8.1.1. Вероятность появления ошибок для кодов Рида-Соломона
8.1.2. Почему коды Рида-Соломона эффективны при борьбе c импульсными помехами
8.1.4.1.Операция сложения в поле расширения GF(2m)
8.1.4.2. Описание конечного поля с помощью примитивного полинома
8.1.4.3. Поле расширения GF(23)
8.1.4.4. Простой тест для проверки полинома на примитивность
8.1.5. Кодирование Рида-Соломона
8.1.5.1. Кодирование в систематической форме
8.1.5.2. Систематическое кодирование с помощью (n-k)-разрядного регистра сдвига
8.1.6. Декодирование Рида-Соломона
8.1.6.4. Исправление принятого полинома с помощью найденного полинома ошибок
8.2. Коды с чередованием и каскадные коды
8.3. Кодирование и чередование в системах цифровой записи информации на компакт-дисках
8.3.1. Кодирование по схеме CIRC
8.4.1. Понятия турбокодирования
8.4.1.1. Функции правдоподобия
8.4.1.2. Пример класса из двух сигналов
8.4.2. Алгебра логарифма правдоподобия
8.4.3. Пример композиционного кода
8.4.3.1. Пример двухмерного кода с одним разрядом контроля четности
8.4.4. Кодирование с помощью рекурсивного систематического кода
8.4.5. Декодер с обратной связью
8.4.6.1. Метрики состояний и метрика ветви
8.4.6.2. Расчет прямой метрики состояния
8.4.7. Пример декодирования по алгоритму MAP
8.4.7.2. Расчет метрик состояний
8.4.7.3. Расчет логарифмического отношения правдоподобий
8.4.7.4. Реализация конечного автомата с помощью регистра сдвига
Приложение 8А. Сложение логарифмических отношений правдоподобий
8.1. Коды Рида-Соломона
Коды Рида-Соломона (Reed-Solomon code, R-S code) — это недвоичные циклические коды, символы которых представляют собой m-битовые последовательности, где т—положительное целое число, большее 2. Код (n, K) определен на m-битовых символах при всех п и k, для которых
![]() (8.1)
(8.1)
где k — число информационных битов, подлежащих кодированию, а n — число кодовых символов в кодируемом блоке. Для большинства сверточных кодов Рида-Соломона (n,k)
![]() (8.2)
(8.2)
где t — количество ошибочных битов в символе, которые может исправить код, а и ![]() — число контрольных символов. Расширенный код Рида-Соломона можно получить при
— число контрольных символов. Расширенный код Рида-Соломона можно получить при ![]() , но не более того.
, но не более того.
Код Рида-Соломона обладает наибольшим минимальным расстоянием, возможным для линейного кода с одинаковой длиной входных и выходных блоков кодера. Для недвоичных кодов расстояние между двумя кодовыми словами определяется (по аналогии с расстоянием Хэмминга) как число символов, которыми отличаются последовательности. Для кодов Рида-Соломона минимальное расстояние определяется следующим образом [1].
![]() (8.3)
(8.3)
Код, который исправляет все искаженные символы, содержащие ошибку в t или меньшем числе бит, где t приведено в уравнении (6.44), можно выразить следующим образом.
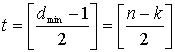 (8.4)
(8.4)
Здесь [x] означает наибольшее целое, не превышающее х. Из уравнения (8.4) видно, что коды Рида-Соломона, исправляющие t символьных ошибок, требуют не более 2t контрольных символов. Из уравнения (8.4) следует, что декодер имеет п-k "используемых" избыточных символов, количество которых вдвое превышает количество исправляемых ошибок. Для каждой ошибки один избыточный символ используется для обнаружения ошибки и один — для определения правильного значения. Способность кода к коррекции стираний выражается следующим образом.
![]() (8.5)
(8.5)
Возможность одновременной коррекции ошибок и стираний можно выразить как требование.
![]() (8.6)
(8.6)
Здесь ![]() — число символьных ошибочных комбинаций, которые можно исправить, а
— число символьных ошибочных комбинаций, которые можно исправить, а ![]() — количество комбинаций символьных стираний, которые могут быть исправлены. Преимущества недвоичных кодов, подобных кодам Рида-Соломона, можно увидеть в следующем сравнении. Рассмотрим двоичный код (п, k) = (7, 3). Полное пространство n-кортежей содержит
— количество комбинаций символьных стираний, которые могут быть исправлены. Преимущества недвоичных кодов, подобных кодам Рида-Соломона, можно увидеть в следующем сравнении. Рассмотрим двоичный код (п, k) = (7, 3). Полное пространство n-кортежей содержит ![]() n-кортежей, из которых
n-кортежей, из которых ![]() (или 1/16 часть всех n-кортежей) являются кодовыми словами. Затем рассмотрим недвоичный код (n, k)=(7, 3), где каждый символ состоит из т = 3 бит. Пространство n-кортежей содержит
(или 1/16 часть всех n-кортежей) являются кодовыми словами. Затем рассмотрим недвоичный код (n, k)=(7, 3), где каждый символ состоит из т = 3 бит. Пространство n-кортежей содержит ![]() 2 097 152 n-кортежа, из которых
2 097 152 n-кортежа, из которых ![]() (или 1/4096 часть всех n-кортежей) являются кодовыми словами. Если операции производятся над недвоичными символами, каждый из которых образован т битами, то только незначительная часть (т.е.
(или 1/4096 часть всех n-кортежей) являются кодовыми словами. Если операции производятся над недвоичными символами, каждый из которых образован т битами, то только незначительная часть (т.е. ![]() из большого числа
из большого числа ![]() ) возможных n-кортежей является кодовыми словами. Эта часть уменьшается с ростом т. Здесь важным является то, что если в качестве кодовых слов используется незначительная часть пространства n-кортежей, то можно достичь большего
) возможных n-кортежей является кодовыми словами. Эта часть уменьшается с ростом т. Здесь важным является то, что если в качестве кодовых слов используется незначительная часть пространства n-кортежей, то можно достичь большего ![]() .
.
Любой линейный код дает возможность исправить n-k комбинаций символьных стираний, если все n-k стертых символов приходятся на контрольные символы. Однако коды Рида-Соломона имеют замечательное свойство, выражающееся в том, что они могут исправить любой набор п-k символов стираний в блоке. Можно сконструировать коды с любой избыточностью. Впрочем, с увеличением избыточности растет сложность ее высокоскоростной реализации. Поэтому наиболее привлекательные коды Рида-Соломона обладают высокой степенью кодирования (низкой избыточностью).
8.1.1. Вероятность появления ошибок для кодов Рида-Соломона
Коды Рида-Соломона чрезвычайно эффективны для исправления пакетов ошибок, т.е. они оказываются эффективными в каналах с памятью. Также они хорошо зарекомендовали себя в каналах с большим набором входных символов. Особенностью кода Рида-Соломона является, то, что к коду длины n можно добавить два информационных символа, не уменьшая при этом минимального расстояния. Такой расширенный код имеет длину п + 2 и то же количество символов контроля четности, что и исходный код. Из уравнения (6.46) вероятность появления ошибки в декодированном символе, РЕ, можно записать через вероятность появления ошибки в канальном символе, ![]() .
.
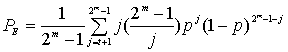 (8.7)
(8.7)
Здесь t — количество ошибочных битов в символе, которые может исправить код, а символы содержат т битов каждый.
Для некоторых типов модуляции вероятность битовой ошибки можно ограничить сверху вероятностью символьной ошибки. Для модуляции MFSK с М=![]() связь РВи РЕвыражается формулой (4.112).
связь РВи РЕвыражается формулой (4.112).
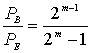 (8.8)
(8.8)
На рис. 8.1 показана зависимость ![]() от вероятности появления ошибки в канальном символе p, полученная из уравнений (8,7) и (8.8) для различных ортогональных 32-ричных кодов Рида-Соломона с возможностью коррекции t ошибочных бит в символе и n = 31 (тридцать один 5-битовый символ в кодовом блоке). На рис.8.2 показана зависимость
от вероятности появления ошибки в канальном символе p, полученная из уравнений (8,7) и (8.8) для различных ортогональных 32-ричных кодов Рида-Соломона с возможностью коррекции t ошибочных бит в символе и n = 31 (тридцать один 5-битовый символ в кодовом блоке). На рис.8.2 показана зависимость ![]() от
от ![]() /N0 для таких систем кодирования при использовании модуляции MFSK и некогерентной демодуляции в канале AWGN [2]. Для кодов Рида-Соломона вероятность появления ошибок является убывающей степенной функцией длины блока, n, а сложность декодирования пропорциональна небольшой степени длины блока [1]. Иногда коды Рида-Соломона применяются в каскадных схемах. В таких системах внутренний сверточный декодер сначала осуществляет некоторую защиту от ошибок за счет мягкой схемы решений на выходе демодулятора; затем сверточный декодер передает данные, оформленные согласно жесткой схеме, на внешний декодер Рида-Соломона, что снижает вероятность появления ошибок. В разделах 8.2.3 и 8.3 мы рассмотрим каскадное декодирование и декодирование Рида-Соломона на примере системы цифровой записи данных на аудиокомпакт-дисках (compact disc — CD).
/N0 для таких систем кодирования при использовании модуляции MFSK и некогерентной демодуляции в канале AWGN [2]. Для кодов Рида-Соломона вероятность появления ошибок является убывающей степенной функцией длины блока, n, а сложность декодирования пропорциональна небольшой степени длины блока [1]. Иногда коды Рида-Соломона применяются в каскадных схемах. В таких системах внутренний сверточный декодер сначала осуществляет некоторую защиту от ошибок за счет мягкой схемы решений на выходе демодулятора; затем сверточный декодер передает данные, оформленные согласно жесткой схеме, на внешний декодер Рида-Соломона, что снижает вероятность появления ошибок. В разделах 8.2.3 и 8.3 мы рассмотрим каскадное декодирование и декодирование Рида-Соломона на примере системы цифровой записи данных на аудиокомпакт-дисках (compact disc — CD).
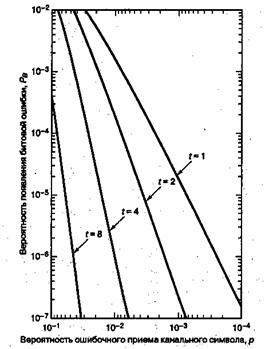
Рис. 8.1. Зависимость Рв от р для различных ортогональных 32-ринных кодов Рида-Соломона с возможностью коррекции t бит в символе и п = 31.(Перепечатано с разрешения автора из Data Communications, Network, and Systems, ed. Thomas C, Bartee, Howard W. Sams Company,Indianapolis,Ind., 1985, p. 311. Ранее публиковалось в J. P. Odenwalder, Error Control Coding Handbook, M/A-COM LINKABIT, Inc., San Diego, Calif., . ./ - . July,15, 1976,p.
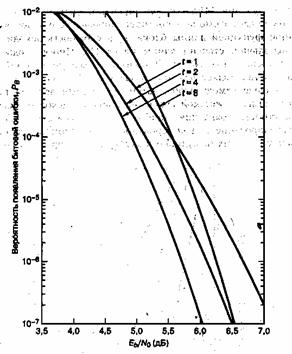
Рис. 8.2. Зависимость рв от Et/NQ для различных ортогональных кодов Рида-Соломона с возможностью коррекции t бит в символе и п = 31, при 32-ринной модуляции MFSK в канале AWGN. (Перепечатано с разрешения автора из Data Communications, Network, and Systems, ed. Thomas C. Bartee, Howard W. Sams Company, Indianapolis, Ind.f 1985, p. 312. Ранее публиковалось в J. P. Odenwalder, Error Control Coding Handbook, M/A-COM LINKABIT, Inc., San Diego, Calif., July, 15, 1976, p. 92.)
8.1.2. Почему коды Рида-Соломона эффективны при борьбе с импульсными помехами
Давайте рассмотрим код (n, k) = (255, 247), в котором каждый символ состоит из т = 8 бит (такие символы принято называть байтами). Поскольку п-k=8, из уравнения (8.4) можно видеть, что этот код может исправлять любые 4-символьные ошибки в блоке длиной до 255. Пусть блок длительностью 25 бит в ходе передачи поражается помехами, как показано на рис. 8.3. В этом примере пакет шума, который попадает на 25 последовательных битов, исказит точно 4 символа. Декодер для кода (255, 247) исправит любые 4-символьные ошибки без учета характера повреждений, причиненных символу. Другими словами, если декодер исправляет байт (заменяет неправильный правильным), то ошибка может быть вызвана искажением одного или всех восьми битов. Поэтому, если символ неправильный, он может быть искажен на всех двоичных позициях. Это дает коду Рида-Соломона огромное преимущество при наличии импульсных помех по сравнению с двоичными кодами (даже при использовании в двоичном коде чередования). В этом примере, если наблюдается 25-битовая случайная помеха, ясно, что искаженными могут оказаться более чем 4 символа (искаженными могут оказаться до 25 символов). Конечно, исправление такого числа ошибок окажется вне возможностей кода (255, 247).
8.1.3. Рабочие характеристики кода Рида-Соломона как функция размера, избыточности и степени кодирования
Для того чтобы код успешно противостоял шумовым эффектам, длительность помех должна составлять относительно небольшой процент от количества кодовых слов. Чтобы быть уверенным, что так будет большую часть времени, принятый шум необходимо усреднить за большой промежуток времени, что снизит эффект от неожиданной или необычной полосы плохого приема. Следовательно, можно предвидеть, что код с коррекцией ошибок будет более эффективен (повысится надежность передачи) при увеличении размера передаваемого блока, что делает код Рида-Соломона более привлекательным, если желательна большая длина блока [3]. Это можно оценить по семейству кривых, показанному на рис. 8.4, где степей кодирования взята равной 7/8, при этом длина блока возрастает с n = 32 символов (при w = 5 бит на символ) до n=256 символов (при n=8 бит на символ). Таким образом, размер блока возрастает с 160 бит до 2048 бит.
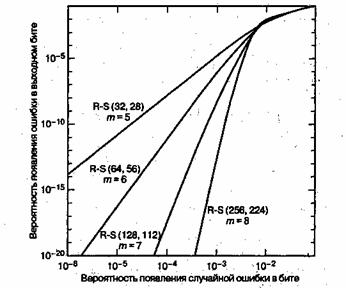
Рис. 8.4. Характеристики декодера Рида-Соломона как функция размера символов (степень кодирования = 7/8)
По мере увеличения избыточности кода (и снижения его степени кодирования), сложность реализации этого кода повышается (особенно для высокоскоростных устройств). При этом для систем связи реального времени должна увеличиться ширина полосы пропускания. Увеличение избыточности, например увеличение размера символа, приводит к уменьшению вероятности появления битовых ошибок, как можно видеть на рис. 8.5, еще кодовая длина п равна постоянному значению 64 при снижении числа символов данных с k = 60 до k = 4 (избыточность возрастает с 4 до 60символов).
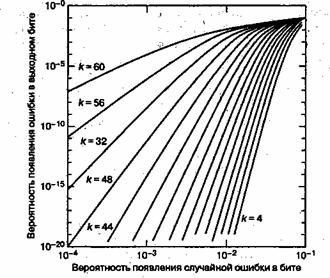
Рис. 8.5. Характеристики декодера Рида-Соломона (64, k) как функция избыточности
На рис. 8.5 показана передаточная функция (выходная вероятность появлений битовой ошибки, зависящая от входной вероятности появления символьной ошибки) гипотетических декодеров. Поскольку здесь не имеется в виду определенная система или канал (лишь вход-выход декодера), можно заключить, что надежность передачи является монотонной функцией избыточности и будет неуклонно возрастать с приближением степени кодирования к нулю. Однако это не так для кодов, используемых в системах связи реального времени. По мере изменения степени кодирования кода от максимального значения до минимального (от 0 до 1), интересно было бы понаблюдать за эффектами, показанными на рис. 8.6. Здесь кривые рабочих характеристик показаны при модуляции BPSK и кодах (31, к) для разных типов каналов. На рис. 8.6 показаны системы связи реального времени, в которых за кодирование с коррекцией ошибок приходится платить расширением полосы пропускания, пропорциональным величине, равной обратной степени кодирования. Приведенные кривые показывают четкий оптимум степени кодирования, минимизирующий требуемое значение ![]() [4]. Для гауссова канала оптимальное значение степени кодирования находится где-то между 0,6 и 0,7, для канала с райсовским замиранием - около 0,5 (с отношением мощности прямого сигнала к мощности отраженного К = 7 дБ) и 0,3 — для канала с релеевским замиранием. (Каналы с замиранием будут рассматриваться в главе 15.) Почему здесь как при очень высоких степенях кодирования (малой избыточности), так и при очень низких (значительной избыточности) наблюдается ухудшение
[4]. Для гауссова канала оптимальное значение степени кодирования находится где-то между 0,6 и 0,7, для канала с райсовским замиранием - около 0,5 (с отношением мощности прямого сигнала к мощности отраженного К = 7 дБ) и 0,3 — для канала с релеевским замиранием. (Каналы с замиранием будут рассматриваться в главе 15.) Почему здесь как при очень высоких степенях кодирования (малой избыточности), так и при очень низких (значительной избыточности) наблюдается ухудшение ![]() ? Для высоких степеней кодирования это легко объяснить, сравнивая высокие степени кодирования с оптимальной степенью кодирования. Любой код в целом обеспечивает все преимущества кодирования; следовательно, как только степень кодирования приближается к единице (нет кодирования), система проигрывает в надежности передачи. Ухудшение характеристик при низких степенях кодирования является более тонким вопросом, поскольку в системах связи реального времени используется и модуляция, и кодирование, т.е. работает два механизма. Один механизм направлен на снижение вероятности появления ошибок, другой повышает ее. Механизм, снижающий вероятность появления ошибки, — это кодирование; чем больше избыточность, тем больше возможности кода в коррекции ошибок. Механизм, повышающий эту вероятность, — это снижение энергии, приходящейся на канальный символ (по сравнению с информационным символом), что следует из увеличения избыточности (и более быстрой передачи сигналов в системах связи реального времени). Уменьшенная энергия символа вынуждает демодулятор совершать больше ошибок. В конечном счете второй механизм подавляет первый, поэтому очень низкие степени кодирования вызывают ухудшение характеристик кода.
? Для высоких степеней кодирования это легко объяснить, сравнивая высокие степени кодирования с оптимальной степенью кодирования. Любой код в целом обеспечивает все преимущества кодирования; следовательно, как только степень кодирования приближается к единице (нет кодирования), система проигрывает в надежности передачи. Ухудшение характеристик при низких степенях кодирования является более тонким вопросом, поскольку в системах связи реального времени используется и модуляция, и кодирование, т.е. работает два механизма. Один механизм направлен на снижение вероятности появления ошибок, другой повышает ее. Механизм, снижающий вероятность появления ошибки, — это кодирование; чем больше избыточность, тем больше возможности кода в коррекции ошибок. Механизм, повышающий эту вероятность, — это снижение энергии, приходящейся на канальный символ (по сравнению с информационным символом), что следует из увеличения избыточности (и более быстрой передачи сигналов в системах связи реального времени). Уменьшенная энергия символа вынуждает демодулятор совершать больше ошибок. В конечном счете второй механизм подавляет первый, поэтому очень низкие степени кодирования вызывают ухудшение характеристик кода.
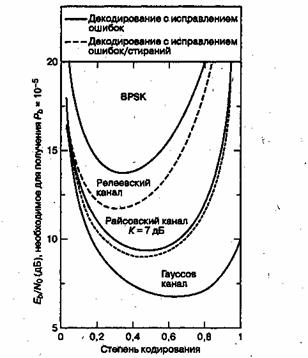
Рис. 8.6. Характеристики декодера Рида-Соломона (31, k) как функция степени кодирования (модуляция BPSK)
Давайте попробуем подтвердить зависимость вероятности появления ошибок от степени кодирования, показанную на рис. 8.6, с помощью кривых, изображенных на рис. 8.2. Непосредственно сравнить рисунки не удастся, поскольку на рис. 8.6 применяется модуляция BPSK, а на рис. 8.2 — 32-ричная модуляция MFSK. Однако, пожалуй, нам удастся показать, что зависимость характеристик кода Рида-Соломона от его степени кодирования выглядит одинаково как при BPSK, так и при MFSK. На рис. 8.2 вероятность появления ошибки в канале AWGN снижается при увеличении способности кода t к коррекции символьных ошибок с t = 1 до t = 4; случаи t = 1 и t = 4 относятся к кодам (31, 29) и (31,23) со степенями кодирования 0,94 и 0,74. Хотя при t = 8, что отвечает коду (31,15) со степенью кодирования 0,48, достоверность передачи ![]() достигается при примерно на 0,5 дБ большем отношении
достигается при примерно на 0,5 дБ большем отношении ![]() , по сравнению со случаем t = 4. Из рис. 8.2 можно сделать вывод, что если нарисовать график зависимости достоверности передачи от степени кодирования кода, то кривая будет иметь вид, подобный приведенному на рис. 8.6. Заметим, что это утверждение нельзя получить из рис. 8.1, поскольку там представлена передаточная функция декодера, которая несет в себе сведения о канале и демодуляции. Поэтому из двух механизмов, работающих в канале, передаточная функция (рис. 8.1) представляет только выгоды, которые проявляются на входе/выходе декодера, и ничего не говорит о потерях энергии как функции низкой степени кодирования.
, по сравнению со случаем t = 4. Из рис. 8.2 можно сделать вывод, что если нарисовать график зависимости достоверности передачи от степени кодирования кода, то кривая будет иметь вид, подобный приведенному на рис. 8.6. Заметим, что это утверждение нельзя получить из рис. 8.1, поскольку там представлена передаточная функция декодера, которая несет в себе сведения о канале и демодуляции. Поэтому из двух механизмов, работающих в канале, передаточная функция (рис. 8.1) представляет только выгоды, которые проявляются на входе/выходе декодера, и ничего не говорит о потерях энергии как функции низкой степени кодирования.
8.1.4. Конечные поля
Для понимания принципов кодирования и декодирования недвоичных кодов, таких как коды Рида-Соломона, нужно сделать экскурс в понятие конечных полей, известных как поля Галуа (Galois fields — GF). Для любого простого числа p существует конечное поле, которое обозначается GF(p) и содержит p элементов. Понятие GF(p) можно обобщить на поле из ![]() элементов, именуемое полем расширения GF(p); это поле обозначается GF(
элементов, именуемое полем расширения GF(p); это поле обозначается GF(![]() ), где т — положительное целое число. Заметим, что GF(
), где т — положительное целое число. Заметим, что GF(![]() ) содержит в качестве подмножества все элементы GF(p). Символы из поля расширения GF(
) содержит в качестве подмножества все элементы GF(p). Символы из поля расширения GF(
) используются при построении кодов Рида-Соломона.
Двоичное поле GF(2) является подполем поля расширения GF(![]() ), точно так же как поле вещественных чисел является подполем поля комплексных чисел. Кроме чисел 0 и 1, в поле расширения существуют дополнительные однозначные элементы, которые будут представлены новым символом а. Каждый ненулевой элемент в GF(
), точно так же как поле вещественных чисел является подполем поля комплексных чисел. Кроме чисел 0 и 1, в поле расширения существуют дополнительные однозначные элементы, которые будут представлены новым символом а. Каждый ненулевой элемент в GF(![]() ) можно представить как степень
) можно представить как степень ![]() . Бесконечное множество элементов, F, образуется из стартового множества
. Бесконечное множество элементов, F, образуется из стартового множества ![]() и генерируется дополнительными элементами путем последовательного умножения последней записи на
и генерируется дополнительными элементами путем последовательного умножения последней записи на ![]() .
.
![]() (8.9)
(8.9)
Для вычисления из F конечного множества элементов GF(![]() ) на F нужно наложить условия: оно может содержать только
) на F нужно наложить условия: оно может содержать только ![]() элемента и быть замкнутым относительно операции умножения. Условие замыкания множества элементов поля по отношению к операции умножения имеет вид неприводимого полинома.
элемента и быть замкнутым относительно операции умножения. Условие замыкания множества элементов поля по отношению к операции умножения имеет вид неприводимого полинома.
![]() (8.9)
(8.9)
или, что тоже самое,
![]() (8.10)
(8.10)
С помощью полиномиального ограничения любой элемент со степенью, большей или равной ![]() , можно следующим образом понизить до элемента со степенью, меньшей
, можно следующим образом понизить до элемента со степенью, меньшей ![]() .
.
![]() (8.11)
(8.11)
Таким образом, как показано ниже, уравнение (8.10) можно использовать для формирования конечной последовательности F* из бесконечной последовательности F.
![]() (8.12)
(8.12)
Следовательно, из уравнения (8.12) можно видеть, что элементы конечного поля GF(![]() ) даются следующим выражением.
) даются следующим выражением.
![]() (8.13)
(8.13)
8.1.4.1. Операция сложения в поле расширения GF(2m)
Каждый из ![]() элементов конечного поля GF(
элементов конечного поля GF(![]() ) можно представить как отдельный полином степени от m-1 или меньше. Степенью полинома называется степень члена максимального порядка. Обозначим каждый ненулевой элемент GF(
) можно представить как отдельный полином степени от m-1 или меньше. Степенью полинома называется степень члена максимального порядка. Обозначим каждый ненулевой элемент GF(![]() ) полиномом
) полиномом ![]() , в котором последние т коэффициентов
, в котором последние т коэффициентов ![]() нулевые. Для
нулевые. Для ![]() ,
,
![]() (8.14)
(8.14)
Рассмотрим случай m = 3, в котором конечное поле обозначается GF(23). На рис. 8.7 показано отображение семи элементов {![]() } и нулевого элемента в слагаемые базисных элементов
} и нулевого элемента в слагаемые базисных элементов ![]() , описываемых уравнением (8.14). Поскольку из уравнения (8.10)
, описываемых уравнением (8.14). Поскольку из уравнения (8.10) ![]() , в этом поле имеется семь ненулевых элементов или всего восемь элементов. Каждая строка на рис. 8.7 содержит последовательность двоичных величин, представляющих коэффициенты
, в этом поле имеется семь ненулевых элементов или всего восемь элементов. Каждая строка на рис. 8.7 содержит последовательность двоичных величин, представляющих коэффициенты ![]() ,
, ![]() и
и ![]() из уравнения (8.14). Одним из преимуществ использования элементов
из уравнения (8.14). Одним из преимуществ использования элементов ![]() поля расширения, вместо двоичных элементов, является компактность записи, что оказывается удобным при математическом описании процессов недвоичного кодирования и декодирования. Сложение двух элементов конечного поля, следовательно, определяется как суммирование по модулю 2 всех коэффициентов при элементах одинаковых степеней.
поля расширения, вместо двоичных элементов, является компактность записи, что оказывается удобным при математическом описании процессов недвоичного кодирования и декодирования. Сложение двух элементов конечного поля, следовательно, определяется как суммирование по модулю 2 всех коэффициентов при элементах одинаковых степеней.
![]() (8.15)
(8.15)
8.1.4.2. Описание конечного поля с помощью примитивного полинома
Класс полиномов, называемых примитивными полиномами, интересует нас, поскольку такие объекты определяют конечные поля GF(![]() ), которые, в свою очередь, нужны для описания кодов Рида-Соломона. Следующее утверждение является необходимым и достаточным условием примитивности полинома. Неприводимый полином f(X) порядка т будет примитивным, если наименьшим положительным целым числом п, для которого
), которые, в свою очередь, нужны для описания кодов Рида-Соломона. Следующее утверждение является необходимым и достаточным условием примитивности полинома. Неприводимый полином f(X) порядка т будет примитивным, если наименьшим положительным целым числом п, для которого ![]() делится на f(X), будет
делится на f(X), будет ![]() . Заметим, что неприводимый полином — это такой полином, который нельзя представить в виде произведения полиномов меньшего порядка; делимость А на В означает, что А делится на В с нулевым остатком и ненулевым частным. Обычно полином записывают в порядке возрастания степеней. Иногда более удобным является обратный формат записи (например, при выполнении полиномиального деления).
. Заметим, что неприводимый полином — это такой полином, который нельзя представить в виде произведения полиномов меньшего порядка; делимость А на В означает, что А делится на В с нулевым остатком и ненулевым частным. Обычно полином записывают в порядке возрастания степеней. Иногда более удобным является обратный формат записи (например, при выполнении полиномиального деления).
|
Образующие элементы |
||||
|
Элементы поля |
|
|
|
|
|
0 |
0 |
0 |
0 |
|
|
|
1 |
0 |
0 |
|
|
|
0 |
1 |
0 |
|
|
|
0 |
0 |
1 |
|
|
|
1 |
1 |
0 |
|
|
|
0 |
1 |
1 |
|
|
|
1 |
1 |
1 |
|
|
|
1 |
0 |
1 |
|
|
|
1 |
0 |
0 |
|
Рис. 8.7. Отображение элементов поля в базисные элементы GF(8) с помощью ![]()
Пример 8.1. Проверка полинома на примитивность
Основываясь на предыдущем определении примитивного полинома, укажите, какие из следующих неприводимых полиномов будут примитивными.
а) ![]()
б) ![]()
Решение
а) Мы можем проверить этот полином порядка т = 4, определив, будет ли он делителем ![]() для значений п из диапазона 1 < n < 15. Нетрудно убедиться, что
для значений п из диапазона 1 < n < 15. Нетрудно убедиться, что ![]() + 1 делится на
+ 1 делится на ![]() (см. раздел 6.8.1), и после повторения вычислений можно проверить, что при любых значениях п из диапазона 1<n<15 полином
(см. раздел 6.8.1), и после повторения вычислений можно проверить, что при любых значениях п из диапазона 1<n<15 полином ![]() +1 не делится на
+1 не делится на ![]() . Следовательно,
. Следовательно, ![]() является примитивным полиномом.
является примитивным полиномом.
б) Легко проверить, что полином является делителем ![]() . Проверив, делится ли
. Проверив, делится ли ![]() на
на ![]() , для значений n, меньших 15, можно также видеть, что указанный полином является делителем Xs+1. Следовательно, несмотря на то что полином
, для значений n, меньших 15, можно также видеть, что указанный полином является делителем Xs+1. Следовательно, несмотря на то что полином ![]() является неприводимым, он не будет примитивным.
является неприводимым, он не будет примитивным.
8.1.4.3. Поле расширения GF(23)
Рассмотрим пример, в котором будут задействованы примитивный полином и конечное поле, которое он определяет. В табл. 8.1 содержатся примеры некоторых примитивных полиномов. Мы выберем первый из указанных там полиномов, ![]() , который определяет конечное поле GF(
, который определяет конечное поле GF(![]() ), где степень полинома т=3. Таким образом, в поле, определяемом полиномом f(Х), имеется 2m = 23 = 8 элементов. Поиск корней полинома f(Х) — это поиск таких значений X, при которых
), где степень полинома т=3. Таким образом, в поле, определяемом полиномом f(Х), имеется 2m = 23 = 8 элементов. Поиск корней полинома f(Х) — это поиск таких значений X, при которых ![]() . Привычные нам двоичные элементы 0 и 1 не подходят полиному
. Привычные нам двоичные элементы 0 и 1 не подходят полиному ![]() (они не являются корнями), поскольку
(они не являются корнями), поскольку ![]() (в рамках операции по модулю 2). Кроме того, основная теорема алгебры утверждает, что полином порядка m должен иметь в точности m корней. Следовательно, в этом примере выражение
(в рамках операции по модулю 2). Кроме того, основная теорема алгебры утверждает, что полином порядка m должен иметь в точности m корней. Следовательно, в этом примере выражение ![]() должно иметь 3 корня. Возникает определенная проблема, поскольку 3 корня не лежат в одном конечном поле, что и коэффициенты f(X). А если они находятся где-то еще, то, наверняка, в поле расширения
должно иметь 3 корня. Возникает определенная проблема, поскольку 3 корня не лежат в одном конечном поле, что и коэффициенты f(X). А если они находятся где-то еще, то, наверняка, в поле расширения ![]() . Пусть,
. Пусть, ![]() , элемент поля расширения, определяется как корень полинома f(X). Следовательно, можно записать следующее.
, элемент поля расширения, определяется как корень полинома f(X). Следовательно, можно записать следующее.
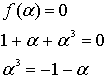 (8.16)
(8.16)
Поскольку при операциях над двоичным полем +1=-1, то ![]() можно представить следующим образом.
можно представить следующим образом.
![]() (8.17)
(8.17)
Таблица 8.1. Некоторые примитивные полиномы
|
m |
m |
||
|
3 |
|
14 |
|
|
4 |
|
15 |
|
|
5 |
|
16 |
|
|
6 |
|
17 |
|
|
7 |
|
18 |
|
|
8 |
|
19 |
|
|
9 |
|
20 |
|
|
10 |
|
21 |
|
|
11 |
|
22 |
|
|
12 |
|
23 |
|
|
13 |
|
24 |
|
Таким образом, ![]() представляется в виде взвешенной суммы всех
представляется в виде взвешенной суммы всех ![]() - членов более низкого порядка. Фактически так можно представить все степени
- членов более низкого порядка. Фактически так можно представить все степени ![]() . Например, рассмотрим следующее.
