппаратурные затраты. В частности, просто реализуется схема сравнения, так как сравнение производится только с одним тэгом. Блок LRU вообще оказывается не нужен (не из чего выбирать!). Серьезным недостатком такой кэш-памяти является невысокий процент кэш-попаданий. Имеется еще ряд мелких, но неприятных недостатков, которые рассматривать не будем.
2. Полностью ассоциативная кэш-память. Здесь любой блок информации может попасть в любую строку блока данных. Поясним это на рис. 3.36.
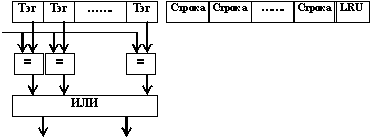
Рис. 3.36
Как видно из рис. 3.36, все строки тэги располагаются на одной единственной горизонтали. Такая кэш-память обеспечивает наивысший процент кэш-попаданий, но требует при реализации больших аппаратурных затрат. Чего стоит одна только схема сравнения, ведь сравнение здесь ведется со всеми тэгами одновременно. На практике такой принцип построения применяется только для кэшей малого объема. Например, Intel использует этот принцип в буферах TLB для больших страниц, в котором блок данных состоит всего из двух (или несколько более) строк.
3. Частично ассоциативная кэш-память. Это компромиссный вариант между полностью ассоциативной кэш-памятью и кэш-памятью с прямым отображением. Этот вариант чаще всего используется на практике. Любой блок информации может попасть в любую из нескольких строк, расположенных на конкретной горизонтали, но не может попасть на другую горизонталь. Такую кэш-память уже подробно рассмотрели выше. Так реализована кэш-память страниц. Необязательно, чтобы на горизонтали располагалось четыре строки (4 way-set cache). Intel использует кэши с двумя строками на горизонтали (2 way-set).
Наличие кэш-памяти приводит, как минимум, к ряду проблем, связанных с согласованностью данных в различных видах памяти системы. Пусть какое-то ВУ, использовав ПДП, занесло в ОП новую информацию. При этом часть информации в кэш-памяти может оказаться устаревшей.
Подобные ситуации должен отслеживать контроллер кэш-памяти. Он в такой ситуации поступает просто ‑ объявляет все строки кэш-памяти недостоверными и кэш-память начинает заполняться «с нуля». Вторая проблема связана с операцией записи в ОП. Пусть МП выполняет команду записи в ОП. При кэш-промахе проблемы не возникает ‑ данные просто будут записаны в ОП (в Р6 при этом будет еще инициировано заполнение строки кэша).
При кэш-попадании обновляется информация в кэш-памяти, а как быть с ОП? Есть два варианта. Первый ‑ сразу продублировать эту информацию в ОП. Это сквозная запись (write through). Однако при этом кэш-память не дает при записи никакого выигрыша в быстродействии. Второй вариант ‑ отложить запись новой информации в ОП до той поры, когда это будет действительно необходимо (например, какое-то ВУ выдало запрос на ПДП для чтения информации из ОП). Это так называемая обратная запись (write back). Кэш с обратной записью обеспечивает большее быстродействие, но требует более сложного контроллера кэш-памяти. В МП 486 внутренняя кэш-память работает только со сквозной записью.
В современных вычислительных системах обычно используется сразу несколько кэшей:
- кэш первого уровня (L1) – кэш небольшого объема, встроенный в процессор;
- кэш второго уровня (L2) – кэш большого объема, часто расположенный вне процессора.
Кроме того, начиная с Pentium, в системах аппаратно поддерживаются два и более процессоров. Поскольку каждый из этих процессоров имеет свои кэши, проблема согласованности информации в различных видах памяти системы серьезно обостряется. Поэтому, начиная с Pentium, для работы с кэшами применяется MESI-протокол. Согласно этому протоколу любая строка любого кэша может находиться в одном из четырех состояний:
- М (modified) – модифицированная строка, которая находится только в этом кэше и ее содержимое изменено процессором, т.е. такая же информация в ОП устарела;
- Е (exclusive) – уникальная строка, которая находится только в этом кэше и информация в ней совпадает с информацией в ОП;
- S (shared) – разделяемая сторока, которая потенциально находится сразу в нескольких кэшах. Если процессор модифицирует информацию в такой строке, то одновременно модифицируется такая же информация в ОП, а соответствующая информация в других кэшах объявляется недостоверной;
- I (invalid) – недостоверная строка.
3.21. Внутренняя кэш-память
Структура внутренней кэш-памяти (L1-кэш для МП 486) приведена на рис. 3.37, откуда видно, что структура внутренней кэш-памяти мало чем отличается от рассмотренной выше структуры буфера TLB.

Рис. 3.37
Алгоритмы работы внутренней кэш-памяти и буфера TLB также практически идентичны. Поэтому не будем повторяться, а подчеркнем, чем отличается внутренний кэш от буфера TLB:
- внутренний кэш работает с физическим адресом Аф, а не с Ал;
- под тэг выделяется 21 бит;
- формат строки (размер блока) составляет 16 байт, при этом в кэш из ОП всегда считывается блок, выровненный по границе параграфа (например, обратились к байту по адресу 3 и произошел кэш-промах, тогда в соответствующую строку кэш-памяти будет из ОП считано 16 байт, начиная с адреса 0 и заканчивая адресом Fh);
- разряды 10 ‑ 4 Аф задают горизонталь (всего горизонталей – 128);
- разряды 3 ‑ 0 Аф определяют конкретный байт (слово и т. д.) внутри блока;
- основное же отличие между внутренней кэш-памятью и буфером TLB заключается в их предназначении, в буфере хранятся начальные адреса страниц, а во внутренней кэш-памяти ‑ команды и данные, при этом данные доступны как по записи, так и по считыванию;
- общий объем внутренней кэш-памяти составляет 128×4×16 байт = 8 Кбайт.
Любую строку во внутренней кэш-памяти можно объявить недостоверной либо программным образом через регистры tr3 ‑ tr5, либо аппаратным образом, используя входы процессора EADS и AHOLD. Можно объявить недостоверными сразу все строки (очистить кэш). Для этого можно:
- подать сигнал на вход RESET;
- подать сигнал на вход FLUSH;
- использовать регистры TR3 ‑ TR5;
- выполнить одну из двух команд invd или wbinvd.
3.22. Сведения о кэшах в процессорах фирмы Intel
Рассмотренные ранее буфер TLB и внутреняя кэш-память используются в МП 486. В других процессорах фирмы Intel имеются нюансы в организации кэшей, хотя общие принципы их организации ничем не отличаются от рассмотренных выше. В табл. 3.14 приведены сведения о кэшах, стоящих в различных процессорах фирмы Intel.
Таблица 3.14
|
Процессор |
L1 | TLB | L2 |
|
386 |
Нет | TLB для обычных страниц кода и данных | Внешний, подключен к ШД |
|
486 |
8 Кбайт для кода и данных | TLB для обычных страниц кода и данных | Внешний, подключен к ШД |
|
Pentium |
L1 для кода (8 или 16 Кбайт, формат строки – 32 байта) L1 для данных (аналогич-но) | TLB кода (обычные страницы) TLB данных (обычные страницы) TLB для больших страниц (код и данные) | Внешний, подключен к ШД |
|
Pentium Pro |
L1 для кода (8 или 16 Кбайт, формат строки – 32 байта) L1 для данных (аналогич-но) | TLB кода (обычные страницы) TLB данных (обычные страницы) TLB для больших страниц кода TLB для больших страниц данных | Внутренний, связан с ядром специальной шиной кэша. Объем: 256 Кбайт, 512 Кбайт или 1 Мбайт |
|
Pentium II |
См. Pentium Pro |
См. Pentium Pro |
Внешний, расположен с процессором на одном картрид-же и связан с ядром шиной кэша. Объем: 256 Кайт, 512 Кайт или 1 Мбайт |
|
Celerone |
См. Pentium Pro |
См. Pentium Pro |
Или не поддер-живается или встроенный в процессор небольшого объема (128 Кбайт) |
|
Pentium III |
См. Pentium Pro |
См. Pentium Pro |
См. Pentium II (объем до 2 Мбайт) или внутренний 256 Кбайт. |
|
Pentium IV |
L1 для кода – нет, имеется кэш микроко-манд объе-мом 12 Кбайт. L1 для данных (8 Кбайт формат строки - 64 байта) | TLB кода, общий для больших и обычных страниц. TLB данных, общий для больших и обычных страниц | Внутренний 256 Кайт, формат строки – 64 байта. |
Примечание. Более точные и подробные сведения о кэшах конкретного процессора можно получить с помощью команды cpuid (см. разд. 3.29).
