7.1. Классификация корректирующих кодов
7.2. Принципы помехоустойчивого кодирования
7.1. Классификация корректирующих кодов
В каналах с помехами эффективным средством повышения достоверности передачи сообщений является помехоустойчивое кодирование. Оно основано на применении специальных кодов, которые корректируют ошибки, вызванные действием помех. Код называется корректирующим, если он позволяет обнаруживать или обнаруживать и исправлять ошибки при приеме сообщений. Код, посредством которого только обнаруживаются ошибки, носит название обнаруживающего кода. Исправление ошибки при таком кодировании обычно производится путем повторения искаженных сообщений. Запрос о повторении передается по каналу обратной связи. Код, исправляющий обнаруженные ошибки, называется исправляющим, кодом. В этом случае фиксируется не только сам факт наличия ошибок, но и устанавливается, какие кодовые символы приняты ошибочно, что позволяет их исправить без повторной передачи. Известны также коды, в которых исправляется только часть обнаруженных ошибок, а остальные ошибочные комбинации передаются повторно.
Для того чтобы «од обладал корректирующими способностями, в кодовой последовательности должны содержаться дополнительные (избыточные) символы, предназначенные для корректирования ошибок. Чем больше избыточность кода, тем выше его корректирующая способность.
Помехоустойчивые коды могут быть построены с любым основанием. Ниже рассматриваются только двоичные коды, теория которых разработана наиболее полно.
В настоящее время известно большое количество корректирующих кодов, отличающихся как принципами построения, так и основными характеристиками. Рассмотрим их простейшую классификацию, дающую представление об основных группах, к которым принадлежит большая часть известных кодов [12]. На рис. 7.1 показана схема, поясняющая классификацию, проведенную по способам построения корректирующих кодов.
Все известные в настоящее время коды могут быть разделены
на две большие группы: блочные и непрерывные. Блочные коды характеризуются тем, что последовательность передаваемых символов разделена на блоки операции кодирования и декодирования в каждом блоке производятся отдельно. Отличительной особенностью непрерывных кодов является то, что первичная последовательность символов, несущих информацию, непрерывно преобразуется по определенному закону в другую последовательность, содержащую избыточное число символов. Здесь процессы кодирования и декодирования не требуют деления кодовых символов на блоки.
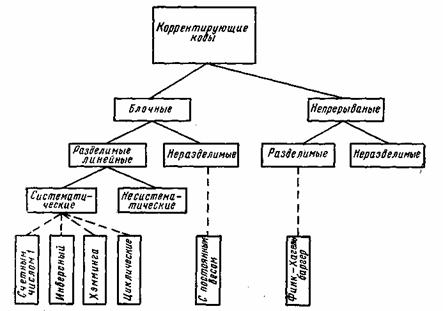
Рис. 7.1. Классификация корректирующих кодов
Разновидностями как блочных, так и непрерывных кодов являются разделимые и неразделимые коды. В разделимых кодах всегда можно выделить информационные символы, содержащие передаваемую информацию, и контрольные (проверочные) символы, которые являются избыточными и служат 'исключительно для коррекции ошибок. В неразделимых кодах такое разделение символов провести невозможно.
Наиболее многочисленный класс разделимых кодов составляют линейные коды. Основная их особенность состоит в том, что контрольные символы образуются как линейные комбинации информационных символов.
В свою очередь, линейные коды могут быть |разбиты на два подкласса: систематические и несистематические. Все двоичные систематические коды являются групповыми. Последние характеризуются принадлежностью кодовых комбинаций к группе, обладающей тем свойством, что сумма по модулю два любой пары комбинаций снова дает комбинацию, принадлежащую этой группе. Линейные коды, которые не могут быть отнесены к подклассу систематических, называются несистематическими. Вертикальными прямоугольниками на схеме рис. 7.1 представлены некоторые конкретные коды, описанные в последующих параграфах.
