6.1. Типы процессоров. Арифметические процессоры
Процессором называется устройство, способное выполнять некоторый заданный набор операций над данными в структурированной памяти и вырабатывать значение заданного набора логических условий над этими данными.
Стандартная схема процессора состоит из двух устройств, называемых арифметико–логическим устройством и устройством управления (рисунок 6.1).

Рисунок 6.1 — Схема процессора
В схему АЛУ включается структурированная память, состоящая, как правило, из регистров, к которым может добавляться один или несколько стеков. С помощью специальных комбинационных схем в структурированной памяти может осуществляться тот или иной набор преобразований.
Операции, выполняемые АЛУ за один такт синхронизирующего генератора, называются микрооперациями, а соответствующий их выполнению такт — микротактом. Выбор той или иной микрооперации осуществляется путем подачи кода этой микрооперации на специальный управляющий вход АЛУ. Как правило, в состав микроопераций АЛУ включаются очистка регистров и стеков (обращение их содержимого в нуль), пересылки данных между регистрами и стеками, сдвиги (вправо или влево) двоичного кода на регистрах, а также накапливающее суммирование. Для этой операции выделяются специальные регистры, называемые накапливающими сумматорами (аккумуляторами). При передаче кода некоторого числа х в аккумулятор, содержавший число у, происходит суммирование (с учетом знаков) этих чисел, а сумма х + у замещает в аккумуляторе его первоначальное содержимое у.
Помимо описанных внутренних микроопераций, в АЛУ реализуются также внешние микрооперации, осуществляющие прием и выдачу данных, т. е. обмен данными между АЛУ и внешним миром.
Кроме того, АЛУ может формировать дополнительно выходные сигналы в виде набора логических условий, выражающих те или иные свойства содержимого памяти АЛУ. Примеры таких свойств: «коды в регистрах А и В одинаковы», «число в регистре А отрицательно» и т. д.
Устройство управления процессора на основе входных сигналов, в качестве которых служат формируемые АЛУ наборы логических условий, формирует выходные сигналы — коды микроопераций АЛУ. Кроме того, УУ может иметь также каналы обмена с внешним миром. Каналы выдачи и приема УУ и АЛУ обычно объединяются в каналы обмена процессора с внешним миром.
Через канал приема в УУ поступают коды команд (инструкций) на выполнение тех или иных операций процессора, а через канал выдачи — запросы на очередные команды, либо сигнал останова, который прекращает работу процессора. Операция процессора обычно не сводится к одной микрооперации, а индуцируется некоторой их последовательностью. Такие последовательности определяются микропрограммами, встраиваемыми или запоминаемыми в УУ. В случае запоминаемых микропрограмм их можно оперативно менять, настраивая процессор на различные наборы операций (команд). В этом случае говорят, что процессор имеет мягкую (перестраиваемую) архитектуру.
Работа процессора может осуществляться двумя различными способами. В первом из них процессор сам извлекает последовательно команды из программы, запомненной в быстродействующей памяти – внешней по отношению к процессору. Все необходимые данные (исходные, промежуточные и выходные) также хранятся в этой памяти. Команды, помимо кода операции, содержат адреса данных, необходимых для их исполнения. Извлекая из памяти очередную команду и анализируя ее, процессор тут же извлекает необходимые для ее выполнения данные. В этом случае принято говорить, что процессор управляется потоком команд. Другой способ состоит в том, что данные, поступающие в АЛУ процессора из внешнего источника, запоминаются в нем, анализируются и вызывают (с помощью УУ) выборку из быстродействующей памяти последовательности команд для их обработки. В этом режиме процессор управляется потоком данных. Быстродействие процессора должно быть достаточно велико, чтобы обработать поступившие данные и выдать результат обработки до поступления очередной порции данных.
6.1. Типы процессоров. Арифметические процессоры
Арифметическими называются процессоры, предназначенные в первую очередь для автоматизации вычислительных операций той или иной степени сложности. Для сложных научных, проектно–конструкторских и планово–экономических расчетов наиболее употребительны процессоры, выполняющие полный набор арифметических операций над многозначными числами в двоичной системе счисления параллельным способом. Выбор двоичной системы и параллельного способа выполнения операций (над всеми разрядами одновременно) обусловлен тем, что при этом достигаются наибольшая скорость вычислений и наилучшее использование оборудования (прежде всего — памяти).
Магистральные процессоры. При выполнении последовательности поступающих команд процессор реализует ряд повторяющихся операций: он должен воспринять код очередной операции, адреса, по которым хранятся операнды, и адрес, по которому должен быть размещен результат операции, принять и разместить на регистрах операнды, выполнить операцию, разместить ее результат и подготовиться к восприятию следующей команды (выработать адрес, по которому за ней надо обратиться).