3.23. Инициализация процессора
Процесс инициализации МП автоматически инициируется после появления сигнала «сброс» на входе RESET. При этом, если выполняются определенные внешние условия (эти условия различаются для разных процессоров, например, для МП 486 в момент заднего фронта сигнала RESET на входе AHOLD должен стоять активный сигнал), то МП выполняет самотестирование (так называемый BIST (build in self test)). Если этот процесс прошел успешно, в eax возвращается 0. В противном случае МП неисправен. Независимо от того, было самотестирование или нет, в dh возвращается номер МП (например, для Pentium – 5), а в dl ‑ номер модели. Содержимое регистров ecx, ebx, esp, ebp, esi и edi ( а также eax, если не было самотестирования) равно нулю.
В теневую часть idtr записываются начальный адрес и размер таблицы прерываний, соответственно 0 и 3FFh.
В cr0 заносится 60000010h. То есть МП стартует в реальном режиме, с выключенным страничным механизмом и запрещенным кэшем. В регистрах cr2, cr3 и cr4 возвращаются нули.
В видимые части всех сегментных регистров (кроме cs) заносятся нули, а в теневые части (в том числе и теневую часть сs) загружается размер сегмента, равный FFFFh.
В видимую часть cs заносится F000h, а в eip ‑ 0000FFF0h. Казалось бы, что МП должен стартовать с адреса Аф = (сs)×16+(eip) = 000FFFF0h, но это не так. Дело в том, что при инициализации в теневую часть cs в качестве начального адреса сегмента кода загружается FFFF0000h. Поэтому стартовый адрес МП Аф = FFFF0000h +(eip) = FFFFFFF0h. То есть МП стартует с адреса, отстоящего на 16 байт от конца 4-гигабайтного пространства. Сделано это для того, чтобы адреса стартового ПЗУ не располагались где-нибудь в середине адресного пространства, а однозначно находились бы в его конце.
Итак, несмотря на утверждение о том, что МП в реальном режиме не может адресовать память свыше одного мегабайта, на самом деле сразу после старта МП «находится» в адресах FFFF0000h - FFFFFFFFh, т.е. в последних 64 килобайтах 4-гигабайтного пространства. Он будет там оставаться до тех пор, пока не встретит команду jmp far. Эта команда занесет в видимую часть cs новое число, процессор умножит это число на 16 и занесет полученный результат в теневую часть cs в качестве начального адреса сегмента кода. После этого МП действительно «окажется» в самом младшем мегабайте адресного пространства и будет там оставаться до тех пор, пока не перейдем в защищенный режим.
3.24. Некоторые сведения о внутренней организации 32-разрядных процессоров
Как показано в разд. 2.4, МП 8086 состоит из двух полунезависимых блоков: операционного устройства и шинного интерфейса. Такая структура позволяет организовать двухступенчатый конвейер (пока одна команда выполняется, другие команды выбираются из ОП).
В более старших процессорах глубина конвейера была значительно увеличена. Например, МП 486 состоит из девяти полунезависимых блоков.
1. Шинный интерфейс. Этот блок обеспечивает обмен между процессором и ОП, процессором и портами ВУ, инициирует все циклы шины. Стандартный цикл шины в МП 486 занимает 2 машинных такта.
2. Внутренняя кэш-память. Доступ к данным при кэш-попадании занимает 1 машинный такт.
3. Блок предвыборки команд. Основной частью этого блока является 32-байтная очередь команд. В процессе выполнения любой команды имеется промежуток времени, когда системная шина оказывается свободна. Шинный интерфейс использует эти промежутки для опережающей выборки команд из памяти. Выбранные с опережением из ОП команды внутри МП хранятся в очереди команд.
4. Блок дешифрации. Преобразует команды в микрокоманды.
5. Блок управления. Формирует все внутренние управляющие сигналы.
6. Устройство с плавающей точкой. Выполняет команды арифметического сопроцессора.
7. Целочисленное устройство. Выполняет команды процессора.
8. Блок сегментации. Обеспечивает работу сегментного механизма.
9. Блок страничного преобразования. Включает в себя буфер TLB и обеспечивает работу страничного механизма.
Эти блоки могут работать параллельно, что обеспечивает достаточно большую глубину конвейера: одна команда выполняется, другая выбирается из ОП, третья дешифрируется, для четвертой формируется адрес и т.д.
Только за счет внутренней организации МП 486 на одинаковой частоте работает в 2,5 раза быстрее МП 386. Внутренняя организация МП 486 такова, что при оптимальной организации программы этот процессор способен обеспечить выполнение одной команды за один машинный такт. В общем случае выполнение конкретной команды может занимать несколько тактов, но это компенсируется наличием конвейера. За один машинный такт конвейер выдает результат одной машинной команды.
Все процессоры, включая МП 486, имели скалярную архитектуру ‑ имели один конвейер. Начиная с Pentium, в процессорах реализована суперскалярная архитектура, т.е. внутри процессора имеется несколько конвейеров, способных работать параллельно.
В Pentium имеются два конвейера и при их оптимальной загрузке процессор способен выдавать за один такт результаты двух машинных команд. Один из этих конвейеров называется U-конвейером, а другой ‑ V-конвейером. Разница между этими конвейерами заключается в том, что на U-конвейере можно запустить любую команду, а V-конвейер имеет в этом смысле определенные ограничения. Кроме того, не любая пара даже допустимых команд может быть одновременно запущена на этих конвейерах. Сведения об этих ограничениях приводятся в справочной литературе. Программист, желающий получить максимальную производительность процессора, должен компоновать команды программы таким образом, чтобы обеспечить максимальную загрузку конвейеров (или использовать специальные компиляторы, если программа пишется на языке высокого уровня).
Очевидно, что подобная структура будет работать максимально эффективно при максимальной загрузке конвейеров. Узким местом, в этом смысле, являются команды переходов. Все процессоры, включая МП 486 при встрече команды перехода, очищали очередь команд и начинали заполнять ее заново, что естественно приводило к снижению производительности. Для обхода этого узкого места в Pentium было введено «предсказание перехода» (branch prediction). То есть, встретив команду перехода, процессор предсказывает, произойдет переход или нет, и в соответствии с этим предсказанием, продолжает выборку команд из памяти. Если предсказание оказалось неверным, то вводятся штрафные циклы (penalty), во время которых вся неправильно выбранная информация сбрасывается и выборка команд начинается сначала по правильной ветви перехода.
Для реализации стратегии предсказания переходов в состав процессора введен буфер целевых адресов переходов BTB (branch target buffer). В этом буфере можно хранить до 256 адресов переходов и статистику о переходах на эти адреса (сведения о четырех последних переходах на этот адрес – «был – не был»). Наличие статистики позволяет реализовать стратегию динамического предсказания перехода. Естественно, когда процессор встречает переход впервые, никакой статистики об этом переходе у него нет. В этом случае используется статическое предсказание перехода: переход назад предсказывается, а вперед – нет. Связано это с тем, что переход назад чаще всего – цикл.