7.2. Принципы помехоустойчивого кодирования
В теории помехоустойчивого кодирования важным является вопрос об использовании избыточности для корректирования возникающих при передаче ошибок. Здесь удобно рассмотреть блочные моды, в которых всегда имеется возможность выделить отдельные кодовые комбинации. Напомним, что для равномерных кодов, которые в дальнейшем только и будут изучаться, число возможных комбинаций равно M=2n, где п — значность кода. В обычном некорректирующем коде без избыточности, например в коде Бодо, число комбинаций М выбирается равным числу сообщений алфавита источника М0и все комбинации используются для передачи информации. Корректирующие коды строятся так, чтобы число комбинаций М превышало число сообщений источника М0. Однако в.этом случае лишь М0комбинаций из общего числа используется для передачи информации. Эти комбинации называются разрешенными, а остальные М—М0комбинаций носят название запрещенных. На приемном конце в декодирующем устройстве известно, какие комбинации являются разрешенными и какие запрещенными. Поэтому если переданная разрешенная комбинация в результате ошибки преобразуется в некоторую запрещенную комбинацию, то такая ошибка будет обнаружена, а при определенных условиях исправлена. Естественно, что ошибки, приводящие к образованию другой разрешенной комбинации, не обнаруживаются.
Различие между комбинациями равномерного кода принято характеризовать расстоянием, равным числу символов, которыми отличаются комбинации одна от другой. Расстояние d![]() между двумя комбинациями
между двумя комбинациями ![]() и
и ![]() определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
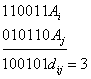
Для любого кода d![]()
![]() . Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
. Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
Расстояние между комбинациями ![]() и
и ![]() условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций
условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций ![]() и
и ![]() , разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация
, разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация ![]() преобразовалась в другую разрешенную комбинацию
преобразовалась в другую разрешенную комбинацию ![]() , должно исказиться d символов.
, должно исказиться d символов.
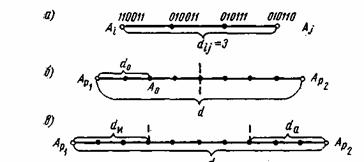
Рис. 7.2. Геометрическое представление разрешенных и запрещенных кодовых комбинаций
При искажении меньшего числа символов комбинация ![]() перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
![]() (7.1)
(7.1)
Если g>d, то некоторые ошибки также обнаруживаются. Однако полной гарантии обнаружения ошибок здесь нет, так как ошибочная комбинация ib этом случае может совпасть с какой-либо разрешенной комбинацией. Минимальное кодовое расстояние, при котором обнаруживаются любые одиночные ошибки, d=2.
Процедура исправления ошибок в процессе декодирования сводится к определению переданной комбинации по известной принятой. Расстояние между переданной разрешенной комбинацией и принятой запрещенной комбинацией d0 равно кратности ошибок g. Если ошибки в символах комбинации происходят независимо относительно друг друга, то вероятность искажения некоторых g символов в n-значной комбинации будет равна:
![]() (7.2)
(7.2)
где ![]() — вероятность искажения одного символа. Так как обычно
— вероятность искажения одного символа. Так как обычно ![]() <<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация
<<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация ![]() (см.рис.7.2б), тогда принимается решение, что была передана комбинация
(см.рис.7.2б), тогда принимается решение, что была передана комбинация ![]() . Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
. Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
![]() (7.3)
(7.3)
Минимальное значение d, при котором еще возможно исправление любых одиночных ошибок, равно 3.
Возможно также построение таких кодов, в которых часть ошибок исправляется, а часть только обнаруживается. Так, в соответствии с рис. 7.2в ошибки кратности ![]() исправляются, а ошибки, кратность которых лежит в пределах
исправляются, а ошибки, кратность которых лежит в пределах ![]() только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах
только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах ![]() , то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А
, то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А![]() вместо A
вместо A![]() или наоборот.
или наоборот.