. Например, рассмотрим следующее.
![]() (8.18,а)
(8.18,а)
А теперь взглянем на следующий случай.
![]() (8.18,б)
(8.18,б)
Из уравнений (8.17) и (8.18), получаем следующее.
Из уравнений (8.17) и (8.18), получаем следующее.
![]() (8.18,в)
(8.18,в)
Из уравнений (8.17) и (8.18), получаем следующее.
![]() (8.18,г)
(8.18,г)
А теперь из уравнения (8.18,г) вычисляем
![]() (8.18,д)
(8.18,д)
Заметим, что ![]() и, следовательно, восьмью элементами конечного поля GF(
и, следовательно, восьмью элементами конечного поля GF(![]() ) ,будут
) ,будут
![]() (8.19)
(8.19)
Отображение элементов поля в базисные элементы, короче описывается уравнением (8.14), можно проиллюстрировать с помощью схемы линейного регистра сдвига с обратной связью (linear feedback shift register – LFSR) (рис 8.8). Схема генерирует (при m = 3) ![]() ненулевых элементов поля и, таким образом, обобщает процедуры, описанные в уравнениях (8.17) – (8.19). Следует отметить, что показанная на рис. 8.8. обратная связь соответствует коэффициентам полинома
ненулевых элементов поля и, таким образом, обобщает процедуры, описанные в уравнениях (8.17) – (8.19). Следует отметить, что показанная на рис. 8.8. обратная связь соответствует коэффициентам полинома ![]() , как и в случае двоичных циклических кодов (см. раздел 6.7.5.). Пусть вначале схема находится в некотором состоянии, например 1 0 0; при выполнении правого сдвига на один такт можно убедиться, что каждый из элементов поля (за исключением нулевого), показанных на рис.8.7, циклически будет появляться в разрядах регистра сдвига. На данном конечном поле GF(
, как и в случае двоичных циклических кодов (см. раздел 6.7.5.). Пусть вначале схема находится в некотором состоянии, например 1 0 0; при выполнении правого сдвига на один такт можно убедиться, что каждый из элементов поля (за исключением нулевого), показанных на рис.8.7, циклически будет появляться в разрядах регистра сдвига. На данном конечном поле GF(![]() ) можно определить две арифметические операции – сложение и умножение. В таб. 8.2. показана операция сложения, а в таб. 8.3. – операция умножения, но только для ненулевых элементов. Правила суммирования следуют из уравнений (8.17) и (8.18,д); и их можно рассчитать путем сложения (по модулю 2) соответствующих коэффициентов из базисных элементов. Правила умножения, указанные в табл. 8.3, следуют из обычной процедуры, в которой произведение элементов поля вычисляются путем сложения по модулю
) можно определить две арифметические операции – сложение и умножение. В таб. 8.2. показана операция сложения, а в таб. 8.3. – операция умножения, но только для ненулевых элементов. Правила суммирования следуют из уравнений (8.17) и (8.18,д); и их можно рассчитать путем сложения (по модулю 2) соответствующих коэффициентов из базисных элементов. Правила умножения, указанные в табл. 8.3, следуют из обычной процедуры, в которой произведение элементов поля вычисляются путем сложения по модулю ![]() их показателей степеней или, для данного случая, по модулю 7.
их показателей степеней или, для данного случая, по модулю 7.
Таблица 8.2. Таблица сложения для GF(8) при ![]()
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
Таблица 8.3. Таблица умножения для GF(8) при ![]()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8.1.4.4. Простой тест для проверки полинома на примитивность
Существует еще один, чрезвычайно простой способ проверки, является ли полином примитивным. У неприводимого полинома, который является примитивным, по крайней мере, хотя бы один из корней должен быть примитивным элементом. Примитивным элементом называется такой элемент поля, который, будучи возведенным в более высокие степени, даст ненулевые элементы поля. Поскольку данное поле является конечным, количество таких элементов также конечно.
Пример 8.2. Примитивный полином должен иметь, по крайней мере, хотя бы один примитивный элемент.
Найдите m = 3 корня полинома ![]() и определите, примитивен ли полином. Для этого проверьте, имеется ли среди корней полинома хотя бы один примитивный элемент. Каковы корни полинома? Какие из них примитивны?
и определите, примитивен ли полином. Для этого проверьте, имеется ли среди корней полинома хотя бы один примитивный элемент. Каковы корни полинома? Какие из них примитивны?
Решение
Корни будут найдены прямым перебором. Итак, ![]() не будет корнем, поскольку
не будет корнем, поскольку ![]() .Теперь, чтобы проверить, является ли корнем
.Теперь, чтобы проверить, является ли корнем ![]() , воспользуемся табл. 8.2. Поскольку
, воспользуемся табл. 8.2. Поскольку ![]() , значит,
, значит, ![]() будет корнем полинома. Далее проверим, будет ли корнем
будет корнем полинома. Далее проверим, будет ли корнем ![]() .
.![]() Значит, и
Значит, и ![]() также будет корнем полинома. Теперь проверим
также будет корнем полинома. Теперь проверим ![]() .
. ![]() Следовательно,
Следовательно, ![]() корнем полинома не является. Будет ли корнем
корнем полинома не является. Будет ли корнем ![]() ?
? ![]() Да,
Да, ![]() будет корнем полинома. Значит, корнями полинома
будет корнем полинома. Значит, корнями полинома ![]() будут
будут ![]() . Нетрудно убедиться, что, последовательно возводя в степень любой из этих корней, можно получить все 7 ненулевых элементов поля. Таким образом, все корни будут примитивными элементами. Поскольку в определении требуется, чтобы по крайней мере один из корней был примитивным, полином является примитивным.
. Нетрудно убедиться, что, последовательно возводя в степень любой из этих корней, можно получить все 7 ненулевых элементов поля. Таким образом, все корни будут примитивными элементами. Поскольку в определении требуется, чтобы по крайней мере один из корней был примитивным, полином является примитивным.
В этом примере описан относительно простой метод проверки полинома на примитивность. Для проверяемого полинома нужно составить регистр LFSR с контуром обратной связи, соответствующий коэффициентам полинома, как показана на рис. 8.8. Затем в схему регистра следует загрузить любое ненулевое состояние и выполнить за каждый такт правый сдвиг. Если за один период схема сгенерирует все ненулевые элементы поля, то данный полином с полем GF(![]() ) будет примитивным.
) будет примитивным.
8.1.5. Кодирование Рида-Соломона
В уравнении (8.2) представлена наиболее распространенная форма кодов Рида-Соломона через параметры n, k, t и некоторое положительное число m > 2. Приведем это уравнение повторно.
![]() (8.20)
(8.20)
Здесь ![]() - число контрольных символов, а t – количество ошибочных битов в символе, которые может исправить код. Генерирующий полином для кода Рида-Соломона имеет следующий вид.
- число контрольных символов, а t – количество ошибочных битов в символе, которые может исправить код. Генерирующий полином для кода Рида-Соломона имеет следующий вид.
![]() (8.21)
(8.21)
Степень полиномиального генератора равна числу контролируемых символов. Коды Рида-Соломона являются подмножеством кодов БЧХ, которые обсуждались в разделе 6.8.3. и показаны в табл. 6.4. Поэтому связь между степенью полиномиального генератора и числом контрольных символов, как и в кодах БЧХ, не должна оказаться неожиданностью. В этом можно убедиться, подвергнув проверке любой генератор из табл. 6.4. Поскольку полиномиальный генератор имеет порядок 2t, мы должны иметь в точности 2t последовательные степени ![]() , которые являются корнями полинома. Обозначим корни
, которые являются корнями полинома. Обозначим корни ![]() как:
как: ![]() . Нет необходимости начинать именно с корня
. Нет необходимости начинать именно с корня ![]() , это можно сделать с помощью любой степени
, это можно сделать с помощью любой степени ![]() . Возьмем, к примеру, код (7,3) с возможностью коррекции двухсимвольных ошибок. Мы выразим полиномиальный генератор через
. Возьмем, к примеру, код (7,3) с возможностью коррекции двухсимвольных ошибок. Мы выразим полиномиальный генератор через ![]() корня следующим образом.
корня следующим образом.
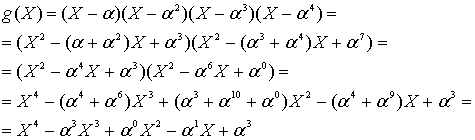
8.1.5.1. Кодирование в систематической форме
Так как код Рида-Соломона является циклическим, кодирование в систематической форме аналогично процедуре двоичного кодирования, разработанной в разделе 6.7.3. Мы можем осуществить сдвиг полинома сообщения m(X) в крайние правые k разряды регистра кодового слова и провести последующее прибавление полинома четности p(X) в крайние левые n – k разряды. Поэтому мы умножаем m(X) на ![]() , проделав алгебраическую операцию таким образом, что m(X) оказывается сдвинутым вправо на n – k позиций. В главе 6 это показано в уравнении (6.61) на примере двоичного кодирования. Далее мы делим
, проделав алгебраическую операцию таким образом, что m(X) оказывается сдвинутым вправо на n – k позиций. В главе 6 это показано в уравнении (6.61) на примере двоичного кодирования. Далее мы делим ![]() на полиномиальный генератор g(X), что можно записать следующим образом.
на полиномиальный генератор g(X), что можно записать следующим образом.
![]()
![]()
Здесь q(X) и p(X) – это частное и остаток от полиномиального деления. Как и в случае двоичного кодирования, остаток будет четным. Уравнение (8.23) можно представить следующим образом.
![]() (8.24)
(8.24)
Результирующий полином кодового слова U(X), показанный в уравнении (6.64), можно переписать следующим образом.
![]() (8.25)
(8.25)
Продемонстрируем шаги, подразумеваемые уравнениями (8.24) и (8.25), закодировав сообщение из трех символов
![]()
с помощью кода (7,3), генератор которого определяется уравнением (8.22). Сначала мы умножаем (сдвиг вверх) полином сообщения ![]() , что дает
, что дает ![]() Далее мы делим такой сдвинутый вверх полином сообщения на полиномиальный генератор из уравнения (8.22),
Далее мы делим такой сдвинутый вверх полином сообщения на полиномиальный генератор из уравнения (8.22), ![]() Полиномиальное деление недвоичных коэффициентов – это еще более утомительная процедура, чем ее двоичный аналог (см. пример 6.9), поскольку операции сложения (вычитания) и умножения (деления) выполняются согласно табл. 8.2 и 8.3. Мы оставим числителю в качестве вспомогательного упражнения проверку того, что полиномиальное деление даст в результате следующей полиномиальный остаток (полином четности).
Полиномиальное деление недвоичных коэффициентов – это еще более утомительная процедура, чем ее двоичный аналог (см. пример 6.9), поскольку операции сложения (вычитания) и умножения (деления) выполняются согласно табл. 8.2 и 8.3. Мы оставим числителю в качестве вспомогательного упражнения проверку того, что полиномиальное деление даст в результате следующей полиномиальный остаток (полином четности).
![]()
Заметим, из уравнения (8.25), полином кодового слова можно записать следующим образом.
![]()
8.1.5.2. Систематическое кодирование с помощью (n-k)-разрядного регистра сдвига
Как показано на рис. 8.9, кодирование последовательности из 3 символов в систематической форме на основе кода (7,3), определяемого генератором g(X) из уравнения (8.22), требует реализации регистра LFSR. Нетрудно убедиться, что элементы умножителя на рис. 8.9, взятые справа налево, соответствуют коэффициентам полинома в уравнении (8.22). Этот процесс кодирования является недвоичным аналогом циклического кодирования, которое описывалась в разделе 6.7.5. Здесь, в соответствии с уравнением (8.20), ненулевые кодовые слова образованы ![]() символами, и каждый символ состоит из m = 3 бит.
символами, и каждый символ состоит из m = 3 бит.
Следует отметить сходство между рис. 8.9, 6.18 и 6.19. Во всех трех случаях количество разрядов в регистре равно n – k. Рисунки в главе 6 отображают пример двоичного кодирования, где каждый разряд содержит 1 бит. В данной главе приведен пример двоичного кодирования, так что каждый разряд регистра сдвига, изображенного на рис. 8.9, содержит 3-битовый символ. На рис. 6.18 коэффициенты, обозначенные ![]() являются двоичными. Поэтому они принимают одно из значений 0 или 1, просто указывая на наличие или отсутствие связи в LFSR. На рис. 8.9 каждый коэффициент является 3-битовым, так что они могут принимать одно из 8 значений.
являются двоичными. Поэтому они принимают одно из значений 0 или 1, просто указывая на наличие или отсутствие связи в LFSR. На рис. 8.9 каждый коэффициент является 3-битовым, так что они могут принимать одно из 8 значений.
Недвоичные операции, осуществляемые кодером, показанным на рис. 8.9, создают кодовые слова в систематической форме, так же как и в двоичном случае. Эти операции определяются следующими шагами.
1. Переключатель 1 в течение первых k тактовых импульсов закрыт, для того чтобы подавать символы сообщения в (n - k)-разрядный регистр сдвига.
2. В течение первых k тактовых импульсов переключатель 2 находится в нижнем положении, что обеспечивает одновременную процедуру всех символов сообщения непосредственно на регистр выхода (на рис. 8.9 не показан).
3. После передачи k-го символа на регистр выхода, переключатель 1 открывается, а переключатель 2 переходит в верхнее положение.
4. Остальные (n-k) тактовых импульсов очищают контрольные символы, содержащиеся в регистре, подавая из на регистр выхода.
5. Общее число тактовых импульсов равно n, и содержимое регистра выхода является полиномом кодового слова ![]() , где p(X) представляет собой кодовые символы, а m(X) – символы сообщения в полиномиальной форме.
, где p(X) представляет собой кодовые символы, а m(X) – символы сообщения в полиномиальной форме.
Для проверки возьмем те же последовательность символов, что и в разделе 8.1.5.1.
![]()
Здесь крайний правый символ является самым первым и крайний правый бит также является самым первым. Последовательность действий в течение первых k = 3 сдвигов в цепи кодирования на рис. 8.9 будет иметь следующий вид.
Очередь ввода Такт Содержимое регистра обратная связь
|
|
|
|
0 |
0 |
0 |
0 |
0 |
|
|
|
|
1 |
|
|
|
|
|
|
|
|
2 |
|
0 |
|
|
|
||
|
- |
3 |
|
|
|
|
- |
Как можно видеть, после третьего такта регистр содержит 4 контрольных символа, ![]() . Затем переключатель 1 переходит в верхнее положение, и контрольные символы, содержащиеся в регистре, подаются на выход. Поэтому выходное слово, записанное в полиномиальной форме, можно представить в следующим виде.
. Затем переключатель 1 переходит в верхнее положение, и контрольные символы, содержащиеся в регистре, подаются на выход. Поэтому выходное слово, записанное в полиномиальной форме, можно представить в следующим виде.
![]()
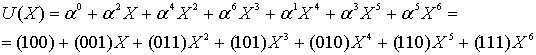 (8.26)
(8.26)
Процесс проверки содержимого регистра во время разных тактов несколько сложнее, чем в случае бинарного кодирования. Здесь сложение и умножение элементов поля должны выполняться согласно табл. 8.2 и 8.3.
Корни полиномиального генератора g(X) должны быть и корнями кодового слова, генерируемого g(X), поскольку правильное кодовое слово имеет следующий вид.
![]() (8.27)
(8.27)
Следовательно, произвольное кодовое слово, выражаемое через корень генератора g(X), должно давать нуль. Представляется интересным, действительно ли полином кодового слова в уравнении (8.26) дает нуль, когда он выражается через какой-либо из четырех корней g(X). Иными словами, это означает проверку следующего.
![]()
Независимо выполнив вычисления для разных корней, получим следующее.
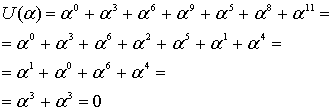
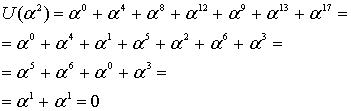
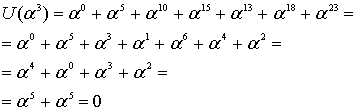
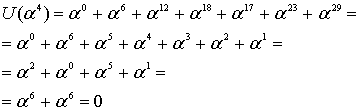
Эти вычисления показывают, что, как и ожидалось, кодовое слово, выражаемое через любой корень генератора g(X), должно давать нуль.
8.1.6. Декодирование Рида-Соломона
В разделе 8.1.5 тестовое сообщение кодируется в систематической форме с помощью кода (7,3), что дает в результате полином кодового слова, описываемый уравнением (8.26). Допустим, что в ходе передачи это кодовое слово подверглось искажению: 2 символа были приняты с ошибкой. (Такое количество ошибок соответствует максимальной способности кода к коррекции ошибок.) При использовании 7-символьного кодового слова ошибочную комбинацию можно представить в полиномиальной форме следующим образом.
![]() (8.28)
(8.28)
Пусть двухсимвольная ошибка будет такой, что
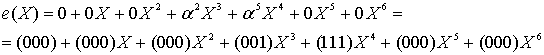 (8.29)
(8.29)
Другими словами, контрольный символ искажен 1-битовой ошибкой (представленной как ![]() ), а символ сообщения — 3-битовой ошибкой (представленной как
), а символ сообщения — 3-битовой ошибкой (представленной как ![]() ). В данном случае принятый полином поврежденного кодового слова r(Х) представляется в виде суммы полинома переданного кодового слова и полинома ошибочной комбинации, как показано ниже.
). В данном случае принятый полином поврежденного кодового слова r(Х) представляется в виде суммы полинома переданного кодового слова и полинома ошибочной комбинации, как показано ниже.
![]()
![]() (8.30)
(8.30)
Следуя уравнению (8.30), мы суммируем U(X) из уравнения (8.26) и e(Х) из уравнения (8.29) и имеем следующее.
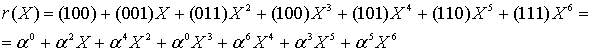 (8.31)
(8.31)
В данном примере исправления 2-символьной ошибки имеется четыре неизвестных — два относятся к расположению ошибки, а два касаются ошибочных значений. Отметим важное различие между недвоичным декодированием r(Х), которое мы показали в уравнении (8.31), и двоичным, которое описывалось в главе 6. При двоичном декодировании декодеру нужно знать лишь расположение ошибки. Если известно, где находится ошибка, бит нужно поменять с 1 на 0 или наоборот. Но здесь недвоичные символы требуют, чтобы мы не только узнали расположение ошибки, но и определили правильное значение символа, расположенного на этой позиции. Поскольку в данном примере у нас имеется четыре неизвестных, нам нужно четыре уравнения, чтобы найти их.
8.1.6.1. Вычисление синдрома
Вернемся к разделу 6.4.7 и напомним, что синдром — это результат проверки четности, выполняемой над r, чтобы определить, принадлежит ли r набору кодовых слов. Если r является членом набора, то синдром S имеет значение, равное 0. Любое ненулевое значение S означает наличие ошибок. Точно так же, как и в двоичном случае, синдром S состоит из n-k символов, ![]()
![]() . Таким образом, для нашего кода (7, 3) имеется по четыре символа в каждом векторе синдрома; их значения можно рассчитать из принятого полинома r(Х). Заметим, кдк облегчаются вычисления благодаря самой структуре кода, определяемой уравнением (8.27).
. Таким образом, для нашего кода (7, 3) имеется по четыре символа в каждом векторе синдрома; их значения можно рассчитать из принятого полинома r(Х). Заметим, кдк облегчаются вычисления благодаря самой структуре кода, определяемой уравнением (8.27).
![]()
Из этой структуры можно видеть, что каждый правильный полином кодового слова U(X) является кратным полиномиальному генератору g(X). Следовательно, корни g(X) также должны быть корнями U(X). Поскольку ![]() , то r(Х), вычисляемый с каждым корнем g(X), должен давать нуль, только если r(Х) будет правильным кодовым словом. Любые ошибки приведут в итоге к ненулевому результату в одном (или более) случае. Вычисления символов синдрома можно записать следующим образом.
, то r(Х), вычисляемый с каждым корнем g(X), должен давать нуль, только если r(Х) будет правильным кодовым словом. Любые ошибки приведут в итоге к ненулевому результату в одном (или более) случае. Вычисления символов синдрома можно записать следующим образом.
![]() (8.32)
(8.32)
Здесь, как было показано в уравнении (8.29), r(Х) содержит 2-символьные ошибки. Если r(Х) окажется правильным кодовым словом, то это приведет к тому, что все символы синдрома ![]() будут равны нулю. В данном примере четыре символа синдрома находятся следующим образом.
будут равны нулю. В данном примере четыре символа синдрома находятся следующим образом.
![]()
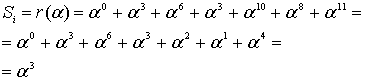 (8.33)
(8.33)
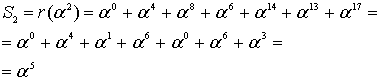 (8.34)
(8.34)
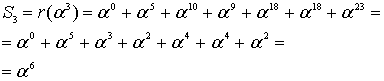 (8.35)
(8.35)
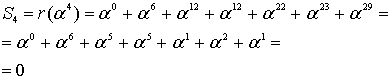 (8.36)
(8.36)
Результат подтверждает, что принятое кодовое слово содержит ошибку (введенную нами), поскольку ![]() .
.
Пример 8.3. Повторная проверка значений синдрома
Для рассматриваемого кода (7, 3) ошибочная комбинация известна, поскольку мы выбрали ее заранее. Вспомним свойство кодов, обсуждаемое в разделе 6.4.8.1, когда была введена нормальная матрица. Все элементы класса смежности (строка) нормальной матрицы имеют один и тот же синдром. Нужно показать, что это свойство справедливо и для кода Рида-Соломона, путем вычисления полинома ошибок e(Х) со значениями корней g(X). Это должно дать те же значения синдрома, что и вычисление r(Х) со значениями корней g(X). Другими словами, это должно дать те же значения, которые были получены в уравнениях (8.33)-(8.36).
Решение
![]()
![]()
![]()
Из уравнения (8.29) следует, что ![]() , поэтому
, поэтому
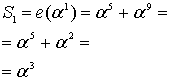
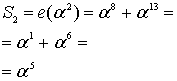
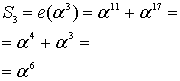
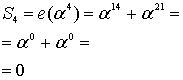
Из этих результатов можно заключить, что значения синдрома одинаковы — как полученные путем вычисления e(Х) со значениями корней g(X), так и полученные путем вычисления r(Х) с теми же значениями корней g(X).
8.1.6.2. Локализация ошибки
Допустим, в кодовом слове имеется ![]() ошибок, расположенных на позициях
ошибок, расположенных на позициях ![]() . Тогда полином ошибок, определяемый уравнениями (8.28) и (8.29), можно записать следующим образом.
. Тогда полином ошибок, определяемый уравнениями (8.28) и (8.29), можно записать следующим образом.
![]() (8.37)
(8.37)
Индексы 1, 2, ..., ![]() обозначают 1-ю, 2-ю, ...,
обозначают 1-ю, 2-ю, ..., ![]() -ю ошибки, а индекс
-ю ошибки, а индекс ![]() — расположение ошибки. Для коррекции искаженного кодового слова нужно определить каждое значение ошибки
— расположение ошибки. Для коррекции искаженного кодового слова нужно определить каждое значение ошибки ![]() и ее расположение
и ее расположение ![]() , где
, где ![]() . Обозначим номер локатора ошибки как
. Обозначим номер локатора ошибки как ![]() . Далее вычисляем
. Далее вычисляем ![]() символа синдрома, подставляя
символа синдрома, подставляя ![]() в принятый полином при
в принятый полином при ![]() .
.
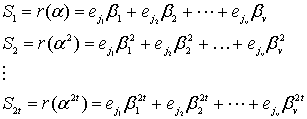 (8.38)
(8.38)
У нас имеется 2t неизвестных (t значений ошибок и t расположений) и система 2t уравнений. Впрочем, эту систему 2t уравнений нельзя решить обычным путем, поскольку уравнения в ней нелинейны (некоторые неизвестные входят в уравнение в степени). Методика, позволяющая решить эту систему уравнений, называется алгоритмом декодирования Рида-Соломона.
Если вычислен ненулевой вектор синдрома (один или более его символов не равны нулю), это означает, что была принята ошибка. Далее нужно узнать расположение ошибки (или ошибок). Полином локатора ошибок можно определить следующим образом.
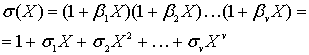 (8.39)
(8.39)
Корнями ![]() будут
будут ![]() . Величины, обратные корням
. Величины, обратные корням ![]() , будут представлять номера расположений ошибочной комбинации e(Х). Тогда, воспользовавшись авторегрессионной техникой моделирования [5], мы составим из синдромов матрицу, в которой первые t синдромов будут использоваться для предсказания следующего синдрома.
, будут представлять номера расположений ошибочной комбинации e(Х). Тогда, воспользовавшись авторегрессионной техникой моделирования [5], мы составим из синдромов матрицу, в которой первые t синдромов будут использоваться для предсказания следующего синдрома.
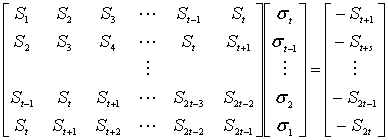 (8.40)
(8.40)
Мы воспользовались авторегрессионной моделью уравнения (8.40), взяв матрицу наибольшей размерности с ненулевым определителем. Для кода (7, 3) с коррекцией двухсимвольных ошибок матрица будет иметь размерность ![]() , и модель запишется следующим образом.
, и модель запишется следующим образом.
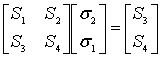 (8.41)
(8.41)
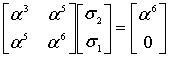 (8.42)
(8.42)
Чтобы найти коэффициенты ![]() и
и ![]() полинома локатора ошибок
полинома локатора ошибок ![]() ,. сначала необходимо вычислить обратную матрицу для уравнения (8.42). Обратная матрица для матрицы [А] определяется следующим образом.
,. сначала необходимо вычислить обратную матрицу для уравнения (8.42). Обратная матрица для матрицы [А] определяется следующим образом.
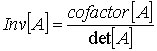
Следовательно,
det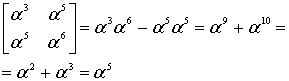 (8.43)
(8.43)
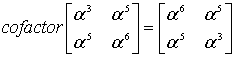 (8.44)
(8.44)
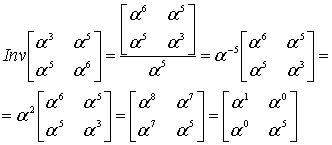 (8.45)
(8.45)
Проверка надежности
Если обратная матрица вычислена правильно, то произведение исходной и обратной матрицы должно дать единичную матрицу.
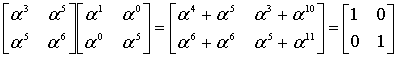 (8.46)
(8.46)
С помощью уравнения (8.42) начнем поиск положений ошибок с вычисления коэффициентов полинома локатора ошибок ![]() , как показано далее.
, как показано далее.
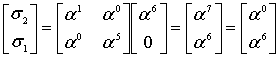 (8.47)
(8.47)
Из уравнений (8.39) и (8.47)
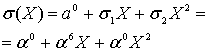 (8.48)
(8.48)
Корни ![]() являются обратными числами к положениям ошибок. После того как эти корни найдены, мы знаем расположение ошибок. Вообще, корни
являются обратными числами к положениям ошибок. После того как эти корни найдены, мы знаем расположение ошибок. Вообще, корни ![]() могут быть одним или несколькими элементами поля. Определим эти корни путем полной проверки полинома
могут быть одним или несколькими элементами поля. Определим эти корни путем полной проверки полинома ![]() со всеми элементами поля, как будет показано ниже. Любой элемент X, который дает
со всеми элементами поля, как будет показано ниже. Любой элемент X, который дает ![]() , является корнем, что позволяет нам определить расположение ошибки.
, является корнем, что позволяет нам определить расположение ошибки.
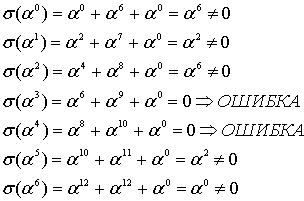
Как видно из уравнения (8.39), расположение ошибок является обратной величиной к корням полинома. А значит, ![]() означает, что один корень получается при
означает, что один корень получается при ![]() . Отсюда
. Отсюда ![]() . Аналогично
. Аналогично ![]() означает, что другой корень появляется при
означает, что другой корень появляется при ![]() , где (в данном примере)
, где (в данном примере) ![]() и
и ![]() обозначают 1-ю и 2-ю ошибки. Поскольку мы имеем дело с 2-символьными ошибками, полином ошибок можно записать следующим образом.
обозначают 1-ю и 2-ю ошибки. Поскольку мы имеем дело с 2-символьными ошибками, полином ошибок можно записать следующим образом.
![]() (8.49)
(8.49)
Здесь были найдены две ошибки на позициях ![]() и
и ![]() . Заметим, что индексация номеров расположения ошибок является сугубо произвольной. Итак, в этом примере мы обозначили величины
. Заметим, что индексация номеров расположения ошибок является сугубо произвольной. Итак, в этом примере мы обозначили величины ![]() как
как ![]()
![]() и
и ![]() .
.
8.1.6.3. Значения ошибок
Мы обозначили ошибки ![]() , где индекс j обозначает расположение ошибки, а индекс l — l-ю ошибку. Поскольку каждое значение ошибки связано с конкретным меcторасположением, систему обозначений можно упростить, обозначив
, где индекс j обозначает расположение ошибки, а индекс l — l-ю ошибку. Поскольку каждое значение ошибки связано с конкретным меcторасположением, систему обозначений можно упростить, обозначив ![]() просто как
просто как ![]() . Теперь, приготовившись к нахождению значений ошибок
. Теперь, приготовившись к нахождению значений ошибок ![]() и
и ![]() , связанных с позициями
, связанных с позициями ![]() и
и ![]() можно использовать любое из четырех синдромных уравнений. Выразим из уравнения (8.38)
можно использовать любое из четырех синдромных уравнений. Выразим из уравнения (8.38) ![]() , и
, и ![]() .
.
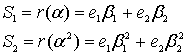 (8.50)
(8.50)
Эти уравнения можно переписать в матричной форме следующим образом.
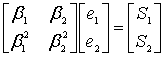 (8.51)
(8.51)
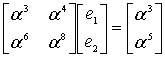 (8.52)
(8.52)
Чтобы найти значения ошибок ![]() и
и ![]() , нужно, как обычно, выполнить поиск обратной матрицы для уравнения (8.52).
, нужно, как обычно, выполнить поиск обратной матрицы для уравнения (8.52).
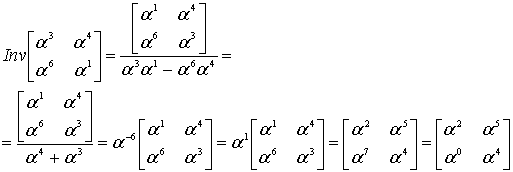 (853)
(853)
Теперь мы можем найти из уравнения (8.52) значения ошибок.
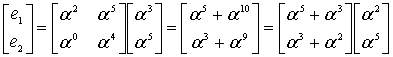 (8.54)
(8.54)
8.1.6.4. Исправление принятого полинома с помощью найденного полинома ошибок
Из уравнений (8.49) и (8.54) мы находим полином ошибок.
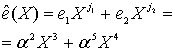 (8.55)
(8.55)
Показанный алгоритм восстанавливает принятый полином, выдавая в итоге предполагаемое переданное кодовое слово и, в конечном счете, декодированное сообщение.
![]() (8.56)
(8.56)
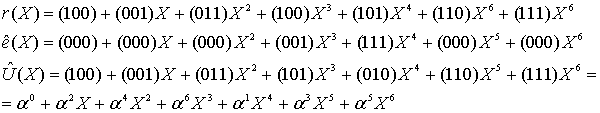 (8.57)
(8.57)
Поскольку символы сообщения содержатся в крайних правых k = 3 символах, декодированным будет следующее сообщение.
![]()
![]()
![]()
Это сообщение в точности соответствует тому, которое было выбрано для этого примера в разделе 8.1.5. (Для более детального знакомства с кодированием Рида-Соломона обратитесь к работе [6].)
8.2. Коды с чередованием и каскадные коды
В предыдущих главах мы подразумевали, что у канала отсутствует память, поскольку рассматривались коды, которые должны были противостоять случайным независимым ошибкам. Канал с памятью — это такой канал, в котором проявляется взаимная зависимость ухудшений передачи сигнала. Канал, в котором проявляется замирание вследствие многолучевого распространения, когда сигнал поступает на приемник по двум или более путям различной длины, есть примером канала с памятью. Следствием является различная фаза сигналов, и в итоге, суммарный сигнал оказывается искаженным. Таким эффектом обладают каналы мобильной беспроводной связи, так же как ионосферные и тропосферные каналы. (Более подробно о замирании см. главу 15.) В некоторых каналах также имеются коммутационные и другие импульсные помехи (например, телефонные каналы или каналы с создаваемыми импульсными помехами). Все эти ухудшения коррелируют во времени и, в результате, дают статистическую взаимную зависимость успешно переданных сигналов. Иными словами, искажения вызывают ошибки, имеющие вид пакетов, а не отдельных изолированных ошибок.