В семействе Р6 (процессоры Pentium Pro, Pentium II, Celerone и Pentium III, в которых используется микроархитектура Р6) введены следующие новые архитектурные решения (рис. 3.38).
1. Процессор за такт способен выдавать результаты трех команд.
2. Ядро процессора выполняет команды не в том порядке, в котором они заданы в программе, а в порядке, «выгодном» процессору (out of order), соблюдая все зависимости по данным. Связано это нововведение со следующим соображением. Пусть есть три подряд идущие команды, причем вторая команда зависит от результата первой. Очевидно, что первую и вторую команды нельзя выполнить одновременно, но если третья команда никак не связана по данным ни с первой, ни со второй, можем одновременно выполнить первую и третью команды, отложив выполнение второй команды.
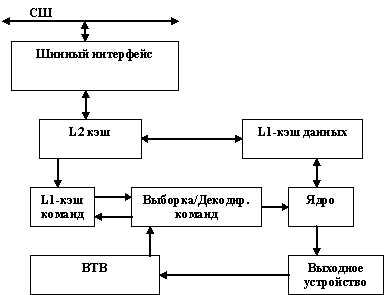
Рис. 3.38
Работа процессора семейства Р6 строится следующим образом. Команды считываются из кэш-памяти команд в порядке, заданном программой, и поступают на устройство декодирования (decode unit). Последнее «разворачивает» команды в последовательность микроопераций (μops).
При этом различаются два вида команд: команда декодируется в последовательность до 4-х μops (такая команда может декодироваться за один такт); команда декодируется в последовательность больше 4-х μops (декодируется за несколько тактов). Само устройство декодирования включает в себя три независимых декодера. Один из них за такт способен декодировать команду, содержащую до 4-х μops, а два других – только 1 μops.
Таким образом, для достижения максимальной производительности надо компоновать команды с учетом соотношения 4-1-1 μops. Декодированные команды поступают в накопитель ядра (reorder buffer). Устройство диспетчеризации (dispatch unit) постоянно просматривает накопитель, выявляя команды, для которых готовы все данные, и направляя такие команды на одно из имеющихся в ядре исполнительных устройств. Выходное устройство (retirement unit) обеспечивает выдачу результатов уже в порядке, заданном программой.
3. Как и в Pentium, реализовано предсказание переходов, только в ВТВ может храниться до 512 целевых адресов переходов.
4. Реализовано «спекулятивное» выполнение команд (speculative execution), т.е. предсказанные после перехода команды не только выбираются из кэша и декодируются, но и по возможности выполняются до проверки условия перехода. При неверном предсказании перехода результаты выполнения таких команд аннулируются.
5. Реализовано «переименование регистров» (registers renaming). Узким местом процессоров фирмы Intel является малое число внутренних регистров. Это приводит к резкому возрастанию зависимости по данным между командами и, соответственно, снижает загрузку конвейеров. Для обхода этого узкого места в состав процессора введено значительно больше регистров, чем дается в описании программной модели, и процессор сам присваивает им временные имена.
Процессор Pentium IV относится к новому семейству прцессоров, реализованному на основе микроархитектуры NetBurst (см. рис. 3.39).
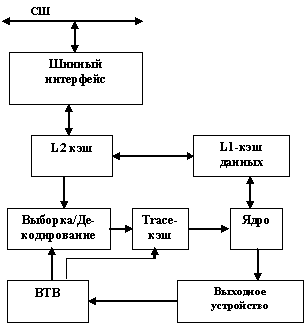
Рис. 3.39
Как видно из рис. 3.38 и 3.39 отличие микроархитектуры Р6 от микроархитектуры NetBurst заключается в отсутствии в последней L1 кэша команд, который заменен trace-кэшем, стоящем на выходе устройства декодирования. Пооследнее выбирает команды из L2-кэша и разворачивает их в последовательности μops, которые называются trace (трек).
Эти треки хранятся в trace-кэше. Такая микроархитектура позволяет снизить некоторые потери в быстродействии, связанные с предсказанием переходов.
Наличие нескольких конвейеров, а тем более неупорядоченного выполнения команд программы, может привести к разного рода коллизиям, например, при переключении одного режима в другой. Поэтому, начиная с Pentium, появились так называемые сериалайзд-команды (serialized instruction), которые гарантируют, что выполнение всех предыдущих команд программы будет полностью завершено перед выполнением такой команды. Сериалайзд-команда – это обычная команда, выполняющаяся обычным образом, но, плюс к этому, обладающая описанным выше свойством. Таких команд в системе команд порядка десятка и большинство из них в защищенном режиме доступны только на нулевом уровне привилегий. Пользователю всегда доступна только одна такая команда – cpuid.
3.25. Режим SMM
В режим SMM (system management mode) можно попасть из любого другого режима процессора, при этом возврат из SMM будет в тот режим, из которого попали в SMM. Работа процессора в этом режиме «не видна» ни прикладным программам, ни операционной системе. Находясь в этом режиме, процессор выполняет программу, написанную производителем аппаратуры. Как правило, в режиме SMM реализуются функции энергосбережения. Появился этот режим еще в МП 386 SL.
Процессор переходит в режим SMM по специальному прерыванию SMI (system management interrupt). Это внешнее аппаратное прерывание, которое инициируется сигналом на специальной ножке процессора (в более старших моделях – специальным сообщением на шине APIC (advanced programmable interrupt controller)). Восприняв прерывание SMI, процессор начинает вырабатывать специальный внешний сигнал, показывающий оборудованию системы, что процессор находится в режиме SMM.
Наличие этого сигнала и позволяет сделать режим SMM «невидимым» обычному программному обеспечению. Достигается это тем, что данный специальный сигнал позволяет адресовать специальную область памяти, недоступную без этого сигнала. Эта область памяти (называется SMRAM) может быть выделена внутри обычной ОП, а может быть отдельной, то есть дублировать некоторую область ОП.
По умолчанию SMRAM имеет размер 64Кбайта, но этот размер может быть изменен. Максимальный размер SMRAM - 4 Гбайта, минимальный – 32Кбайта. Начальный адрес SMRAM (этот адрес называется SMBASE) задается процессору в специальном внутреннем регистре. По умолчанию SMBASE = 30000h, но, при желании его можно изменить.
Попав в режим SMM процессор вначале запоминает свое текущее состояние (содержимое основных своих регистров) в области памяти:
SMBASE + FEOOh - SMBASE + FFFFh.
Затем процессор начинает выполнять программу, начиная с адреса SMBASE + 8000h.
При входе в режим SMM все прерывания должны быть запрещены. Прерывания по входу INTR запрещает сам процессор сбрасывая флаг if в ноль, а прерывания по входам NMI и SMI должны быть запрещены программно-аппаратным способом. Связано это с тем, что при входе в режим SMM у процессора по сути дела отсутствует таблица прерываний. Если находясь в режиме SMM создать эту таблицу, то прерывания можно разрешить.
Режим SMM ‑ обычный реальный режим, но в SMM процессор сразу способен адресовать память объемом 4 Гбайта (в теневых частях всех сегментных регистров занесен размер сегмента, равный FFFFFFFFh). Для обращения к памяти за пределами 1 Мбайта необходимо использовать префикс размера адреса. Обработчики прерываний (если разрешили прерывания) необходимо размещать в пределах первого мегабайта памяти (иначе процессор их не найдет, поскольку используется таблица прерываний реального режима!).