Существуют двоичные системы связи, в которых решающее устройство выдает, кроме обычных символов 0 и 1, еще так называемый символ стирания ![]() . Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов
. Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов ![]() оказалось равным gc, причем
оказалось равным gc, причем
![]() (7.4)
(7.4)
а остальные символы приняты без ошибок, то такая комбинация полностью восстанавливается. Действительно, для восстановления всех символов ![]() необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок
необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок ![]() , то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
, то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
Если ![]() , то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
, то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
Таким образом, при фиксированном кодовом расстоянии максимально возможная кратность корректируемых ошибок достигается в кодах, которые обнаруживают ошибки или .восстанавливают стертые символы. Исправление ошибок представляет собой более трудную задачу, практическое решение которой сопряжено с усложнением кодирующих и декодирующих устройств. Поэтому исправляющие «оды обычно используются для корректирования ошибок малой кратности.
Корректирующая способность кода возрастает с увеличением d. При фиксированном числе разрешенных комбинаций М![]() увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
![]() (7.5)
(7.5)
что, в свою очередь, требует избыточного числа символов r=n—k, где k — количество символов в комбинации кода без избыточности. Можно ввести понятие избыточности кода и количественно определить ее по аналогии с (6.12) как
![]() (7.6)
(7.6)
При независимых ошибках вероятность определенного сочетания g ошибочных символов в n-значной кодовой комбинации выражается ф-лой ((7.2), а количество всевозможных сочетаний g ошибочных символов в комбинации зависит от ее длины и определяется известной формулой числа сочетаний
![]()
Отсюда полная вероятность ошибки кратности g, учитывающая все сочетания ошибочных символов, равняется:
![]() (7.7)
(7.7)
Используя (7.7), можно записать формулы, определяющие вероятность отсутствия ошибок в кодовой комбинации, т. е. вероятность правильного приема
![]()
и вероятность правильного корректирования ошибок
![]()
Здесь суммирование 'Производится по всем значениям кратности ошибок g, которые обнаруживаются и исправляются. Таким образом, вероятность некорректируемых ошибок равна:
![]() (7.8)
(7.8)
Анализ ф-лы (7.8) показывает, что при малой величине Р0и сравнительно небольших значениях п наиболее вероятны ошибки малой кратности, которые и необходимо корректировать в первую очередь.
Вероятность Р![]() , избыточность
, избыточность ![]() и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
Общая задача, которая ставится при создании кода, заключается, в достижении наименьших значений Р![]() и
и ![]() . Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
. Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
В соответствии с общим принципом корректирования ошибок, основанным на использовании разрешенных и запрещенных комбинаций, необходимо сравнивать принятую комбинацию со всеми комбинациями данного кода. В результате М сопоставлений и принимается решение о переданной комбинации. Этот способ декодирования логически является наиболее простым, однако он требует сложных устройств, так как в них должны запоминаться все М комбинаций кода. Поэтому на практике чаще всего используются коды, которые позволяют с помощью ограниченного числа преобразований принятых кодовых символов извлечь из них всю информацию о корректируемых ошибках. Изучению таких кодов и посвящены последующие разделы.
7.3. Систематические коды
Изучение конкретных способов помехоустойчивого кодирования начнем с систематических кодов, которые в соответствии с классификацией (рис. 7.1) относятся к блочным разделимым кодам, т. е. к кодам, где операции кодирования осуществляются независимо в пределах каждой комбинации, состоящей из информационных и контрольных символов.
Остановимся кратко на общих принципах построения систематических кодов. Если обозначить информационные символы буквами с, а контрольные — буквами е, то любую кодовую комбинацию, содержащую k информационных и r контрольных символов, можно представить последовательностью:![]() , где с и е в двоичном коде принимают значения 0 или 1.
, где с и е в двоичном коде принимают значения 0 или 1.