Если канал имеет память, то ошибки не являются независимыми, одиночными и случайно распределенными. Большинство блочных и сверточных кодов разрабатывается для борьбы с независимыми случайными ошибками. Влияние канала с памятью на кодированный таким образом сигнал приведет к ухудшению достоверности передачи. Существуют схемы кодирования для каналов с памятью, но наибольшую проблему в этом кодировании представляет расчет точных моделей сильно нестационарных статистик таких каналов. Один подход, при котором требуется знать только объем памяти канала, а не его точное статистическое описание, использует временное разнесение, или чередование битов.
Чередование битов кодированного сообщения перед передачей и обратная операция после приема приводят к рассеиванию пакета ошибок во времени: таким образом, они становятся для декодера случайно распределенными. Поскольку в реальной ситуации память канала уменьшается с временным разделением, идея, лежащая в основе метода чередования битов, заключается в разнесении символов кодовых слов во времени. Получаемые промежутки времени точно так же заполняются символами других кодовых слов. Разнесение символов во времени эффективно превращает канал с памятью в канал без памяти и, следовательно, позволяет использовать коды с коррекцией случайных ошибок в канале с импульсными помехами.
Устройство чередования смешивает кодовые символы в промежутке нескольких длин блоков (для блочных кодов) или нескольких длин кодового ограничения (для сверточных кодов). Требуемый промежуток определяется длительностью пакета., Подробности структуры битового перераспределения должны быть известны приемнику, чтобы иметь возможность выполнить восстановление порядка битов перед декодированием. На рис. 8.10 показан простой пример чередования. На рис. 8.10, а мы можем видеть кодовые слова, которые еще не подвергались описанной операции, от A до G. Каждое кодовое слово состоит из семи кодовых символов. Пусть наш код может исправлять однобитовые ошибки в любой 7-символьной последовательности. Если промежуток памяти канала равен длительности одного кодового слова, такой пакет, длительностью в семь символов, может уничтожить информацию в одном или двух кодовых словах. Тем не менее допустим, что после получения кодированных данных кодовые символы затем перемешиваются, как показано на рис. 8.10, б. Иными словами, каждый кодовый символ каждого кодового слова отделяется от своего соседа на расстояние из семи символьных периодов. Полученный поток затем преобразуется в модулированный сигнал и передается по каналу. Как можно видеть на рис. 8.10, 6, последовательные канальные пакеты шума попадают на семь символьных промежутков, влияя на один кодовый символ каждого из семи исходных кодовых слов. Во время приема в потоке вначале восстанавливается исходный порядок битов, так что он становится похож на исходную кодированную последовательность, изображенную на рис. 8.10, а. Затем поток декодируется. Поскольку в каждом кодовом слове возможно исправление одиночной ошибки, импульсная помеха не оказывает никакого влияния на конечную последовательность.
Идея чередования битов используется во всех блочных и сверточных кодах, рассмотренных здесь и ранее в предыдущих главах. Обычно применяются два типа устройств чередования — блочные и сверточные (оба рассматриваются далее).

8.2.1. Блочное чередование
Блочное устройство чередования принимает кодированные символы блоками от кодера, переставляет их, а затем передает измененные символы на модулятор. Как правило, перестановка блоков завершается заполнением столбцов матрицы М строками и N столбцами (![]() ) кодированной последовательности. После того как матрица полностью заполнена, символы подаются на модулятор (по одной строке за раз), а затем передаются по каналу. В приемнике устройство восстановления выполняет обратные операции; оно принимает символы из демодулятора, восстанавливает исходный порядок битов и передает их на декодер. Символы поступают в массив устройства восстановления по строкам и заменяются столбцами. На рис. 8.11, а приведен пример устройства чередования с М = 4 строками и N = 6 столбцами. Записи в массиве отображают порядок, в котором 24 кодовых символа попадают в устройство чередования. Выходная последовательность, предназначенная для передатчика, состоит из кодовых символов, которые построчно удалены из массива, как показано на рисунке. Ниже перечисляются наиболее важные характеристики такого блочного устройства.
) кодированной последовательности. После того как матрица полностью заполнена, символы подаются на модулятор (по одной строке за раз), а затем передаются по каналу. В приемнике устройство восстановления выполняет обратные операции; оно принимает символы из демодулятора, восстанавливает исходный порядок битов и передает их на декодер. Символы поступают в массив устройства восстановления по строкам и заменяются столбцами. На рис. 8.11, а приведен пример устройства чередования с М = 4 строками и N = 6 столбцами. Записи в массиве отображают порядок, в котором 24 кодовых символа попадают в устройство чередования. Выходная последовательность, предназначенная для передатчика, состоит из кодовых символов, которые построчно удалены из массива, как показано на рисунке. Ниже перечисляются наиболее важные характеристики такого блочного устройства.
1. Пакет, который содержит меньше N последовательных канальных символов, дает на выходе устройства восстановления исходного порядка символов ошибки, разнесенные между собой, по крайней мере, на М символов.
2. Пакет из bN ошибок, где ![]() , дает на выходе устройства восстановления пакет, который содержит не меньше [b] символьных ошибок. Каждый из пакетов ошибок отделен от другого не меньше, чем на
, дает на выходе устройства восстановления пакет, который содержит не меньше [b] символьных ошибок. Каждый из пакетов ошибок отделен от другого не меньше, чем на ![]() символов. Запись [x] означает наименьшее целое число, не меньшее х, а запись [x] — наибольшее целое число, не превышающее х.
символов. Запись [x] означает наименьшее целое число, не меньшее х, а запись [x] — наибольшее целое число, не превышающее х.
3. Периодическая последовательность одиночных ошибок, разделенных N символами, дает на выходе устройства восстановления одиночные пакеты ошибок длиной М.
4. Прямая задержка между устройствами чередования и восстановления равна приблизительно длительности 2MN символов. Если быть точным, перед тем как начать передачу, нужно заполнить лишь ![]() ячеек памяти (как только будет внесен первый символ последнего столбца массива
ячеек памяти (как только будет внесен первый символ последнего столбца массива ![]() ). Соответствующее время нужно приемнику, чтобы начать декодирование. Значит, минимальная прямая задержка будет составлять длительность
). Соответствующее время нужно приемнику, чтобы начать декодирование. Значит, минимальная прямая задержка будет составлять длительность ![]() символов, не учитывая задержку на передачу по каналу.
символов, не учитывая задержку на передачу по каналу.
5. Необходимая память составляет MN символов для каждого объекта (устройств чередования и восстановления исходного порядка). Однако массив ![]() нужно заполнить (по большей части) до того, как он будет считан. Для каждого объекта нужно предусмотреть память для 2MN символов, чтобы опорожнить массив
нужно заполнить (по большей части) до того, как он будет считан. Для каждого объекта нужно предусмотреть память для 2MN символов, чтобы опорожнить массив ![]() , пока другой будет наполняться, и наоборот.
, пока другой будет наполняться, и наоборот.
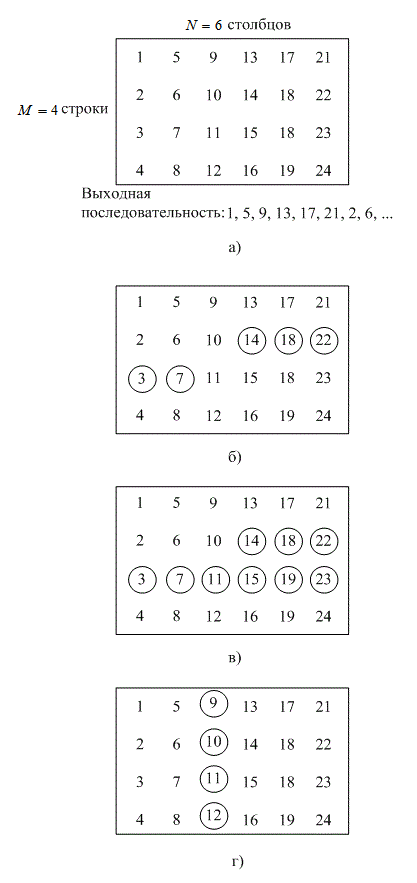
Пример 8.4. Характеристики устройств чередования
Используя структуру устройства чередования с M = 4, N = 6, изображенную на рисунке 8.11, a, проверьте описанные выше характеристики.
Решение
1.Пусть имеется пакет шума длительностью в пять символьных интервалов; так, что символы, выделенные на рис. 8.11,б, подвергнуться искажению во время передачи. После восстановления исходного порядка битов в приемнике, последовательность принимает следующий вид.
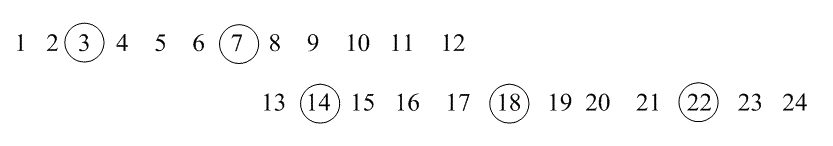
Здесь выделенные символы являются ошибочными. Можно видеть, что, минимальное расстояние, разделяющее символы с ошибками, равно M = 4.
2.Пусть b = 1,5, так что bN = 9. Пример девятисимвольного пакета ошибок можно видеть на рис. 8.11, в. После того как в приемнике проведена процедура восстановления исходного порядка, последовательность примет следующий виц.
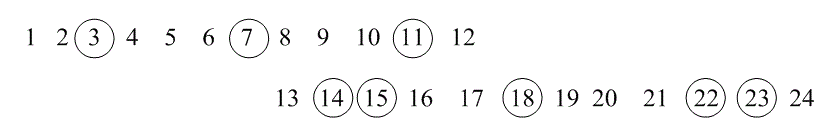
Снова выделенные символы являются ошибочными. Здесь можно видеть, что пакеты содержат не больше [1,5] = 2 символов подряд и разнесены, по крайней мере, на [1,5] = 4 – 1 = 3 символа.
3.На рис. 8.11, г показана последовательность одиночных ошибок, разделенных (каждый по отдельности) N = 6 символами. После восстановления исходного порядка в приемнике, последовательность принимает следующий вид.
![]()
Можно видеть, что после этого последовательность содержит пакет одиночных ошибок длиной M = 4 символа.
4. Прямая задержка: минимальная прямая задержка, вызванная обоими устройствами, составляет ![]() символьных периода.
символьных периода.
5. Требуемый объем памяти: размерность массивов устройств чередования и восстановления составляет ![]() . Значит, требуется объем памяти для хранения MN = 24 символов на обоих концах канала. Как упоминалось ранее, в общем случае память реализуется для хранения 2MN = 48 символов.
. Значит, требуется объем памяти для хранения MN = 24 символов на обоих концах канала. Как упоминалось ранее, в общем случае память реализуется для хранения 2MN = 48 символов.
Как правило, параметры устройства чередования, используемого совместно с кодом с коррекцией одиночных ошибок, выбираются таким образом, чтобы число столбцов N превышало ожидаемую длину пакета. Выбираемое число строк зависит от того, какая схема кодирования будет использована. Для блочных кодов М должно быть больше длины кодового блока; для сверточных кодов М должно превышать длину кодового ограничения. Поэтому пакет длиной N может вызвать в блоке кода (самое большее) одиночную ошибку; аналогично в случае сверточных кодов в пределах одной длины кодового ограничения будет не более одной ошибки. Для кодов с коррекцией ошибок кратности t, выбираемое N должно лишь превышать ожидаемую длину пакета, деленную на t.
8.2.2. Сверточное чередование
Сверточные устройства чередования были предложены Рамси (Ramsey) [7] и Форни (Forney) [8]. Схема, предложенная Форни, показана на рис. 8.12. Кодовые символы послдовательно подаются в блок из N регистров; каждый последующий регистр может хранить на J символов больше, чем предыдущий. Нулевой регистр не предназначен для хранения (символ сразу же передается). С каждым новым кодовым символом коммутатор переключается на новый регистр, и кодовый символ подается на него до тех пор, пока наиболее старый кодовый символ в регистре не будет передан на модулятор/передатчик. После ![]() -го регистра коммутатор возвращается к нулевому регистру и повторяет все снова. После приема операции повторяются в обратном порядке. И вход, и выход устройств чередования и восстановления должны быть синхронизированы.
-го регистра коммутатор возвращается к нулевому регистру и повторяет все снова. После приема операции повторяются в обратном порядке. И вход, и выход устройств чередования и восстановления должны быть синхронизированы.
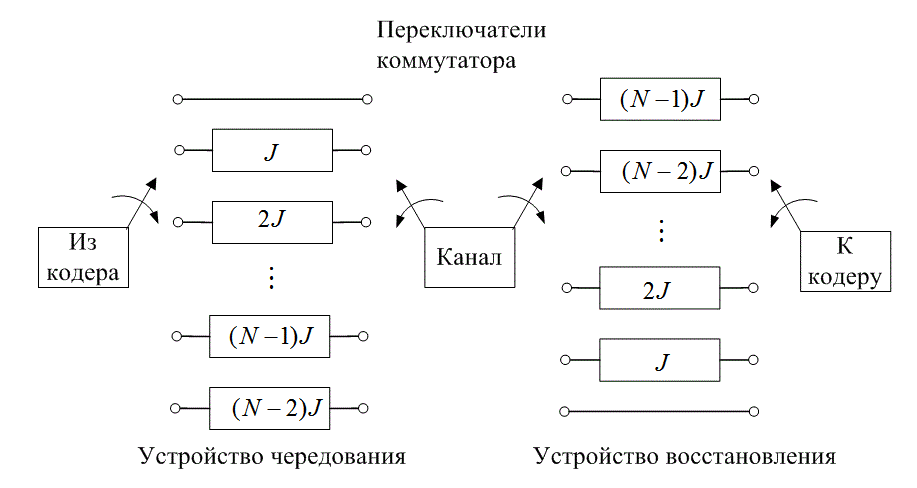
Рис. 8. 12. Реализация регистра сдвига для сверточного устройства чередования/восстановления
На рис. 8.13 показан пример простого сверточного четырехрегистрового (У= 1) устройства чередования, загруженного последовательностью кодовых символов. Одновременно представлено синхронизированное устройство восстановления, которое передает обработанные символы на декодер. На рис. 8.13, а показана загрузка символов 1-4; знак "х" означает неизвестное состояние. На рис. 8.13, б представлены первые четыре символа, подаваемые в регистры, и показана передача символов 5—8 на выход устройства чередования. На рис. 8.13, в показаны поступающие в устройство символы 9—12. Теперь устройство восстановления заполнено символами сообщения, но еще не способно ничего передавать на декодер. И наконец, на рис. 8.13, г показаны символы 13-16, поступившие в устройство чередования, и символы 1—4, переданные на декодер. Процесс продолжается таким образом до тех пор, пока полная последовательность кодового слова не будет передана на декодер в своей исходной форме.
Рабочие характеристики сверточного устройства чередования сходны с параметрами блочного устройства. Важным преимуществом сверточного устройства перед блочным является то, что при сверточном чередовании прямая задержка составляет M(N-l) символов при M = NJ, а требуемые объемы памяти— ![]() на обоих концах канала. Очевидно, что требования к памяти и время задержки снижаются вдвое, по сравнению с блочным чередованием [9].
на обоих концах канала. Очевидно, что требования к памяти и время задержки снижаются вдвое, по сравнению с блочным чередованием [9].
8.2.3. Каскадные коды
Каскадными называются коды, в которых кодирование осуществляется в два уровня; имеется внутренний и внешний коды, с помощью которых и достигается желаемая надежность передачи сообщений. На рис. 8.14 изображен порядок кодирования и декодирования. Внутренний код связан с модулятором. Демядулятор, как правило, настраивается для исправления большинства канальных ошибок. Внешний код, чаще всего высокоскоростной (с низкой избыточностью), снижает вероятность появления ошибок до заданного значения. Основной причиной использования каскадного кода является низкая степень кодирования и общая сложность реализации, меньшая той, которая потребовалась бы для осуществления отдельной процедуры кодирования. На рис. 8.14 между двумя этапами кодирования располагается устройство чередования. Обычно это делается для того, чтобы разнести пакетные ошибки, которые могли бы появиться в результате внутреннего кодирования.
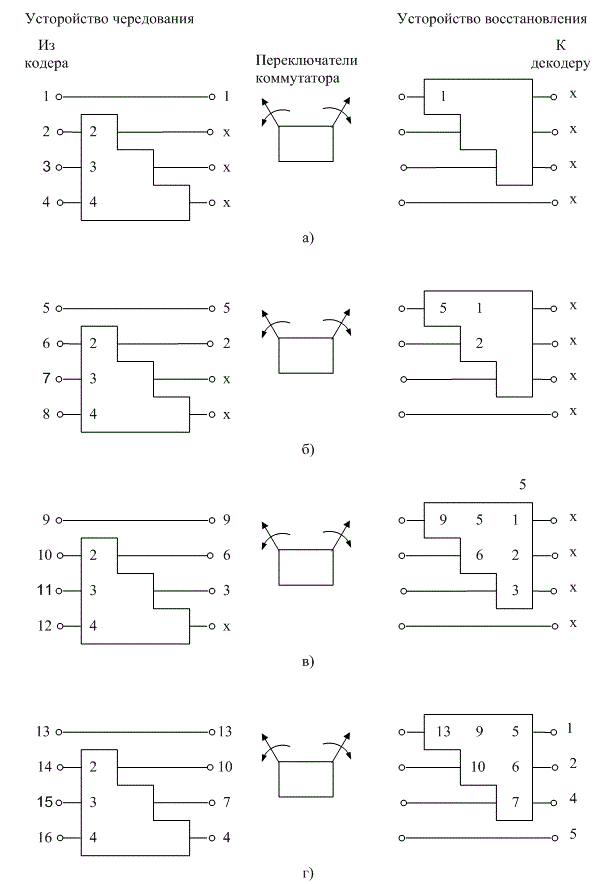
Рис. 8.13. Пример сверточного чередования/восстановления
В одной из наиболее популярных систем каскадного кодирования для внутреннего кода применяется сверточное кодирование по алгоритму Витерби, а для внешнего — код Рида-Соломона с чередованием между двумя этапами кодирования [2]. Функционирование таких систем при ![]() , находящемся в пределах от 0,2 до 2,5 дБ, для достижения
, находящемся в пределах от 0,2 до 2,5 дБ, для достижения ![]() реально достижимо в прикладных задачах [9]. В этой системе демодулятор выдает мягко квантованные кодовые символы на внутренний свёрточный декодер, который, в свою очередь, выдает жестко квантованные кодовые символы с пакетными ошибками на декодер Рида-Соломина.
реально достижимо в прикладных задачах [9]. В этой системе демодулятор выдает мягко квантованные кодовые символы на внутренний свёрточный декодер, который, в свою очередь, выдает жестко квантованные кодовые символы с пакетными ошибками на декодер Рида-Соломина.
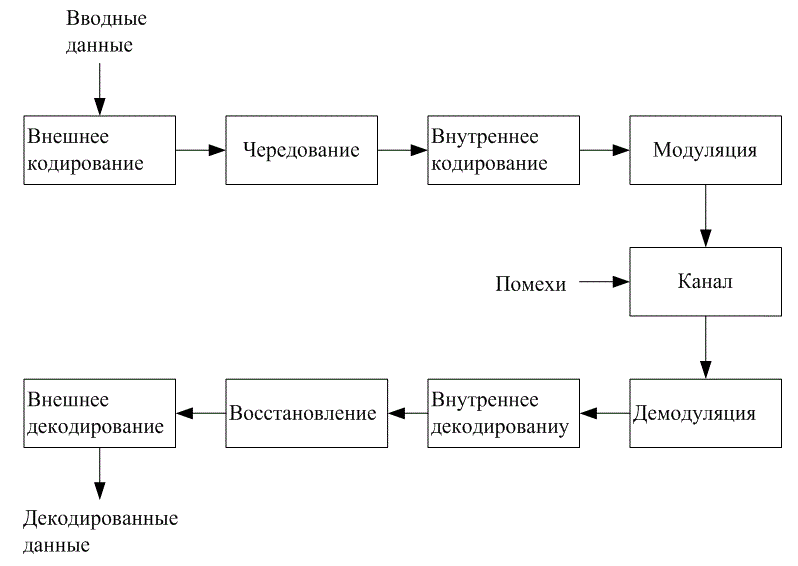
Рис. 8.14. Блочная диаграмма каскадной системы кодирования
(В системе декодирования по алгоритму Витерби выходные ошибки имеют тенденцию к появлению пакетами.) Внешний код Рида-Соломона образуется из m-битовых сегментов двоичного потока данных. Производительность такого (недвоичного) кода Рида-Соломона зависит только от числа символьных ошибок в блоке. Код не искажается пакетами ошибок внутри m-битового символа. Иными словами, для данной символьной ошибки производительность кода Рида-Соломона такова, как если бы символьная ошибка была вызвана одним битом или т бит. Тем не менее производительность каскадных систем несколько ухудшается за счет коррелирующих ошибок в последовательных символах. Поэтому чередование между кодированиями нужно выполнять на уровне символов (а не битов). Работа [10] представляет собой обзор каскадных кодов, которые были разработаны для дальней космической связи. В следующем разделе мы рассмотрим распространенную практическую реализацию символьного чередования в каскадных системах.
8.3. Кодирование и чередование в системах цифровой записи информации на компакт-дисках
В 1979 году компании Philips Corp. (Нидерланды) и Sony Corp. (Япония) запатентовали стандарт хранения и воспроизведения цифровой записи аудиосигналов, известный как система цифровой записи на компакт-дисках (compact disc digital audio — CD-DA). Эта система стала мировым стандартом, позволяющим достичь безукоризненнбй точности воспроизведения звука, и опередила другие методики. Для хранения оцифрованных аудиосигналов используется пластиковый диск диаметром 120 мм. Сигнал дискретизирован с частотой 44100 фрагментов/с для получения записи в полосе 20 кГц. Каждый аудиофрагмент однозначно квантован на один из 216 уровней (16 бит/фрагмент), что дает в результате динамический диапазон в 96 дБ и нелинейное искажение 0,005%. Отдельный диск (время звучания составляет порядка 70 минут) хранит порядка ![]() бит в виде коротких впадин, которые сканируются лазером.
бит в виде коротких впадин, которые сканируются лазером.
В данном случае существует несколько источников канальных ошибок: 1) маленькие нежелательные частички или воздушные пузырьки в материале пластика или неточное расположение впадин при изготовлении диска; 2) отпечатки пальцев или царапины, появившиеся при эксплуатации. Трудно предсказать, как в среднем можно поделить крмпакт-диск; но при наличии точной канальной модели можно со всей уверенностью сказать, что канал, в основном, склонен, вносить пакетоподобные ошибки, Поскольку царапины или пятна от пальцев будут вызывать ошибки в нескольких последовательных фрагментах данных. Важным элементом разработки системы получения, высококачественных характеристик является каскадная схема защиты от ошибок, которая называется кодом Рида-Соломона с перекрестным чередованием.(cross-interleave Reed-Solomon code — CIRC). Данные перемешиваются во времени так, что знаки, выходящие из последовательных фрагментов сигнала, оказываются разнесенными во времени. Таким образом, появление ошибок представляется в виде единичных случайных ошибок (см. предыдущий раздел). Цифровая информация, защищена посредством прибавления байтов четности, получаемых в двух кодерах Рида-Соломона. Защита от ошибок, осуществляемая на компакт-дисках, зависит обычно от кодирования Рида-Соломона и алгоритма чередования.
В прикладных задачах передачи цифровой аудиоинформации, невыявляемая ошибка декодирования очень значительна, поскольку является результатом щелчка при воспроизведении, в то время как выявляемые ошибки незначительны, так как их можно скрыть. Схема защиты от ошибок CIRC в системе CD-DA включает в себя и исправление, и маскировку ошибок. Технические характеристики схемы CIRC даются в табл. 8.4. Из данных таблицы должно быть ясно, что компакт-диск может выдержать сильные повреждения (например, 8-миллиметровые отверстия, пробитые в диске) без значительных потерь в качестве звучания.
Таблица 8.4. Спецификация кода Рида-Соломона с перекрестным уродованием, применяемого в аудиокомпакт-дисках
|
Максимальная длина исправимого пакета |
= 4200 бит (2,5 мм длины дорожки на диске ) |
|
Максимальная длина пакета, который можно интерполировать |
=12000 бит (8 мм) |
|
Скорость интерполяции фрагмента |
фрагмент/10 часов при 1000 фрагментов/мин. при |
|
Необнаруженные фрагменты с ошибками (щелчки) |
Менее чем 1 на 750 часов при Пренебрежимо малое количество при |
|
Качество нового диска |
|
В системе CIRC защита от ошибок обеспечивается множеством способов.
1. Декодер обеспечивает нужный уровень коррекции ошибок.
2. Если исчерпывается способность к коррекции ошибок, то декодер переходит на уровень коррекции стираний (см. раздел 6.5.5).
3. Если исчерпывается и эта способность, декодер предпринимает попытки замаскировать ненадежные фрагменты данных путем интерполяции между ближайшими надежными фрагментами.
4. Если исчерпывается способность к интерполяции, декодер выключает или подавляет систему на период ненадежного фрагмента.
8.3.1. Кодирование по схеме CIRC
На рис. 8.15 показана основная блочная диаграмма кодера CIRC (с оборудованием для записи компакт-диска) и декодера (с оборудованием для воспроизведений компакт-диска). Процедура кодирования состоит из собственно кодирования и чередования, где введены следующие обозначения: ![]() -чередование,
-чередование, ![]() -кодирование,
-кодирование, ![]() -чередование,
-чередование, ![]() -кодирование и D-чередование. Процедура декодирования состоит из этапов декодированиями восстановления исходного порядка битов, котыторые выполняются в обратном порядке; здесь идут D-восстановление,
-кодирование и D-чередование. Процедура декодирования состоит из этапов декодированиями восстановления исходного порядка битов, котыторые выполняются в обратном порядке; здесь идут D-восстановление, ![]() -декодирование,
-декодирование, ![]() -восстановление,
-восстановление, ![]() -декрдирование и
-декрдирование и ![]() -восстановление.
-восстановление.
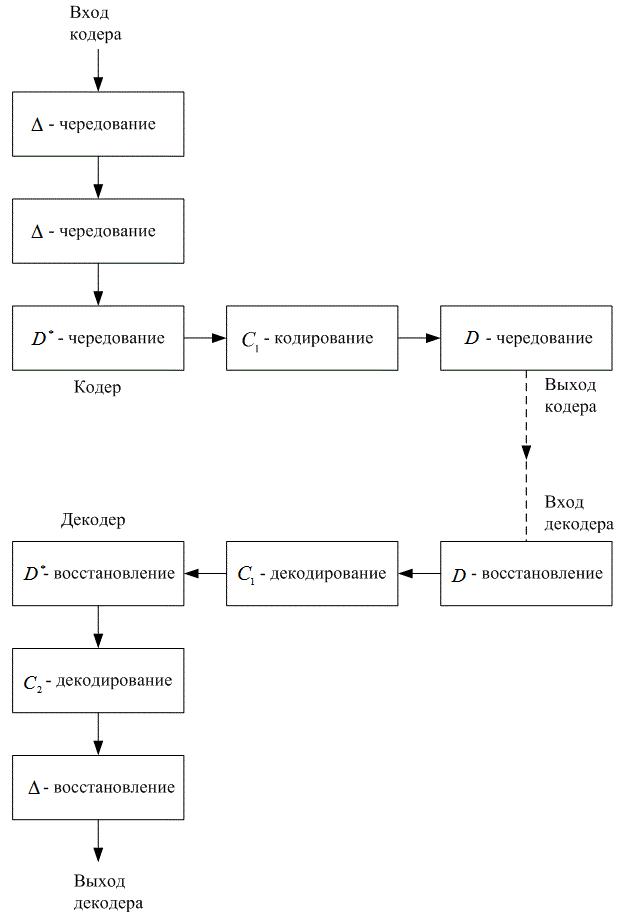
Рис. 8.13. Схема кодера и декодера CIRC
На рис. 8.16 показан элементарный период системного кадра и шесть периодов дискретизации, каждый из которых состоит из пары стереофрагментов (16-битовый левый фрагмент и 16-битовый правый фрагмент). Биты собраны в символы или байты размером 8 бит каждый. Следовательно, каждая пара фрагментов содержит 4 байт, а некодированный кадр — k = 24 байт. На рис. 8.16, а—д представлены пять этапов кодирования, которые характеризуют систему CIRC. Функции каждого этапа будут более понятны, если мы рассмотрим процедуру декодирования. Этапы выглядят следующим образом.
а) ![]() -чередование. Четные фрагменты отделяются от нечетных двумя кадрами для перемешивания ошибок, которые определены, но нельзя исправить. Это облегчает процесс интерполяции.
-чередование. Четные фрагменты отделяются от нечетных двумя кадрами для перемешивания ошибок, которые определены, но нельзя исправить. Это облегчает процесс интерполяции.
б) ![]() -кодирование. К
-кодирование. К ![]() -чередованному 24-байтовому кадру прибавляется четыре байта четности Рида-Соломона, что дает в итоге п = 28 байт. Такой код (28, 24) называется внешним.
-чередованному 24-байтовому кадру прибавляется четыре байта четности Рида-Соломона, что дает в итоге п = 28 байт. Такой код (28, 24) называется внешним.
в) ![]() -чередование. Здесь каждый байт задерживается на разную длину; таким образом, ошибки разбрасываются на несколько кодовых слов.
-чередование. Здесь каждый байт задерживается на разную длину; таким образом, ошибки разбрасываются на несколько кодовых слов. ![]() -кодирование;совместно с
-кодирование;совместно с ![]() -чередованием нужно для исправления пакетных ошибок и ошибочных комбинаций, которые
-чередованием нужно для исправления пакетных ошибок и ошибочных комбинаций, которые ![]() -декодер не в состоянии исправить.
-декодер не в состоянии исправить.
г) ![]() -кодирование. К k = 28 байт
-кодирование. К k = 28 байт ![]() -чередованного кадра прибавляется четыре байта. четности Рида-Соломона, что дает в итоге всего n = 32 байт. Такой код (32,28) называется внутренним.
-чередованного кадра прибавляется четыре байта. четности Рида-Соломона, что дает в итоге всего n = 32 байт. Такой код (32,28) называется внутренним.
д) D-чередование. Осуществляется перекрестное чередование четных байтов кадра с нечетными байтами следующего кадра: После этой процедуры два последовательных байта на диске будут всегда расположены в двух разных кодовых словах. При декодировании это чередование даст возможность исправлять большинство случайных одиночных ошибок и обнаруживать более длинные пакеты ошибок.
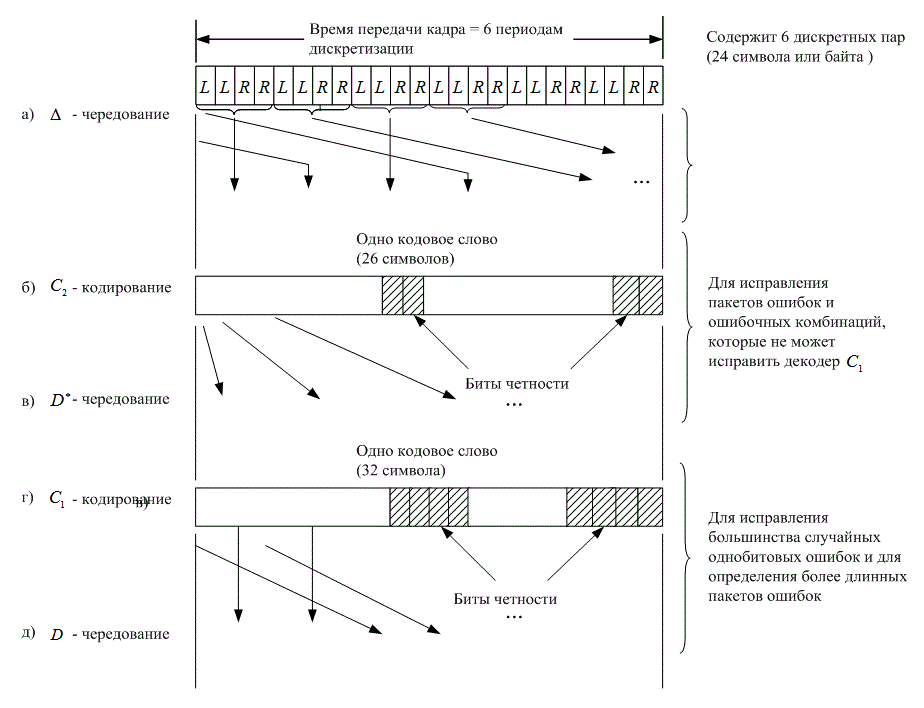
Рис. 8.16. Кодирование компакт-диска: а) ![]() -чередование; б)
-чередование; б) ![]() -кодирование; в)
-кодирование; в) ![]() -чередование; г)
-чередование; г) ![]() -кодирование; д) D -чередование
-кодирование; д) D -чередование
8.3.1.1. Укорачивание кода Рида-Соломона
В разделе 8.1 код (n, k) выражался через ![]() итоговых символов и
итоговых символов и ![]() символов данных, где т представляет собой число битов в символе, a t — способность кода к коррекции ошибок в символах. Для системы CD-DA, где символ образован из 8 бит, код с коррекцией 2-битовых ошибок можно сконфигурировать как код (255, 251). Однако в системе CD-DA используется значительно меньшая длина блока. Любой блочный код (в систематической форме) можно укоротить без уменьшения числа ошибок, которые поддаются исправлению внутри блока. Представим себе, что в терминах кода (255, 251), 227 из 251 информационного символа являются набором нулевых символов (которые в действительности не передавались и поэтому не содержат, ошибок). Тогда код в действительно будет кодом (28, 24) с коррекцией 2-символьных ошибок. Это и делается в
символов данных, где т представляет собой число битов в символе, a t — способность кода к коррекции ошибок в символах. Для системы CD-DA, где символ образован из 8 бит, код с коррекцией 2-битовых ошибок можно сконфигурировать как код (255, 251). Однако в системе CD-DA используется значительно меньшая длина блока. Любой блочный код (в систематической форме) можно укоротить без уменьшения числа ошибок, которые поддаются исправлению внутри блока. Представим себе, что в терминах кода (255, 251), 227 из 251 информационного символа являются набором нулевых символов (которые в действительности не передавались и поэтому не содержат, ошибок). Тогда код в действительно будет кодом (28, 24) с коррекцией 2-символьных ошибок. Это и делается в ![]() -кодере системы CD-DA.