Возврат из режима SMM происходит по специальной команде rsm (resume system mode). В любом другом режиме эта команда вызовет прерывание #UD.
3.26. Система прерываний 32-х разрядных процессоров
Как и в любых других процессорах, все прерывания 32-разрядных процессоров можно разделить на внешние, внутренние и программные. Внутренние прерывания принято называть «особыми случаями» (иногда «исключениями»). Рассмотрим именно особые случаи, которые можно разбить на три группы.
1. Нарушение (fault) ‑ МП запоминает в стеке адрес возврата, указывающий на «виноватую» команду. При возврате из обработчика происходит рестарт отказавшей команды.
2. Ловушка (trap) ‑ запоминаемый в стеке адрес возврата указывает на следующую (за «виноватой») команду программы. Рестарта здесь не будет.
3. Аавария (abort) ‑ при аварии некоторый контекст текущей задачи теряется и выполнять ее дальше невозможно. Установить причину аварии также невозможно. Единственное, что может предпринять обработчик ‑ сохранить текущее состояние системы и корректно ее отключить (перейти на цикл отключения ‑ shutdown).
Действия процессора при прерывании зависят от того, в каком режиме он находится.
В реальном режиме 32-разрядный процессор выполняет при прерывании те же действия, что и МП 8086. В стеке запоминается содержимое регистра флагов (f) и адрес возврата (cs:ip). Затем по известному типу прерывания в таблице прерываний отыскивается начальный адрес обработчика и управление передается этому обработчику.
В отличие от МП 8086, у которого таблица прерываний фиксирована в младшем килобайте ОП, в реальном режиме имеется возможность, используя команду lidt перемещать эту таблицу в ОП и менять ее размер. Пользователю это отличие не видно, поскольку при инициализации МП для таблицы прерываний задается (в регистре idtr) нулевой начальный адрес и размер 1 Кбайт. У пользователя есть возможность перемещать эту таблицу.
Вторым отличием 32-разрядного процессора от МП 8086 является количество возможных особых случаев. В МП 8086 их было всего четыре (и все они относились к классу ловушек): ошибка деления (тип 0), прерывание по флагу tf (тип 1), прерывание по команде int3 (тип 3) и прерывание по команде into (тип 4). С оговорками сюда же можно отнести прерывание по входу NMI (тип 2), которое хотя и является внешним прерыванием, но имеет алгоритм обработки, типичный для особого случая. В реальном режиме 32-разрядного процессора особых случаев значительно больше.
В защищенном режиме в качестве таблицы прерываний используется таблица IDT. Начальный адрес и размер таблицы задаются в регистре idtr. В этой таблице не может быть ни одного дескриптора, там располагаются только шлюзы. Связано это со следующими соображениями. Прерывание может произойти в любой момент, и когда работаем на 0-м уровне привилегий, и когда работаем на 3-м уровне. Следовательно, обработчик должен быть доступен с любого уровня привилегий. А такой доступ может быть обеспечен только через шлюз, причем этот шлюз должен иметь 3-й уровень привилегий.
Имеется еще одно обстоятельство. Как известно, через шлюз можно перейти либо к сегменту с тем же, либо с более высоким уровнем привилегий, чем текущий. К кодовому сегменту с более низким уровнем привилегий получить доступ невозможно. Отсюда вывод: обработчик надо располагать в сегменте с 0-м уровнем привилегий.
При любом прерывании МП автоматически сохраняет в стеке содержимое регистра флагов (ef) и адрес возврата в формате 00cs:eip. Если обработчик располагается в сегменте с более высоким уровнем привилегий, то процессор должен сменить стек на более привилегирован-ный. Вершина старого стека запоминается в новом стеке в формате 00ss:esp. Для некоторых особых случаев в защищенном режиме МП помещает в стек дополнительную информацию, называемую кодом ошибки. При прерывании МП автоматически загружает в стек от 12-ти до 24-х байт. Существуют четыре варианта заполнения стека, приведенные на рис. 3.40.
Формат кода ошибки различен для разных особых случаев. Если особый случай связан с обращением к дескриптору, например нарушены права доступа или сегмент не присутствует в ОП, код ошибки имеет формат, приведенный на рис. 3.41.
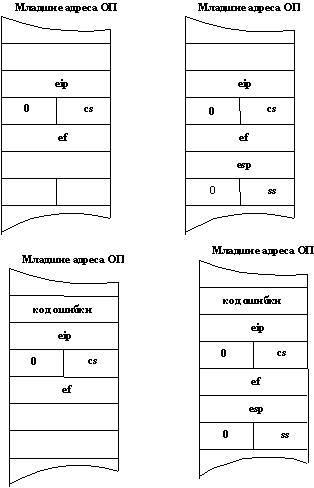
Рис. 3.40
| 31 16 | 15 3 |
2 |
1 |
0 |
|
Резерв |
Селектор |
TI |
I |
EXT |
Рис. 3.41
Селектор задает «виноватый» дескриптор в одной из дескрипторных таблиц. Дескрипторная таблица определяется битами TI и I:
I = 1, TI ‑ безразлично ‑ это IDT;
I = 0, TI = 0 ‑ это GDT;
I = 0, TI = 1 ‑ то LDT.
Если бит EXT (external – «внешний») равен единице, этот особый случай вызван аппаратным прерыванием или возник при обработке другого особого случая. Обработчик может с помощью кода ошибки прочитать «виноватый» дескриптор и по нему определить конкретную причину особого случая. Иногда МП формирует код ошибки, состоящий из одних нулей. Никакой информации он не несет и его назначение неизвестно. Наконец имеется еще один формат кода ошибки, формируемый процессором при страничном нарушении (тип 14). Этот формат рассмотрим несколько позже.
Действия процессора при прерывании в режиме V86 достаточно подробно обсуждались в разд. 3.11.
Рассмотрим подробное описание особых случаев.
Тип 0 ‑ ошибка деления. Этот особый случай относится к нарушениям. Может возникнуть при выполнении команд деления, если формат результата превышает формат регистра-получателя. С точки зрения МП этот результат является бесконечным, а такое деление эквивалентно делению на ноль.
Тип 1 ‑ особый случай отладки. В реальном режиме может возникать в трех случаях: по флагу tf (это ловушка), по контрольной точке по данным или порту ввода-вывода (тоже ловушка) и по контрольной точке по команде (а вот это ‑ нарушение!). Кроме того, в защищенном режиме возможен еще один случай, когда возникает это прерывание: при переключении задач, если бит Т в TSS входящей задачи установлен в единицу. Последний особый случай является ловушкой. Кода ошибки нет. Напомним, что контрольные точки задаются в регистрах отладки dr0 -dr3. Чтобы установить конкретную причину прерывания типа 1, надо анализировать содержимое регистра dr6.
Тип 2 ‑ прерывание по NMI. Можно отнести к особым случаям с некоторыми оговорками. Так как этот вход опрашивается на границах между командами, то нельзя назвать это прерывание ни ловушкой, ни нарушением.
Тип 3 ‑ прерывание по команде int3 (контрольная точка). Это ловушка. Команда int3 используется при отладке, в частности, ее активно используют различные «дебагеры». Эти команды располагаются в критических местах отлаживаемой программы. Обработчик этого прерывания обычно выводит на экран содержимое внутренних регистров МП. Таким образом, в критических местах программы останавливаемся и смотрим на полученные результаты. Когда программа отлажена, все команды int3 заменяются командами nop (пустая команда). У команды int3 есть аналог ‑ команда int 3, однако первая занимает в памяти один байт, а вторая ‑ два.
Тип 4 ‑ прерывание по команде into. Это ловушка. Возникает, если выполняется команда into и флаг переполнения of установлен.