Процесс кодирования на передающем конце сводится к образованию контрольных символов, которые выражаются в виде линейной функции информационных символов:
![]()
![]() (7.9)
(7.9)
Здесь ![]() — коэффициенты, равные 0 или 1, а
— коэффициенты, равные 0 или 1, а ![]() и
и ![]() — знаки суммирования по модулю два. Значения
— знаки суммирования по модулю два. Значения ![]()
![]() выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными" методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации
выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными" методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации ![]()
![]()
![]() образуется по правилу (7.9) вторая группа контрольных символов
образуется по правилу (7.9) вторая группа контрольных символов ![]()
![]()
Затем производится сравнение обеих групп контрольных символов путем их суммирования по модулю два:
![]()
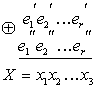 (7.10)
(7.10)
Полученное число X называется контрольным числом или синдромом. С его помощью можно обнаружить или исправить часть ошибок. Если ошибки в принятой комбинации отсутствуют, то все суммы![]()
![]() , а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае
, а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае ![]() , что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
, что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
Для исправления ошибок знание одного факта их возникновения является недостаточным. Необходимо указать номер ошибочно принятых символов. С этой целью каждому сочетанию исправляемых ошибок в комбинации присваивается одно из контрольных чисел, что позволяет по известному контрольному числу определить место положения ошибок и исправить их.
Контрольное число X записывается в двоичной системе, поэтому общее количество различных контрольных чисел, отличающихся от нуля, равно![]()
![]() . Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно
. Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно ![]() . В этом случае должно выполняться условие
. В этом случае должно выполняться условие
![]() (7.11)
(7.11)
Формула (7.11) позволяет при заданном количестве информационных символов k определить необходимое число контрольных символов r, с помощью которых исправляются все одиночные ошибки.
7.4. Код с чётным числом единиц. Инверсионный код
Рассмотрим некоторые простейшие систематические коды, применяемые только для обнаружения ошибок. Одним из кодов подобного типа является код с четным числом единиц. Каждая комбинация этого кода содержит, помимо информационных символов, один контрольный символ, выбираемый равным 0 или 1 так, чтобы сумма единиц в комбинации всегда была четной. Примером могут служить пятизначные комбинации кода Бодо, к которым добавляется шестой контрольный символ: 10101,1 и 01100,0. Правило вычисления контрольного символа можно выразить на
основании (7.9) в следующей форме: ![]() . Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (
. Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (![]() — суммирование по модулю):
— суммирование по модулю):
![]() (7.12)
(7.12)
Это позволяет в декодирующем устройстве сравнительно просто производить обнаружение ошибок путем проверки на четность. Нарушение четности имеет место при появлении однократных, трехкратных и в общем, случае ошибок нечетной кратности, что и дает возможность их обнаружить. Появление четных ошибок не изменяет четности суммы (7.12), поэтому такие ошибки не обнаруживаются. На основании ,(7.8) вероятность необнаруженной ошибки равна:
![]()
![]()
К достоинствам кода следует отнести простоту кодирующих и декодирующих устройств, а также малую .избыточность ![]() , однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
, однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
Значительно лучшими корректирующими способностями обладает инверсный код, который также применяется только для обнаружения ошибок. С принципом построения такого кода удобно ознакомиться на примере двух комбинаций: 11000, 11000 и 01101, 10010. В каждой комбинации символы до запятой являются информационными, а последующие — контрольными. Если количество единиц в информационных символах четное, т. е. сумма этих
символов
![]() (7.13)
(7.13)
равна нулю, то контрольные символы представляют собой простое повторение информационных. В противном случае, когда число единиц нечетное и сумма (7.13) равна 1, контрольные символы получаются из информационных посредством инвертирования, т. е. путем замены всех 0 на 1, а 1 на 0. Математическая форма записи образования контрольных символов имеет вид ![]() . При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е.
. При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е. ![]() , то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c'
, то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c'![]() =1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность:
=1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность: ![]() . Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
. Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
Анализ показывает, что при ![]() наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения
наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения ![]() равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
![]()
Для g>4 вероятность необнаруженных ошибок еще меньше. Поэтому при достаточно малых вероятностях ошибочных символов ро можно полагать, что полная вероятность необнаруженных ошибок ![]()
Инверсный код обладает высокой обнаруживающей способностью, однако она достигается ценой сравнительно большой избыточности, которая, как нетрудно определить, составляет величину ![]() =0,5.
=0,5.