-кодере системы CD-DA.
Мы можем представить 28 символов вне ![]() -кодера как информационные символы в
-кодера как информационные символы в ![]() -кодере. И снова можно сконфигурировать сокращенный код (255, 251) с коррекцией 2-символьных ошибок, отбросив 223 символа данных; результатом будет код (32, 28).
-кодере. И снова можно сконфигурировать сокращенный код (255, 251) с коррекцией 2-символьных ошибок, отбросив 223 символа данных; результатом будет код (32, 28).
8.3.2. Декодирование по схеме CIRC
Внутренний и внешний коды Рида-Соломона с параметром (n, k), равным (32,28) и (28, 24), используют четыре контрольных байта. Степень кодирования кода в схеме CIRC равна ![]() . Из уравнения (8.3) следует, что минимальное расстояние
. Из уравнения (8.3) следует, что минимальное расстояние ![]() и
и ![]() кодов Рида-Соломона будет
кодов Рида-Соломона будет ![]() daiu = n-k+l=5. Из уравнений (8.4) и (8.5) имеем следующее.
daiu = n-k+l=5. Из уравнений (8.4) и (8.5) имеем следующее.
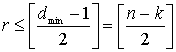 (8.58)
(8.58)
![]() (8.59)
(8.59)
Здесь t — способность к коррекции ошибок, а ![]() — способность к коррекции стираний. Видно, что
— способность к коррекции стираний. Видно, что ![]() и
и ![]() -декодеры могут исправить максимум 2 символьные ошибки или 4 символьных стирания на кодовое слово. Или, как определяется уравнением (8.6), имеется возможность исправлять
-декодеры могут исправить максимум 2 символьные ошибки или 4 символьных стирания на кодовое слово. Или, как определяется уравнением (8.6), имеется возможность исправлять ![]() ошибок и
ошибок и ![]() стираний одновременно, если
стираний одновременно, если
![]() (8.60)
(8.60)
Существует компромисс между коррекцией ошибок и коррекцией стираний; чем больше возможностей задействовано в коррекции ошибок, тем меньше остается возможностей для коррекции стираний.
Преимущества схемы CIRC лучше видны на примере декодера. Рабочие этапы, изображенные на рис. 8.17, имеют обратный порядок по сравнению с кодером. Давайте рассмотрим этапы работы декодера.
1.D-восстановление. Этот этап нужен для чередования линий задержки, обозначенных символом D. 32 байт ![]() кодированного кадра выстраиваются для параллельной подачи на 32 входа D-восстановителя. Каждая задержка равна длительности 1 байт, так что происходит обращение перекрестного чередования информации четных байтов кадра с нечетными байтами следующего кадра.
кодированного кадра выстраиваются для параллельной подачи на 32 входа D-восстановителя. Каждая задержка равна длительности 1 байт, так что происходит обращение перекрестного чередования информации четных байтов кадра с нечетными байтами следующего кадра.
2.![]() -декодирование. D-восстановитель и
-декодирование. D-восстановитель и ![]() -декодер разработаны для исправления однобайтовых ошибок в блоке из 32 байт и обнаружения больших, пакетов ошибок. Если появляются многократные ошибки, то
-декодер разработаны для исправления однобайтовых ошибок в блоке из 32 байт и обнаружения больших, пакетов ошибок. Если появляются многократные ошибки, то ![]() -декодер пропускает их без изменений, приписывая ко всем 28 байт метку стирания и пересылая их по пунктирным линиям (четыре бита контроля четности используются в
-декодер пропускает их без изменений, приписывая ко всем 28 байт метку стирания и пересылая их по пунктирным линиям (четыре бита контроля четности используются в ![]() -декодере и.больше не сохраняются).
-декодере и.больше не сохраняются).
3.![]() -восстановление. Из-за разности длины линий задержки
-восстановление. Из-за разности длины линий задержки ![]() (l, ...,27) при воcстановлении порядка битов, ошибки, возникающие в слове на выходе
(l, ...,27) при воcстановлении порядка битов, ошибки, возникающие в слове на выходе ![]() -декодера, оказываются разбросанными по большому количеству слов на входе
-декодера, оказываются разбросанными по большому количеству слов на входе ![]() -декодера, что позволяет
-декодера, что позволяет ![]() -декодеру заниматься исправлением этих ошибок.
-декодеру заниматься исправлением этих ошибок.
3.![]() -декодирование.
-декодирование. ![]() -декодер применяется для исправления пакетов ошибок, которые не может исправить
-декодер применяется для исправления пакетов ошибок, которые не может исправить ![]() -декодер. Если
-декодер. Если ![]() -декодеру не удается исправить эти ошибки, то 24-байтовое кодовое слово пропускается без изменений на
-декодеру не удается исправить эти ошибки, то 24-байтовое кодовое слово пропускается без изменений на ![]() -восстановитель и на соответствующие позиции ставится метка стирания по пунктирным линиям,
-восстановитель и на соответствующие позиции ставится метка стирания по пунктирным линиям, ![]() .
.
4.![]() -восстановление. Это финальная операция, в ходе которой осуществляется обращение чередования неисправимых, но обнаружимых ошибок, в результате чего происходит интерполяция между соседними кадрами.
-восстановление. Это финальная операция, в ходе которой осуществляется обращение чередования неисправимых, но обнаружимых ошибок, в результате чего происходит интерполяция между соседними кадрами.
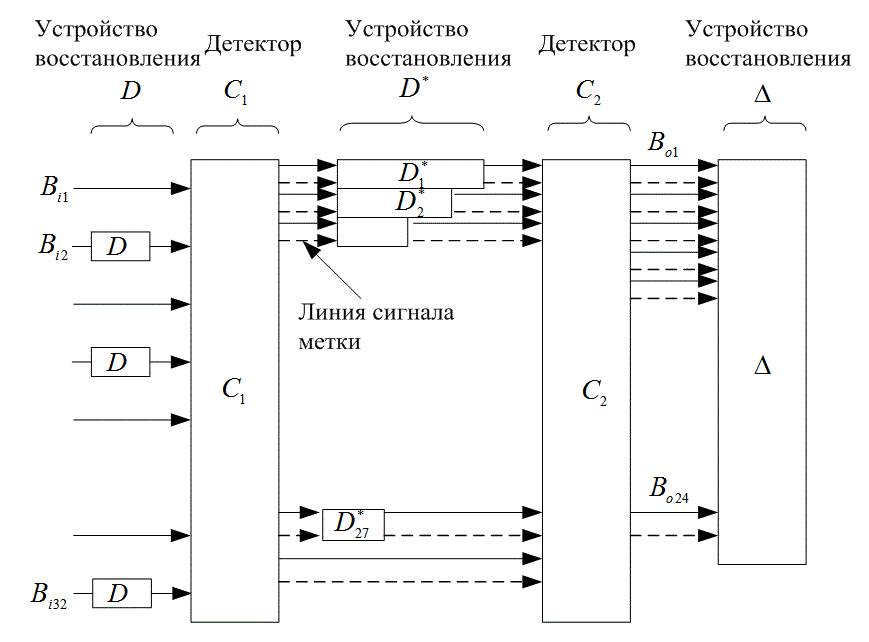
Рис. 8.17. Декодер системы воспроизведения компакт-дисков
На рис. 8.18 выделены 2-, 3- и 4-й этапы декодирования. На выходе ![]() -декодера видна последовательность четырех 28-байтовых кодовых слов, которые превышают однобайтовую способность кода корректировать ошибки. Следовательно, каждый из символов в этих кодовых словах получает метку стирания (показана кружком).
-декодера видна последовательность четырех 28-байтовых кодовых слов, которые превышают однобайтовую способность кода корректировать ошибки. Следовательно, каждый из символов в этих кодовых словах получает метку стирания (показана кружком). ![]() -восстановитель выполняет разнесение линий задержки для каждого байта кодового слова так, что байты данного кодового слова попадают в разные кодовые слова на входе
-восстановитель выполняет разнесение линий задержки для каждого байта кодового слова так, что байты данного кодового слова попадают в разные кодовые слова на входе ![]() -декодера. Если допустить, что коэффициент задержки
-декодера. Если допустить, что коэффициент задержки ![]() -восстановителя, изображенного на рис. 8.18, равен 1 байт, то можно исправить пакет ошибок четырех последовательных кодовых слов
-восстановителя, изображенного на рис. 8.18, равен 1 байт, то можно исправить пакет ошибок четырех последовательных кодовых слов ![]() (поскольку
(поскольку ![]() -декодер может исправить четыре стирания на кодовое слово). В прикладных системах CD-DA коэффициент задержки составляет 4 байт; поэтому максимальная способность кода к исправлению пакетных ошибок равняется 16 последовательным неисправленным
-декодер может исправить четыре стирания на кодовое слово). В прикладных системах CD-DA коэффициент задержки составляет 4 байт; поэтому максимальная способность кода к исправлению пакетных ошибок равняется 16 последовательным неисправленным ![]() -словам.
-словам.
8.3.3.Интерполяция и подавление
Фрагменты, которые нельзя исправить с помощью ![]() -декодера, могут вызвать слышимые искажения. Роль процедуры интерполяции фрагменты, оцениваемые по ближайшим соседям, вместо ненадежных. Если полное слово признано ненадежным, то невозможно произвести интерполяцию; без дополнительного чередования, поскольку и четные, и нечетные фрагменты одинаково ненадежны. Это может ,произойти, есди
-декодера, могут вызвать слышимые искажения. Роль процедуры интерполяции фрагменты, оцениваемые по ближайшим соседям, вместо ненадежных. Если полное слово признано ненадежным, то невозможно произвести интерполяцию; без дополнительного чередования, поскольку и четные, и нечетные фрагменты одинаково ненадежны. Это может ,произойти, есди ![]() -декрдер не обнаруживает ошибки, а
-декрдер не обнаруживает ошибки, а ![]() -декодер обнаруживает ее. Целью
-декодер обнаруживает ее. Целью ![]() -восстановления (в течение двух кадровых периодов) является вычисление структуры, в которой четные фрагменты можно интерполировать по нечетным иди наоборот.
-восстановления (в течение двух кадровых периодов) является вычисление структуры, в которой четные фрагменты можно интерполировать по нечетным иди наоборот.
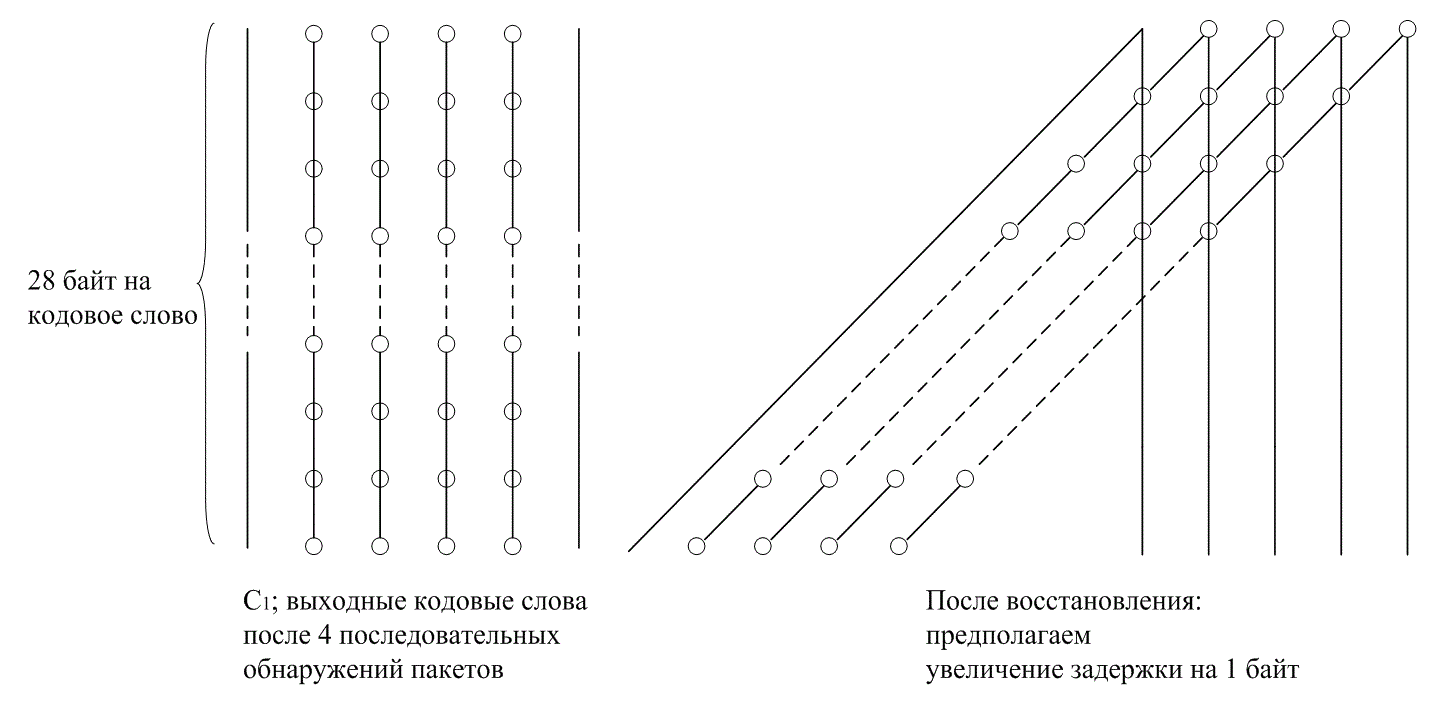
Рис. 8.18. Пример 4-байтовой возможности стираний (время показано справа налево)
На рис. 8.19 показаны два последовательных ненадежных слова, состоящих из 12 пар фрагментов. Пара фрагментов состоит из фрагмента (2 байта) правого аудиоканала и фрагмента левого. Числа означают порядок размещения фрагментов. Фрагменты, номера которых выделены, отмечены меткой стирания. После ![]() -восстановления ненадежные фрагменты, показанные на рисунке, оцениваются с помощью линейной интерполяции первого порядка между ближайшими соседними фрагментами из разных мест диска.
-восстановления ненадежные фрагменты, показанные на рисунке, оцениваются с помощью линейной интерполяции первого порядка между ближайшими соседними фрагментами из разных мест диска.
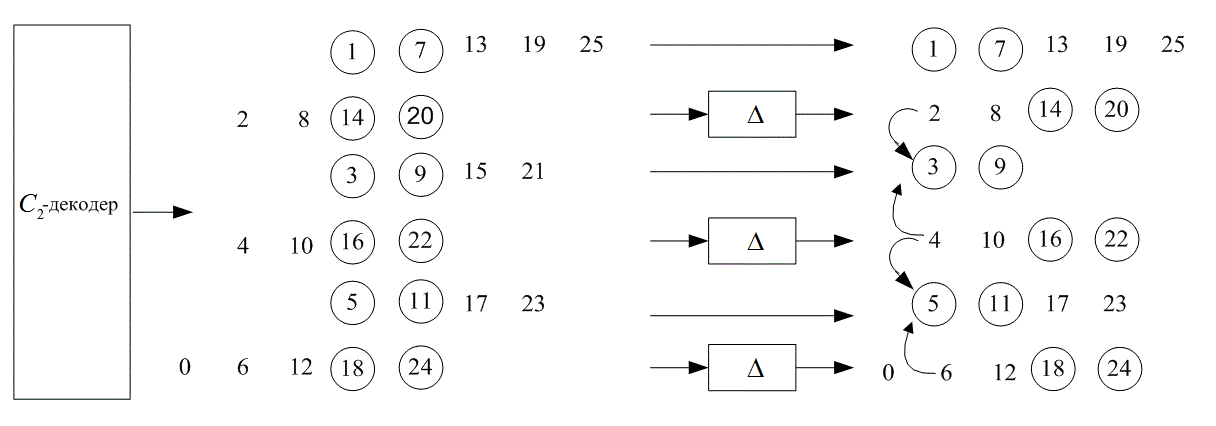
В проигрывателях компакт-дисков при появлении пакетов ошибок, превышающих 48 кадров и дающих в итоге 2 или более последовательных ненадежных фрагментов, применяется иной уровень защиты от ошибок. В этом случае система подавляется (звук приглушается), что незаметно для человеческого слуха, если, время подавления не превышает нескольких миллисекунд. Для более подробного ознакомления со схемой кодирования CIRC в системе CD-DA см. [11-15].
8.4. Турбокоды
Схема каскадкого кодирования впервые была предложена Форни [16] как метод получения высокоэффективного кода посредством комбинацйи двух или более компонуемых кодов (иногда называемых составными). В результате, такие коды могут корректировать ошибки в значительно более длинных кодах и имеют структуру, которая позволяет относительно легко осуществить декодирование средней сложности. Последовательные каскадные коды часто используются в системах с ограничением мощности, таких как космические зонды. Самая распространенная из этих схем содержит внешний код Рида-Соломона (выполняется первым, убирается последним), который следует за сверточным внутренним кодом (выполняется последним, убирается первым) [10]. Турбокод можно считать обновлением структуры каскадного кодирования с итеративным алгоритмом декодирования связанной кодовой последовательности. Поскольку такая схема имеет итеративную форму, на рис. 1.3 турбокодирование представлено как отдельная категория в структурированных последовательностях.
Турбокоды впервые были введены в 1993 году Берру, Главье и Цитимаджимой (Berrou, Glavieux, Thitimajshima) и опубликованы в [17, 18], где в описываемой схеме достигалась вероятность появления ошибок ![]() при степени кодирования 1/2 и модуляции BPSK в канале с белым аддитивным гауссовым шумом (additive white Gaussian noise — AWGN) с
при степени кодирования 1/2 и модуляции BPSK в канале с белым аддитивным гауссовым шумом (additive white Gaussian noise — AWGN) с ![]() , равным 0,7 дБ. Коды образуются посредством компоновки двух или более составных кодов, являющихся разными вариантами чередования одной и той же информационной последовательности. Тогда как для сверточных кодов на финальном этапе декодер выдает жестко декодированные биты (или в более общем случае — декодированные символы), в каскадной схеме, такой как турбоход, для хорошей работы алгоритм декодирования не должен ограничивать себя, подавая на декодеры жесткую схему решений. Для лучшего использования информации, получаемой с каждого декодера, алгоритм декодирования должен применять, в первую очередь, мягкую схему декодирования, вместо жесткой. Для систем с двумя составными кодами концепция, лежащая в основе турбодекодирования, заключается в том, чтобы передать мягкую схему принятия решений с выхода одного декодера на вход другого и повторять эту процедуру до тех пор, пока не будут получены надежные решения.
, равным 0,7 дБ. Коды образуются посредством компоновки двух или более составных кодов, являющихся разными вариантами чередования одной и той же информационной последовательности. Тогда как для сверточных кодов на финальном этапе декодер выдает жестко декодированные биты (или в более общем случае — декодированные символы), в каскадной схеме, такой как турбоход, для хорошей работы алгоритм декодирования не должен ограничивать себя, подавая на декодеры жесткую схему решений. Для лучшего использования информации, получаемой с каждого декодера, алгоритм декодирования должен применять, в первую очередь, мягкую схему декодирования, вместо жесткой. Для систем с двумя составными кодами концепция, лежащая в основе турбодекодирования, заключается в том, чтобы передать мягкую схему принятия решений с выхода одного декодера на вход другого и повторять эту процедуру до тех пор, пока не будут получены надежные решения.
8.4.1. Понятия турбокодирования
8.4.1.1. Функции правдоподобия
Математическое обоснование критерия проверки гипотез остается за теоремой Байеса, которая приводится в приложении Б. В области связи, где наибольший интерес представляют прикладные системы, включающие в себя каналы AWGN, наиболее распространенной формой теоремы Байеса является та, которая выражает апостериорную вероятность (a posteriori probability— APP) решения через случайную непрерывную переменную х как
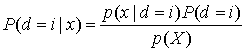
![]() (8.61)
(8.61)
![]() , (8.62)
, (8.62)
где ![]() — это апостериорная вероятность, a d = i представляет данные d, принадлежащие i-му классу сигналов из набора классов М. Ранее
— это апостериорная вероятность, a d = i представляет данные d, принадлежащие i-му классу сигналов из набора классов М. Ранее ![]() представляло функцию плотности вероятности принимаемого непрерывного сигнала с шумом х, при d = i. Также
представляло функцию плотности вероятности принимаемого непрерывного сигнала с шумом х, при d = i. Также ![]() , называемое априорной вероятностью, означает вероятность появления i-го класса сигналов. Обычно х представляет "наблюдаемую" случайную переменную или лежащую в основе критерия статистику, которая получается на выходе, демодулятора или какого-либо иного устройства обработки сигналов. Поэтому p(х) — это функция распределения вероятностей принятого сигнала х, дающая тестовую статистику в полном пространстве классов сигналов. В уравнении (8.61) при конкретном наблюдении p(x) является коэффициентом масштабирования, поскольку он получается путем усреднения по всем классам пространства. Литера p нижнего регистра используется для обозначения функции распределения вероятностей непрерывной случайной переменной, а литера P верхнего регистра — для обозначения вероятности (априорной и апостериорной). Определение апостериорной вероятности принятого сигнала, из уравнения (8.61), можно представлять как результат эксперимента. Перед экспериментом, в общем, существует (или поддается оценке) априорная вероятность
, называемое априорной вероятностью, означает вероятность появления i-го класса сигналов. Обычно х представляет "наблюдаемую" случайную переменную или лежащую в основе критерия статистику, которая получается на выходе, демодулятора или какого-либо иного устройства обработки сигналов. Поэтому p(х) — это функция распределения вероятностей принятого сигнала х, дающая тестовую статистику в полном пространстве классов сигналов. В уравнении (8.61) при конкретном наблюдении p(x) является коэффициентом масштабирования, поскольку он получается путем усреднения по всем классам пространства. Литера p нижнего регистра используется для обозначения функции распределения вероятностей непрерывной случайной переменной, а литера P верхнего регистра — для обозначения вероятности (априорной и апостериорной). Определение апостериорной вероятности принятого сигнала, из уравнения (8.61), можно представлять как результат эксперимента. Перед экспериментом, в общем, существует (или поддается оценке) априорная вероятность ![]() . В эксперименте для расчета апостериорной вероятности,
. В эксперименте для расчета апостериорной вероятности, ![]() используется уравнение (8.61), и это можно считать "обновлением" имевшихся сведений, полученных при изучении принятого сигнала х.
используется уравнение (8.61), и это можно считать "обновлением" имевшихся сведений, полученных при изучении принятого сигнала х.
8.4.1.2. Пример класса из двух сигналов
Пусть двоичные логические элементы 1 и 0 представляются электрическими напряжениями +1 и -1. Переменная d представляет бит переданных данных, который выглядит как уровень напряжения или логический элемент. Иногда более предпочтительным оказывается один из способов представления; читатель должен уметь различать это по контексту. Пусть двоичный 0 (или электрическое напряжение -1) будет нулевым элементом при сложении. На рис. 8.20 показана условная функция распределения вероятностей при передаче сигнала по каналу AWGN, представленная как функция правдоподобия. Функция, изображенная справа, ![]() , представляет функцию распределения вероятностей случайной переменной х, которая передается при условии, что
, представляет функцию распределения вероятностей случайной переменной х, которая передается при условии, что ![]() . Функция, изображенная слева,
. Функция, изображенная слева, ![]() , в свою очередь, представляет ту же функцию распределения вероятностей случайной переменной х, которая передается при условии, что
, в свою очередь, представляет ту же функцию распределения вероятностей случайной переменной х, которая передается при условии, что ![]() . На оси абсцисс показан полный диапазон возможных значений тестовой статистики х, которая образуется в приемнике. На рис. 8.20 показано одно такое произвольное значение
. На оси абсцисс показан полный диапазон возможных значений тестовой статистики х, которая образуется в приемнике. На рис. 8.20 показано одно такое произвольное значение ![]() , индекс которого представляет наблюдение, произведенное в k-й период времени. Прямая, опушенная в точку
, индекс которого представляет наблюдение, произведенное в k-й период времени. Прямая, опушенная в точку ![]() , пересекает две кривые функций правдоподобия, что дает в итоге два значения правдоподобия
, пересекает две кривые функций правдоподобия, что дает в итоге два значения правдоподобия ![]() и
и ![]() . Хорошо известное правило принятия решения по жесткой схеме, называемое принципом максимального правдоподобия, определяет выбор данных
. Хорошо известное правило принятия решения по жесткой схеме, называемое принципом максимального правдоподобия, определяет выбор данных ![]() или
или ![]() , основываясь на большем из двух имеющихся значений
, основываясь на большем из двух имеющихся значений ![]() или
или ![]() . Для каждого бита данных в момент k решение гласит, что
. Для каждого бита данных в момент k решение гласит, что ![]() , если
, если ![]() попадает по правую сторону линии принятия решений, обозначаемой
попадает по правую сторону линии принятия решений, обозначаемой ![]() , в противном случае —
, в противном случае — ![]() .
.
Аналогичное правило принятия решения, известное как максимум апостериорной вероятности (maximum a posteriori — MAP), можно представить в виде правила минимальной вероятности ошибки, принимая во внимание априорную вероятность данных. В общем случае правило MAP выражается следующим образом.
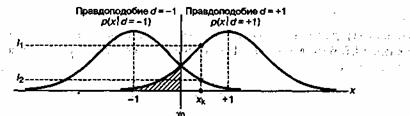
Рис. 8.20. Функции правдоподобия
![]() Я.
Я. 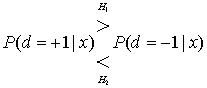 (8.63)
(8.63)
Уравнение (8.63) утверждает, что выбирается одна из гипотез — ![]()
![]()
![]() , если апостериорная вероятность
, если апостериорная вероятность ![]() больше апостериорной вероятности
больше апостериорной вероятности ![]() . В противном случае выбирается гипотеза
. В противном случае выбирается гипотеза ![]() ,
, ![]() . Воспользовавшись байесовской формой уравнения (8.61), можно заменить апостериорную вероятность в уравнении (8.63) эквивалентным выражением, что дает следующее.
. Воспользовавшись байесовской формой уравнения (8.61), можно заменить апостериорную вероятность в уравнении (8.63) эквивалентным выражением, что дает следующее.
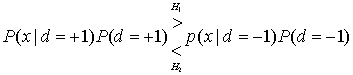 (8.64)
(8.64)
Здесь функция распределения вероятности p(х), имеющаяся в обеих частях неравенства, (8.61), была исключена. Уравнение (8.64), в целом представленное через дроби, дает так называемую проверку отношения правдоподобий.
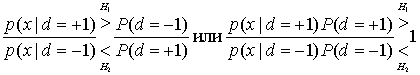 (8.65)
(8.65)
8.4.1.3. Логарифмическое отношение правдоподобий
Если взять логарифм от соотношения правдоподобия, полученного в уравнениях (8.63)-(8.65), получится удобная во многих отношениях метрика, называемая логарифмическое отношение правдоподобия (log-likelihood ratio — LLR). Это вещественное представление мягкого решения вне декодера определяется выражением
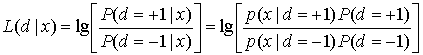 (8.66)
(8.66)
так, что
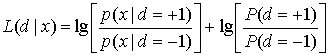 (8.67)
(8.67)
или
![]() , (8.68)
, (8.68)
где ![]() — это LLR тестовой статистики х, получаемой путем измерений х на выходе канала при чередовании условий, что может быть передан
— это LLR тестовой статистики х, получаемой путем измерений х на выходе канала при чередовании условий, что может быть передан ![]() или
или ![]() ,a L(d) — априорное LLR бита данных d. Для упрощения обозначений уравнение (8.68) можно переписать следующим образом.
,a L(d) — априорное LLR бита данных d. Для упрощения обозначений уравнение (8.68) можно переписать следующим образом.
![]() (8.69)
(8.69)
Здесь ![]() означает, что данный член LLR получается в результате канальных измерений, произведенных в приемнике. Уравнения (8.61)—(8.69) получены только исходя из данных детектора. Далее введение декодера даст стандартные преимущества схемы принятия решений. Для систематических кодов было пЬказано [17], что LLR (мягкий выход) вне декодера равняется следующему.
означает, что данный член LLR получается в результате канальных измерений, произведенных в приемнике. Уравнения (8.61)—(8.69) получены только исходя из данных детектора. Далее введение декодера даст стандартные преимущества схемы принятия решений. Для систематических кодов было пЬказано [17], что LLR (мягкий выход) вне декодера равняется следующему.
![]() (8.70)
(8.70)
Здесь ![]() — это LLR бита данных вне демодулятора (на входе декодера), а
— это LLR бита данных вне демодулятора (на входе декодера), а ![]() называется внешним LLR и представляет внешнюю информацию, вытекающую из процесса декодирования. Выходная последовательность систематического декодера образована величинами, представляющими информационные биты или биты четности. Из уравнений (8.69) и (8.70) выходное LLR декодера теперь примет следующий вид.
называется внешним LLR и представляет внешнюю информацию, вытекающую из процесса декодирования. Выходная последовательность систематического декодера образована величинами, представляющими информационные биты или биты четности. Из уравнений (8.69) и (8.70) выходное LLR декодера теперь примет следующий вид.
![]() (8.71)
(8.71)
Уравнение (8.71) показывает, что выходное LLR систематического декодера можно представить как состоящее из трех компонентов — канального измерения, априорного знания данных и внешнего LLR, относящегося только к декодеру. Чтобы получить финальное ![]() , нужно просуммировать отдельные вклады LLR, как показано в уравнении (8.71), поскольку все три компонента статистически независимы [17, 19]. Доказательство оставляем читателю в качестве самостоятельного упражнения (см. задачу 8.18.). Мягкий выход декодера
, нужно просуммировать отдельные вклады LLR, как показано в уравнении (8.71), поскольку все три компонента статистически независимы [17, 19]. Доказательство оставляем читателю в качестве самостоятельного упражнения (см. задачу 8.18.). Мягкий выход декодера ![]() является вещественным числом, обеспечивающим в итоге как само принятие жесткого решения, так и его надежность. Знак
является вещественным числом, обеспечивающим в итоге как само принятие жесткого решения, так и его надежность. Знак ![]() задает жесткое решение, т.е. при положительном знаке
задает жесткое решение, т.е. при положительном знаке ![]() решение —
решение — ![]() , а при отрицательном —
, а при отрицательном — ![]() . Величина
. Величина ![]() определяет надежность этого решения. Часто величина
определяет надежность этого решения. Часто величина ![]() вследствие декодирования имеет тот же знак, что и
вследствие декодирования имеет тот же знак, что и ![]() , и поэтому повышает надежность
, и поэтому повышает надежность ![]() .
.