Тип 5 ‑ выход за границы массива. Может возникнуть только при выполнении команды bound. Команда задает три операнда, два в памяти и один в регистре. Операнды в памяти рассматриваются как верхняя и нижняя границы некоторого массива, а операнд в регистре ‑ как индекс внутри массива. МП проверяет, находится ли этот индекс внутри заданных границ. Если находится, МП переходит к следующей команде, если нет ‑ генерируется прерывание типа 5. Этот особый случай является нарушением.
Тип 6 ‑ неверный код операции. Возникает при неправильном использовании префикса lock, при попытке выполнить в реальном режиме команду, допустимую только в защищенном режиме, при попытке выполнить ММХ – команду на процессоре, который такие команды не поддерживает и т.д. Это нарушение.
Тип 7 ‑ устройство недоступно. Под устройством здесь понимается арифметический сопроцессор. Возникает при попытке выполнить команду сопроцессора или ММХ ‑ команду при ЕМ = 1 или TS = 1 (в регистре cr0). Это нарушение.
Тип 8 ‑ двойная ошибка. Это авария. Код ошибки равен нулю. Возможна ситуация, когда при вызове обработчика какого-либо особого случая происходит еще один особый случай. Например, сегмент, в котором расположен этот обработчик, в ОП отсутствует. Чаще всего МП может обработать оба подряд возникших особых случая последовательно, но иногда это оказывается невозможным. В последнем случае МП генерирует прерывание типа 8 ‑ двойная ошибка. Для того чтобы МП мог отличить двойную ошибку от двух последовательно идущих особых случаев, он делит все особые случаи на три группы: легкие (benign) (типы 1‑7, 9, 16‑18, все программные и все внешние прерывания), тяжелые (contributory) (типы 0 и 10‑13) и страничные (page) (тип 14). Два подряд тяжелых случая, или страничный и тяжелый случаи, или два подряд страничных нарушения и приводят к двойной ошибке. Если при вызове обработчика двойной ошибки возникает третий особый случай (например, переполнение стека), МП генерирует цикл отключения.
Тип 9 ‑ зарезервирован (кроме МП 386).
Тип 10 ‑ недействительный сегмент TSS. В реальном режиме не возникает. Сегмент TSS считается недействительным в достаточно многих случаях. Например, если его размер меньше 104 байт. Этот особый случай является нарушением и для него генерируется код ошибки (с его помощью можно понять, что же конкретно произошло).
Тип 11 ‑ не присутствующий сегмент (кроме сегмента стека). В реальном режиме не возникает. Нарушение есть код ошибки. Возникает при обращении к дескриптору, у которого бит Р установлен в 0.
Тип 12 ‑ нарушение стека. Как и следует из названия, это нарушение. Возникает, если стековая операция выводит за заданные в теневой части регистра ss размеры стека, либо сегмент стека, к которому мы обращаемся, помечен как не присутствующий в ОП. Код ошибки есть.
Тип 13 ‑ нарушение общей защиты. Это нарушение. Код ошибки есть и, если не связан с дескриптором, равен нулю. Причин возникновения этого особого случая очень много (не менее тридцати) и они очень разные. Фирма свела в этот тип все причины прерываний, не вошедшие в другие типы. Перечислим лишь некоторые возможные причины этого особого случая:
- эффективный адрес выводит за заданные размеры сегмента ( кроме сегмента стека, для него тип 12);
- длина команды больше 15 байт;
- попытка включить в реальном режиме страничный механизм;
- нарушены атрибуты сегмента;
- нарушены права доступа к сегменту и т.д.
Тип 14 ‑ страничное нарушение ( отказ страницы). В реальном режиме не возникает. Может возникнуть только при включенном страничном механизме. Вызывается этот особый случай следующими причинами:
- таблица или страница не присутствует в ОП (в PDE или PTE бит Р = 0);
- нарушены права доступа к странице.
Нарушение, код ошибки есть и имеет специфический формат, приведенный на рис. 3.42 .
|
Резерв |
U/S |
R/W |
P |
Рис. 3.42
Кроме того, при страничном нарушении МП автоматически загружает «виноватый» линейный адрес в регистр CR2.
Тип 15 ‑ зарезервирован.
Тип 16 ‑ ошибка сопроцессора. Хотя этот особый случай относится к нарушениям, рестарт «виноватой» команды здесь невозможен. Связано это с тем что такое прерывание генерируется не во время выполнения «виноватой» команды, а в начале выполнения следующей команды сопроцессора.
Тип 17 ‑ контроль выравнивания. Появился в МП 486. Возникает, если флаг АС = 1, бит АМ = 1, текущей CPL = 3 и обращаемся к не выровненным данным. Нарушение, код ошибки равен нулю.
Тип 18 ‑ аппаратный сбой. Авария. Введен, начиная с Pentium. Является модельно-зависимым. Причина сбоя возвращается в регистрах MSR. Если бит МСЕ в регистре cr4 установлен в единицу, то при сбое вызывается обработчик, если же МСЕ = 0, то процессор просто переходит в состояние отключения.
Тип 19 ‑ нарушение в SSE команде. Введен, начиная с Pentium III. Является модельно зависимым.
3.27. Переключение из защищенного режима в реальный
При переключении из защищенного режима в реальный программист должен выполнить примерно следующие действия.
1. Если включен страничный механизм:
- перейти к странице с тождественным отображением адресов, т.е. к странице, для которой Ал = Аф; если этого не сделать, то после выключения страничного механизма можно оказаться в самом неожиданном месте памяти;
- выключить страничный механизм (сбросить бит PG в 0);
- обнулить регистр cr3, при этом автоматически очистится буфер TLB.
2. Обеспечить загрузку в теневую часть cs предела сегмента кода, равного 64 Кбайта.
3. Обеспечить загрузку в теневые части остальных сегментных регистров: предел равен 64 Кбайта, G = 0, D = 0, P = 1.
4. Запретить внешние прерывания.
5. Сбросить бит РЕ. После этого мы уже в реальном режиме.
6. Рекомендуется (для МП 386 и МП 486) первой командой после переключения ставить команду jmp far на следующую команду программы. Эта команда заносит правильное значение в регистр cs и очищает очередь от команд защищенного режима.
7. Восстановить таблицу прерываний реального режима и загрузить ее начальный адрес в idtr.
8. Задать правильные значения в остальных сегментных регистрах.
9. Разрешить внешние прерывания.
Эта схема действий рассчитана на самый сложный случай. В конкретной ситуации выполнение некоторых пунктов может оказаться необязательным. В простейшем случае оказывается достаточно сбросить бит PE.
3.28. Формат машинной команды
Формат машинной команды 32-разрядного процессора приведен на рис. 3.43. Каждый прямоугольник обозначает поле. Сверху поля указано, сколько байт может занимать это поле. Например, поле кода операций (КОП) занимает либо один, либо два байта. Любое из полей (кроме КОП) в конкретной команде может отсутствовать. Префиксы, если они есть, располагаются в младших байтах команды, а поле DATA (если оно есть) занимает старшие байты. Далее приведем назначения полей.
|
0/1 |
0/1 |
0/1 |
0/1 |
|||||||||||||||||||||||
|
Префикс команды |
Префикс размера операнда |
Префикс размера адреса |
Префикс замены сегмента |
|||||||||||||||||||||||
|
1/2 |
0/1 |
0/1 |
0/1/2/4 |
0/1/2/4 |
||||||||||||||||||||||
|
КОП |
постбайт |
SIB |
Disp. |
data |
||||||||||||||||||||||
Рис. 3.43
Префикс команды. Это либо префикс rep, либо префикс lock, который может ставить перед командой программист.