7.5. Коды Хэмминга
К этому типу кодов обычно относят систематические коды с расстоянием d=3, которые позволяют исправить все одиночные ошибки (7.3).
Рассмотрим построение семизначного кода Хэмминга, каждая комбинация которого содержит четыре информационных и триконтрольных символа. Такой код, условно обозначаемый (7.4), удовлетворяет неравенству (7.11) и имеет избыточность ![]()
Если информационные символы с занимают в комбинация первые четыре места, то последующие три контрольных символа образуются по общему правилу (7.9) как суммы:
![]() (7.14)
(7.14)
Декодирование осуществляется путем трех проверок на четность (7.10):
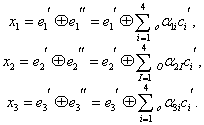 (7.15)
(7.15)
Так как х равно 0 или 1, то всего может быть восемь контрольных чисел Х=х1х2х3: 000, 100, 010, 001, 011, 101, 110 и 111. Первое из них имеет место в случае правильного приема, а остальные семь появляются при наличии искажений и должны использоваться для определения местоположения одиночной ошибки в семизначной комбинации. Выясним, каким образом устанавливается взаимосвязь между контрольными числами я искаженными символами. Если искажен один из контрольных символов: ![]() или
или ![]() , то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
, то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
Таблица 7.1

Порядок присвоения контрольных чисел ошибочным информационным символам может устанавливаться любой, например, как показано в табл. 7.1. Нетрудно показать, что этому распределению контрольных чисел соответствуют коэффициенты ![]() , приведенные в табл. 7.2.
, приведенные в табл. 7.2.
Таблица 7.2
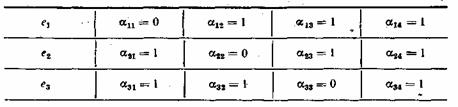
Если подставить коэффициенты ![]() в выражение (7.15), то получим:
в выражение (7.15), то получим:
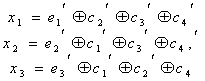 (7.16)
(7.16)
При искажении одного из информационных символов становятся равными единице те суммы х, в которые входит этот символ. Легко проверить, что получающееся в этом случае контрольное число![]() согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов
согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов ![]() . Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются
. Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются ![]() , Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
, Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
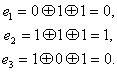
Передаваемая комбинация при этом будет ![]() . Предположим, что принята комбинация — 1001, 010 (искажен символ
. Предположим, что принята комбинация — 1001, 010 (искажен символ ![]() ). Подставляя соответствующие значения в (7.16), получим:
). Подставляя соответствующие значения в (7.16), получим:
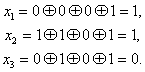
Вычисленное таким образом контрольное число ![]() 110 позволяет согласно табл. 7.1 исправить ошибку в символе.
110 позволяет согласно табл. 7.1 исправить ошибку в символе.
Здесь был рассмотрен простейший способ построения и декодирования кодовых комбинаций, в которых первые места отводились информационным символам, а соответствие между контрольными числами и ошибками определялось таблице. Вместе с тем существует более изящный метод отыскания одиночных ошибок, предложенный впервые самим Хэммингом. При этом методе код строится так, что контрольное число в двоичной системе счисления сразу указывает номер искаженного символа. Правда, в этом случае контрольные символы необходимо располагать среди информационных, что усложняет процесс кодирования. Для кода (7.4) символы в комбинации должны размещаться в следующем порядке: ![]() , а контрольное число вычисляться по формулам:
, а контрольное число вычисляться по формулам:
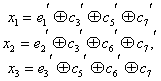 (7.17)
(7.17)
Так, если произошла ошибка в информационном символе с'5 то контрольное число ![]() , что соответствует числу 5 в двоичной системе.
, что соответствует числу 5 в двоичной системе.
В заключение отметим, что в коде (7.4) при появлении многократных ошибок контрольное число также может отличаться от нуля. Однако декодирование в этом случае будет проведено неправильно, так как оно рассчитано на исправление лишь одиночных ошибок.