8.4.1.4. Принципы итеративного (турбо) декодирования
В типичном приемнике демодулятор часто разрабатывается для выработки решений по мягкой схеме, которые затем будут переданы на декодер. В главе 7 повышение достоверности передачи в системе, по сравнению с жесткой схемой принятия решений, оценивается приблизительно в 2 дБ в канале AWGN. Такой декодер следует называть декодером с мягким входом и жестким выходом, поскольку процесс финального декодирования должен завершаться битами (жесткая схема). В турбокодах, где используется два или несколько составных кодов и декодирование подразумевает подключение выхода одного декодера ко входу другого для возможности поддержки итераций, декодер с жестким выходом нежелателен. Это связано с тем, что жесткая схема в декодере снизит производительность системы (по сравнению с мягкой схемой). Следовательно, для реализации турбодекодирования необходим декодер с мягким входом и мягким выходом. Во время перво итерации на таком декодере (с мягким входом и мягким выходом), показанном на рис. 8.21, данные считаются равновероятными, что дает начальное априорное значение LLR ![]() для третьего члена уравнения (8.67). Канальное значение LLR Lc(x) получается путем взятия логарифма отношения величин
для третьего члена уравнения (8.67). Канальное значение LLR Lc(x) получается путем взятия логарифма отношения величин ![]() и
и ![]() для определенных значений х (рис. 8.20) и является вторым членом уравнения (8.67). Выход декодера
для определенных значений х (рис. 8.20) и является вторым членом уравнения (8.67). Выход декодера ![]() на рис. 8.21 образуется из LLR детектора
на рис. 8.21 образуется из LLR детектора ![]() и внешнего LLR выхода
и внешнего LLR выхода ![]() и представляет собой сведения, вытекающие из процесса декодирования. Как показано на рис. 8.21 для итеративного декодирования, внешнее правдоподобие подается обратно на вход (иного составного декодера) для обновления априорной вероятности информации следующей итерации.
и представляет собой сведения, вытекающие из процесса декодирования. Как показано на рис. 8.21 для итеративного декодирования, внешнее правдоподобие подается обратно на вход (иного составного декодера) для обновления априорной вероятности информации следующей итерации.
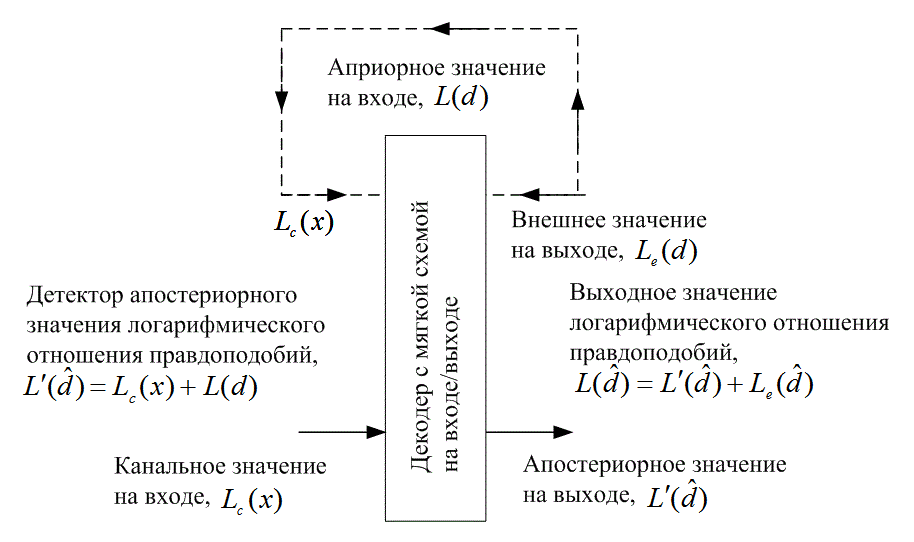
Рис. 8.21. Декодер с мягким входом и мягким выходом
8.4.2. Алгебра логарифма правдоподобия
Для более подробного объяснения итеративной обратной связи выходов мягких декодеров, вводится понятие алгебры логарифма правдоподобия [19]. Для статистически независимых данных d сумма двух логарифмических отношений правдоподобия (log-likelihood ratio — LLR) определяется следующим образом.
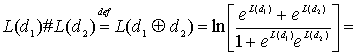 (8.72)
(8.72)
![]() (8.72)
(8.72)
Здесь использован натуральный логарифм, а функция ![]() возвращает знак своего аргумента. В уравнении (8.72) имеется три операции сложения. Знак "
возвращает знак своего аргумента. В уравнении (8.72) имеется три операции сложения. Знак "![]() " применяется для обозначения суммы по модулю 2 данных, представленных двоичными цифрами. Знак # используется для обозначения суммы логарифмов правдоподобия или, что то же самое, математической операции, описываемой уравнением (8.72). Сумма двух LLR обозначается оператором, который определяется как LLR суммы по модулю 2 основных статистически независимых информационных битов. Вывод уравнения (8.72) показан в приложении 8А. Уравнение (8.73) является аппроксимацией уравнения (8.72), которая будет использована позднее в численном примере. Сложение LLR, определяемое уравнениями (8.72) и (8.73), дает один очень интересный результат в том случае, если один из LLR значительно превышает второй.
" применяется для обозначения суммы по модулю 2 данных, представленных двоичными цифрами. Знак # используется для обозначения суммы логарифмов правдоподобия или, что то же самое, математической операции, описываемой уравнением (8.72). Сумма двух LLR обозначается оператором, который определяется как LLR суммы по модулю 2 основных статистически независимых информационных битов. Вывод уравнения (8.72) показан в приложении 8А. Уравнение (8.73) является аппроксимацией уравнения (8.72), которая будет использована позднее в численном примере. Сложение LLR, определяемое уравнениями (8.72) и (8.73), дает один очень интересный результат в том случае, если один из LLR значительно превышает второй.
![]()
![]()
Следует сказать, что алгебра логарифма правдоподобия, описанная здесь, немного отличается от той, которая используется в [19], из-за различного выбора нулевого элемента. В данном случае нулевым элементом двоичного набора (1, 0) выбран 0.
8.4.3. Пример композиционного кода
Рассмотрим двухмерный код (композиционный код), изображенный на рис. 8.22. Его структуру можно описать как массив данных, состоящий из ![]() строк и
строк и ![]() столбцов. В
столбцов. В ![]() строках содержатся кодовые слова, образованные
строках содержатся кодовые слова, образованные ![]() битами данных и
битами данных и ![]() битами четности. Каждая из
битами четности. Каждая из ![]() строк представляет собой кодовое слово кода
строк представляет собой кодовое слово кода ![]() . Аналогично
. Аналогично ![]() столбцов содержат кодовые слова, образованные из
столбцов содержат кодовые слова, образованные из ![]() бит данных и
бит данных и ![]() бит четности. Таким образом, каждый из
бит четности. Таким образом, каждый из ![]() столбцов представляет собой кодовые слова кода
столбцов представляет собой кодовые слова кода ![]() . Различные участки структуры обозначены следующим образом: d — для данных,
. Различные участки структуры обозначены следующим образом: d — для данных, ![]() — для горизонтальной четности (вдоль строк) и
— для горизонтальной четности (вдоль строк) и ![]() — для вертикальной четности (вдоль столбцов). Фактически каждый блок битов данных размером
— для вертикальной четности (вдоль столбцов). Фактически каждый блок битов данных размером ![]() кодирован двумя кодами — горизонтальным и вертикальным.
кодирован двумя кодами — горизонтальным и вертикальным.
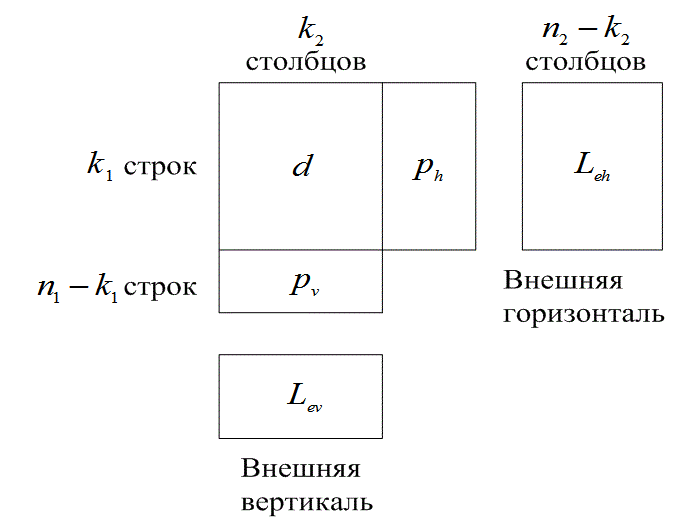
Рис. 8.22. Структура двухмерного композиционного кода
Еще на рис. 8.22 присутствуют блоки ![]() и
и ![]() , содержащие значения внешних LLR, полученные из горизонтального и вертикального кодов. Код с коррекцией ошибок дает некоторое улучшение достоверности передачи. Можно увидеть, что внешние LLR представляют собой меру этого улучшения. Заметьте, что такой композиционный код является простым примером каскадного кода. Его структура описывается двумя отдельными этапами кодирования — горизонтальным и вертикальным.
, содержащие значения внешних LLR, полученные из горизонтального и вертикального кодов. Код с коррекцией ошибок дает некоторое улучшение достоверности передачи. Можно увидеть, что внешние LLR представляют собой меру этого улучшения. Заметьте, что такой композиционный код является простым примером каскадного кода. Его структура описывается двумя отдельными этапами кодирования — горизонтальным и вертикальным.
Напомним, что решение при финальном декодировании каждого бита и его надежности зависит от значения ![]() , как показывает уравнение (8.71). Опираясь на это уравнение, можно описать алгоритм, дающий внешние LLR (горизонтальное и вертикальное) и финальное
, как показывает уравнение (8.71). Опираясь на это уравнение, можно описать алгоритм, дающий внешние LLR (горизонтальное и вертикальное) и финальное ![]() . Для композиционного кода алгоритм такого итеративного декодирования будет иметь следующий вид.
. Для композиционного кода алгоритм такого итеративного декодирования будет иметь следующий вид.
1. Устанавливается априорное LLR ![]() (если априорные вероятности битов данных не равны).
(если априорные вероятности битов данных не равны).
2. Декодируется горизонтальный код и, основываясь на уравнении (8.71), вычисляется горизонтальное LLR.
![]()
3. .На этапе 4 вертикального декодирования устанавливается ![]() .
.
4. Декодируется вертикальный код и, основываясь на уравнении (8.71), вычисляется вертикальное LLR.
![]()
5. Для этапа 2 горизонтального декодирования устанавливается ![]() Затем повторяются этапы 2—5.
Затем повторяются этапы 2—5.
6. После достаточного для получения надежного решения количества итераций (т.е. повторения этапов 2-5) следует перейти к этапу 7.
7. Мягким решением на выходе будет
![]() (8.74)
(8.74)
Далее следует пример, демонстрирующий применение этого алгоритма к очень простому композиционному коду.
8.4.3.1. Пример двухмерного кода с одним разрядом контроля четности
Пусть в кодере биты данных и биты контроля четности имеют значения, показанные на рис. 8.23, а. Связь между битами данных и битами контроля четности внутри конкретной строки (или столбца) выражается через двоичные цифры (1, 0) следующим образом.

Рис. 8.23. Пример композиционного кода
![]() (8.75)
(8.75)
и
![]()
![]() (8.76)
(8.76)
Здесь символ "![]() " обозначает сумму по модулю 2. Переданные биты представлены последовательностью
" обозначает сумму по модулю 2. Переданные биты представлены последовательностью ![]() . На входе приемника искаженные помехами биты представляются последовательностью
. На входе приемника искаженные помехами биты представляются последовательностью ![]() ,
, ![]() . В данной ситуации для каждого принятого бита данных
. В данной ситуации для каждого принятого бита данных ![]() , для каждого принятого бита контроля четности
, для каждого принятого бита контроля четности ![]() , а n представляет собой распределение помех, которое статистически независимо от
, а n представляет собой распределение помех, которое статистически независимо от ![]() , и
, и ![]() .Индексы i и j обозначают позицию в выходном массиве кодера, изображенном на рис. 8.23, а. Хотя зачастую удобнее использовать обозначение принятой последовательности в виде
.Индексы i и j обозначают позицию в выходном массиве кодера, изображенном на рис. 8.23, а. Хотя зачастую удобнее использовать обозначение принятой последовательности в виде ![]() , где k является временным индексом. Оба типа обозначений будут рассматриваться далее; i и j используются для позиционных отношений внутри композиционного кода, a k — для более общих аспектов временной зависимости сигнала. Какое из обозначений должно быть заметно по контексту? Если основываться на отношениях, установленных в уравнениях (8.67)-(8.69), и считать модель каналом AWGN с помехами, LLR для канальных измерений сигнала
, где k является временным индексом. Оба типа обозначений будут рассматриваться далее; i и j используются для позиционных отношений внутри композиционного кода, a k — для более общих аспектов временной зависимости сигнала. Какое из обозначений должно быть заметно по контексту? Если основываться на отношениях, установленных в уравнениях (8.67)-(8.69), и считать модель каналом AWGN с помехами, LLR для канальных измерений сигнала ![]() принятого в момент k, будет иметь следующий вид.
принятого в момент k, будет иметь следующий вид.
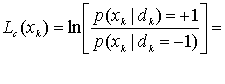 (8.77,а)
(8.77,а)
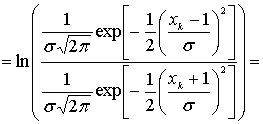 (8.78,б)
(8.78,б)
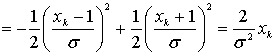 (8.79,в)
(8.79,в)
Здесь применяется натуральный логарифм. Если сделать предварительное допущение, что помеха имеет дисперсию ![]() , равную 1, то получим следующее.
, равную 1, то получим следующее.
![]() (8.78)
(8.78)
Рассмотрим пример, в котором информационная последовательность ![]() образована двоичными числами 1 0 0 1, как показано на рис. 8.23, а. Опираясь на уравнение (8.75), можно видеть, что контрольная последовательность
образована двоичными числами 1 0 0 1, как показано на рис. 8.23, а. Опираясь на уравнение (8.75), можно видеть, что контрольная последовательность ![]() должна быть равна 1 1 1 1. Следовательно, переданная последовательность будет иметь следующий вид.
должна быть равна 1 1 1 1. Следовательно, переданная последовательность будет иметь следующий вид.
![]() (8.79)
(8.79)
Если информационные биты выражаются через значения биполярного э лектрического напряжения +1 и -1, соответствующие логическим двоичным уровням 1 и 0, то переданная последовательность будет следующей.
![]()
Допустим теперь, что помехи преобразуют эту последовательность информации и I контрольных данных в принятую последовательность
![]() 0,75, 0,05, 0,10, 0,15, 1,25, 1,0, 3,0, 0,5, (8.80)
0,75, 0,05, 0,10, 0,15, 1,25, 1,0, 3,0, 0,5, (8.80)
где компоненты ![]() указывают переданную информацию и контрольные данные
указывают переданную информацию и контрольные данные ![]() . Таким образом, следуя позиционному описанию, принятую последовательность можно записать следующим образом.
. Таким образом, следуя позиционному описанию, принятую последовательность можно записать следующим образом.
![]()
Из уравнения (8.78) предполагаемые канальные измерения дают следующие значения LLR.
![]() 1,5, 0,1, 0,20, 0,3, 2,5 ,2,0, 6,0, 1,0 (8.81)
1,5, 0,1, 0,20, 0,3, 2,5 ,2,0, 6,0, 1,0 (8.81)
Эти величины показаны на рис. 8.23, б как входные измерения декодера. Следует заметить, что (при равной априорной вероятности переданных данных) если принимаются жесткие решения на основе значений ![]() или
или ![]() описанных ранее, то такой процесс должен в результате давать две ошибки, поскольку и
описанных ранее, то такой процесс должен в результате давать две ошибки, поскольку и ![]() и
и ![]() могут быть неправильно трактованы как двоичная 1.
могут быть неправильно трактованы как двоичная 1.
8.4.3.2. Внешние правдоподобия
В случае композиционного кода, изображенного на рис. 8.23, при выражении мягкого выхода для принятого сигнала, соответствующего данным ![]() , используется уравнение (8.71), так что
, используется уравнение (8.71), так что
![]() , (8.82)
, (8.82)
где член ![]()
![]() представляют внешнее LLR, распределенное кодом (т.е. прием соответствующих данных
представляют внешнее LLR, распределенное кодом (т.е. прием соответствующих данных ![]() и их априорной вероятности совместно с приемом соответствующей четности
и их априорной вероятности совместно с приемом соответствующей четности ![]() ). В общем случае мягким выходом
). В общем случае мягким выходом ![]() для принятого сигнала, соответствующего данным
для принятого сигнала, соответствующего данным ![]() будет
будет
![]() . (8.83)
. (8.83)
где ![]() и
и ![]() — канальное измерение LLR приема соответствующих
— канальное измерение LLR приема соответствующих ![]() ,
, ![]() и
и ![]() .
. ![]() ,
, ![]() —LLR для априорных вероятностей
—LLR для априорных вероятностей ![]() и
и ![]() ,
,![]() — внешнее распределение LLR для кода. Уравнения (8.82) и (8.83) становятся понятнее при рассмотрении рис. 8.23, б. В данной ситуации, если считать, что происходит равновероятная передача сигнала, мягкий выход
— внешнее распределение LLR для кода. Уравнения (8.82) и (8.83) становятся понятнее при рассмотрении рис. 8.23, б. В данной ситуации, если считать, что происходит равновероятная передача сигнала, мягкий выход ![]() представляется измерением LLR детектора
представляется измерением LLR детектора ![]() для приема, соответствующего данным
для приема, соответствующего данным ![]() , плюс внешнее LLR
, плюс внешнее LLR ![]() , получаемое в результате того, что данные
, получаемое в результате того, что данные ![]() и четность
и четность ![]() также дают сведения о данных
также дают сведения о данных ![]() , как это показывают уравнения (8.75) и (8.76).
, как это показывают уравнения (8.75) и (8.76).
8.4.3.3. Вычисление внешних правдоподобий
Для случая, показанного на рис. 8.23, горизонтальная часть расчетов для, получения Leh (d) и вертикальная часть расчетов для получения Lev (d) выглядят следующим образом.
![]() (8.84,а)
(8.84,а)
![]() (8.84,б)
(8.84,б)
![]() (8.85,а)
(8.85,а)
![]() (8.85,б)
(8.85,б)
![]() (8.86,а)
(8.86,а)
![]() (8.86,б)
(8.86,б)
![]() (8.87,а)
(8.87,а)
![]() (8.87,б)
(8.87,б)
Значения LLR, показанные на рис. 8.23, входят в выражение для ![]() в уравнениях (8.84)—(8.87). Подразумевая передачу сигналов равновероятной, а начальную установку значения
в уравнениях (8.84)—(8.87). Подразумевая передачу сигналов равновероятной, а начальную установку значения ![]() равной нулю, получаем следующее.
равной нулю, получаем следующее.
![]() - новое
- новое ![]() (8.88)
(8.88)
![]() - новое
- новое ![]() (8.89)
(8.89)
![]() - новое
- новое ![]() (8.90)
(8.90)
![]() - новое
- новое ![]() (8.91)
(8.91)
где сложения логарифма правдоподобия производятся, исходя из приближения, показанного в уравнении (8.73). Далее, продолжая первое вертикальное вычисление, используются выражения для ![]() из уравнений (8.84)-(8.87). Теперь значение
из уравнений (8.84)-(8.87). Теперь значение ![]() можно обновить, исходя из нового значения
можно обновить, исходя из нового значения ![]() , полученного из первого вертикального вычисления, показанного в уравнениях (8.88)-(8.91).
, полученного из первого вертикального вычисления, показанного в уравнениях (8.88)-(8.91).
![]() - новое
- новое ![]() (8.92)
(8.92)
![]() - новое
- новое ![]() (8.93)
(8.93)
![]() - новое
- новое ![]() (8.94)
(8.94)
![]() - новое
- новое ![]() (8.95)
(8.95)
Результаты первой полной итерации двух этапов декодирования (горизонтального и вертикального) будут следующими.
Исходные измерения ![]()
|
1,5 |
0,1 |
|
0,2 |
0,3 |
|
-0,1 |
-1,5 |
|
-0,3 |
-0,2 |
![]() после первого вертикального декодирования
после первого вертикального декодирования
|
0 |
-1,6 |
|
-1,3 |
1,2 |
![]()
![]() после первого вертикального декодирования
после первого вертикального декодирования
Каждый этап декодирования улучшает исходные LLR, которые основываются только на канальных измерениях. Это видно из расчетов выходного LLR декодера с помощью уравнения (8.74). Исходное LLR и внешние горизонтальные LLR вместе дают следующее улучшение (внешний вертикальный член еще не рассматривался).
Улучшение LLRиз-за ![]()
|
1,4 |
-1,4 |
|
-0,1 |
0,1 |
Исходное LLR совместно с горизонтальным и вертикальным внешним LLR дает следующее улучшение.
Улучшение LLR из-за ![]()
|
1,5 |
-1,5 |
|
-1,5 |
1,1 |
В данном случае можно видеть, что сведений, полученных лишь из горизонтального декодирования, достаточно для получения правильного жесткого решения вне декодера, но с низкой степенью доверия к битам данных d3 и d4. После включения внешних вертикальных LLR в декодер новые значения LLR появляются на более высоком уровне надежности и доверия. Пусть будет произведена еще одна вертикальная и одна горизонтальная итерация декодирования, чтобы определить наличие или отсутствие существенных изменений в результатах. Снова на помощь приходят отношения из уравнений (8.84)—(8.87), и далее следует горизонтальное вычисление для получения Leh(d) с новым L(d) из первого вертикального расчета, показанного в уравнениях (8.92)—(8.95), так что получаем следующее.
![]() - новое
- новое ![]() (8.96)
(8.96)
![]() - новое
- новое ![]() (8.97)
(8.97)
![]() - новое
- новое ![]() (8.98)
(8.98)
![]() - новое
- новое ![]() (8.99)
(8.99)
Затем необходимо выполнить второе вертикальное вычисление для получения ![]() с новым
с новым ![]() , полученным из второго горизонтального расчета, показанного в уравнения (8.96)-(8.99), что приводит к следующему.
, полученным из второго горизонтального расчета, показанного в уравнения (8.96)-(8.99), что приводит к следующему.
![]() - новое
- новое ![]() (8.100)
(8.100)
![]() - новое
- новое ![]() (8.101)
(8.101)
![]() - новое
- новое ![]() (8.102)
(8.102)
![]() - ново е
- ново е ![]() (8.103)
(8.103)
Вторая итерация вертикального и горизонтального декодирования, дающая упомянутые выше величины, отражается на мягких выходных LLR, которые снова рассчитываются из уравнения (8.74), переписанного сдедующим образом.
![]() (8.104)
(8.104)
Горизонтальные и вертикальные LLR из уравнения (8.96)-(8.103) и итоговое LLR декодера показаны ниже. В данном примере вторые итерации, горизонтальная и вертикальная, что в целом дает всего четыре итерации, показывают скромный прирост, по сравнению с одной вертикальной и горизонтальной итерацией. Результаты показывают, что доверительные значения сохраняются для каждого из четырех данных.
Исходные измерения ![]()
|
1,5 |
0,1 |
|
0,2 |
0,3 |
|
0 |
-1,6 |
|
-1,3 |
-1,2 |
![]() после первого вертикального декодирования
после первого вертикального декодирования
|
1,1 |
-1,0 |
|
-1,5 |
1,0 |
![]()
![]() после первого вертикального декодирования
после первого вертикального декодирования
Мягкий выход равен ![]() , который после всех четырех итераций дает следующие значения
, который после всех четырех итераций дает следующие значения ![]() .
.
|
2,6 |
-2,5 |
|
-2,6 |
2,5 |
В результате видно, что получены правильные решения по каждому биту данных и уровень доверия к этим решениям высок. Итеративное декодирование турбокодов напоминает процесс решения кроссвордов. Первый проход по кроссворду, вероятно, содержит несколько ошибок. Некоторые слова нуждаются в подгонке, но когда буквы в нужных строках и столбцах не подходят, нужно вернуться и исправить слова, вписанные после первого прохода.
8.4.4. Кодирование с помощью рекурсивного систематического кода
Ранее были описаны основные идеи сочетаний, итераций и мягкого декодирования на примере простого композиционного кода. Затем эти идеи применялись при реализации турбокодов, которые образуются в результате параллельных сочетаний сверточных кодов [17, 20].
Далее наступает очередь обзора простых двоичных сверточных кодеров со степенью кодирования 1/2, длиной кодового ограничения K и памятью порядка ![]() . На вход кодера в момент k, подается бит
. На вход кодера в момент k, подается бит ![]() , и соответствующим кодовым словом будет битовая пара
, и соответствующим кодовым словом будет битовая пара ![]() , где
, где
![]() по мудулю 2,
по мудулю 2, ![]() (8.105)
(8.105)
и
![]()
![]() по модулю 2,
по модулю 2, ![]() (8.106)
(8.106)
![]()
![]() и
и ![]() — генераторы кода, a
— генераторы кода, a ![]() представлен как двоичная цифра. Этот кодер можно представить как линейную систему с дискретной конечной импульсной характеристикой (finite impulse response — FIR), порождающую хорошо знакомый несистематический сверточный (nonsystematic convolutional — NSC) код, разновидность которого показана на рис. 8.24. Соответствующую решетчатую структуру можно увидеть на рис. 7.7. В данном случае длина кодового ограничения равна К = 3 и используются два генератора кода —
представлен как двоичная цифра. Этот кодер можно представить как линейную систему с дискретной конечной импульсной характеристикой (finite impulse response — FIR), порождающую хорошо знакомый несистематический сверточный (nonsystematic convolutional — NSC) код, разновидность которого показана на рис. 8.24. Соответствующую решетчатую структуру можно увидеть на рис. 7.7. В данном случае длина кодового ограничения равна К = 3 и используются два генератора кода — ![]() и
и ![]() . Хорошо известно, что при больших значениях
. Хорошо известно, что при больших значениях ![]() достоверность передачи с кодом NSC выше, чем у систематического кода с той же памятью. При малых значениях
достоверность передачи с кодом NSC выше, чем у систематического кода с той же памятью. При малых значениях ![]() существует обходной путь [17]. В качестве составляющих компонентов для турбокода был предложен класс сверточных кодов с бесконечной импульсной характеристикой [17]. Такие же компоненты используются в рекурсивных систематических сверточных (recursive systematic convolutional — RSC) кодах, поскольку в них предварительно кодированные биты данных постоянно должны подаваться обратно на вход кодера. При высоких степенях кодирования коды RSC дают значительно более высокие результаты, чем самые лучшие коды NSC, при любых значениях
существует обходной путь [17]. В качестве составляющих компонентов для турбокода был предложен класс сверточных кодов с бесконечной импульсной характеристикой [17]. Такие же компоненты используются в рекурсивных систематических сверточных (recursive systematic convolutional — RSC) кодах, поскольку в них предварительно кодированные биты данных постоянно должны подаваться обратно на вход кодера. При высоких степенях кодирования коды RSC дают значительно более высокие результаты, чем самые лучшие коды NSC, при любых значениях ![]() . Двоичный код RSC со степенью кодирования 1/2 получается из кода NSC с помощью контура обратной связи и установки одного из двух выходов (
. Двоичный код RSC со степенью кодирования 1/2 получается из кода NSC с помощью контура обратной связи и установки одного из двух выходов (![]() или
или ![]() ) равным
) равным ![]() . На рис. 8.25, а показан пример такого RSC-кода с К = 3, где
. На рис. 8.25, а показан пример такого RSC-кода с К = 3, где ![]() получается из рекурсивной процедуры
получается из рекурсивной процедуры
![]() по модулю 2, (8.107)
по модулю 2, (8.107)
a ![]() равно
равно ![]() если
если ![]() , и
, и ![]() — если
— если ![]() . На рис. 8.25, б изображена решетчатая структура RSC-кода, представленного на рис. 8.25, а.
. На рис. 8.25, б изображена решетчатая структура RSC-кода, представленного на рис. 8.25, а.
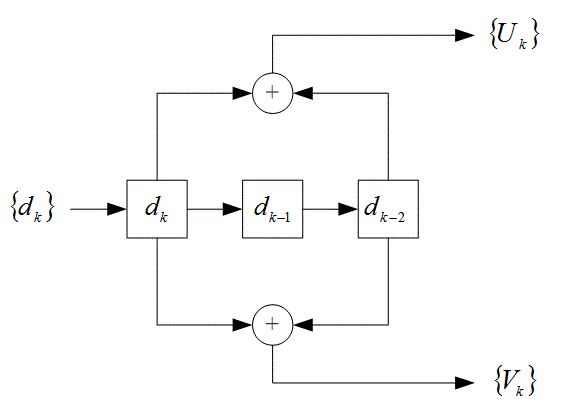
Рис. 8.24. Несистематический сверточный код(nonsystematic convolution - NSC)
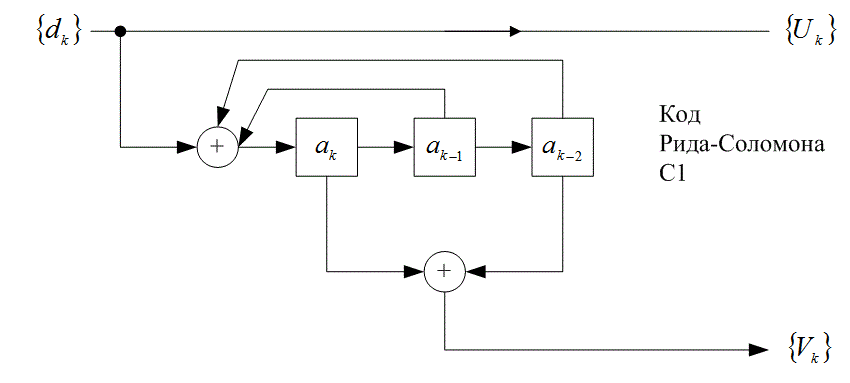
Рис. 8.25а. Рекурсивный систематический
сверточный код (recursive systematic convolution - RSC)
Рис. 8.25б. Решетчатая структура RSC-
кода, представленного на рис. 8.25, а
Считается, что входной бит с одинаковой вероятностью может принимать как значение 1, так и 0. Кроме того, ![]() показывает те же статистические вероятности, что
показывает те же статистические вероятности, что ![]() [17]: Просвет одинаков у RSC-кода (рис. 8.25, а) и NSC-кода (рис. 8.24). Точно так же совпадает их решетчатая структура по отношению к переходам между состояниями и соответствующим входным битам. Впрочем, у RSC- и NSC-кодов две выходные последовательности
[17]: Просвет одинаков у RSC-кода (рис. 8.25, а) и NSC-кода (рис. 8.24). Точно так же совпадает их решетчатая структура по отношению к переходам между состояниями и соответствующим входным битам. Впрочем, у RSC- и NSC-кодов две выходные последовательности ![]() и
и ![]() не соответствуют той же входной последовательности
не соответствуют той же входной последовательности ![]() . Можно сказать, что при тех же генераторах кода распределение весовых коэффициентов кодовых слов RSC-кодера не изменяется, по сравнению с распределением весовых коэффициентов кодовых слов NSC-кодера. Единственное различие состоит в отображении между входной и выходной последовательностями данных.
. Можно сказать, что при тех же генераторах кода распределение весовых коэффициентов кодовых слов RSC-кодера не изменяется, по сравнению с распределением весовых коэффициентов кодовых слов NSC-кодера. Единственное различие состоит в отображении между входной и выходной последовательностями данных.
Пример 8.5. Рекурсивные кодеры и их решетчатые диаграммы
а) Используя RSC-кодер (рис. 8.25, а), проверьте справедливость участка решетчатой структуры (диаграммы), изображенного на рис. 8.25, б.
б) Для кодера, указанного в п. а, начиная с последовательности данных ![]() = 1110, поэтапно покажите процедуру кодирования до нахождения выходного кодового слова.
= 1110, поэтапно покажите процедуру кодирования до нахождения выходного кодового слова.
Решение
а) Для кодеров NSC содержимое регистра и переходы между состояниями отслеживаются непосредственно. Но если кодер является рекурсивным, следует быть очень аккуратным. В табл. 8.5 содержится 8 строк, соответствующих 8 возможным переходам в данной системе, образованной из 4-х состояний. Первые четыре строки представляют переходы, когда входной информационный бит ![]() является двоичным нулем, а последние четыре — переходы, в которых
является двоичным нулем, а последние четыре — переходы, в которых ![]() является единицей. В данном случае процедуру кодирования с помощью табл. 8.5 и рис. 8.25 можно поэтапно описать следующим образом.
является единицей. В данном случае процедуру кодирования с помощью табл. 8.5 и рис. 8.25 можно поэтапно описать следующим образом.
1. В момент введения произвольного входного бита, k, состояние перед переходом (начальное) определяется содержимым двух крайних разрядов регистра, а именно ![]() и
и ![]() .
.
2. В любой строке таблицы (переход на решетке) поиск содержимого разряда ![]() выполняется сложением (по модулю 2) битов
выполняется сложением (по модулю 2) битов ![]() ,
, ![]() и
и ![]() в этой строке.
в этой строке.
3. Выходная кодовая последовательность битов, ![]() , для каждого возможного начального состояния (т.е. а = 00, b = 10, с = 01 и d = 11) находится путем прибавления (по модулю 2)
, для каждого возможного начального состояния (т.е. а = 00, b = 10, с = 01 и d = 11) находится путем прибавления (по модулю 2) ![]() и
и ![]() к
к ![]() .
.