Префикс размера операнда. Вместе с битом D в дескрипторе, загруженном в теневую часть cs, определяет размерность используемых в команде операндов. Если этот префикс есть и D = 0 или если этого префикса нет и D = 1, то команда работает с 32-разрядными операндами. В двух противных случаях команда работает с 16-разрядными операндами. Префикс размера операнда имеет значение 66h.
Префикс размера адреса (67h). Аналогичен предыдущему префиксу, но определяет размерность (16-или 32-разрядный) вырабатываемого командой Аэф.
Префикс замены сегмента. Напрямую задает сегментный регистр, участвующий в формировании Аф. Например, mov cs:[200h], al.
Отметим, что порядок следования префиксов значения не имеет, т.е. например, префикс замены сегмента может стоять перед префиксом команды.
Код операции (КОП). Чаще всего это поле имеет размер один байт и формат, приведенный на рис. 3.44.
| КОП | W |
Рис. 3.44
Бит W определяет размерность операндов. При W = 0 ‑ 8-разрядный, при W = 1 ‑ 16- или 32-разрядный.
Постбайт имеет формат, приведенный на рис. 3.45.
![]()
Рис. 3.45
Поля reg и r/m задают два операнда в двухоперандных командах. При этом поле reg задает операнд в регистре, а поле r/m ‑ в регистре или в памяти. В однооперандных командах или в двухоперандных, где один операнд задан непосредственно (в поле data), поле reg оказывается не нужным и используется для расширения кода операции. Если поле reg используется для задания операнда, то оно трактуется в соответствии с табл. 3.16.
Аналогично трактуется поле r/m при md = 11. При других значениях md вместе с r/m задает алгоритм формирования Аэф. При этом для 16- и для 32-разрядного Аэф эти алгоритмы различны. Для 16-ти разрядного Аэф алгоритм его вычисления определяется в соответствии с табл. 3.17.
Таблица 3.16
|
Reg |
w = 0 |
w = 1 |
|
000 |
AL |
(E)AX |
|
001 |
CL |
(E)CX |
|
010 |
DL |
(E)DX |
|
011 |
BL |
(E)BX |
|
100 |
AH |
(E)SP |
|
101 |
CH |
(E)BP |
|
110 |
DH |
(E)SI |
|
111 |
BH |
(E)DI |
Таблица 3.17
|
r/m |
md = 00 |
md = 01 |
md = 10 |
|
000 |
BX+SI |
BX+SI+disp8 |
BX+SI+disp16 |
|
001 |
BX+DI |
BX+DI+disp8 |
BX+DI+disp16 |
|
010 |
BP+SI |
BP+SI+disp8 |
BP+SI+disp16 |
|
011 |
BP+DI |
BP+DI+disp8 |
BP+DI+disp16 |
|
100 |
SI |
SI+disp8 |
SI+disp16 |
|
101 |
DI |
DI+disp8 |
DI+disp16 |
|
110 |
disp16 |
BP+disp8 |
BP+disp16 |
|
111 |
BX |
BX+disp8 |
BX+disp16 |
В табл. 3.17 disp8 и disp16 соответственно 8- и 16-разрядное смещение, заданное в поле disp команды. Из табл. 3.17 следует, что допустима команда mov [bx], al и недопустимы команды mov [ax], cx и mov [si+di], dx.
Алгоритм формирования 32-разрядного Аэф показан в табл. 3.18.
Таблица 3.18
|
r/m |
md = 00 |
md = 01 |
md = 10 |
|
000 |
EAX |
EAX+disp8 |
EAX+disp32 |
|
001 |
ECX |
ECX+disp8 |
ECX+disp32 |
|
010 |
EDX |
EDX+disp8 |
EDX+disp32 |
|
011 |
EBX |
EBX+disp8 |
EBX+disp32 |
|
100 |
Аэф задается байтом SIB |
SIB и disp8 |
SIB и disp32 |
|
101 |
disp32 |
EBP+disp8 |
EBP+disp32 |
|
110 |
ESI |
ESI+disp8 |
ESI+disp32 |
|
111 |
EDI |
EDI+disp8 |
EDI+disp32 |
Байт SIB имеет формат, представленный на рис. 3.46.
При наличии байта SIB Аэф рассчитывается по формуле:
Аэф = 2SCALE×INDEX+BASE+DISP.
Поле INDEX трактуется в соответствии с табл. 3.19.
Поле BASE трактуется в соответствии с табл. 3.20.
![]()
Рис. 3.46
Таблица 3.19
|
000 |
EAX |
|
001 |
ECX |
|
010 |
EDX |
|
011 |
EBX |
|
100 |
нет индекса (scale = 0) |
|
101 |
EBP |
|
110 |
ESI |
|
111 |
EDI |
Особый случай: если md = 00, то в качестве BASE берется disp32 из поля disp, если md = 01 или md = 10, то в качестве BASE берется содержимое EBP.
Из вышеизложенного видно, что в случае 32-разрядного Аэф возможных вариантов команд значительно больше, чем при 16-разрядном Аэф (за счет байта SIB).
Таблица 3.20
|
000 |
EAX |
|
001 |
ECX |
|
010 |
EDX |
|
011 |
EBX |
|
100 |
ESP |
|
101 |
Особый случай |
|
110 |
ESI |
|
111 |
EDI |
Например, возможна команда mov eax, [2*eax+eax+7]. В шестнадцатеричной системе счисления эта команда имеет следующее представление:
66 67 8B 44 40 07,
где 66 ‑ префикс размера операнда, 67 ‑ префикс размера адреса, 8В ‑ КОП, 44 ‑ постбайт, 40 ‑ SIB, 07 ‑ disp8.
3.29. Команда CPUID
Команда CPUID документирована, начиная с Pentium, хотя реально появилась в старших моделях МП 486. Прикладная программа может определить доступность этой команды, если ей удается менять значение флага ID (21-й бит регистра ef). Надо отметить, что эта проверка имеет смысл только для МП 486, поскольку более ранние процессоры эту команду однозначно не поддерживают, а более поздние ‑ однозначно поддерживают.
Старые трансляторы, которыми пользуется в реальной жизни, эту команду «не понимают», потому ее приходится задавать в программе в машинных кодах:
| db 0fh |
; это CPUID |
| db 0a2h |
Команда может использовать несколько функций, задаваемых в регистре еах. Результаты возвращаются в регистрах еах, евх, есх и еdx. При этом имеются два набора функций, задаваемых в еах:
- первый набор (еах = 0, 1, 2, или 3) возвращает базовую информацию о процессоре;
- второй набор (значение в еах лежит в диапазоне от 80000000h до 80000004h) возвращает расширенную информацию о процессоре.
При этом различные процессоры поддерживают различные подмножества этих наборов (см. табл. 3.21).
Таблица 3.21
| Семейство |
Базовый набор |
Расширенный набор |
| Поздние 486 и Pentium |
Максимальный ЕАХ = 1 |
Не поддерживается |
| Pentium Pro, Pentium IIи Celeron |
Максимальный ЕАХ = 2 |
Не поддерживается |
|
Pentium III |
Максимальный ЕАХ = 3 |
Не поддерживается |
|
Pentium IV |
Максимальный ЕАХ = 2 |
ЕАХ от 80000000h до 80000004h |
Но и без табл. 3.21 всегда можно определить набор функций, который поддерживает неизвестный нам процессор. Делается это следующим образом:
mov eax, 0
cpuid.
После этого в регистре al вернется максимальная функция базового набора для данного процессора, например, для Pentium вернется 1.
Аналогично можно определить максимальное число и для расширенного набора:
mov eax, 80000000h
cpuid.