7.6. Циклические коды
Важное место среди систематических кодов занимают циклические коды. Свойство цикличности состоит в том, что циклическая перестановка всех символов кодовой комбинации ![]() дает другую комбинацию
дает другую комбинацию ![]() также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например,
также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например, ![]()
![]()
![]()
![]() .
.
Комбинации циклического кода, выражаемые двоичными числами, для удобства преобразований обычно определяют в виде полиномов, коэффициенты которых равны 0 или 1. Примером этому может служить следующая запись:
![]()
Помимо цикличности, кодовые комбинации обладают другим важным свойством. Если их представить в виде полиномов, то все они делятся без остатка на так называемый порождающий полином G(z) степени ![]() , где k-значность первичного кода без избыточности, а п-значность циклического кода
, где k-значность первичного кода без избыточности, а п-значность циклического кода
Построение комбинаций циклических кодов возможно путем умножения комбинации первичного кода A*(z) ,на порождающий полином G(z):
A(z)=A*(z)G(z).
Умножение производится по модулю zn и в данном случае сводится к умножению по обычным правилам с приведением подобных членов по модулю два.
В полученной таким способом комбинации A(z) в явном виде не содержатся информационные символы, однако они всегда могут быть выделены в результате обратной операции: деления A(z) на G(z).
Другой способ кодирования, позволяющий представить кодовую комбинацию в виде информационных и контрольных символов, заключается в следующем. К комбинации первичного кода дописывается справа г нулей, что эквивалентно повышению полинома A*(z) на ,г разрядов, т. е. умножению его на гг. Затем произведение zrA*(z) делится на порождающий полином. B общем случае результат деления состоит из целого числа Q(z) и остатка R(z). Отсюда
![]()
Вычисленный остаток К(г) я используется для образования комбинации циклического кода в виде суммы
A(z)=zrA*(z)@R(z).
Так как сложение и вычитание по модулю два дают один и тот же результат, то нетрудно заметить, что A(z) = Q(z)G(z), т. е. полученная комбинация удовлетворяет требованию делимости на порождающий полином. Степень полинома R{z) не превышает r—1, поэтому он замещает нули в комбинации z![]() A*(z).
A*(z).
Для примера рассмотрим циклический код c n = 7, k=4, r=3 и G(z)=z3-z+1=1011. Необходимо закодировать комбинацию A*(z)=z*+1 = 1001. Тогда z![]() A*(z)=z
A*(z)=z![]() +z
+z![]() = 1001000. Для определения остатка делим z3A*(z) на G(z):
= 1001000. Для определения остатка делим z3A*(z) на G(z):
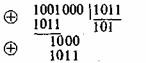
Окончательно получаем
В А(z) высшие четыре разряда занимают информационные символы, а остальные при — контрольные.
Контрольные символы в циклическом коде могут быть вычислены по общим ф-лам (7.9), однако здесь определение коэффициентов ![]() затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
Процедура декодирования принятых комбинаций также основана на использовании полиномов G(z). Если ошибок в процессе передачи не было, то деление принятой комбинации A(z) на G(z) дает целое число. При наличии корректируемых ошибок в результате деления образуется остаток, который и позволяет обнаружить или исправить ошибки.
Кодирующие и декодирующие устройства циклических кодов в большинстве случаев обладают сравнительной простотой, что следует считать одним из основных их преимуществ. Другим важным достоинством этих кодов является их способность корректировать пачки ошибок, возникающие в реальных каналах, где действуют импульсные и сосредоточенные помехи или наблюдаются замирания сигнала.
7.7. Коды с постоянным весом
В теории кодирования весом кодовых комбинаций принято называть .количество единиц, которое они содержат. Если все комбинации кода имеют одинаковый вес, то такой код называется кодом с постоянным весом. Коды с постоянным весом относятся к классу блочных неразделимых кодов, так как здесь не представляется возможным выделить информационные и контрольные символы. Из кодов этого типа наибольшее распространение получил обнаруживающий семизначный код 3/4, каждая разрешенная комбинация которого имеет три единицы и четыре нуля. Известен также код 2/5. Примером комбинаций кода 3/4 могут служить следующие семизначные последовательности: 1011000, 0101010, 0001110 и т. д.