Таблица 8.5. Проверка участка решетки с рис. 8.25, б
|
Входной бит |
Текущий бит |
Начальное состояние |
Кодовые биты |
Конечное состояние |
|
|
|
|
|
|
|
0 |
0 1 1 0 |
0 0 1 0 0 1 1 1 |
0 0 0 1 0 0 0 1 |
0 0 1 1 1 0 0 1 |
|
1 |
1 0 0 1 |
0 0 1 0 0 1 1 1 |
1 1 1 0 1 1 1 0 |
1 0 0 1 0 0 1 1 |
Нетрудно убедиться, что элементы табл. 8.5 соответствуют участку решетки, изображенному на рис. 8.25, б. При использовании для реализации составных кодов регистров сдвига у турбокодеров проявляется интересное свойство, которое заключается в том, что два перехода, входящие в состояние, не соответствуют одному и тому же входному битовому значению (т.е. в данное состояние не входят две сплошные или две пунктирные линии). Это свойство проявляется, если полиномиальное описание обратной связи регистра сдвига имеет все порядки или одна из линий обратной связи выходит из разряда более высокого порядка, в данном случае ![]() .
.
б) Существует два способа реализации кодирования входной информационной последовательности ![]() =1110. Первый состоит в применении решетчатой диаграммы, а другой — в использовании цепи кодера. Воспользовавшись участком решетки, изображенным на рис. 8.25, б, мы выбираем переход по пунктирной линии (представляющий двоичную единицу) из состояния а = 00 (естественный выбор начального состояния) в следующее состояние b = 10 (которое подходит в качестве стартового для следующего входного бита). Следует заметить, что биты показаны на этом переходе как выходная кодовая последовательность 11. Эта процедура повторяется для каждого входного бита. Другой способ предполагает построение таблицы, такой как табл. 8.6, на основе цепи кодера, изображенной на рис. 8.25, а. Здесь время k показано от начала до конца всей процедуры (5 моментов времени и 4 временных интервала). Табл. 8.6 записывается в следующем порядке.
=1110. Первый состоит в применении решетчатой диаграммы, а другой — в использовании цепи кодера. Воспользовавшись участком решетки, изображенным на рис. 8.25, б, мы выбираем переход по пунктирной линии (представляющий двоичную единицу) из состояния а = 00 (естественный выбор начального состояния) в следующее состояние b = 10 (которое подходит в качестве стартового для следующего входного бита). Следует заметить, что биты показаны на этом переходе как выходная кодовая последовательность 11. Эта процедура повторяется для каждого входного бита. Другой способ предполагает построение таблицы, такой как табл. 8.6, на основе цепи кодера, изображенной на рис. 8.25, а. Здесь время k показано от начала до конца всей процедуры (5 моментов времени и 4 временных интервала). Табл. 8.6 записывается в следующем порядке.
1. В произвольный момент времени бит данных ![]() начинает преобразовываться в
начинает преобразовываться в ![]() путем суммирования его (по модулю 2) с битами
путем суммирования его (по модулю 2) с битами ![]() и
и ![]() в той же строке.
в той же строке.
2. Например, в момент времени k = 2 бит данных ![]() преобразуется в
преобразуется в ![]() путем суммирования его с битами
путем суммирования его с битами ![]() и
и ![]() в той же строке k = 2.
в той же строке k = 2.
3. Итоговый выход ![]() , определяемый логической схемой кодера, является кодовой битовой последовательностью, связанной со временем k = 2 (в действительности — интервалом между k = 2 и k = 3).
, определяемый логической схемой кодера, является кодовой битовой последовательностью, связанной со временем k = 2 (в действительности — интервалом между k = 2 и k = 3).
4. В момент k = 2 содержимое крайних правых разрядов ![]() представляет собой состояние системы в начале этого переходам.
представляет собой состояние системы в начале этого переходам.
5. Конечное состояние этого перехода представляется содержимым двух крайних левых регистров ![]() в той же строке (01). Поскольку сдвиг битов происходит слева направо, это конечное состояние перехода в момент k = 3 будет представлено как стартовое в следующей строке.
в той же строке (01). Поскольку сдвиг битов происходит слева направо, это конечное состояние перехода в момент k = 3 будет представлено как стартовое в следующей строке.
6. Каждая строка описывается аналогично. Таким образом, в последнем столбце табл. 8.6 можно будет увидеть кодированную последовательность 1 1 1 0 1 1 0 0.
Таблица 8.6. Кодирование битовой последовательности с помощью кодера, изображенного на рис. 8.25, а
| Время | Входной бит | Первый разряд | Состояние в момент k | Кодовые биты |
| k | ||||
| 1 | 1 | 1 | 0 0 | 1 1 |
| 2 | 1 | 0 | 1 0 | 1 0 |
| 3 | 1 | 0 | 0 1 | 1 1 |
| 4 | 0 | 0 | 0 0 | 0 0 |
| 5 | 0 0 |
8.4.4.1. Конкатенация кодов RSC
Рассмотрим параллельную конкатенацию двух RSC-кодеров, подобных изображенному на рис. 8.25. Хороший турбокод строится из составных кодов с небольшой длиной кодового ограничения (К=3-5). В качестве примера такого турбокодера можно взять кодер, показанный на рис. 8.26, где переключатель ![]() делает степень кодирования всего кода равной 1/2. Без переключателя степень кодирования кода будет равна 1/3. Ограничений на количество соединяемых кодеров нет. Составные коды должны иметь одинаковую длину кодового ограничения и степень кодирования. Целью разработки турбохода является наилучший подбор составных кодов путем минимизации просвета кода [21]. При больших значениях
делает степень кодирования всего кода равной 1/2. Без переключателя степень кодирования кода будет равна 1/3. Ограничений на количество соединяемых кодеров нет. Составные коды должны иметь одинаковую длину кодового ограничения и степень кодирования. Целью разработки турбохода является наилучший подбор составных кодов путем минимизации просвета кода [21]. При больших значениях ![]() это эквивалентно максимизации минимального весового коэффициента кодовых слов. Хотя при низких значениях
это эквивалентно максимизации минимального весового коэффициента кодовых слов. Хотя при низких значениях ![]() (область, представляющая наибольший интерес) оптимизация распределения весовых коэффициентов кодовых слов является более важной, чем их максимизация или минимизация [20].
(область, представляющая наибольший интерес) оптимизация распределения весовых коэффициентов кодовых слов является более важной, чем их максимизация или минимизация [20].
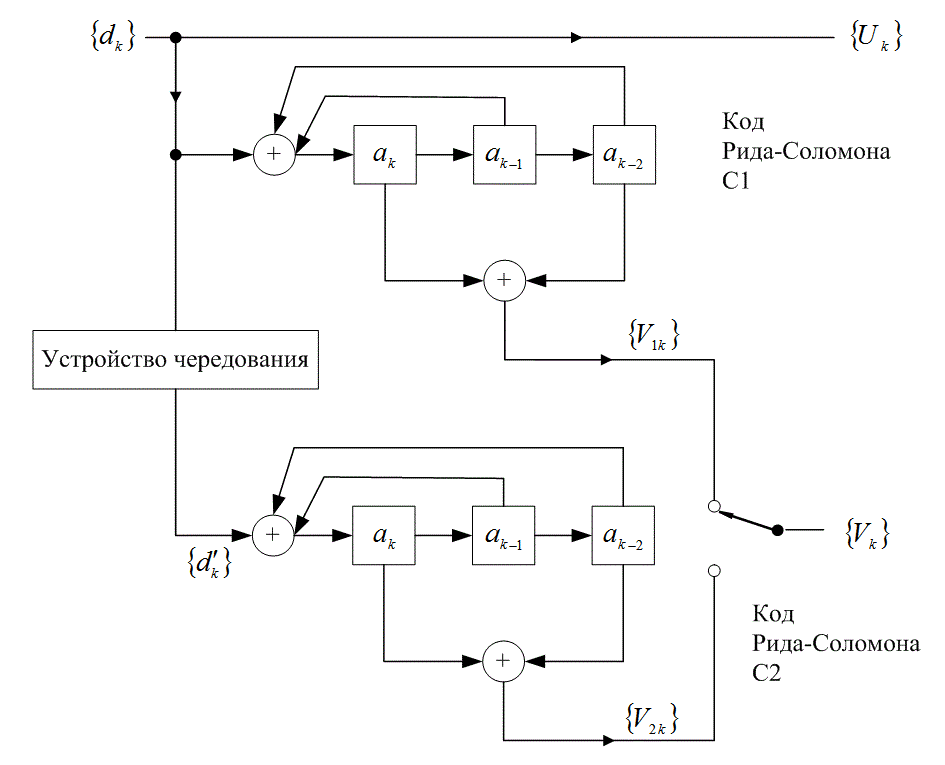
Рис. 8.26. Схема параллельного соединения двух RSC-кодеров
Турбокодер, изображенный на рис. 8.26, выдает кодовые слова из каждого из двух своих составных кодеров. Распределение весовых коэффициентов кодовых слов без такого параллельного соединения зависит от того, сколько кодовых слов из одного составного кодера комбинируется с кодовыми словами из другого составного кодера.
Интуитивно понятно, что следует избегать спаривания кодовых слов с малым весовым коэффициентом из одного кодера с кодовыми словами с малым весовым коэффициентом из другого кодера. Большого количества таких спариваний можно избежать, сконфигурировав надлежащим образом устройство чередования. Устройство, которое обрабатывает данные случайным образом, более эффективно, чем рассмотренное ранее блочное устройство чередования [22].
Если составной кодер не рекурсивный, входная последовательность с единичным весовым коэффициентом (0 0... 0 0 1 0 0 ... 0 0) всегда будет генерировать кодовое слово с малым весовым коэффициентом на входе второго кодера, при любой конструкции устройства чередования. Иначе говоря, устройство чередования не сможет повлиять на выходное распределение весовых коэффициентов кодовых слов, если составные коды не рекурсивные. Впрочем, если составные коды рекурсивные, входная последовательность с единичным весовым коэффициентом генерирует бесконечную импульсную характеристику (выход с бесконечным весовым коэффициентом). Следовательно, при рекурсивных кодах входная последовательность с единичным весовым коэффициентом не дает кодового слова с минимальным весовым коэффициентом вне кодера. Кодированный выходной весовой коэффициент сохраняется конечным только при погашении решетки, процессе, принуждающем кодированную последовательность к переходу в конечное состояние таким образом, что кодер возвращается к нулевому состоянию. Фактически сверточный код преобразуется в блочный.
Для кодера, изображенного на рис. 8.26, кодовое слово с минимальным весовым коэффициентом для каждого составного кодера порождается входной последовательностью с весовым коэффициентом 3 (0 0 ... 0 0 1 1 1 0 0 0 ... 0 0) и тремя последовательными единицами. Другая последовательность, порождающая кодовые слова с малым весом, представлена последовательностью с весом 2 (0 0 ... 0 0 1 0 0 1 0 0 ... 0 0). Однако после перестановок, внесенных устройством чередования, любая из этих опасных структур имеет слабую вероятность появления на входе второго кодера, что делает маловероятной возможность комбинирования одного кодового слова с малым весом с другим кодовым словом с малым весом.
Важным аспектом компоновки турбокодов является их рекурсивность (систематический аспект незначителен). Это бесконечная импульсная характеристика, присущая кодам RSC, которая является защитой от генерации кодовых слов с малым весом, не поддающихся исправлению в устройстве чередования. Можно обсудить то, что производительность турбокодера сильно поддается влиянию со стороны кодовых слов с малым весом, производимых входной последовательностью с весом 2. В защиту этого можно сказать, что входную последовательность с весом 1 можно проигнорировать, поскольку она дает кодовые слова с большим весом из-за бесконечной импульсной характеристики кодера. Для входной последовательности, имеющей вес 3 и более, правильно сконфигурированное устройство чередования делает вероятность появления кодовых слов с малым весом на выходе относительно низкой [21—25].
8.4.5. Декодер с обратной связью
Использование алгоритма Витерби является оптимальным методом декодирования для минимизации вероятности появления ошибочной последовательности. К сожалению, этот алгоритм (с жесткой схемой на выходе) не подходит для генерации апостериорной вероятности (a posteriori probability — АРР) или мягкой схемы на выходе для каждого декодированного бита. Подходящий для этой задачи алгоритм был предложен Балом и др. [26]. Алгоритм Бала был модифицирован Берру и др. [17] для использования в кодах RSC. Апостериорную вероятность того, что декодированный бит данных ![]() , можно вывести из совместной вероятности
, можно вывести из совместной вероятности ![]() Х., определяемой как
Х., определяемой как
![]() (8.108)
(8.108)
где ![]() — состояние кодера в момент времени k, a
— состояние кодера в момент времени k, a ![]() — принятая двоичная последовательность за время от k = 1 в течение некоторого времени N.
— принятая двоичная последовательность за время от k = 1 в течение некоторого времени N.
Таком образом, апостериорная вероятность того, что декодированный информационный бит ![]() представляется как двоичная цифра, получается путем суммирования совокупных вероятностей по всем состояниям.
представляется как двоичная цифра, получается путем суммирования совокупных вероятностей по всем состояниям.
![]()
![]() (8.109)
(8.109)
Далее логарифмическое отношение правдоподобий (log-likelihood ratio — LLR) переписывается как логарифм отношения апостериорных вероятностей.
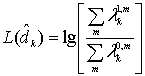 (8.110)
(8.110)
Декодер осуществляет схему решений, известную как решающее правило максимума апостериорной вероятности (maximum a posteriori — MAP), путем сравнения ![]() с нулевым пороговым значением.
с нулевым пороговым значением.
![]() если
если ![]()
(8.111)
![]() если
если ![]()
Для систематического кода LLR ![]() , связанное с каждым декодированным битом
, связанное с каждым декодированным битом ![]() , можно описать как сумму LLR для dk вне демодулятора и других LLR, порождаемых декодером (внешние сведения), как показано уравнениями (8.72) и (8.73). Рассмотрим обнаружение последовательности данных с помехами, исходящей из кодера, изображенного на рис. 8.26, с помощью декодера, представленного на рис. 8.27. Предполагается, что используется двоичная модуляция и дискретный гауссов канал без памяти. Вход декодера формируется набором Rk из двух случайных переменных
, можно описать как сумму LLR для dk вне демодулятора и других LLR, порождаемых декодером (внешние сведения), как показано уравнениями (8.72) и (8.73). Рассмотрим обнаружение последовательности данных с помехами, исходящей из кодера, изображенного на рис. 8.26, с помощью декодера, представленного на рис. 8.27. Предполагается, что используется двоичная модуляция и дискретный гауссов канал без памяти. Вход декодера формируется набором Rk из двух случайных переменных ![]() и
и ![]() . Для битов
. Для битов ![]() и
и ![]() , которые в момент времени k представляются двоичными числами (1, 0), переход к принятым биполярным импульсам (+1, -1) можно записать следующим образом.
, которые в момент времени k представляются двоичными числами (1, 0), переход к принятым биполярным импульсам (+1, -1) можно записать следующим образом.
![]() (8.112)
(8.112)
и
![]() (8.113)
(8.113)
Здесь ![]() и
и ![]() являются двумя случайными статистически независимыми переменными с одинаковой дисперсией
являются двумя случайными статистически независимыми переменными с одинаковой дисперсией ![]() , определяющей распределение помех. Избыточная информация yk разуплотняется и пересылается на декодер DEC1 как
, определяющей распределение помех. Избыточная информация yk разуплотняется и пересылается на декодер DEC1 как ![]() , если
, если ![]() , и на декодер DEC2 как
, и на декодер DEC2 как ![]() , если
, если ![]() . Если избыточная информация начальным декодером не передается, то вход соответствующего декодера устанавливается на нуль. Следует отметить, что выход декодера DEC1 имеет структуру чередования, аналогичную структуре, использованной в передатчике между двумя составными кодерами. Это связано с тем, что информация, обрабатываемая декодером, DEC1, является неизмененным выходом кодера С1 (искаженной канальным шумом). И наоборот, информация, обрабатываемая декодером DEC2, является искаженным выходом кодер С2, вход которого составляют как раз те данные, что поступают в С1, но обработаны устройством чередования. Декодер DEC2 пользуется выходом декодера DEC1, обеспечивая такое же временное упорядочение этого выхода, как и входа С2 (т.е. две последовательности в декодере DEC2 должны придерживаться позиционной структуры сигналов в каждой последовательности).
. Если избыточная информация начальным декодером не передается, то вход соответствующего декодера устанавливается на нуль. Следует отметить, что выход декодера DEC1 имеет структуру чередования, аналогичную структуре, использованной в передатчике между двумя составными кодерами. Это связано с тем, что информация, обрабатываемая декодером, DEC1, является неизмененным выходом кодера С1 (искаженной канальным шумом). И наоборот, информация, обрабатываемая декодером DEC2, является искаженным выходом кодер С2, вход которого составляют как раз те данные, что поступают в С1, но обработаны устройством чередования. Декодер DEC2 пользуется выходом декодера DEC1, обеспечивая такое же временное упорядочение этого выхода, как и входа С2 (т.е. две последовательности в декодере DEC2 должны придерживаться позиционной структуры сигналов в каждой последовательности).
8.4.5.1. Декодирование при наличии контура обратной связи
Уравнение (8.71) можно переписать для мягкого выхода в момент времени k с нулевой начальной установкой априорного LLR ![]() . Это делается на основе предположения о равной вероятности информационных битов. Следовательно,
. Это делается на основе предположения о равной вероятности информационных битов. Следовательно,
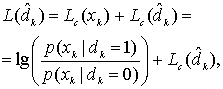 (8.114)
(8.114)
где ![]() — мягкий выход декодера, а
— мягкий выход декодера, а ![]() — LLR канального измерения, получаемый из отношения функций правдоподобия
— LLR канального измерения, получаемый из отношения функций правдоподобия ![]() , связанных с моделью дискретного канала без памяти
, связанных с моделью дискретного канала без памяти ![]() является функцией избыточной информации. Это внешние сведения, получаемые декодером и не зависящие от входных данных xk декодера. В идеале Lc(xk) и
является функцией избыточной информации. Это внешние сведения, получаемые декодером и не зависящие от входных данных xk декодера. В идеале Lc(xk) и ![]() искажаются некоррелированным шумом, а следовательно,
искажаются некоррелированным шумом, а следовательно, ![]() может использоваться как новое наблюдение
может использоваться как новое наблюдение ![]() другим декодером для образования итеративного процесса. Основным принципом передачи информации обратно на другой декодер является то, что декодер никогда не следует заполнять собственными данными (иначе искажения на входе и выходе будут сильно коррелировать).
другим декодером для образования итеративного процесса. Основным принципом передачи информации обратно на другой декодер является то, что декодер никогда не следует заполнять собственными данными (иначе искажения на входе и выходе будут сильно коррелировать).
Для гауссового канала в уравнении (8.114) при описании канального LLR Lc(xk) использовался натуральный логарифм, как и в уравнении (8.77). Уравнение (8.77,в) можно переписать следующим образом.
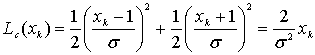 (8.115)
(8.115)
Оба декодера, DEC1 и DEC2, используют модифицированный алгоритм Бала [26]. Если данные ![]() и
и ![]() подаваемые на вход декодера DEC2 (рис. 8.27), являются статистически независимыми, то LLR
подаваемые на вход декодера DEC2 (рис. 8.27), являются статистически независимыми, то LLR ![]() на выходе декодера DEC2 можно переписать как
на выходе декодера DEC2 можно переписать как
![]() (8.116)
(8.116)
при
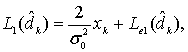 (8.117)
(8.117)
где ![]() используется для выражения функциональной зависимости. Внешние сведения
используется для выражения функциональной зависимости. Внешние сведения ![]() вне декодера DEC2 являются функцией последовательности
вне декодера DEC2 являются функцией последовательности ![]() Поскольку
Поскольку ![]() зависит от наблюдения
зависит от наблюдения ![]() , внешние сведения
, внешние сведения ![]() коррелируют с наблюдениями xk и
коррелируют с наблюдениями xk и ![]() Тем не менее, чем больше значение
Тем не менее, чем больше значение ![]() тем меньше коррелируют
тем меньше коррелируют![]() и наблюдения
и наблюдения ![]() и
и ![]() . Вследствие чередования выходов декодеров DEC1 и DEC2, внешние сведения
. Вследствие чередования выходов декодеров DEC1 и DEC2, внешние сведения ![]() слабо коррелируют с наблюдениями
слабо коррелируют с наблюдениями ![]() и
и ![]() . Поэтому можно совместно использовать их для декодирбвания битов
. Поэтому можно совместно использовать их для декодирбвания битов ![]() [17]. На рис. 8.27 показана процедура подачи параметра
[17]. На рис. 8.27 показана процедура подачи параметра ![]() на декодер DEC1 как эффект разнесения в итеративном процессе. Вообще,
на декодер DEC1 как эффект разнесения в итеративном процессе. Вообще, ![]() имеет тот же знак, что и
имеет тот же знак, что и ![]()
![]() . Следовательно,
. Следовательно, ![]() может увеличить соответствующее LLR и, значит, повысить надежность каждого декодированного бита данных.
может увеличить соответствующее LLR и, значит, повысить надежность каждого декодированного бита данных.
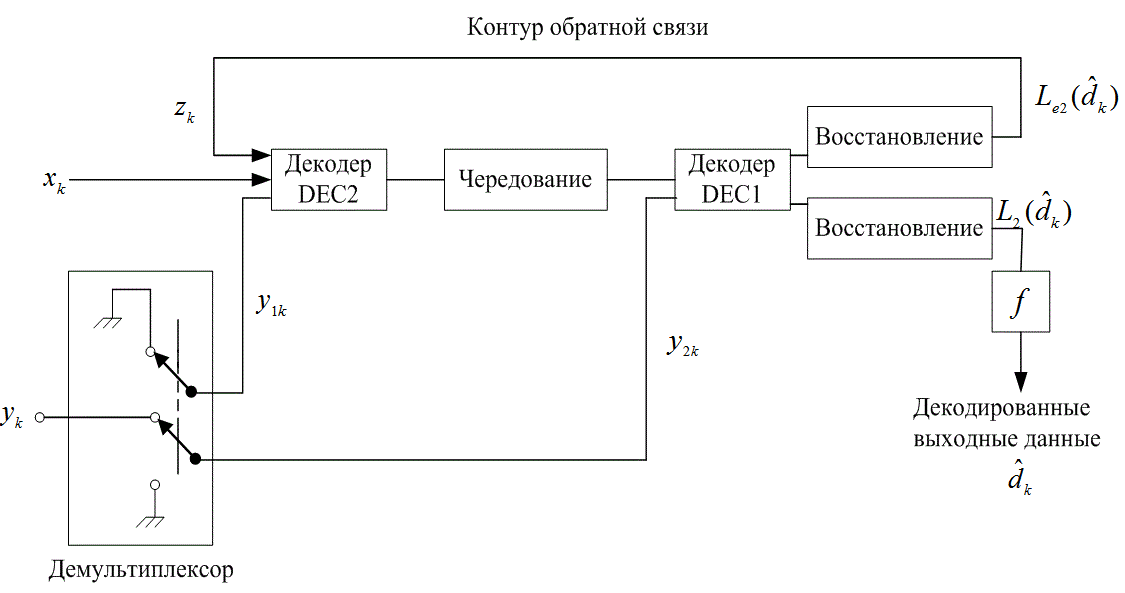
Рис. 8.27 Схема оекооера с ооратнои связью
Подробное описание алгоритма вычисления LLR ![]() апостериорной вероятности каждого бита данных было представлено несколькими авторами [17, 18, 30]. В работах [27—31] были высказаны предположения относительно снижения конструктивной сложности алгоритмов. Приемлемый подход к представлению процесса, дающего значения апостериорной вероятности для каждого информационного бита, состоит в реализации оценки максимально правдоподобной последовательности, или алгоритма Витерби, и вычислении ее по двум направлениям блоков кодовых битов. Если осуществлять такой двунаправленный алгоритм Витерби по схеме раздвижных окон — получатся метрики, связанные с предшествующими и последующими состояниями. В результате получим апостериорную вероятность для каждого бита данных, имеющегося в блоке. Итак, декодирование турбоходов можно оценить как в два раза более сложное, чем декодирование одного из составных кодов с помощью алгоритма Витерби.
апостериорной вероятности каждого бита данных было представлено несколькими авторами [17, 18, 30]. В работах [27—31] были высказаны предположения относительно снижения конструктивной сложности алгоритмов. Приемлемый подход к представлению процесса, дающего значения апостериорной вероятности для каждого информационного бита, состоит в реализации оценки максимально правдоподобной последовательности, или алгоритма Витерби, и вычислении ее по двум направлениям блоков кодовых битов. Если осуществлять такой двунаправленный алгоритм Витерби по схеме раздвижных окон — получатся метрики, связанные с предшествующими и последующими состояниями. В результате получим апостериорную вероятность для каждого бита данных, имеющегося в блоке. Итак, декодирование турбоходов можно оценить как в два раза более сложное, чем декодирование одного из составных кодов с помощью алгоритма Витерби.
8.4.5.2. Достоверность передачи при турбокодировании
В [17] приведены результаты моделирования методом Монте-Карло кодера со степенью кодирования 1/2, K = 5, построенного на генераторах ![]() = {1 1 1 1 1} и
= {1 1 1 1 1} и ![]() = {1 0 0 0 1}, при параллельном соединении и использовании устройства чередования с массивом
= {1 0 0 0 1}, при параллельном соединении и использовании устройства чередования с массивом ![]() . Был использован модифицированный алгоритм Бала и блок, длиной 65536 бит. После 18 итераций декодирования вероятность появления ошибки в бите
. Был использован модифицированный алгоритм Бала и блок, длиной 65536 бит. После 18 итераций декодирования вероятность появления ошибки в бите ![]() была меньше
была меньше ![]() при
при ![]() дБ. Характер снижения вероятности появления ошибки при увеличении числа итераций можно увидеть на рис. 8.28. Заметьте, что достигается предел Шеннона -1,6 дБ. Требуемая ширина полосы пропускания приближается к бесконечности, а емкость (степень кодирования кода) приближается к нулю. Поэтому предел Шеннона является интересной границей с теоретической точки зрения, но не является практической целью. Для двоичной модуляции несколько авторов использовали в качестве практического предела Шеннона значения
дБ. Характер снижения вероятности появления ошибки при увеличении числа итераций можно увидеть на рис. 8.28. Заметьте, что достигается предел Шеннона -1,6 дБ. Требуемая ширина полосы пропускания приближается к бесконечности, а емкость (степень кодирования кода) приближается к нулю. Поэтому предел Шеннона является интересной границей с теоретической точки зрения, но не является практической целью. Для двоичной модуляции несколько авторов использовали в качестве практического предела Шеннона значения ![]() и
и ![]() дБ для кода со степенью кодирования 1/2. Таким образом, при параллельном соединении сверточных кодов RSC и декодировании с обратной связью, достоверность передачи турбокода при
дБ для кода со степенью кодирования 1/2. Таким образом, при параллельном соединении сверточных кодов RSC и декодировании с обратной связью, достоверность передачи турбокода при ![]() находится в 0,5 дБ от (практического) предела Шеннона. Существует класс кодов, в которых, вместо параллельного, используется последовательное соединение чередуемых компонентов. Предполагается, что последовательное соединение кодов может дать характеристики [28], превышающие аналоги при параллельном соединении.
находится в 0,5 дБ от (практического) предела Шеннона. Существует класс кодов, в которых, вместо параллельного, используется последовательное соединение чередуемых компонентов. Предполагается, что последовательное соединение кодов может дать характеристики [28], превышающие аналоги при параллельном соединении.
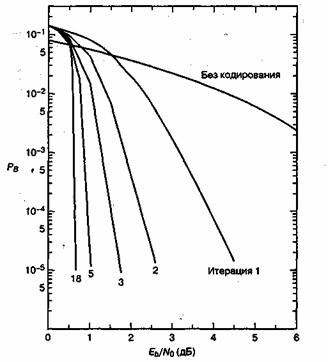
Рис. 8.28. Вероятность появления битовой ошибки как функция Eb/N0 и количества итераций. (Источник: Berrou С., Glavieux A. and Thitimajshima P. "Near Shannon Limit Error-Correcting Coding and Decoding: Turbo Codes". IEEE Proc. of Int'l Conf on Communications, Geneva, Switzerland, May, 1993 (ICC '93), pp. 1064-1070.)
8.4.6. Алгоритм MAP
Процесс декодирования турбокода начинается с формирования апостериорных вероятностей (a posteriori probability — АРР) для всех информационных битов, которые затем используются для изменения значений информационных битов в соответствии с принципом максимума апостериорной (maximum a posteriori— MAP) вероятности информационного бита. В ходе приема искаженной последовательности кодированных битов осуществляется схема принятия решений, основанная на значениях апостериорных вероятностей, и алгоритм MAP для определения наиболее вероятного информационного бита, который должен быть передан за время прохождения бита. Здесь имеется отличие от алгоритма Витерби, в котором апостериорная вероятность для каждого бита данных не существует. Вместо этого в алгоритме Витерби находится наиболее вероятная последовательность, которая могла быть передана. Но в реализации обоих алгоритмов, впрочем, имеется сходство (см. раздел 8.4.6.3). Если декодированное ![]() мало, существует незначительное различие в производительности между алгоритмами MAP и Витерби с мягкий выходом (soft-output Viterbi algorithm— SOVA). Более того, при высоких значениях
мало, существует незначительное различие в производительности между алгоритмами MAP и Витерби с мягкий выходом (soft-output Viterbi algorithm— SOVA). Более того, при высоких значениях ![]() и низких значениях
и низких значениях ![]() алгоритм MAP превосходит алгоритм SOVA на 0,5 дБ и более [30, 31]. Это может оказаться очень важным для турбокодов, поскольку первая итерация декодирования может давать довольно высокую вероятность ошибки. Алгоритм MAP основывается на той же идее, что и алгоритм Витерби, — обработка блоков кодовых битов в двух направлениях. Как только такое двунаправленное вычисление даст состояние и метрики ветвей блока, можно начинать расчет апостериорной вероятности и MAP для каждого бита данных в блоке. Здесь предлагается алгоритм MAP декодирования для систематических сверточных кодов; полагается, что используется канал AWGN, как указано Питробоном [30]. Расчет начинается с отношения значений апостериорных вероятностей, известных как отношения правдоподобий
алгоритм MAP превосходит алгоритм SOVA на 0,5 дБ и более [30, 31]. Это может оказаться очень важным для турбокодов, поскольку первая итерация декодирования может давать довольно высокую вероятность ошибки. Алгоритм MAP основывается на той же идее, что и алгоритм Витерби, — обработка блоков кодовых битов в двух направлениях. Как только такое двунаправленное вычисление даст состояние и метрики ветвей блока, можно начинать расчет апостериорной вероятности и MAP для каждого бита данных в блоке. Здесь предлагается алгоритм MAP декодирования для систематических сверточных кодов; полагается, что используется канал AWGN, как указано Питробоном [30]. Расчет начинается с отношения значений апостериорных вероятностей, известных как отношения правдоподобий ![]() , или их логарифмов,
, или их логарифмов, ![]() , называемых логарифмическими отношениями правдоподобий (log-likelihood ratio — LLR), как было показано в уравнении (8.110).
, называемых логарифмическими отношениями правдоподобий (log-likelihood ratio — LLR), как было показано в уравнении (8.110).
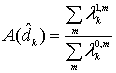 (8.118,a)
(8.118,a)
(8.119,б)
Здесь ![]() (совокупная вероятность того, что
(совокупная вероятность того, что ![]() и
и ![]() , при условии, что принята кодовая последовательность
, при условии, что принята кодовая последовательность ![]() , получаемая с момента k = 1 в течение некоторого времени N) определяется уравнением (8.108) и повторно риводится ниже.
, получаемая с момента k = 1 в течение некоторого времени N) определяется уравнением (8.108) и повторно риводится ниже.
![]() (8.119)
(8.119)
где ![]() представляет искаженную последовательность кодированных битов, передаваемую по каналу, демодулированную и поданную на декодер согласно мягкой схеме решений. В действительности, алгоритм MAP требует, чтобы последовательность на выходе демодулятора подавалась на декодер по одному блоку из N бит за такт. Пусть
представляет искаженную последовательность кодированных битов, передаваемую по каналу, демодулированную и поданную на декодер согласно мягкой схеме решений. В действительности, алгоритм MAP требует, чтобы последовательность на выходе демодулятора подавалась на декодер по одному блоку из N бит за такт. Пусть ![]() имеет следующий вид.
имеет следующий вид.
![]() (8.120)
(8.120)
Чтобы упростить применение теоремы Байеса, уравнение (8.119) переписывается с использованием букв А, В, С и D. Таким образом, уравнение (8.119) примет следующий вид.
![]() (8.121)
(8.121)
Вспомним, что теорема Байеса гласит следующее.
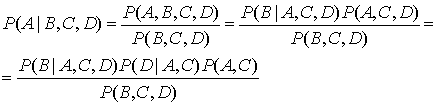 (8.122)
(8.122)
Отсюда, в приложении теоремы к уравнению (8.121) получается следующее.