После этого в регистре eax вернется максимальное для данного процессора число для расширенного набора. Если вернулось число, меньшее 80000000h, то расширенный набор не поддерживается.
Если в ЕАХ загрузить число, превышающее максимально допустимое для данного процессора, будет выполнена максимально возможная функция для базового набора. Например, для Pentium IV при ЕАХ = 5 будет выполнена функция ЕАХ = 2 и при ЕАХ = 80000005h будет выполнена та же функция ЕАХ = 2.
Далее рассмотрим сведения о процессоре, возвращаемые командой CPUID.
Функция 0 (ЕАХ = 0).
В ЕАХ возвращается максимальный номер функции базового набора, разрешенный для данного процессора.
В остальных регистрах возвращаются сведения о производителе. Например:
|
EBX |
ASCII ‘u’ |
ASCII’n’ |
ASCII’e’ |
ASCII’G’ |
|
EDX |
ASCII’I’ |
ASCII’e’ |
ASCII’n’ |
ASCII’i’ |
|
ECX |
ASCII’l’ |
ASCII’e’ |
ASCII’t’ |
ASCII’n’ |
Это означает GenuineIntel («Настоящий Intel») (47h 65h 6eh 75h 69h 6eh 65h 49h 6eh 74h 65h 6ch).
Для AMD возвращается AuthenticAMD («Натуральный AMD»).
Функция 1 (EAX = 1).
В ЕАХ возвращается сигнатура процессора:
- биты 3‑0 – степпинг (Stepping ID);
- биты 7‑4 – модель (Model Number);
- биты 11‑8 – семейство (Family Code);
- биты 13‑12 – тип (Processor Type);
- биты 15‑14 – резерв;
- биты 19‑16 – расширение модели (Extended Model);
- биты 27‑20 – расширение семейства (Extended Family);
- биты 31‑28 – резерв.
Основным здесь является поле Семейство. В нем возвращается номер семейства процессора. Например, для МП 486 в этом поле вернется 4, для Pentium – 5, для P6 – 6 и для Pentium IV ‑ 0fh. (К Р6 относятся Pentium Pro, Pentium II, Pentium III и Celeron). Поле Расширение семейства должно использоваться совместно с полем Семейство, но в настоящее время оно еще не используется, так как даже для Pentium IV в этом поле возвращаются нули. Поле Модель (и совместно с ним поле Расширение модели, в котором на сегодняшний день также всегда возвращаются нули) позволяет определить номер модели внутри семейства, а поле Степпинг ‑ номер варианта внутри модели. Поле Тип трактуется следующим образом:
00 Original OEM processor (обычный процессор);
01 OverDrive ® processor;
10 Dual processor (поддерживает двухпроцессорные конфигурации);
11 Intel reserved (Do not use).
Существуют справочные таблицы, в основном позволяющие по сигнатуре однозначно идентифицировать процессор. Например: Семейство ‑ 0101, Модель – 0100, Тип – 01, Степпинг – хххх, остальные поля – нули, это Pentium OverDrive процессор с ММХ-технологией. Однако имеется ряд случаев, когда по сигнатуре невозможно однозначно идентифицировать процессор. В частности процессоры Pentium II 5-й модели, Pentium II Xeon 5-й модели и Celeron 5-й модели имеют одинаковую сигнатуру. Поэтому для их более точной идентификации приходится исследовать наличие и размер L2-кэша (CPUID при ЕАХ = 2). И даже в этом случае невозможно различить Pentium II и Xeon с кэшем на 512 Кбайт.
Для Pentium III, поддерживающего PSN (бит 18 в табл. 3.23), сигнатура одновременно представляет собой старшие 32 бита 96-битного сериального номера процессора (Serial Number). Младшие 64 бита этого номера возвращаются командой CPUID при ЕАХ = 3.
Например (для ЕАХ = 1):
МП 486 возвратил в ЕАХ = 480h,
5x86 ‑ EAX = 4F4h,
Pentium ‑ EAX = 543h,
Pentium II – EAX = 633h.
Естественно и эти, и приводимые ниже результаты были получены на конкретных моделях процессоров. Для других моделей цифры могут быть другими.
В ЕВХ (при ЕАХ = 1), как правило, возвращаются нули. Однако, начиная с Pentium III модель 8 (а возможно и ранее), информация, возвращаемая в этом регистре, имеет следующий смысл:
- биты 7‑0 ‑ идентификатор марки процессора (Brand ID);
- биты 15‑8 ‑ размер строки кэша (chunks);
- биты 23‑16 ‑ резерв;
- биты 31‑24 ‑ физический идентификатор встроенного в процессор контроллера прерываний APIC (APIC ID).
Поле BRAND ID (если там не нули) упрощает идентификацию процессора (см. табл. 3.22).
Поле CHUNKS задает размер строки кэша (число в поле надо умножить на 8), который будет использоваться в команде CLFLUSH, если последняя в процессоре поддерживается.
Таблица 3.22
|
Brand ID |
CPU |
|
00h |
Не поддерживается |
|
01h |
Intel® Celeron™ processor |
|
02h |
Intel® Pentium® III processor |
|
03h |
Intel® Pentium® III Xeon™ processor |
|
04h |
Intel® Pentium® III processor |
|
08h |
Intel® Pentium® 4 processor |
|
09h |
Intel® Xeon™ processor |
|
Другие |
Резерв |
В EDX (при ЕАХ = 1) возвращаются особенности, которые поддерживает данный процессор. Смотри табл. 3.23.
Таблица 3.23
|
№ БИТА |
ИМЯ |
ОПИСАНИЕ |
| Бит 0 = 1 |
FPU |
Есть встроенный сопроцессор |
| Бит 1 = 1 |
VME |
Поддерживается VME |
| Бит 2 = 1 |
DE |
Поддерживается DE |
| Бит 3 = 1 |
PSE |
Поддерживается PSE |
| Бит 4 = 1 |
TSC |
Поддерживается TSC (команда RDTSC) |
| Бит 5 = 1 |
MSR |
Поддерживается MSR (команды RDMSR и WRMSR) |
| Бит 6 = 1 |
PAE |
Поддерживается РАE |
| Бит 7 = 1 |
MCE |
Поддерживается MСE |
| Бит 8 = 1 |
CXB |
Поддерживается команда СМРХСНG |
| Бит 9 = 1 |
APIC |
Есть встроенный APIC |
| Бит 10 | Резерв | |
| Бит 11 = 1 |
SEP |
Поддерживаются команды SYSENTER и SYSEXIT |
| Бит 12 = 1 |
MTRR |
Поддерживается MTRR |
| Бит 13 = 1 |
PGE |
Поддерживается PGE |
| Бит 14 = 1 |
MCA |
Поддерживается MGE_CAP (machine check global capability) MSR |
| Бит 15 = 1 |
CMOV |
Поддержка команд CMOV cc (mov and compare), cc‑условие |
| Бит 16 = 1 |
PAT |
Поддерживается РАТ (Page Attribute Table) |
| Бит 17 = 1 |
PSE-36 |
Поддерживается PSE-36 |
| Бит 18 = 1 |
PSN |
Процессор имеет сериальный номер |
| Бит 19 = 1 |
CLFSH |
Поддерживается команда CLFLUSH |
| Бит 20 | Резерв | |
| Бит 21 = 1 |
DS |
Поддерживается возможность записи отладочной информации и «истории переходов» в созданный в памяти резидентный буфер |
| Бит 22 = 1 |
ACPI |
Поддерживается контроль температу-ры и регулировка производительности процессора под управлением ПО |
| Бит 23 = 1 |
MMX |
Поддерживается ММХ |
| Бит 24 = 1 |
FXSR |
Поддерживаются команды FXRSTOR и FXRSAVE |
| Бит 25 = 1 |
SSE |
Поддерживается набор команд SSE |
| Бит 26 = 1 |
SSE2 |
Поддерживается набор команд SSE2 |
| Бит 27 = 1 |
SS |
Самослежение процессора за собственными кэшами (Self-Snoop) |
| Бит 28 | Резерв | |
| Бит 29 = 1 |
TM |
Встроенный аппаратный контроль температуры. |
| Биты 31-30 | Резерв |
Например:
5х86 вернул EDX = 1,
486 ‑ ЕDX = 3,
Pentium c MMX ‑ EDX = 8001bfh,
Pentium II – EDX = 80fbffh.