Поскольку все эти составные части процесса выполнения любой команды выстроены в цепочку, закономерна мысль об их выполнении на конвейере, представляющем собой ряд соединенных друг с другом специализированных процессоров, каждый из которых выполняет лишь свою часть работы, после чего передает обрабатываемую команду следующему процессору по цепочке. Сам же он получает от предыдущего процессора следующую команду для исполнения соответствующей ее части. Темп выполнения команд при этом существенно ускоряется. Рассмотренный конвейерный метод выполнения команд представляет собой частный случай магистрального метода. В отличие от рассмотренного простого конвейера, в магистрали на отдельные составные части раскладывается также выполнение основной операции. Поскольку такие разложения для разных операций, вообще говоря, различны, в магистральном методе используется обычно несколько конвейерных линий с гибко перестраиваемыми связями между ними.
Особенно большой эффект подобное распараллеливание основной операции дает в случае сложных операций, характерных для интеллектуальных процессоров, при этом, чем сложнее операции, тем больший эффект может быть получен.
В идеале на магистральном процессоре последовательность команд может обрабатываться в темпе следования отдельных микроопераций или в темпе — один рабочий такт процессора (микротакт) на одну команду (при достаточной скорости внешних обменов).
Специализированные процессоры. Если ЭВМ предназначается для работы, в которой часто приходится использовать определенные виды сложных операций, в ее состав включают специализированные процессоры, предназначенные для быстрого выполнения этих операций. Наибольшее распространение получили векторные и матричные процессоры, в состав которых включается обычно несколько десятков элементарных процессоров для одновременного выполнения тех или иных операций над отдельными компонентами вектора или матрицы.
Наряду с векторно–матричными процессорами достаточно широкое распространение получили процессоры, ориентированные на задачи спектрального анализа сигналов (быстрое преобразование Фурье), задачи интерполяции и на ряд других применений.
Микропроцессоры. Успехи микроэлектроники позволили создать процессоры, полностью размещаемые на одном кристалле. Вначале разрядность таких процессоров была очень низкой (4 двоичных разряда), что фактически не позволяло использовать их как отдельные устройства. По мере увеличения уровня интеграции оказалось возможным повысить разрядность однокристальных микропроцессоров до 8, а потом и до 32 двоичных разрядов.
Важнейшим качеством микропроцессоров, помимо миниатюрных размеров и малого энергопотребления, является их относительно низкая стоимость. Благодаря этому качеству микропроцессоры и строящиеся на их основе микро–ЭВМ и ПЭВМ находят широкий класс применений, для которых применение ЭВМ прежних поколений было экономически невыгодно.
6.2. Оценка производительности процессоров
Производительность процессоров определяется обычно количеством операций (команд), которые они могут выполнить за одну секунду. Однако время выполнения различных операций может довольно сильно разниться. Поэтому при определении производительности указывают среднее быстродействие на смеси различных операций, взятых в определенных пропорциях друг к другу.
Если ![]() — относительные доли этих операций в смеси, a
— относительные доли этих операций в смеси, a ![]() — время выполнения каждой из этих операций (в секундах), то среднее быстродействие
— время выполнения каждой из этих операций (в секундах), то среднее быстродействие ![]() вычисляется по формуле
вычисляется по формуле
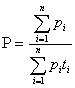 .
.
Одна из наиболее употребительных смесей, основанная на статистике для многих научных задач и называемая смесью Гибсона I, принимает для операций сложения и вычитания с фиксированной запятой ![]() %, с плавающей запятой
%, с плавающей запятой ![]() %; для умножения с фиксированной запятой
%; для умножения с фиксированной запятой![]() %, с плавающей запятой
%, с плавающей запятой ![]() %; для деления с фиксированной запятой
%; для деления с фиксированной запятой ![]() %, с плавающей запятой
%, с плавающей запятой ![]() % (время выполнения операции сложения и вычитания у ЭВМ обычно одно и то же). Доля операций других типов составляет 53,3 %.
% (время выполнения операции сложения и вычитания у ЭВМ обычно одно и то же). Доля операций других типов составляет 53,3 %.
6.3. Мультипроцессирование
В многопроцессорных вычислительных системах центральные процессоры закрепляются и своевременно перераспределяются между различными программными модулями и различными потоками данных. Наиболее просто этот вопрос решается в том случае, когда каждый ЦП решает свою собственную независимую задачу. Если несколько ЦП используются для решения одной и той же задачи, то должно производиться распараллеливание вычислительного процесса.
Необходимо отметить, что распараллеливание допускают не все процессы. В тех случаях, когда оно возможно, различают два основных типа распараллеливания. Первый тип использует для всех процессоров один и тот же поток команд, но различные потоки данных. Например, при сложении двух матриц можно разделить между процессорами строки этих матриц и выполнить параллельно сложение различных пар строк с помощью одного и того же программного цикла. Второй тип распараллеливания использует для каждого процессора свой программный модуль, выполняемый над одними и теми же или различными данными. Поскольку разные модули исполняются, как правило, за разное время, возникает задача их синхронизации. Смысл ее состоит в том, что очередной программный модуль запускается в работу лишь после того, как для него подготовлены (в результате работы предшествующих модулей) все необходимые исходные данные. Подобная взаимозависимость модулей определяет одновременно и возможность их параллельного исполнения.