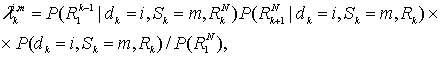 (8.123)
(8.123)
причем ![]() . Уравнение (8.123) можно переписать, выделяя вероятностный член, вносящий вклад
. Уравнение (8.123) можно переписать, выделяя вероятностный член, вносящий вклад ![]() . В следующем разделе три множителя в правой части уравнения (8.123) будут определены и описаны как прямая метрика состояния, обратная метрика состояния и метрика ветви.
. В следующем разделе три множителя в правой части уравнения (8.123) будут определены и описаны как прямая метрика состояния, обратная метрика состояния и метрика ветви.
8.4.6.1. Метрики состояний и метрика ветви
Первый множитель в правой части уравнения (8.123) является прямой метрикой состояния для момента k и состояния т и обозначается ![]() . Таким образом, для i = 1,0
. Таким образом, для i = 1,0
![]() (8.124)
(8.124)
Следует отметить, что dk = i и ![]() обозначены как несущественные, поскольку предположение о том, что
обозначены как несущественные, поскольку предположение о том, что ![]() , подразумевает, что на события до момента k не влияют измерения после момента k. Другими словами, будущее не оказывает влияния на прошлое; таким образом,
, подразумевает, что на события до момента k не влияют измерения после момента k. Другими словами, будущее не оказывает влияния на прошлое; таким образом, ![]() не зависит от того, что dk = i и последовательность равна
не зависит от того, что dk = i и последовательность равна ![]() . В то же время, поскольку кодер обладает памятью, состояние кодера
. В то же время, поскольку кодер обладает памятью, состояние кодера ![]() основывается на прошлом, а значит, этот член является значимым и его следует оставить в выражении. Очевидно, что форма уравнения (8.124) является понятной, поскольку представляет прямую метрику состояния
основывается на прошлом, а значит, этот член является значимым и его следует оставить в выражении. Очевидно, что форма уравнения (8.124) является понятной, поскольку представляет прямую метрику состояния ![]() для момента k как вероятность того, что прошлая последовательность зависит только от теперешнего состояния, вызванного этой последовательностью и ничем более. В этом сверточком кодере нетрудно узнать уже упоминавшийся в главе 7 Марковский процесс.
для момента k как вероятность того, что прошлая последовательность зависит только от теперешнего состояния, вызванного этой последовательностью и ничем более. В этом сверточком кодере нетрудно узнать уже упоминавшийся в главе 7 Марковский процесс.
Точно так же второй сомножитель в правой части уравнения (8.123) представляет собой обратную метрику состояния ![]() для момента времени k и состояния т, определяемую следующим выражением.
для момента времени k и состояния т, определяемую следующим выражением.
![]() (8.125)
(8.125)
Здесь ![]() — это следующее состояние, определяемое входом i и состоянием т,
— это следующее состояние, определяемое входом i и состоянием т, ![]() - обратная метрика состояния в момент
- обратная метрика состояния в момент ![]() и состояние
и состояние ![]() .Ясно, что уравнение (8.125) удовлетворяется, поскольку обратная метрика состояния (в будущий момент времени представлена как вероятность будущей последовательности, которая зависит от состояния (в будущий момент
.Ясно, что уравнение (8.125) удовлетворяется, поскольку обратная метрика состояния (в будущий момент времени представлена как вероятность будущей последовательности, которая зависит от состояния (в будущий момент ![]() ), которое, в свою очередь, является функцией входного бита и состояния (в текущий момент k).Это уже знакомое основное определение конечного автомата (см. раздел 7.2.2).
), которое, в свою очередь, является функцией входного бита и состояния (в текущий момент k).Это уже знакомое основное определение конечного автомата (см. раздел 7.2.2).
Третий сомножитель в правой части уравнения (8.123) представляет собой метрику ветви (в состоянии т, в момент времени k), которая обозначается ![]() . Таким образом, можно записать следующее.
. Таким образом, можно записать следующее.
![]() (8.126)
(8.126)
Подстановка уравнений (8.124)-(8.126) в уравнение (8.123) дает следующее, более компактное выражение для совокупной вероятности.
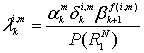 (8.127)
(8.127)
Используя уравнение (8.127), формулу (8.118) можно представить следующим образом.
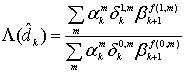 (8.128,a)
(8.128,a)
и
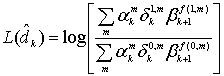 (8.128,6)
(8.128,6)
Здесь ![]() — это отношение правдоподобий k-го бита данных;
— это отношение правдоподобий k-го бита данных; ![]() , логарифм
, логарифм ![]() , является логарифмическим отношением правдоподобий для k-го бита данных, где, в общем случае, логарифм берется по основанию е.
, является логарифмическим отношением правдоподобий для k-го бита данных, где, в общем случае, логарифм берется по основанию е.
8.4.6.2. Расчет прямой метрики состояния
Исходя из уравнения (8.124), ![]() можно представить как сумму всех возможных переходов из момента
можно представить как сумму всех возможных переходов из момента ![]() .
.
![]() (8.129)
(8.129)
![]() можно переписать как
можно переписать как ![]() и, согласно теореме Байеса,
и, согласно теореме Байеса,
![]() (8.130,а)
(8.130,а)
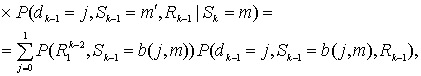 (8.130,б)
(8.130,б)
где ![]() — это состояние по предыдущей ветви, соответствующей входу j, исходящее обратно по времени из состояния т. Уравнение (8.130,6) может заменить уравнение (8.130,а), поскольку сведения о состоянии
— это состояние по предыдущей ветви, соответствующей входу j, исходящее обратно по времени из состояния т. Уравнение (8.130,6) может заменить уравнение (8.130,а), поскольку сведения о состоянии ![]() и входе j в момент времени
и входе j в момент времени ![]() полностью определяют путь в состояние
полностью определяют путь в состояние ![]() . Воспользовавшись уравнениями (8.124) и (8.126) для упрощения обозначений в уравнении (8.130), можно получить следующее.
. Воспользовавшись уравнениями (8.124) и (8.126) для упрощения обозначений в уравнении (8.130), можно получить следующее.
![]() (8.131)
(8.131)
Уравнение (8.131) означает, что новая прямая метрика состояния т в момент k получается из суммирования двух взвешенных метрик состояний в момент ![]() . Взвешивание включает метрики ветвей, связанные с переходами, соответствующими информационным битам 1 и 0. На рис. 8.29, а показано применение двух разных типов обозначений для параметра
. Взвешивание включает метрики ветвей, связанные с переходами, соответствующими информационным битам 1 и 0. На рис. 8.29, а показано применение двух разных типов обозначений для параметра ![]() . Запись
. Запись ![]() используется для обозначения прямой метрики состояния в момент времени
используется для обозначения прямой метрики состояния в момент времени ![]() , если имеется два возможных предыдущих состояния (зависящих от того, равно ли j единице или нулю). А запись
, если имеется два возможных предыдущих состояния (зависящих от того, равно ли j единице или нулю). А запись ![]() применяется для обозначения прямой метрики состояния в момент k, если имеется два возможных перехода из предыдущего момента, которые оканчиваются в том же состоянии т в момент k.
применяется для обозначения прямой метрики состояния в момент k, если имеется два возможных перехода из предыдущего момента, которые оканчиваются в том же состоянии т в момент k.

Рис. 8.29. Графическое представление расчета![]() и
и ![]() . (Источник: Pietrobon S. S. "Implementation and Performance of a Turbo/Map Decoder". Int'l. J. of Satellite Communications, vol. 16, Jan.-Feb., 1998, pp. 23-46.)
. (Источник: Pietrobon S. S. "Implementation and Performance of a Turbo/Map Decoder". Int'l. J. of Satellite Communications, vol. 16, Jan.-Feb., 1998, pp. 23-46.)
8.4.6.3. Расчет обратной метрики состояния
Возвращаясь к уравнению (8.125), где ![]() , имеем следующее.
, имеем следующее.
![]() (8.132)
(8.132)
![]() можно представить как сумму вероятностей всех возможных переходов в момент
можно представить как сумму вероятностей всех возможных переходов в момент ![]() .
.
![]() (8.133)
(8.133)
Применяя теорему Байеса, получим следующее.
![]()
(8.134)
![]()
В первом члене правой части уравнения (8.134) ![]() и
и ![]() полностью определяют путь, ведущий в
полностью определяют путь, ведущий в ![]() следующее состояние будет иметь вход j и состояние т. Таким образом, эти условия позволяют заменить
следующее состояние будет иметь вход j и состояние т. Таким образом, эти условия позволяют заменить ![]() на
на ![]() во втором члене уравнения (8.134), что дает следующее.
во втором члене уравнения (8.134), что дает следующее.
![]()
(8.135)
![]()
Уравнение (8.135) показывает, что новая обратная метрика состояния т в момент k, получается путем суммирования двух взвешенных метрик состояния в момент ![]() . Взвешивание включает метрики ветвей, связанные с переходами, соответствующими информационным битам 1 и 0. На рис. 8.29, б показано применение двух разных типов обозначений для параметра
. Взвешивание включает метрики ветвей, связанные с переходами, соответствующими информационным битам 1 и 0. На рис. 8.29, б показано применение двух разных типов обозначений для параметра ![]() . Первый тип, запись
. Первый тип, запись ![]() , используется для обозначения обратной метрики состояния в момент времени
, используется для обозначения обратной метрики состояния в момент времени ![]() , если имеется два возможных предыдущих состояния (зависящих от того, равно ли j единице или нулю). Второй тип,
, если имеется два возможных предыдущих состояния (зависящих от того, равно ли j единице или нулю). Второй тип, ![]() , применяется для обозначения обратной метрики состояния в момент k, если имеется два возможных перехода, поступающих в момент
, применяется для обозначения обратной метрики состояния в момент k, если имеется два возможных перехода, поступающих в момент ![]() , которые выходят из того же состояния т в момент времени k На рис. 8.29 приведены пояснения к вычислениям прямой и обратной метрик.
, которые выходят из того же состояния т в момент времени k На рис. 8.29 приведены пояснения к вычислениям прямой и обратной метрик.
Алгоритм декодирования MAP подобен алгоритму декодирования Витерби (см. разделЛ.З). В алгоритме Витерби метрика ветви прибавляется к метрике состояния. Затем сравнивается и выбирается минимальное расстояние (максимально правдоподобное) для получения следующей метрики состояния. Этот процесс называется сложение, сравнение и выбор (Add-Compare-Select — ACS). В алгоритме MAP выполняется умножение (в логарифмическом представлении — сложение) метрик состояния и метрик ветвей. Затем, вместо сравнения, осуществляется их суммирование для вычисления следующей прямой (обратной) метрики состояния, как это видно из рис; 8.29. Различия, воспринимаются на уровне интуиции. В алгоритме Витерби осуществляется поиск наиболее вероятной последовательности (пути); следовательно, выполняется постоянное сравнение и отбор, для того чтобы отыскать наилучший путь. В алгоритме MAP выполняется поиск правдоподобного или логарифмически правдоподобного числа (в мягкой схеме); следовательно, за период времени процесс использует все метрики из всех возможных переходов, чтобы получить полную статистическую картину информационных битов в данном периоде времени.
8.4.6.4. Расчет метрики ветви
Сначала обратимся к уравнению (8.126).
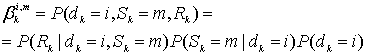 (8.136)
(8.136)
Здесь Rk представляет собой последовательность ![]() ,
, ![]() — это принятые биты данных с шумом, a
— это принятые биты данных с шумом, a ![]() — принятые контрольные биты с шумом. Поскольку помехи влияют на информационные биты и биты контроля четности независимо, текущее состояние не зависит от текущего входа и, следовательно, может быть одним из
— принятые контрольные биты с шумом. Поскольку помехи влияют на информационные биты и биты контроля четности независимо, текущее состояние не зависит от текущего входа и, следовательно, может быть одним из ![]() состояний, где
состояний, где ![]() — это число элементов памяти в сверточной кодовой системе. Иными словами, длина кодового ограничения этого кода, К, равняется
— это число элементов памяти в сверточной кодовой системе. Иными словами, длина кодового ограничения этого кода, К, равняется ![]() . Значит,
. Значит,
![]()
и
![]() , (8.137)
, (8.137)
где ![]() обозначает
обозначает ![]() , априорную вероятность dk.
, априорную вероятность dk.
Из уравнения (1.25,г) в главе 1, вероятность ![]() того, что случайная переменная Xk примет значение xk, связана с функцией плотности вероятности
того, что случайная переменная Xk примет значение xk, связана с функцией плотности вероятности ![]() следующим образом.
следующим образом.
![]() (8.138)
(8.138)
Для упрощения обозначений случайная переменная ![]() , принимающая значение
, принимающая значение ![]() , часто будет называться “случайной переменной
, часто будет называться “случайной переменной ![]() ”, которая будет представлять значения
”, которая будет представлять значения ![]() и
и ![]() в уравнении (8.137). Таким образом, для канала AWGN, в котором шум имеет нулевое среднее и дисперсию
в уравнении (8.137). Таким образом, для канала AWGN, в котором шум имеет нулевое среднее и дисперсию ![]() , при замене вероятностного члена в уравнении (8.137) его эквивалентом (функцией плотности вероятности) используется уравнение (8.138), что дает следующее.
, при замене вероятностного члена в уравнении (8.137) его эквивалентом (функцией плотности вероятности) используется уравнение (8.138), что дает следующее.
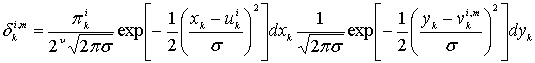 (8.139)
(8.139)
Здесь ![]() и
и ![]() представляют переданные биты данных и биты контроля четности (в биполярной форме), a
представляют переданные биты данных и биты контроля четности (в биполярной форме), a ![]() и
и ![]() являются дифференциалами xk и yk и далее будут включаться в постоянную Ak. Следует заметить, что параметр
являются дифференциалами xk и yk и далее будут включаться в постоянную Ak. Следует заметить, что параметр ![]() представляет данные, не зависящие от состояния т, поскольку код имеет память. Для того чтобы привести выражение к более простому виду, нужно исключить все члены в числителе и знаменателе и использовать сокращения; в результате получим следующее.
представляет данные, не зависящие от состояния т, поскольку код имеет память. Для того чтобы привести выражение к более простому виду, нужно исключить все члены в числителе и знаменателе и использовать сокращения; в результате получим следующее.
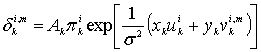 (8.140)
(8.140)
Если подставить уравнение (8.140) в уравнение (8.128,а), получим следующее.
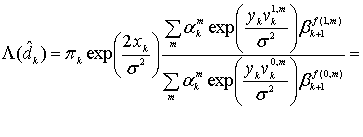 (8.141,a)
(8.141,a)
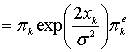 (8.141,б)
(8.141,б)
и
![]() (8.141,в)
(8.141,в)
Здесь ![]() является входным отношением априорных вероятностей (априорное правдоподобие), a
является входным отношением априорных вероятностей (априорное правдоподобие), a ![]() — внешним выходным правдоподобием, каждое в момент времени k. В уравнении (8.141,б) член
— внешним выходным правдоподобием, каждое в момент времени k. В уравнении (8.141,б) член ![]() можно считать фактором коррекции (вследствие кодирования), который меняет входные априорные сведения о битах данных. В турбокоде такие корректировочные члены проходят из одного декодера в другой, чтобы улучшить отношение правдоподобий для каждого информационного бита и, таким образом, минимизировать вероятность появления ошибок декодирования. Следойательно, процесс декодирования влечет за собой использование уравнения (8.141,б) для получения за несколько итераций
можно считать фактором коррекции (вследствие кодирования), который меняет входные априорные сведения о битах данных. В турбокоде такие корректировочные члены проходят из одного декодера в другой, чтобы улучшить отношение правдоподобий для каждого информационного бита и, таким образом, минимизировать вероятность появления ошибок декодирования. Следойательно, процесс декодирования влечет за собой использование уравнения (8.141,б) для получения за несколько итераций ![]() . Внешнее правдоподобие
. Внешнее правдоподобие ![]() , получаемое из конкретной итерации, заменяет априорное правдоподобие
, получаемое из конкретной итерации, заменяет априорное правдоподобие ![]() на следующую итерацию. Взятие логарифма от
на следующую итерацию. Взятие логарифма от ![]() в уравнении (8.141,б) дает уравнение (8.141,в), которое показывает те же результаты, что и уравнение (8.71). Они заключаются в том, что итоговые данные
в уравнении (8.141,б) дает уравнение (8.141,в), которое показывает те же результаты, что и уравнение (8.71). Они заключаются в том, что итоговые данные ![]() (согласно мягкой схеме принятия решений) образуются тремя членами LLR — априорным LLR, LLR канального измерения и внешним LLR.
(согласно мягкой схеме принятия решений) образуются тремя членами LLR — априорным LLR, LLR канального измерения и внешним LLR.
Алгоритм MAP можно реализовать через отношение правдоподобий ![]() , как показывает уравнение (8.128,а) или (8.141,в); конструкция станет менее громоздкой за счет устранения операций умножения.
, как показывает уравнение (8.128,а) или (8.141,в); конструкция станет менее громоздкой за счет устранения операций умножения.
8.4.7. Пример декодирования по алгоритму MAP
На рис. 8.30 изображен пример декодирования по алгоритму MAP. На рис. 8.30, а представлен систематический сверточный кодер с длиной кодового ограничения ![]() и степенью кодирования 1/2. Входные данные - последовательность d = {1, 0, 0}, соответствующая временам k = 1,2,3. Выходная кодированная битовая последовательность образуется путем последовательного взятия одного бита из последовательности v = {1, 0, 0} вслед за битом контроля четности из последовательности v={ 1, 0, 1}. В каждом случае крайний слева бит является самым первым. Таким образом, выходной последовательностью будет 1 1 0 0 0 1 или ее биполярное представление — +1 +1 -1 -1 -1 +1. На рис. 8.30, б видны результаты искажения последовательностей u и v векторами помех
и степенью кодирования 1/2. Входные данные - последовательность d = {1, 0, 0}, соответствующая временам k = 1,2,3. Выходная кодированная битовая последовательность образуется путем последовательного взятия одного бита из последовательности v = {1, 0, 0} вслед за битом контроля четности из последовательности v={ 1, 0, 1}. В каждом случае крайний слева бит является самым первым. Таким образом, выходной последовательностью будет 1 1 0 0 0 1 или ее биполярное представление — +1 +1 -1 -1 -1 +1. На рис. 8.30, б видны результаты искажения последовательностей u и v векторами помех ![]() и
и ![]() , так что теперь они обозначаются как
, так что теперь они обозначаются как ![]() , и
, и ![]() . Как показано на рис. 8.30, б, входные данные демодулятора, поступающие на декодер в моменты k = 1, 2, 3, имеют значения 1,5; 0,8; 0,5; 0,2; -0,6; 1,2. Также показаны априорные вероятности того, что принятые биты данных будут равны 1 или 0, что обозначается как
. Как показано на рис. 8.30, б, входные данные демодулятора, поступающие на декодер в моменты k = 1, 2, 3, имеют значения 1,5; 0,8; 0,5; 0,2; -0,6; 1,2. Также показаны априорные вероятности того, что принятые биты данных будут равны 1 или 0, что обозначается как ![]() и
и ![]() . Предполагается, что эти вероятности будут одинаковы для всех k моментов времени. В этом примере уже имеется вся необходимая информация для расчета метрик ветвей и метрик состояний и ввода их значений в решетчатую диаграмму декодера, изображенную на рис. 8.30, в. На решетчатой диаграмме каждый переход, возникающий между временами k и
. Предполагается, что эти вероятности будут одинаковы для всех k моментов времени. В этом примере уже имеется вся необходимая информация для расчета метрик ветвей и метрик состояний и ввода их значений в решетчатую диаграмму декодера, изображенную на рис. 8.30, в. На решетчатой диаграмме каждый переход, возникающий между временами k и ![]() , соответствует информационному биту dk, который появляется на входе кодера в момент начала перехода k. В момент времени k кодер находится в некотором состоянии т, а в момент
, соответствует информационному биту dk, который появляется на входе кодера в момент начала перехода k. В момент времени k кодер находится в некотором состоянии т, а в момент ![]() он переходит в новое состояние (возможно, такое же). Если использовать такую решетчатую диаграмму для отображения последовательности кодовых битов (представляющих N бит данных), последовательность будет описываться N временами переходов и
он переходит в новое состояние (возможно, такое же). Если использовать такую решетчатую диаграмму для отображения последовательности кодовых битов (представляющих N бит данных), последовательность будет описываться N временами переходов и ![]() состояниями.
состояниями.
8.4.7.1. Расчет метрик ветвей
Начнем с уравнения (8.140) при ![]() (в данном примере информационные биты считаются равновероятными для любых времен). Для простоты предполагается, что
(в данном примере информационные биты считаются равновероятными для любых времен). Для простоты предполагается, что ![]() для всех моментов и
для всех моментов и ![]() . Таким образом,
. Таким образом, ![]() примет следующий вид.
примет следующий вид.
![]() (8.142)
(8.142)
На что похожа основная функция приемника, определяемая уравнением (8.142)? Выражение напоминает корреляционный процесс. В декодере в каждый момент k принимается пара данных,( ![]() относящееся к битам данных, и
относящееся к битам данных, и ![]() , относящееся к контрольным битам). Метрика ветви рассчитывается путем умножения принятого
, относящееся к контрольным битам). Метрика ветви рассчитывается путем умножения принятого ![]() на каждый первообразный сигнал uk и принятого yk на каждый первообразный сигнал
на каждый первообразный сигнал uk и принятого yk на каждый первообразный сигнал ![]() . Для каждого перехода по решетке величина метрики ветви будет функцией того, насколько согласуются пара данных, принятых с помехами, и кодовые значения битов этого перехода по решетке. При
. Для каждого перехода по решетке величина метрики ветви будет функцией того, насколько согласуются пара данных, принятых с помехами, и кодовые значения битов этого перехода по решетке. При ![]() для вычисления восьми метрик ветвей (переходов из состояний т для всех значений данных i) применяется уравнение (8.142). Для простоты, состояния на решетке обозначены следующим образом: а = 00, b = 10, с = 01, d = 11. Заметьте, что кодированные битовые значения,
для вычисления восьми метрик ветвей (переходов из состояний т для всех значений данных i) применяется уравнение (8.142). Для простоты, состояния на решетке обозначены следующим образом: а = 00, b = 10, с = 01, d = 11. Заметьте, что кодированные битовые значения, ![]() ,
, ![]() , каждого перехода по решетке указаны над самими переходами, как можно видеть на рис. 8.30, в (только для
, каждого перехода по решетке указаны над самими переходами, как можно видеть на рис. 8.30, в (только для ![]() ), и их можно получить обычным образом, используя структуру кодера (см. раздел 7.2.4.). Для переходов по решетке на рис. 8.30, в оговаривается, что пунктирные и сплошные линии обозначают информационные биты 1 и 0. Расчеты дают такие значения.
), и их можно получить обычным образом, используя структуру кодера (см. раздел 7.2.4.). Для переходов по решетке на рис. 8.30, в оговаривается, что пунктирные и сплошные линии обозначают информационные биты 1 и 0. Расчеты дают такие значения.
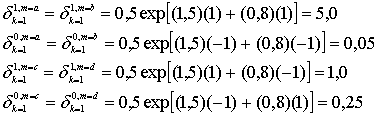
Затем эти расчеты повторяются, с помощью уравнения (8.142), для восьми метрик ветвей в момент k = 2.
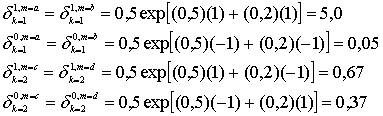
Снова расчеты повторяются для значений восьми метрик ветвей уже в момент k =3.
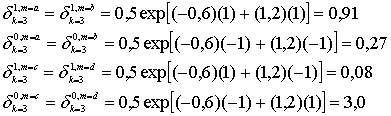
8.4.7.2. Расчет метрик состояний
Как только при всех k рассчитаны восемь значений ![]() , можно вычислить прямые метрики состояний
, можно вычислить прямые метрики состояний ![]() , воспользовавшись рис. 8.29, 8.30, в и уравнением (8.131), которое повторно приводится ниже.
, воспользовавшись рис. 8.29, 8.30, в и уравнением (8.131), которое повторно приводится ниже.
![]()
Допустим, что начальным состоянием кодера будет а = 00. Тогда,
![]() и
и ![]()
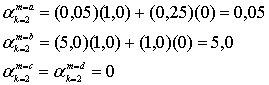 и т.д.
и т.д.
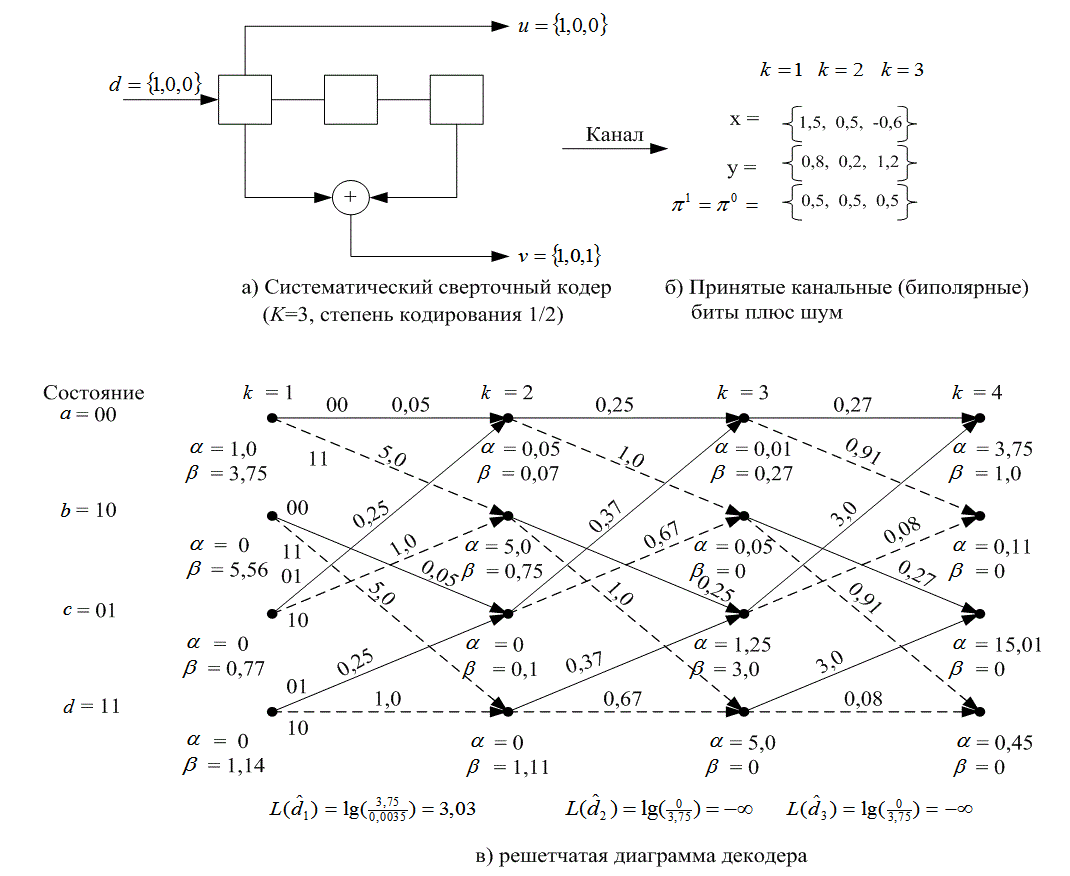
Рис. 8.30. Пример декодирования по алгоритму MAP (К = 3, степень кодирования 1/2, систематическое)
как показано с помощью решетчатой диаграммы на рис. 8.30, в. Аналогично можно вычислить обратные метрики состояний ![]() , воспользовавшись рис. 8.29, 8.30, в и уравнением (8.135), которое повторно приводится ниже.
, воспользовавшись рис. 8.29, 8.30, в и уравнением (8.135), которое повторно приводится ниже.
![]()
Последовательность данных и код в этом примере умышленно были изменены так, что финальным состоянием решетки в момент времени k = 4 является а = 00. В противном случае нужно использовать остаточные биты для принудительного изменения конечного состояния системы в такое известное состояние. Таким образом, в этом примере, проиллюстрированном на рис. 8.30, исходя из того, что конечное состояние — а = 00, можно рассчитать обратные метрики состояний.
![]() и
и ![]()
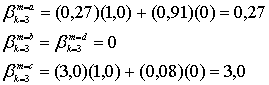
Все значения обратных метрик состояний показаны на решетке (рис. 8.30, в).
8.4.7.3. Расчет логарифмического отношения правдоподобий
Теперь у нас есть рассчитанные метрики ![]() ,
, ![]() , и
, и ![]() для кодированной битовой последовательности рассматриваемого примера. В процессе турбодекодирования для нахождения решения согласно мягкой схеме,
для кодированной битовой последовательности рассматриваемого примера. В процессе турбодекодирования для нахождения решения согласно мягкой схеме, ![]() или
или ![]() , для каждого бита данных можно воспользоваться уравнением (8.128) или (8.141). При использовании турбокодов этот процесс повторяется несколько раз, чтобы достичь необходимой надежности решений. В целом все заканчивается применением параметра внешнего правдоподобия из уравнения (8.141,б) для вычисления и повторного расчета в несколько итераций отношения правдоподобий
, для каждого бита данных можно воспользоваться уравнением (8.128) или (8.141). При использовании турбокодов этот процесс повторяется несколько раз, чтобы достичь необходимой надежности решений. В целом все заканчивается применением параметра внешнего правдоподобия из уравнения (8.141,б) для вычисления и повторного расчета в несколько итераций отношения правдоподобий ![]() . Внешнее правдоподобие
. Внешнее правдоподобие ![]() последней итерации заменяет в следующей итерации априорное правдоподобие
последней итерации заменяет в следующей итерации априорное правдоподобие ![]() .
.
В нашем примере будут использованы метрики, рассчитанные ранее (с одним прохождением через декодер). Для вычисления LLR каждого информационного бита в последовательности ![]() берется уравнение (8.128,б). Затем, с помощью правила принятия решений из уравнения (8.111), итоговые данные, представленные согласно мягкой схеме решений, преобразуются в решения в жесткой схеме. Для
берется уравнение (8.128,б). Затем, с помощью правила принятия решений из уравнения (8.111), итоговые данные, представленные согласно мягкой схеме решений, преобразуются в решения в жесткой схеме. Для ![]() , опуская некоторые нулевые слагаемые, получаем следующее.
, опуская некоторые нулевые слагаемые, получаем следующее.
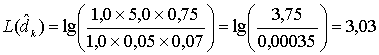
Для k = 2, опуская некоторые нулевые слагаемые, получаем следующее.
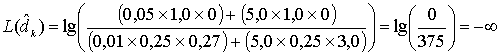
Для k = 3
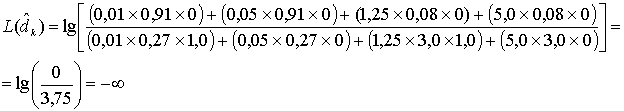
С помощью уравнения (8.111) для выражения финального решения относительно битов в моменты k = 1,2,3, последовательность декодируется как {1 0 0}. Итак, получен абсолютно точный результат, совпадающий с теми данными, которые были введены в декодер.
8.4.7.4. Реализация конечного автомата с помощью регистра сдвига
В этой книге используются регистры сдвига с прямой и обратной связью, представленные по большей части как разряды памяти и соединительные линии. Важно обратить внимание на то, что часто оказывается удобным представлять кодер (конкретнее, рекурсивный кодер) на регистрах сдвига несколько иным образом. Некоторые авторы для обозначения временных задержек (как правило, длиной в 1 бит) используют блоки, помеченные буквами D или Т. Соединения вне блоков, передающие напряжение или логические уровни, представляют память кодера между тактами. Два формата — блоки памяти и блоки задержек — никоим образом не меняют характеристик или функционирования описанного выше процесса. Для некоторых конечных автоматов с множеством рекурсивных соединений при отслеживании сигналов более удобным может оказаться применение формата блоков задержек. В задачах 8.23 и 8.24 используются кодеры, изображенные на рис. 38.2 и 38.3. При использовании формата разрядов памяти текущее состояние системы определяется содержимым крайних правых ![]() разрядов. Аналогично для формата блоков задержек текущее состояние определяется уровнями сигналов в крайних правых
разрядов. Аналогично для формата блоков задержек текущее состояние определяется уровнями сигналов в крайних правых ![]() узлах (соединения вне блоков задержек). Для обоих форматов связь между памятью v и длиной кодового ограничения K одинакова, т.е.