Функция 2 (EAX = 2).
Данная функция возвращает сведения о всех видах кэш-памяти процессора. В al возвращается число, задающее, сколько раз надо запустить CPUID с ЕАХ = 2 для получения полных сведений об имеющихся кэшах. Реально в al всегда возвращается 1. В остальных байтах регистров EAX, EBX, EDX и ECX возвращаются дескрипторы кэшей. Список дескрипторов проведен в табл. 3.24.
Таблица 3.24
|
Дескриптор |
Описание |
| 00h | Пустой |
| 01h | TLB команд 4 Kбайт; 4 w.s., 32 строки |
| 02h | TLB команд 4 Мбайт; fully., 2 строки |
| 03h | TLB данных 4 Kбайт; 4 w.s., 64 строки |
| 04h | TLB данных 4 Мбайт; 4 w.s., 8 строк |
| 06h | Кэш команд, 8 Кбайт; 4ws, строка-32байта |
| 08h | Кэш команд, 16 Кбайт; 4ws, строка-32байта |
| 0ah | Кэш данных, 8 Кбайт;2ws, строка-32байта |
| 0ch | Кэш данных, 16 Кбайт; 4ws, строка-32байта |
| 40h | Нет L2 кэша для P6 или L3 для Pentium IV |
| 41h | Кэш L2, 128 Кбайт; 4ws, строка-32байта |
| 42h | Кэш L2, 256 Кбайт; 4ws, строка-32байта |
| 43h | Кэш L2, 512 Кбайт; 4ws, строка-32байта |
| 44h | Кэш L2, 1 Mбайт; 4ws, строка-32байта |
| 45h | Кэш L2, 2 Mбайт; 4ws, строка-32байта |
| 50h | Общий TLB команд, fully, 64 строки |
| 51h | Общий TLB команд, fully, 128 строк |
| 52h | Общий TLB команд, fully, 256 строк |
| 5bh | Общий TLB данных, fully, 64 строки |
| 5ch | Общий TLB данных, fully, 128 строк |
| 5dh | Общий TLB данных, fully, 256 строк |
| 66h | Кэш данных, 8 Кбайт ;4ws, строка‑64 байта |
| 67h | Кэш данных, 16 Кбайт ;4ws, строка‑64 байта |
| 68h | Кэш данных, 32 Кбайт ;4ws, строка‑64 байта |
| 70h | Trace-кэш команд 8ws, 12K mops |
| 71h | Trace-кэш команд 8ws, 16K mops |
| 72h | Trace-кэш команд 8ws, 32K mops |
| 79h | Кэш L2, 128 Кбайт ;8ws, строка‑64байта |
| 7ah | Кэш L2, 256 Кбайт ;8ws, строка‑64байта |
| 7bh | Кэш L2, 512 Кбайт ;8ws, строка‑64байта |
| 7ch | Кэш L2, 1 Mбайт ;8ws, строка‑64байта |
| 82h | Кэш L2, 256 Kайт ;8ws, строка‑32байта |
| 83h | Кэш L2, 512 Kбайт ;8ws, строка‑32байта |
| 84h | Кэш L2, 1 Mбайт ;8ws, строка‑32байта |
| 85h | Кэш L2, 2 Mбайт ;8ws, строка‑32байта |
В табл. 3.24 4ws ‑ частично ассоциативный кэш с четырьмя строками на горизонтали. (4 way-set), fully – полностью ассоциативный кэш, «общий TLB» – используемый и для обычных и для больших страниц, trace-кэш микроопераций (декодированных команд) введен в архитектуру Pentium IV. Например, Pentium II вернул:
EAX = 03020101h,
EBX = 0,
ECX = 0,
EDX = 0c040843h.
Intel приводит пример того, что возвращает Pentium IV:
EAX = 665b5001h,
EBX = 0,
ECX = 0,
EDX = 007a7040h.
Функция 3 (ЕАX = 3).
ЕАХ и ЕВХ зарезервированы. В ЕСХ и ЕDX возвращаются 64 младших бита 96-битного сериального номера процессора (старшие 32 бита этого номера берутся из сигнатуры, см. ЕАХ = 1). В ЕСХ биты 31‑0, а в EDX биты 63‑32.
Расширенный набор функций.
ЕАХ = 80000000h.
В ЕАХ – максимальное значение расширенного набора. EBX, ECX, EDX – зарезервированы.
ЕАХ = 800000002h – 80000004h.
B EAX, EBX, ECX, EDX последовательно возвращается Маркерная строка (Brand String) процессора в формате ASCIIZ. Строка состоит из 47 ASCII-символов и завершается (48-м) нулем. Она идентифицирует процессор и содержит его максимальную рабочую частоту. Расширенный набор доступен, начиная с Pentium IV.
Intel при определении процессора предлагает следующую последовательность действий.
1. Запустить CPUID при ЕАХ = 80000000h. Если в ЕАХ вернулось большее число (чем 80000000h), то прочесть Маркерную строку и определить процессор. Если вернулось меньшее число, то перейти к следующему пункту.
2. Запустить CPUID при ЕАХ = 1. Если bl>0, то есть BRAND ID и им пользуемся для определения процессора.
3. Если bl = 0, используем сигнатуру процессора.
Этот алгоритм пригоден, если уверены в том, что программа не будет запускаться на процессорах ниже Pentium. Если это не так, то перед тем как запускать CPUID, придется стандартным образом поработать с регистром флагов. В табл. 3.25 приводятся коротко все описанные выше сведения о команде CPUID.
Таблица 3.25
|
Функция в ЕАХ |
Информация о процессоре |
|
Базовая информация |
|
|
0 |
ЕАХ ‑Максимальное значение функции для базового набора
ЕВХ ‑ Genu ЕСХ ‑ ntel EDX ‑ ineI |
|
1 |
ЕАХ ‑ Сигнатура процессора или, если установлен бит 18 в особенностях, старшие разряды сериального номера. ЕВХ ‑ Brand ID, chunks, APIC ID ЕСХ ‑ Резерв EDX ‑ Особенности процессора |
|
2 |
ЕАХ, ЕВХ, ЕСХ, EDX Дескрипторы кэшей |
|
3 |
ЕАХ, ЕВХ ‑ Резерв ЕСХ ‑ Биты 31-0 сериального номера EDX ‑ Биты 63-32 сериального номера |
|
Расширенная информация |
|
|
80000000h |
ЕАХ ‑ Максимальное значение функции для расширенного набора
ЕВХ, ЕСХ, EDX ‑ Резерв |
|
80000001h |
ЕАХ ‑ Расширение сигнатуры и битов особенностей (пока зарезервир.)
ЕВХ, ЕСХ, EDX ‑ Резерв |
|
80000002h |
ЕАХ ‑ Маркерная строка ЕВХ ЕСХ, EDX ‑ Продолжение маркерной строки |
|
80000003h |
ЕАХ, ЕВХ, ЕСХ, EDX ‑ Продолжение маркерной строки |
|
80000004h |
ЕАХ, ЕВХ, ЕСХ, EDX ‑ Продолжение маркерной строки |