Декодирование принятых комбинаций сводится к определению их веса. Если он отличается от заданного, то комбинация принята с ошибкой. Этот код обнаруживает все ошибки нечетной краткости и часть ошибок четной кратности. Не обнаруживаются только так называемые ошибки смещения, сохраняющие неизменным вес комбинации. Ошибки смещения характеризуются тем, что число искаженных единиц всегда равно числу искаженных нулей. Можно показать, что вероятность необнаруженной ошибки для кода 3/4 равна:
![]() при
при ![]() (7.18)
(7.18)
В этом коде из общего числа комбинаций М = 27=128 разрешенными являются лишь ![]() , поэтому в соответствии с (7.6) коэффициент избыточности
, поэтому в соответствии с (7.6) коэффициент избыточности
![]()
Код 3/4 находит применение при частотной манипуляции в каналах с селективными замираниями, где вероятность ошибок смещения невелика.
7.8. Непрерывные коды
Из непрерывных кодов, исправляющих ошибки, наиболее известны коды Финка—Хагельбаргера, в которых контрольные символы образуются путем линейной операции над двумя или более информационными символами. Принцип построения этих кодов рассмотрим на примере простейшего цепного кода. Контрольные символы в цепном коде формируются путем суммирования двух информационных символов, расположенных один относительно другого на определенном расстоянии:
![]() ;
;![]() (7.19)
(7.19)
Расстояние между информационными символами l=k-i определяет основные свойства кода и называется шагом сложения. Число контрольных символов при таком способе кодирования равно числу информационных символов, поэтому избыточность кода ![]() =0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
=0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
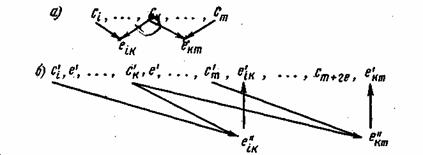
Рис. 7.3. Образование и размещение контрольных символов в цепном коде Финка—Хагельбаргера
При декодировании из принятых информационных символов по тому же правилу (7.19) формируется вспомогательная последовательность контрольных символов е", которая сравнивается с принятой последовательностью контрольных символов е' (рис. 7.36). Если произошла ошибка в информационном символе, например, c'k, то это вызовет искажения сразу двух символов e"k и e"km, что и обнаружится в результате их сравнения с ![]() и e'km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с'
и e'km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с'![]() Ошибка в принятом контрольном символе, например, e'k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Ошибка в принятом контрольном символе, например, e'k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Важное преимущество непрерывных кодов состоит в их способности исправлять не только одиночные ошибки, но я группы (пакеты) ошибок. Если задержка контрольных символов выбрана равной 2l, то можно показать, что максимальная длина исправляемого пакета ошибок также равна 2l при интервале между пакетами не менее 6l+1. Таким образом, возможность исправления длинных пакетов связана с увеличением шага сложения, а следовательно, и с усложнением кодирующих и декодирующих устройств.
Вопросы для повторения
1. Как могут быть классифицированы корректирующие коды?
2. Каким образом исправляются ошибки в кодах, которые только их обнаруживают?
3. В чем состоят основные принципы корректирования ошибок?
4. Дайте определение кодового расстояния.
5. При каких условиях код может обнаруживать или исправлять ошибки?
6. Как используется корректирующий код в системах со стиранием?
7. Какие характеристики определяют корректирующие способности кода?
8. Как осуществляется построение кодовых комбинаций в систематических кодах?
9. На чем основан принцип корректирования ошибок с использованием контрольного числа?
10. Объясните метод построения кода с четным числом единиц.
11. Как осуществляется процедура кодирования в семизначном коде Хэмминга?
12. Почему семизначный код 3/4 не обнаруживает ошибки смещения?
13. Каким образом производится непрерывное кодирование?
14. От чего зависит длина пакета исправляемых ошибок в коде Финка—Хагельбаргера?