узлах (соединения вне блоков задержек). Для обоих форматов связь между памятью v и длиной кодового ограничения K одинакова, т.е. ![]() . Таким образом, на рис. 38.2 три блока задержек означают, что
. Таким образом, на рис. 38.2 три блока задержек означают, что ![]() v = 3 и
v = 3 и ![]() . Аналогично на рис. 38.3 два блока задержек означают, что
. Аналогично на рис. 38.3 два блока задержек означают, что ![]() , а
, а ![]() .
.
Приложение 8А. Сложение логарифмических отношений правдоподобий
Ниже приводятся алгебраические подробности, используемые при выводе уравнения (8.72).
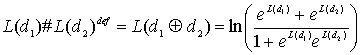 (8A.1)
(8A.1)
Начнем с записи отношения правдоподобия апостериорной вероятности того, что информационный бит равен +1, к апостериорной вероятности того, что он равен -1. Поскольку логарифм отношения правдоподобий, обозначаемый L(d), берется по основанию e, это можно записать следующим образом.
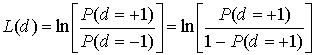 , (8.A2)
, (8.A2)
так что
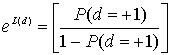 . (8A3)
. (8A3)
Выражая ![]() , получаем следующее.
, получаем следующее.
![]() (8А.4)
(8А.4)
![]() (8А.5)
(8А.5)
и
![]() (8.A6)
(8.A6)
Из уравнения (8А.6) видно, что
![]() . (8А.7)
. (8А.7)
Пусть ![]() и
и ![]() два статистически независимых бита данных, задаваемых уровнями напряжения +1 и -1, соответствующими логическим уровням 1 и 0.
два статистически независимых бита данных, задаваемых уровнями напряжения +1 и -1, соответствующими логическим уровням 1 и 0.
При таком формате сложение (по модулю 2) ![]() и
и ![]() дает -1, если
дает -1, если ![]() , и
, и ![]() имеют одинаковое значение (оба равны +1 или -1, одновременно), и +1, если
имеют одинаковое значение (оба равны +1 или -1, одновременно), и +1, если ![]() и
и ![]() имеют разные значения. Тогда
имеют разные значения. Тогда
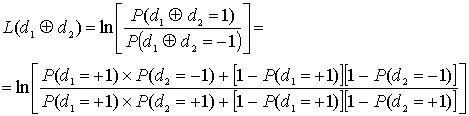 (8А-8)
(8А-8)
Воспользовавшись уравнениями (8А.6) и (8А.7) для замены вероятностного члена в уравнении (8А.8), получаем следующее.
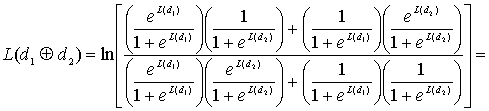 (8A.9)
(8A.9)
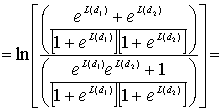 (8A.10)
(8A.10)
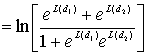 (8A.11)
(8A.11)
Литература
1. Gallager R. G. Information Theory and Reliable Communication. John Wiley and Sons, New York, 1968.
2. Odenwalder J. P. Error Control Coding Handbook. Linkabit Corporation, San Diego, CA, July, 15, 1976.
3. Derlekamp E. R., Peile R. E. and Pope S. P. The Application of Error Control to Communicftions.IEEE Communication Magazine, vol. 25, n. 4, April, 1987, pp. 44-57.
4. Hagenauer J. and Lutz E. Forward Error Correction Coding for Fading Compensation in Mobile Satellite Channels. IEEE J. on Selected Areas in Comm., vol. SAC-5, n. 2, February, 1987, pp. 215-225.
5. Blahut R. E. Theory and Practice of Error Control Codes. Addison-Wesley Publishing Co., Reading, Massachusetts, 1983.
6. Reed-Solomon Codes and Their Applications, ed. Wicker S. B. and Bhargava V. K. IEEE Press, Piscataway, New Jersey, 1983.
7. Ramsey J. L. Realization of Optimum Interleaves. IEEE Trans. Inform. Theory, vol. IT-16, n. 3, May, 1970, pp.338-345.
8. Forney G. D. Burst-Correcting Codes for the Classic Bursty Channel. IEEE Trans. Commun. Technol., vol. COM-19, October, 1971, pp. 772-781.
9. Clark G. C. Jr. and Cain J. B. Error-Corection Coding for Digiral Communications. Plenum Press, New York, 1981.
10. J. H. Yuen, et. al. Modulation and Coding for Satellite and Space Communications. Proc. IEEE,vol. 78., n. 7, July, 1990, pp. 1250-1265.
11. Peek J. B. H. Communications Aspects of the Compact Disc Digital Audio System. IEEE Communication Magazine, vol. 23, n. 2, February, 1985, pp.7—20.
12. Berkhout P. J. and Eggermont L. D. J. Digital Audio Systems. IEEE ASSP Magazine, October, 1985, pp. 45-67.
13. Driessen L. M. H. E. and Vries L. B. Performance Calculations of the Compact Disc Error Correcting Code on Memoryless Channel. Fourth Int'l. Conf. Video and Data Recording, Southampton, England, April 20-23, 1982, IERE Conference Proc #54, pp. 385-395.
14. Hoeve H., Timmermans J. and Vries L. B. Error Correction in the Compact Disc System. Philips Tech. Rev., vol. 40, n. 6, 1982, pp. 166-172.
15. Pohlmann K. C. The Compact Disk Handbook. A-R Editions Inc., Madison, Wisconsin, 1992.
16. Forney G. ОЛг. Concatenated Codes. Cambridge, Massachusetts: M. I. T. Press, 1966.
17. Berrou C., Glavieux A. and Thitimajshima P. Near Shannon Limit Error-Correcting Coding and Decoding: Turbo Codes. IEEE Prceedings of the Int. Conf. on Communications, Geneva, Switzerland, May, 1993 (ICC'93), pp. 1064-1070.
18. Berrou C., Glavieux A. Near Optimum Error Correcting Coding and Decoding: Turbo-Codes. IEEE Trans. On Communications, vol. 44, n. 10, October, 1996, pp. 1261-1271.
19. Hagenauer J. Iterative Decoding of Binary Block and Conventional Codes. IEEE Trans. On Information Theory, vol. 42, n. 2, March, 1996, pp. 429-445.
20. Divsalar D. and Pollara F. On the Design of Turbo Codes. TDA Progress Report 42-123, Jet Propulsion Laboratory, Pasadena, California, November, 15, 1995, pp. 99—121.
21. Divsalar D. and McElience R. J. Effective Free Distance of Turbo Codes. Electronic Letters, vol. 23, n. 5, February, 29, 1996, pp. 445-446.
22. Dolinar S. and Divsalar D. Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations. TDA Progress Report 42-122, Jet Propulsion Laboratory, Pasadena, California, August, 15, 1995, pp. 56-65.
23. Divsalar D. and Pollara F. Turbo Codes for Deep-Space Communications. TDA Progress Report 42—120, Jet Propulsion Laboratory, Pasadena, California, February, 15, 1995, pp. 29-39.
24. Divsalar D. and Pollara F. Multiple Turbo Codes for Deep-Space Communications. TDA Progress Report 42-121, Jet Propulsion Laboratory, Pasadena, California, May, 15, 1995, pp. 66-77.
25. Divsalar D. and Pollara F. Turbo Codes for PCS Applications. Proc. ICC'95, Seattle, Washington, June, 18-22, 1995.
26. Bahl. L. R., Cocke J., Jelinek F. and Raviv J. Optimal Decoding of Linear Codes for Minimizing Symbol Error Rate. Trans. Inform. Theory, vol. IT-20, March, 1974, pp. 248-287.
27. Benedetto S. et. al. Soft Output Decoding Algorithm in Iterative Decoding of Turbo Codes. TDA Progress Report 42-124, Jet Propulsion Laboratory, Pasadena, California, February, 15, 1996, pp. 63-87.
28. Benedetto S. et. al. A Soft-Input Soft-Output Maximum A Posteriori (MAP) Module to Decode Parallel and Serial Concatenated Codes. TDA Progress Report 42-127, Jet Propulsion Laboratory, Pasadena, California, November, 15, 1996, pp. 63-87.
29. Benedetto S. et. al. A Soft-Input Soft-Output APP Module for Iterative Decoding of Concatenated Codes. IEEE Communication Letters, vlo. 1, n. 1, January, 1997, pp. 22-24.
30. Pietrobon S. Implementation and Performance of a Turbo/MAP Decoder. Int'l. J. Satellite Commun., vol. 15, January-February, 1998, pp. 23-46v
31. Robertson P., Villebrun E. and Hoeher P. A Comparison of Optimal and Sub-Optimal MAP Decoding Algorithms Operating in the Log Domain. Proc. of ICC'95, Seattle, Washington, June, 1995, pp. 1009-1013.
Задачи
8.1. Определите, какой из следующих полиномов будет примитивным. Подсказка: самый простой способ состоит в применении LFSR; аналогично способу, показанному на рис. 8.8.
а) ![]()
б) ![]()
в) ![]()
г) ![]()
д) ![]()
е) ![]()
ж) ![]()
з) ![]()
и) ![]()
8.2. а) Какова способность к коррекции ошибок у кода (7, 3)? Сколько
битов в символе?
б) Определите количество строк и столбцов нормальной матрицы (см. раздел 6.6), необходимой для представления кода (7, 3), описанного в п. а.
в) Подтвердите, что при использовании размерности нормальной матрицы из п. б получается способность к коррекции ошибок, найденная в п. а.
г) Является ли код (7; 3) совершенным? Если нет; то какую остаточную способность к коррекции ошибок он имеет?
8.3. а) Определите множество элементов ![]() через образующие
через образующие
элементы конечного поля GF(![]() ), при
), при ![]() .
.
б) Для конечного поля, определенного в п. а, составьте, таблицу сложения, аналогичную табл. 8.2.
в) Постройте таблицу умножения, подобную табл. 8.3.
г) Найдите полиномиальный генератор для кода (31, 27).
д) Кодируйте сообщение {96 нулей, затем 110010001111} (крайний правый бит является первым) систематическим кодом (7, 3). Почему, по вашему мнению, сообщение построено с таким большим количеством нулей в начале?
8.4. С помощью полиномиального генератора для кода (7, 3), кодируйте
сообщение 010110111 (крайний правый бит является первым) в систематической форме. Для нахождения полинома контроля четности используйте полиномиальное деление. Представьте итоговое кодовое слово в двоичной и полиномиальной форме.
8.5. а) Применяйте регистр LFSR для кодирования сообщения {6, 5, 1}
(крайний правый бит является первым) с помощью кода (7, 3) в систематической форме. Представьте итоговое кодовое слово в двоичной форме.
б) Проверьте результат кодирования в п. а путем вычисления полинома кодового слова со значениями корней полиномиального генератора кода (7, 3).
8.6. а) Пусть кодовое слово, найденное в задаче 8.5, искажается в ходе
передачи, в результате чего крайние правые 6 бит были инвертированы. Найдите значения всех синдромов путем вычисления полинома поврежденного кодового слова со значениями корней полиномиального генератора, g(X).
б) Проверьте, что значения синдромов, вычисленные в п. а, можно найти путем вычисления полинома ошибок, e(Х), со значениями корней генератора g(X).
8.7. а) Воспользуйтесь авторегрессионной моделью из уравнения (8.40)
вместе с искаженным кодовым словом из задачи 8.6 для нахождения месторасположения каждой символьной ошибки.
б) Найдите значение каждой символьной ошибки.
в) Воспользуйтесь сведениями, полученными в пп. а и б, чтобы исправить искаженное кодовое слово.
8.8. Последовательность 1011011000101100 подается на вход блочного
устройства чередования размером ![]() . Какой будет выходная последовательность? Та же последовательность передана на сверточное устройство чередования, изображенное на рис.. 8.13. Какой будет выходная последовательность в этом случае?
. Какой будет выходная последовательность? Та же последовательность передана на сверточное устройство чередования, изображенное на рис.. 8.13. Какой будет выходная последовательность в этом случае?
8.9. Для каждого из следующих условий разработайте устройство чередования
для системы связи, действующей в канале с импульсными помехами со скоростью передачи 19200 кодовых символов/с.
а) Как правило, пакет шума длится 250 мс. Системным кодом является БЧХ (127, 36) при ![]() . Прямая задержка не превышает 5 с.
. Прямая задержка не превышает 5 с.
б) Как правило, пакет шума длится 20 мс. Системным кодом является сверточный код (127, 36) с обратной связью при степени Кодирования 1/2, способный корректировать в среднем 3 символа в последовательности из 21 символа. Прямая задержка не превышает 160 мс.
8.10 а) Рассчитайте вероятность появления байтовой (символьной) ошибки
после декодирования данных, находящихся на\ компакт-диске! как было описано в разделе 8.3. Считается, что вероятность передачи канального символа с ошибкой для компакт-диска составляет ![]() . Предполагается также, что внешний и внутренний декодеры сконфигурированы для коррекции всех 2-символьных ошибок и процесс чередования исключает корреляции ошибок между собой.
. Предполагается также, что внешний и внутренний декодеры сконфигурированы для коррекции всех 2-символьных ошибок и процесс чередования исключает корреляции ошибок между собой.
б) Повторите расчеты п. а для компакт-диска, для которого вероятность ошибочной передачи канального символа равна ![]() .
.
8.11. Система, в которой реализована модуляция BPSK, принимает
равновероятные биполярные символы (+1 или -1) с шумом AWGN. Дисперсия шума считается равной единице. В момент k значение принятого сигнала ![]() равняется 0,11.
равняется 0,11.
а) Вычислите два значения правдоподобия для этого принятого сигнала.
б) Каким будет максимальное апостериорное решение, +1 или -1?
в) Априорная вероятность того, что переданный символ равен +1, равна 0,3. Каким будет максимальное апостериорное решение, +1 или -1?
г) Считая априорные вероятности равными полученным в п. в, рассчитайте логарифмическое отношение правдоподобий ![]() .
.
8.12. Рассмотрим пример двухмерного кода с контролем четности, описанного
в разделе 8.4.3. Как указано, переданные символы представляются в виде последовательности ![]() , которая определяет степень кодирования кода равной 1/2. Конкретная схема, требующая более высоких скоростей, выдает кодовую последовательность этого кода с исключениями через один бит, что дает в итоге степень кодирования, равную 2/3. Переданный выход теперь определяется последовательностью
, которая определяет степень кодирования кода равной 1/2. Конкретная схема, требующая более высоких скоростей, выдает кодовую последовательность этого кода с исключениями через один бит, что дает в итоге степень кодирования, равную 2/3. Переданный выход теперь определяется последовательностью ![]() , где i и j являются индексами месторасположения. Помехи преобразуют эту последовательность данных и контрольных разрядов в принятую последовательность
, где i и j являются индексами месторасположения. Помехи преобразуют эту последовательность данных и контрольных разрядов в принятую последовательность ![]() 0,05, 0,10, 0,15 1,25, 3,0, где k —временной индекс. Вычислите значения мягкого выхода для битов данных после двух горизонтальных и двух вертикальных итераций декодирования. Дисперсия считается равной единице.
0,05, 0,10, 0,15 1,25, 3,0, где k —временной индекс. Вычислите значения мягкого выхода для битов данных после двух горизонтальных и двух вертикальных итераций декодирования. Дисперсия считается равной единице.
8.13. Рассмотрим параллельное соединение двух составных RSC-кодеров, как
показано на рис. 8.26. Устройство чередования блоков размером 10 отображает последовательность входных битов ![]() в последовательность
в последовательность ![]() , где влияние устройства чередования задается равным [6, 3, 8, 9, 5, 7, 1, 4, 10, 2], т.е. первый бит входного блока данных отображается на позицию 6, второй бит — на позицию 3 и т.д. Входная последовательность равна (0, 1, 1, 0, 0, 1, 0, 1, 1,0). Предполагается, что составной кодер начинает из нулевого состояния и к нему принудительно прибавляется бит погашения, необходимый для перевода кодера обратно в нулевое состояние.
, где влияние устройства чередования задается равным [6, 3, 8, 9, 5, 7, 1, 4, 10, 2], т.е. первый бит входного блока данных отображается на позицию 6, второй бит — на позицию 3 и т.д. Входная последовательность равна (0, 1, 1, 0, 0, 1, 0, 1, 1,0). Предполагается, что составной кодер начинает из нулевого состояния и к нему принудительно прибавляется бит погашения, необходимый для перевода кодера обратно в нулевое состояние.
а) Рассчитайте 10-битовую контрольную последовательность ![]() .
.
б) Рассчитайте 10-битовую контрольную последовательность ![]() .
.
в) Переключатель осуществляет исключение из последовательности ![]() так, что последовательность
так, что последовательность ![]() становится равной
становится равной ![]() , а степень кодирования кода равна 1/2. Рассчитайте весовой коэффициент выходного кодового слова.
, а степень кодирования кода равна 1/2. Рассчитайте весовой коэффициент выходного кодового слова.
г) Если декодирование осуществляется на основе алгоритма MAP, какие изменения, по-вашему, нужно внести в метрики состояний и метрики ветвей, если кодер не погашен?
8.14. а) Для нерекурсивного кодера, изображенного на рис. 38.1, вычислите
минимальное расстояние по всему коду.
б) Для рекурсивного кодера, изображенного на рис. 8.26, вычислите минимальное расстояние по всему коду. Считайте, что исключений битов нет, а значит, степень кодирования кода равна 1/3.
в) Для кодера, показанного на рис. 8.26, обсудите изменения в весовом коэффициенте выходной последовательности, если вход каждого составного кодера определяется последовательностью с весом 2 (00...00100100...00) (считать, что исключений нет).
г) Повторите п. в для последовательности с весом 2 (00...0010100...00).
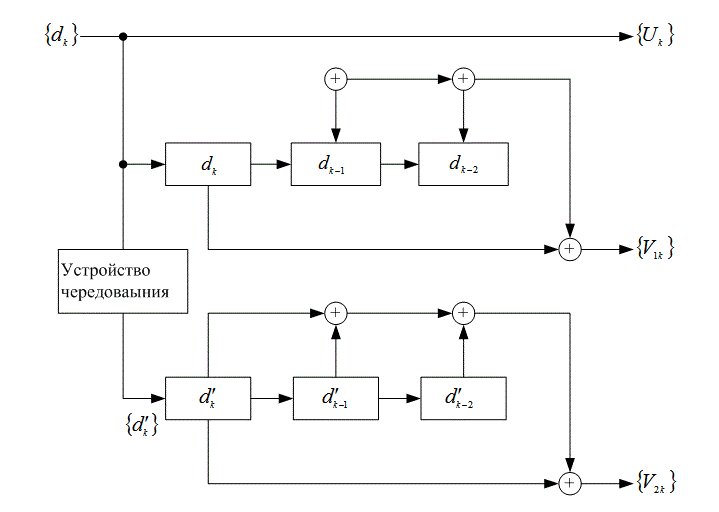
Рис. 38.1. Схема кодера с нерекурсивными составными кодами
8.15. Рассмотрим кодер, представленный на рис.8.25, а. Пусть он используется
в качестве составного кода в турбокоде. Его решетчатая структура из 4 состояний изображена на рис.8.25, б. Степень кодирования кода равна 1/2. Ветвь, помеченная как и, v, представляет выходное ответвляющееся слово (кодовые биты) для той ветви, где и является битами данных (систематический код), a v — контрольными битами. Биты данных и контроля четности передаются за каждый такт k. Сигналы, принятые из демодулятора, имеют искаженные помехами значения и,v: 1,9; 0,7 — в момент k = 1 и -0,4; 0,8 — в момент k = 2. Предполагается, что априорные вероятности битов 1 и 0 равновероятны и что кодер начинает из нулевого состояния в начальный момент k = 1. Также считается, что дисперсия помех равна 1,3. Напомним, что последовательность N бит характеризуется N интервалами переходов и N + 1 состояниями (от начального до конечного). Следовательно, в данном случае биты стартуют в моменты k = 1, 2, и интерес представляют метрики в моменты k = 1,2,3.
а) Рассчитайте метрики ветвей для моментов k = 1 и k = 2, которые нужны для применения алгоритма MAP.
б) Вычислите прямые метрики состояний для моментов k = 1, 2 и 3.
в) Ниже для каждого правильного состояния в табл. 38.1 даются значения обратных метрик в моменты k = 2и k = 3. Основываясь на данных таблицы и значениях, полученных в пп. а и б, вычислите значение логарифмического отношения правдоподобий, соответствующего битам данных в моменты k = 1 и k = 2.С помощью правила принятия решений MAP найдите наиболее вероятную последовательность информационных битов, которая могла быть передана.
Таблица 38.4
|
|
|
|
|
|
4,6 |
2,1 |
|
|
2,4 |
11,5 |
|
|
5,7 |
3,4 |
|
|
4,3 |
0,9 |
8.16. Пусть принятая последовательность, полученная в задаче 8.15 для кода со
степенью кодирования 2/3, создается путем исключений из кода со степенью кодирования 1/2 (задаваемого решеткой на рис. 8.25, б). Исключение происходит таким образом, что передается только каждый второй контрольный бит. Таким образом, принятая последовательность из четырех сигналов представляет собой информационный бит, контрольный бит, информационный бит, информационный бит. Вычислите метрики ветвей и прямые метрики состояний для моментов времени k = 1 и k = 2, которые необходимы для алгоритма MAP.
8.17. Решетка для кода из четырех состояний используется как составной код в
турбокоде, как показано на рис. 8.25, б. Степень кодирования равна 1/2, а ветвь, обозначенная как и, v, представляет собой выход, ответвляющееся слово (кодированные биты) для этой ветви, где и — это информационные биты, a v — биты четности. Из демодулятора принимается блок из N = 1024 фрагментов. Пусть первый сигнал из демодулятора поступает в момент k = 1 и в каждый последующий момент k поступают зашумленные биты данных и контроля четности. В момент времени = 1023 принятые сигналы имеют зашумленные значения и, v, равные 1,3; -0,8, а в момент k = 1024 значения равны -1,4; -0,9. Предполагается, что априорные вероятности того, что биты данных равны 1 или 0, равны и что конечное состояние кодера будет а = 00 в завершающий момент k = 1025. Также считается, что дисперсия помех равна 2,5.
а) Рассчитайте метрики ветвей для моментов k = 1023 и k = 1024.
б) Рассчитайте обратные метрики состояний для моментов k = 1023, 1024 и 1025.
в) Ниже в табл. 38.2 даются значения прямых метрик состояний в моменты k = 1023 и k — 1024 для каждого правильного состояния. Основываясь на таблице и информации из пп. а и б, вычислите значения отношений правдоподобий, связанных с информационными битами в моменты времени k = 1023 и k = 1024. Используя правило принятия решений алгоритма MAP, найдите наиболее вероятную последовательность битов данных, которая могла быть передана.
Таблица 38.2
|
|
|
|
|
|
6,6 |
12,1 |
|
|
7,0 |
1,5 |
|
|
4,2 |
13,4 |
|
|
4,0 |
5,9 |
8.18. Имеется два статистически независимых наблюдения зашумленного
сигнала, ![]() и
и ![]() . Проверьте, что логарифмическое отношение правдоподобий (log-likelihood ratio — LLR)
. Проверьте, что логарифмическое отношение правдоподобий (log-likelihood ratio — LLR) ![]() можно выразить через индивидуальные LLR как
можно выразить через индивидуальные LLR как
![]() ,
,
где L(d) является априорным LLR основного бита данных d.
8.19. а) Используя теорему Байеса, подробно распишите этапы
преобразования ![]() , приведенной в уравнениях (8.129) и (8.130,6). Подсказка: воспользуйтесь упрощенной системой обозначений, применяемой в уравнениях (8.121) и (8.122).
, приведенной в уравнениях (8.129) и (8.130,6). Подсказка: воспользуйтесь упрощенной системой обозначений, применяемой в уравнениях (8.121) и (8.122).
б) Объясните, каким образом суммирование по состояниям ![]() в уравнении (8.130,а) дает в итоге уравнение (8.130,б).
в уравнении (8.130,а) дает в итоге уравнение (8.130,б).
в) Повторите п. а и покажите, как уравнение (8.133) переходит в уравнение (8.135).Также объясните, как суммирование по состояниям ![]() в будущий момент
в будущий момент ![]() дает уравнение (8.135).
дает уравнение (8.135).
8.20.Исходя из уравнения (8.139) для метрики ветви ![]() , покажите, каким образом получается уравнение (8.140), и укажите, какие члены следует считать постоянными
, покажите, каким образом получается уравнение (8.140), и укажите, какие члены следует считать постоянными ![]() в уравнении (8.140). Почему члены
в уравнении (8.140). Почему члены ![]() не появляются в уравнении (8.140,а)?
не появляются в уравнении (8.140,а)?
8.21. Устройство чередования на рис. 8.27 (аналогичное устройству в
соответствующем кодере) гарантирует, что выходная последовательность декодера DEC1 упорядочена во времени так же, как и последовательность ![]()
![]() . Можно ли реализовать это более простым способом? Что можно сказать о применении устройства восстановления в нижнем ряду? Не будет ли это более простым способом? Если это осуществить, тогда можно будет убрать два прежних устройства восстановлений. Объясните, почему это не сработает.
. Можно ли реализовать это более простым способом? Что можно сказать о применении устройства восстановления в нижнем ряду? Не будет ли это более простым способом? Если это осуществить, тогда можно будет убрать два прежних устройства восстановлений. Объясните, почему это не сработает.
8.22. При декодировании согласно алгоритму Витерби, используется
устройство сложения, сравнения и выбора (add-compare-select — ACS). А при реализации алгоритма максимума апостериорной (maximum a posteriori — MAP) вероятности в турбодекодировании не применяется идея сравнения и выбора переходов. Вместо этого в алгоритме MAP рассматриваются все метрики ветвей и состояний для данного интервала времени. Объясните это принципиальное различие между двумя алгоритмами.
8.23. На рис. 38.2 показан рекурсивный систематический сверточный (recursive
systematic convolutional — RSC) кодер со степенью кодирования 1/2, К = 4. Заметьте, что на рисункеиспользуется формат памяти в виде 1-битовых блоков задержек (см. раздел 8.4.7.4). Следовательно, текущее состояние цепи можно описать с помощью уровней сигналов в точках ![]() ,
, ![]() ,
,![]() , аналогично способу описания состояния в формате разрядов памяти. Составьте таблицу, аналогичную табл. 8.5, которая будет определять все возможные переходы в цепи, и с ее помощью изобразите участок решетки.
, аналогично способу описания состояния в формате разрядов памяти. Составьте таблицу, аналогичную табл. 8.5, которая будет определять все возможные переходы в цепи, и с ее помощью изобразите участок решетки.
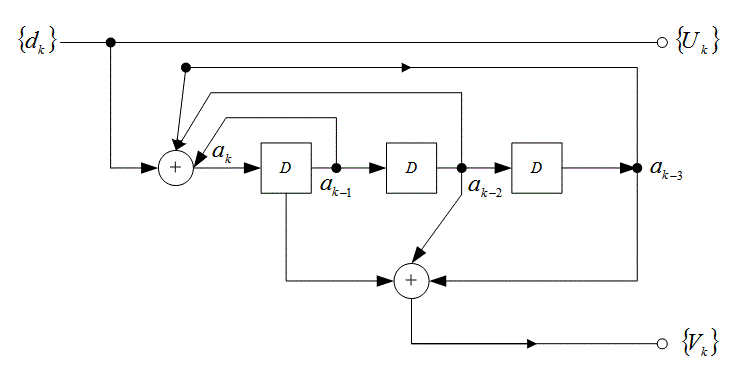
Рис. 38.2. Рекурсивный систематический сверточный (RSC) кодер со степенью кодирования 1/2, К = 4
8.24. На рис. 38.3 показан рекурсивный систематический сверточный (recursive
systematic convolutional — RSC) кодер со степенью кодирования 2/3, К=3. Заметьте, что на рисунке используется формат памяти в виде 1-битовых блоков задержек (см. раздел 8.4.7.4). Составьте таблицу, аналогичную табл. 8.5, которая будет определять все возможные переходы в цепи, и с ее помощью изобразите участок решетки. С помощью таблицы, подобной табл. 8.6, найдите выходное кодовое слово для информационной последовательности 1 1 0 0 1 1 0 0 1 1.В течение каждого такта данные поступают в цепь в виде пары ![]() , а каждое выходное ответвляющееся слово
, а каждое выходное ответвляющееся слово ![]() образуется из пары битов данных и одного контрольного бита,
образуется из пары битов данных и одного контрольного бита, ![]() .
.
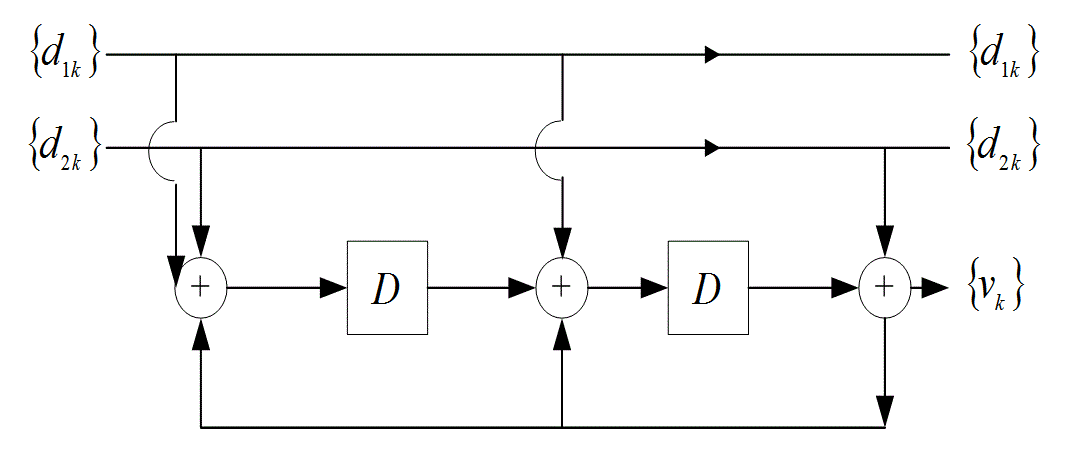
Рис. 38.3, Рекурсивный систематический сверточный (RSC) кодер со степенью кодирования 2/3, К = 3
8.25. Рассмотрим турбокод, состоящий из двух сверточных кодов, которые, в
свою очередь, состоят из четырех состояний. Оба составных кода описываются решеткой, которая изображена на рис. 8.25, б. Степень кодирования кода равна 1/2, а длина блока — 12. Второй кодер оставлен не погашенным. Метрики ветвей, прямые метрики состояний и обратные метрики состояний для информационных битов, связанных с кодером в конечном состоянии, описываются матрицей, изображенной ниже. Принятый 12-сигнальный вектор образован из сигнала данных, сигнала контроля четности, сигнала данных, сигнала контроля четности и т.д. и имеет следующие значения.
1,2 1,3 -1,2 0,6 -0,4 1,9-0,7 -1,9 -2,2 0,2 -0,1 0,6 Матрица ветвей ![]()
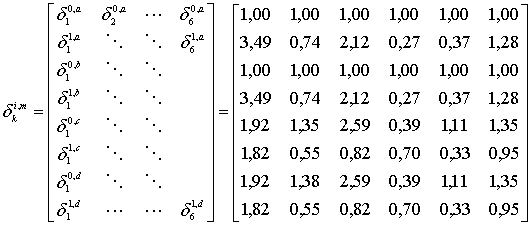
Альфа-матрица ![]()
![]()

Бета-матрица ![]()

Вычислите логарифмическое отношение правдоподобий для каждого из шести информационных битов ![]() . С помощью правила принятия решений алгоритма MAP найдите наиболее вероятную последовательность информационных битов, которая могла быть передана.
. С помощью правила принятия решений алгоритма MAP найдите наиболее вероятную последовательность информационных битов, которая могла быть передана.
Вопросы для самопроверки
8.1. Объясните высокую эффективность кодов Рида-Соломона при наличии импульсных помех (см. раздел 8.1.2.).
8.2. Объясните, почему кривые на рис. 8.6 показывают снижение достоверности передачи при низких значениях степеней кодирования (см раздел 8.1.З.).
8.3. Среди всех способов определения примитивности полинома наиболее простой — использование линейного регистра сдвига с обратной связью (linear feedback shift register —LFSR). Объясните эту процедуру (см. пример 8.2.).
8.4. Объясните, каким образом можно получить синдром, вычисляя принятый полином со всеми значениями корней полиномиального генератора кода (см. раздел 8.1.6.1).
8.5. Какое ключевое преобразование осуществляет система чередования/восстановления над мпульсными помехами (см. раздел 8.2.1.)?
8.6. Почему предел Шеннона, равный -1,6 дБ, не представляет интереса при разработке реальных систем (см. раздел 8.4.5.2.)?
8.7. Почему алгоритм декодирования Витерби не дает апостериорных вероятностей (см. раздел 8.4.6.)?
8.8. Каково более описательное название алгоритма Витерби (см. раздел 8.4.6.)?
8.9. Опишите сходство и отличие в реализации декодирования на основе алгоритмов Витерби и максимума апостериорной вероятности (MAP) (см. раздел 8.4.6.).